HDFS的设计架构
HDFS 是 Hadoop 生态系统中的分布式文件系统,设计用于存储和处理超大规模数据集。它具有高可靠性、高扩展性和高吞吐量的特点,适合运行在廉价硬件上。
1. HDFS 的设计思想
HDFS 的设计目标是解决大规模数据存储和处理的问题,其核心设计思想包括:
(1)分布式存储
- 数据被分割成多个块(Block),并分布存储在集群中的多个节点上。
- 每个数据块默认大小为 128MB 或 256MB,可以根据需求配置。
(2)高容错性
- 通过数据冗余(默认 3 副本)确保数据可靠性。
- 如果某个节点故障,系统可以从其他节点的副本中恢复数据。
(3)高吞吐量
- 适合批量数据处理,而不是低延迟的随机读写。
- 通过流式数据访问模式,优化了大文件的读写性能。
(4)廉价硬件
- 设计运行在普通商用硬件上,通过软件层面的容错机制弥补硬件可靠性不足的问题。
(5)数据本地性
- 将计算任务调度到存储数据的节点上,减少数据传输开销,提高处理效率。
(6)一次写入,多次读取
- 适合写入一次、读取多次的场景,不支持文件的随机修改。
2. HDFS 的框架结构
HDFS 采用主从架构(Master-Slave),主要由以下组件组成:
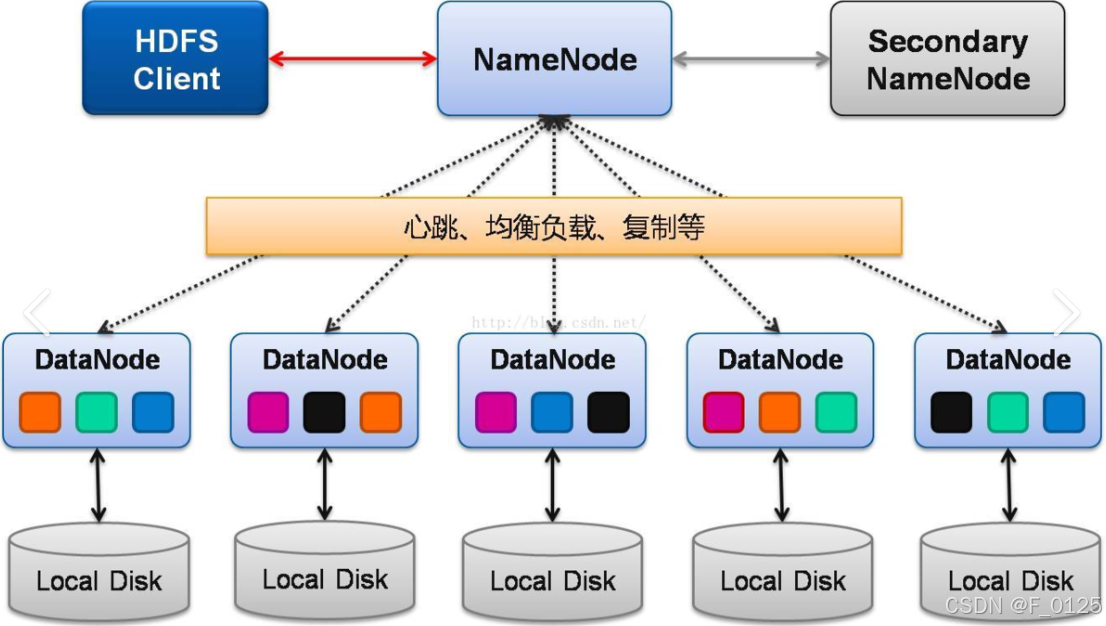
(1)NameNode(主节点)
NameNode 是 HDFS 的核心组件,负责管理文件系统的元数据。
主要职责:维护文件系统的命名空间(如目录树、文件信息)。管理数据块(Block)与 DataNode 的映射关系。处理客户端的元数据请求(如打开、关闭、重命名文件)。NameNode 是单点故障(SPOF),因此通常需要配置高可用性(HA)方案,如使用双 NameNode(Active-Standby)。
(2)DataNode(从节点)
DataNode 是工作节点,负责存储实际的数据块。
主要职责:存储和检索数据块。定期向 NameNode 发送心跳信号和数据块报告。执行数据块的创建、删除和复制操作。DataNode 通常是集群中的多个节点,共同提供分布式存储能力。
(3)Secondary NameNode(辅助节点)
Secondary NameNode 不是 NameNode 的备份,而是辅助 NameNode 完成元数据的管理。
主要职责:定期合并 NameNode 的编辑日志(EditLog)和文件系统镜像(FsImage),减少 NameNode 的启动时间。不提供故障恢复功能。
(4)客户端(Client)
客户端是与 HDFS 交互的应用程序或用户工具。
主要职责:与 NameNode 通信,获取元数据(如文件位置)。与 DataNode 通信,读写数据块。
3. HDFS 的工作流程
(1)文件写入流程
1. 客户端向 NameNode 请求写入文件。
2. NameNode 检查文件是否存在,并确定数据块存储的 DataNode 列表。
3. 客户端将数据块写入第一个 DataNode,第一个 DataNode 将数据复制到第二个 DataNode,依此类推。
4. 写入完成后,客户端通知 NameNode,NameNode 更新元数据。
(2)文件读取流程
1. 客户端向 NameNode 请求读取文件。
2. NameNode 返回文件的数据块位置(DataNode 列表)。
3. 客户端直接从 DataNode 读取数据块。
(3)数据块复制流程
当某个 DataNode 故障或数据块损坏时,NameNode 会检测到并触发数据块的复制操作,确保数据冗余。
4. HDFS 的核心特性
(1)高可靠性
- 通过数据冗余(默认 3 副本)确保数据不会丢失。
- NameNode 的高可用性(HA)方案进一步提升了系统的可靠性。
(2)高扩展性
- 可以通过增加 DataNode 节点来扩展存储容量和处理能力。
- 支持 PB 级甚至 EB 级数据存储。
(3)高吞吐量
- 适合批量数据处理,能够高效地读写大文件。
- 通过数据本地性优化计算任务的执行效率。
(4)廉价硬件支持
- 设计运行在普通商用硬件上,降低了成本。
(5)一次写入,多次读取
- 适合数据仓库、日志存储等场景,但不适合频繁修改的文件。
HDFS 是一个分布式文件系统,设计用于存储和处理超大规模数据集。其核心设计思想包括分布式存储、高容错性、高吞吐量和廉价硬件支持。HDFS 的框架结构由 NameNode、DataNode 和 Secondary NameNode 组成,采用主从架构。HDFS 适合大数据批处理场景,但不适合低延迟的随机读写和频繁修改的文件。
相关文章:
HDFS的设计架构
HDFS 是 Hadoop 生态系统中的分布式文件系统,设计用于存储和处理超大规模数据集。它具有高可靠性、高扩展性和高吞吐量的特点,适合运行在廉价硬件上。 1. HDFS 的设计思想 HDFS 的设计目标是解决大规模数据存储和处理的问题,其核心设计思想…...

