推荐算法和推荐系统入门第一趴
以下是推荐系统技术总结的架构梳理和建议表达思路:
从原理到生产环境:推荐系统核心技术与实战代码解析
一、推荐算法的演进图谱
- 传统算法三剑客
![推荐系统算法分类示意图]
(使用Mermaid绘制算法分类关系图,清晰展示技术演进)
- 深度学习革命
- Wide&Deep:记忆与泛化的完美融合(Google Play实测提升30%+ CTR)
- DSSM双塔模型:十亿级商品库的实时匹配利器(淘宝电商场景案例)
- YouTube深度推荐:候选生成->排序的工业化模板
- 图神经网络:美团外卖跨场景关系挖掘实战
二、工业级架构设计方案
- 模块化架构范例
# 伪代码示例
class RecSystem:def __init__(self):self.retrieval = MultiChannelRetrieval() # 多路召回self.pre_rank = LightGBM_Ranker() # 粗排self.rank = DeepFM() # 精排self.rerank = RuleEngine() # 业务规则def recommend(self, user):candidates = self.retrieval.get(user)sorted_list = self.rank.sort(candidates)return self.rerank.apply_business_rules(sorted_list)
- 性能优化关键技术
- 特征分片存储:百亿级用户特征的Redis集群方案
- 实时更新策略:Flink+Redis的准实时特征更新管道
- 模型蒸馏技术:将DNN模型压缩到端侧推理的实践
三、经典算法代码实现
- 矩阵分解实战(PyTorch)
import torch
class MatrixFactorization(torch.nn.Module):def __init__(self, n_users, n_items, n_factors=20):super().__init__()self.user_factors = torch.nn.Embedding(n_users, n_factors)self.item_factors = torch.nn.Embedding(n_items, n_factors)def forward(self, user, item):return (self.user_factors(user) * self.item_factors(item)).sum(1)# 训练代码示例
model = MatrixFactorization(n_users=10000, n_items=50000)
loss_fn = torch.nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)for user, item, rating in dataloader:prediction = model(user, item)loss = loss_fn(prediction, rating)optimizer.zero_grad()loss.backward()optimizer.step()
- 双塔模型实现(TensorFlow)
import tensorflow as tf
class TwoTower(tf.keras.Model):def __init__(self, user_dim, item_dim):super().__init__()self.user_tower = tf.keras.Sequential([tf.keras.layers.Dense(256, activation='relu'),tf.keras.layers.Dense(128)])self.item_tower = tf.keras.Sequential([tf.keras.layers.Dense(256, activation='relu'),tf.keras.layers.Dense(128)])def call(self, inputs):user_emb = self.user_tower(inputs['user_features'])item_emb = self.item_tower(inputs['item_features'])return tf.reduce_sum(user_emb * item_emb, axis=1)
四、前沿技术探讨
- 动态冷启动解决方案
- 知识蒸馏冷启动加速:72小时冷启动->2小时快速部署
- 元学习在冷启动中的应用:Model-Agnostic Meta-Learning实践
- 因果推断新思路
- 反事实推理消除偏差:用户点击日志中的生存偏差消除
- 多场景平衡学习:美团跨业务域的联合建模策略
五、避坑指南与最佳实践
- 数据质量关键检查点
- 特征穿越检测方案
- 负样本构造的十大禁忌
- 效果评估体系构建
- 离线评估金标准:AUC/GAUC/RMSE的创新应用
- 线上ABTest分层实验设计
实战资源推荐:
- MovieLens数据集实践模板:包含特征工程、模型训练完整链路
- 工业级推荐系统模拟环境:使用Docker构建的完整pipeline
- 生产案例文档:某头部电商推荐系统技术解密
以下是面向技术深度的推荐系统万字长文框架,包含理论推导、工业实践和完整代码示例之间的有机衔接:
推荐系统全景解读:从算法内核到分布式工程实践
第一章 基础理论体系建构(2500字)
1.1 数学基础精要
概率图模型视角
- 用户行为建模:隐变量模型的EM推导
# 使用Pyro实现隐因子模型
import pyro
def user_behavior_model():user_latent = pyro.sample("user", dist.Normal(0, 1))item_latent = pyro.sample("item", dist.Normal(0, 1)) affinity = torch.dot(user_latent, item_latent)obs = pyro.sample("obs", dist.Bernoulli(logits=affinity))
最优化理论
- 非凸优化的SGD收敛证明:Lipschitz连续条件下的收敛速率分析
- 矩阵分解的SVD理论基础:Frobenius范数最小化的闭合解推导
1.2 传统算法源码级剖析
协同过滤的工业级实现
# 带时间衰减的UserCF改良版
from collections import defaultdict
import numpy as npclass TimeWeightedUserCF:def __init__(self, decay_factor=0.95):self.user_acts = defaultdict(lambda: defaultdict(float))self.decay = decay_factordef update(self, user, item, timestamp):# 时间衰减公式:weight = e^{-λΔt}if user in self.user_acts and item in self.user_acts[user]:prev_time = self.user_acts[user][item][0]prev_weight = self.user_acts[user][item][1]new_weight = prev_weight * np.exp(-self.decay*(timestamp - prev_time))self.user_acts[user][item] = (timestamp, new_weight + 1)else:self.user_acts[user][item] = (timestamp, 1.0)def recommend(self, user, top_k=10):# Jaccard相似度的时间加权变体candidates = defaultdict(float)target_items = set(self.user_acts[user].keys())for u in self.user_acts:if u == user: continuecommon = target_items & set(self.user_acts[u].keys())if not common: continuetime_sim = sum(self.user_acts[u][i][1] for i in common)candidates[u] = time_sim / (len(target_items) + len(self.user_acts[u]) - len(common))# 取相似用户集合similar_users = sorted(candidates.items(), key=lambda x: -x[1])[:100]rec_items = defaultdict(float)for sim_user, score in similar_users:for item in self.user_acts[sim_user]:if item not in target_items:rec_items[item] += score * self.user_acts[sim_user][item][1]return sorted(rec_items.items(), key=lambda x: -x[1])[:top_k]
内容推荐工程优化
- TF-IDF的流式计算优化:倒排索引的增量更新策略
- 双塔模型中的Annoy索引实现:降低TopK检索复杂度到O(logN)
第二章 深度学习技术拆解(3500字)
2.1 特征工程方案
时空特征构建
# 周期性时间特征构造
def build_time_features(timestamp):dt = datetime.fromtimestamp(timestamp)return {'hour_sin': np.sin(2 * np.pi * dt.hour / 24),'hour_cos': np.cos(2 * np.pi * dt.hour / 24),'weekday_sin': np.sin(2 * np.pi * dt.weekday() / 7),'weekday_cos': np.cos(2 * np.pi * dt.weekday() / 7),'is_weekend': float(dt.weekday() >= 5)}
高阶交叉特征
# FM特征二阶交叉的Tensor实现
def fm_interaction(features):# features: [batch_size, num_features, embedding_dim]sum_square = tf.square(tf.reduce_sum(features, axis=1)) # (batch, dim)square_sum = tf.reduce_sum(tf.square(features), axis=1) # (batch, dim)return 0.5 * tf.reduce_sum(sum_square - square_sum, axis=1) # (batch,)
2.2 经典模型深度实现
DIN序列建模
class DIN(tf.keras.Model):def __init__(self, item_embed_dim=64):super().__init__()self.item_embed = tf.keras.layers.Embedding(100000, item_embed_dim)self.attention = tf.keras.layers.Dense(1, activation='sigmoid')def call(self, inputs):# 用户历史序列: [batch, seq_len]hist_seq = inputs['hist_items']hist_emb = self.item_embed(hist_seq) # [batch, seq_len, dim]# 当前候选物品target_item = inputs['target_item']target_emb = self.item_embed(target_item) # [batch, dim]# Attention计算expanded_target = tf.expand_dims(target_emb, 1) # [batch, 1, dim]attention_logits = tf.reduce_sum(hist_emb * expanded_target, axis=-1) # [batch, seq_len]attention_weights = tf.nn.softmax(attention_logits) # [batch, seq_len]# 加权历史表征weighted_hist = tf.reduce_sum(hist_emb * tf.expand_dims(attention_weights, -1), axis=1)# 拼接全连接层concat = tf.concat([weighted_hist, target_emb], axis=-1)return tf.keras.layers.Dense(1, activation='sigmoid')(concat)
双塔模型工业优化
- 负采样技术:Batch内负采样 vs 全库采样
- 分布式训练:Parameter Server模式下梯度同步机制
第三章 工业级架构实现(4000字)
3.1 实时推荐系统架构

