redis基础结构
title: redis基础结构
date: 2025-03-04 08:39:12
tags: redis
categories: redis笔记
Redis入门
(NoSQL, Not Only SQL) 非关系型数据库

关系型数据库:以 表格 的形式存在,以 行和列 的形式存取数据,一系列的行和列被称为表,无数张表组成了 数据库。支持复杂的 SQL 查询,能够体现出数据之间、表之间的关联关系;也支持事务,便于提交或者回滚。
非关系型数据库:以 key-value 的形式存在,可以想象成电话本的形式,人名(key)对应电话号码(value)。不需要写一些复杂的 SQL 语句,不需要经过 SQL 的重重解析,性能很高;可扩展性也比较强,数据之间没有耦合性,需要新加字段就直接增加一个 key-value 键值对即可。
Redis 是 速度极快的、基于内存的,键值型 NoSQL 数据库。
为什么这么快?
-
完全基于内存操作。
-
使用非阻塞的 IO 多路复用机制。
-
数据结构简单,对数据操作也简单。
-
使用单线程,避免了上下文切换和竞争产生的消耗。
-
支持多种数据类型,包括 String、Hash、List、Set、ZSet 等。
IO 多路复用机制
Redis 使用的是 IO 多路复用机制 来处理 高并发请求,这使得它能在 单线程 模式下仍然保持高吞吐量。
🔹 Redis 为什么要用 IO 多路复用?
- Redis 是单线程的,但仍然能高效处理大量连接,这依赖于 IO 多路复用。
- 传统的 阻塞 IO 方式,每次只能处理一个连接,性能受限。
- 多路复用可以 同时监听多个客户端请求,只处理活跃连接,减少 CPU 空转。
🔹 Redis 的 IO 多路复用机制
Redis 采用 epoll(Linux)或 select(Windows) 作为 IO 多路复用技术,主要使用 aeEventLoop 事件处理机制:
- 主线程通过
epoll/select/kqueue监听多个客户端连接 - 当某个连接有数据可读(如命令请求),Redis 触发相应的回调函数
- 回调函数读取请求,处理命令,返回结果
- 继续监听新的请求,不会阻塞在某个请求上
Redis 使用 事件驱动模型,主要有:
- 可读事件(AE_READABLE):当客户端有数据可读时触发。
- 可写事件(AE_WRITABLE):当客户端可以写数据时触发。
- 文件事件(File Event):通过
epoll监听 多个 socket 连接。 - 时间事件(Time Event):用于定时任务(比如 key 过期检测)。
🔹 Redis 多路复用示意图
[多个客户端]│▼
[epoll/select 监听]│├── 客户端 A 可读 -> 触发回调 -> 读取数据├── 客户端 B 可写 -> 触发回调 -> 发送数据├── 客户端 C 可读 -> 触发回调 -> 读取数据│▼
[主线程执行 Redis 命令逻辑]
Redis的基础结构类型
Key结构
让 Redis 的 key 形成层级结构,使用 : 隔开:项目名:业务名:类型:id。
set blog:user:1 '{"id":1, "name":"Jack", "age":22}'
set blog:user:2 '{"id":2, "name":"Mike", "age":23}'
set blog:article:1 '{"id":1, "title":"Spring"}'
String类型
| Key | Value |
|---|---|
| blog:user:1 | ‘{“id”:1, “name”:“Jack”, “age”:22}’ |
| blog:user:2 | ‘{“id”:2, “name”:“Mike”, “age”:23}’ |
分配策略:
Java 的 String 是不可变的,无法修改。Redis 的 String 是动态的,可以修改的。Redis 的 String 在内部结构实现上类似于 Java 的 ArrayList,采用预分配冗余空间的方式来减少内存的频繁分配。如图所示,当前字符串实际分配的空间为 capacity,一般高于实际的字符串长度 len。当字符串长度小于 1M 时,扩容是对现有空间的成倍增长;如果长度超过 1M 时,扩容一次只会多增加 1M 的空间。String 的最大长度为 512M。

