扩散模型中三种加入条件的方式:Vanilla Guidance,Classifier Guidance 以及 Classifier-Free Guidance
扩散模型主要包括两个过程:前向扩散过程和反向去噪过程。前向过程逐渐给数据添加噪声,直到数据变成纯噪声;反向过程则是学习如何从噪声中逐步恢复出原始数据。在生成过程中,模型从一个随机噪声开始,通过多次迭代去噪,最终生成有意义的数据,比如图像。这时候,如果需要生成特定类别的数据,比如生成猫的图像而不是狗的,就需要加入条件引导,控制生成的方向。这就是条件扩散模型的作用。
Vanilla Guidance、Classifier Guidance和Classifier-Free Guidance,是在反向过程中如何利用条件信息的不同策略:
- Vanilla Guidance: 指的是最基本的条件加入方式,也就是在模型训练时直接将条件信息(比如类别标签,时间标签)作为输入的一部分。例如,在UNet的结构中,除了输入噪声图像和时间步信息外,还会将条件向量拼接或嵌入到网络中,让模型在训练时学会根据条件生成对应的图像。这种方法可能的问题是需要大量带标签的数据,并且在推理时可以通过替换不同的条件来生成不同类别的图像。不过,可能控制的效果有限,或者需要更多的调整。
- Classifier Guidance :这个方法是需要预训练一个分类器,在反向过程中利用分类器的梯度来调整生成的方向,使得生成的图像符合给定的条件。具体来说,在每一步去噪的时候,不仅根据扩散模型的预测去噪,还会计算分类器对当前中间图像的梯度,将梯度信息加入到噪声预测中,从而使得生成的图像在分类器看来属于目标类别。这种方法的好处是不需要在扩散模型本身中加入条件,而是通过外部分类器来引导生成,可能更加灵活。不过缺点是需要额外训练分类器,并且分类器需要在带噪声的数据上进行训练,因为扩散过程的中间结果是有噪声的,可能影响分类器的准确性。
- Classifier-Free Guidance :不需要单独的分类器,而是通过训练时的条件和非条件生成来隐式地引导生成方向。具体来说,可能是在训练时随机地忽略条件信息(比如以一定概率将条件置空),让模型同时学习有条件生成和无条件生成。在推理时,通过调整条件和非条件预测的权重,来增强条件的影响。比如,将条件预测的结果和无条件预测的结果进行线性组合,从而在不需要外部分类器的情况下实现更强的条件控制。这种方法结合了两者的优点,既不需要额外的分类器,又能有效利用条件信息,但可能需要更大的模型或更复杂的训练策略。
举个例子,假设我要生成一个带有“猫”标签的图像。
Vanilla Guidance在训练时将“猫”的标签编码后输入到模型中,让模型在生成过程中始终考虑这个条件。
Classifier Guidance则是在生成过程中,每一步都使用一个已经训练好的猫分类器,对中间图像计算梯度,调整生成方向。
而Classifier-Free Guidance则是在训练时,有时告诉模型生成猫,有时不告诉任何条件,然后在推理时通过调整条件和非条件的权重来加强条件的影响,比如让条件预测的权重更大,从而生成更符合要求的猫的图像。
总结:
- Vanilla Guidance:在模型训练时将条件信息作为输入,直接训练条件生成模型。生成时通过输入不同的条件来控制输出。但可能缺乏对条件的强引导,导致控制不够精准。
- Classifier Guidance:在反向过程中使用预训练的分类器梯度来调整生成方向,强化条件信号。需要额外训练分类器,并且分类器需要适应带噪声的输入,但能够更精确地控制生成结果。
- Classifier-Free Guidance:在训练时同时学习有条件和无条件生成,推理时通过组合两者的预测来增强条件效果。不需要外部分类器,通过模型自身的条件和非条件预测差异来引导生成,灵活性高,效果较好,但训练时需要更多的策略(如随机丢弃条件)。
1. Vanilla Guidance(朴素引导)
- 核心思想:在训练时直接将条件信息(如类别标签、文本描述)作为模型输入的一部分,通过端到端学习条件生成。
- 实现方式:
- 条件信息(如类别嵌入或文本编码)通过拼接、相加或多层感知机(MLP)注入到模型的每一层(如UNet的残差块中)。
- 模型直接学习基于条件的噪声预测,无需额外引导机制。
- 优点:
- 实现简单,直接融入模型结构。
- 推理时通过替换条件输入灵活控制生成内容。
- 缺点:
- 条件控制较弱,尤其在复杂任务(如细粒度文本生成图像)中可能生成与条件无关的结果。
- 依赖大量带标注数据,且条件信息可能未被充分建模。
- 典型应用:早期的条件扩散模型(如DDPM的类别条件生成)。
2. Classifier Guidance(分类器引导)
- 核心思想:利用预训练的分类器梯度,在反向去噪过程中调整生成方向,使输出符合目标条件。
