[Computer Vision]实验七:图像检索
目录
一、实验内容
二、实验过程
2.1 准备数据集
2.2 SIFT特征提取
2.3 学习“视觉词典”(vision vocabulary)
2.4 建立图像索引并保存到数据库中
2.5 用一幅图像查询
三、实验小结
一、实验内容
- 实现基于颜色直方图、bag of word等方法的以图搜图,打印图片特征向量、图片相似度等
- 打印视觉词典大小、可视化部分特征基元、可视化部分图片的频率直方图
二、实验过程
2.1 准备数据集
如图1所示,这里准备的文件夹中含有100张实验图片。
2.2 SIFT特征提取
2.2.1 实验代码
import os
import cv2
import numpy as np
from PCV.tools.imtools import get_imlist
#获取图像列表
imlist = get_imlist(r'D:\Computer vision\20241217dataset')
nbr_images = len(imlist)
#生成特征文件路径
featlist = [os.path.splitext(imlist[i])[0] + '.sift' for i in range(nbr_images)]
#创建sift对象
sift = cv2.SIFT_create()
#提取sift特征并保存
for i in range(nbr_images):try:img = cv2.imread(imlist[i], cv2.IMREAD_GRAYSCALE)if img is None:raise ValueError(f"Image {imlist[i]} could not be read")keypoints, descriptors = sift.detectAndCompute(img, None)locs = np.array([[kp.pt[0], kp.pt[1], kp.size, kp.angle] for kp in keypoints])np.savetxt(featlist[i], np.hstack((locs, descriptors)))print(f"Processed {imlist[i]} to {featlist[i]}")except Exception as e:print(f"Failed to process {imlist[i]}: {e}")
#可视化sift特征
def visualize_sift_features(image_path, feature_path):img = cv2.imread(image_path, cv2.IMREAD_GRAYSCALE)if img is None:raise ValueError(f"Image {image_path} could not be read")features = np.loadtxt(feature_path)locs = features[:, :4]descriptors = features[:, 4:]img_with_keypoints = cv2.drawKeypoints(img, [cv2.KeyPoint(x=loc[0], y=loc[1], _size=loc[2], _angle=loc[3]) for loc in locs], outImage=np.array([]))plt.figure(figsize=(10, 10))plt.imshow(img_with_keypoints, cmap='gray')plt.title('SIFT Features Visualization')plt.axis('off')plt.show()visualize_sift_features(imlist[0], featlist[0])2.2.2 结果展示
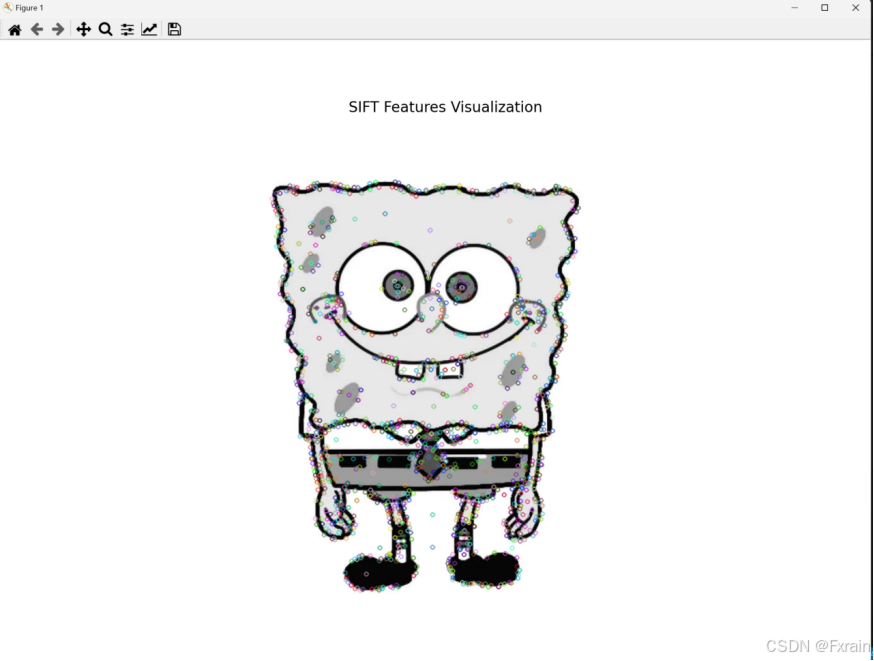
如图2所示,对文件夹中的所有图片使用sift特征描述子,图3展示了对第一个图像的SIFT特征的可视化。
