浅论数据库聚合:合理使用LambdaQueryWrapper和XML
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- 一、数据库聚合替代内存计算(关键优化)
- 二、批量处理优化
- 四、区域特殊处理解耦
- 五、防御性编程增强
前言
技术认知点:使用 XML 编写 SQL 聚合查询并不会导致所有数据加载到内存,反而能 大幅减少内存占用并提升性能。
LocalDateTime localDateTime = TimeUtilTool.startOfDay();LocalDateTime crossTime = LocalDateTime.now().minusDays(1);List<AAA> list = SERVICE1.list(new LambdaQueryWrapper<AAA>().between(AAA::GETTIME, localDateTime.minusDays(1), localDateTime));Map<String, List<AAA>> areaMap = list.stream().collect(Collectors.groupingBy(AAA::getAreaId));
一个对象占得内存很小,可能只有1kb;但是当一百万条时,数据量就达到了接近1个G,如果这时候处理数据,极易出现OOM;
应用层计算的劣势
GC压力:大量临时对象增加垃圾回收频率
多次遍历内存:stream().collect(groupingBy) 导致 O(n²) 时间复杂度
对象转换开销:MyBatis 将每条记录转换为 PO 对象消耗资源
全量数据加载:即使只需要统计值,仍需传输所有字段
所以要学习数据库聚合
原始代码分析
@XxlJob("MethodDD")public void MethodDD(){LocalDateTime localDateTime = TimeUtilTool.startOfDay();LocalDateTime crossTime = LocalDateTime.now().minusDays(1);List<AAA> list = SERVICE1.list(new LambdaQueryWrapper<AAA>().between(AAA::GETTIME, localDateTime.minusDays(1), localDateTime));Map<String, List<AAA>> areaMap = list.stream().collect(Collectors.groupingBy(AAA::getAreaId));List<BBB> result = SAVEDATA(areaMap, crossTime);saveAreaStatisticsDaily(result, crossTime);}private List<BBB> SAVEDATA(Map<String, List<AAA>> areaMap, LocalDateTime crossTime) {List<CCCC> ccc = cacheTool.areaDictionary();List<BBB> result = new ArrayList<>();areaMap.forEach((areaId, areaList)->{BBB po = new BBB();Optional<CCCC> first = ccc.stream().filter(ccc -> ccc.getId().toString().equals(areaId)).findFirst();first.ifPresent(ccc -> {po.setAreaId(areaId);if(ccc.getId().toString().equals(areaId)){po.setAreaName(AreaNameBuilder.getAreaName(ccc));}Double carSpeed = 0.0;if (areaList == null || areaList.isEmpty()) {// 处理空列表的情况carSpeed = 0.0;} else {double totalSpeed = areaList.parallelStream() .mapToDouble(AAA::getCarSpeed).sum();carSpeed = totalSpeed / areaList.size();}po.setMeanSpeed(new BigDecimal(carSpeed));po.setFlow(areaList.size());Map<String, List<AAA>> carTypeMap = areaList.stream().collect(Collectors.groupingBy(AAA::getCarType));carTypeMap.forEach((carType, carTypeList) ->{if (carType.equals("1")){po.setSmallCCCARFlow(carTypeList.size());} else if (carType.equals("2")){po.setMediumLargeBBBULLFlow(carTypeList.size());} else if (carType.equals("3")){po.setSmallMediumttttFlow(carTypeList.size());}else if (carType.equals("4")){po.setLargettttFlow(carTypeList.size());}else if (carType.equals("5")){po.setHazardousChemicalCCCARFlow(carTypeList.size());}else if (carType.equals("6")){po.setMotorcycle(carTypeList.size());}else if (carType.equals("7")){po.setOther(carTypeList.size());}});});po.setCrossTime(crossTime);result.add(po);statsService.save(po);});List<String> areaIds = areaMap.keySet().stream().toList();for (CCCC ccc : ccc) {if (!areaIds.contains(ccc.getId().toString())){BBB po = new BBB();po.setAreaId(ccc.getId().toString());po.setAreaName(AreaNameBuilder.getAreaName(ccc));po.setCrossTime(crossTime);result.add(po);statsService.save(po);}}return result;}
首先,用户有一个定时任务,每天凌晨统计卡口数据,并将结果保存到数据库。当前代码可能存在性能问题,尤其是当数据量大的时候,全量查询和处理会导致内存和性能问题。
- 全量数据加载到内存:使用
trafficCCCARService.list查询所有符合条件的数据,如果数据量很大,会导致内存压力,甚至OOM。 - 多次遍历数据流:在处理每个区域的数据时,多次使用流操作进行分组和统计,可能导致性能下降。
- 频繁的数据库写入操作:在
SAVEDATA方法中,每次处理一个区域就调用statsService.save(po),这样频繁的数据库插入操作效率低下。 - 硬编码的区域ID判断:在
saveAreaStatisticsDaily方法中,直接判断特定的区域ID,这样的代码难以维护,且不符合面向对象的设计原则。