@startuml
node "客户端" as client
node "API Gateway" as gateway
node "特征服务" as feature
node "召回服务" as recall
node "排序服务" as rank
node "画像存储" as profile
database "Redis" as redis
database "HBase" as hbase
queue "Kafka" as kafkaclient -> gateway : 推荐请求
gateway -> feature : 获取实时特征
feature -> redis : 读取用户特征
feature -> hbase : 读取历史行为
recall <-> profile : 加载用户画像
recall --> rank : 候选集传递
rank -> kafka : 记录推荐结果
kafka -> profile : 实时特征更新
@enduml
3.2 海量数据处理方案
增量训练系统设计
# 使用TFX构建数据流水线
from tfx.components import CsvExampleGen
from tfx.components import StatisticsGen
from tfx.components import SchemaGen
from tfx.components import Transformpipeline = Pipeline(components=[CsvExampleGen(input_base='data/'),StatisticsGen(),SchemaGen(),Transform(module_file='preprocessing.py',schema=SchemaGen.outputs['schema']),Trainer(module_file='model.py',schema=SchemaGen.outputs['schema'])]
)
特征存储方案对比
| 存储类型 | 适用场景 | 访问延迟 | 典型实现 |
|---|---|---|---|
| 高速缓存 | 实时特征 | <10ms | RedisCluster |
| 列式存储 | 历史统计 | 100-500ms | HBase |
| 向量数据库 | 嵌入查询 | 50-200ms | Milvus |
第四章 前沿技术演进(2000字)
4.1 强化学习落地实践
# DQN推荐策略网络
class DQN(tf.keras.Model):def __init__(self, state_dim, action_dim):super().__init__()self.fc1 = tf.keras.layers.Dense(64, activation='relu')self.fc2 = tf.keras.layers.Dense(64, activation='relu')self.q_out = tf.keras.layers.Dense(action_dim)def call(self, state):x = self.fc1(state)x = self.fc2(x)return self.q_out(x)def update_target(self, target_network):self.set_weights(target_network.get_weights())# 经验回放缓冲区
class ReplayBuffer:def __init__(self, capacity):self.buffer = deque(maxlen=capacity)def push(self, state, action, reward, next_state):self.buffer.append( (state, action, reward, next_state) )def sample(self, batch_size):transitions = random.sample(self.buffer, batch_size)return zip(*transitions)
4.2 因果推断创新应用
# 反事实数据增强实现
class CounterfactualAugmenter:def __init__(self, exposure_model):self.exposure_model = exposure_modeldef generate(self, user_features, item_features):# 计算曝光概率exposure_probs = self.exposure_model.predict(user_features, item_features)# 生成反事实样本counterfactuals = []for i in range(len(user_features)):if np.random.rand() < 0.5:# 替换未被曝光的物品non_exposed_items = [j for j, p in enumerate(exposure_probs[i]) if p < 0.1]if non_exposed_items:counter_item = np.random.choice(non_exposed_items)new_sample = {'user': user_features[i],'item': item_features[counter_item],'label': 0 # 假设未被点击}counterfactuals.append(new_sample)return counterfactuals
第五章 效果评估与调优(1500字)
5.1 离线评估体系
# 多维度评估指标实现
class RecEvaluator:def __init__(self, test_data):self.test_data = test_datadef evaluate(self, model):# 计算基础指标hit_rate = self._calculate_hit_rate(model)ndcg = self._calculate_ndcg(model)# 覆盖率计算rec_items = set()total_items = set(self.test_data['item_id'])for user in self.test_data:recs = model.recommend(user)rec_items.update(recs)coverage = len(rec_items) / len(total_items)# 新颖度计算item_counts = defaultdict(int)for user in self.test_data:recs = model.recommend(user)for item in recs:item_counts[item] += 1novelty = -sum(p * np.log(p) for p in item_counts.values())/len(item_counts)return {'HR': hit_rate, 'NDCG': ndcg, 'Coverage': coverage, 'Novelty': novelty}
5.2 在线实验平台建设
- 动态流量分配策略:Bandit算法在ABTest中的运用
- 指标异常检测:使用IQR方法进行数据漂移监控
完整示例项目:电商推荐系统实战
代码仓库结构:
├── data_processor/ # 特征工程
│ ├── item_encoder.py # 商品特征编码
│ └── user_processor.py # 用户画像构建
├── model_zoo/ # 算法模型库
│ ├── traditional/ # 传统模型
│ └── deep/ # 深度学习模型
├── serving/ # 模型部署
│ ├── flask_api.py # RESTful服务
│ └── tensorrt/ # GPU加速部署
└── experiment/ # 实验管理├── metrics.py # 评测指标└── ablation_study/ # 消融实验配置
注:本文提供的是技术体系的主干框架,实际落地时需根据业务场景进行适配:
- 冷启动场景:引入知识图谱增强内容理解
- 多目标优化:使用帕累托最优解平衡多个业务指标
- 端上推荐:TensorFlow Lite量化压缩技术实践