- 实现方式:
- 训练阶段:扩散模型可无条件训练,同时额外训练一个噪声鲁棒的分类器(适应各时间步的噪声数据)。
- 推理阶段:
- 在每一步去噪时,计算分类器对中间图像的条件概率梯度。
- 将梯度信息加权后注入噪声预测:
ϵ θ ( x t , t ) → ϵ θ ( x t , t ) + s ⋅ ∇ x t log p ϕ ( y ∣ x t ) \epsilon_\theta(x_t, t) \rightarrow \epsilon_\theta(x_t, t) + s \cdot \nabla_{x_t} \log p_\phi(y \mid x_t) ϵθ(xt,t)→ϵθ(xt,t)+s⋅∇xtlogpϕ(y∣xt)
其中, s s s 为引导尺度,控制条件强度。
- 优点:
- 通过梯度调整实现精准条件控制,生成质量高。
- 扩散模型与分类器解耦,可复用预训练分类器。
- 缺点:
- 需额外训练噪声适应的分类器,增加训练成本。
- 分类器在强噪声下可能失效,影响引导效果。
- 典型应用:OpenAI的Guided Diffusion(2021)。
3. Classifier-Free Guidance(无分类器引导)
- 核心思想:隐式学习条件与无条件生成的差异,通过混合预测结果增强条件控制,无需外部分类器。
- 实现方式:
- 训练阶段:
- 随机以概率 p p p 丢弃条件(替换为空白标识),使模型同时学习条件生成( p ( y ∣ x ) p(y \mid x) p(y∣x))和无条件生成( p ( x ) p(x) p(x))。
- 例如,在文本到图像任务中,以一定概率将文本描述替换为空字符串。
- 推理阶段:
- 混合条件预测 ϵ θ ( x t , t , y ) \epsilon_\theta(x_t, t, y) ϵθ(xt,t,y) 和无条件预测 ϵ θ ( x t , t , ∅ ) \epsilon_\theta(x_t, t, \emptyset) ϵθ(xt,t,∅):
ϵ guided = ϵ θ ( x t , t , ∅ ) + s ⋅ ( ϵ θ ( x t , t , y ) − ϵ θ ( x t , t , ∅ ) ) \epsilon_\text{guided} = \epsilon_\theta(x_t, t, \emptyset) + s \cdot (\epsilon_\theta(x_t, t, y) - \epsilon_\theta(x_t, t, \emptyset)) ϵguided=ϵθ(xt,t,∅)+s⋅(ϵθ(xt,t,y)−ϵθ(xt,t,∅))
其中, s > 1 s > 1 s>1 时增强条件效应, s = 1 s=1 s=1 退化为普通条件生成。
- 混合条件预测 ϵ θ ( x t , t , y ) \epsilon_\theta(x_t, t, y) ϵθ(xt,t,y) 和无条件预测 ϵ θ ( x t , t , ∅ ) \epsilon_\theta(x_t, t, \emptyset) ϵθ(xt,t,∅):
- 训练阶段:
- 优点:
- 无需外部分类器,简化训练流程。
- 通过调整引导尺度 s s s 灵活平衡生成质量与多样性。
- 缺点:
- 训练时需同时建模条件与无条件生成,可能增加模型容量需求。
- 条件丢弃概率需调优,否则影响收敛稳定性。
- 典型应用:Stable Diffusion、DALL·E 2等主流文本到图像模型。
对比总结
| 特性 | Vanilla Guidance | Classifier Guidance | Classifier-Free Guidance |
|---|---|---|---|
| 是否需要分类器 | 否 | 是(噪声适应) | 否 |
| 训练复杂度 | 低(端到端条件训练) | 中(需训练分类器) | 中(条件随机丢弃策略) |
| 推理灵活性 | 低(直接替换条件) | 中(依赖分类器) | 高(通过 s s s 调节控制强度) |
| 生成质量与条件控制 | 一般 | 高(依赖分类器质量) | 高(自适应调节) |
| 典型场景 | 简单条件生成 | 高精度条件生成(需分类器可靠) | 复杂条件生成(如文本到图像) |
选择建议
- 数据充足且条件简单:Vanilla Guidance足够高效。
- 需高精度控制且分类器可靠:Classifier Guidance适合特定领域(如医学图像生成)。
- 通用复杂条件生成:Classifier-Free Guidance更优,已成为当前主流(如Stable Diffusion)。
通过理解这三种方法的差异,可根据具体任务需求选择最适合的条件引导策略。
相关文章:

扩散模型中三种加入条件的方式:Vanilla Guidance,Classifier Guidance 以及 Classifier-Free Guidance
扩散模型主要包括两个过程:前向扩散过程和反向去噪过程。前向过程逐渐给数据添加噪声,直到数据变成纯噪声;反向过程则是学习如何从噪声中逐步恢复出原始数据。在生成过程中,模型从一个随机噪声开始,通过多次迭代去噪&a…...

Banana Pi OpenWRT One Wifi6 OpenWrt社区官方开源路由器评测
第一款不可破解、开源、版权软件、符合 FCC、CE 和 RoHS 的维修权路由器 OpenWRT项目今年已经20岁了,为了纪念这一时刻,Banana Pi OpenWrt One/AP-24.XY路由器开发系统已经上市。这是OpenWRT团队与硬件公司的第一个联合项目。选择 Banana Pi,…...

9.1go结构体
Go不是完全面向对象的,没有类的概念,所以结构体应该承担了更多的责任。 结构体定义 使用 type 和 struct 关键字定义: type Person struct { Name string Age int } 字段可以是任意类型,包括其他结构体或指针。 字段名以大写…...

Manus全球首个通用Agent,Manus AI:Agent应用的ChatGPT时刻
文章目录 前言Manus AI: 全球首个通用AgentManus AI: 技术架构与创始人经历AI Agent的实现框架与启示AI Agent的发展预测行业风险提示 前言 这是一篇关于Manus AI及其在通用人工智能领域的应用和前景的报告,主要介绍了Manus AI的产品定位、功能、技术架构、创始人经…...
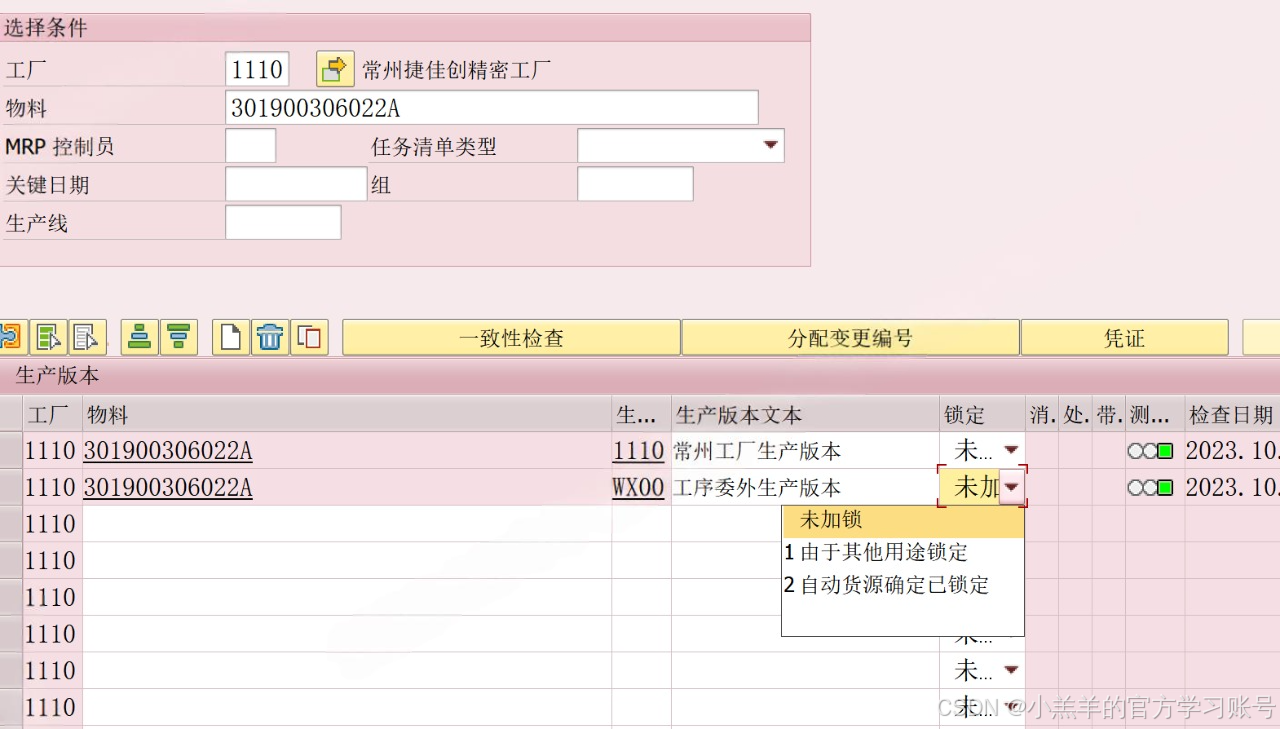
【SAP-PP】生产版本维护
