深度学习进阶:神经网络优化技术全解析
文章目录
- 前言
- 一、优化问题的本质
- 1.1 目标
- 1.2 挑战
- 二、梯度下降优化算法
- 2.1 基础SGD
- 2.2 动量法
- 2.3 Adam优化器
- 三、正则化技术
- 3.1 L2正则化
- 3.2 Dropout
- 四、学习率调度
- 4.1 为什么要调度?
- 4.2 指数衰减
- 4.3 ReduceLROnPlateau
- 五、实战优化:MNIST案例
- 5.1 完整代码
- 六、进阶技巧
- 6.1 Batch Normalization
- 6.2 Gradient Clipping
- 6.3 Early Stopping
- 七、注意事项
- 八、总结
前言
神经网络是深度学习的核心,但训练一个高效、稳定的模型并非易事。优化技术直接影响模型的收敛速度、性能和泛化能力。本文将深入探讨神经网络优化中的关键方法,包括梯度下降变种、正则化、学习率调度等,并结合Python代码展示其实战效果。如果你已经掌握神经网络基础,想进一步提升模型性能,这篇教程将是你的进阶指南。欢迎在评论区分享你的优化经验!
一、优化问题的本质
1.1 目标
神经网络训练的目标是最小化损失函数 ( L(\theta) ),通过调整参数 (\theta)(权重和偏置)。
- 公式:(\theta = \theta - \eta \cdot \nabla L(\theta)),(\eta) 为学习率。
1.2 挑战
- 梯度消失/爆炸:深层网络中梯度可能过小或过大。
- 局部极值:非凸损失函数可能陷入次优解。
- 过拟合:模型在训练集上表现好,但在测试集上泛化差。
二、梯度下降优化算法
2.1 基础SGD
随机梯度下降(SGD)是基础优化方法:
# 伪代码
weights = initial_weights
learning_rate = 0.01
for epoch in range(epochs):gradient = compute_gradient(loss, weights)weights -= learning_rate * gradient
缺点:收敛慢,易震荡。
2.2 动量法
引入动量加速收敛:
import numpy as npvelocity = 0
learning_rate = 0.01
momentum = 0.9
for epoch in range(epochs):gradient = compute_gradient(loss, weights)velocity = momentum * velocity - learning_rate * gradientweights += velocity
优点:减少震荡,加速沿梯度方向前进。
2.3 Adam优化器
自适应矩估计(Adam)结合动量和RMSProp优点:
import tensorflow as tfmodel = tf.keras.Sequential([tf.keras.layers.Dense(64, activation="relu"),tf.keras.layers.Dense(10, activation="softmax")
])
model.compile(optimizer="adam",loss="sparse_categorical_crossentropy",metrics=["accuracy"])
原理:
- 一阶动量(均值):平滑梯度。
- 二阶动量(方差):自适应调整学习率。
三、正则化技术
3.1 L2正则化
在损失函数中添加权重惩罚项:
[ L = L_{original} + \lambda \sum w^2 ]
model = tf.keras.Sequential([tf.keras.layers.Dense(64, activation="relu", kernel_regularizer=tf.keras.regularizers.l2(0.01)),tf.keras.layers.Dense(10, activation="softmax")
])
效果:限制权重过大,减少过拟合。
3.2 Dropout
随机丢弃神经元,增强泛化:
model = tf.keras.Sequential([tf.keras.layers.Dense(64, activation="relu"),tf.keras.layers.Dropout(0.2), # 20%神经元失活tf.keras.layers.Dense(10, activation="softmax")
])
Tips:Dropout仅在训练时生效,测试时自动关闭。
四、学习率调度
4.1 为什么要调度?
初始高学习率加速收敛,后期低学习率精细调整。
4.2 指数衰减
学习率随时间指数下降:
initial_lr = 0.1
lr_schedule = tf.keras.optimizers.schedules.ExponentialDecay(initial_lr, decay_steps=10000, decay_rate=0.9
)
