关于sqlalchemy的使用
关于sqlalchemy的使用
- 说明
- 一、sqlachemy总体使用思路
- 二、安装与创建库、连结库
- 三、创建表、增加数据
- 四、查询记录
- 五、更新或删除
- 六、关联表定义
- 七、一对多关联查询
- 八、映射类定义与添加记录
说明
- 本教程所需软件及库python3.10、sqlalchemy
- 安装与创建库、连结库
- 创建表、增加数据
- 查询记录
- 更新或删除
- 关联表定义
一、sqlachemy总体使用思路
- 在创建或连结后会返回engine(可以参考第二节安装与创建库、连结库)
- 在创建表后会返回一个表名(可以参考第三节创建表、增加数据)
- 使用时表名.方法.属性
- 方法有insert,select,update,delecte
- 与数据对接时,conn = engine.connect()—conn.execut(表方法返回的值)
- 当数据库的数据发生改变时,要提交(conn.commit())
- 查询时,要注意条件,有两种方法where() | or_ | and_
二、安装与创建库、连结库
- 安装库
pip install sqlalchemy
#查看版本
sqlalchemy.__vetrsion__
- 创建库或连结库
#连结或创建sqlite3
from sqlalchemy import create_engine
engine = create_engine('sqlite:///db_path.db',echo=True)
conn = engine.connect()
#连结或创建mysql
from sqlalchemy import create_engine
engine = create_engine('mysql://user:pwd@localhoast/库名',echo=True)
conn = engine.connect()
注:create_engine如果已经存在就连结,如果不存在就创建。
- 在sqlalchemy执行sql语句
import sqlachemy
query = sqlachemy.text("select * from 表名")#sql语句
engine = sqlalchemy.create_engine(`sqlite:///db_path.db`,echo=True)
conn = engine.connect()
result_set = conn.execute(query)
print(result_set.all())
conn.close()
engine.dispose()
注:以下代码engine代表创建或检查数据库,conn代表连结数据库。
三、创建表、增加数据
- 创建表
创建表要用到sqlalchemy的三个库MetaData、Table、Column及类型代码
from sqlalchemy import MetaData,Table,Column
meta = MetaData()
#Meta定义好的字段属性存在这,所以第二个字段就要传它
var = Table(
'表名',meta,
Clolumn('字段名',sqlachemy.类型,primary_key=True),
.......
)
meta.create_all(engine)#创建表
如果表已经存在了,就不会创建,如果不存在就创建。
2. sqlachemy字段类型
| 名称 | 字段英文 | 用法 | 说明 |
|---|---|---|---|
| 整形 | Integer | Integer | 存整数 |
| 小数 | 存小数 | ||
| 字符 | String | String(字符个数) | 存字符 |
| 日期 | Date | Date | 存年月日 |
| – | – | – | – |
注:主键primary_key=True,unique=True唯一,unllable=True不能为空。
- 增加数据(insert)
3.1 插入一条数据
var = 表名.insert().values(字段名=值,......)
with engine.connect() as conn:conn.execute(var)conn.commit()
1、连结conn以后执行数据库操作要用conn.execut(sqlachemy语句)
2、数据库数据有变要提交事务,conn.commit()
3、var = 表名.insert().values(字段名=值,…)是新增数据的sqlachemy语句
4、 自增长是插一次,它就增加一次,它不管你是否成功
3.2 插入多条数据
var = 表名.insert()
with engine.connect() as conn:conn.execute(var,[{'字段名':value,.......},{'字段名':value,.......},........])conn.commit()
这个要用列表,并且列表里放字典,key是字段名,value是对应的值
四、查询记录
- sql查询语句
select * from 表名
- 函数表达式
表名.select()
- 结果获取
结果.fetchall()#获取所有数据
结果.fetchone()#获取第一条数据
- 条件查询
表名.select().where(表名.c.字段名条件)
#一次只能有一个条件
#如果多个条件查询时,在后面加.where(表名.c.字段名条件)
- and_(与)、or_(或)
from sqlalchemy.sql import and_,or_
表名.select().where(or_(条件,条件.....) | and_(条件,条件.....))
# 要在where中使用and_,or_
# and_,or_可以相互嵌套
五、更新或删除
- 更新
表名.update().where(条件).values(字段名=value)
#查询结果后再更新值,一个values可以更新多条记录或所有记录,取决于查询的结果
- 删除
表名.delete().where(条件)
#查询结果后再删除,可以删除多条记录或所有记录,取决于查询的结果
六、关联表定义
- 一对多关联(sqlachemy.ForeignKey(‘表名.id’))
import sqlalchemy
#创建表
mate = sqlalchemy.MateData()
表名 = sqlachemy.Table('表名',mate,sqlachemy.Column('字段名',sqlachemy.Integer,sqlachemy.ForeignKey('关联的表名.id'),nullable=False),)
- 多对多
七、一对多关联查询
- 查询条件
imort sqlalchemy
join = 关联表名.join(被关联表名,关联表名.c.id==被关联表名.c.id)
- 使用查询
imort sqlalchemy
join = 关联表名.join(被关联表名,关联表名.c.id==被关联表名.c.id)
#关联表和被关联表的信息都显示
query = sqlalchemy.select(join).where(关联表或被关联表.字段=value)
#只显示关联表或被关联表的信息
query = sqlalchemy.select(被关联表名或关联表名).select_from(join).where(关联表或被关联表.字段=value)
print(conn.execute(query).fetchall())
八、映射类定义与添加记录
- 映射基础
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()class 类名(Base):__tablename__='表名'字段名 = Column(类型,其它参数)......
#创建表
类名.metadata.create_all(engine)
- 利用类添加记录
from sqlalchemy.orm import sessionmakerSession = sessionmaker(bind=engine)session = Session()
#上面的类名
#增加一条记录
var = 类名(字段名=value,......)#类名实例化
session.add(var)
session.commit()
#增加多条记录
varList = [类名实例化列表]
session.add_all(varList)
session.commit()
相关文章:

关于sqlalchemy的使用
关于sqlalchemy的使用 说明一、sqlachemy总体使用思路二、安装与创建库、连结库三、创建表、增加数据四、查询记录五、更新或删除六、关联表定义七、一对多关联查询八、映射类定义与添加记录 说明 本教程所需软件及库python3.10、sqlalchemy安装与创建库、连结库创建表、增加数…...
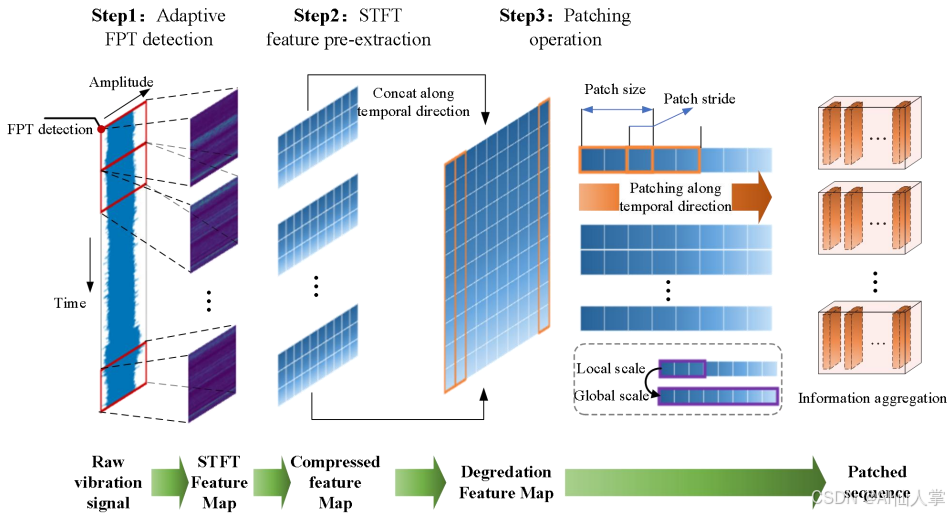
利用LLMs准确预测旋转机械(如轴承)的剩余使用寿命(RUL)
研究背景 研究问题:如何准确预测旋转机械(如轴承)的剩余使用寿命(RUL),这对于设备可靠性和减少工业系统中的意外故障至关重要。研究难点:该问题的研究难点包括:训练和测试阶段数据分布不一致、长期RUL预测的泛化能力有限。相关工作:现有工作主要包括基于模型的方法、数…...

深度学习 PyTorch 中 18 种数据增强策略与实现
深度学习pytorch之简单方法自定义9类卷积即插即用 数据增强通过对训练数据进行多种变换,增加数据的多样性,它帮助我们提高模型的鲁棒性,并减少过拟合的风险。PyTorch 提供torchvision.transforms 模块丰富的数据增强操作,我们可以…...

