通用信息抽取大模型PP-UIE开源发布,强化零样本学习与长文本抽取能力,全面适配多场景任务
背景与简介
信息抽取(information extraction)是指,从非结构化或半结构化数据(如自然语言文本)中自动识别、提取并组织出结构化信息。通常包含多个子任务,例如:命名实体识别(NER)、关系抽取(RE)、事件抽取(EE)。由于任务目标的多样性(如实体、关系、事件和情感等)、文本结构的异构性(如片段、三元组、记录等)以及特定应用需求的多变性,传统的信息抽取方法往往针对特定任务或领域进行优化,难以在跨任务或跨领域的情境中迁移和泛化。
随着大语言模型的发展,通用信息抽取大模型逐渐成为主流。此类模型将不同任务和领域统一为端到端的框架,并能够在未见过的数据或领域上展现出较好的性能。然而,当前主流的通用信息抽取大模型通常规模较大,这些模型在本地部署时,面临推理速度较慢、计算资源受限等问题,难以满足实际应用的需求。为应对上述挑战,飞桨团队基于开源模型和高质量数据集,开发了通用信息抽取大模型PP-UIE。PP-UIE借鉴了百度UIE的建模思想,旨在支持中英文信息抽取任务。模型涵盖命名实体识别(NER)、关系抽取(RE)和事件抽取(EE)等任务,提供0.5B、1.5B、7B和14B四个版本,以适应不同场景中的需求。同时模型在零样本预测能力上,在多个数据集(包含 Boson、CLUENER、CCIR2021等常见数据集)相比传统UIE-Base模型的抽取效果大幅度得到提升,具备更好的实用价值。
产品亮点
1. 效果更佳的零样本信息抽取能力PP-UIE具备强零样本学习能力,能快速适应新任务和数据,相比UIE-Base模型在 通用领域、新闻领域等多个数据上效果抽取效果平均提升66% ;相比开源信息抽取大模型YaYi-UIE在F1指标上提高18.3个百分点,相比DeepSeek-R1-Distill-Qwen-14B 在F1指标上提高25.8个百分点。同时PP-UIE具备更好小样本能力,只需要1-10条样本就可以快速提升模型在特定业务上的效果,相比传统的信息抽取模型,大幅降低数据标注成本。
2. 强大的长文档信息抽取能力PP-UIE具备处理长文本能力,能跨越多个段落或句子识别关键信息,形成完整理解。该能力对于大型文档等复杂文本尤为重要,传统的UIE-Base模型只能支持 256 个Token长度的文本抽取,而PP-UIE可以支持8192个Token长度文档的信息抽取,支持的文本长度提升3 2倍。
3. 完备的大模型信息抽取定制能力本模型基于PaddleNLP 3.0,提供模块化、可定制化的训练和推理流程,支持灵活调整以满足不同需求。训练效率较LLama-Factory提升1.8倍 。 同时,在推理阶段,PaddleNLP 3.0还为用户提供了便捷的调用方式,助力用户快速完成模型的部署与实际应用。
欢迎开发者前往开源项目主页直接体验:
https://github.com/PaddlePaddle/PaddleNLP

亮点一: 效果更佳的零样本信息抽取能力
信息抽取任务中,要获取高质量的标注数据不仅成本高昂,而且耗时长。为了应对这一挑战,PaddleNLP开发的通用信息抽取大模型特别强化了零样本(Zero-shot)学习的能力,旨在通过少量甚至没有标注数据的支持,实现快速冷启动和高效迁移学习。
下表为模型在各数据集的零样本(zero-shot)和小样本(few-shot)能力。

从表格中可以看出,随着模型规模的增大,无论是零样本(zero-shot)能力还是小样本(few-shot)能力都有显著提升。具体来说:
- 在零样本(zero-shot)任务中,模型的表现随着规模的增加逐步提高。例如,PP-UIE-0.5B模型在CMeEE数据集中F1分数为0.479,而PP-UIE-14B模型的F1分数则达到了0.556,显示出明显的提升。
抽取内容:"嫌疑人,案发城市,资损金额"输出:"贺某,孙某,杞县阳堌镇北村,杞县,3700多元,1300元"
- 在小样本(few-shot)任务中,随着模型参数的增大,F1值也呈现出相应的增长。PP-UIE-14B在CMeEE数据集中少样本条件下的F1达到了0.588,优于其他规模较小的模型。PP-UIE通过在输入数据前增加对应输出格式和输出内容样例,提升模型的输出准确性和格式规范性。
抽取内容:"身体部位"zero-shot输出:"肾上腺皮质,肾上腺皮质,肾上腺皮质"few-shot输出:"肾上腺皮质"
综上所述,模型的规模与其在零样本和小样本任务中的表现成正比,增大模型规模能够显著提高其性能。