optimizer = tf.keras.optimizers.Adam(learning_rate=lr_schedule)
model.compile(optimizer=optimizer, loss="sparse_categorical_crossentropy")
4.3 ReduceLROnPlateau
当验证损失停止下降时降低学习率:
reduce_lr = tf.keras.callbacks.ReduceLROnPlateau(monitor="val_loss", factor=0.5, patience=10, min_lr=0.0001
)
model.fit(X_train, y_train, epochs=50, validation_split=0.2, callbacks=[reduce_lr])
效果:动态适应训练过程,避免过早收敛。
五、实战优化:MNIST案例
5.1 完整代码
结合上述技术优化MNIST分类模型:
import tensorflow as tf
from tensorflow.keras import layers, models# 数据加载
(X_train, y_train), (X_test, y_test) = tf.keras.datasets.mnist.load_data()
X_train, X_test = X_train / 255.0, X_test / 255.0# 模型构建
model = models.Sequential([layers.Flatten(input_shape=(28, 28)),layers.Dense(128, activation="relu", kernel_regularizer=tf.keras.regularizers.l2(0.01)),layers.Dropout(0.2),layers.Dense(10, activation="softmax")
])# 学习率调度
lr_schedule = tf.keras.optimizers.schedules.ExponentialDecay(0.001, decay_steps=10000, decay_rate=0.9)
optimizer = tf.keras.optimizers.Adam(learning_rate=lr_schedule)# 编译和训练
model.compile(optimizer=optimizer, loss="sparse_categorical_crossentropy", metrics=["accuracy"])
history = model.fit(X_train, y_train, epochs=20, validation_split=0.2, batch_size=64)# 评估
test_loss, test_acc = model.evaluate(X_test, y_test)
print(f"测试准确率: {test_acc:.4f}")# 可视化
import matplotlib.pyplot as plt
plt.plot(history.history["accuracy"], label="训练准确率")
plt.plot(history.history["val_accuracy"], label="验证准确率")
plt.xlabel("Epoch")
plt.ylabel("Accuracy")
plt.legend()
plt.show()
结果:
准确率提升至98%以上,验证集表现稳定。
六、进阶技巧
6.1 Batch Normalization
在每层后标准化输入,加速训练:
model.add(layers.BatchNormalization())
6.2 Gradient Clipping
限制梯度大小,避免爆炸:
optimizer = tf.keras.optimizers.Adam(clipnorm=1.0)
6.3 Early Stopping
当验证性能不再提升时停止训练:
early_stopping = tf.keras.callbacks.EarlyStopping(monitor="val_loss", patience=5)
model.fit(X_train, y_train, callbacks=[early_stopping])
七、注意事项
- 超参数调优:尝试不同学习率、正则化强度。
- 计算资源:深层网络需GPU支持,可用Google Colab。
- 监控训练:用TensorBoard可视化损失和指标(
callbacks.TensorBoard())。
八、总结
神经网络优化是深度学习成功的基石。从动量法到Adam,从Dropout到学习率调度,这些技术能显著提升模型性能。通过本文的MNIST实战,你可以轻松将这些方法应用到自己的项目中。下一步,不妨尝试优化更复杂的模型,如CNN或Transformer。
互动环节:
- 你在神经网络优化中用过哪些技巧?效果如何?
- 遇到过哪些训练难题?欢迎留言讨论!
相关文章:

深度学习进阶:神经网络优化技术全解析
文章目录 前言一、优化问题的本质1.1 目标1.2 挑战 二、梯度下降优化算法2.1 基础SGD2.2 动量法2.3 Adam优化器 三、正则化技术3.1 L2正则化3.2 Dropout 四、学习率调度4.1 为什么要调度?4.2 指数衰减4.3 ReduceLROnPlateau 五、实战优化:MNIST案例5.1 完…...

肿瘤检测新突破:用随机森林分类器助力医学诊断
前言 你有没有想过,科技能不能在肿瘤检测中发挥巨大的作用?别着急,今天我们将带你走进一个“聪明”的世界,通过随机森林分类器进行肿瘤检测。对,你没听错,机器学习可以帮助医生更快、更准确地判断肿瘤是良性还是恶性,就像医生口袋里的“超级助手”一样,随时准备提供帮…...

DeepSeek学习 一
DeepSeek学习 一 一、DeepSeek是什么?二、Deepseek可以做什么?模型理解提问内容差异使用原则 模式认识三、如何提问?RTGO提示语结构CO-STAR提示语框架DeepSeek R1提示语技巧 总结 一、DeepSeek是什么? DeepSeek是一家专注通用人工…...

编程考古-Borland历史:《.EXE Interview》对Anders Hejlsberg关于Delphi的采访内容(上)
为了纪念Delphi在2002年2月14日发布的25周年(2020.2.12),这里有一段由.EXE杂志编辑Will Watts于1995年对Delphi首席架构师Anders Hejlsberg进行的采访记录。在这次采访中,Anders讨论了Delphi的设计与发展,以及即将到来的针对Windows 95的32位版本。 问: Delphi是如何从T…...

高并发之接口限流,springboot整合Resilience4j实现接口限流
添加依赖 <dependency><groupId>io.github.resilience4j</groupId><artifactId>resilience4j-spring-boot2</artifactId><version>1.7.0</version> </dependency><dependency><groupId>org.springframework.boot…...

电脑如何拦截端口号,实现阻断访问?
如果你弟弟喜欢玩游戏,你可以查询该应用占用的端口,结合以下方法即可阻断端口号,让弟弟好好学习,天天向上! 拦截端口可以通过防火墙和路由器进行拦截 ,以下是常用方法: 方法 1:使用…...

RK3588 安装ffmpeg6.1.2
在安装 ffmpeg 在 RK3588 开发板上时,你需要确保你的开发环境(例如 Ubuntu、Debian 或其他 Linux 发行版)已经设置好了交叉编译工具链,以便能够针对 RK3588 架构编译软件。以下是一些步骤和指导,帮助你安装 FFmpeg: 1. 安装依赖项 首先,确保你的系统上安装了所有必要的…...

SQL SELECT DISTINCT 语句
在 SQL 中,SELECT DISTINCT 语句用于从表中查询不重复的值。这对于需要从数据库检索唯一值时非常有用。DISTINCT 关键字会去除结果集中重复的行,只返回唯一的记录。 SELECT DISTINCT column1, column2, ... FROM table_name; column1, column2, ... 是…...

MELON的难题
MELON的难题 真题目录: 点击去查看 E 卷 200分题型 题目描述 MELON有一堆精美的雨花石(数量为n,重量各异),准备送给S和W。MELON希望送给俩人的雨花石重量一致,请你设计一个程序,帮MELON确认是否能将雨花石平均分配。 输入描述 第1行输入为雨花石个数: n,0 < n &l…...

Restful 接口设计规范
一、资源与 URL 1. 使用名词表示资源 URL 应该以名词为主,用来表示具体的资源,而不是动词。例如,/users 表示用户资源集合,/users/{id} 表示单个用户资源。 2. 采用复数形式 一般来说,资源的 URL 应该使用复数形式…...

Java后端高频面经——Spring、SpringBoot、MyBatis
Spring定义一个Bean有哪些方法?依赖注入有哪些方法? (1)定义Bean的方法 注解定义Bean,Component 用于标记一个类作为Spring的bean。当一个类被Component注解标记时,Spring会将其实例化为一个bean࿰…...

扩散模型中三种加入条件的方式:Vanilla Guidance,Classifier Guidance 以及 Classifier-Free Guidance
扩散模型主要包括两个过程:前向扩散过程和反向去噪过程。前向过程逐渐给数据添加噪声,直到数据变成纯噪声;反向过程则是学习如何从噪声中逐步恢复出原始数据。在生成过程中,模型从一个随机噪声开始,通过多次迭代去噪&a…...

Banana Pi OpenWRT One Wifi6 OpenWrt社区官方开源路由器评测
第一款不可破解、开源、版权软件、符合 FCC、CE 和 RoHS 的维修权路由器 OpenWRT项目今年已经20岁了,为了纪念这一时刻,Banana Pi OpenWrt One/AP-24.XY路由器开发系统已经上市。这是OpenWRT团队与硬件公司的第一个联合项目。选择 Banana Pi,…...

9.1go结构体
Go不是完全面向对象的,没有类的概念,所以结构体应该承担了更多的责任。 结构体定义 使用 type 和 struct 关键字定义: type Person struct { Name string Age int } 字段可以是任意类型,包括其他结构体或指针。 字段名以大写…...