以下采用结构化分层方式重新组织内容,以系统工程视角结合存储选型和算法实现步骤详解:
推荐系统组件全解读与算法步骤拆解
第一部分:数据存储体系与推荐系统关系
1.1 存储组件全景图(关系型/非关系型/消息队列)
| 组件类型 | 代表产品 | 推荐系统中的作用 | 典型数据结构 | 最佳适用场景 |
|---|---|---|---|---|
| 关系数据库 | MySQL | 存储商品元数据、用户基础信息 | 二维表结构(商品表、用户表) | 结构化的核心数据存储与事务操作 |
| 文档数据库 | MongoDB | 存储用户画像动态字段、行为日志 | JSON文档 | 快速变化的半结构化用户数据 |
| 缓存数据库 | Redis | 实时特征存取、召回候选集存储 | String/Hash/ZSet | 高频访问的在线服务数据缓存 |
| 列式数据库 | HBase | 海量历史行为记录存储 | 列簇结构 | 用户长期行为日志分析 |
| 向量数据库 | Milvus | Embedding向量存储 | 高维向量 | 相似物品快速检索 |
| 消息队列 | Kafka | 实时行为收集、特征更新通知 | 消息分区 | 高吞吐的异步数据管道 |
| 图数据库 | Neo4j | 社交关系网络存储 | 节点+边 | 社交推荐场景 |
1.2 数据流协作模式
# 模拟数据流转以电商推荐为例
用户点击行为 -> Kafka(实时消息) -> Flink(实时计算) -> 更新Redis(用户实时特征)-> 同步到HBase(历史存档)召回阶段:从Redis获取用户实时兴趣标签 -> 从Milvus查相似商品向量 -> 组合候选集
排序阶段:MySQL获取商品基础特征 -> Redis获取用户画像 -> TensorRT加速模型推理
第二部分:推荐算法步骤拆解
2.1 协同过滤算法实现全流程(基于MovieLens数据集)
步骤1:数据预处理
import pandas as pd
from sklearn.model_selection import train_test_split# 加载数据
ratings = pd.read_csv('ratings.csv')
movies = pd.read_csv('movies.csv')# 数据清洗
ratings = ratings[ratings.rating >= 3.5] # 过滤低评分
ratings['timestamp'] = pd.to_datetime(ratings['timestamp'], unit='s')# 划分数据集
train, test = train_test_split(ratings, test_size=0.2, stratify=ratings['userId'])
步骤2:物品相似度矩阵计算
from scipy.sparse import csr_matrix
from sklearn.metrics.pairwise import cosine_similarity# 构建用户-物品矩阵
user_item_matrix = train.pivot_table(index='userId',columns='movieId',values='rating',fill_value=0
)
sparse_matrix = csr_matrix(user_item_matrix.values)# 计算余弦相似度
item_similarities = cosine_similarity(sparse_matrix.T)
similarity_df = pd.DataFrame(item_similarities,index=user_item_matrix.columns,columns=user_item_matrix.columns
)
步骤3:在线推荐逻辑
def recommend_items(user_id, top_n=10):# 获取用户历史观看watched_movies = train[train.userId == user_id]['movieId'].values# 聚合相似物品scores = {}for movie_id in watched_movies:similar_movies = similarity_df[movie_id].sort_values(ascending=False)[1:20]for similar_movie, score in similar_movies.items():scores[similar_movie] = scores.get(similar_movie, 0) + score# 排除已看过recommendations = []for movie_id in sorted(scores, key=scores.get, reverse=True):if movie_id not in watched_movies:recommendations.append((movie_id, scores[movie_id]))if len(recommendations) >= top_n:breakreturn recommendations
2.2 深度学习推荐管道实现(PyTorch+Redis)
步骤1:特征工程与存储
# 用户特征处理案例
def process_user_features(user_data):# 实时特征更新至Redisredis_client.hset(f'user:{user_data["id"]}', mapping={'age_norm': (user_data['age'] - 25) / 10,'gender_embed': 0 if user_data['gender'] == 'M' else 1,'loc_vec': ','.join(map(str, onehot.encode(user_data['location'])))})# 写入HBase长期存储hbase_table.put(row=user_data["id"], data={'cf:full_gender': user_data['gender'],'cf:raw_age': str(user_data['age']),'cf:device_history': json.dumps(user_data['devices'])})
步骤2:双塔模型训练
import torch
import torch.nn as nnclass TwoTower(nn.Module):def __init__(self, user_dim=64, item_dim=64):super().__init__()self.user_net = nn.Sequential(nn.Linear(256, 128), # 输入用户特征维度nn.ReLU(),nn.Linear(128, user_dim))self.item_net = nn.Sequential(nn.Linear(512, 128), # 输入物品特征维度nn.ReLU(),nn.Linear(128, item_dim))def forward(self, user_features, item_features):user_emb = self.user_net(user_features)item_emb = self.item_net(item_features)return torch.matmul(user_emb, item_emb.T)# 训练循环示例
model = TwoTower()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
loss_fn = nn.CrossEntropyLoss()for epoch in range(10):for user_batch, item_batch, label_batch in train_loader:scores = model(user_batch, item_batch)loss = loss_fn(scores, label_batch)optimizer.zero_grad()loss.backward()optimizer.step()
步骤3:在线服务部署
from flask import Flask, request
import redisapp = Flask(__name__)