2.3 学习“视觉词典”(vision vocabulary)
2.3.1 实验代码
(1)vocabulary.py文件
from numpy import *
from scipy.cluster.vq import *
from PCV.localdescriptors import sift
#构建视觉词汇表
class Vocabulary(object):#初始化方法def __init__(self,name):self.name = nameself.voc = []self.idf = []self.trainingdata = []self.nbr_words = 0#训练过程def train(self,featurefiles,k=100,subsampling=10):nbr_images = len(featurefiles)descr = []descr.append(sift.read_features_from_file(featurefiles[0])[1])descriptors = descr[0] for i in arange(1,nbr_images):descr.append(sift.read_features_from_file(featurefiles[i])[1])descriptors = vstack((descriptors,descr[i]))#使用K-means聚类生成视觉单词self.voc,distortion = kmeans(descriptors[::subsampling,:],k,1)self.nbr_words = self.voc.shape[0]#生成视觉单词的直方图imwords = zeros((nbr_images,self.nbr_words))for i in range( nbr_images ):imwords[i] = self.project(descr[i])nbr_occurences = sum( (imwords > 0)*1 ,axis=0)#计算每个视觉单词的逆文档频率self.idf = log( (1.0*nbr_images) / (1.0*nbr_occurences+1) )self.trainingdata = featurefiles#投影方法def project(self,descriptors):imhist = zeros((self.nbr_words))words,distance = vq(descriptors,self.voc)for w in words:imhist[w] += 1return imhistdef get_words(self,descriptors):return vq(descriptors,self.voc)[0](2)visual vocabulary.py文件
import pickle
from PCV.imagesearch import vocabulary
from PCV.tools.imtools import get_imlistimlist = get_imlist(r'D:\Computer vision\20241217dataset')
nbr_images = len(imlist)featlist = [imlist[i][:-3] + 'sift' for i in range(nbr_images)]
voc = vocabulary.Vocabulary('bof_test')
voc.train(featlist, 50, 10)with open(r'D:\Computer vision\20241217dataset\vocabulary50.pkl', 'wb') as f:pickle.dump(voc, f)
print('vocabulary is:', voc.name, voc.nbr_words)2.3.2 结果展示
如图4所示,打印视觉词典的名称和长度

