MySQL(单表)知识点
文章目录
- 1.数据库的概念
- 2.下载并配置MySQL
- 2.1初始化MySQL的数据
- 2.2注册MYSQL服务
- 2.3启动MYSQL服务
- 2.4修改账户默认密码
- 2.5登录MYSQL
- 2.6卸载MYSQL
- 3.MYSQL数据模型
- 3.1连接数据库
- 4.SQL简介
- 4.1SQL的通用语法
- 4.2SQL语句的分类
- 4.3DDL语句
- 4.3.1数据库
- 4.3.2表(创建,查询,修改,删除)
- 4.3.3对数据库中约束的详细说明
- 4.3.4DDL语句中的数据类型
- 4.4使用IDEA连接数据库
- 4.4.1在IDEA中对数据库进行操作
- 4.5DML语句
- 4.5.1添加数据(INSERT)
- 4.5.2修改数据(UPDATE)
- 4.5.3 删除数据(DELETE)
- 4.6DQL语句
- 4.6.1DQL语法
- 4.6.2基本查询
- 4.6.3条件查询
- 4.6.4分组查询
- 4.6.5排序查询
- 4.6.6分页查询
- 5.综合案例
- 5.1案例
- 5.2if条件表达式
- 5.3case表达式
1.数据库的概念
数据库:DataBase(DB),是村粗和管理数据的仓库
数据库管理系统:DataBase Management System(DBMS),操纵和管理数据库的大型软件
SQL:Structured Query Language(结构化查询语言),操作关系型数据库的变成语言,定义了一套操作关系型数据库的统一标准
2.下载并配置MySQL
MySQL的官网:MySQL :: Download MySQL Community Server
-
下载安装包并解压
-
配置环境变量
![![[Pasted image 20250227215121.png]]](https://i-blog.csdnimg.cn/direct/840f3e6bcda84eb1a87e9b453c6b7746.png)
-
检验环境变量是否配置成功
在命令行中输入mysql
出现下面错误信息为配置成功
![![[Pasted image 20250227215307.png]]](https://i-blog.csdnimg.cn/direct/60b90cddd324474ea29c99de1d466bfa.png)
2.1初始化MySQL的数据
在管理员身份的命令行中输入
mysqld --initialize-insecure
![![[Pasted image 20250227215923.png]]](https://i-blog.csdnimg.cn/direct/96dd723d506142839bbf7a390cf4e26b.png)
2.2注册MYSQL服务
在管理员身份的命令行中执行下面的指令
mysqld -install
![![[Pasted image 20250228084804.png]]](https://i-blog.csdnimg.cn/direct/e567226e25d747859ac4d2ba998c4f34.png)
![![[Pasted image 20250228085040.png]]](https://i-blog.csdnimg.cn/direct/4b91569ab86b40a280845773388453dd.png)
MYSQL成功注册成系统服务并在开机时自动启动
2.3启动MYSQL服务
在命令行下输入下面的指令,分别为启动MYSQL服务和停止MYSQL服务
net start mysql // 启动mysql服务
net stop mysql // 停止mysql服务
![![[Pasted image 20250228091423.png]]](https://i-blog.csdnimg.cn/direct/3ebf84c80f6b4f05812d2237261cec24.png)
2.4修改账户默认密码
mysqladmin -u root password 1234
1234为修改后的密码-可以任意修改自己喜欢的(我的密码与校园圈密码相同)
2.5登录MYSQL
mysql -uroot -p1234(1234部分修改成自己的密码)//登录
exit//退出
或
quit//退出
-u+用户名 -p+密码
使用更安全的方法登录MYSQL
先输入
mysql -uroot -p
再输入密码
![![[Pasted image 20250228092507.png]]](https://i-blog.csdnimg.cn/direct/ef96df32502140bca32133505bdef482.png)
2.6卸载MYSQL
以管理员身份执行命令行,输入
net stop mysql+回车
mysqld -remove mysql+回车
最后删除相关的目录及环境变量
语法
mysql -u用户名 -p密码[-h数据库服务器IP地址(不指定时为0.0.1) -p端口号(不指定端口号时使用默认端口号3306)]
3.MYSQL数据模型
- 关系型数据库(RDBMS):建立在关系模型的基础上,由多张相互连接的二维表组成的数据库
3.1连接数据库
创建一个新的数据库
登录后使用命令
CREATE DATABASE 数据库名字;
![![[Pasted image 20250228112819.png]]](https://i-blog.csdnimg.cn/direct/5e22307f6aad4ad9815faf65ad3c7b8f.png)
一个数据库服务器中可以创建多个数据库,而且数据库之间是相互独立,互不影响的
4.SQL简介
SQL:一门操作关系型数据库的编程语言,定义操作所有关系型数据库的统一标准
4.1SQL的通用语法
- SQL语句可以单行或多行书写,以分号结尾
- SQL语句可以使用空格/缩进来增强语句的可读性
- MSQL数据库的SQL语句不区分大小写
- 注释
- 单行注释:
--注释内容或#注释内容(MYSQL特有) - 多行注释:
/*注释内容*/
4.2SQL语句的分类
- DDL:(Data Definition Language)-数据定义语言,用来定义数据库对象(数据库,表,字段)
- DML:(Data manipulation Language)-数据操作语言,用来对数据库中的数据进行增删改
- DQL:(Data Query Language)-数据查询语言,用来查询数据库中表的记录