Manus全球首个通用Agent,Manus AI:Agent应用的ChatGPT时刻
文章目录 前言Manus AI: 全球首个通用AgentManus AI: 技术架构与创始人经历AI Agent的实现框架与启示AI Agent的发展预测行业风险提示 前言 这是一篇关于Manus AI及其在通用人工智能领域的应用和前景的报告,主要介绍了Manus AI的产品定位、功能、技术架构、创始人经…...
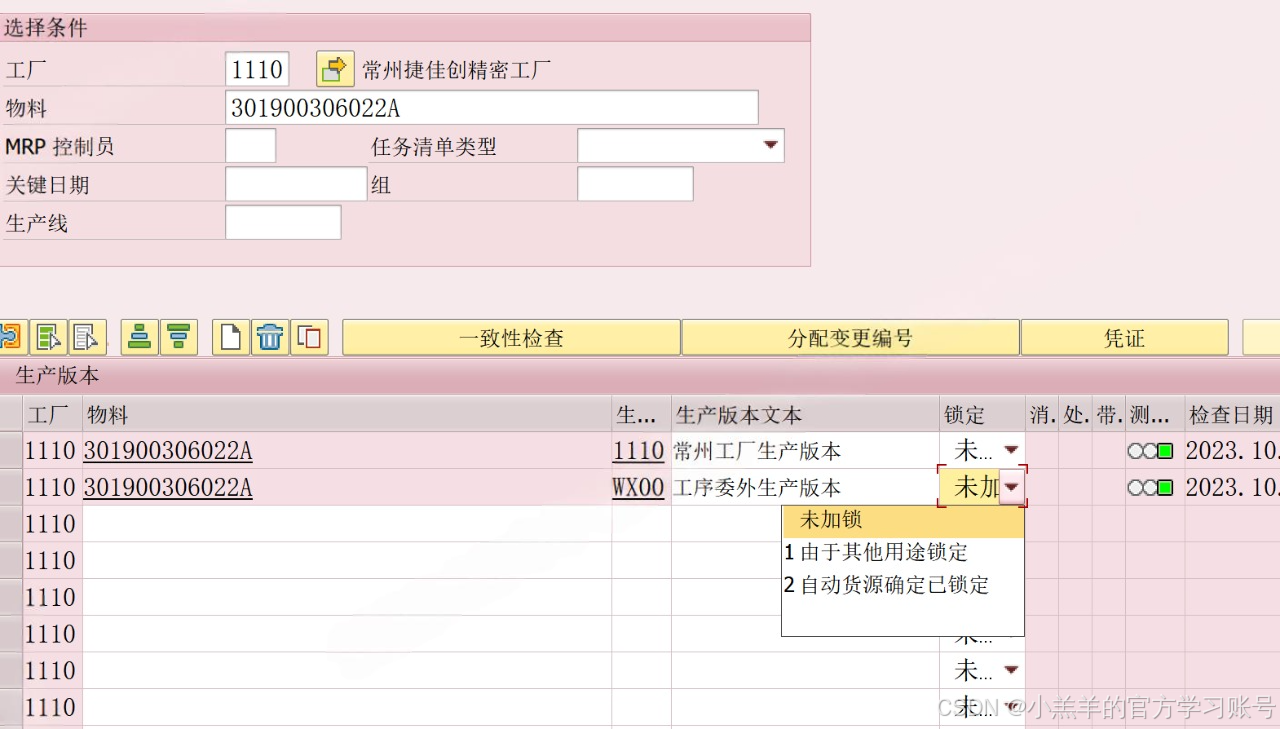
【SAP-PP】生产版本维护
一、基本概念 生产版本:用于定义一种产品,不同的生产方式,包含物料清单(BOM)和工艺路线的信息,给生产带来更多的灵活性。在做产品需求计划时和产品生产时(创建生产订单、生产订单下达前和生产订…...

软考 中级软件设计师 考点笔记总结 day01
文章目录 软考1.0上午考点下午考点 软考1.11、数值及其转换2、计算机内数据表示2.1、定点数 - 浮点数2.2、奇偶校验 和 循环冗余校验 (了解)2.3、海明码 (掌握)2.4、机器数 软考1.0 上午考点 软件工程基础知识: 开发模型、设计原则、测试方…...

K8s控制器Deployment详解
回顾 ReplicaSet 控制器,该控制器是用来维护集群中运行的 Pod 数量的,但是往往在实际操作的时候,我们反而不会去直接使用 RS,而是会使用更上层的控制器,比如说 Deployment。 Deployment 一个非常重要的功能就是实现了 Pod 的滚动…...

【微知】Centos如何迁移到Anolis系统的失败记录?(yum -y install centos2anolis、centos2anolis.py)
背景 本文记录如何从centos 8迁移到anolis系统。 详细步骤 下载迁移repo wget https://mirrors.openanolis.cn/anolis/migration/anolis-migration.repo -O /etc/yum.repos.d/anolis-migration.repo下载centos2anolis工具包 yum -y install centos2anolis安装额外工具包 …...