2.4 建立图像索引并保存到数据库中
2.4.1 实验代码
(1)imagesearch.py文件
from numpy import *
import pickle
import sqlite3 as sqlite
from functools import cmp_to_keyclass Indexer(object):def __init__(self,db,voc):self.con = sqlite.connect(db)self.voc = vocdef __del__(self):self.con.close()def db_commit(self):self.con.commit()def get_id(self,imname):cur = self.con.execute("select rowid from imlist where filename='%s'" % imname)res=cur.fetchone()if res==None:cur = self.con.execute("insert into imlist(filename) values ('%s')" % imname)return cur.lastrowidelse:return res[0] def is_indexed(self,imname):im = self.con.execute("select rowid from imlist where filename='%s'" % imname).fetchone()return im != Nonedef add_to_index(self,imname,descr):if self.is_indexed(imname): returnprint ('indexing', imname)imid = self.get_id(imname)imwords = self.voc.project(descr)nbr_words = imwords.shape[0]for i in range(nbr_words):word = imwords[i]self.con.execute("insert into imwords(imid,wordid,vocname) values (?,?,?)", (imid,word,self.voc.name))self.con.execute("insert into imhistograms(imid,histogram,vocname) values (?,?,?)", (imid,pickle.dumps(imwords),self.voc.name))def create_tables(self): self.con.execute('create table imlist(filename)')self.con.execute('create table imwords(imid,wordid,vocname)')self.con.execute('create table imhistograms(imid,histogram,vocname)') self.con.execute('create index im_idx on imlist(filename)')self.con.execute('create index wordid_idx on imwords(wordid)')self.con.execute('create index imid_idx on imwords(imid)')self.con.execute('create index imidhist_idx on imhistograms(imid)')self.db_commit()def cmp_for_py3(a, b):return (a > b) - (a < b)class Searcher(object):def __init__(self,db,voc):self.con = sqlite.connect(db)self.voc = vocdef __del__(self):self.con.close()def get_imhistogram(self, imname):cursor = self.con.execute("select rowid from imlist where filename='%s'" % imname)row = cursor.fetchone()if row is None:raise ValueError(f"No entry found in imlist for filename: {imname}")im_id = row[0]cursor = self.con.execute("select histogram from imhistograms where rowid=%d" % im_id)s = cursor.fetchone()if s is None:raise ValueError(f"No histogram found for rowid: {im_id}")return pickle.loads(s[0])def candidates_from_word(self,imword):im_ids = self.con.execute("select distinct imid from imwords where wordid=%d" % imword).fetchall()return [i[0] for i in im_ids]def candidates_from_histogram(self,imwords):words = imwords.nonzero()[0]candidates = []for word in words:c = self.candidates_from_word(word)candidates+=ctmp = [(w,candidates.count(w)) for w in set(candidates)]tmp.sort(key=cmp_to_key(lambda