- DCL:(Data Control Language)-数据控制语言,用来创建数据库用户,控制数据库的访问权限
4.3DDL语句
DDL:(Data Definition Language)-数据定义语言,用来定义数据库对象(数据库,表,字段)
4.3.1数据库
- 查询
- 查询所有数据库
show databases;
- 查询当前数据库
select databases();
- 使用
- 使用数据库
use 数据库名;
- 创建
- 创建数据库
create database[if not exists] 数据库名;
- 删除
- 删除数据库
drop database[if exists] 数据库名;
注意:上述语法中的database也可以替换成schema
4.3.2表(创建,查询,修改,删除)
- 表结构的创建
语法:
creat table 表名(字段1 字段类型[约束][comment 字段1注释],......字段n 字段类型[约束][comme nt 字段n注释]
)[comment 表注释];
==注意:==语法中[]的内容是可选的,可以加也可以不加
例:创建下图表结构
![![[Pasted image 20250303115039.png]]](https://i-blog.csdnimg.cn/direct/5505e3928f17435981ebbfe7d13aaf38.png)
create table tb_user( id int comment 'ID,唯一标识', username varchar(20) comment'用户名', name varchar(10) comment'姓名', age int comment '年龄', gender char(1) comment'性别'
)comment '用户表';
-- varchar相当于java中的字符串类型 varchar(20)表示该字符串长度最长为20\
-- comment后面为字段的注释
![![[Pasted image 20250303115306.png]]](https://i-blog.csdnimg.cn/direct/98d47024d17c4c59be660480691ef4c4.png)
- 表结构的查询
- 查询当前数据库的所有表
show tables;
- 查询表结构
desc 表名;
- 查询建表语句
show create table 表名;
- 修改表结构
-- 添加字段
alter table 表名 add 字段名 类型(长度)[comment 注释][约束]
-- 修改字段类型
alter table 表名 modify 旧字段名 新字段名 类型(长度)[comment 注释][约束]
-- 修改字段名和字段类型
alter table 表名 change 旧字段名 新字段名 类型(长度)[comment 注释][约束]
-- 删除字段
alter table表名 drop column字段名
-- 修改表名
rename table 表名 to 新表名
- 删除表结构
drop table[if eists]表名;
4.3.3对数据库中约束的详细说明
概念:约束是作用于表中字段上的规则,用于限制存储在表中的数据
目的:保证数据库中数据的正确性,有效性和完整性
- 非空约束:限制字段值不能为空,
not null - 唯一约束:保证字段的所有数据都是唯一的,不重复的,
unique - 主键约束:主键是一行数据的唯一标识,要求非空且唯一,
primary key(auto_increment自增)
auto_increment:自动从1往上增长 - 默认约束:保存数据时,如果未指定该字段值,则采用默认值,
default(default要加默认值) - 外键约束:让两张表的数据建立连接,保证数据的一致性和完整性,
foreign key
例:在创建的数据库表示中添加约束
![![[Pasted image 20250303161559.png]]](https://i-blog.csdnimg.cn/direct/85ebb0ec2ce74777ae4a6141af7492b6.png)
-- 创建:基本语法(约束)
create table tb_user( id int unique auto_increment comment'ID,唯一标识', username varchar(20) primary key comment '用户名', name varchar(10) not null comment'姓名', age int comment '年龄', gender char(1) default'男' comment'性别'
)comment '用户表';
4.3.4DDL语句中的数据类型
MySQL中的数据类型有很多,主要分为三类:数值类型,字符串类型,日期时间类型
-
数值类型
以tinyint为例,如果仅使用tinyint作为数据类型则默认为有符号范围,使用无符号范围需要用tinyint unsigned
![![[Pasted image 20250303162156.png]]](https://i-blog.csdnimg.cn/direct/f50d1f0724d4463780294f6b6353027f.png)
-
字符串类型
char(10):最多只能存10个字符,不足时10个字符,也会占用10个字符的空间,
varchar(10):最多只能存10个字符,不足10个字符时,按照实际长度进行空间占用
char不需要判断字符存储的空间,相较于varchar来说性能较高,而varchar需要判断字符空间,相较与char性能较低
![![[Pasted image 20250303162254.png]]](https://i-blog.csdnimg.cn/direct/9b5c37084f014ae68b1af549361f0827.png)
-
日期时间类型
![![[Pasted image 20250303162315.png]]](https://i-blog.csdnimg.cn/direct/4e5bfa806f5a49cfb6014fad728a03ab.png)
4.4使用IDEA连接数据库
在IDEA中创建一个空项目
