图片分类实战:食物分类问题(含半监督)
食物分类问题
simple_class
1. 导入必要的库和模块
import random
import torch
import torch.nn as nn
import numpy as np
import os
from PIL import Image #读取图片数据
from torch.utils.data import Dataset, DataLoader
from tqdm import tqdm
from torchvision import transforms
import time
import matplotlib.pyplot as plt
from model_utils.model import initialize_model
import random: 导入Python标准库中的随机数生成器。import torch: 导入PyTorch库,用于深度学习模型的构建和训练。import torch.nn as nn: 导入PyTorch的神经网络模块,包含各种层和损失函数。import numpy as np: 导入NumPy库,用于数值计算和数组操作。import os: 导入操作系统接口模块,用于文件路径处理。from PIL import Image: 导入PIL(Python Imaging Library)库,用于图像处理。from torch.utils.data import Dataset, DataLoader: 导入PyTorch的数据集和数据加载器类,用于管理数据集和批量加载数据。from tqdm import tqdm: 导入tqdm库,用于显示进度条。from torchvision import transforms: 导入PyTorch的图像变换模块,用于对图像进行预处理。import time: 导入时间模块,用于记录训练时间。import matplotlib.pyplot as plt: 导入matplotlib库,用于绘制图表。from model_utils.model import initialize_model: 导入自定义模块中的初始化模型函数。
2. 设置随机种子以确保结果可重复
def seed_everything(seed):torch.manual_seed(seed)torch.cuda.manual_seed(seed)torch.cuda.manual_seed_all(seed)torch.backends.cudnn.benchmark = Falsetorch.backends.cudnn.deterministic = Truerandom.seed(seed)np.random.seed(seed)os.environ['PYTHONHASHSEED'] = str(seed)seed_everything(0)
def seed_everything(seed):: 定义一个函数seed_everything,用于设置所有可能影响随机性的种子。torch.manual_seed(seed): 设置PyTorch的CPU随机种子。torch.cuda.manual_seed(seed): 设置PyTorch的GPU随机种子。torch.cuda.manual_seed_all(seed): 如果有多个GPU,设置所有GPU的随机种子。torch.backends.cudnn.benchmark = False: 关闭CuDNN自动优化功能,确保每次运行的结果一致。torch.backends.cudnn.deterministic = True: 设置CuDNN为确定性模式,确保结果可重复。random.seed(seed): 设置Python内置随机数生成器的种子。np.random.seed(seed): 设置NumPy的随机数生成器的种子。os.environ['PYTHONHASHSEED'] = str(seed): 设置环境变量PYTHONHASHSEED,确保哈希值的一致性。seed_everything(0): 调用seed_everything函数,设置全局随机种子为0。
3. 定义图像变换
HW = 224train_transform = transforms.Compose([transforms.ToPILImage(), # 将numpy.ndarray转换为PIL.Imagetransforms.RandomResizedCrop(224), # 随机裁剪并调整大小到224x224transforms.RandomRotation(50), # 随机旋转角度在[-50, 50]之间transforms.ToTensor() # 将PIL.Image转换为tensor]
)val_transform = transforms.Compose([transforms.ToPILImage(), # 将numpy.ndarray转换为PIL.Imagetransforms.ToTensor() # 将PIL.Image转换为tensor]
)
HW = 224: 定义图像的高度和宽度为224像素。train_transform: 定义训练集的图像变换组合:transforms.ToPILImage(): 将输入的numpy数组转换为PIL图像格式。transforms.RandomResizedCrop(224): 随机裁剪并调整大小到224x224像素。transforms.RandomRotation(50): 随机旋转图像,角度范围在[-50, 50]度之间。transforms.ToTensor(): 将PIL图像转换为PyTorch张量(tensor),并将像素值归一化到[0, 1]区间。
val_transform: 定义验证集的图像变换组合:transforms.ToPILImage(): 将输入的numpy数组转换为PIL图像格式。transforms.ToTensor(): 将PIL图像转换为PyTorch张量(tensor),并将像素值归一化到[0, 1]区间。
4. 自定义数据集类
class food_Dataset(Dataset):def __init__(self, path, mode="train"):self.mode = modeif mode == "semi":self.X = self.read_file(path)else:self.X, self.Y = self.read_file(path)self.Y = torch.LongTensor(self.Y) # 标签转为长整形if mode == "train":self.transform = train_transformelse:self.transform = val_transformdef read_file(self, path):if self.mode == "semi":file_list = os.listdir(path)xi = np.zeros((len(file_list), HW, HW, 3), dtype=np.uint8)for j, img_name in enumerate(file_list):img_path = os.path.join(path, img_name)img = Image.open(img_path)img = img.resize((HW, HW))xi[j, ...] = np.array(img)print("读到了%d个数据" % len(xi))return xielse:for i in tqdm(range(11)):file_dir = path + "/%02d" % ifile_list = os.listdir(file_dir)xi = np.zeros((len(file_list), HW, HW, 3), dtype=np.uint8)yi = np.zeros(len(file_list), dtype=np.uint8)for j, img_name in enumerate(file_list):img_path = os.path.join(file_dir, img_name)img = Image.open(img_path)img = img.resize((HW, HW))xi[j, ...] = np.array(img)yi[j] = iif i == 0:X = xiY = yielse:X = np.concatenate((X, xi), axis=0)Y = np.concatenate((Y, yi), axis=0)print("读到了%d个数据" % len(Y))return X, Ydef __getitem__(self, item):if self.mode == "semi":return self.transform(self.X[item]), self.X[item]else:return self.transform(self.X[item]), self.Y[item]def __len__(self):return len(self.X)