Hash结构

list结构
List 类似 Java 中的 LinkedList,可以看作一个双向链表(有序可重复)。使用 List 可以对链表的两端进行 push 和 pop 操作、读取单个或多个元素、根据值查找或删除元素、支持正向检索和反向检索。
栈:LPUSH + LPOP 或 RPUSH + RPOP。
队列:LPUSH + RPOP 或 RPUSH + LPOP。
Set结构
SADD key member [member ...] :向 Set 中添加一个或多个元素。
SMEMBERS key :获取指定 Set 中的所有元素。
SISMEMBER key member :判断 Set 中是否存在指定元素。
SCARD key :返回 Set 中的元素个数。
SREM key member [member ...] :移除 Set 中的指定元素。
SINTER key [key ...] :求 n 个 key 间的交集。
SDIFF key [key ...] :求 n 个 key 间的差集。
SUNION key [key ...] :求 n 个 key 间的并集。
Redis 的 Set 类似 HashSet,可以看作一个 value 为 null 的 HashMap;其特征也与 HashSet 类似:无序不可重复,支持 交集、并集、差集等功能。
ZSet
Redis 的 ZSet 是一个可排序的 Set 集合,类似 ZSet。ZSet 的每一个元素都带有一个 score 属性,可以基于 score 属性对元素排序。
ZADD key [score member ...] :以 score 为权重向 ZSet 中添加一个或多个元素,如果存在则更新 score。
ZREM key member [member ...] :删除 ZSet 中的指定元素。
ZCARD key :返回 ZSet 中的元素个数。
ZSCORE key member :获取 ZSet 中指定元素的 score 值。
ZADD key [score member ...] :以 score 为权重向 ZSet 中添加一个或多个元素,如果存在则更新 score。
ZREM key member [member ...] :删除 ZSet 中的指定元素。
ZCARD key :返回 ZSet 中的元素个数。
ZSCORE key member :获取 ZSet 中指定元素的 score 值。
ZRANGEBYSCORE key min max :按照 score 排序后,获取 指定 score 范围 内的元素。
ZINTER numberKeys key [key ...] | ZDIFF numberKeys key [key ...] | ZUNION numberKeys key [key ...] :求 n 个 Zset 的交集、差集、并集。
Redis 基础结构及其操作指令总结
| 基础结构 | 描述 | 常用指令 | 示例 |
|---|---|---|---|
| String(字符串) | 最基本的数据结构,可以存储字符串、整数或浮点数 | SET、GET、INCR、DECR、APPEND、MSET、MGET | SET key value,GET key |
| List(列表) | 有序集合,允许重复元素,底层为双向链表 | LPUSH、RPUSH、LPOP、RPOP、LRANGE | LPUSH mylist A B C,LRANGE mylist 0 -1 |
| Set(集合) | 无序集合,不允许重复元素 | SADD、SREM、SMEMBERS、SISMEMBER | SADD myset A B C,SMEMBERS myset |
| Hash(哈希) | 类似于对象,存储键值对 | HSET、HGET、HGETALL、HDEL | HSET user name "Alice",HGET user name |
| ZSet(有序集合) | 具有权重(score)的集合,元素按分数排序 | ZADD、ZRANGE、ZREM、ZSCORE | ZADD myzset 1 A 2 B,ZRANGE myzset 0 -1 |
| Bitmap(位图) | 位级别的存储,用于高效存储和操作二进制数据 | SETBIT、GETBIT、BITCOUNT | SETBIT mybitmap 10 1,GETBIT mybitmap 10 |
| HyperLogLog | 近似去重计数结构,适用于大数据计数 | PFADD、PFCOUNT | PFADD myhll A B C,PFCOUNT myhll |
| Geo(地理位置) | 存储经纬度并计算地理距离 | GEOADD、GEODIST、GEORADIUS | GEOADD mygeo 120.0 30.0 "place1",GEODIST mygeo place1 place2 |
| Stream(流) | 可持久化的消息队列结构 | XADD、XLEN、XREAD | XADD mystream * name "Alice",XREAD COUNT 1 STREAMS mystream 0 |
这些结构和指令在不同的应用场景中有不同的优势,比如 String 适用于缓存数据,List 适用于消息队列,Set 适用于去重,ZSet 适用于排行榜,Hash 适用于存储对象,Bitmap 适用于用户签到或活跃记录,HyperLogLog 适用于大规模数据去重统计,Geo 适用于地理位置存储,Stream 适用于事件流和消息队列。
java客户端连接redis
使用Jedis
1.导入依赖
<dependency><groupId>redis.clients</groupId><artifactId>jedis</artifactId><version>3.8.0</version>
</dependency>
2.建立连接
public class JedisTest {private Jedis jedis;@BeforeEachvoid setUp(){//1.建立连接jedis = new Jedis("192.168.200.130",6379);//2.设置密码jedis.auth("1234");//3.选择库jedis.select(0);}@Testvoid testString(){String result = jedis.set("name", "小明");System.out.println("result= " + result);String name = jedis.get("name");System.out.println("name= "+name);}@AfterEachvoid tearDown(){if(jedis!=null){jedis.close();}}}3.jedis连接池
public class JedisConnectFactory {private static final JedisPool jedisPool;static{//配置连接池JedisPoolConfig poolConfig = new JedisPoolConfig();poolConfig.setMaxTotal(8);poolConfig.setMaxIdle(8);poolConfig.setMinIdle(0);poolConfig.setMaxWait(Duration.ofMillis(1000));jedisPool = new JedisPool(poolConfig,"192.168.200.130",6379,1000,"1234");}public static Jedis getJedis(){return jedisPool.getResource();}}1) JedisConnectionFacotry:工厂设计模式是实际开发中非常常用的一种设计模式,我们可以使用工厂,去降低代的耦合,比如Spring中的Bean的创建,就用到了工厂设计模式
2)静态代码块:随着类的加载而加载,确保只能执行一次,我们在加载当前工厂类的时候,就可以执行static的操作完成对 连接池的初始化
3)最后提供返回连接池中连接的方法.
使用springDataRedis连接