x,y:cmp_for_py3(x[1],y[1])))tmp.reverse()return [w[0] for w in tmp] def query(self, imname):try:h = self.get_imhistogram(imname)except ValueError as e:print(e)return []candidates = self.candidates_from_histogram(h)matchscores = []for imid in candidates:cand_name = self.con.execute("select filename from imlist where rowid=%d" % imid).fetchone()cand_h = self.get_imhistogram(cand_name)cand_dist = sqrt(sum(self.voc.idf * (h - cand_h) ** 2))matchscores.append((cand_dist, imid))matchscores.sort()return matchscoresdef get_filename(self,imid):s = self.con.execute("select filename from imlist where rowid='%d'" % imid).fetchone()return s[0]def tf_idf_dist(voc,v1,v2):v1 /= sum(v1)v2 /= sum(v2)return sqrt( sum( voc.idf*(v1-v2)**2 ) )def compute_ukbench_score(src,imlist):nbr_images = len(imlist)pos = zeros((nbr_images,4))for i in range(nbr_images):pos[i] = [w[1]-1 for w in src.query(imlist[i])[:4]]score = array([ (pos[i]//4)==(i//4) for i in range(nbr_images)])*1.0return sum(score) / (nbr_images)from PIL import Image
from pylab import *def plot_results(src,res):figure()nbr_results = len(res)for i in range(nbr_results):imname = src.get_filename(res[i])subplot(1,nbr_results,i+1)imshow(array(Image.open(imname)))axis('off')show()(2)quantizeSet.py文件
import pickle
from PCV.imagesearch import imagesearch
from PCV.localdescriptors import sift
import sqlite3
from PCV.tools.imtools import get_imlist
import cv2
import matplotlib.pyplot as pltimlist = get_imlist(r'D:\Computer vision\20241217dataset')
nbr_images = len(imlist)featlist = [imlist[i][:-3] + 'sift' for i in range(nbr_images)]with open(r'D:\Computer vision\20241217dataset\vocabulary50.pkl', 'rb') as f:voc = pickle.load(f)
indx = imagesearch.Indexer('D:\\Computer vision\\20241217CODES\\testImaAdd.db', voc)
indx.create_tables()
for i in range(nbr_images)[:100]:locs, descr = sift.read_features_from_file(featlist[i])indx.add_to_index(imlist[i], descr)
indx.db_commit()
con = sqlite3.connect('D:\\Computer vision\\20241217CODES\\testImaAdd.db')
print(con.execute('select count (filename) from imlist').fetchone())
print(con.execute('select * from imlist').fetchone())
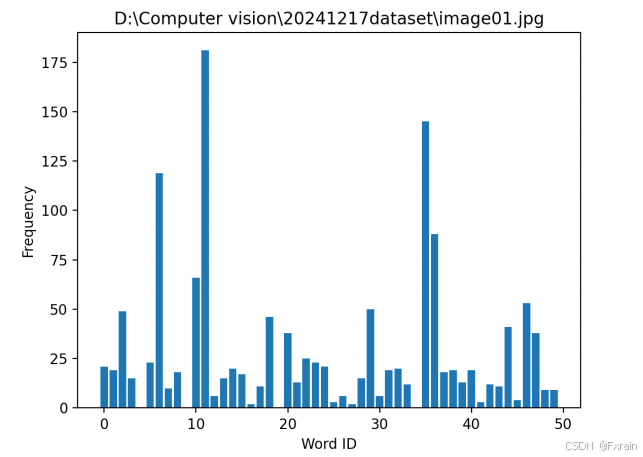
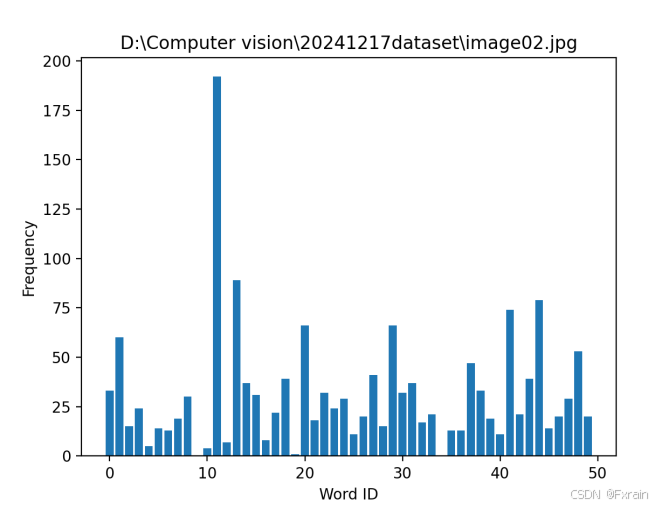
searcher = imagesearch.Searcher('D:\\Computer vision\\20241217CODES\\testImaAdd.db', voc)image_files = imlist[:5]for image_file in image_files:histogram = searcher.get_imhistogram(image_file)plt.figure()plt.title(image_file)plt.bar(range(len(histogram)), histogram)plt.xlabel('Word ID')plt.ylabel('Frequency')plt.show()2.4.2 结果展示
如图5所示,对数据集中的所有图像进行量化,为所有图像创建索引,再遍历所有的图像,将它们的特征投影到词汇上,最终提交到数据库保存下来(如图6)。图7、图8展示了部分图像的频率直方图。