class food_Dataset(Dataset):: 定义一个继承自Dataset的自定义数据集类food_Dataset。def __init__(self, path, mode="train"):: 初始化方法,接受数据集路径和模式(默认为“train”)作为参数。self.mode = mode: 记录数据集的模式。if mode == "semi":: 如果是半监督模式,则仅读取未标记的图像数据。else:: 否则,读取带有标签的图像数据,并将标签转换为长整型。if mode == "train":: 如果是训练模式,使用train_transform进行图像变换。else:: 否则,使用val_transform进行图像变换。
def read_file(self, path):: 定义一个读取文件的方法,根据不同的模式读取图像数据。if self.mode == "semi":: 如果是半监督模式,读取未标记的图像数据:file_list = os.listdir(path): 获取目录下的所有文件名。xi = np.zeros((len(file_list), HW, HW, 3), dtype=np.uint8): 创建一个零数组用于存储图像数据。for j, img_name in enumerate(file_list):: 遍历每个文件名,打开图像并调整大小,然后将其存储在xi中。print("读到了%d个数据" % len(xi)): 打印读取到的图像数量。return xi: 返回图像数据。
else:: 否则,读取带有标签的图像数据:for i in tqdm(range(11)):: 使用tqdm显示进度条,遍历每个类别(假设共有11个类别)。file_dir = path + "/%02d" % i: 构建类别目录路径。file_list = os.listdir(file_dir): 获取该类别目录下的所有文件名。xi = np.zeros((len(file_list), HW, HW, 3), dtype=np.uint8): 创建一个零数组用于存储图像数据。yi = np.zeros(len(file_list), dtype=np.uint8): 创建一个零数组用于存储标签。for j, img_name in enumerate(file_list):: 遍历每个文件名,打开图像并调整大小,然后将其存储在xi中,并将对应的标签存储在yi中。if i == 0:: 如果是第一个类别,初始化X和Y。else:: 否则,将当前类别的图像和标签连接到已有数据中。print("读到了%d个数据" % len(Y)): 打印读取到的图像数量。return X, Y: 返回图像数据和标签。
def __getitem__(self, item):: 定义获取指定索引的数据项的方法。if self.mode == "semi":: 如果是半监督模式,返回变换后的图像及其原始图像。else:: 否则,返回变换后的图像及其标签。
def __len__(self):: 定义返回数据集长度的方法,即图像的数量。
5. 半监督数据集类
class semiDataset(Dataset):def __init__(self, no_label_loader, model, device, thres=0.99):x, y = self.get_label(no_label_loader, model, device, thres)if x == []:self.flag = Falseelse:self.flag = Trueself.X = np.array(x)self.Y = torch.LongTensor(y)self.transform = train_transformdef get_label(self, no_label_loader, model, device, thres):model = model.to(device)pred_prob = []labels = []x = []y = []soft = nn.Softmax(dim=1)with torch.no_grad():for bat_x, _ in no_label_loader:bat_x = bat_x.to(device)pred = model(bat_x)pred_soft = soft(pred)pred_max, pred_value = pred_soft.max(1)pred_prob.extend(pred_max.cpu().numpy().tolist())labels.extend(pred_value.cpu().numpy().tolist())for index, prob in enumerate(pred_prob):if prob > thres:x.append(no_label_loader.dataset[index][0])y.append(labels[index])return x, ydef __getitem__(self, item):return self.transform(self.X[item]), self.Y[item]def __len__(self):return len(self.X)
class semiDataset(Dataset):: 定义一个继承自Dataset的半监督数据集类semiDataset。def __init__(self, no_label_loader, model, device, thres=0.99):: 初始化方法,接受未标记数据加载器、模型、设备和置信度阈值作为参数。x, y = self.get_label(no_label_loader, model, device, thres): 调用get_label方法获取高置信度的伪标签样本。if x == []:: 如果没有找到符合条件的样本,设置flag为False。else:: 否则,设置flag为True,并将样本数据和标签存储在self.X和self.Y中,并使用train_transform进行图像变换。
def get_label(self, no_label_loader, model, device, thres):: 定义一个获取伪标签的方法。model = model.to(device): 将模型移动到指定设备(CPU或GPU)。pred_prob = []: 初始化预测概率列表。labels = []: 初始化标签列表。x = []: 初始化图像数据列表。y = []: 初始化标签列表。soft = nn.Softmax(dim=1): 初始化Softmax函数,用于将模型输出转换为概率分布。with torch.no_grad():: 禁用梯度计算,减少内存占用和加速推理。for bat_x, _ in no_label_loader:: 遍历未标记数据加载器中的每个批次。bat_x = bat_x.to(device): 将输入数据移动到指定设备。pred = model(bat_x): 使用模型进行前向传播,得到预测结果。pred_soft = soft(pred): 使用Softmax函数将预测结果转换为概率分布。pred_max, pred_value = pred_soft.max(1): 获取每个样本的最大概率及其对应的类别。pred_prob.extend(pred_max.cpu().numpy().tolist()): 将最大概率值添加到pred_prob列表中。labels.extend(pred_value.cpu().numpy().tolist()): 将对应的类别标签添加到labels列表中。
for index, prob in enumerate(pred_prob):: 遍历每个样本的概率值。if prob > thres:: 如果概率值大于设定的阈值,则认为该样本的预测结果是可靠的。x.append(no_label_loader.dataset[index][0]): 将该样本的图像数据添加到x列表中。y.append(labels[index]): 将该样本的预测标签添加到y列表中。
return x, y: 返回筛选出的图像数据和标签。