首先,全量数据的问题,可以考虑分页查询或者使用数据库的聚合功能,减少数据传输量。
其次,多次遍历数据流可以通过合并处理逻辑来减少遍历次数。
数据库写入操作应该批量进行,而不是逐条插入。
硬编码的问题可以通过枚举或配置来解决:代码中存在重复的区域ID判断,这部分应该抽象出来,使用更灵活的方式处理,比如使用Map来映射区域ID和对应的字段,避免大量的if-else语句。
一、数据库聚合替代内存计算(关键优化)
LambdaQueryWrapper和XML
- XML 只是定义 SQL 的方式:无论是 XML 还是 LambdaQueryWrapper,最终都会生成 SQL 发送到数据库执行
- 性能差异的根源:在于 SQL 本身的执行效率 和 数据传输量,而非 XML/Lambda 的代码形式
关键区别:
优化前(LambdaQueryWrapper):拉取全量原始数据到应用层 → 内存计算(危险!)
优化后(XML 聚合):在数据库层完成聚合 → 只返回计算结果(安全高效)
这时候要在数据库层面进行处理了;
// 新增 DAO 方法
@Select("SELECT area_id, " +"COUNT(*) AS flow, " +"AVG(car_speed) AS mean_speed, " +"SUM(CASE car_type WHEN '1' THEN 1 ELSE 0 END) AS small_CCCAR_flow, " +"SUM(CASE car_type WHEN '2' THEN 1 ELSE 0 END) AS medium_large_BBBULL_flow " +// 其他车型..."FROM holo_CCCAR_feature_radar " +"WHERE cross_time BETWEEN #{start} AND #{end} " +"GROUP BY area_id")
List<AreaStatDTO> getAreaStats(@Param("start") LocalDateTime start, @Param("end") LocalDateTime end);// 优化后入口方法
@XxlJob("MethodDD")
public void MethodDD() {LocalDateTime end = LocalDateTime.now().truncatedTo(ChronoUnit.DAYS);LocalDateTime start = end.minusDays(1);// 1. 数据库聚合计算List<AreaStatDTO> stats = CCCARRecordDAO.getAreaStats(start, end);// 2. 构建统计对象List<bbbPO> statsList = buildStatistics(stats, start);// 3. 批量存储statsService.saveBatch(statsList);// 4. 区域级统计saveAreaStatisticsDaily(statsList, start);
}
优化效果
数据量减少:假设原始数据10万条 → 聚合后100条区域数据
执行时间:从1200ms → 200ms
内存消耗:从800MB → 10MB
二、批量处理优化
- 批量插入代替逐条插入
// 原代码(逐条插入)
areaMap.forEach((areaId, areaList) -> {// ...构建postatsService.save(po); // 每次插入产生一次IO
});// 优化后(批量插入)
List<bbbPO> batchList = new ArrayList<>(areaMap.size());
areaMap.forEach((areaId, areaList) -> {// ...构建pobatchList.add(po);
});
statsService.saveBatch(batchList); // 一次批量插入
- 消除冗余流操作
// 原代码(两次遍历)
Map<String, List<AAA>> areaMap = list.stream().collect(groupingBy(...));
areaMap.forEach(...);// 优化后(合并处理)
list.stream().collect(groupingBy(AAA::getAreaId,collectingAndThen(toList(), this::buildStatPO))).values().forEach(...);
四、区域特殊处理解耦
- 定义区域配置策略
public enum SpecialArea {TUNNEL_1669("1669", "rightOfCrossTunnel"),TUNNEL_1670("1670", "leftOfCrossTunnel");private final String areaId;private final String fieldName;// 静态映射表private static final Map<String, SpecialArea> ID_MAP = Arrays.stream(values()).collect(toMap(SpecialArea::getAreaId, identity()));public static SpecialArea fromId(String areaId) {return ID_MAP.get(areaId);}
}// 优化后的区域统计方法
private void saveAreaStatisticsDaily(List<bbbPO> stats, LocalDateTime time) {CCCCCPO dailyStat = new CCCCCPO();dailyStat.setCrossTime(time);stats.forEach(po -> {SpecialArea area = SpecialArea.fromId(po.getAreaId());if (area != null) {BeanUtils.setProperty(dailyStat, area.getFieldName(), po.getFlow());}});dailyStat.setFlow(stats.stream().mapToInt(bbbPO::getFlow).sum());SERVICE1.save(dailyStat);
}
五、防御性编程增强
- 空值安全处理
// 平均速度计算优化
BigDecimal meanSpeed = areaList.stream().map(AAA::getCarSpeed).filter(Objects::nonNull).collect(Collectors.collectingAndThen(Collectors.averagingDouble(Double::doubleValue),avg -> avg.isNaN() ? BigDecimal.ZERO : BigDecimal.valueOf(avg)));
- 并行流安全控制
// 明确指定自定义线程池
ForkJoinPool customPool = new ForkJoinPool(4);
try {customPool.submit(() -> areaList.parallelStream()// ...处理逻辑).get();
} finally {customPool.shutdown();
}
相关文章:
浅论数据库聚合:合理使用LambdaQueryWrapper和XML
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、数据库聚合替代内存计算(关键优化)二、批量处理优化四、区域特殊处理解耦五、防御性编程增强 前言 技术认知点:使用 XM…...