![![[Pasted image 20250303105325.png]]](https://i-blog.csdnimg.cn/direct/06b6a13f833f4f1b80c24dac2acec7a6.png)
![![[Pasted image 20250303112318.png]]](https://i-blog.csdnimg.cn/direct/69c3235b141541308d926cf978671926.png)
4.4.1在IDEA中对数据库进行操作
除使用SQL语句对数据库进行增删改查外的方法对数据库进行管理
![![[Pasted image 20250303113143.png]]](https://i-blog.csdnimg.cn/direct/97b2510fb1a2467b8bb2e0714b50f9e3.png)
快速找到consel控制台界面
![![[Pasted image 20250303113635.png]]](https://i-blog.csdnimg.cn/direct/6352f88597b247fca145c6b1d875c5c8.png)
在创建的表格中添加数据
![![[Pasted image 20250303153959.png]]](https://i-blog.csdnimg.cn/direct/93dda06ae35347e691de8bea4dd19ff8.png)
4.5DML语句
==DML:==DML的英文全称是Data Manipulate Language(数据操作语言),用于对数据库中表的记录进行增删改操作
4.5.1添加数据(INSERT)
- 指定字段添加数据:insert into 表名(字段名1,字段名2) values(值1,值2)
- 全部字段添加数据:insert into 表名 values(值1,值2…)
- 批量添加数据(指定字段):insert into 表名(字段名1,字段名2) values(值1,值2)(值1,值2)
- 批量添加数据(全部字段):insert into 表名 values(值1,值2…)(值1,值2…)
-- DML:数据操作语言
-- DML:插入数据:insert
-- 1.为tb_staff表中的username,name,gender字段插入值
-- 使用now()函数把当前时间赋值给创建时间和更新时间
insert into tb_staff(username,name,gender,create_time,` update_time`)
values ('liangmou2121','梁某',1,now(),now()); -- 2.为tb_staff表中的所有字段插入值
insert into tb_staff values(null,'limou3434','123','李某',1,'1.jpg',2,'2004-09-23',now(),now()); -- 3.批量为tb_staff表中的username,name,gender字段插入数据
insert into tb_staff(username,name,gender,create_time,` update_time`)
values ('zhangsan','张三',1,now(),now()),('lisi','李四',2,now(),now());
注意:
1)插入数据时,指定的字段顺序需要与值的顺序是一一对应的
2)字符串和日期型数据应该包含在引导中
3)插入的数据大小,应该在字段的规定范围内
4.5.2修改数据(UPDATE)
- 修改数据:update 表名 set 字段名1=值1,字段名2=值2,…
[where 条件]
-- DML:更新数据
-- 1.将tb_staff表中id为1员工的姓名name字段更新为张三
-- 更新时间也需要修改
update tb_staff set name ='张三' ,` update_time` = now() where id = 1; -- 2.将tb_staff表的所有员工的入职日期更新为'2010-01-01'
update tb_staff set entrydate = '2010-01-01',` update_time` = now();
注意:修改语句的条件可以有,也可以没有,如果没有条件,则会修改整张表的数据
4.5.3 删除数据(DELETE)
- 删除数据:delete from 表名
[where 条件]
-- DML:删除数据-delete
-- 1.删除tb_staff表中id为1的员工
delete from tb_staff where id = 1; -- 2.删除tb_staff表中的所有员工
delete from tb_staff;
注意:1)DELETE语句的条件可以有,也可以没有,如果没有条件,则会删除整张表的所有数据
2)DELETE语句不能删除某一个字段的值,如果要操作可以使用UPDATE,将该字段的值置为NULL
4.6DQL语句
DQL:DQL英文全称是Data Query Language(数据查询语言),用来查询数据库表中的记录
关键字:SELETE
4.6.1DQL语法
- 基本查询
- select:字段列表
- from:表名列表
- 条件查询
- where:条件列表
- 分组查询
- group by:分组字段列表
- having:分组后条件列表
- 排序查询
- order by:排序字段列表
- 分页查询
- limit:分页参数
4.6.2基本查询
基本查询的语法:
- 查询多个字段:select 字段1,字段2,字段3 from 表名;
- 查询所有字段(通配符):select * from 表名;
- 设置别名:select 字段1
[as 别名1],字段2[as 别名2]from 表名; - 去除重复记录:select distinct 字段列表 from 表名;
-- DQL:基本查询
-- 1.查询指定字段 name,entrydate 并返回
select name,entrydate from tb_emp; -- 2.查询并返回所有字段
-- 1)第一种方式-推荐
select id, username, password, name, gender, image, job, entrydate, create_time, update_time from tb_emp;
-- 第二种方式-不推荐(不直观,性能低)
select * from tb_emp; -- 3.查询所有员工name,entrydate,并起别名(姓名,入职日期)