def __getitem__(self, item):: 定义获取指定索引的数据项的方法,返回变换后的图像及其标签。def __len__(self):: 定义返回数据集长度的方法,即图像的数量。
明白了,我们将从“6. 获取半监督数据加载器”继续逐句分析代码,并保持详细的解释风格。
6. 获取半监督数据加载器
def get_semi_loader(no_label_loder, model, device, thres):semiset = semiDataset(no_label_loder, model, device, thres)if semiset.flag == False:return Noneelse:semi_loader = DataLoader(semiset, batch_size=16, shuffle=False)return semi_loader
- get_semi_loader:定义了一个函数,用于创建包含伪标签样本的数据加载器。
- no_label_loder:未标记数据的加载器。
- model:当前训练的模型,用于对未标记数据进行预测。
- device:设备类型(CPU或GPU)。
- thres:置信度阈值,用于选择高置信度样本。
- semiset:使用
semiDataset类创建一个包含伪标签样本的数据集对象。 - if semiset.flag == False:如果
semiDataset对象中没有满足条件的样本,则返回None。 - else:否则,使用
DataLoader创建一个新的数据加载器semi_loader,批次大小为16且不打乱数据。
明白了,让我们重新详细解析 myModel 类的定义部分,并继续进入训练和验证函数的解析。
7. 定义模型
class myModel(nn.Module):def __init__(self, num_class):super(myModel, self).__init__()self.conv1 = nn.Conv2d(3, 64, 3, 1, 1)self.bn1 = nn.BatchNorm2d(64)self.relu = nn.ReLU()self.pool1 = nn.MaxPool2d(2)self.layer1 = nn.Sequential(nn.Conv2d(64, 128, 3, 1, 1),nn.BatchNorm2d(128),nn.ReLU(),nn.MaxPool2d(2))self.layer2 = nn.Sequential(nn.Conv2d(128, 256, 3, 1, 1),nn.BatchNorm2d(256),nn.ReLU(),nn.MaxPool2d(2))self.layer3 = nn.Sequential(nn.Conv2d(256, 512, 3, 1, 1),nn.BatchNorm2d(512),nn.ReLU(),nn.MaxPool2d(2))self.pool2 = nn.MaxPool2d(2)self.fc1 = nn.Linear(25088, 1000)self.relu2 = nn.ReLU()self.fc2 = nn.Linear(1000, num_class)def forward(self, x):x = self.conv1(x)x = self.bn1(x)x = self.relu(x)x = self.pool1(x)x = self.layer1(x)x = self.layer2(x)x = self.layer3(x)x = self.pool2(x)x = x.view(x.size()[0], -1)x = self.fc1(x)x = self.relu2(x)x = self.fc2(x)return x
__init__ 方法
- super(myModel, self).init():调用父类
nn.Module的构造函数。 - self.conv1:定义第一个卷积层,输入通道数为3(RGB图像),输出通道数为64,卷积核大小为3x3,步长为1,填充为1。
- self.bn1:定义第一个批量归一化层,用于归一化卷积层的输出。
- self.relu:定义ReLU激活函数。
- self.pool1:定义第一个最大池化层,池化窗口大小为2x2。
- self.layer1:定义第一个卷积块,包含一个卷积层、批量归一化层、ReLU激活函数和最大池化层。卷积层将输入通道数从64变为128。
- self.layer2:定义第二个卷积块,与
layer1类似,但将输入通道数从128变为256。 - self.layer3:定义第三个卷积块,与
layer2类似,但将输入通道数从256变为512。 - self.pool2:定义第二个最大池化层,池化窗口大小为2x2。
- self.fc1:定义第一个全连接层,输入特征数为25088(经过前面的卷积和池化操作后的特征图大小),输出特征数为1000。
- self.relu2:定义第二个ReLU激活函数。
- self.fc2:定义第二个全连接层,输入特征数为1000,输出特征数为
num_class(类别数量)。
forward 方法
- def forward(self, x):定义前向传播过程。
- x = self.conv1(x):对输入数据
x进行第一次卷积操作。 - x = self.bn1(x):对卷积结果进行批量归一化。
- x = self.relu(x):应用ReLU激活函数。
- x = self.pool1(x):对激活结果进行最大池化操作。
- x = self.layer1(x):通过第一个卷积块。
- x = self.layer2(x):通过第二个卷积块。
- x = self.layer3(x):通过第三个卷积块。
- x = self.pool2(x):对第三个卷积块的结果进行最大池化操作。
- x = x.view(x.size()[0], -1):将多维张量展平成二维张量,以便输入到全连接层中。
- x = self.fc1(x):通过第一个全连接层。
- x = self.relu2(x):应用ReLU激活函数。
- x = self.fc2(x):通过第二个全连接层,输出最终预测结果。
- return x:返回模型的预测结果。
- x = self.conv1(x):对输入数据
8. 训练和验证函数
接下来我们继续解析 train_val 函数:
def train_val(model, train_loader, val_loader, no_label_loader, device, epochs, optimizer, loss, thres, save_path):model = model.to(device)semi_loader = Noneplt_train_loss = []plt_val_loss = []plt_train_acc = []plt_val_acc = []max_acc = 0.0for epoch in range(epochs):train_loss = 0.0val_loss = 0.0train_acc = 0.0val_acc = 0.0start_time = time.time()
初始化部分
- model = model.to(device):将模型移动到指定设备(CPU或GPU)。
- semi_loader = None:初始化半监督数据加载器为
None。 - plt_train_loss、plt_val_loss、plt_train_acc、plt_val_acc:分别存储训练和验证的损失及准确率。
- max_acc = 0.0:初始化最大验证准确率为0.0。
每个epoch的训练循环
for epoch in range(epochs):train_loss = 0.0val_loss = 0.0train_acc = 0.0val_acc = 0.0start_time = time.time()model.train()for batch_x, batch_y in train_loader:x, target = batch_x.to(device), batch_y.to(device)pred = model(x)train_bat_loss = loss(pred, target)train_bat_loss.backward()optimizer.step()optimizer.zero_grad()train_loss += train_bat_loss.cpu().item()train_acc += np.sum(np.argmax(pred.detach().cpu().numpy(), axis=1) == target.cpu().numpy())