为wordpress自定义一个留言表单并可以在后台进行管理的实现方法
要为WordPress添加留言表单功能并实现后台管理,你可以按照以下步骤操作: 1. 创建留言表单 首先,你需要创建一个留言表单。可以使用插件(如Contact Form 7)或手动编写代码。 使用Contact Form 7插件 安装并激活Contact Form 7插件。 创建…...
tauri-plugin-shell插件将_blank的a标签用浏览器打开了,,,解决办法
不要使用这个插件,这个插件默认会将网页中a标签为_blank的使用默认浏览器打开,但是这种做法在我的程序里不是很友好,我需要自定义这种行为,当我点击我自己的链接的时候,使用默认浏览器打开,当点击别的链接的…...

【大模型基础_毛玉仁】1.1 基于统计方法的语言模型
【大模型基础_毛玉仁】1.1 基于统计方法的语言模型 1.语言模型基础1.1 基于统计方法的语言模型1.1.1 n-grams 语言模型1.1.2 n-grams 的统计学原理 1.语言模型基础 语言是概率的。语言模型(LanguageModels, LMs)旨在准确预测语言符号的概率。 将按照语…...

使用 Docker 部署 RabbitMQ 并实现数据持久化
非常好!以下是一份完整的 Docker 部署 RabbitMQ 的博客文档,包含从安装到问题排查的详细步骤。你可以直接将其发布到博客中。 使用 Docker 部署 RabbitMQ 并实现数据持久化 RabbitMQ 是一个开源的消息队列系统,广泛应用于分布式系统中。使用…...