一、基本概念 生产版本:用于定义一种产品,不同的生产方式,包含物料清单(BOM)和工艺路线的信息,给生产带来更多的灵活性。在做产品需求计划时和产品生产时(创建生产订单、生产订单下达前和生产订…...

软考 中级软件设计师 考点笔记总结 day01
文章目录 软考1.0上午考点下午考点 软考1.11、数值及其转换2、计算机内数据表示2.1、定点数 - 浮点数2.2、奇偶校验 和 循环冗余校验 (了解)2.3、海明码 (掌握)2.4、机器数 软考1.0 上午考点 软件工程基础知识: 开发模型、设计原则、测试方…...

K8s控制器Deployment详解
回顾 ReplicaSet 控制器,该控制器是用来维护集群中运行的 Pod 数量的,但是往往在实际操作的时候,我们反而不会去直接使用 RS,而是会使用更上层的控制器,比如说 Deployment。 Deployment 一个非常重要的功能就是实现了 Pod 的滚动…...

【微知】Centos如何迁移到Anolis系统的失败记录?(yum -y install centos2anolis、centos2anolis.py)
背景 本文记录如何从centos 8迁移到anolis系统。 详细步骤 下载迁移repo wget https://mirrors.openanolis.cn/anolis/migration/anolis-migration.repo -O /etc/yum.repos.d/anolis-migration.repo下载centos2anolis工具包 yum -y install centos2anolis安装额外工具包 …...

在 macOS 上使用 CLion 进行 Google Test 单元测试
介绍 Google Test(GTest)是 Google 开源的 C 单元测试框架,它提供了简单易用的断言、测试夹具(Fixtures)和测试运行机制,使 C 开发者能够编写高效的单元测试。 本博客将介绍如何在 macOS 上使用 CLion 配…...

