数据结构第六节:二叉搜索树(BST)的基本操作与实现

【本节要点】
- 二叉搜索树(BST)基本原理
- 代码实现
- 核心操作实现
- 辅助函数
- 测试代码
- 完整代码
一、二叉搜索树(BST)基本原理与设计总结
注:基本原理的详细分析可以在数据结构第六节中查看,这里是简单描述。
二叉搜索树(Binary Search Tree)是一种特殊的二叉树结构,具有以下核心性质:
有序性:每个节点的左子树所有节点值均小于当前节点值
递归结构:每个节点的右子树所有节点值均大于当前节点值
动态维护:通过插入和删除操作维护树的有序性
其时间复杂度特性为:在平衡状态下,插入、删除、查找操作的平均时间复杂度为O(log n);最坏情况下退化为链表结构,时间复杂度为O(n)
在这里本设计使用了两个版本来实现二叉搜索树:K版本和KV版本
K版本:
- 声明并定义命名空间 K。实现了 BSTree 类,这个类主要用于存储和操作单一的关键字(Key)。
- 每个节点包含一个键 _key,并且提供了插入(Insert)、查找(Find)和删除(Erase)等操作
- 主要用于简单的关键字搜索和管理。
KV版本:
- 实现了 BSTree 类,这个类用于存储和操作键值对(Key-Value Pair)。
- 每个节点包含一个键 _key 和一个值 _value,并且提供了插入键值对(Insert)、通过键查找节点(Find)等操作。
- 主要用于需要关联数据存储和检索的场景,例如统计单词出现次数、存储配置信息等。
同时本设计使用了两个版本来实现增删查改与遍历的操作:迭代版和递归版
设计思维导图:

二、代码实现
2.1 节点结构定义(K版本)
在实现二叉搜索树之前,首先需要定义树的结构。基本的二叉搜索树由节点组成,每个节点包含一个键值(Key)、一个指向左子节点的指针(Left)和一个指向右子节点的指针(Right)。
下面是二叉搜索树节点的定义示例:
template<class K>
struct BSTreeNode {BSTreeNode<K>* _left; // 左子树指针BSTreeNode<K>* _right; // 右子树指针K _key; // 存储的关键字BSTreeNode(const K& key) // 构造函数:_left(nullptr), _right(nullptr), _key(key){}
};2.2 类框架与成员函数(K版本)
二叉搜索树的操作主要通过
BSTree类来实现。该类包括树的根节点指针以及各种操作函数,如插入(Insert)、查找(Find)、删除(Erase)等。
下面是BSTree类的一个基本实现示例:
template<class K>
class BSTree {typedef BSTreeNode<K> Node;
public:核心接口 bool Insert(const K& key);bool Erase(const K& key);bool Find(const K& key);// 递归版本接口 //bool InsertR(const K& key);bool EraseR(const K& key);内部实现 void InOrder();~BSTree();
private:Node* _root = nullptr; // 根节点指针
};2.3 节点结构定义(KV版本)
核心特性:
双数据成员:
_key用于维护树结构,_value存储关联数据强类型约束:构造函数强制要求同时初始化键值对
指针类型:使用模板参数确保类型安全
// 定义支持键值对的二叉搜索树节点模板结构体
template<class K, class V>
struct BSTreeNode {BSTreeNode<K, V>* _left; // 左子树指针BSTreeNode<K, V>* _right; // 右子树指针K _key; // 键(用于排序和索引)V _value; // 值(关联的存储数据)// 构造函数(必须同时初始化键值对)BSTreeNode(const K& key, const V& value): _left(nullptr), _right(nullptr),_key(key),_value(value){}
};2.4 类框架与成员函数(KV版本)
成员函数详解:
插入操作:
参数:必须同时提供键和值
特性:保持二叉搜索树性质,键唯一
时间复杂度:O(h),h为树高度
查找操作:
返回值:节点指针(可直接修改关联的
_value)应用场景:字典查找、配置项修改
遍历操作:
输出格式:
key:value键值对形式遍历顺序:按键的中序(升序)排列
template<class K, class V>
class BSTree {typedef BSTreeNode<K, V> Node; // 类型别名定义
public:核心接口 // 插入键值对(迭代实现)bool Insert(const K& key, const V& value);// 查找键对应的节点(返回节点指针便于修改值)Node* Find(const K& key);// 中序遍历打印键值对void Inorder();private:内部实现 // 递归中序遍历实现void _Inorder(Node* root);// 根节点指针(私有维护树结构)Node* _root = nullptr;
};与K版本的关键差异:
| 特性 | K版本 | KV版本 |
|---|---|---|
| 节点数据 | 单一_key | _key + _value |
| 插入参数 | 单个键 | 键值对 |
| 查找返回值 | bool | 节点指针 |
| 应用场景 | 存在性检查 | 数据关联存储 |
| 构造函数要求 | 允许默认构造 | 必须显式初始化键值对 |
三、核心操作实现详解
3.1 插入操作(迭代版)
实现要点:
空树直接创建根节点
循环查找插入位置,维护parent指针
比较节点值决定插入方向
时间复杂度:O(h),h为树高度
bool Insert(const K& key) {if (_root == nullptr) { // 空树处理_root = new Node(key);return true;}Node* parent = nullptr;Node* cur = _root;while (cur) { // 搜索插入位置parent = cur;if (cur->_key < key) cur = cur->_right;else if (cur->_key > key) cur = cur->_left;else return false; // 已存在相同key}cur = new Node(key); // 创建新节点// 链接到父节点if (parent->_key < key) parent->_right = cur;else parent->_left = cur;return true;
}3.2 删除操作(迭代版)
删除策略:
单子树节点:直接提升子树
双子树节点:寻找右子树最小节点进行值替换
根节点处理:需要特殊处理根指针
bool Erase(const K& key){Node* parent = nullptr;Node* cur = _root;while (cur){if (cur->_key < key){parent = cur;cur = cur->_right;}else if (cur->_key > key){parent = cur;cur = cur->_left;}else{// 1、左为空// 2、右为空// 3、左右都不为空,替换删除if (cur->_left == nullptr){//if (parent == nullptr)if (cur == _root){_root = cur->_right;}else{if (parent->_left == cur){parent->_left = cur->_right;}else{parent->_right = cur->_right;}}delete cur;}else if (cur->_right == nullptr){//if (parent == nullptr)if (cur == _root){_root = cur->_left;}else{if (parent->_left == cur){parent->_left = cur->_left;}else{parent->_right = cur->_left;}}delete cur;}else{// 右子树的最小节点Node* parent = cur;Node* minRight = cur->_right;while (minRight->_left){parent = minRight;minRight = minRight->_left;}cur->_key = minRight->_key;if (minRight == parent->_left){parent->_left = minRight->_right;}else{parent->_right = minRight->_right;}delete minRight;}return true;}}return false;}3.3 查找操作(迭代版)