1.导入依赖
<!--Redis依赖--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId></dependency><!--连接池依赖--><dependency><groupId>org.apache.commons</groupId><artifactId>commons-pool2</artifactId></dependency>
2.配置连接信息
spring:redis:host: 192.168.200.130port: 6379password: 1234database: 0lettuce:pool:max-active: 8 #最大连接数max-idle: 8 #最大空闲连接min-idle: 0 #最小空闲连接max-wait: 100 #连接等待时间
3.直接注入RedisTemplate出现的问题
// 自动注入的 `RedisTemplate` 需要加上泛型
@Resource
private RedisTemplate redisTemplate;@Test
public void test() {redisTemplate.opsForValue().set("k1", "v1");Map<String, String> map = new HashMap<>();map.put("k2", "v2");map.put("k3", "v3");map.put("k4", "v4");map.put("k5", "v5");redisTemplate.opsForValue().multiSet(map);redisTemplate.opsForValue().multiGet(Arrays.asList("k1", "k2", "k3", "k4")).forEach(System.out::println); // v1 v2 v3 v4 v5
}//结果
# 在 Redis 中查看通过 RedisTemplate 插入的数据
> keys *
1) "\xac\xed\x00\x05t\x00\x02k1"
2) "\xac\xed\x00\x05t\x00\x02k2"
3) "\xac\xed\x00\x05t\x00\x02k3"
4) "\xac\xed\x00\x05t\x00\x02k4"
5) "\xac\xed\x00\x05t\x00\x02k5"> get "\xac\xed\x00\x05t\x00\x02k1"
"\xac\xed\x00\x05t\x00\x02v1"
RedisTemplate 存在的问题
通过以上操作可以发现:RedisTemplate 可以将任意类型的数据写入到 Redis 中,在写入前会将其序列化为字节形式存储,底层默认采用 ObjectOutputStream 序列化。
4.因此我们要重写他的序列化工具
导入 jackson-databind 依赖,并编写配置类 RedisTemplateConfig。
@Configuration
public class RedisTemplateConfig {@Beanpublic RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {// 创建 RedisTemplate 对象RedisTemplate<String, Object> redisTemplate = new RedisTemplate<>();// 设置连接工厂redisTemplate.setConnectionFactory(redisConnectionFactory);// 设置序列化工具GenericJackson2JsonRedisSerializer jsonRedisSerializer = new GenericJackson2JsonRedisSerializer();// Key 和 HashKey 采用 String 序列化(StringRedisSerializer)redisTemplate.setKeySerializer(RedisSerializer.string());redisTemplate.setHashKeySerializer(RedisSerializer.string());// Value 和 HashValue 采用 JSON 序列化(GenericJackson2JsonRedisSerializer)redisTemplate.setValueSerializer(jsonRedisSerializer);redisTemplate.setHashValueSerializer(jsonRedisSerializer);return redisTemplate;}
}
// 自动注入的 `RedisTemplate` 需要加上泛型
@Autowired
private RedisTemplate<String, Object> redisTemplate;@Test
public void test() {redisTemplate.opsForValue().set("k1", "v1");redisTemplate.opsForValue().set("user:1", new User("Jack", 21));
}通过以上的方法能够解决数据序列化时 可读性差、内存占用大 的问题。
但是 JSON 的序列化方式仍然存在一些问题:为了反序列化时知道对象的类型,JSON 序列化器会将类的 class 类型写入 JSON 结果,存入 Redis 中,会带来额外的内存开销。
5.使用StringRedisTemplate
为了节省内存空间,Spring 提供了一个 StringRedisTemplate,它的 key 和 value 的序列化方式默认就是 String,统一使用 String 序列化器。
当需要存储 Java 对象时,手动完成对象的序列化和反序列化。
- 使用 StringRedisTemplate。
- 写入数据到 Redis 中,手动将对象序列化为 JSON。
- 从 Redis 中读取数据,手动将读取到的 JSON 反序列化为对象。
@Autowired
private StringRedisTemplate stringRedisTemplate;private static final ObjectMapper objectMapper = new ObjectMapper();@Test
public void ttt() throws JsonProcessingException {User user = new User("Michael", 27);// 手动序列化String json = objectMapper.writeValueAsString(user);// 写入数据stringRedisTemplate.opsForValue().set("user:1", json);// 读取数据String data = stringRedisTemplate.opsForValue().get("user:1");// 反序列化User deserializedUser = objectMapper.readValue(data, User.class);System.out.println(deserializedUser);
}
//结果
{"username": "Michael","age": 27
}相关文章:
redis基础结构
title: redis基础结构 date: 2025-03-04 08:39:12 tags: redis categories: redis笔记 Redis入门 (NoSQL, Not Only SQL) 非关系型数据库 关系型数据库:以 表格 的形式存在,以 行和列 的形式存取数据,一系列的行和列被…...