- for epoch in range(epochs):遍历每个epoch。
- train_loss = 0.0、val_loss = 0.0、train_acc = 0.0、val_acc = 0.0:初始化每个epoch的损失和准确率。
- start_time = time.time():记录当前epoch的开始时间。
- model.train():设置模型为训练模式。
- for batch_x, batch_y in train_loader:遍历训练数据加载器中的每个批次。
- x, target = batch_x.to(device), batch_y.to(device):将输入数据和标签移动到指定设备。
- pred = model(x):前向传播,计算模型输出。
- train_bat_loss = loss(pred, target):计算批次损失。
- train_bat_loss.backward():反向传播,计算梯度。
- optimizer.step():更新模型参数。
- optimizer.zero_grad():清空梯度,避免累积。
- train_loss += train_bat_loss.cpu().item():累加批次损失。
- train_acc += np.sum(np.argmax(pred.detach().cpu().numpy(), axis=1) == target.cpu().numpy()):计算并累加批次准确率。
处理半监督数据
if semi_loader is not None:for batch_x, batch_y in semi_loader:x, target = batch_x.to(device), batch_y.to(device)pred = model(x)semi_bat_loss = loss(pred, target)semi_bat_loss.backward()optimizer.step()optimizer.zero_grad()train_loss += semi_bat_loss.cpu().item()train_acc += np.sum(np.argmax(pred.detach().cpu().numpy(), axis=1) == target.cpu().numpy())print("半监督数据集的训练准确率为", train_acc / len(semi_loader.dataset))
- if semi_loader is not None:如果存在半监督数据加载器,则处理这些数据。
- for batch_x, batch_y in semi_loader:遍历半监督数据加载器中的每个批次。
- x, target = batch_x.to(device), batch_y.to(device):将输入数据和标签移动到指定设备。
- pred = model(x):前向传播,计算模型输出。
- semi_bat_loss = loss(pred, target):计算批次损失。
- semi_bat_loss.backward():反向传播,计算梯度。
- optimizer.step():更新模型参数。
- optimizer.zero_grad():清空梯度,避免累积。
- train_loss += semi_bat_loss.cpu().item():累加批次损失。
- train_acc += np.sum(np.argmax(pred.detach().cpu().numpy(), axis=1) == target.cpu().numpy()):计算并累加批次准确率。
- print(“半监督数据集的训练准确率为”, train_acc / len(semi_loader.dataset)):打印半监督数据集的训练准确率。
验证过程
model.eval()
with torch.no_grad():for batch_x, batch_y in val_loader:x, target = batch_x.to(device), batch_y.to(device)pred = model(x)val_bat_loss = loss(pred, target)val_loss += val_bat_loss.cpu().item()val_acc += np.sum(np.argmax(pred.detach().cpu().numpy(), axis=1) == target.cpu().numpy())
- model.eval():设置模型为评估模式。
- with torch.no_grad():禁用梯度计算,节省内存和计算资源。
- for batch_x, batch_y in val_loader:遍历验证数据加载器中的每个批次。
- x, target = batch_x.to(device), batch_y.to(device):将输入数据和标签移动到指定设备。
- pred = model(x):前向传播,计算模型输出。
- val_bat_loss = loss(pred, target):计算批次损失。
- val_loss += val_bat_loss.cpu().item():累加批次损失。
- val_acc += np.sum(np.argmax(pred.detach().cpu().numpy(), axis=1) == target.cpu().numpy()):计算并累加批次准确率。
更新半监督数据加载器和保存最佳模型
if epoch % 3 == 0 and plt_val_acc[-1] > 0.6:semi_loader = get_semi_loader(no_label_loader, model, device, thres)if val_acc / len(val_loader.dataset) > max_acc:torch.save(model, save_path)max_acc = val_acc / len(val_loader.dataset)
- if epoch % 3 == 0 and plt_val_acc[-1] > 0.6:每3个epoch检查一次是否需要更新半监督数据加载器。
- semi_loader = get_semi_loader(no_label_loader, model, device, thres):调用
get_semi_loader函数获取新的半监督数据加载器。
- semi_loader = get_semi_loader(no_label_loader, model, device, thres):调用
- if val_acc / len(val_loader.dataset) > max_acc:如果当前验证准确率高于历史最高,则保存当前模型。
- torch.save(model, save_path):保存模型到指定路径。
- max_acc = val_acc / len(val_loader.dataset):更新最大验证准确率。
打印训练结果
print('[%03d/%03d] %2.2f sec(s) TrainLoss : %.6f | valLoss: %.6f Trainacc : %.6f | valacc: %.6f' % \(epoch, epochs, time.time() - start_time, plt_train_loss[-1], plt_val_loss[-1], plt_train_acc[-1], plt_val_acc[-1]))
- print:打印每个epoch的训练和验证结果,包括epoch编号、耗时、训练损失、验证损失、训练准确率和验证准确率。
9、绘制损失和准确率曲线
plt.plot(plt_train_loss)
plt.plot(plt_val_loss)
plt.title("loss")
plt.legend(["train", "val"])
plt.show()plt.plot(plt_train_acc)
plt.plot(plt_val_acc)
plt.title("acc")
plt.legend(["train", "val"])
plt.show()
- plt.plot(plt_train_loss) 和 plt.plot(plt_val_loss):绘制训练和验证的损失变化曲线。
- plt.title(“loss”):设置图表标题为“loss”。
- plt.legend([“train”, “val”]):添加图例,区分训练和验证曲线。
- plt.show():显示图表。
- plt.plot(plt_train_acc) 和 plt.plot(plt_val_acc):绘制训练和验证的准确率变化曲线。