视觉图像处理
在MATLAB中进行视觉图像处理仿真通常涉及图像增强、滤波、分割、特征提取等操作。以下是一个分步指南和示例代码,帮助您快速入门: 1. MATLAB图像处理基础步骤 1.1 读取和显示图像 % 读取图像(替换为实际文件路径) img = imread(lena.jpg); % 显示原图 figure; subplot(2…...

深度学习与普通神经网络有何区别?
深度学习与普通神经网络的主要区别体现在以下几个方面: 一、结构复杂度 普通神经网络:通常指浅层结构,层数较少,一般为2-3层,包括输入层、一个或多个隐藏层、输出层。深度学习:强调通过5层以上的深度架构…...

Vue3、vue学习笔记
<!-- Vue3 --> 1、Vue项目搭建 npm init vuelatest cd 文件目录 npm i npm run dev // npm run _ 这个在package.json中查看scripts /* vue_study\.vscode可删 // vue_study\src\components也可删除(基本语法,不使用组件) */ // vue_study\.vscode\lau…...

python中C#类库调用+调试方法~~~
因为开发需要,我们经常会用C#来写一些库供python调用,但是在使用过程中难免会碰到一些问题,需要我们抽丝剥茧来解决~~~ 首先,我们在python中要想调用C#(基于.net)的dll,需要安装一个库,它就是 pythonnet …...

L33.【LeetCode笔记】循环队列(数组解法)
目录 1.题目 2.分析 方法1:链表 尝试使用单向循环链表模拟 插入节点 解决方法1:开辟(k1)个节点 解决方法2:使用变量size记录队列元素个数 获取队尾元素 其他函数的实现说明 方法2:数组 重要点:指针越界的解决方法 方法1:单独判断 方法2:取模 3.数组代码的逐步实现…...

css实现元素垂直居中显示的7种方式
文章目录 * [【一】知道居中元素的宽高](https://blog.csdn.net/weixin_41305441/article/details/89886846#_1) [absolute 负margin](https://blog.csdn.net/weixin_41305441/article/details/89886846#absolute__margin_2) [absolute margin auto](https://blog.csdn.net…...

【Python】Django 中的算法应用与实现
Django 中的算法应用与实现 在 Django 开发中,算法的应用可以极大地扩展 Web 应用的功能和性能。从简单的数据处理到复杂的机器学习模型,Django 都可以作为一个强大的后端框架来支持这些算法的实现。本文将介绍几种常见的算法及其在 Django 中的使用方法…...

Docker 运行 GPUStack 的详细教程
GPUStack GPUStack 是一个用于运行 AI 模型的开源 GPU 集群管理器。它具有广泛的硬件兼容性,支持多种品牌的 GPU,并能在 Apple MacBook、Windows PC 和 Linux 服务器上运行。GPUStack 支持各种 AI 模型,包括大型语言模型(LLMs&am…...
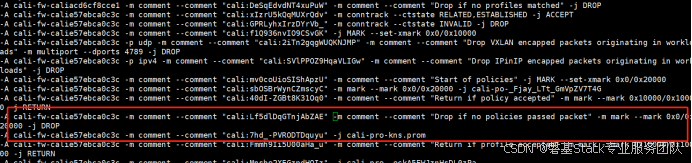
Kubernetes中的 iptables 规则介绍
#作者:邓伟 文章目录 一、Kubernetes 网络模型概述二、iptables 基础知识三、Kubernetes 中的 iptables 应用四、查看和调试 iptables 规则五、总结 在 Kubernetes 集群中,iptables 是一个核心组件, 用于实现服务发现和网络策略。iptables 通…...
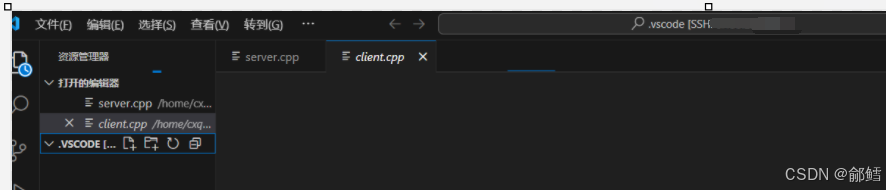
解决VScode 连接不上问题
问题 :VScode 连接不上 解决方案: 1、手动杀死VS Code服务器进程,然后重新尝试登录 打开xshell ,远程连接服务器 ,查看vscode的进程 ,然后全部杀掉 [cxqiZwz9fjj2ssnshikw14avaZ ~]$ ps ajx | grep vsc…...