2.5 用一幅图像查询
2.5.1 实验代码
import pickle
from PCV.imagesearch import imagesearch
from PCV.geometry import homography
from PCV.tools.imtools import get_imlist
import numpy as np
import cv2
import warnings
warnings.filterwarnings("ignore")imlist = get_imlist(r'D:\Computer vision\20241217dataset')
nbr_images = len(imlist)
featlist = [imlist[i][:-3] + 'sift' for i in range(nbr_images)]with open(r'D:\Computer vision\20241217dataset\vocabulary50.pkl', 'rb') as f:voc = pickle.load(f, encoding='iso-8859-1')src = imagesearch.Searcher(r'D:\Computer vision\20241217CODES\testImaAdd.db', voc)q_ind = 3
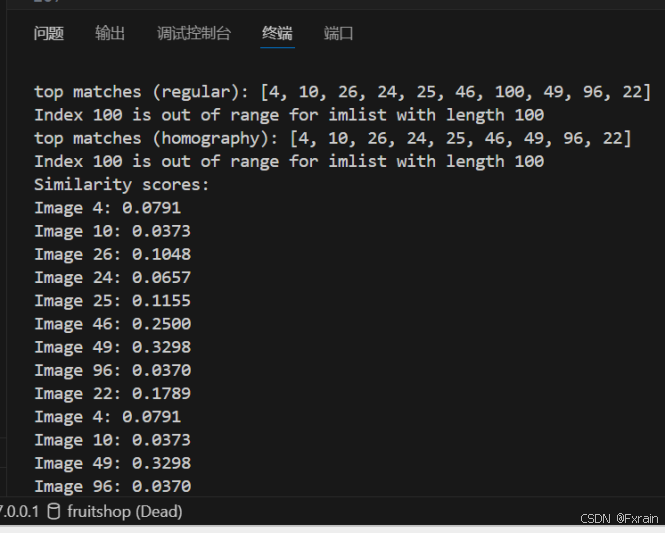
nbr_results = 10res_reg = [w[1] for w in src.query(imlist[q_ind])[:nbr_results]]
print('top matches (regular):', res_reg)img = cv2.imread(imlist[q_ind])
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
sift = cv2.SIFT_create()
kp, q_descr = sift.detectAndCompute(gray, None)
q_locs = np.array([[kp[i].pt[0], kp[i].pt[1]] for i in range(len(kp))])
fp = homography.make_homog(q_locs[:, :2].T)model = homography.RansacModel()
rank = {}bf = cv2.BFMatcher()
for ndx in res_reg[1:]:if ndx >= len(imlist):print(f"Index {ndx} is out of range for imlist with length {len(imlist)}")continueimg = cv2.imread(imlist[ndx])gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)kp, descr = sift.detectAndCompute(gray, None)locs = np.array([[kp[i].pt[0], kp[i].pt[1]] for i in range(len(kp))])matches = bf.knnMatch(q_descr, descr, k=2)good_matches = []for m, n in matches:if m.distance < 0.75 * n.distance:good_matches.append(m)ind = [m.queryIdx for m in good_matches]ind2 = [m.trainIdx for m in good_matches]tp = homography.make_homog(locs[:, :2].T)try:H, inliers = homography.H_from_ransac(fp[:, ind], tp[:, ind2], model, match_theshold=4)except:inliers = []# store inlier countrank[ndx] = len(inliers)sorted_rank = sorted(rank.items(), key=lambda t: t[1], reverse=True)
res_geom = [res_reg[0]] + [s[0] for s in sorted_rank]
print('top matches (homography):', res_geom)def calculate_similarity(query_index, result_indices, imlist):similarities = []for res_index in result_indices:if res_index >= len(imlist):print(f"Index {res_index} is out of range for imlist with length {len(imlist)}")continueimg1 = cv2.imread(imlist[query_index])img2 = cv2.imread(imlist[res_index])gray1 = cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY)gray2 = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)sift = cv2.SIFT_create()kp1, des1 = sift.detectAndCompute(gray1, None)kp2, des2 = sift.detectAndCompute(gray2, None)bf = cv2.BFMatcher()matches = bf.knnMatch(des1, des2, k=2)good_matches = []for m, n in matches:if m.distance < 0.75 * n.distance:good_matches.append(m)similarity = len(good_matches) / min(len(kp1), len(kp2))similarities.append((res_index, similarity))return similaritiesquery_index = q_ind
result_indices = res_reg + res_geom
similarities = calculate_similarity(query_index, result_indices, imlist)print("Similarity scores:")
for index, score in similarities:print(f"Image {index}: {score:.4f}")imagesearch.plot_results(src, res_reg)
imagesearch.plot_results(src, res_geom)
imagesearch.plot_results(src, res_reg[:6])
imagesearch.plot_results(src, res_geom[:6]) 2.5.2 结果展示
如图9所示,根据给定的查询图像索引q_ind,执行常规查询,返回前nbr_results个匹配结果,并打印这些结果以及可视化图片。