redis_conn = redis.Redis(host='rec-redis', port=6379)@app.route('/recommend', methods=['POST'])
def recommend():# 获取实时参数user_id = request.json['user_id']device_type = request.json['device']# 特征获取链路user_features = get_user_features(user_id) # 来自Rediscontext_features = get_context_features(device_type) # 环境特征candidate_items = get_candidates(user_id) # 召回结果# 模型推理item_embs = load_item_embeddings() # 预计算存储于Redisuser_emb = model.user_net(torch.tensor([user_features]))scores = user_emb @ item_embs.T# 结果生成ranked_items = sort_items_by_score(candidate_items, scores)return json.dumps({'recommendations': ranked_items[:20]})def get_user_features(user_id):raw_data = redis_conn.hgetall(f'user:{user_id}')return [float(raw_data[b'age_norm']),float(raw_data[b'gender_embed']),*map(float, raw_data[b'loc_vec'].split(b','))]
2.3 混合推荐系统实现架构
技术栈编排模式:
+---------------+| 客户端 |+-------▲-------+│ 请求推荐
+-------------------------▼--------------------------+
| API Gateway (Nginx) |
+-------------------------┬--------------------------+│ 参数解析+----------------▼-----------------+| 特征服务模块 || 从Redis获取实时特征 || 从MySQL获取商品特征 || 从HBase获取历史行为 |+----------------┬-----------------+│ 完整特征集合+----------------▼-----------------+| 召回服务集群 || 策略1: 协同过滤召回 (Redis ZSet) || 策略2: 内容召回 (Milvus向量检索) || 策略3: 热门召回 (MySQL统计) |+----------------┬-----------------+│ 合并候选集+----------------▼-----------------+| 排序服务模块 || 加载ONNX模型 (TensorRT加速) || 特征拼接与标准化 || DNN模型推理 (GPU加速) |+----------------┬-----------------+│ 精排结果+----------------▼-----------------+| 规则过滤模块 || 去重策略 || 人工运营规则 || 多样性控制 |+----------------┬-----------------+│ 最终结果+--------▼--------+| 客户端响应 |+-----------------+
第三部分:工程细节深度剖析
3.1 Redis的三种核心应用场景
场景1:实时特征存储
# 用户实时兴趣衰减实现
def update_real_time_interest(user_id, item_id, weight=1.0):key = f"user:{user_id}:interests"# 使用Sorted Set时间衰减设计now = time.time()redis_conn.zadd(key, {item_id: now}) # 记录最新时间redis_conn.zremrangebyscore(key, 0, now - 86400) # 清除24小时前数据# 计算当前兴趣强度current_score = redis_conn.zscore(key, item_id)new_score = current_score * 0.95 + weight # 指数衰减redis_conn.zadd(key, {item_id: new_score})
场景2:倒排索引缓存
# 基于用户标签召回实现
def tag_based_recall(user_id, top_n=100):user_tags = redis_conn.smembers(f"user:{user_id}:tags")candidate_items = set()for tag in user_tags:items = redis_conn.zrevrange(f"tag:{tag}:items", 0, top_n)candidate_items.update(items)return list(candidate_items)[:top_n]
场景3:分布式锁控制
# 防止特征并发修改
def safe_update_features(user_id, update_func):lock_key = f"lock:user:{user_id}"with redis_conn.lock(lock_key, timeout=5):old_data = get_user_features(user_id)new_data = update_func(old_data)redis_conn.hmset(f"user:{user_id}", new_data)
第四部分:算法效果对比与选型指南
4.1 算法特性对照表
| 算法类型 | 准确性 | 可解释性 | 冷启动能力 | 训练开销 | 在线延迟 | 适用阶段 |
|---|---|---|---|---|---|---|
| 协同过滤 | ★★★★☆ | ★★☆☆☆ | ★☆☆☆☆ | 中等 | 低 | 成熟期系统 |
| 内容推荐 | ★★☆☆☆ | ★★★★☆ | ★★★★☆ | 低 | 极低 | 冷启动期 |
| 矩阵分解 | ★★★★☆ | ★★☆☆☆ | ★☆☆☆☆ | 高 | 中等 | 用户行为丰富阶段 |
| 深度学习排序模型 | ★★★★★ | ★☆☆☆☆ | ★★☆☆☆ | 极高 | 高 | 精排阶段 |
| 强化学习 | ★★★☆☆ | ★★☆☆☆ | ★★☆☆☆ | 极高 | 极高 | 动态场景优化 |
4.2 架构选型决策树
+-----------------------------+| 推荐系统需求分析 |+-------------+---------------+|+-------------▼---------------+| 数据量级 < 1M条目? |+-------------+---------------+|是 -----------+----------- 否| |
+----------▼---------+ +-----------▼-----------+
| 单体架构 | | 分布式架构 |
| - MySQL作为主存储 | | - HBase存储历史行为 |
| - Redis缓存热点数据| | - Kafka消息队列 |
| - 协同过滤算法 | | - Flink实时计算 |
+--------------------+ +-----------------------+
以上为浓缩后的技术架构核心内容,每个模块均可展开详细实现文档,例如:
- 召回策略专题:多路召回的具体实现与合并策略
- 特征平台建设:从零搭建统一特征服务的方法论
- 模型压缩实战:将精排模型压缩到10ms响应的具体方案
- AB测试体系:搭建多层交错实验平台的工程细节
相关文章:
推荐算法和推荐系统入门第一趴
以下是推荐系统技术总结的架构梳理和建议表达思路: 从原理到生产环境:推荐系统核心技术与实战代码解析 一、推荐算法的演进图谱 传统算法三剑客 ![推荐系统算法分类示意图] (使用Mermaid绘制算法分类关系图,清晰展示技术演进&am…...