PP-UIE系列 zero-shot和Few-Shot样例
同时我们和开源的信息抽取大模型YaYi-13B、DeepSeek-R1-Distill-Qwen-14B进行了效果对比测试,下表为不同数据集领域中zero-shot的效果对比

综合来看,PP-UIE-0.5B在零样本任务中的整体表现明显超过YaYi-UIE-13B 和DeepSeek-R1-Distill-Qwen-14B,说明PP-UIE-0.5B具有更强的零样本学习能力,且PP-UIE-0.5B可以大幅降低推理部署成本。
亮点二: 长跨度的信息抽取能力
当前,用户面临着前所未有的海量文本数据,其中不乏长篇文章、报告和文档。因此,用户对于长文信息抽取的必要性愈发凸显。在此背景下,PP-UIE系列模型凭借其长文能力,为用户提供长文信息抽取的高效工具。PP-UIE能跨越多个段落或句子识别关键信息,形成对文本内容的完整理解。传统的UIE-Base模型在处理文本时存在局限性,只能支持256个Token长度的文本抽取,这大大限制了其在处理长文本时的应用。而 PP-UIE 则突破了这一限制,可以支持8192个Token长度的文档级别的信息抽取,使得长文档信息抽取能力得到大幅提升。这一改进使得 PP-UIE 在处理复杂文本时更加高效、准确,具有广泛的应用前景。
抽取内容:"嫌疑人,案发城市,资损金额"输出:"贺某,孙某,杞县阳堌镇北村,杞县,3700多元,1300元"
抽取内容:"时间,公司,财务数据,业务"输出:"2023年10月18日,摩根士丹利,2023年第三季度,72亿美元,18%,165亿美元,145亿美元,14%,88亿美元,12%,全球财富管理市场,高净值客户市场,北美和欧洲市场,高净值客户,并购和IPO业务,美国联邦储备系统(美联储),债券交易业务,债券交易收入,同比下降了8%,人工智能(AI),数字化金融,科技创新基金,绿色债券,环境、社会和治理(ESG)投资,绿色金融产品,清洁能源项目,可再生能源,碳排放减排技术,高盛集团,瑞士信贷,花旗银行,全球信用卡和零售银行业务,亚洲市场,中国,印度,新兴市场,全球高净值客户,大数据,人工智能"
亮点三: 完备的大模型信息抽取定制能力
对于基础的信息抽取任务,PP-UIE系列模型可以直接上手,高效完成信息抽取。然而,面对更为复杂或特定领域的任务场景,我们强烈推荐利用轻定制功能(即仅需标注少量数据即可对模型进行微调)以进一步提高模型效果。PaddleNLP 为通用信息抽取大模型提供了完整的、可定制化的训练和推理全流程,使用户能够根据具体应用需求灵活调整模型,实现更高效、更精准的信息抽取任务。相较于LLama-Factory,PaddleNLP在训练效率上实现了1.8倍的提升(特别针对7B模型),进一步展示了其在大模型精调上的卓越性能。