【keil】一种将STM32的armcc例程转换为armclang的方式
【keil】一种将所有armcc例程转换为armclang的方式 改的原因第一步下载最新arm6第二步编译成功 第三步去除一些warning编译成功 我这边用armclang去编译的话,主要是freertos中的portmacro.h和port.c会报错 改的原因 我真的服了,现在大部分的单片机例程都…...

计算机视觉算法实战——表面缺陷检测(表面缺陷检测)
✨个人主页欢迎您的访问 ✨期待您的三连 ✨ ✨个人主页欢迎您的访问 ✨期待您的三连 ✨ ✨个人主页欢迎您的访问 ✨期待您的三连✨ 1. 引言 表面缺陷检测是计算机视觉领域中的一个重要研究方向,旨在通过图像处理和机器学习技术自动检测产品表面的缺陷&…...

window下的docker内使用gpu
Windows 上使用 Docker GPU需要进行一系列的配置和步骤。这是因为 Docker 在 Windows 上的运行环境与 Linux 有所不同,需要借助 WSL 2(Windows Subsystem for Linux 2)和 NVIDIA Container Toolkit 来实现 GPU 的支持。以下是详细的流程: 一、环境准备 1.系统要求 Window…...
)
Modbus协议(TCP)
从今开始,会详细且陆续整理各类的通信协议,以便在需要且自身忘记的情况下,迅速复习。如有错误之处,还请批评指正。 一、Modbus协议的简述 Modbus协议作为应用层协议,基于主从设备模型,主设备负责请求消息&…...
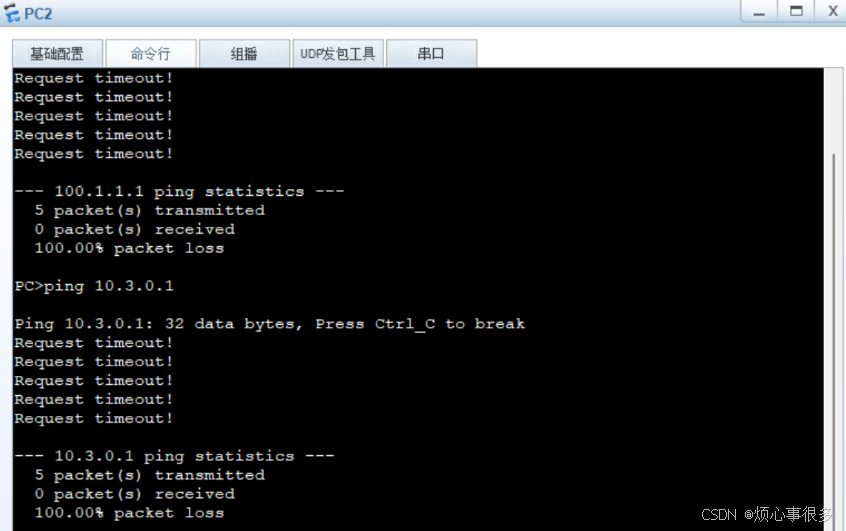
虚拟系统配置实验报告
一、实验拓扑图 二、实验配置 要求一: 虚拟系统: 设置管理: 进行信息配置 R1配置 虚拟系统配置 a: b: c: 测试 a–>b: 检测...