unity pico开发 四 物体交互 抓取 交互层级
文章目录 手部设置物体交互物体抓取添加抓取抓取三种类型抓取点偏移抓取事件抓取时不让物体吸附到手部 射线抓取交互层级 手部设置 为手部(LeftHandController)添加XRDirInteractor脚本 并添加一个球形碰撞盒,勾选isTrigger,调整大小为0.1 …...

基于深度学习的青花瓷图像检索系统开发与实现
目录 1.研究背景与目的 1.1课题背景 1.2研究目的 二、调研资料情况 2.1图像分割研究现状 2.2图像检索调研 2.2.1选择深度学习进行检索的原因及优势 2.2.2基于深度学习的图像检索技术的发展 2.2.3基于深度学习的图像检索的研究重点 2.3基于深度学习的图像检索方法调研 …...
—— Vuex 的使用)
uniapp 系统学习,从入门到实战(八)—— Vuex 的使用
全篇大概 4500 字(含代码),建议阅读时间 30min 📚 目录 Vuex核心概念解析在 UniApp 中集成Vuex状态管理与数据共享实践总结 一、Vuex 核心概念解析 1.1 什么是状态管理 在跨多组件的大型应用中,不同页面/组件需要共享和修改相同数据时&am…...

Vue Hooks 深度解析:从原理到实践
Vue Hooks 深度解析:从原理到实践 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家!点我试试!! 文章目录 Vue Hooks 深度解析:从原理到实践一、背景…...

django中序列化器serializer 的高级使用和需要注意的点
在 Django REST framework(DRF)中,序列化器(Serializer)是一个强大的工具,用于将复杂的数据类型(如 Django 模型实例)转换为 Python 原生数据类型,以便将其渲染为 JSON、XML 等格式,同时也能将接收到的外部数据反序列化为 Django 模型实例。以下将介绍序列化器的高级…...