时间复杂度分析
情况 时间复杂度 说明 最佳情况 O(1) 目标节点为根节点 平均情况 O(log n) 树接近平衡时 最坏情况 O(n) 树退化为链表(如有序插入) 边界情况处理
空树处理:初始时
cur = nullptr,直接返回nullptr键不存在处理:循环自然结束返回
nullptr重复键处理:由于插入时禁止重复键,查找时不会遇到重复情况
// KV版本二叉搜索树的查找操作(迭代实现)
Node* Find(const K& key) {Node* cur = _root; // 从根节点开始搜索while (cur != nullptr) { // 当当前节点存在时循环if (key > cur->_key) { // 目标键大于当前节点键cur = cur->_right; // 转向右子树搜索} else if (key < cur->_key) { // 目标键小于当前节点键cur = cur->_left; // 转向左子树搜索}else { // 找到匹配键return cur; // 返回目标节点指针}}return nullptr; // 遍历结束未找到返回空指针
}3.4 增删查改(递归版)
// 插入(递归实现)
bool InsertR(const K& key)
{return _InsertR(_root, key);
}
// 删除(递归实现)
bool EraseR(const K& key)
{return _EraseR(_root, key);
}
// 查找(递归实现)
bool FindR(const K& key)
{return _EraseR(_root, key);
}递归与迭代实现对比
| 特性 | 递归实现 | 迭代实现 |
|---|---|---|
| 代码复杂度 | 简洁(约10行) | 复杂(需维护parent指针) |
| 空间效率 | O(h)栈空间 | O(1)额外空间 |
| 可读性 | 更符合算法逻辑 | 需要显式指针操作 |
| 栈溢出风险 | 树高度>1000时可能发生 | 无风险 |
四、辅助函数
4.1 中序遍历
中序遍历是一种遍历二叉树的方式,按照访问左子树——根节点——右子树的顺序进行。对于二叉搜索树,中序遍历会按照节点键值的升序访问所有节点,这是一种非常有用的遍历方式,因为它可以生成树的有序列表。
以下是中序遍历的递归实现代码:
// 中序遍历(递归实现) void InOrder() {_InOrder(_root);cout << endl;在这段代码中,
InOrder函数通过调用辅助函数_InOrder来实现递归遍历。_InOrder函数首先递归遍历左子树,然后打印当前节点的键值,最后递归遍历右子树。通过这种方式,可以按照从小到大的顺序打印树中的所有节点。
4.2 树的销毁与拷贝
销毁二叉搜索树是指释放树中所有节点占用的内存空间。销毁操作通常在二叉搜索树不再需要时调用,以确保不浪费内存资源。销毁操作可以通过递归实现,从根节点开始,先递归销毁左子树和右子树,然后再销毁根节点。
以下是销毁二叉搜索树的代码实现:
template<class K> void BSTree<K>::Destroy(BSTreeNode<K>* root) {if (root == nullptr) {return;}Destroy(root->_left);Destroy(root->_right);delete root; }在这段代码中,
Destroy函数通过递归调用自身,先销毁左子树,再销毁右子树,最后销毁根节点,从而释放整个树的内存空间。
拷贝二叉搜索树是指创建一个新的二叉搜索树,其结构与原树完全相同,节点的值也相同。拷贝操作通常在需要复制二叉搜索树时使用。拷贝操作同样可以通过递归实现,从根节点开始,先递归拷贝左子树和右子树,然后再创建新节点,并将其键值设置为原节点的键值。
以下是拷贝二叉搜索树的代码实现:
template<class K> BSTreeNode<K>* BSTree<K>::Copy(BSTreeNode<K>* root) {if (root == nullptr) {return nullptr;}BSTreeNode<K>* newRoot = new BSTreeNode<K>(root->_key);newRoot->_left = Copy(root->_left);newRoot->_right = Copy(root->_right);return newRoot; }在这段代码中,
Copy函数通过递归调用自身,先拷贝左子树,再拷贝右子树,最后创建新节点,并将其键值设置为原节点的键值,从而生成与原树结构相同的新树。
五、测试代码
5.1 基本功能验证(TestBSTree1)
void TestBSTree1() {int a[] = {8, 3, 1, 10, 6, 4, 7, 14, 13};K::BSTree<int> t;// 测试递归插入for (auto e : a) t.InsertR(e); t.InOrder(); // 输出:1 3 4 6 7 8 10 13 14// 测试拷贝构造函数K::BSTree<int> copyt(t);copyt.InOrder(); // 应与原树输出一致// 测试插入新键t.InsertR(9);t.InOrder(); // 新增9:1 3 4 6 7 8 9 10 13 14// 测试迭代删除t.Erase(14); // 删除叶子节点t.InOrder(); // 14消失// 测试递归删除t.EraseR(3); // 删除有子树的节点t.EraseR(8); // 删除根节点t.InOrder(); // 输出剩余节点// 清空树for (auto e : a) {t.EraseR(e); // 删除所有元素t.InOrder(); // 逐步输出删除过程}
}验证内容:
- 插入操作的递归实现正确性
- 拷贝构造函数实现深拷贝
- 混合使用迭代和递归删除的兼容性
- 树结构动态变化时的平衡性
- 析构函数内存释放验证(通过逐步删除)
输出结果:

5.2 字典应用(TestBSTree2)
void TestBSTree2() {KV::BSTree<string, string> dict;// 构建词典dict.Insert("sort", "排序");dict.Insert("string", "字符串");dict.Insert("left", "左边");dict.Insert("right", "右边");// 交互式查询string str;while (cin >> str) {auto* ret = dict.Find(str);if (ret) cout << ret->_value << endl;else cout << "无此单词" << endl;}
}操作示例:
输入:sort → 输出:排序
输入:apple → 输出:无此单词
输入:left → 输出:左边验证内容:
键值对插入的正确性
查找功能返回完整节点信息
交互式查询的稳定性
处理不存在键的鲁棒性
输出结果:

5.3 统计应用(TestBSTree3)
void TestBSTree3() {string arr[] = {"苹果", "西瓜", "香蕉", "草莓", "苹果", /*...*/};KV::BSTree<string, int> countTree;// 统计词频for (auto e : arr) {auto* ret = countTree.Find(e);if (ret) ret->_value++; // 存在则计数+1else countTree.Insert(e, 1); // 不存在则插入}countTree.Inorder(); // 按键升序输出统计结果
}预期输出:
苹果:7
草莓:1
西瓜:3
香蕉:3验证内容:
-
动态更新值的能力
-
统计逻辑的正确性
-
中序遍历的有序性
- 混合插入与查找的稳定性
输出结果:

六、完整代码
6.1 BSTree.h
#pragma once
#define _CRT_SECURE_NO_WARNINGS
#include<iostream>
using namespace std;
/*
* 声明并定义 命名空间 K
* 实现了 BSTree 类,这个类主要用于存储和操作单一的关键字(Key)。
* 每个节点包含一个键 _key,并且提供了插入(Insert)、查找(Find)和删除(Erase)等操作。
* 主要用于简单的关键字搜索和管理。
*/
namespace K
{// 定义二叉搜索树结点模板结构体 Ktemplate<class K>struct BSTreeNode{BSTreeNode<K>* _left; // 指针:左孩子BSTreeNode<K>* _right; // 指针:右孩子K _key; // 数据:存储该结点实际数据(单一的关键字)// 构建函数BSTreeNode(const K& key):_left(nullptr), _right(nullptr),_key(key){}};// 定义二叉搜索树模板类 Ktemplate<class K>class BSTree{// 使用Node作为二叉搜索树结点的别名typedef BSTreeNode<K> Node;public://K 结构体结点 需要默认构造函数,以便在没有提供关键字的情况下创建节点。一、默认成员函数// 1.1 构造函数BSTree():_root(nullptr){}// 1.2 拷贝构造BSTree(const BSTree<K>& t){_root = Copy(t._root);}// 1.3 操作符重载BSTree<K>& operator=(BSTree<K>& t){swap(_root, t._root);return *this;}// 1.4 析构函数~BSTree(){Destroy(_root);_root = nullptr;}二、二叉搜索树操作// 2.1 插入(迭代实现)// 根节点为空,创建新结点;键值已存在,返回false;键值不存在,找到合适位置插入新结点bool Insert(const K& key){if (_root == nullptr){_root = new Node(key);return true;}Node* parent = nullptr;Node* cur = _root;while (cur){// 找到插入的位置if (cur->_key < key){parent = cur;cur = cur->_right;}else if (cur->_key > key){parent = cur;cur = cur->_left;}else return false;}// 插入结点cur = new Node(key);if (parent->_key < key) parent->_right = cur;else parent->_left = cur;return true;}// 2.2 删除(迭代实现)bool Erase(const K& key){Node* parent = nullptr;Node* cur = _root;while (cur){if (cur->_key < key){parent = cur;cur = cur->_right;}else if (cur->_key > key){parent = cur;cur = cur->_left;}else{// 1、左为空// 2、右为空// 3、左右都不为空,替换删除if (cur->_left == nullptr){//if (parent == nullptr)if (cur == _root){_root = cur->_right;}else{if (parent->_left == cur){parent->_left = cur->_right;}else{parent->_right = cur->_right;}}delete cur;}else if (cur->_right == nullptr){//if (parent == nullptr)if (cur == _root){_root = cur->_left;}else{if (parent->_left == cur){parent->_left = cur->_left;}else{parent->_right = cur->_left;}}delete cur;}else{// 右子树的最小节点Node* parent = cur;Node* minRight = cur->_right;while (minRight->_left){parent = minRight;minRight = minRight->_left;}cur->_key = minRight->_key;if (minRight == parent->_left){parent->_left = minRight->_right;}else{parent->_right = minRight->_right;}delete minRight;}return true;}}return false;}// 2.3 查找(迭代实现)// 从根节点开始找,找到返回true,否则返回 falsebool Find(const K& key){Node* cur = _root;while (cur){if (cur->_key < key) cur = cur->_right;else if (cur->_key > key) cur = cur->_left;else return true;}return false;}// 2.4 中序遍历(递归实现)void InOrder(){_InOrder(_root);cout << endl;}// 2.5 插入(递归实现)bool InsertR(const K& key){return _InsertR(_root, key);}// 2.6 删除(递归实现)bool EraseR(const K& key){return _EraseR(_root, key);}// 2.7 查找(递归实现)bool FindR(const K& key){return _EraseR(_root, key);}private:三、二叉搜索树结点操作// 3.1 销毁结点void Destroy(Node* root){if (root == nullptr)return;Destroy(root->_left);Destroy(root->_right);delete root;}// 3.2 拷贝结点Node* Copy(Node* root){if (root == nullptr)return nullptr;Node* newRoot = new Node(root->_key);newRoot->_left = Copy(root->_left);newRoot->_right = Copy(root->_right);return newRoot;}// 3.3 删除结点bool _EraseR(Node*& root, const K& key){if (root == nullptr){return false;}if (root->_key < key){return _EraseR(root->_right, key);}else if (root->_key > key){return _EraseR(root->_left, key);}else{Node* del = root;if (root->_right == nullptr){root = root->_left;}else if (root->_left == nullptr){root = root->_right;}else{Node* minRight = root->_right;while (minRight->_left){minRight = minRight->_left;}swap(root->_key, minRight->_key);// 转换成在子树中去删除节点return _EraseR(root->_right, key);}delete del;return true;}}// 3.4 插入结点bool _InsertR(Node*& root, const K& key){if (root == nullptr){root = new Node(key);return true;}if (root->_key < key)return _InsertR(root->_right, key);else if (root->_key > key)return _InsertR(root->_left, key);elsereturn false;}// 3.5 查找结点bool _FindR(Node* root, const K& key){if (root == nullptr)return false;if (root->_key < key)return _FindR(root->_right, key);else if (root->_key > key)return _FindR(root->_left, key);elsereturn true;}// 3.6 中序遍历结点void _InOrder(Node* root){if (root == nullptr)return;_InOrder(root->_left);cout << root->_key << " ";_InOrder(root->_right);}private:Node* _root = nullptr;};}/*
* 实现了 BSTree 类,这个类用于存储和操作键值对(Key-Value Pair)。
*每个节点包含一个键 _key 和一个值 _value,并且提供了插入键值对(Insert)、通过键查找节点(Find)等操作。
*主要用于需要关联数据存储和检索的场景,例如统计单词出现次数、存储配置信息等。
*/namespace KV
{// 定义二叉搜索树结点模板结构体 KVtemplate<class K,class V>struct BSTreeNode{BSTreeNode<K, V>* _left;BSTreeNode<K, V>* _right;K _key; // 用于确定节点在二叉搜索树中的位置和排序,是树的索引和查找依据V _value; // 用于存储与 _key 相关的数据,提供额外的信息存储和检索能力// 构建函数BSTreeNode(const K& key,const V& value):_left(nullptr),_right(nullptr),_key(key),_value(value){}};/*这里KV不需要默认成员函数* KV 结构体结点 由于总是需要提供键值对来创建节点,因此不需要默认构造函数。* 在实际编程中,构造函数的目的是为了确保对象在创建时能够正确初始化其成员变量。*对于包含多个成员变量的类来说,如果没有提供所有成员变量的初始化参数,则需要默认构造函数来确保对象能够被正确创建。*/// 定义二叉搜索树模板类 KVtemplate<class K, class V>class BSTree{typedef BSTreeNode<K, V> Node;public:二叉搜索树操作// 插入bool Insert(const K& key, const V& value){if (_root == nullptr){_root = new Node(key, value);return true;}Node* parent = nullptr;Node* cur = _root;while (cur){if (cur->_key < key){parent = cur;cur = cur->_right;}else if (cur->_key > key){parent = cur;cur = cur->_left;}else{return false;}}cur = new Node(key, value);if (parent->_key < key){parent->_right = cur;}else{parent->_left = cur;}return true;}Node* Find(const K& key){Node* cur = _root;while (cur){if (cur->_key < key){cur = cur->_right;}else if (cur->_key > key){cur = cur->_left;}else{return cur;}}return nullptr;}void Inorder(){_Inorder(_root);}void _Inorder(Node* root){if (root == nullptr)return;_Inorder(root->_left);cout << root->_key << ":" << root->_value << endl;_Inorder(root->_right);}private:Node* _root = nullptr;};
}6.2 Test.cpp
#include "BSTree.h"
void TestBSTree1()
{int a[] = { 8, 3, 1, 10, 6, 4, 7, 14, 13 };K::BSTree<int> t;for (auto e : a){t.InsertR(e);}t.InOrder();K::BSTree<int> copyt(t);copyt.InOrder();t.InsertR(9);t.InOrder();t.Erase(14);t.InOrder();t.EraseR(3);t.InOrder();t.EraseR(8);t.InOrder();for (auto e : a){t.EraseR(e);t.InOrder();}
}void TestBSTree2()
{// 场景:检查单词拼写是否正确/车库出入系统/...//K::BSTree<string> dict;// Key/Value的搜索模型,通过Key查找或修改ValueKV::BSTree<string, string> dict;dict.Insert("sort", "排序");dict.Insert("string", "字符串");dict.Insert("left", "左边");dict.Insert("right", "右边");string str;while (cin >> str){KV::BSTreeNode<string, string>* ret = dict.Find(str);if (ret){cout << ret->_value << endl;}else{cout << "无此单词" << endl;}}
}void TestBSTree3()
{// 统计水果出现的次数string arr[] = { "苹果", "西瓜", "香蕉", "草莓","苹果", "西瓜", "苹果", "苹果", "西瓜", "苹果", "香蕉", "苹果", "香蕉" };KV::BSTree<string, int> countTree;for (auto e : arr){auto* ret = countTree.Find(e);if (ret == nullptr){countTree.Insert(e, 1);}else{ret->_value++;}}countTree.Inorder();
}
int main()
{TestBSTree3();return 0;
}以上就是关于二叉搜索树的设计总结,如果有发现问题的小伙伴,请在评论区说出来哦。后面还会持续更新C++相关知识,感兴趣请持续关注我哦!!