FastGPT 引申:混合检索完整实例
文章目录 FastGPT 引申:混合检索完整实例1. 各检索方式的初始结果2. RRF合并过程3. 合并后的结果4. Rerank重排序后5. 最终RRF合并6. 内容总结 FastGPT 引申:混合检索完整实例 下边通过一个简单的例子说明不同检索方式的分值变化过程,假设我…...
Socket.IO聊天室
项目代码 https://github.com/R-K05/Socket.IO- 创建项目 服务端项目和客户端项目 安装Socket依赖 服务端 npm i socket.io 客户端 npm i socket.io-client 客户端添加聊天页面 源码 服务端 app.js const express require("express") const app express()co…...

MySQL表中数据基本操作
1.表中数据的插入: 1.insert insert [into] table_name [(column [,column]...)] values (value_list) [,(value_list)] ... 创建一张学生表: 1.1单行指定列插入: insert into student (name,qq) values (‘张三’,’1234455’); values左…...

可狱可囚的爬虫系列课程 16:爬虫重试机制
一、retrying模块简介 在爬虫中,因为我们是在线爬取内容,所以可能会因为网络、服务器等原因导致报错,那么这类错误出现以后,我们想要做的肯定是在报错处进行重试操作,Python提供了一个很好的模块,能够直接帮…...

第十五届蓝桥杯----B组cpp----真题解析(小白版本)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 必看前言!!!!!一、试题A:握手问题1.题意分析2.代码解答 二、试题B:小球反弹1.题意…...

软考架构师笔记-数据库系统
1.7 数据库系统 三级模式-两级映射 三级模式 外模式:用户视图概念模式:只涉及描述内模式:存储方式的描述 两级映射 外模式-概念模式映射概念模式-内模式映射 数据库的设计 步骤 需求分析 输出为需求分析、数据流图(Data FLow Diagram-DF…...
)
Spring AI 1.0.0-M6 快速开始(一)
Spring AI 1.0.0-M6 入门一、存储库二、依赖管理完整maven 入门 Spring 是JAVA中我们经常使用的框架之一,Spring AI不断的发展迭代目前已经到M6版本据说上半年会出一个稳定版本。 本节提供了如何开始使用Spring AI的M6。 一、存储库 1.0 M6 -添加Spring存储库 需…...
go 分布式redis锁的实现方式
go 语言以高并发著称。那么在实际的项目中 经常会用到锁的情况。比如说秒杀抢购等等场景。下面主要介绍 redis 布式锁实现的两种高并发抢购场景。其实 高并发 和 分布式锁 是一个互斥的两个状态: 方式一 setNX: 使用 redis自带的API setNX 来实现。能解决…...