1. 定制自己的训练数据集
步骤1:准备语料并标注
首先,需要准备相应的预标注文本,预标注文本中一行代表一条数据,并保存为txt以下格式
2022年语言与智能技术竞赛由中国中文信息学会和中国计算机学会联合主办,百度公司、中国中文信息学会评测工作委员会和中国计算机学会自然语言处理专委会承办,已连续举办4届,成为全球最热门的中文NLP赛事之一。
我们推荐使用数据标注平台doccano进行数据标注,标注方法的详细介绍请参考doccano数据标注指南。标注完成后,在doccano平台上导出文件。
· doccano数据标注指南:
https://github.com/PaddlePaddle/PaddleNLP/blob/develop/llm/application/doccano.md
步骤2:数据集格式转换
在doccano平台上导出的json格式的文件,通常不能直接用来模型微调。PaddleNLP也打通了从标注到训练的通道,即doccano导出数据后可通过doccano.py脚本轻松将数据转换为输入模型时需要的形式,实现无缝衔接。
--doccano_file your/data/path \--save_dir ./data \--splits 0.8 0.2 0 \--schema_lang ch
执行以上脚本进行数据转换,执行后会在./data目录下生成训练/验证/测试集文件。
2. 模型微调
推荐使用大模型精调对模型进行微调。只需输入模型、数据集等就可以高效快速地进行微调和模型压缩等任务,可以一键启动多卡训练、混合精度训练、梯度累积、断点重启、日志显示等功能,并且针对训练过程的通用训练配置做了封装,比如:优化器、学习率调度等。
使用下面的命令,使用paddlenlp/PP-UIE-1.5B作为预训练模型进行模型微调,将微调后的模型保存至指定路径中。
如果在GPU环境中使用,可以指定gpus参数进行多卡训练:
# 返回llm目录python -u -m paddle.distributed.launch --gpus "0,1" run_finetune.py ./config/qwen/sft_argument.json
sft_argument.json的参考配置如下:
"model_name_or_path": "paddlenlp/PP-UIE-1.5B","dataset_name_or_path": "./application/information_extraction/data","output_dir": "./checkpoints/ie_ckpts","per_device_train_batch_size": 1,"gradient_accumulation_steps": 1,"per_device_eval_batch_size": 1,"eval_accumulation_steps":8,"num_train_epochs": 3,"learning_rate": 3e-05,"warmup_steps": 30,"logging_steps": 1,"evaluation_strategy": "epoch","save_strategy": "epoch","src_length": 1024,"max_length": 2048,"fp16": true,"fp16_opt_level": "O2","do_train": true,"do_eval": true,"disable_tqdm": true,"load_best_model_at_end": true,"eval_with_do_generation": false,"metric_for_best_model": "accuracy","recompute": false,"save_total_limit": 1,"tensor_parallel_degree": 1,"pipeline_parallel_degree": 1,"sharding": "stage2","zero_padding": false,"unified_checkpoint": true,"use_flash_attention": false}
3. 定制模型一键推理
PaddleNLP提供了两种可选的方式对模型进行推理:
(1)使用 PaddleNLP的高性能 predictor进行快速推理
- 内置全环节融合算子策略
- 支持 Weight Only INT8及 INT4推理,支持权重、激活、Cache KV 进行 INT8、FP8量化的推理
- 支持动态图推理和静态图推理两种方式
python predict/predictor.py \--model_name_or_path paddlenlp/PP-UIE-1.5B \--dtype float16 \--data_file ./application/information_extraction/data/test.json \--output_file ./output.json \--src_length 512 \--max_length 20 \--batch_size 4 \
更多关于predictor.py的配置参数说明,请参考大模型推理教程:
https://paddlenlp.readthedocs.io/zh/latest/llm/docs/predict/inference.html**
(2)使用taskflow进行快速推理
paddlenlp.Taskflow支持装载定制模型,通过task_path指定模型权重文件的路径,路径下需要包含训练好的模型权重文件
>>> from paddlenlp import Taskflow>>> schema = {"竞赛名称": ["主办方", "承办方", "已举办次数"]}# 设定抽取目标和定制化模型权重路径>>> my_ie = Taskflow("information_extraction", schema=schema, model='paddlenlp/PP-UIE-1.5B',precision = "bfloat16", task_path='./checkpoints/ie_ckpts')>>> pprint(my_ie("2022年语言与智能技术竞赛由中国中文信息学会和中国计算机学会联合主办,百度公司、中国中文信息学会评测工作委员会和中国计算机学会自然语言处理专委会承办,已连续举办4届,成为全球最热门的中文NLP赛事之一。"))[{'竞赛名称': [{'relations': {'主办方': [{'text': '中国中文信息学会,中国计算机学会'}],'已举办次数': [{'text': '4'}],'承办方': [{'text': '百度公司,中国中文信息学会评测工作委员会,中国计算机学会自然语言处理专委会'}]},'text': '2022年语言与智能技术竞赛'}]}]
· 飞桨星河社区教程链接
https://aistudio.baidu.com/projectdetail/8796056
· PaddleNLP 链接
https://github.com/PaddlePaddle/PaddleNLP
为了帮助您迅速且深入地了解PP-UIE,并熟练掌握实际操作技巧,百度高级研发工程师为您详细解读从通用信息抽取大模型 PP-UIE在多场景任务下的信息抽取能力,课程视频点击链接入群即可观看;另外,我们还为您开展《PP-UIE信息抽取》实战营,助力实操PP-UIE进行信息抽取,报名即可免费获得项目消耗算力(限时一周),名额有限,先到先得:https://www.wjx.top/vm/mBKC6pb.aspx?udsid=611062