# select name as 姓名,entrydate as 入职日期 from tb_emp;-- 省略as
-- 如果别名中有特殊符号如空格或下划线,需要对别名添加上单引号或者双引号
-- 例;select name '姓 名',entrydate '入职_日期' from tb_emp; -- 4.查询已有员工关联了哪几种职位(不要重复)
select distinct job from tb_emp;
注意:1)*代表所有字段,在实际开发中尽量少用(不直观,影响效率)
2)as关键字可以省略
4.6.3条件查询
条件查询的语法:
- 条件查询:select 字段列表 from 表名 where 条件列表;
比较运算符
>-大于>=-大于等于>-小于<=-小于等于=-等于<>或者!=-不等于between...and-在某个范围之内(含最小,最大值)in(...)-在in之后的列表中的值,多选一like 占位符-模糊匹配(_匹配单个字符,%匹配任意个字符)is null-是nulland或&&-并且(多个条件同时成立)or或||-或者(多个条件任意一个成立)not或!-非,不是
-- 分组查询
-- 1.查询姓名为杨逍的员工 where后面写要查询的条件-从数据库的所有表中查询姓名为杨逍的信息
select * from tb_emp where name = '杨逍'; -- 2.查询id小于等于5的员工信息
select * from tb_emp where id <= 5; -- 3.查询没有分配职位的员工信息-查询job为null的员工
select * from tb_emp where job is null; -- 4.查询有职位的员工信息
select * from tb_emp where job is not null; -- 5.查询密码不等于'123456'的员工信息
select * from tb_emp where password != '123456';
-- 或
select * from tb_emp where password <> '123456';
-- 6.查询入职日期在'2000-01-01(包含)到'2010-01-01'(包含)之间的员工信息
select * from tb_emp where entrydate >='2000-01-01' and entrydate <='2010-01-01';
-- 或
select * from tb_emp where entrydate between'2000-01-01' and '2010-01-01';
-- 7.查询入职日期在'2000-01-01(包含)到'2010-01-01'(包含)之间且性别为女的员工信息
select * from tb_emp where entrydate between '2000-01-01' and '2010-01-01' and gender = 2;
-- 或
select * from tb_emp where entrydate between '2000-01-01' and '2010-01-01' && gender = 2;
-- 8.查询职位是2(讲师),3(学生主管),4(教研主任)的员工信息
select * from tb_emp where job = 2 or job = 3 or job = 4;
-- 或
select * from tb_emp where job = 2 || job = 3 || job = 4;
-- 或
select * from tb_emp where job in(2,3,4);
-- 9查询姓名为两个字的员工信息
select * from tb_emp where name like'__'; -- 10.查询姓'张'的员工信息
select * from tb_emp where name like'张%';
4.6.4分组查询
聚合函数:将一列数据作为一个整体,进行纵向计算
语法1:select 聚合函数(字段列表) from 表名;
- count:统计数量
- max:最大值
- min:最小值
- avg:平均值
- sum:求和
-- DQL:分组查询
-- 聚合函数-不对null值进行计算
-- 1.统计该企业员工数量
-- A.count(字段)-使用字段统计时,要选择非空字段
select count(id) from tb_emp;
-- B.count(常量)
select count(1) from tb_emp;
-- C.count(*)-统计表的总数据量-推荐使用
select count(*) from tb_emp; -- 2.统计该企业最早入职的员工-最早(小)的入职日期-min
select min(entrydate) from tb_emp; -- 3.统计该企业最迟入职的员工-最晚(大)的入职日期-min
select max(entrydate) from tb_emp; -- 4.统计该企业员工ID的平均值-avg
select avg(id) from tb_emp; -- 5.统计该企业员工的ID之和-sum
select sum(id) from tb_emp;
注意:
- null值不参与所有聚合函数运算
- 统计数量可以使用:count(
*),count(字段),count(常量),推荐使用count(*)
语法2:分组查询 select 字段列表 from 表名[where 条件] group by 分组字段名 [having 分组后过滤条件]
- 分组
-- 1.根据性别分组,统计男性和女性员工的数量
-- select后返回的结果有两类,一类是分组字段,一类是聚合函数
select gender,count(*) from tb_emp group by gender; -- 2.先查询入职时间在'2015-01-01'(包含)以前的员工,并对结果根据职位分组,获取员工数量大于等于2的职位
select job,count(*) from tb_emp where entrydate <= '2015-01-01' group by job having count(*) >= 2;
-- 先使用where条件进行约束-入职时间在2015-01-01(包括)以前