Python SQLite3 保姆级教程:从零开始学数据库操作
Python SQLite3 保姆级教程:从零开始学数据库操作 本文适合纯新手!无需任何数据库基础,跟着步骤操作即可掌握 SQLite3 的核心用法。 目标:让你像用记事本一样轻松操作数据库! 目录 什么是 SQLite3?环境准…...

深度解析:视频软编码与硬编码的优劣对比
视频编码 一、基本原理与核心技术 压缩原理 通过时空冗余消除实现数据压缩: 空间冗余:利用帧内预测(如DC/角度预测)消除单帧内相邻像素相似性。时间冗余:运动估计与补偿技术(ME/MC)减少连续帧间…...

Azure云生态系统详解:核心服务、混合架构与云原生概念
核心服务:深入掌握Azure SQL Database、Azure Database for PostgreSQL、Azure Database for MySQL的架构、备份恢复、高可用性配置(如Geo-Replication、自动故障转移组、异地冗余备份)。混合架构:熟悉Azure Arc(管理混…...

人工智能之数学基础:正交矩阵
本文重点 正交矩阵是线性代数中一个重要的特殊矩阵,它在许多领域都有广泛的应用。 什么是正交矩阵 如图所示,当矩阵A满足如上所示的条件的时候,此时我们就可以认为是正交矩阵,需要注意一点矩阵A必为方阵。 正交矩阵的充要条件 …...

分布式锁—7.Curator的分布式锁
大纲 1.Curator的可重入锁的源码 2.Curator的非可重入锁的源码 3.Curator的可重入读写锁的源码 4.Curator的MultiLock源码 5.Curator的Semaphore源码 1.Curator的可重入锁的源码 (1)InterProcessMutex获取分布式锁 (2)InterProcessMutex的初始化 (3)InterProcessMutex.…...

【笔记】STM32L4系列使用RT-Thread Studio电源管理组件(PM框架)实现低功耗
硬件平台:STM32L431RCT6 RT-Thread版本:4.1.0 目录 一.新建工程 二.配置工程 编辑 三.移植pm驱动 四.配置cubeMX 五.修改驱动文件,干掉报错 六.增加用户低功耗逻辑 1.设置唤醒方式 2.设置睡眠时以及唤醒后动作 编辑 3.增加测试命…...

C++什么是深复制和浅复制,构造函数和析构函数,哪一个可以写成虚函数,为什么?
在C之中深复制是指对于值类型复制它的值,对于指针类型不仅仅复制指针指向的值,还会重新分配一个内存空间用于放置复制的值(对动态分配的内存进行重新分配和内存复制),这种深复制不会出现悬空指针的问题,但是…...

从连接到交互:SDN 架构下 OpenFlow 协议的流程与报文剖析
在SDN架构中,交换机与控制器之间的通信基于 OpenFlow协议,其设计目的是实现控制平面与数据平面的解耦。以下是 交换机连接控制器 和 数据包进入交换机触发交互 的详细流程及协议报文分析: 一、交换机连接控制器的流程(初始化阶段&…...

第七课:Python反爬攻防战:Headers/IP代理与验证码
在爬虫开发过程中,反爬虫机制成为了我们必须面对的挑战。本文将深入探讨Python爬虫中常见的反爬机制,并详细解析如何通过随机User-Agent生成、代理IP池搭建以及验证码识别来应对这些反爬策略。文章将包含完整的示例代码,帮助读者更好地理解和…...

Golang学习笔记_47——访问者模式
Golang学习笔记_44——命令模式 Golang学习笔记_45——备忘录模式 Golang学习笔记_46——状态模式 文章目录 一、核心概念1. 定义2. 解决的问题3. 核心角色4. 类图 二、特点分析三、适用场景1. 编译器实现2. 财务系统3. UI组件系统 四、Go语言实现示例完整实现代码执行结果 五、…...

软件高级架构师 - 软件工程
补充中 测试 测试类型 静态测试 动态测试 测试阶段 单元测试中,包含性能测试,如下: 集成测试中,包含以下: 维护 遗留系统处置 高水平低价值:采取集成 对于这类系统,采取 集成 的方式&…...