Pandas的数据转换函数
Pandas的数据转换函数:map, apply, applymap 参数描述map只用于Series,实现每个值->值的映射apply用于Series实现每个值的处理,用于DataFrame实现某个轴的Series的处理applymap只能用于DataFrame, 用于处理该DataFrame的每个元素 1. map用于Series值…...
影刀 RPA 实战开发阶段总结
目录 1. 影刀 RPA 官方教程的重要性 1.1系统全面的知识体系 1.2 权威准确的技术指导 1.3 贴合实际的案例教学 1.4高效的学习方法引导 2. 官方视频教程与实战 2.1 官方视频教程:奠定坚实基础 2.2 实战:拓展应用视野 3. 往期实战博文导航 3.1 初级…...

Linux系统上安装kafka
目录 1. 安装Java环境 2. 下载和解压Kafka 3. 配置Kafka 4. 启动ZooKeeper和Kafka 5. 测试Kafka 6. 停止服务 7.常见问题 1. 安装Java环境 Kafka依赖Java运行环境(JDK 8或更高版本): # 安装OpenJDK(推荐) yum…...
DeepSeek如何快速开发PDF转Word软件
一、引言 如今,在线工具的普及让PDF转Word成为了一个常见需求,常见的PDF转Word工具有收费的WPS,免费的有PDFGear,以及在线工具SmallPDF、iLovePDF、24PDF等。然而,大多数免费在线转换工具存在严重隐私风险——文件需上…...

虚拟机 | Ubuntu图形化系统: open-vm-tools安装失败以及实现文件拖放
系列文章目录 虚拟机 | Ubuntu 安装流程以及界面太小问题解决 文章目录 系列文章目录虚拟机 | Ubuntu 安装流程以及界面太小问题解决 前言一、VMware Tools 和 open-vm-tools 是什么1、VMware Tools2、open-vm-tools 二、推荐使用open-vm-tools(简单)1、…...
-主从同步由于主键问题引发的故障)
Mysql-经典故障案例(1)-主从同步由于主键问题引发的故障
故障报错 Could not execute Write_rows event on table test.users; Duplicate entry 3 for key PRIMARY, Error_code: 1062; handler error HA_ERR_FOUND_DUPP_KEY; the events master log mysql-bin.000031, end_log_pos 3297这是由于从库存在与主库相同主键值,…...

Linux下学【MySQL】中如何实现:多表查询(配sql+实操图+案例巩固 通俗易懂版~)
每日激励:“不设限和自我肯定的心态:I can do all things。 — Stephen Curry” 绪论: 本章是MySQL篇中,非常实用性的篇章,相信在实际工作中对于表的查询,很多时候会涉及多表的查询,在多表查询…...
ubuntu局域网部署stable-diffusion-webui记录
需要局域网访问,如下设置: 过程记录查看源码: 查看源码,原来修改参数:--server-name 故启动: ./webui.sh --server-name0.0.0.0 安装下载记录: 快速下载可设置: export HF_ENDPOI…...

最基于底层的运算符——位运算符
位运算符是直接对二进制位(bit)进行操作的运算符,它们在底层开发、算法优化和特定场景(如位掩码、数据压缩)中非常高效。以下是常见位运算符的详解、使用技巧及注意事项: 一、六大核心位运算符 1. 按位与&…...

代码随想录算法训练营第三十二天 | 509. 斐波那契数 70. 爬楼梯 746. 使用最小花费爬楼梯
509. 斐波那契数 力扣题目链接(opens new window) 斐波那契数,通常用 F(n) 表示,形成的序列称为 斐波那契数列 。该数列由 0 和 1 开始,后面的每一项数字都是前面两项数字的和。也就是: F(0) 0,F(1) 1 F(n) F(n -…...
)
3-9 WPS JS宏单元格复制、重定位应用(拆分单表到多表)
************************************************************************************************************** 点击进入 -我要自学网-国内领先的专业视频教程学习网站 *******************************************************************************************…...

C++ 中前置 `++` 与后置 `++` 运算符重载
C 中前置 与后置 运算符重载的设计原理与使用规范 1. 为什么后置 返回对象而不是引用? 原因: 后置 需要返回自增前的旧值,但旧值在运算后已被修改。为了保存旧值,必须在函数内部创建一个临时对象(拷贝原对象的状态…...
)
Scala:case class(通俗易懂版)
1. case class 是什么? 想象你要做一个表格,比如学生信息表,每一行需要填:姓名、年龄、成绩。 在代码里,这种“表格的一行”就是一个数据对象,case class 就是帮你快速创建这种“表格行”的工具。 普通方…...