-- select * from tb_emp where entrydate <= '2015-01-01' ;
-- 再根据职位进行分组,返回聚合函数和分组字段-count聚合函数用于统计数量
select job,count(*) from tb_emp where entrydate <= '2015-01-01' group by job;
-- 最后只呈现员工数量大于等于2的职位
-- select job,count(*) from tb_emp where entrydate <= '2015-01-01' group by job having count(*) >= 2;
注意:where和having的区别
- 执行时机不同:where是分组之前进行过滤,不满足where条件,不参与分组,而having是分组之后对结果进行过滤
- 判断条件不同,where不能对聚合函数进行判断,而having可以
- 分组之后,查询的字段一般为聚合函数和分组字段,查询其他字段无任何意义
- 执行顺序:where>聚合函数>having
4.6.5排序查询
条件查询:select 字段列表 from 表名[where 条件列表]``[group by 分组字段]order by 字段1 排序方式1,字段2,排序方式2…;
排序方式:
- ASC:升序(默认值)
- DESC:降序
-- 排序查询
-- 1.根据入职时间,对员工进行升序排序-asc
-- 如果需要升序排序,可以省略asc 在系统中排序是默认为升序的
# select * from tb_emp order by entrydate asc;
select * from tb_emp order by entrydate; -- 2.根据入职时间,对员工进行降序排序-desc
select * from tb_emp order by entrydate desc; -- 3.根据入职时间对公司的员工进行升序排序,入职时间相同,再按照更新时间进行升序排序
select * from tb_emp order by entrydate desc,update_time desc;
注意:如果是多字段排序,当第一个字段值相同时,才会根据第二个字段进行排序
4.6.6分页查询
分页查询:select 字段列表 from 表名 limit 起始索引,查询记录数;
起始索引:从哪一条记录往后进行查询(从0开始)
起始索引 = (页码 - 1) * 每页展示的记录数
查询记录数:每一页需要展示多少条数据
-- 分页查询
-- 1.从起始索引0开始查询员工数量,每页展示五条记录
select * from tb_emp limit 0 , 5 ; -- 2.查询第1页员工数据,每页展示5条记录
select * from tb_emp limit 0 , 5 ; -- 3.查询第2页员工数据,每页展示5条记录
select * from tb_emp limit 5 , 5 ; -- 4.查询第3页员工数据,每页展示五条记录
select * from tb_emp limit 10 , 5 ;
注意:
- 起始索引从0开始,起始索引=(查询页码-1)
*每页显示记录数 - 分页查询时数据库的方言,不同的数据库有不同的实现,在MySQL中是LIMIT
- 如果查询的是第一页的数据,起始索引可以省略,直接简写为limit 查询记录数
例: 查询第一页的五条记录
select * from tb_emp limit 5;
5.综合案例
5.1案例
- 案例1:
-- 案例1:按需求完成员工管理系统分页查询-根据输入条件,查询第一页数据,每页展示10条记录
-- 输入条件:
-- 姓名:张
-- 性别:男
-- 入职时间:2000-01-01到2015-12-31
-- 对最后查询的结果根据修改时间进行倒序排序
-- 对语句进行格式化代码 ctrl + alt + lselect *
from tb_emp
where entrydate between '2000-01-01' and '2015-12-31' && name like '%张%' && gender = 1
order by update_time desc
limit 0,10;
- 案例2:
-- 案例2-1:根据需求,完成员工性别信息的统计count(*)
-- 统计男性员工和女性员工分别有多少人
-- 使用if表达式将性别从1,2转换成真实值
-- if(条件表达式,true取值,false取值)
# select gender,count(*) from tb_emp group by gender;
select if(gender = 1,'男性员工','女性员工')性别,count(*) from tb_emp group by gender;
5.2if条件表达式
if条件表达式的语法:if(条件表达式,true取值,false取值)[别名]
![![[Pasted image 20250308204522.png]]](https://i-blog.csdnimg.cn/direct/5c7cafafbd8d496c9ac312e6922f4986.png)
5.3case表达式
case表达式语法:case表达式 when 值1 then 结果1 when 值2 结果2…else…end
case语法用于有多种情况需要从数字转换成具体值
-- 案例2-2:根据需求,完成员工职位信息的统计
-- 使用case语法表达式 case表达式 when 值1 then 结果1 when 值2 then 结果2...else...end
-- 下列sql语句中job为表达式
select (case job when 1 then '班主任' when 2 then '讲师' when 3 then'学生主管' when 4 then '教研主管' else '未分配职位' end)职位, count(*)
from tb_emp
group by job;
相关文章:
MySQL(单表)知识点
文章目录 1.数据库的概念2.下载并配置MySQL2.1初始化MySQL的数据2.2注册MYSQL服务2.3启动MYSQL服务2.4修改账户默认密码2.5登录MYSQL2.6卸载MYSQL 3.MYSQL数据模型3.1连接数据库 4.SQL简介4.1SQL的通用语法4.2SQL语句的分类4.3DDL语句4.3.1数据库4.3.2表(创建,查询,修改,删除)4…...