靶场(二)---靶场心得小白分享
开始: 看一下本地IP 21有未授权访问的话,就从21先看起 PORT STATE SERVICE VERSION 20/tcp closed ftp-data 21/tcp open ftp vsftpd 2.0.8 or later | ftp-anon: Anonymous FTP login allowed (FTP code 230) |_Cant get dire…...

PHP Error处理指南
PHP Error处理指南 引言 在PHP开发过程中,错误处理是一个至关重要的环节。正确的错误处理不仅能够提高代码的健壮性,还能提升用户体验。本文将详细介绍PHP中常见的错误类型、错误处理机制以及最佳实践,帮助开发者更好地应对和处理PHP错误。 PHP错误类型 在PHP中,错误主…...

视频输入设备-V4L2的开发流程简述
一、摄像头的工作原理与应用 基本概念 V4L2的全称是Video For Linux Two,其实指的是V4L的升级版,是linux系统关于视频设备的内核驱动,同时V4L2也包含Linux系统下关于视频以及音频采集的接口,只需要配合对应的视频采集设备就可以实…...

【Manus资料合集】激活码内测渠道+《Manus Al:Agent应用的ChatGPT时刻》(附资源)
DeepSeek 之后,又一个AI沸腾,冲击的不仅仅是通用大模型。 ——全球首款通用AI Agent的破圈启示录 2025年3月6日凌晨,全球AI圈被一款名为Manus的产品彻底点燃。由Monica团队(隶属中国夜莺科技)推出的“全球首款通用AI…...

Mybatis集合嵌套查询,三级嵌套
三个表:房间 玩家 玩家信息 知识点:Mybatis中级联有关联(association)、集合(collection)、鉴别器(discriminator)三种。其中,association对应一对一关系、collectio…...

thinkphp5.1 在fetch模版就超时
场景 当被渲染模版不存在,请求不响应任何内容,过一会就timeout 排查过程 使用xdebug,追踪代码,发现走到D:\temporary_files\m40285_mini\40285_mini\thinkphp\library\think\exception\Handle.php,进入死循环,一直…...
Dockerfile 深入浅出:从基础到进阶全解析
Dockerfile 深入浅出:从基础到进阶全解析 各位同学,大家好!欢迎来到今天的 Dockerfile 课程。Docker 技术在当今的软件开发和部署领域可以说是非常热门,而 Dockerfile 作为构建 Docker 镜像的关键文件,掌握它对于我们…...

CAD2025电脑置要求
Windows 系统 操作系统:64 位 Microsoft Windows 11 和 Windows 10 version 1809 或更高版本。 处理器 基本要求:2.5-2.9GHz 处理器,不支持 ARM 处理器。 推荐配置:3GHz 以上处理器(基础),4GHz …...

