【Python】Django 中的算法应用与实现
Django 中的算法应用与实现
在 Django 开发中,算法的应用可以极大地扩展 Web 应用的功能和性能。从简单的数据处理到复杂的机器学习模型,Django 都可以作为一个强大的后端框架来支持这些算法的实现。本文将介绍几种常见的算法及其在 Django 中的使用方法。
1\.协同过滤算法
1.1 算法简介
协同过滤是一种常用的推荐系统算法,通过分析用户的行为数据(如评分、浏览历史等),为用户推荐他们可能感兴趣的内容。常见的协同过滤算法包括基于用户的协同过滤(User-based CF)和基于物品的协同过滤(Item-based CF)。
1.2 Django 中的实现
以下是一个简单的基于用户的协同过滤算法实现:
数据库模型
from django.db import modelsclass User(models.Model):name = models.CharField(max_length=100)class Item(models.Model):name = models.CharField(max_length=100)class Rating(models.Model):user = models.ForeignKey(User, on_delete=models.CASCADE)item = models.ForeignKey(Item, on_delete=models.CASCADE)rating = models.FloatField()协同过滤算法
import numpy as npfrom django.db.models import Avgdef user_based_cf(user_id, num_recommendations=5):# 获取所有用户的评分数据ratings = Rating.objects.all().values('user_id', 'item_id', 'rating')ratings = list(ratings)# 构建用户-物品评分矩阵user_item_matrix = {}for rating in ratings:user_id = rating['user_id']item_id = rating['item_id']score = rating['rating']if user_id not in user_item_matrix:user_item_matrix[user_id] = {}user_item_matrix[user_id][item_id] = score# 计算用户相似度def cosine_similarity(user1, user2):common_items = set(user_item_matrix[user1].keys()) & set(user_item_matrix[user2].keys())if not common_items:return 0vec1 = [user_item_matrix[user1][item] for item in common_items]vec2 = [user_item_matrix[user2][item] for item in common_items]return np.dot(vec1, vec2) / (np.linalg.norm(vec1) * np.linalg.norm(vec2))# 找到与目标用户最相似的用户target_user_ratings = user_item_matrix[user_id]similarities = []for other_user in user_item_matrix:if other_user != user_id:similarity = cosine_similarity(user_id, other_user)similarities.append((other_user, similarity))similarities.sort(key=lambda x: x[1], reverse=True)similar_users = [user for user, sim in similarities[:num_recommendations]]# 生成推荐recommendations = {}for user in similar_users:for item, rating in user_item_matrix[user].items():if item not in target_user_ratings:if item not in recommendations:recommendations[item] = []recommendations[item].append(rating)final_recommendations = []for item, ratings in recommendations.items():avg_rating = sum(ratings) / len(ratings)final_recommendations.append((item, avg_rating))final_recommendations.sort(key=lambda x: x[1], reverse=True)return final_recommendations[:num_recommendations]1.3 使用方法
在视图中调用`user_based_cf`函数,传入用户 ID 和推荐数量,即可获取推荐结果:
from django.shortcuts import renderfrom .models import Itemdef recommend_items(request, user_id):recommendations = user_based_cf(user_id)recommended_items = [Item.objects.get(id=item_id) for item_id, _ in recommendations]return render(request, 'recommendations.html', {'items': recommended_items})2\.KNN 算法
2.1 算法简介
KNN(K-Nearest Neighbors)是一种简单而有效的分类和回归算法。它通过计算数据点之间的距离,找到最近的 K 个邻居,并根据这些邻居的标签来预测目标点的标签。
2.2 Django 中的实现
以下是一个基于 KNN 的分类器实现:
数据库模型
from django.db import modelsclass DataPoint(models.Model):feature1 = models.FloatField()feature2 = models.FloatField()label = models.CharField(max_length=50)KNN 分类器
import numpy as npfrom django.db.models import Qdef knn_classifier(new_point, k=3):# 获取所有数据点data_points = DataPoint.objects.all().values('feature1', 'feature2', 'label')data_points = list(data_points)# 计算欧几里得距离distances = []for point in data_points:distance = np.sqrt((point['feature1'] - new_point[0])**2 + (point['feature2'] - new_point[1])**2)distances.append((point, distance))# 找到最近的 K 个邻居distances.sort(key=lambda x: x[1])neighbors = distances[:k]# 统计邻居的标签labels = [neighbor[0]['label'] for neighbor in neighbors]most_common_label = max(set(labels), key=labels.count)return most_common_label2.3 使用方法
在视图中调用`knn_classifier`函数,传入新的数据点和邻居数量,即可获取分类结果:
from django.http import JsonResponsedef classify_point(request):feature1 = float(request.GET.get('feature1'))feature2 = float(request.GET.get('feature2'))label = knn_classifier((feature1, feature2))return JsonResponse({'label': label})3\.机器学习模型集成
3.1 算法简介
Django 可以与机器学习库(如 scikit-learn、TensorFlow 等)结合,实现复杂的机器学习模型。这些模型可以用于分类、回归、预测等多种任务。
3.2 Django 中的实现
以下是一个使用 scikit-learn 预测房价的示例:
数据库模型
from django.db import modelsclass House(models.Model):area = models.FloatField()bedrooms = models.IntegerField()price = models.FloatField()加载和使用模型
import pickleimport osfrom django.conf import settingsfrom sklearn.linear_model import LinearRegression# 加载模型def load_model():model_path = os.path.join(settings.BASE_DIR, 'models', 'house_price_model.pkl')with open(model_path, 'rb') as file:model = pickle.load(file)return model# 预测房价def predict_price(area, bedrooms):model = load_model()features = [[area, bedrooms]]predicted_price = model.predict(features)[0]return predicted_price3.3 使用方法
在视图中调用`predict_price`函数,传入房屋特征,即可获取预测结果:
from django.http import JsonResponsedef predict_house_price(request):area = float(request.GET.get('area'))bedrooms = int(request.GET.get('bedrooms'))price = predict_price(area, bedrooms)return JsonResponse({'predicted_price': price})4\.数据处理与分析
4.1 算法简介
Django 可以结合 Pandas 等数据分析库,实现数据的导入、处理和可视化。
4.2 Django 中的实现
以下是一个从 Excel 文件中导入数据并进行处理的示例:
数据库模型
from django.db import modelsclass SalesData(models.Model):category = models.CharField(max_length=100)value = models.FloatField()数据导入与处理
import pandas as pdfrom django.http import JsonResponsefrom django.views.decorators.csrf import csrf_exempt@csrf_exemptdef import_excel(request):if request.method == 'POST':excel_file = request.FILES['file']df = pd.read_excel(excel_file, engine='openpyxl')data = df.to_dict(orient='records')for item in data:SalesData.objects.create(category=item['Category'], value=item['Value'])return JsonResponse({'status': 'success'})return JsonResponse({'status': 'error'})5\.排序算法
5.1 算法简介
排序算法是计算机科学中最基础的算法之一,用于将一组数据按照特定的顺序排列。常见的排序算法包括冒泡排序、快速排序、归并排序等。虽然 Python 内置了高效的排序方法(如`sorted()`和`.sort()`),但在某些场景下,我们可能需要自定义排序逻辑。
5.2 Django 中的实现
以下是一个在 Django 中实现快速排序算法的示例,用于对数据库查询结果进行排序。
数据库模型
from django.db import modelsclass Product(models.Model):name = models.CharField(max_length=100)price = models.FloatField()快速排序算法
def quick_sort(arr, key):if len(arr) <= 1:return arrpivot = arr[len(arr) // 2]left = [x for x in arr if key(x) < key(pivot)]middle = [x for x in arr if key(x) == key(pivot)]right = [x for x in arr if key(x) > key(pivot)]return quick_sort(left, key) + middle + quick_sort(right, key)使用方法
在视图中调用`quick_sort`函数,对查询结果进行排序:
from django.shortcuts import renderdef sorted_products(request):products = Product.objects.all()sorted_products = quick_sort(list(products), key=lambda x: x.price)return render(request, 'products.html', {'products': sorted_products})6\.搜索算法
6.1 算法简介
搜索算法用于在数据集中查找特定的目标值。常见的搜索算法包括线性搜索和二分搜索。在 Django 中,我们通常使用数据库查询来实现搜索功能,但在某些情况下,手动实现搜索算法可以提供更灵活的解决方案。
6.2 Django 中的实现
以下是一个在 Django 中实现二分搜索算法的示例,用于在有序数据中查找目标值。
数据库模型
from django.db import modelsclass Item(models.Model):name = models.CharField(max_length=100)value = models.IntegerField()二分搜索算法
def binary_search(arr, target, key):low, high = 0, len(arr) - 1while low <= high:mid = (low + high) // 2if key(arr[mid]) == target:return midelif key(arr[mid]) < target:low = mid + 1else:high = mid - 1return -1使用方法
在视图中调用`binary_search`函数,对查询结果进行搜索:
from django.shortcuts import renderdef search_item(request, target_value):items = Item.objects.all().order_by('value') # 确保数据有序index = binary_search(list(items), target_value, key=lambda x: x.value)if index != -1:found_item = items[index]return render(request, 'item_found.html', {'item': found_item})else:return render(request, 'item_not_found.html')7\.缓存优化算法