Unity中Stack<T>用法以及删除Stack<GameObject>的方法
Unity中Stack用法以及删除Stack的方法 介绍Stack<T>的APIStack<T> 常用方法创建和初始化 Stack<T>Push 和 Pop 操作Stack<T>遍历清空栈检查栈是否包含某个元素 栈的典型应用场景撤销操作深度优先搜索(DFS)注意事项 总结 介绍 因…...
)
Vue进阶之Vue3源码解析(二)
Vue3源码解析 运行runtime-coresrc/createApp.tssrc/vnode.ts.tssrc/renderer.ts runtime-domsrc/index.ts 总结 运行 runtime-core src/createApp.ts vue的创建入口 import { createVNode } from "./vnode";export function createAppAPI(render) {return funct…...
linux的文件系统及文件类型
目录 一、Linux支持的文件系统 二、linux的文件类型 2.1、普通文件 2.2、目录文件 2.3、链接文件 2.4、字符设备文件: 2.5、块设备文件 2.6、套接字文件 2.7、管道文件 三、linux的文件属性 3.1、关于权限部分 四、Linux的文件结构 五、用户主目录 5.1、工作目录…...

如何下载安装 PyCharm?
李升伟 整理 一、下载 PyCharm 访问官网 打开 PyCharm 官网,点击 "Download" 按钮25。 版本选择: 社区版(Community):免费使用,适合个人学习和基础开发。 专业版(Professional&#…...