- plt.title(“acc”):设置图表标题为“acc”。
- plt.legend([“train”, “val”]):添加图例,区分训练和验证曲线。
- plt.show():显示图表。
好的,让我们详细解析你提供的代码段,并解释每个部分的功能和作用。
10、数据集路径设置与数据加载器初始化
train_path = r"F:\pycharm\beike\classification\food_classification\food-11_sample\training\labeled"
val_path = r"F:\pycharm\beike\classification\food_classification\food-11_sample\validation"
no_label_path = r"F:\pycharm\beike\classification\food_classification\food-11_sample\training\unlabeled\00"train_set = food_Dataset(train_path, "train")
val_set = food_Dataset(val_path, "val")
no_label_set = food_Dataset(no_label_path, "semi")train_loader = DataLoader(train_set, batch_size=16, shuffle=True)
val_loader = DataLoader(val_set, batch_size=16, shuffle=True)
no_label_loader = DataLoader(no_label_set, batch_size=16, shuffle=False)
- train_path、val_path 和 no_label_path:定义了训练集、验证集和未标记数据集的路径。
- food_Dataset:自定义的数据集类,用于加载和预处理图像数据。它接受路径和模式(“train”、“val” 或 “semi”)作为参数。
- train_set:创建一个训练数据集对象。
- val_set:创建一个验证数据集对象。
- no_label_set:创建一个未标记数据集对象。
- DataLoader:PyTorch中的数据加载器类,用于批量加载数据。
- train_loader:训练数据加载器,批次大小为16,且打乱数据。
- val_loader:验证数据加载器,批次大小为16,且打乱数据。
- no_label_loader:未标记数据加载器,批次大小为16,不打乱数据。
11、模型初始化
# model = myModel(11)
model, _ = initialize_model("vgg", 11, use_pretrained=True)
- myModel(11):注释掉的行表示使用自定义模型
myModel,类别数为11。 - initialize_model(“vgg”, 11, use_pretrained=True):调用一个函数来初始化预训练的VGG模型,类别数为11,并使用预训练权重。
12、超参数设置
lr = 0.001
loss = nn.CrossEntropyLoss()
optimizer = torch.optim.AdamW(model.parameters(), lr=lr, weight_decay=1e-4)
device = "cuda" if torch.cuda.is_available() else "cpu"
save_path = "model_save/best_model.pth"
epochs = 15
thres = 0.99
- lr:学习率设置为0.001。
- loss:损失函数使用交叉熵损失
nn.CrossEntropyLoss()。 - optimizer:优化器使用AdamW优化器
torch.optim.AdamW,并设置了学习率和权重衰减参数。 - device:检查是否有可用的GPU,如果没有则使用CPU。
- save_path:保存最佳模型的路径。
- epochs:训练轮数设置为15。
- thres:置信度阈值设置为0.99,用于半监督学习中选择高置信度样本。
13、训练和验证
train_val(model, train_loader, val_loader, no_label_loader, device, epochs, optimizer, loss, thres, save_path)
- train_val:调用训练和验证函数,传入模型、数据加载器、设备类型、训练轮数、优化器、损失函数、置信度阈值和保存路径。
数据集加载
train_set = food_Dataset(train_path, "train")
val_set = food_Dataset(val_path, "val")
no_label_set = food_Dataset(no_label_path, "semi")train_loader = DataLoader(train_set, batch_size=16, shuffle=True)
val_loader = DataLoader(val_set, batch_size=16, shuffle=True)
no_label_loader = DataLoader(no_label_set, batch_size=16, shuffle=False)
- food_Dataset:假设这是一个自定义的数据集类,负责读取和预处理图像数据。
- DataLoader:用于高效加载数据,支持多线程和批处理。
模型初始化
model, _ = initialize_model("vgg", 11, use_pretrained=True)
- initialize_model:假设这是另一个自定义函数,用于初始化预训练的VGG模型,并根据需要调整输出层以适应11个分类任务。
超参数配置
lr = 0.001
loss = nn.CrossEntropyLoss()
optimizer = torch.optim.AdamW(model.parameters(), lr=lr, weight_decay=1e-4)
device = "cuda" if torch.cuda.is_available() else "cpu"
save_path = "model_save/best_model.pth"
epochs = 15
thres = 0.99
- lr:学习率设置为0.001。
- loss:使用交叉熵损失函数,适用于多分类问题。
- optimizer:使用AdamW优化器,结合了Adam的优点并添加了权重衰减,有助于防止过拟合。
- device:自动检测并选择合适的计算设备(GPU或CPU)。
- save_path:指定保存最佳模型的文件路径。
- epochs:训练轮数设置为15。
- thres:置信度阈值设置为0.99,用于筛选高质量伪标签样本。
调用训练和验证函数
train_val(model, train_loader, val_loader, no_label_loader, device, epochs, optimizer, loss, thres, save_path)
- train_val:假设这是一个包含训练和验证逻辑的函数,负责在给定的训练轮数内迭代地训练模型,并在每个epoch结束后进行验证。
总结
这段代码实现了从数据集加载到模型训练和验证的完整流程,具体步骤包括:
- 数据集加载:通过自定义的
food_Dataset类加载训练、验证和未标记数据集,并使用DataLoader进行批处理和数据打乱。 - 模型初始化:使用预训练的VGG模型,并根据任务需求调整输出层。
- 超参数配置:设置学习率、损失函数、优化器等超参数,并确定训练轮数和设备类型。
- 训练和验证:调用
train_val函数执行训练过程,并在每个epoch结束后进行验证,保存最佳模型。
相关文章:
)
图片分类实战:食物分类问题(含半监督)
食物分类问题 simple_class 1. 导入必要的库和模块 import random import torch import torch.nn as nn import numpy as np import os from PIL import Image #读取图片数据 from torch.utils.data import Dataset, DataLoader from tqdm import tqdm from torchvision impo…...