AI 驱动的软件测试革命:从自动化到智能化的进阶之路
🚀引言:软件测试的智能化转型浪潮 在数字化转型加速的今天,软件产品的迭代速度与复杂度呈指数级增长。传统软件测试依赖人工编写用例、执行测试的模式,已难以应对快速交付与高质量要求的双重挑战。人工智能技术的突破为测试领域注…...
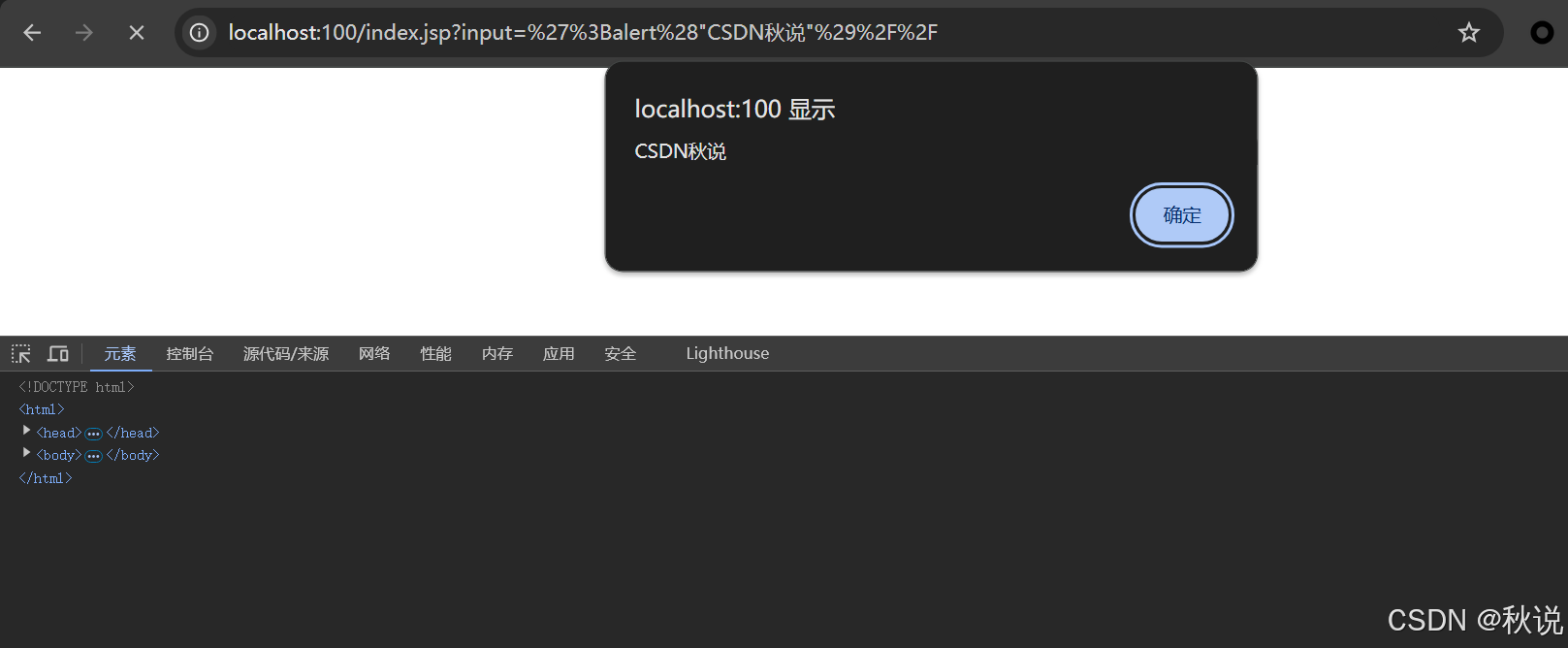
【Java代码审计 | 第六篇】XSS防范
文章目录 XSS防范使用HTML转义使用Content Security Policy (CSP)输入验证使用安全的库和框架避免直接使用用户输入构建JavaScript代码 XSS防范 使用HTML转义 在输出用户输入时,对特殊字符进行转义,防止它们被解释为HTML或JavaScript代码。 例如&…...

Android WebSocket工具类:重连、心跳、消息队列一站式解决方案
依赖库 使用 OkHttp 的WebSocket支持。 在 build.gradle 中添加依赖: implementation com.squareup.okhttp3:okhttp:4.9.3WebSocket工具类实现 import okhttp3.*; import android.os.Handler; import android.os.Looper; import android.util.Log;import java.ut…...