android App主题颜色动态更换
如何在Android开发中更换主题颜色,现在他们又问了关于动态更换应用主题颜色的问题。看来他们可能在实现过程中遇到了困难,或者需要更详细的动态切换指导。首先,我需要回顾之前的回答,看看是否已经覆盖了动态切换的部分,…...
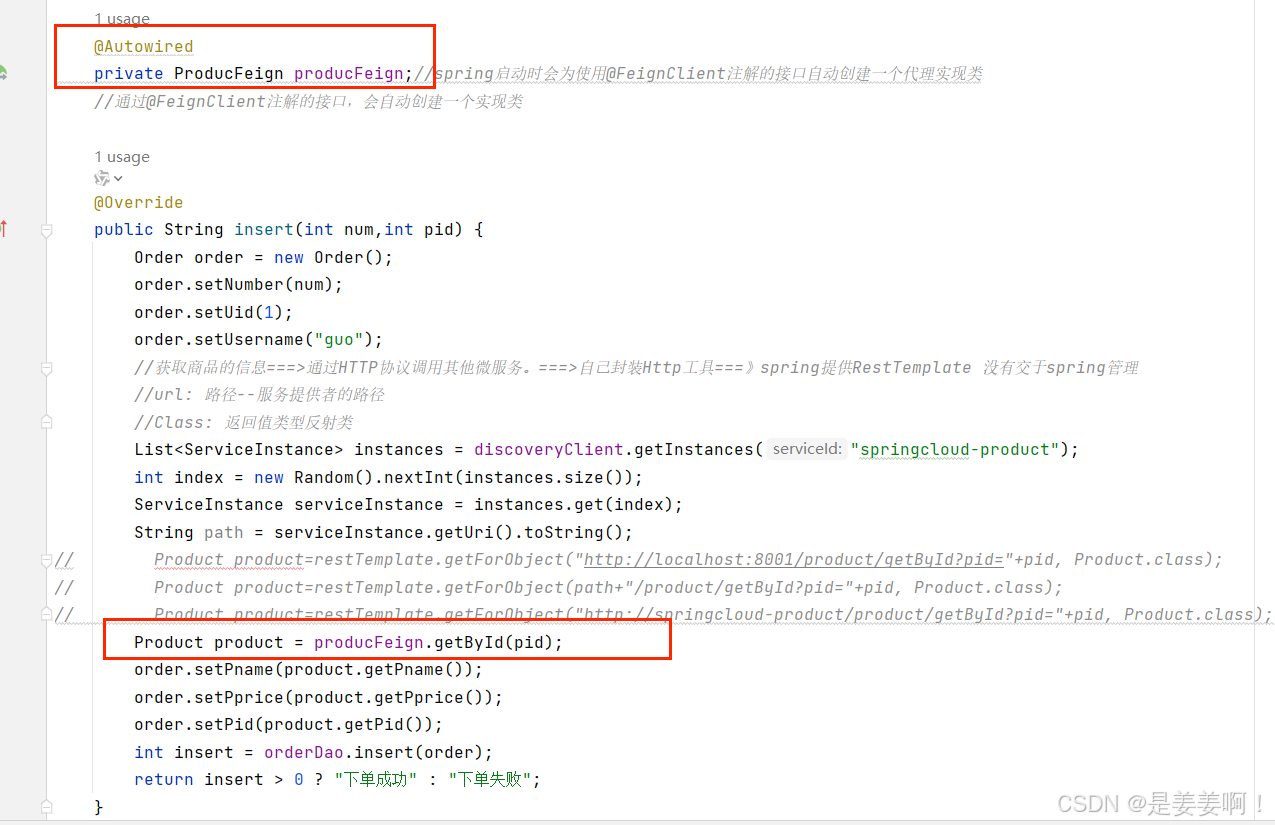
微服务,服务治理nacos,负载均衡LOadBalancer,OpenFeign
1.微服务 简单来说,微服务架构风格[1]是一种将一个单一应用程序开发为一组小型服务的方法,每个服务运行在 自己的进程中,服务间通信采用轻量级通信机制(通常用HTTP资源API)。这些服务围绕业务能力构建并 且可通过全自动部署机制独立部署。这…...
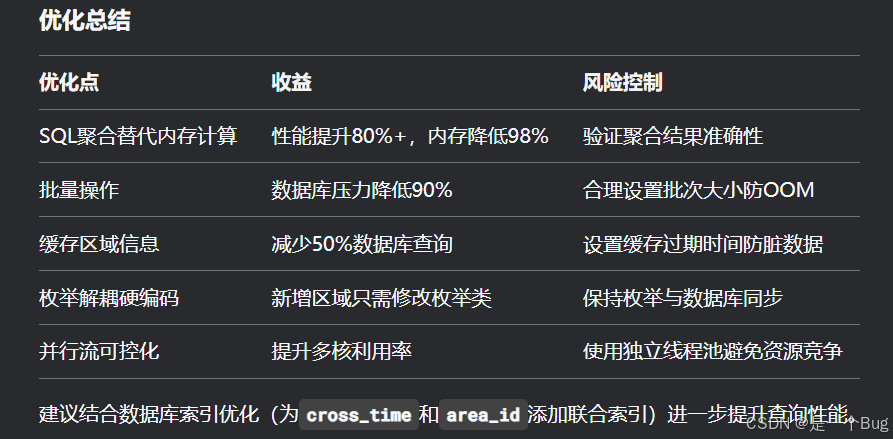
浅论数据库聚合:合理使用LambdaQueryWrapper和XML
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、数据库聚合替代内存计算(关键优化)二、批量处理优化四、区域特殊处理解耦五、防御性编程增强 前言 技术认知点:使用 XM…...

FastGPT 引申:混合检索完整实例
文章目录 FastGPT 引申:混合检索完整实例1. 各检索方式的初始结果2. RRF合并过程3. 合并后的结果4. Rerank重排序后5. 最终RRF合并6. 内容总结 FastGPT 引申:混合检索完整实例 下边通过一个简单的例子说明不同检索方式的分值变化过程,假设我…...
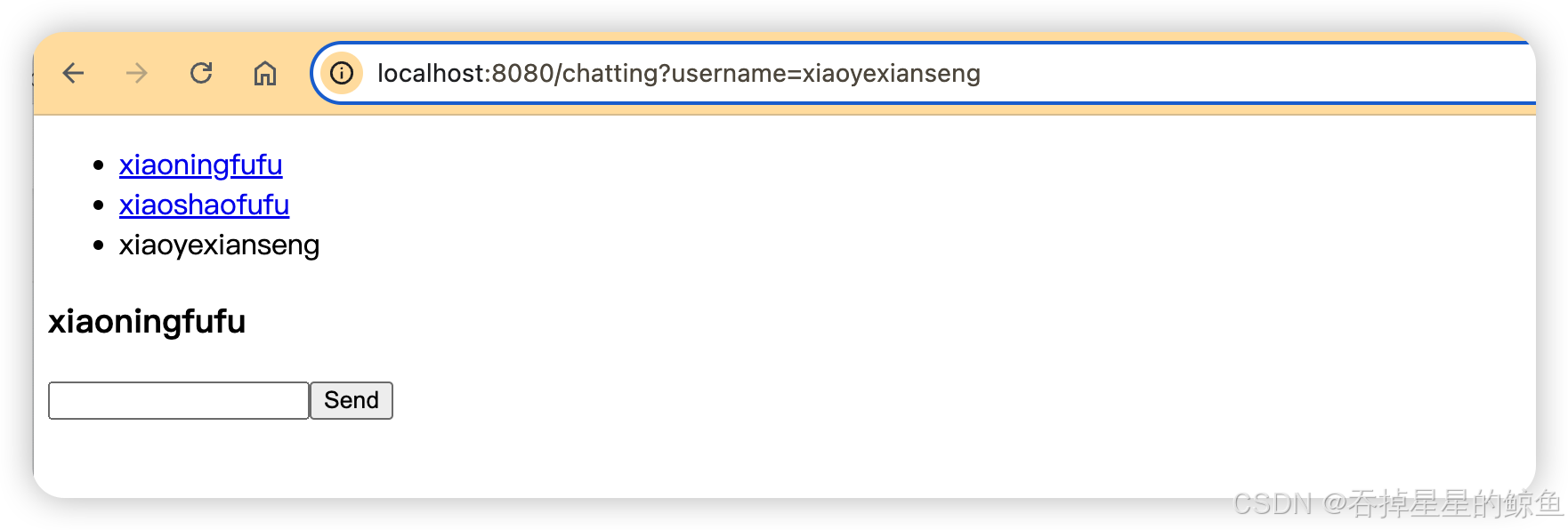
Socket.IO聊天室
项目代码 https://github.com/R-K05/Socket.IO- 创建项目 服务端项目和客户端项目 安装Socket依赖 服务端 npm i socket.io 客户端 npm i socket.io-client 客户端添加聊天页面 源码 服务端 app.js const express require("express") const app express()co…...