Agentic系统:负载均衡与Redis缓存优化
摘要 本文在前文Agentic系统的基础上,新增负载均衡(动态调整线程数以避免API限流)和缓存机制(使用Redis存储搜索结果,减少API调用)。通过这些优化,系统在高并发场景下更加稳定高效。代码完整可…...

28-文本左右对齐
给定一个单词数组 words 和一个长度 maxWidth ,重新排版单词,使其成为每行恰好有 maxWidth 个字符,且左右两端对齐的文本。 你应该使用 “贪心算法” 来放置给定的单词;也就是说,尽可能多地往每行中放置单词。必要时可…...

建筑兔零基础自学python记录39|实战词云可视化项目——章节分布10(上)
这次我们来制作《红楼梦》各章节的分布情况: 源代码: import pandas as pd import numpy as np import matplotlib.pyplot as pltdf_hlm pd.read_csv("hlm.txt", names["hlm_texts"]).dropna()df_hlm df_hlm[~df_hlm.hlm_texts.s…...

Impacket工具中的横向渗透利器及其使用场景对比详解
在渗透测试中,横向移动(Lateral Movement)是指攻击者在获得一个系统的控制权限后,通过网络进一步渗透到其他系统的过程。Impacket 是一款强大的渗透测试工具集,提供了多种实现横向渗透的脚本,常见的工具包括…...

基于java,SpringBoot和Vue的医院药房药品管理系统设计
摘要 随着医疗行业信息化的快速发展,高效、精准的医院药房药品管理对于提升医疗服务质量和医院运营效率至关重要。本文基于 Java 语言,采用 SpringBoot 框架和 Vue 框架进行医院药房药品管理系统的设计与研究。该系统以 SpringBoot 作为后端开发框架&am…...

MQ保证消息的顺序性
在消息队列(MQ)中保证消息的顺序性是一个常见的需求,尤其是在需要严格按顺序处理业务逻辑的场景(例如:订单创建 → 支付 → 发货)。 一、消息顺序性被破坏的原因 生产者异步/并行发送:消息可能…...

cmake、CMakeLists.txt、make、ninja
文章目录 一、概念0.cmake官网1.什么是cmake2.为什么使用cmake3.CMakeLists.txt 二、CMakeLists.txt语法:如何编写CMakeLists.txt,语法详解(0)语法基本原则(1)project关键字(2)set关键字(3)message关键字(4)add_executable关键字(5)add_subdirectory关键…...

数据结构与算法 计算机组成 八股
文章目录 数据结构与算法数组与链表的区别堆的操作红黑树定义及其原理 计算机组成int和uint的表示原码反码补码移码的定义?为什么用补码? 数据结构与算法 数组与链表的区别 堆的操作 红黑树定义及其原理 计算机组成 int和uint的表示 原码反码补码移…...

RoboBrain:从抽象到具体的机器人操作统一大脑模型
25年2月来自北大、北京智源、中科院自动化所等的论文“RoboBrain: A Unified Brain Model for Robotic Manipulation from Abstract to Concrete”。 目前的多模态大语言模型(MLLM) 缺少三项必备的机器人大脑能力:规划能力,将复杂…...

算法 之 前缀和 与 滑动窗口 与 背包问题 的差异(子数组之和为k问题)
文章目录 使用前缀和哈希表560.和为K的子数组525.连续数组2588.统计美丽子数组数目 子数组的定义是原来的数组当中连续的非空的序列,而我们的背包问题的选与不选的情况,对应的是这个非连续的情况,那么这种情况就要注意当然啦,对于线性的时间内…...

微电网协调控制器ACCU-100 分布式光伏 光储充一本化
安科瑞 华楠 18706163979 应用范围: 分布式光伏、微型风力发电、工商业储能、光储充一体化电站、微电网等领域。 主要功能: 数据采集:支持串口、以太网等多通道实时运行,满足各类风电与光伏逆变器、储能等 设备接入ÿ…...