7.1 算法简介
缓存优化算法用于提高系统的性能,通过将频繁访问的数据存储在内存中,减少对数据库的查询次数。常见的缓存策略包括最近最少使用(LRU)和最不经常使用(LFU)。
7.2 Django 中的实现
Django 提供了强大的缓存框架,支持多种缓存后端(如内存缓存、Redis 等)。以下是一个简单的 LRU 缓存实现示例。
缓存工具类
from collections import OrderedDictclass LRUCache:def __init__(self, capacity: int):self.cache = OrderedDict()self.capacity = capacitydef get(self, key: int) -> int:if key not in self.cache:return -1self.cache.move_to_end(key)return self.cache[key]def put(self, key: int, value: int) -> None:if key in self.cache:self.cache.move_to_end(key)self.cache[key] = valueif len(self.cache) > self.capacity:self.cache.popitem(last=False)使用方法
在视图中使用 LRU 缓存来存储频繁访问的数据:from django.shortcuts import renderfrom .cache import LRUCache# 初始化缓存cache = LRUCache(capacity=10)def get_expensive_data(request, key):if cache.get(key) == -1:# 模拟从数据库中获取数据data = expensive_query(key)cache.put(key, data)else:data = cache.get(key)return render(request, 'data.html', {'data': data})def expensive_query(key):# 模拟耗时查询import timetime.sleep(2)return f"Data for key {key}"8\.图算法
8.1 算法简介
图算法用于处理图结构数据,常见的图算法包括深度优先搜索(DFS)、广度优先搜索(BFS)和最短路径算法(如 Dijkstra 算法)。在 Django 中,图算法可以用于社交网络分析、路径规划等场景。
8.2 Django 中的实现
以下是一个使用广度优先搜索(BFS)算法实现的社交网络好友推荐系统。
数据库模型
from django.db import modelsclass User(models.Model):name = models.CharField(max_length=100)class Friendship(models.Model):user1 = models.ForeignKey(User, on_delete=models.CASCADE, related_name='friendships1')user2 = models.ForeignKey(User, on_delete=models.CASCADE, related_name='friendships2')BFS 算法
from collections import dequedef bfs_recommendations(start_user, depth=2):visited = set()queue = deque([(start_user, 0)])recommendations = []while queue:current_user, current_depth = queue.popleft()if current_depth >= depth:breakvisited.add(current_user.id)friends = Friendship.objects.filter(user1=current_user).values_list('user2', flat=True)friends |= Friendship.objects.filter(user2=current_user).values_list('user1', flat=True)for friend_id in friends:friend = User.objects.get(id=friend_id)if friend.id not in visited:recommendations.append(friend)queue.append((friend, current_depth + 1))return recommendations使用方法
在视图中调用`bfs_recommendations`函数,为用户推荐好友:
from django.shortcuts import renderdef recommend_friends(request, user_id):user = User.objects.get(id=user_id)recommendations = bfs_recommendations(user)return render(request, 'recommendations.html', {'recommendations': recommendations})9\.动态规划算法
9.1 算法简介
动态规划(Dynamic Programming,DP)是一种通过将复杂问题分解为更简单的子问题来求解的算法。它通常用于优化问题,如背包问题、最短路径问题等。
9.2 Django 中的实现
以下是一个经典的动态规划问题——背包问题的实现。假设我们需要根据用户的需求动态计算最优解。
数据库模型
from django.db import modelsclass Item(models.Model):name = models.CharField(max_length=100)weight = models.IntegerField()value = models.IntegerField()动态规划算法
def knapsack(max_weight, items):n = len(items)dp = [[0 for _ in range(max_weight + 1)] for _ in range(n + 1)]for i in range(1, n + 1):for w in range(max_weight + 1):if items[i - 1].weight <= w:dp[i][w] = max(dp[i - 1][w], dp[i - 1][w - items[i - 1].weight] + items[i - 1].value)else:dp[i][w] = dp[i - 1][w]return dp[n][max_weight]使用方法
在视图中调用`knapsack`函数,传入最大重量和物品列表:
from django.shortcuts import renderfrom .models import Itemdef calculate_knapsack(request, max_weight):items = Item.objects.all()max_value = knapsack(max_weight, list(items))return render(request, 'knapsack_result.html', {'max_value': max_value})10\.分治算法
10.1 算法简介
分治算法是一种将复杂问题分解为多个小问题分别求解,然后将结果合并的算法。常见的分治算法包括归并排序、快速幂等。
10.2 Django 中的实现
以下是一个使用分治思想实现的快速幂算法,用于高效计算幂运算。
快速幂算法