相关文章:
通用信息抽取大模型PP-UIE开源发布,强化零样本学习与长文本抽取能力,全面适配多场景任务
背景与简介 信息抽取(information extraction)是指,从非结构化或半结构化数据(如自然语言文本)中自动识别、提取并组织出结构化信息。通常包含多个子任务,例如:命名实体识别(NER&am…...
)
基于uniapp的蓝牙打印功能(佳博打印机已测试)
相关步骤 1.蓝牙打印与低功耗打印的区别2.蓝牙打印流程2.1 搜索蓝牙2.2 连接蓝牙 3.连接蓝牙设备4.获取服务5.写入命令源码gbk.jsglobalindex.ts 1.蓝牙打印与低功耗打印的区别 低功耗蓝牙是一种无线、低功耗个人局域网,运行在 2.4 GHz ISM 频段 1、低功耗蓝牙能够…...

【Azure 架构师学习笔记】- Azure Databricks (15) --Delta Lake 和Data Lake
本文属于【Azure 架构师学习笔记】系列。 本文属于【Azure Databricks】系列。 接上文 【Azure 架构师学习笔记】- Azure Databricks (14) – 搭建Medallion Architecture part 2 前言 ADB 除了UC 这个概念之外,前面【Azure 架构师学习笔记】- Azure Databricks (1…...

WPF高级 | WPF 应用程序部署与发布:确保顺利交付到用户手中
WPF高级 | WPF 应用程序部署与发布:确保顺利交付到用户手中 一、前言二、部署与发布基础概念2.1 部署的定义与目的2.2 发布的方式与渠道2.3 部署与发布的关键要素 三、WPF 应用程序打包3.1 使用 Visual Studio 自带的打包工具3.2 使用第三方打包工具 四、发布到不同…...

在 IntelliJ IDEA(2024) 中创建 JAR 包步骤
下是在 IntelliJ IDEA 中创建 JAR 包的详细的步骤: 1. 选择File -> Project Structure->Artifacts, (1)点击➕新建,如下图所示: (2)选择JAR->Empty (3)输入jar包名称,确定输出路径 (4&#…...

【C++】5.4.3 范围for语句
范围for语句基本形式: for(声明变量:序列容器) {循环执行语句; } 其中,“序列容器”是指花括号括起来的初始值列表、数组、vector或者string等类型的对象,主要特点是拥有能返回迭代器的 begin() 和 end() 成员; “声明变量”是一个类似声明…...

达梦数据库备份
达梦数据库联机在线备份操作指南 一、基础条件与准备 开启归档模式: 联机备份必须处于归档模式下,否则无法执行。需通过disql工具执行以下操作: alter database mount; alter database ARCHIVELOG; 例子: [dmdbaserver ~]$ cd /op…...

Linux系统基于ARM平台的LVGL移植
软硬件介绍:Ubuntu 20.04 ARM 和(Cortex-A53架构)开发板 基本原理 LVGL图形库是支持使用Linux系统的Framebuffer帧缓冲设备实现的,如果想要实现在ARM开发板上运行LVGL图形库,那么就需要把LVGL图形库提供的关于帧缓冲设…...

C++ 二叉搜索树代码
C 二叉搜索树代码 #include <iostream> using namespace std;template<typename T> struct TreeNode{T val;TreeNode *left;TreeNode *right;TreeNode():val(0), left(NULL), right(NULL){}TreeNode(T x):val(x), left(NULL), right(NULL){} };template<typena…...
DeepSeek+知识库+鸿蒙,助力鸿蒙高效开发
不知道你们发现没有,就是鸿蒙开发官网,文档也太多太多了,对于新手来说确实头疼,开发者大多是极客,程序的目的是让世界更高效!看文档,挺头疼的,毕竟都是理科生。 遇到问题不要慌&…...
蓝桥杯牛客1-10重点(自用)
1 import mathdef lcm(a,b):return a * b // math.gcd(a, b) # math.gcd(a, b)最小公倍数 a,b map(int,input().split()) # a int(input()) # 只读取一个整数 # print(a) print(lcm(a,b)) 2 import os import sysdef fly(lists,n):count 0flag Falsefor i in range(1,n…...