Vue、React、原生小程序的写法对比差异
以下是从 变量、方法、路由、状态管理、父子传值 等多个维度对 Vue、React、原生小程序 的对比表格: 技术对比表格 功能/技术Vue (Options/Composition API)React (Hooks)原生微信小程序变量定义data() { return { count: 0 } }(Options API)const count = ref(0)(Composition…...

【AIGC系列】6:HunyuanVideo视频生成模型部署和代码分析
AIGC系列博文: 【AIGC系列】1:自编码器(AutoEncoder, AE) 【AIGC系列】2:DALLE 2模型介绍(内含扩散模型介绍) 【AIGC系列】3:Stable Diffusion模型原理介绍 【AIGC系列】4࿱…...

如何用MGit在Android手机上轻松管理Git仓库:完整指南
如何用MGit在Android手机上轻松管理Git仓库:完整指南 【免费下载链接】MGit A Git client for Android. 项目地址: https://gitcode.com/gh_mirrors/mg/MGit 你是否曾经希望在Android手机上也能像在电脑上一样轻松管理Git仓库?MGit就是为你量身打…...

LinuxCNC RS274NGC解释器工作流详解:从G代码文本到电机动作的完整旅程
LinuxCNC RS274NGC解释器工作流详解:从G代码文本到电机动作的完整旅程 在工业自动化领域,G代码作为数控机床的通用编程语言,其解释执行过程往往被视为黑箱操作。本文将深入剖析LinuxCNC中RS274NGC解释器的完整工作流,揭示一段G代码…...

ISO 11452-4 BCI测试补偿系数:从核心原理到工程校准的完整指南
1. 项目概述:从一次“诡异”的测试失败说起几年前,我接手了一个车载ECU的电磁兼容性摸底测试项目。按照标准流程,我们需要在电波暗室里,对样件进行ISO 11452-4标准规定的BCI(大电流注入)测试。测试计划、设…...

终极指南:3步彻底解决腾讯游戏ACE-Guard卡顿,免费提升游戏性能
终极指南:3步彻底解决腾讯游戏ACE-Guard卡顿,免费提升游戏性能 【免费下载链接】sguard_limit 限制ACE-Guard Client EXE占用系统资源,支持各种腾讯游戏 项目地址: https://gitcode.com/gh_mirrors/sg/sguard_limit 你是否在玩《英雄联…...

终极KMS激活指南:如何免费激活Windows和Office的完整教程
终极KMS激活指南:如何免费激活Windows和Office的完整教程 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows和Office的激活问题烦恼吗?KMS_VL_ALL_AIO是一款开…...

零成本替代 Zendesk,个人 / 小团队专属开源客服系统
零成本替代 Zendesk,个人 / 小团队专属开源客服系统 前言 在线客服这个赛道,Intercom、Zendesk 这些产品做得确实成熟,但价格对于小团队来说始终是个门槛。随便看一家,每月订阅费基本从几百到几千不等,企业版功能更是直…...

美国不断自我革新的历史,为这个国家面对充满巨大机遇却又充满不确定性的未来提供了引人深思的经验教训
https://www.mckinsey.com/mgi/our-research/At-250-sustaining-Americas-competitive-edge 美国不断自我革新的历史,为这个国家面对充满巨大机遇却又充满不确定性的未来提供了引人深思的经验教训 这一切始于一场惊天动地的反抗行动。 1776年7月,来自13…...

Solidworks PDM二次开发实战:文件夹权限与数据卡配置详解
1. Solidworks PDM二次开发入门指南 如果你正在使用Solidworks PDM管理产品数据,可能会遇到需要批量创建文件夹并设置权限的场景。比如新项目启动时,需要为不同部门创建标准化的文件夹结构,同时设置工程师只读、管理员完全控制的权限规则。手…...

ADXL335模拟传感器读数不稳?手把手教你用Arduino进行软件滤波与校准
ADXL335模拟传感器读数不稳?手把手教你用Arduino进行软件滤波与校准 当你把ADXL335加速度计接入Arduino,兴奋地跑起第一个测试程序时,那些跳动的数字可能很快会浇灭你的热情。原始读数像得了疟疾般颤抖,静止时本该稳定的1g重力加速…...

开源自动驾驶系统终极指南:从入门到精通
开源自动驾驶系统终极指南:从入门到精通 【免费下载链接】openpilot openpilot is an operating system for robotics. Currently, it upgrades the driver assistance system on 300 supported cars. 项目地址: https://gitcode.com/GitHub_Trending/op/openpilo…...