HarmonyOS Next 属性动画和转场动画
HarmonyOS Next 属性动画和转场动画 在鸿蒙应用开发中,动画是提升用户体验的关键要素。通过巧妙运用动画,我们能让应用界面更加生动、交互更加流畅,从而吸引用户的注意力并增强其使用粘性。鸿蒙系统为开发者提供了丰富且强大的动画开发能力&…...

使用Node.js从零搭建DeepSeek本地部署(Express框架、Ollama)
目录 1.安装Node.js和npm2.初始化项目3.安装Ollama4.下载DeepSeek模型5.创建Node.js服务器6.运行服务器7.Web UI对话-Chrome插件-Page Assist 1.安装Node.js和npm 首先确保我们机器上已经安装了Node.js和npm。如果未安装,可以通过以下链接下载并安装适合我们操作系…...

Docker 部署 MongoDB 并持久化数据
Docker 部署 MongoDB 并持久化数据 在现代开发中,MongoDB 作为 NoSQL 数据库广泛应用,而 Docker 则提供了高效的容器化方案。本教程将介绍如何使用 Docker 快速部署 MongoDB,并实现数据持久化,确保数据不会因容器重启或删除而丢失…...

DeepSeek + 沉浸式翻译 打造智能翻译助手
本文详细介绍如何使用 DeepSeek API 沉浸式翻译插件打造个性化翻译助手。 一、DeepSeek API 配置 基础配置 API 基础地址:https://api.deepseek.com需要申请 API Key支持与 OpenAI SDK 兼容的调用方式 可用模型 deepseek-chat:已升级为 DeepSeek-V3&am…...