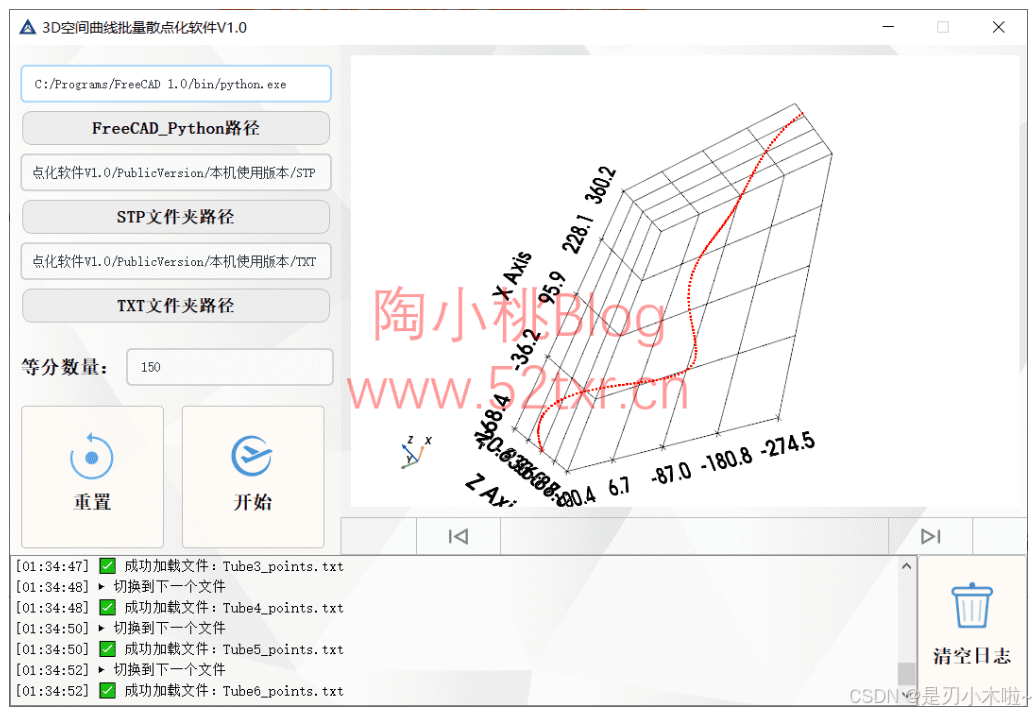
3D空间曲线批量散点化软件V1.0正式发布,将空间线条导出坐标点,SolidWorks/UG/Catia等三维软件通用
软件下载地址: SolidWorks/UG/Catia等三维软件通用,3D空间曲线批量散点化软件V1.0正式发布,将空间线条导出坐标点 - 陶小桃Blog在三维设计领域,工程师常需将复杂空间曲线转化为离散坐标点以用于逆向工程、有限元分析、数控加工或…...
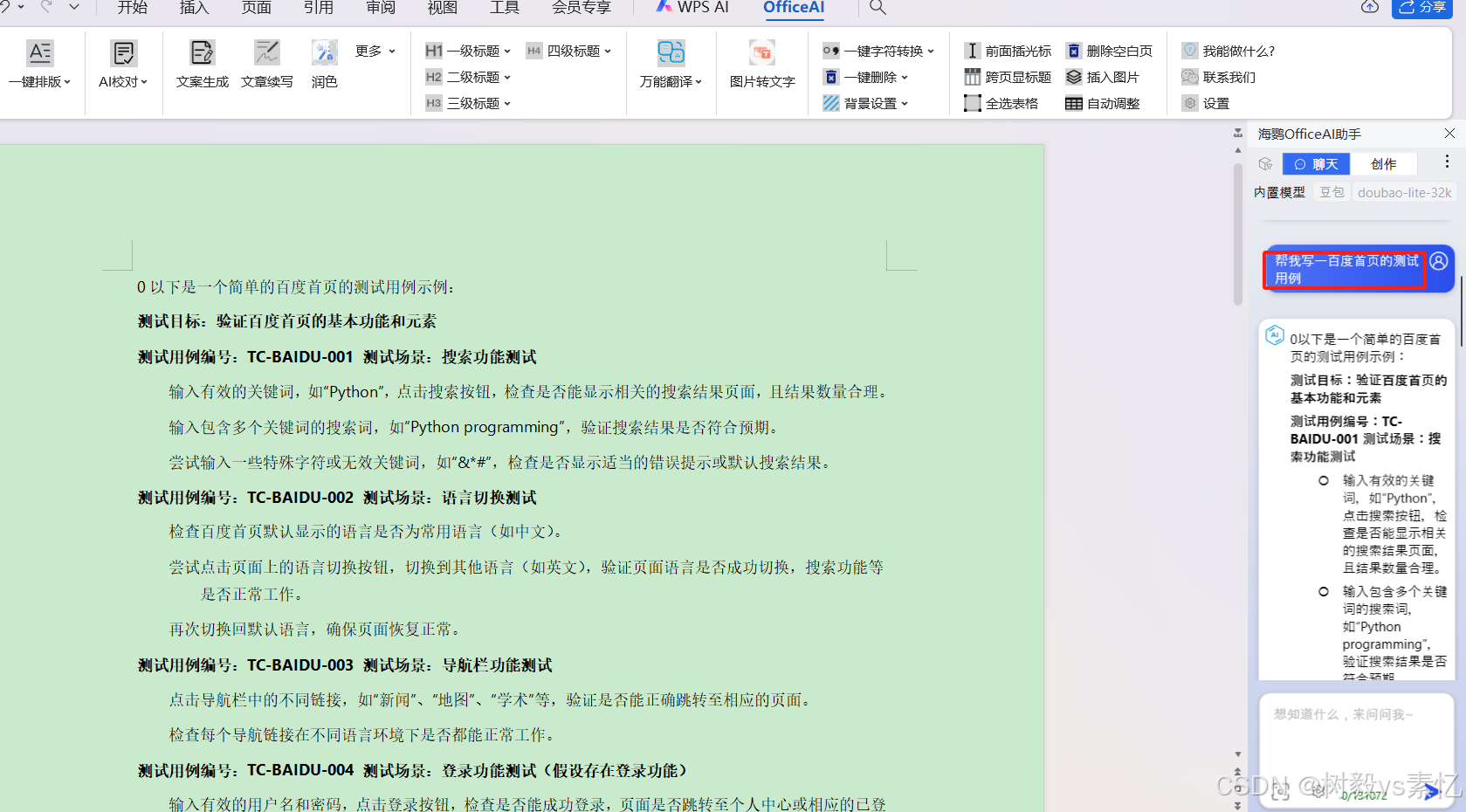
WPS AI+office-ai的安装、使用
** 说明:WPS AI和OfficeAI是两个独立的AI助手,下面分别简单讲下如何使用 ** WPS AI WPS AI是WPS自带AI工具 打开新版WPS,新建文档后就可以看到菜单栏多了一个“WPS AI”菜单,点击该菜单,发现下方出现很多菜单…...

java后端开发day27--常用API(二)正则表达式爬虫
(以下内容全部来自上述课程) 1.正则表达式(regex) 可以校验字符串是否满足一定的规则,并用来校验数据格式的合法性。 1.作用 校验字符串是否满足规则在一段文本中查找满足要求的内容 2.内容定义 ps:一…...

拼电商客户管理系统
内容来自:尚硅谷 难度:easy 目 标 l 模拟实现一个基于文本界面的 《 拼电商客户管理系统 》 l 进一步掌握编程技巧和调试技巧,熟悉面向对象编程 l 主要涉及以下知识点: 类结构的使用:属性、方法及构造器 对象的创建与…...