如图10所示,使用 RANSAC 模型拟合单应性找到与查询图像几何一致的候选图像。

如图11所示,计算查询图像与候选图像之间的相似度分数,并返回一个包含相似度分数的列表。
当生成不同维度视觉词典时,常规排序结果如图12所示。

三、实验小结
图像检索是一项重要的计算机视觉任务,它在根据用户的输入(如图像或关键词),从图像数据库中检索出最相关的图像。Bag of Feature 是一种图像特征提取方法,参考Bag of Words的思路,把每幅图像描述为一个局部区域/关键点(Patches/Key Points)特征的无序集合。同时从图像抽象出很多具有代表性的「关键词」,形成一个字典,再统计每张图片中出现的「关键词」数量,得到图片的特征向量。
相关文章:
[Computer Vision]实验七:图像检索
目录 一、实验内容 二、实验过程 2.1 准备数据集 2.2 SIFT特征提取 2.3 学习“视觉词典”(vision vocabulary) 2.4 建立图像索引并保存到数据库中 2.5 用一幅图像查询 三、实验小结 一、实验内容 实现基于颜色直方图、bag of word等方法的以图搜…...

C++之thread_local变量
C之thread_local变量_c threadlocal-CSDN博客 thread_local简介 thread_local 是 C11 为线程安全引进的变量声明符。表示对象的生命周期属于线程存储期。 线程局部存储(Thread Local Storage,TLS)是一种存储期(storage duration),对象的存储是在…...

【国产Linux | 银河麒麟】麒麟化龙——KylinOS下载到安装一条龙服务,起飞!
🗺️博客地图 📍一、下载地址 📍二、 系统安装 本文基于Windows操作系统vmware虚拟机安装 一、下载地址 官网:产品试用申请国产操作系统、麒麟操作系统——麒麟软件官方网站 下载自己需要的版本,完成后,…...
js中的execCommand怎么复制富文本内容解析)
(接“使用js去复制网页内容的方法”)js中的execCommand怎么复制富文本内容解析
document.execCommand(copy) 是传统的剪贴板操作方法,但它主要用于复制纯文本内容。如果你想复制富文本内容(包括 HTML 标签和样式),需要结合一些技巧来实现。以下是具体方法: 方法:通过创建隐藏的富文本元…...

npm ERR! code 128 npm ERR! An unknown git error occurred
【问题描述】 【问题解决】 管理员运行cmd(右键window --> 选择终端管理员) 执行命令 git config --global url.“https://”.insteadOf ssh://git cd 到项目目录 重新执行npm install 个人原因,这里执行npm install --registryhttps:…...

解决Leetcode第3470题全排列IV
3470.全排列IV 难度:困难 问题描述: 给你两个整数n和k,一个交替排列是前n个正整数的排列,且任意相邻两个元素不都为奇数或都为偶数。 返回第k个交替排列,并按字典序排序。如果有效的交替排列少于k个,则…...

MyBatis 配置文件核心
MyBatis 配置文件核心标签解析 以下是针对你的笔记中的三个核心标签的详细解析,帮助你全面理解它们的用途和配置逻辑。 1. properties 标签:动态加载外部配置 功能 将环境相关的配置(如数据库连接、密钥等)与 MyBatis 核心配置…...

bert模型笔记
1.各预训练模型说明 BERT模型在英文数据集上提供了两种大小的模型,Base和Large。Uncased是意味着输入的词都会转变成小写,cased是意味着输入的词会保存其大写(在命名实体识别等项目上需要)。Multilingual是支持多语言的࿰…...