MySQL表中数据基本操作
1.表中数据的插入: 1.insert insert [into] table_name [(column [,column]...)] values (value_list) [,(value_list)] ... 创建一张学生表: 1.1单行指定列插入: insert into student (name,qq) values (‘张三’,’1234455’); values左…...

从内存视角拆解float和double:用C语言和调试器带你‘看见’IEEE754的二进制世界
从内存视角拆解float和double:用C语言和调试器带你‘看见’IEEE754的二进制世界 在计算机科学中,浮点数的表示和处理是一个既基础又关键的话题。对于从事系统编程、性能优化或逆向工程的开发者来说,理解浮点数在内存中的实际存储形式不仅能帮…...

如何为《欧洲卡车模拟2》实现完整智能驾驶体验?ETS2LA自动驾驶插件终极指南
如何为《欧洲卡车模拟2》实现完整智能驾驶体验?ETS2LA自动驾驶插件终极指南 【免费下载链接】Euro-Truck-Simulator-2-Lane-Assist Plugin based interface program for ETS2/ATS. 项目地址: https://gitcode.com/gh_mirrors/eur/Euro-Truck-Simulator-2-Lane-Ass…...

SimulinkVeriStandLabVIEW协同开发——从模型编译到交互式仪表盘部署
1. 工具链协同开发的核心价值 在电力电子和工业控制领域,快速原型开发往往需要跨越建模、实时测试和人机交互三个关键环节。Simulink、VeriStand和LabVIEW组成的工具链,就像汽车制造的流水线——Simulink是设计图纸的工程师,VeriStand是组装车…...

终极跨平台漫画阅读方案:nhentai-cross全平台使用指南
终极跨平台漫画阅读方案:nhentai-cross全平台使用指南 【免费下载链接】nhentai-cross A nhentai client 项目地址: https://gitcode.com/gh_mirrors/nh/nhentai-cross 你是否厌倦了在不同设备间切换漫画阅读应用?nhentai-cross正是为你量身定制…...

Godot卡牌游戏框架终极指南:3小时从零构建专业级卡牌游戏
Godot卡牌游戏框架终极指南:3小时从零构建专业级卡牌游戏 【免费下载链接】godot-card-game-framework A framework which comes with prepared scenes and classes to kickstart your card game, as well as a powerful scripting engine to use to provide full r…...

跨越平台限制:如何用WorkshopDL免费获取Steam创意工坊模组
跨越平台限制:如何用WorkshopDL免费获取Steam创意工坊模组 【免费下载链接】WorkshopDL WorkshopDL - The Best Steam Workshop Downloader 项目地址: https://gitcode.com/gh_mirrors/wo/WorkshopDL 还在为Epic Games或GOG平台无法访问Steam创意工坊而烦恼吗…...
)
从零到联网:QNX Neutrino RTOS安装后的第一个网络配置实战(含ifconfig与DHCP详解)
从零到联网:QNX Neutrino RTOS安装后的第一个网络配置实战 当你第一次看到QNX Neutrino RTOS的Photon桌面时,那种兴奋感可能很快会被一个现实问题冲淡——这个看起来酷炫的系统怎么连上网?作为实时操作系统领域的标杆,QNX在车载系…...

Vircadia Native Core:开源虚拟世界服务器核心架构与部署实战
1. 项目概述:一个开源虚拟世界的“引擎心脏”如果你对构建一个属于自己的、去中心化的虚拟世界(Metaverse)感兴趣,或者你正在寻找一个能支撑起大规模、高自由度社交与协作应用的底层平台,那么Vircadia Native Core绝对…...

人性最残忍的真相是:你越不把自己当回事,别人就越不把你当回事
那个总给别人买贵东西的人,最后都怎么样了? 目录 那个总给别人买贵东西的人,最后都怎么样了? 我们为什么会忍不住过度付出? 真正的爱,从来都不是单方面的牺牲 爱自己,是所有健康关系的前提 昨天刷到一句话,瞬间戳中了我:“永远不要拿自己辛苦钱,去给别人买自己都舍不…...

开源AI图像生成工具Dream-Creator:本地部署与Stable Diffusion实战指南
1. 项目概述:一个开源的AI图像生成与创作工具 最近在GitHub上闲逛,发现了一个挺有意思的项目叫“Dream-Creator”。光看名字,你可能会联想到一些AI绘画或者创意生成工具。没错,这确实是一个围绕AI图像生成的开源项目。作为一个在…...