Kafka - 高吞吐量的七项核心设计解析
文章目录 概述一、顺序磁盘I/O (分区顺序追加)1.1 存储架构设计1.2 性能对比实验1.3 存储优化策略 二、零拷贝技术:颠覆传统的数据传输革命2.1 传统模式痛点2.2 Kafka优化方案 三、页缓存机制:操作系统的隐藏加速器3.1 实现原理3.2 优势对比 四、日志索引…...
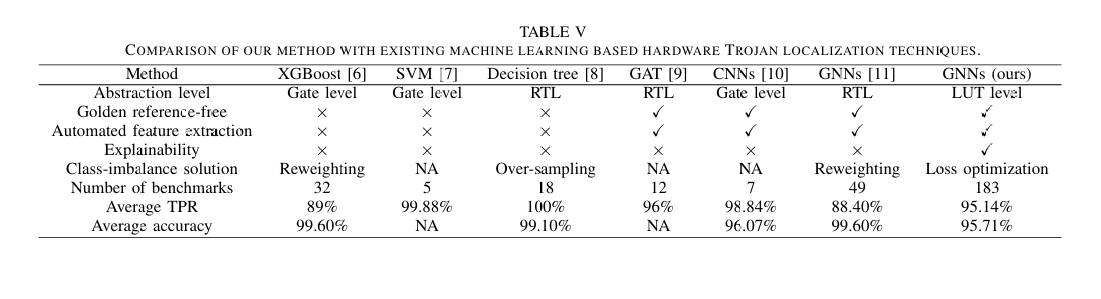
Towards Precise and Explainable Hardware Trojan Localization at LUT Level
文章 《Towards Precise and Explainable Hardware Trojan Localization at LUT Level》 TCAD’2025 《LUT层次的精细可解释木马定位》 期刊介绍 《IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems》(TCAD)是集成电路…...

Python实现鼠标点击获取窗口进程信息
最近遇到挺无解的一个问题:电脑上莫名其妙出现一个白色小方块,点击没有反应,关也关不掉,想知道它和哪个软件有关还是显卡出了问题,也找不到思路,就想着要不获取一下它的进程号看看。 于是写了一个Python脚本…...

Mac安装jdk教程
在Mac上安装JDK(Java Development Kit)的步骤如下: 一、下载JDK安装包 访问Oracle官网: 打开浏览器,访问Oracle JDK下载页面。 选择JDK版本: 根据你的开发需求选择合适的JDK版本。例如,JDK 11…...

【HeadFirst系列之HeadFirst设计模式】第14天之与设计模式相处:真实世界中的设计模式
与设计模式相处:真实世界中的设计模式 设计模式是软件开发中的经典解决方案,它们帮助我们解决常见的设计问题,并提高代码的可维护性和可扩展性。在《Head First设计模式》一书中,作者通过生动的案例和通俗的语言,深入…...

JDBC 完全指南:掌握 Java 数据库交互的核心技术
JDBC 完全指南:掌握 Java 数据库交互的核心技术 一、JDBC 是什么?为什么它如此重要? JDBC(Java Database Connectivity)是 Java 语言中用于连接和操作关系型数据库的标准 API。它允许开发者通过统一的接口访问不同的数…...

Vue父子组件传递笔记
Vue父子组件传递笔记 props 父组件向子组件进行传值 (1)在父组件APP.vue <template><div> <!-- 给子组件Child.vue传递以msg的信号,传递的信息内容为messages --><Child :msg"messages"></Child>…...

文件上传漏洞与phpcms漏洞安全分析
目录 1. 文件上传漏洞简介 2. 文件上传漏洞的危害 3. 文件上传漏洞的触发条件 1. 文件必须能被服务器解析执行 2. 上传目录必须支持代码执行 3. 需要能访问上传的文件 4. 例外情况:非脚本文件也可能被执行 4. 常见的攻击手法 4.1 直接上传恶意文件 4.2 文件…...