RuoYi框架添加自己的模块(学生管理系统CRUD)
RuoYi框架添加自己的模块(学生管理系统) 框架顺利运行 首先肯定要顺利运行框架了,这个我不多说了 设计数据库表 在ry数据库中添加表tb_student 表字段如图所示 如图所示 注意id字段是自增的 注释部分是后面成功后前端要展示的部分 导入…...

机器学习在地图制图学中的应用
原文链接:https://www.tandfonline.com/doi/full/10.1080/15230406.2023.2295948#abstract CSDN/2025/Machine learning in cartography.pdf at main keykeywu2048/CSDN GitHub 核心内容 本文是《制图学与地理信息科学》特刊的扩展评论,系统探讨了机…...
)
【JAVA架构师成长之路】【电商系统实战】第9集:订单超时关闭实战(Kafka延时队列 + 定时任务补偿)
30分钟课程:订单超时关闭实战(Kafka延时队列 定时任务补偿) 课程目标 理解订单超时关闭的业务场景与核心需求。掌握基于 Kafka 延时队列与定时任务的关单方案设计。实现高并发场景下的可靠关单逻辑(防重复、幂等性)。…...

《探秘课程蒸馏体系“三阶训练法”:解锁知识层级递进式迁移的密码》
在人工智能与教育科技深度融合的时代,如何高效地实现知识传递与能力提升,成为众多学者、教育工作者以及技术专家共同探索的课题。课程蒸馏体系中的“三阶训练法”,作为一种创新的知识迁移模式,正逐渐崭露头角,为解决这…...
Pod)
K8s 1.27.1 实战系列(六)Pod
一、Pod介绍 1、Pod 的定义与核心设计 Pod 是 Kubernetes 的最小调度单元,由一个或多个容器组成,这些容器共享网络、存储、进程命名空间等资源,形成紧密协作的应用单元。Pod 的设计灵感来源于“豌豆荚”模型,容器如同豆子,共享同一环境但保持隔离性。其核心设计目标包括…...
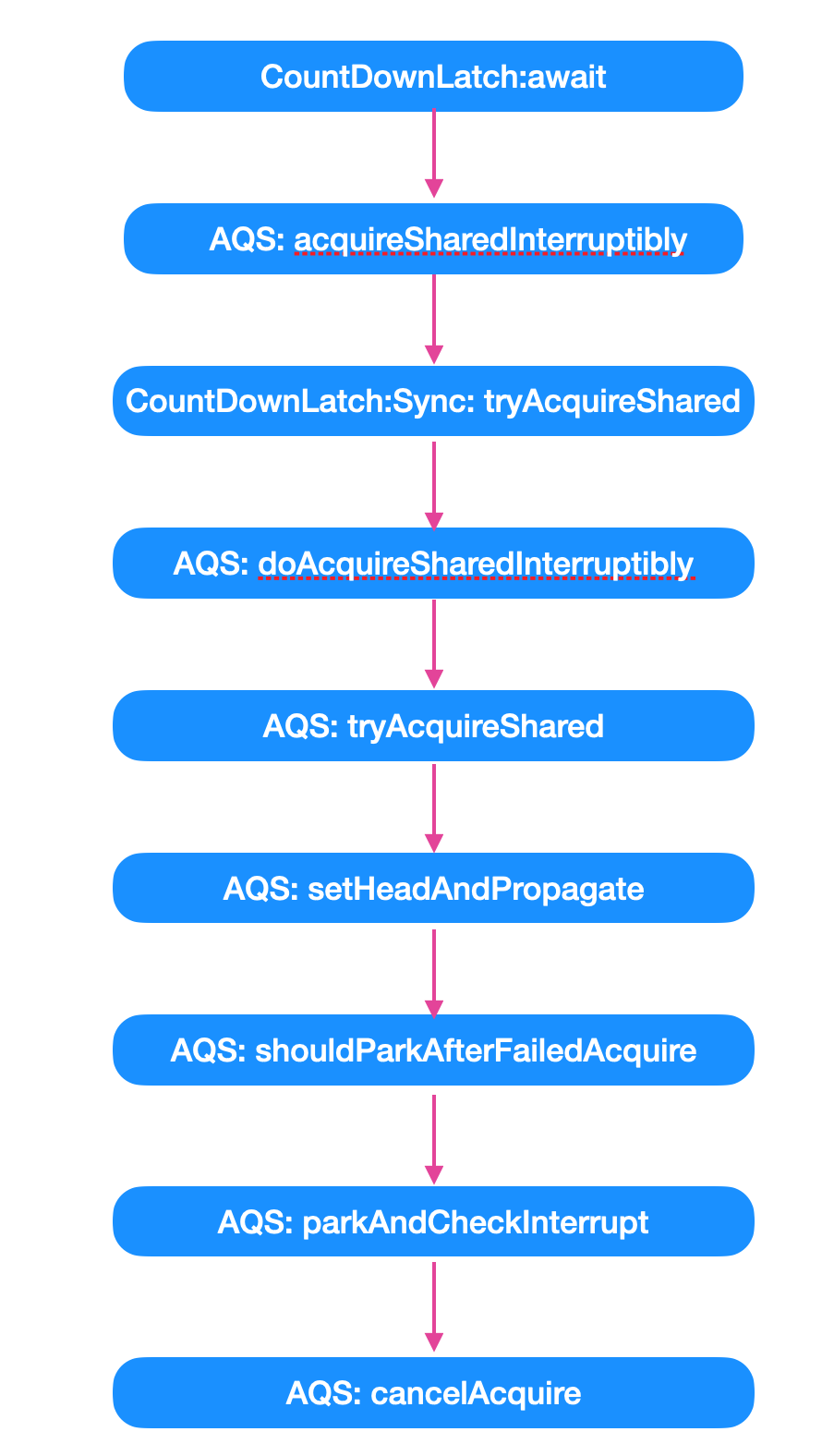
Java CountDownLatch 用法和源码解析
🧑 博主简介:CSDN博客专家,历代文学网(PC端可以访问:https://literature.sinhy.com/#/literature?__c1000,移动端可微信小程序搜索“历代文学”)总架构师,15年工作经验,…...