cdn取消接口缓存
添加cdn后,使用cdn加速域名访问接口 是缓存,不是最新的数据,如果使用局域网则是最新的数据,如果修改配置,确保使用cdn域名请求的接口返回不是缓存 要确保通过CDN加速域名访问接口时返回的是最新的数据,而不…...

字节跳动C++客户端开发实习生内推-抖音基础技术
智能手机爱好者和使用者,追求良好的用户体验; 具有良好的编程习惯,代码结构清晰,命名规范; 熟练掌握数据结构与算法、计算机网络、操作系统、编译原理等课程; 熟练掌握C/C/OC/Swift一种或多种语言ÿ…...

OpenHarmony子系统开发编译构建指导
OpenHarmony子系统开发编译构建指导 概述 OpenHarmony编译子系统是以GN和Ninja构建为基座,对构建和配置粒度进行部件化抽象、对内建模块进行功能增强、对业务模块进行功能扩展的系统,该系统提供以下基本功能: 以部件为最小粒度拼装产品和独…...

MySQL进阶-关联查询优化
采用左外连接 下面开始 EXPLAIN 分析 EXPLAIN SELECT SQL_NO_CACHE * FROM type LEFT JOIN book ON type.card book.card; 结论:type 有All ,代表着全表扫描,效率较差 添加索引优化 ALTER TABLE book ADD INDEX Y ( card); #【被驱动表】࿰…...

数据结构第六节:二叉搜索树(BST)的基本操作与实现
【本节要点】 二叉搜索树(BST)基本原理代码实现核心操作实现辅助函数测试代码完整代码 一、二叉搜索树(BST)基本原理与设计总结 注:基本原理的详细分析可以在数据结构第六节中查看,这里是简单描述。 二叉搜…...

在昇腾GPU上部署DeepSeek大模型与OpenWebUI:从零到生产的完整指南
引言 随着国产AI芯片的快速发展,昇腾(Ascend)系列GPU凭借其高性能和兼容性,逐渐成为大模型部署的重要选择。本文将以昇腾300i为例,手把手教你如何部署DeepSeek大模型,并搭配OpenWebUI构建交互式界面。无论…...

在window终端创建docker容器的问题
问题: 错误原因: PowerShell 换行符错误 PowerShell 中换行应使用反引号而非反斜杠 \,错误的换行符导致命令解析中断。 在 Windows 的 PowerShell 中运行 Docker 命令时遇到「sudo 无法识别」的问题,这是因为 Windows 系统原生不…...

掌握Kubernetes Network Policy,构建安全的容器网络
在 Kubernetes 集群中,默认情况下,所有 Pod 之间都是可以相互通信的,这在某些场景下可能会带来安全隐患。为了实现更精细的网络访问控制,Kubernetes 提供了 Network Policy 机制。Network Policy 允许我们定义一组规则,…...

ReAct论文阅读笔记总结
ReAct:Synergizing Reasoning and Acting in Language Models 背景 最近的研究结果暗示了在自主系统中结合语言推理与交互决策的可能性。 一方面,经过适当Prompt的大型语言模型(LLMs)已经展示了在算术、常识和符号推理任务中通…...

Linux云计算SRE-第十七周
1. 做三个节点的redis集群。 1、编辑redis节点node0(10.0.0.100)、node1(10.0.0.110)、node2(10.0.0.120)的安装脚本 [rootnode0 ~]# vim install_redis.sh#!/bin/bash # 指定脚本解释器为bashREDIS_VERSIONredis-7.2.7 # 定义Redis的版本号PASSWORD123456 # 设置Redis的访问…...

Python在数字货币交易中的算法设计:从策略到实践
Python在数字货币交易中的算法设计:从策略到实践 随着区块链技术的发展和加密货币市场的繁荣,数字货币交易已经成为金融领域的一个重要分支。从个体投资者到量化基金,算法交易(Algorithmic Trading)正在为提高交易效率和决策质量提供强大的支撑。在这些技术应用中,Pytho…...
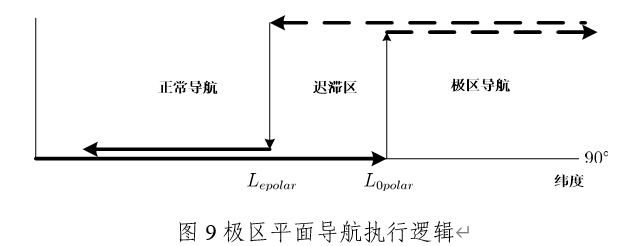
高纬度、跨极区导航技术
本文是何昆鹏老师所写,在此非常感谢何老师的分享。 全球导航,特别是极区导航,一直被美俄导航领域所关注。美俄本身部分国土就处于极区,很多战略军事部署与全球航线也都处于该区域,加之其战略军事任务也都强调全球覆盖…...

用AI学编程2——python学习1
一个py文件,学会所有python所有语法和特性,给出注释,给出这样的文件 Python 学习整合文件 """ Python 学习整合文件 包含 Python 的基础语法、数据结构、函数定义、面向对象编程、异常处理、文件操作、高级特性等内容 每个部…...