在 macOS 上使用 CLion 进行 Google Test 单元测试
介绍 Google Test(GTest)是 Google 开源的 C 单元测试框架,它提供了简单易用的断言、测试夹具(Fixtures)和测试运行机制,使 C 开发者能够编写高效的单元测试。 本博客将介绍如何在 macOS 上使用 CLion 配…...

学妹问降AI率工具选哪个性价比最高?4款降AI软件1万字花多少过AIGC检测
学妹问降AI率工具选哪个性价比最高?4款降AI软件1万字花多少过AIGC检测 学妹的具体问题 3 月 23 号晚上学妹问我:「学姐我送知网测了 AI 率 65%——市面降 AI 工具一堆我怎么选性价比最高的?预算 300 元以内」。 「性价比最高」是用户最常问…...
)
保姆级教程:用PyTorch复现DLA-34分割模型(含可变形卷积版DLAseg)
深度解析DLA-34分割模型:从理论到PyTorch实战 在计算机视觉领域,特征融合一直是提升模型性能的关键技术。Deep Layer Aggregation(DLA)作为CVPR 2018提出的创新架构,通过独特的树状连接机制实现了跨层级的深度特征融合…...

React组件库spac-kit:原子化间距与声明式布局的工程实践
1. 项目概述:一个为现代Web应用而生的React组件库最近在做一个新的后台管理系统,UI框架选型时,我又一次陷入了纠结。市面上成熟的组件库很多,但要么过于庞大,引入后项目体积膨胀得厉害;要么设计风格固化&am…...

研扬EPIC-RPS9工控主板解析:4英寸板载13代酷睿,赋能边缘AI与机器视觉
1. 项目概述:当“小钢炮”遇上工业严苛环境在工业自动化、边缘计算和嵌入式视觉这些领域里,我们常常面临一个经典矛盾:既要强大的算力来处理海量数据、运行复杂算法,又要设备足够紧凑、坚固,能塞进各种空间受限、环境恶…...

2026亚洲消费电子展!媒体曝光资源加码
北京讯——2026年6月10日至12日,2026亚洲消费电子展将在北京盛大启幕。作为亚太消费电子领域极具影响力的行业盛会,本届展会全面升级品牌传播矩阵,百家主流媒体集结现场全程报道,全媒体曝光资源重磅加码。目前展会赞助合作席位余量…...

Bash脚本集成AI:实现自然语言到命令行的自动化运维工具
1. 项目概述:当Bash脚本遇见AI,自动化运维的新范式最近在GitHub上看到一个挺有意思的项目,叫“Hezkore/bash-ai”。光看名字,你可能会有点懵:Bash脚本和AI,这两个看似八竿子打不着的玩意儿,怎么…...

Godot引擎集成CEF实现Web混合渲染:gdcef项目架构与实战指南
1. 项目概述与核心价值最近在折腾一个老项目的现代化改造,需要把传统的桌面应用嵌入到Web视图中,实现混合渲染。在技术选型时,我绕不开一个名字:CEF,也就是Chromium Embedded Framework。它几乎是桌面应用内嵌浏览器控…...

基于视觉大模型的GUI自动化:从原理到实践
1. 项目概述:当GUI自动化遇见视觉大模型 最近在折腾自动化测试和RPA(机器人流程自动化)的时候,我遇到了一个老生常谈但又极其棘手的问题:如何稳定、高效地识别和操作那些没有标准控件标识的图形界面元素?传…...

自行车轮POV显示:基于视觉暂留与微控制器的DIY空中光绘
1. 项目概述:在车轮上“画”出光之画卷几年前,我第一次在夜间的公园里看到一辆飞驰而过的自行车,它的轮辐间竟然清晰地显示着一行发光的文字和图案,那种瞬间的震撼感至今难忘。那不是魔法,而是视觉暂留原理与微控制器精…...

Python 的串口操作库 pyserial
封装了串口通讯模块,支持Linux、Windows、BSD(可能支持所有支持POSIX的操作系统),支持 Jython (Java) 和 IconPython (.NET and Mono)。 首页 http://pyserial.sf.net/ 1. 特性 所有平台使用同样的类接口端口号默认从0开始&…...