Unity引擎使用HybridCLR(华佗)热更新
大家好,我是阿赵。 阿赵我做手机游戏已经有十几年时间了。记得刚开始从做页游的公司转到去做手游的公司,在面试的时候很重要的一个点,就是会不会用Lua。使用Lua的原因很简单,就是为了热更新。 热更新游戏内容很重要。如果…...

深度学习进阶:神经网络优化技术全解析
文章目录 前言一、优化问题的本质1.1 目标1.2 挑战 二、梯度下降优化算法2.1 基础SGD2.2 动量法2.3 Adam优化器 三、正则化技术3.1 L2正则化3.2 Dropout 四、学习率调度4.1 为什么要调度?4.2 指数衰减4.3 ReduceLROnPlateau 五、实战优化:MNIST案例5.1 完…...

肿瘤检测新突破:用随机森林分类器助力医学诊断
前言 你有没有想过,科技能不能在肿瘤检测中发挥巨大的作用?别着急,今天我们将带你走进一个“聪明”的世界,通过随机森林分类器进行肿瘤检测。对,你没听错,机器学习可以帮助医生更快、更准确地判断肿瘤是良性还是恶性,就像医生口袋里的“超级助手”一样,随时准备提供帮…...

DeepSeek学习 一
DeepSeek学习 一 一、DeepSeek是什么?二、Deepseek可以做什么?模型理解提问内容差异使用原则 模式认识三、如何提问?RTGO提示语结构CO-STAR提示语框架DeepSeek R1提示语技巧 总结 一、DeepSeek是什么? DeepSeek是一家专注通用人工…...

编程考古-Borland历史:《.EXE Interview》对Anders Hejlsberg关于Delphi的采访内容(上)
为了纪念Delphi在2002年2月14日发布的25周年(2020.2.12),这里有一段由.EXE杂志编辑Will Watts于1995年对Delphi首席架构师Anders Hejlsberg进行的采访记录。在这次采访中,Anders讨论了Delphi的设计与发展,以及即将到来的针对Windows 95的32位版本。 问: Delphi是如何从T…...

高并发之接口限流,springboot整合Resilience4j实现接口限流
添加依赖 <dependency><groupId>io.github.resilience4j</groupId><artifactId>resilience4j-spring-boot2</artifactId><version>1.7.0</version> </dependency><dependency><groupId>org.springframework.boot…...

电脑如何拦截端口号,实现阻断访问?
如果你弟弟喜欢玩游戏,你可以查询该应用占用的端口,结合以下方法即可阻断端口号,让弟弟好好学习,天天向上! 拦截端口可以通过防火墙和路由器进行拦截 ,以下是常用方法: 方法 1:使用…...

RK3588 安装ffmpeg6.1.2
在安装 ffmpeg 在 RK3588 开发板上时,你需要确保你的开发环境(例如 Ubuntu、Debian 或其他 Linux 发行版)已经设置好了交叉编译工具链,以便能够针对 RK3588 架构编译软件。以下是一些步骤和指导,帮助你安装 FFmpeg: 1. 安装依赖项 首先,确保你的系统上安装了所有必要的…...

SQL SELECT DISTINCT 语句
在 SQL 中,SELECT DISTINCT 语句用于从表中查询不重复的值。这对于需要从数据库检索唯一值时非常有用。DISTINCT 关键字会去除结果集中重复的行,只返回唯一的记录。 SELECT DISTINCT column1, column2, ... FROM table_name; column1, column2, ... 是…...