相关文章:
数据结构第六节:二叉搜索树(BST)的基本操作与实现
【本节要点】 二叉搜索树(BST)基本原理代码实现核心操作实现辅助函数测试代码完整代码 一、二叉搜索树(BST)基本原理与设计总结 注:基本原理的详细分析可以在数据结构第六节中查看,这里是简单描述。 二叉搜…...

在昇腾GPU上部署DeepSeek大模型与OpenWebUI:从零到生产的完整指南
引言 随着国产AI芯片的快速发展,昇腾(Ascend)系列GPU凭借其高性能和兼容性,逐渐成为大模型部署的重要选择。本文将以昇腾300i为例,手把手教你如何部署DeepSeek大模型,并搭配OpenWebUI构建交互式界面。无论…...

在window终端创建docker容器的问题
问题: 错误原因: PowerShell 换行符错误 PowerShell 中换行应使用反引号而非反斜杠 \,错误的换行符导致命令解析中断。 在 Windows 的 PowerShell 中运行 Docker 命令时遇到「sudo 无法识别」的问题,这是因为 Windows 系统原生不…...

掌握Kubernetes Network Policy,构建安全的容器网络
在 Kubernetes 集群中,默认情况下,所有 Pod 之间都是可以相互通信的,这在某些场景下可能会带来安全隐患。为了实现更精细的网络访问控制,Kubernetes 提供了 Network Policy 机制。Network Policy 允许我们定义一组规则,…...

ReAct论文阅读笔记总结
ReAct:Synergizing Reasoning and Acting in Language Models 背景 最近的研究结果暗示了在自主系统中结合语言推理与交互决策的可能性。 一方面,经过适当Prompt的大型语言模型(LLMs)已经展示了在算术、常识和符号推理任务中通…...

Linux云计算SRE-第十七周
1. 做三个节点的redis集群。 1、编辑redis节点node0(10.0.0.100)、node1(10.0.0.110)、node2(10.0.0.120)的安装脚本 [rootnode0 ~]# vim install_redis.sh#!/bin/bash # 指定脚本解释器为bashREDIS_VERSIONredis-7.2.7 # 定义Redis的版本号PASSWORD123456 # 设置Redis的访问…...

Python在数字货币交易中的算法设计:从策略到实践
Python在数字货币交易中的算法设计:从策略到实践 随着区块链技术的发展和加密货币市场的繁荣,数字货币交易已经成为金融领域的一个重要分支。从个体投资者到量化基金,算法交易(Algorithmic Trading)正在为提高交易效率和决策质量提供强大的支撑。在这些技术应用中,Pytho…...
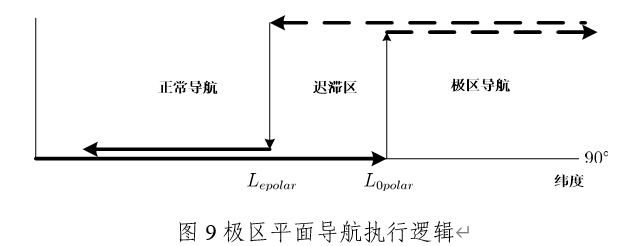
高纬度、跨极区导航技术
本文是何昆鹏老师所写,在此非常感谢何老师的分享。 全球导航,特别是极区导航,一直被美俄导航领域所关注。美俄本身部分国土就处于极区,很多战略军事部署与全球航线也都处于该区域,加之其战略军事任务也都强调全球覆盖…...