用数据唤醒深度好眠,时序数据库 TDengine 助力安提思脑科学研究
在智能医疗与脑科学快速发展的今天,高效的数据处理能力已成为突破创新的关键。安提思专注于睡眠监测与神经调控,基于人工智能和边缘计算,实现从生理体征监测、智能干预到效果评估的闭环。面对海量生理数据的存储与实时计算需求,安…...

Ubuntu下MySQL的安装与使用(一)
目录 用户切换 MySQL的安装 MySQL的初步使用 登录与退出 Linux和mysql中的普通用户和root用户 查看、创建与使用 简单应用 MySQL 数据库在 Linux 文件系统中的存储结构 数据库、数据库服务、数据库管理系统(宏观) 微观下的DBMS SQL语言及其分…...

抖音内容采集工具的技术创新与合规应用实践
抖音内容采集工具的技术创新与合规应用实践 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support. 抖音批量下载工具&…...

Python自动化脚本:从零构建《三国杀》钓鱼辅助
1. 环境准备:搭建自动化钓鱼的基石 想要实现《三国杀》钓鱼自动化,首先需要搭建一个稳定的开发环境。我推荐使用雷电模拟器9作为游戏运行平台,它不仅对Android游戏兼容性好,而且提供了丰富的调试功能。记得在安装时选择非vivo手机…...
)
【仅限头部金融科技团队内部流通】FastAPI 2.0 AI流式响应安全加固方案:防内存溢出、防连接耗尽、防Token泄露(含OWASP ASVS v4.0合规对照表)
第一章:FastAPI 2.0 AI流式响应安全加固方案全景概览FastAPI 2.0 引入了对 Server-Sent Events(SSE)与异步生成器的原生增强支持,使大语言模型(LLM)的流式响应(如 token-by-token 输出ÿ…...

Qwen3-ASR-1.7B效果展示:实测多语言语音识别,准确率超高
Qwen3-ASR-1.7B效果展示:实测多语言语音识别,准确率超高 1. 开篇:一款让人惊艳的语音识别模型 最近测试了Qwen3-ASR-1.7B这款语音识别模型,结果让我大吃一惊。作为一款中等规模的模型,它在多语言识别上的表现完全不输…...

windows 下使用 arthas 排查接口慢的问题
文章目录1、windows 如何安装 arthas2、在排查问题之前,先启动 arthas3、排查某个慢接口&方法4、更多功能参考官网文档1、windows 如何安装 arthas 进入 https://github.com/alibaba/arthas/releases,点击 arthas-bin.zip 进行下载。 解压下载完成后…...

2026年AI Agent将迎来爆发!这五大趋势将重塑企业未来,你准备好了吗?
2026年AI Agent将进入规模化部署阶段,应用渗透率将大幅提升。文章分析了五大核心趋势:多智能体协同、企业级部署规模化、行业垂直化、可信性与透明度提升,以及人机协作模式重构。同时,文章也提醒企业需警惕项目失败风险࿰…...

【等保三级Java安全加固实战指南】:20年专家亲授7大高危漏洞修复清单与合规落地路径
第一章:等保三级Java安全加固的合规基线与实施全景图等保三级对Java应用系统提出了覆盖身份鉴别、访问控制、安全审计、通信保密性、代码安全及运行环境防护等多维度强制性要求。其合规基线并非单一技术点的叠加,而是以《GB/T 22239-2019 信息安全技术 网…...

GB28181视频监控平台EasyCVR助力景区数字化转型,打造一体化视频监控解决方案
随着文旅行业数字化转型进程持续加速,旅游景区的安全管理、服务优化与运营效率提升已成为行业发展的核心诉求。景区场景普遍具有面积广阔、人员流动性强等特点,传统监控方案存在设备兼容性差、可视化管控能力不足等诸多短板,难以满足当前景区…...

OffscreenCanvas黑科技:让你的网页动画性能提升300%的配置指南
OffscreenCanvas黑科技:让你的网页动画性能提升300%的配置指南 当网页动画开始卡顿,用户的体验就会直线下降。传统Canvas渲染在主线程执行,复杂的图形运算很容易阻塞UI响应。OffscreenCanvas的出现彻底改变了这一局面——它允许你将绘制逻辑转…...

Vivado项目文件太多分不清?这份FPGA开发必备的‘文件后缀速查手册’请收好
Vivado项目文件管理终极指南:从后缀识别到高效工作流 当你第一次打开一个成熟的Vivado项目文件夹时,那种面对几十种陌生文件后缀的茫然感,相信每个FPGA开发者都记忆犹新。就像走进了一个满是神秘符号的仓库,每个文件似乎都在向你发…...