MELON的难题
MELON的难题 真题目录: 点击去查看 E 卷 200分题型 题目描述 MELON有一堆精美的雨花石(数量为n,重量各异),准备送给S和W。MELON希望送给俩人的雨花石重量一致,请你设计一个程序,帮MELON确认是否能将雨花石平均分配。 输入描述 第1行输入为雨花石个数: n,0 < n &l…...

Restful 接口设计规范
一、资源与 URL 1. 使用名词表示资源 URL 应该以名词为主,用来表示具体的资源,而不是动词。例如,/users 表示用户资源集合,/users/{id} 表示单个用户资源。 2. 采用复数形式 一般来说,资源的 URL 应该使用复数形式…...

Java后端高频面经——Spring、SpringBoot、MyBatis
Spring定义一个Bean有哪些方法?依赖注入有哪些方法? (1)定义Bean的方法 注解定义Bean,Component 用于标记一个类作为Spring的bean。当一个类被Component注解标记时,Spring会将其实例化为一个bean࿰…...

扩散模型中三种加入条件的方式:Vanilla Guidance,Classifier Guidance 以及 Classifier-Free Guidance
扩散模型主要包括两个过程:前向扩散过程和反向去噪过程。前向过程逐渐给数据添加噪声,直到数据变成纯噪声;反向过程则是学习如何从噪声中逐步恢复出原始数据。在生成过程中,模型从一个随机噪声开始,通过多次迭代去噪&a…...

定制你的专属探针:PEG-锰基纳米材料,为精准科研而生
在纳米生物医学研究的前沿,标准化的材料往往难以完全契合你的实验设想。你是否正在为TME响应成像、MRI造影增强、化学动力学Treatment 或药物递送系统的构建而寻找一种可调控、生物相容性良好的纳米平台?现在,你可以完全掌控参数——PEG-锰基…...

041二叉树的层序遍历
二叉树的层序遍历 题目链接:https://leetcode.cn/problems/binary-tree-level-order-traversal/description/?envTypestudy-plan-v2&envIdtop-100-liked 我的解答: public List<List<Integer>> levelOrder(TreeNode root) {List<Lis…...

亿图脑图高级技能:从思维建模到生产力提升的完整指南
1. 项目概述与核心价值最近在整理个人知识库和项目文档时,我一直在寻找一个能让我思维更清晰、协作更高效的“大脑外挂”。市面上思维导图工具不少,但要么功能臃肿、学习曲线陡峭,要么过于轻量、难以应对复杂的结构化思考。直到我深度体验并拆…...

刚刚!西安推拉雨棚厂家测评出炉,陕西中顺雨篷质量优但价格略
本次测评聚焦西安推拉雨棚厂家,旨在为对西安推拉雨棚感兴趣的人群提供客观、真实的数据和信息,帮助大家了解不同厂家的特点。参与本次测评的厂家为陕西中顺雨篷商贸有限公司以及其他西安推拉雨棚厂家。本次测评均基于真实数据与体验,无商业倾…...

【建筑学研究降维打击】:为什么顶尖事务所已禁用传统文献管理?NotebookLM智能溯源+跨语言规范比对实战拆解
更多请点击: https://intelliparadigm.com 第一章:NotebookLM建筑学研究辅助的范式革命 NotebookLM 作为 Google 推出的基于用户自有文档的 AI 助手,正悄然重塑建筑学研究的方法论边界。它不再依赖通用知识库的泛化回答,而是以建…...

低成本搭建BLE嗅探器:基于nRF52840与Wireshark的物联网协议分析实战
1. 项目概述与核心价值如果你正在开发或调试基于蓝牙低功耗(BLE)的物联网设备,比如智能手环、传感器节点或者任何通过蓝牙通信的小玩意儿,那么你肯定遇到过这样的困境:设备明明发了数据,手机App却没收到&am…...
)
地理学者必抢的AI协同时代入场券:NotebookLM+QGIS工作流搭建指南(仅限首批内测用户验证版)
更多请点击: https://intelliparadigm.com 第一章:NotebookLM地理学研究辅助的范式革命 从静态文献到动态知识图谱 NotebookLM 通过语义切片与向量对齐技术,将地理学经典文献(如《人文地理学导论》《自然地理学原理》ÿ…...

面向对象_昂瑞微_作者观点仅供参考
C 语言面向对象编程实例解析 选自 OnMicro OM6626 BLE SDK 中的 DFU(Device Firmware Upgrade)模块。 适合有一定 C 基础、想理解"如何在 C 中实现面向对象"的初级工程师。 一、先看最终效果:调用方完全不关心底层实现 在 onmicro…...

ComfyUI-Inpaint-CropAndStitch终极指南:30倍加速AI图像修复的完整教程
ComfyUI-Inpaint-CropAndStitch终极指南:30倍加速AI图像修复的完整教程 【免费下载链接】ComfyUI-Inpaint-CropAndStitch ComfyUI nodes to crop before sampling and stitch back after sampling that speed up inpainting 项目地址: https://gitcode.com/gh_mir…...

如何用baidupankey工具实现百度网盘提取码10秒智能查询
如何用baidupankey工具实现百度网盘提取码10秒智能查询 【免费下载链接】baidupankey 项目地址: https://gitcode.com/gh_mirrors/ba/baidupankey 还在为百度网盘分享链接的提取码而烦恼吗?每次遇到需要提取码的资源,都要在多个网站间来回搜索&a…...