认识vue2脚手架
1.认识脚手架结构 使用VSCode将vue项目打开: package.json:包的说明书(包的名字,包的版本,依赖哪些库)。该文件里有webpack的短命令: serve(启动内置服务器) build命令…...
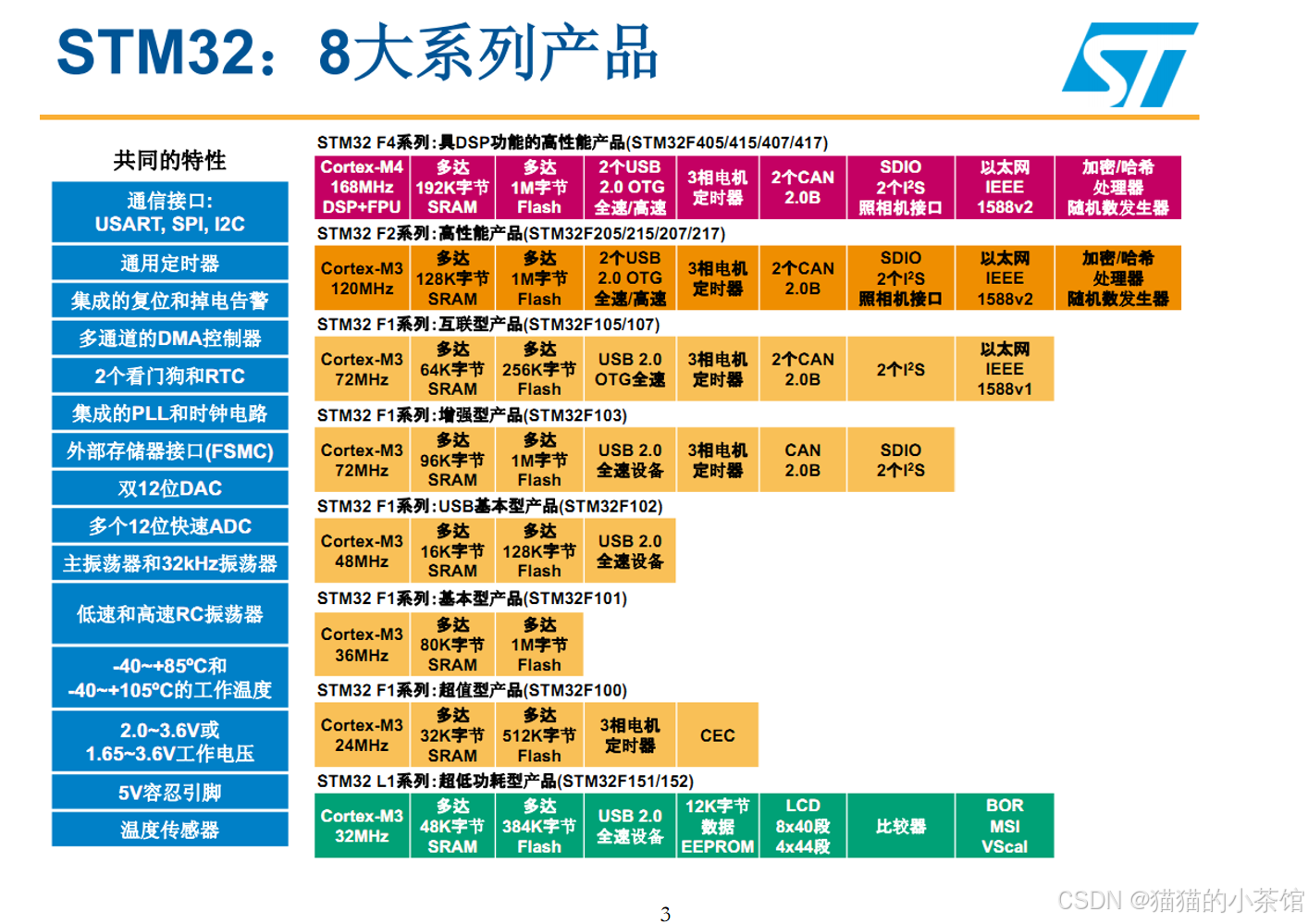
【STM32】STM32系列产品以及新手入门的STM32F103
📢 STM32F103xC/D/E 系列是一款高性能、低功耗的 32 位 MCU,适用于工业、汽车、消费电子等领域;基于 ARM Cortex-M3,主频最高 72MHz,支持 512KB Flash、64KB SRAM,适合复杂嵌入式应用,提供丰富的…...
<建模软件安装教程1>Blender4.2系列
Blender4.2安装教程 0注意:Windows环境下安装 第一步,百度网盘提取安装包。百度网盘链接:通过网盘分享的文件:blender.zip 链接: https://pan.baidu.com/s/1OG0jMMtN0qWDSQ6z_rE-9w 提取码: 0309 --来自百度网盘超级会员v3的分…...