肿瘤样本SV分析避坑指南:Delly somatic检测中那些容易忽略的过滤与注释细节
肿瘤样本SV分析避坑指南:Delly somatic检测中那些容易忽略的过滤与注释细节 在癌症基因组学研究中,结构变异(SV)的准确检测对于理解肿瘤发生机制和寻找潜在治疗靶点至关重要。Delly作为一款广泛使用的SV检测工具,其som…...

CST实战指南 | 场路协同仿真中的元器件模型导入与验证
1. 场路协同仿真中的元器件模型导入基础 我第一次接触CST场路协同仿真时,最头疼的就是如何把各种元器件模型正确导入到仿真环境中。经过多次项目实践,我发现这其实是个系统性工程,需要根据不同的仿真场景和元器件类型采取不同的处理策略。 在…...

从入门到精通:trtexec命令行工具在TensorRT模型部署中的实战指南
1. trtexec工具基础入门 第一次接触trtexec时,我也被这个命令行工具的参数数量吓到了。但实际用下来发现,它就像瑞士军刀一样,虽然功能多但每个都很实用。trtexec是TensorRT安装包自带的命令行工具,主要用来做三件事:…...

小白程序员看过来!TS同学半年逆袭AI大模型产品经理,收藏这份转行避坑指南!
TS同学从景观设计转行AI大模型产品经理的经历分享。他经历了离职、脱产学习、国企子公司项目被裁等波折,最终以20%薪资涨幅加入AI公司。文章重点介绍了他的心态调整、求职策略变化以及对“稳定”的新理解,同时探讨了AI时代教育孩子的思考。 本期嘉宾TS同…...

工业级RS-485收发器自主设计:从电路原理到PCB布局的实战指南
1. 项目概述与核心价值 在工业自动化、楼宇控制、能源监控这些领域里,设备之间要“说话”,RS-485总线绝对是那个最可靠、最耐用的“方言”。你可能在PLC、变频器、智能电表或者一堆传感器上见过那两个标着A、B的端子,背后驱动它们的ÿ…...

CircuitPython开发板选型指南:从需求到Adafruit产品实战解析
1. 项目概述:为什么选择CircuitPython开发板是个技术活如果你刚开始接触硬件编程,或者是从Arduino转向更友好的开发环境,那么CircuitPython绝对是一个让人眼前一亮的选项。它把Python的简洁语法带到了微控制器上,让你能用几行代码…...

AI Agents 越智能,企业的人类判断力需求反而会爆炸式增长:Jevons 悖论在企业落地中的隐形反弹
在企业全面拥抱 AI Agents 的当下,最容易被忽略的不是模型能力,而是“智能变便宜”之后带来的责任边界扩张。产品团队让 Agent 自动起草客户邮件、更新工单、标记流失风险、总结销售通话、推荐代码变更、升级支持问题、准备决策材料——每一步都变得前所…...

郎朗乐境音乐会定档7月5日深圳:以破界之姿,开启全维感官盛宴
2026年7月5日,郎朗乐境音乐会将在深圳市宝安体育中心体育馆启幕,作为“深圳国际形象大使”的郎朗,将在这座以创新著称的国际化都市,,进一步探索艺术表达形式的多重可能,呈现一场融合音乐、文化与多维感官体…...

3DMax对齐功能全解析:从基础操作到高阶建模实战
1. 3DMax对齐功能基础入门 刚接触3D建模的新手最常遇到的困扰就是:为什么我的模型总是对不齐?记得我第一次用3DMax做建筑模型时,花了两小时都没能把一扇窗户准确地装到墙面上。直到后来掌握了对齐工具,才发现原来这种问题5秒钟就能…...

AI与Web3融合:Solana开发者工具箱core-ai架构解析与实践
1. 项目概述:当AI遇见Web3,一个开发者工具箱的诞生最近在Web3和AI的交叉领域里折腾,发现了一个挺有意思的项目——helius-tech-labs/core-ai。这名字听起来就很有野心,core(核心)和ai(人工智能&…...