【deepseek】辅助思考生物学问题:ICImapping构建遗传图谱gap较大
基于ICImapping构建遗传图谱的常见问题与解答 问题一:染色体两端标记间遗传距离gap较大 答疑一 标记密度不足(如芯片设计时分布不均)重组概率低基因组结构变异软件算法限制 Deepseek的解释 #### 1. **染色体末端的重组率较低** - **现象*…...

Python try...except ImportError 语句详解
在Python编程中,ImportError 是与模块导入相关的核心异常。优雅地处理它,是编写健壮、可维护和跨平台代码的关键。try...except ImportError 结构正是实现这一目标的标准工具。本文将为你抽丝剥茧,从基础概念到高级实践,全面解析这…...

技术视角:Sketchfab数据提取工具深度解析3D模型下载机制
技术视角:Sketchfab数据提取工具深度解析3D模型下载机制 【免费下载链接】sketchfab sketchfab download userscipt for Tampermonkey by firefox only 项目地址: https://gitcode.com/gh_mirrors/sk/sketchfab 在WebGL技术日益成熟的今天,Sketch…...

从零构建可定制对话系统:模块化架构与RAG实战指南
1. 项目概述:从零构建一个可定制的对话系统最近在折腾一个挺有意思的东西,我把它叫做“定制化聊天系统”。起因很简单,市面上现成的聊天机器人,无论是开源的还是商业的,总感觉差了那么点意思。要么是功能太臃肿&#x…...

实战指南:用UABEA高效解析Unity资源结构的5个关键要点
实战指南:用UABEA高效解析Unity资源结构的5个关键要点 【免费下载链接】UABEA c# uabe for newer versions of unity 项目地址: https://gitcode.com/gh_mirrors/ua/UABEA 在Unity开发的世界里,资源管理往往是项目优化中最棘手的一环。你是否曾经…...

OpenClaw 小龙虾智能体联动 DeepSeek 大模型部署实操攻略
前置准备 获取小龙虾open claw一键安装包(www.totom.top)并安装电脑端已成功安装并正常启动OpenClaw,右上角 Gateway 状态显示在线设备网络通畅,可正常访问 DeepSeek 开放平台拥有可接收验证码的手机号 / 微信,用于平…...

紧急更新!Midjourney 6.2.1已悄然修复碳素印相的硫化银衰减模拟缺陷——但97%用户仍在用旧参数,立即校准你的工作流
更多请点击: https://intelliparadigm.com 第一章:碳素印相的视觉本质与Midjourney 6.2.1修复的底层动因 碳素印相的物质性光感逻辑 碳素印相并非数字渲染的模拟,而是一种基于明胶-碳黑颗粒物理沉积的连续调成像工艺。其高密度阴影区呈现哑…...

开源技能图谱工具SkillPort:Go语言构建的知识管理利器
1. 项目概述:一个技能图谱与知识管理的开源利器 最近在整理个人技术栈和团队知识库时,我一直在寻找一个能直观展示技能关联、又能深度管理学习路径的工具。市面上的笔记软件要么太“平”,只能线性记录;要么太“重”,像…...
TransPrompt:结构化提示词工程,提升LLM应用开发效率
1. 项目概述:当提示词工程遇上结构化工具最近在折腾大语言模型应用开发的朋友,估计都绕不开一个核心痛点:如何高效、稳定地管理那些越来越复杂、越来越长的提示词(Prompt)。直接写在代码里?改起来麻烦&…...

Arm Fast Models中VGIC架构与中断虚拟化解析
1. Arm Fast Models中的VGIC架构解析虚拟通用中断控制器(Virtual Generic Interrupt Controller, VGIC)是Armv7/v8架构虚拟化扩展的核心组件之一。在Fast Models仿真环境中,Iris组件通过精确建模实现了VGIC的完整功能,包括:物理中断与虚拟中断…...

开源可视化利器:用声明式数据驱动构建交互式技术解释图
1. 项目概述:一个将复杂概念可视化的开源利器最近在整理技术分享材料时,我一直在寻找一种能直观展示复杂系统架构或算法流程的工具。传统的流程图工具要么太笨重,要么定制化程度不够,直到我遇到了nicobailon/visual-explainer这个…...