IDEA入门及常用快捷键
IDEA是java常用的IDE。当run一个.java文件时,其实是经历了先编译为.class,再运行的过程。 在project文件夹中,out文件夹存储编译的.class文件,src文件夹存储.java代码文件。 设置自动导包 快捷键: 格式化快捷键&…...

electron打包结构了解
Electron 应用打包后的文件结构和内容取决于你使用的打包工具(如 electron-builder、electron-packager 等)以及目标操作系统(Windows、macOS、Linux)。以下是典型 Electron 应用打包后的文件结构和关键组成部分: 1. 基…...

03.06 QT
一、使用QSlider设计一个进度条,并让其通过线程自己动起来 程序代码: <1> Widget.h: #ifndef WIDGET_H #define WIDGET_H#include <QWidget> #include <QThread> #include "mythread.h"QT_BEGIN_NAMESPACE namespace Ui {…...

Ansys Mechanical|远程点Behavior设置:刚性与柔性选择背后的工程考量
1. 远程点Behavior设置的核心逻辑 在Ansys Mechanical中,远程点(Remote Point)的Behavior设置看似只是一个简单的下拉选项,实则直接影响整个仿真结果的准确性。我见过太多工程师在这里踩坑,包括我自己早期也犯过错误。…...

立创泰山派RK3566开发环境实战:从交叉编译到高效文件传输
1. 立创泰山派RK3566开发环境搭建全攻略 第一次拿到立创泰山派RK3566开发板时,我和大多数嵌入式开发者一样兴奋又忐忑。这款基于Rockchip RK3566处理器的开发板性能强劲,但配套资料相对分散,特别是对于从其他平台(比如我熟悉的IMX…...
)
告别物理开关!用CD4013和MOS管自制零功耗一键开关机模块(3-18V宽压适用)
零功耗一键开关机模块:基于CD4013的硬件设计实战 在电池供电的嵌入式系统和DIY电子项目中,电源管理往往成为决定设备续航能力的关键因素。传统机械开关虽然简单可靠,但无法实现软关机功能;而普通电子开关又常因静态功耗过高导致电…...

基于开源项目构建实时语音AI对话系统:从ASR、LLM到TTS的完整技术栈解析
1. 项目概述与核心价值 最近在折腾一个挺有意思的东西,一个叫 bigsk1/voice-chat-ai 的开源项目。简单来说,它让你能和一个AI进行实时的语音对话,就像打电话一样。你对着麦克风说话,AI不仅能听懂,还能思考࿰…...

独立开发者如何利用 Taotoken 统一管理多个 AI 项目支出
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何利用 Taotoken 统一管理多个 AI 项目支出 对于同时维护多个小型 AI 应用或实验项目的独立开发者而言,成…...

深度学习嵌入操作优化与DAE架构实践
1. 嵌入操作与DAE架构的核心挑战在深度学习推荐系统和图神经网络中,嵌入操作(Embedding Operations)占据了超过60%的计算时间。这类操作本质上是一种特殊的稀疏-密集张量乘法(SpMM),其计算模式具有两个显著…...

CST Studio Suite 视窗操控进阶:从快捷键到高效建模的视觉掌控
1. 3D视窗操控的核心逻辑与效率提升 刚开始用CST Studio Suite建模时,我总被复杂的模型结构搞得晕头转向。直到发现视窗操控的底层逻辑其实遵循空间认知三要素:视角定位、焦点聚焦、结构解析。举个例子,在调试一个微带天线时,通过…...

第20章:Skill ≠ Prompt——从提示词到可复用技能的范式升级
第20章:Skill ≠ Prompt——从提示词到可复用技能的范式升级 20.1 问题定义:为什么"保存Prompt"不够 很多团队的做法是:把常用的Prompt保存在文档或笔记中,需要时复制粘贴。这看起来合理,但存在三个根本问题: 不可版本化:Prompt是散落的文本片段,没有版本号…...

3分钟掌握APK Installer:在Windows电脑上轻松安装安卓应用的终极方案
3分钟掌握APK Installer:在Windows电脑上轻松安装安卓应用的终极方案 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾想在Windows电脑上直接运行An…...

量子强化学习与混合架构在工业控制与缺陷检测中的实践
1. 量子强化学习在工业控制中的实践突破量子强化学习(QRL)作为传统强化学习的量子化延伸,正在工业自动化领域展现出独特优势。以移动通信基站天线选择为例,传统方法需要精确追踪手机运动轨迹,而QRL通过训练智能体基于历…...