用AI学编程2——python学习1
一个py文件,学会所有python所有语法和特性,给出注释,给出这样的文件 Python 学习整合文件 """ Python 学习整合文件 包含 Python 的基础语法、数据结构、函数定义、面向对象编程、异常处理、文件操作、高级特性等内容 每个部…...

用数据唤醒深度好眠,时序数据库 TDengine 助力安提思脑科学研究
在智能医疗与脑科学快速发展的今天,高效的数据处理能力已成为突破创新的关键。安提思专注于睡眠监测与神经调控,基于人工智能和边缘计算,实现从生理体征监测、智能干预到效果评估的闭环。面对海量生理数据的存储与实时计算需求,安…...

Ubuntu下MySQL的安装与使用(一)
目录 用户切换 MySQL的安装 MySQL的初步使用 登录与退出 Linux和mysql中的普通用户和root用户 查看、创建与使用 简单应用 MySQL 数据库在 Linux 文件系统中的存储结构 数据库、数据库服务、数据库管理系统(宏观) 微观下的DBMS SQL语言及其分…...

步进电机软件细分算法解析与实践指南
1. 步进电机细分技术概述 步进电机是一种将电脉冲信号转换为角位移的执行机构,其基本运动单位为步距角。传统步进电机的步距角通常为 1.8(对应 200 步 / 转),但在高精度定位场景下,这种分辨率已无法满足需求。细分技术…...

pytorch retain_grad vs requires_grad
requires_grad大家都挺熟悉的,因此穿插在retain_grad的例子里进行捎带讲解就行。下面看一个代码片段: import torch# 创建一个标量 tensor,并开启梯度计算 x torch.tensor(2.0, requires_gradTrue)# 中间计算:y 依赖于 x&#x…...

RabbitMQ消息队列中间件安装部署教程(Windows)-2025最新版详细图文教程(附所需安装包)
目录 前言 一、安装Erlang环境 1、下载Erlang安装包 2、安装Erlang 3、设置环境变量 二、安装RabbitMQ环境 1、下载RabbitMQ安装包 2、安装RabbitMQ 3、设置环境变量 三、启动RabbitMQ 1、开启RabbitMQ管理插件 2、启动RabbitMQ 四、访问RabbitMQ 前言 RabbitMQ 是…...

vue-cli3+vue2+elementUI+avue升级到vite+vue3+elementPlus+avue总结
上一个新公司接手了一个vue-cli3vue2vue-router3.0elementUI2.15avue2.6的后台管理项目,因为vue2在2023年底已经不更新维护了,elementUI也只支持到vue2,然后总结了一下vue3的优势,最后批准升级成为了vitevue3vue-router4.5element…...

车载以太网测试-3【Wireshark介绍】
1 摘要 Wireshark 是一款开源的网络协议分析工具,广泛用于网络故障排查、协议分析、网络安全检测等领域。它能够捕获网络数据包,并以详细的、可读的格式显示这些数据包的内容。广泛应用于车载网络测试,是车载网络测试工程师必须掌握的工具。…...

扫雷雷雷雷雷雷雷
大家好啊,我是小象٩(๑ω๑)۶ 我的博客:Xiao Xiangζั͡ޓއއ 很高兴见到大家,希望能够和大家一起交流学习,共同进步。 这一节课我们不学习新的知识,我们来做一个扫雷小游戏 目录 扫雷小游戏概述一、扫雷游戏分析…...
)
图片分类实战:食物分类问题(含半监督)
食物分类问题 simple_class 1. 导入必要的库和模块 import random import torch import torch.nn as nn import numpy as np import os from PIL import Image #读取图片数据 from torch.utils.data import Dataset, DataLoader from tqdm import tqdm from torchvision impo…...