微信小程序接入deepseek
先上效果 话不多说,直接上代码(本人用的hbuilder Xuniapp) <template><view class"container"><!-- 聊天内容区域 --><scroll-view class"chat-list" scroll-y :scroll-top"scrollTop":…...

推荐算法和推荐系统入门第一趴
以下是推荐系统技术总结的架构梳理和建议表达思路: 从原理到生产环境:推荐系统核心技术与实战代码解析 一、推荐算法的演进图谱 传统算法三剑客 ![推荐系统算法分类示意图] (使用Mermaid绘制算法分类关系图,清晰展示技术演进&am…...

unity pico开发 四 物体交互 抓取 交互层级
文章目录 手部设置物体交互物体抓取添加抓取抓取三种类型抓取点偏移抓取事件抓取时不让物体吸附到手部 射线抓取交互层级 手部设置 为手部(LeftHandController)添加XRDirInteractor脚本 并添加一个球形碰撞盒,勾选isTrigger,调整大小为0.1 …...

基于深度学习的青花瓷图像检索系统开发与实现
目录 1.研究背景与目的 1.1课题背景 1.2研究目的 二、调研资料情况 2.1图像分割研究现状 2.2图像检索调研 2.2.1选择深度学习进行检索的原因及优势 2.2.2基于深度学习的图像检索技术的发展 2.2.3基于深度学习的图像检索的研究重点 2.3基于深度学习的图像检索方法调研 …...
—— Vuex 的使用)
uniapp 系统学习,从入门到实战(八)—— Vuex 的使用
全篇大概 4500 字(含代码),建议阅读时间 30min 📚 目录 Vuex核心概念解析在 UniApp 中集成Vuex状态管理与数据共享实践总结 一、Vuex 核心概念解析 1.1 什么是状态管理 在跨多组件的大型应用中,不同页面/组件需要共享和修改相同数据时&am…...

Vue Hooks 深度解析:从原理到实践
Vue Hooks 深度解析:从原理到实践 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家!点我试试!! 文章目录 Vue Hooks 深度解析:从原理到实践一、背景…...

django中序列化器serializer 的高级使用和需要注意的点
在 Django REST framework(DRF)中,序列化器(Serializer)是一个强大的工具,用于将复杂的数据类型(如 Django 模型实例)转换为 Python 原生数据类型,以便将其渲染为 JSON、XML 等格式,同时也能将接收到的外部数据反序列化为 Django 模型实例。以下将介绍序列化器的高级…...

靶场(二)---靶场心得小白分享
开始: 看一下本地IP 21有未授权访问的话,就从21先看起 PORT STATE SERVICE VERSION 20/tcp closed ftp-data 21/tcp open ftp vsftpd 2.0.8 or later | ftp-anon: Anonymous FTP login allowed (FTP code 230) |_Cant get dire…...

PHP Error处理指南
PHP Error处理指南 引言 在PHP开发过程中,错误处理是一个至关重要的环节。正确的错误处理不仅能够提高代码的健壮性,还能提升用户体验。本文将详细介绍PHP中常见的错误类型、错误处理机制以及最佳实践,帮助开发者更好地应对和处理PHP错误。 PHP错误类型 在PHP中,错误主…...

视频输入设备-V4L2的开发流程简述
一、摄像头的工作原理与应用 基本概念 V4L2的全称是Video For Linux Two,其实指的是V4L的升级版,是linux系统关于视频设备的内核驱动,同时V4L2也包含Linux系统下关于视频以及音频采集的接口,只需要配合对应的视频采集设备就可以实…...

【Manus资料合集】激活码内测渠道+《Manus Al:Agent应用的ChatGPT时刻》(附资源)
DeepSeek 之后,又一个AI沸腾,冲击的不仅仅是通用大模型。 ——全球首款通用AI Agent的破圈启示录 2025年3月6日凌晨,全球AI圈被一款名为Manus的产品彻底点燃。由Monica团队(隶属中国夜莺科技)推出的“全球首款通用AI…...