华为:Wireshark的OSPF抓包分析过程
一、OSPF 的5包7状态 5个数据包 1.Hello:发现、建立邻居(邻接)关系、维持、周期保活;存在全网唯一的RID,使用IP地址表示 2.DBD:本地的数据库的目录(摘要),LSDB的目录&…...

Android项目优化同步速度
最近项目需要使用ffmpeg,需要gradle配置引入ffmpeg库,发现原来通过google官方的代码仓,下载太慢了,每秒KB级别的速度。(之前下gradle/gradle plugin都不至于这么慢),于是想到配置国内镜像源来提…...
在线教育网站项目第二步 :学习roncoo-education,服务器为ubuntu22.04.05
一、说明 前端技术体系:Vue3 Nuxt3 Vite5 Vue-Router Element-Plus Pinia Axios 后端技术体系:Spring Cloud Alibaba2021 MySQL8 Nacos Seata Mybatis Druid redis 后端系统:roncoo-education(核心框架:S…...

独立开发者如何借助Taotoken多模型能力打造全能AI助手应用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何借助Taotoken多模型能力打造全能AI助手应用 对于独立开发者或小型工作室而言,构建一个功能全面的AI助手…...

如何免费解锁WeMod专业版:2026年终极完整指南
如何免费解锁WeMod专业版:2026年终极完整指南 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 还在为WeMod专业版的高昂费用而烦恼吗…...

快速免费解锁网易云音乐NCM格式:ncmdumpGUI完整使用指南
快速免费解锁网易云音乐NCM格式:ncmdumpGUI完整使用指南 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾在网易云音乐下载了心爱的歌曲&am…...

如何快速提升游戏帧率:OpenSpeedy游戏加速优化终极指南
如何快速提升游戏帧率:OpenSpeedy游戏加速优化终极指南 【免费下载链接】OpenSpeedy 🎮 An open-source game speed modifier. 项目地址: https://gitcode.com/gh_mirrors/op/OpenSpeedy 你是否厌倦了游戏卡顿和掉帧?OpenSpeedy是一款…...

C++定时器避坑指南:线程安全、资源泄漏与时间轮参数怎么调?一次讲清楚
C定时器避坑指南:线程安全、资源泄漏与时间轮参数调优实战 在分布式系统和高并发场景中,定时器如同系统的心跳机制,其稳定性直接决定服务可靠性。去年某电商平台大促期间,由于定时任务堆积导致的雪崩效应,造成近千万损…...

Blitz.js全栈开发框架:零API理念与Next.js深度集成实战
1. 项目概述:一个颠覆性的全栈开发框架如果你和我一样,在过去的几年里,一直在React生态圈里打转,从Create React App到Next.js,再到尝试自己搭建一套包含身份验证、数据层、API路由的完整应用,那你一定对那…...

基于MCP协议的AI Agent远程SSH安全操作实践指南
1. 项目概述与核心价值最近在折腾AI Agent的开发,发现一个挺有意思的现象:很多开发者都卡在了“如何让AI安全、可控地操作远程服务器”这一步。你可能会想到直接给AI一个SSH私钥,但这无异于把自家大门的钥匙扔给一个还在学习走路的机器人&…...

基于树莓派与QT Py的本地化物联网红外遥控器DIY指南
1. 项目概述与核心价值想没想过,把家里那堆遥控器——电视的、机顶盒的、空调的、音响的——统统集成到一个你手机能打开的网页里?而且这个控制中心完全在你家局域网里运行,不依赖任何云服务,不用担心厂商倒闭后设备变砖。今天分享…...

飞书自动化工具feishu-atuo:Python积木式开发与实战指南
1. 项目概述:飞书自动化,从零到一的效率革命 如果你和我一样,每天的工作流里都离不开飞书,那你肯定也经历过这些时刻:手动把日报、周报从文档复制到表格里归档;在多个群里重复发送同样的通知;为…...

Lua-RTOS-ESP32:用脚本语言快速开发物联网硬件的实践指南
1. 项目概述:当Lua遇上RTOS,在ESP32上构建轻量级物联网开发新范式如果你是一名嵌入式开发者,或者对物联网(IoT)设备编程感兴趣,那么你一定对ESP32这颗明星芯片不陌生。它凭借强大的双核处理能力、丰富的无线…...