CentOS Docker 安装指南
CentOS Docker 安装指南 引言 Docker 是一个开源的应用容器引擎,它允许开发者打包他们的应用以及应用的依赖包到一个可移植的容器中,然后发布到任何流行的 Linux 机器上,也可以实现虚拟化。Docker 容器是完全使用沙箱机制,相互之…...

智慧无人机巡检-无人机可见光红外数据集 无人机多模态检测数据集 红外与可见光检测数据集
智慧无人机巡检-无人机可见光红外数据集,已完成标注,可导出各种常用数据集,yolo,voc,coco等格式。可见光33000张,红外16100张,目标一张一个 无人机可见光红外目标数据集项目详细信息数据集名称无…...

基于Netburner NANO54415构建工业级嵌入式Web服务器:从硬件选型到广域监控实战
1. 项目概述:一个为广域与本地监控而生的嵌入式Web服务器如果你正在寻找一个能部署在野外、工厂角落或者任何需要远程数据采集与控制场景下的嵌入式Web服务器方案,并且对市面上那些要么性能孱弱、要么开发门槛极高的开发板感到厌倦,那么这个基…...

从零构建FOC轮腿机器人:开源平衡机器人完整指南
从零构建FOC轮腿机器人:开源平衡机器人完整指南 【免费下载链接】foc-wheel-legged-robot Open source materials for a novel structured legged robot, including mechanical design, electronic design, algorithm simulation, and software development. | 一个…...
运营管理与服务保障平台建设方案)
低空旅游观光与低空通勤(eVTOL)运营管理与服务保障平台建设方案
本方案旨在为eVTOL载具构建集运营管理、空中交通管制、安全保障与乘客服务于一体的数字化平台。通过微服务架构、5G-A融合感知、空域网格化与零信任安全等核心技术,解决高密度飞行中的资源调度与安全冲突问题。目标实现毫秒级冲突解算与15分钟内快速周转,…...

TII投稿避坑指南:LaTeX模板编译报错‘xxx-eps-converted-to.pdf not found’的终极解决方案
TII投稿LaTeX避坑实战:从编译报错到完美PDF生成的终极指南 凌晨三点的实验室,屏幕上闪烁的xxx-eps-converted-to.pdf not found错误提示仿佛在嘲笑你连续八小时的徒劳尝试。这不是科幻场景,而是每位用LaTeX撰写TII论文的研究者都可能遭遇的真…...

如何用嘎嘎降AI处理金融学论文:金融学毕业论文降AI4.8元完整操作教程
如何用嘎嘎降AI处理金融学论文:金融学毕业论文降AI4.8元完整操作教程 第一次用降AI工具有很多不确定——传什么格式、选哪个模式、怎么验收。 这篇教程把金融学论文降AI教程的常见问题都覆盖了,主要基于嘎嘎降AI(www.aigcleaner.com&#x…...

独立开发者如何利用Taotoken的TokenPlan在项目初期有效控制AI实验成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何利用Taotoken的TokenPlan在项目初期有效控制AI实验成本 对于独立开发者或学生而言,在构建AI应用原型时&…...

如何快速上手SoundMind:10分钟完成音频逻辑推理模型训练
如何快速上手SoundMind:10分钟完成音频逻辑推理模型训练 【免费下载链接】SoundMind We introduce the Audio Logical Reasoning (ALR) dataset, consisting of 6,446 text-audio annotated samples specifically designed for complex reasoning tasks. Building o…...

3个关键步骤:从零开始使用AlphaFold 3进行蛋白质结构预测
3个关键步骤:从零开始使用AlphaFold 3进行蛋白质结构预测 【免费下载链接】alphafold3 AlphaFold 3 inference pipeline. 项目地址: https://gitcode.com/gh_mirrors/alp/alphafold3 AlphaFold 3是DeepMind开发的最新蛋白质结构预测工具,它不仅能…...

终极指南:5步精通开源网页版三国杀无名杀
终极指南:5步精通开源网页版三国杀无名杀 【免费下载链接】noname 项目地址: https://gitcode.com/GitHub_Trending/no/noname 想要随时随地畅玩经典的三国杀卡牌游戏吗?无名杀作为当前最受欢迎的开源网页版三国杀,让你无需下载客户端…...