Mybatis集合嵌套查询,三级嵌套
三个表:房间 玩家 玩家信息 知识点:Mybatis中级联有关联(association)、集合(collection)、鉴别器(discriminator)三种。其中,association对应一对一关系、collectio…...

如何永久珍藏你的微信数字记忆?WeChatMsg让聊天记录成为永恒财富!
如何永久珍藏你的微信数字记忆?WeChatMsg让聊天记录成为永恒财富! 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/Gi…...

终极指南:在Windows上直接安装安卓APK文件的5个简单步骤
终极指南:在Windows上直接安装安卓APK文件的5个简单步骤 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 想在Windows电脑上运行安卓应用,但又厌…...

如何为《欧洲卡车模拟2》实现完整智能驾驶体验?ETS2LA自动驾驶插件终极指南
如何为《欧洲卡车模拟2》实现完整智能驾驶体验?ETS2LA自动驾驶插件终极指南 【免费下载链接】Euro-Truck-Simulator-2-Lane-Assist Plugin based interface program for ETS2/ATS. 项目地址: https://gitcode.com/gh_mirrors/eur/Euro-Truck-Simulator-2-Lane-Ass…...

Fast-GitHub:三步安装解决国内GitHub访问难题的终极指南
Fast-GitHub:三步安装解决国内GitHub访问难题的终极指南 【免费下载链接】Fast-GitHub 国内Github下载很慢,用上了这个插件后,下载速度嗖嗖嗖的~! 项目地址: https://gitcode.com/gh_mirrors/fa/Fast-GitHub 你是否经常因为…...

生物信息学逆向解析mRNA疫苗序列:从公开数据组装BNT-162b2与mRNA-1273的基因蓝图
1. 项目概述与背景解析 最近在生物信息学和疫苗研究领域,一个名为“NAalytics/Assemblies-of-putative-SARS-CoV2-spike-encoding-mRNA-sequences-for-vaccines-BNT-162b2-and-mRNA-1273”的项目引起了我的注意。这个项目标题看起来很长,但核心非常明确&…...

Seraphine:英雄联盟智能BP助手与战绩查询工具完整指南
Seraphine:英雄联盟智能BP助手与战绩查询工具完整指南 【免费下载链接】Seraphine 英雄联盟战绩查询工具 项目地址: https://gitcode.com/gh_mirrors/se/Seraphine 在英雄联盟的对局中,BP(禁选英雄)阶段往往是决定胜负的关…...

基于Arduino与TSL2561的光照度测量系统:从硬件连接到软件调试
1. 项目概述:从园艺需求到嵌入式光测量方案最近在折腾一个园艺相关的项目,需要量化评估不同覆盖材料(比如遮阳网、塑料薄膜)对光线透射率的影响。说白了,就是想精确知道,盖上一层材料后,底下还能…...

MCP服务器开发指南:为AI助手构建安全可控的外部工具扩展
1. 项目概述:一个为AI助手赋能的MCP服务器最近在折腾AI应用开发的朋友,可能都绕不开一个词:MCP。全称是Model Context Protocol,你可以把它理解成一套标准化的“插件协议”。它让像Claude、Cursor这类AI助手,能够安全、…...

从零构建可定制对话系统:架构设计、RAG与智能体实战
1. 项目概述:从零构建一个可定制的对话系统最近在折腾一个挺有意思的东西,我把它叫做“customized-chat”。这名字听起来可能有点泛,但它的核心目标非常明确:打造一个完全由你自己掌控、能深度融入你特定业务逻辑或知识体系的对话…...
NeoPixel光剑制作全攻略:从WS2812B原理到实战装配
1. 项目概述:从零件到光剑的旅程如果你和我一样,是个对《星球大战》里的光剑毫无抵抗力,同时又喜欢动手折腾电子玩意儿的人,那么用NeoPixel灯带自制一把会发光、能变色的光剑,绝对是件充满成就感的事。这不仅仅是把灯塞…...