RuoYi框架添加自己的模块(学生管理系统CRUD)
RuoYi框架添加自己的模块(学生管理系统) 框架顺利运行 首先肯定要顺利运行框架了,这个我不多说了 设计数据库表 在ry数据库中添加表tb_student 表字段如图所示 如图所示 注意id字段是自增的 注释部分是后面成功后前端要展示的部分 导入…...

机器学习在地图制图学中的应用
原文链接:https://www.tandfonline.com/doi/full/10.1080/15230406.2023.2295948#abstract CSDN/2025/Machine learning in cartography.pdf at main keykeywu2048/CSDN GitHub 核心内容 本文是《制图学与地理信息科学》特刊的扩展评论,系统探讨了机…...

零基础新手会议记录,选购避坑指南 可直接上手
日常工作学习中,不少人会遇到会议纪要整理、访谈录音处理、讲座笔记记录的难题,手动整理耗时费力还易出错。本文评测了市面上主流录音转写工具,整理了新手避坑指南和实用选择建议,零基础也能快速上手。综合实测后,听脑…...

RK3506开发板PWM输入捕获配置与调试实战指南
1. 项目概述:在RK3506上搞定PWM输入捕获最近在做一个工业网关项目,需要精确测量外部传感器发来的PWM信号频率和占空比,核心板选型正好落在了触觉智能的RK3506开发板上。这块板子接口丰富,性能也够用,但上手调试PWM输入…...

Blender MMD插件终极指南:三步实现专业级MMD模型制作
Blender MMD插件终极指南:三步实现专业级MMD模型制作 【免费下载链接】blender_mmd_tools MMD Tools is a blender addon for importing/exporting Models and Motions of MikuMikuDance. 项目地址: https://gitcode.com/gh_mirrors/bl/blender_mmd_tools 想…...

OpenPnP贴片机新手避坑:从Allegro导出坐标文件到成功贴片,这5个细节决定成败
OpenPnP贴片机实战指南:从Allegro设计到精准贴片的5个关键控制点 引言 当PCB设计从图纸走向实体,贴片环节往往成为新手工程师的"滑铁卢"。我曾亲眼见证一个团队因为坐标文件导出时的0.5mm偏差,导致整批样板元件全部错位。这不是个例…...

基于Slack与AI的IDE智能助手:架构设计与实战部署
1. 项目概述:当你的IDE拥有了“光标智能体” 如果你是一名开发者,每天在IDE(集成开发环境)里敲代码的时间超过8小时,那你一定对这样的场景不陌生:光标在代码行间跳跃,你正试图理解一个复杂的函…...

LaTeX-PPT:3分钟学会在PowerPoint中快速插入专业数学公式的终极指南
LaTeX-PPT:3分钟学会在PowerPoint中快速插入专业数学公式的终极指南 【免费下载链接】latex-ppt Use LaTeX in PowerPoint 项目地址: https://gitcode.com/gh_mirrors/la/latex-ppt 你是否曾经在PowerPoint中为编辑复杂的数学公式而头疼?手动调整…...

纯文本CRM:用Markdown与Git构建极简客户关系管理系统
1. 项目概述与核心价值最近在开源社区里,我注意到一个名为anthroos/plaintext-crm的项目,它提出了一种非常规的客户关系管理(CRM)思路。简单来说,这个项目主张用纯文本文件(如 Markdown、TXT)来…...

基于AI宏观流动性监测框架的黄金三日连跌研究:美联储加息预期按兵不动后的市场重定价逻辑
摘要:本文通过AI宏观利率模型、美元流动性监测系统与黄金波动率因子分析,结合美通胀数据、美债收益率变化及市场利率预期重定价过程,分析黄金连续三日回落背后的核心驱动逻辑,并探讨当前“高利率持续”环境下黄金资产的阶段性压力…...

基于BLE与伺服电机的非侵入式墙壁开关遥控改造方案
1. 项目概述想给家里的老式墙壁灯开关加个遥控功能,但又不想碰那危险的220V强电线路?这个项目或许能给你一个既安全又有趣的解决方案。我最近用Adafruit的几块开发板,配合一个微型伺服电机和3D打印的支架,做了一个蓝牙遥控的机械式…...

Stardew Valley Mod开发:使用OpenClaw主题框架快速构建原生风格UI
1. 项目概述:一个为Stardew Valley Mod开发者量身打造的主题框架如果你是一位《星露谷物语》(Stardew Valley)的模组(Mod)开发者,或者正打算踏入这个充满创造力的社区,那么你很可能已经体会过&a…...