def fast_power(base, exponent):if exponent == 0:return 1if exponent % 2 == 0:half_power = fast_power(base, exponent // 2)return half_power * half_powerelse:return base * fast_power(base, exponent - 1)使用方法
在视图中调用`fast_power`函数,传入底数和指数:
from django.http import JsonResponsedef calculate_power(request, base, exponent):result = fast_power(base, exponent)return JsonResponse({'result': result})11\.字符串处理算法
11.1 算法简介
字符串处理算法用于高效处理字符串数据,常见的算法包括 KMP 算法(用于字符串匹配)、最长公共子序列(LCS)等。
11.2 Django 中的实现
以下是一个实现最长公共子序列(LCS)算法的示例,用于比较两个字符串的相似性。
LCS 算法
def lcs(str1, str2):m, n = len(str1), len(str2)dp = [[0] * (n + 1) for _ in range(m + 1)]for i in range(1, m + 1):for j in range(1, n + 1):if str1[i - 1] == str2[j - 1]:dp[i][j] = dp[i - 1][j - 1] + 1else:dp[i][j] = max(dp[i - 1][j], dp[i][j - 1])return dp[m][n]使用方法
在视图中调用`lcs`函数,传入两个字符串:
from django.http import JsonResponsedef compare_strings(request, str1, str2):length = lcs(str1, str2)return JsonResponse({'lcs_length': length})12\.图像处理算法
12.1 算法简介
图像处理算法用于对图像数据进行分析和处理,常见的算法包括边缘检测、图像分割、特征提取等。Django 可以结合 Python 的图像处理库(如 OpenCV、Pillow)实现这些功能。
12.2 Django 中的实现
以下是一个使用 OpenCV 实现的边缘检测算法的示例。
安装依赖
pip install opencv-python边缘检测算法
import cv2import numpy as npfrom django.core.files.base import ContentFilefrom django.core.files.storage import default_storagedef detect_edges(image_path):image = cv2.imread(image_path)gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)edges = cv2.Canny(gray, 100, 200)# 保存处理后的图像_, buffer = cv2.imencode('.png', edges)processed_image = ContentFile(buffer.tobytes())file_name = default_storage.save("processed_image.png", processed_image)return default_storage.url(file_name)使用方法
在视图中调用`detect_edges`函数,传入图像路径:
from django.http import JsonResponsefrom .utils import detect_edgesdef process_image(request):if request.method == 'POST':image_file = request.FILES['image']image_path = default_storage.save("original_image.png", image_file)image_url = default_storage.url(image_path)processed_image_url = detect_edges(image_url)return JsonResponse({'processed_image_url': processed_image_url})return JsonResponse({'error': 'Invalid request'}, status=400)13\.机器学习模型的实时预测
13.1 算法简介
Django 可以与机器学习库(如 scikit-learn、TensorFlow、PyTorch)结合,实现模型的加载和实时预测。这在推荐系统、分类器、预测器等场景中非常有用。
13.2 Django 中的实现
以下是一个使用 scikit-learn 加载预训练模型并进行实时预测的示例。
加载模型
import osimport picklefrom django.conf import settingsdef load_model():model_path = os.path.join(settings.BASE_DIR, 'models', 'classifier.pkl')with open(model_path, 'rb') as file:model = pickle.load(file)return model实时预测
def predict(request):model = load_model()feature1 = float(request.GET.get('feature1'))feature2 = float(request.GET.get('feature2'))features = [[feature1, feature2]]prediction = model.predict(features)[0]return JsonResponse({'prediction': prediction})14\.分布式任务处理
14.1 算法简介
在大型系统中,某些任务可能需要分布式处理以提高效率。Django 可以结合 Celery 和 RabbitMQ 等工具实现异步任务处理。
14.2 Django 中的实现
以下是一个使用 Celery 实现异步任务的示例。
安装依赖
pip install celery redisCelery 配置
# settings.py
CELERY_BROKER_URL = 'redis://localhost:6379/0'CELERY_RESULT_BACKEND = 'redis://localhost:6379/0'定义任务
# tasks.py
from celery import shared_task@shared_taskdef long_running_task(data):# 模拟耗时任务import timetime.sleep(10)return f"Processed {data}"调用任务
from django.http import JsonResponsefrom .tasks import long_running_taskdef trigger_task(request):task = long_running_task.delay("Sample Data")return JsonResponse({'task_id': task.id})相关文章:

【Python】Django 中的算法应用与实现
Django 中的算法应用与实现 在 Django 开发中,算法的应用可以极大地扩展 Web 应用的功能和性能。从简单的数据处理到复杂的机器学习模型,Django 都可以作为一个强大的后端框架来支持这些算法的实现。本文将介绍几种常见的算法及其在 Django 中的使用方法…...

Docker 运行 GPUStack 的详细教程
GPUStack GPUStack 是一个用于运行 AI 模型的开源 GPU 集群管理器。它具有广泛的硬件兼容性,支持多种品牌的 GPU,并能在 Apple MacBook、Windows PC 和 Linux 服务器上运行。GPUStack 支持各种 AI 模型,包括大型语言模型(LLMs&am…...
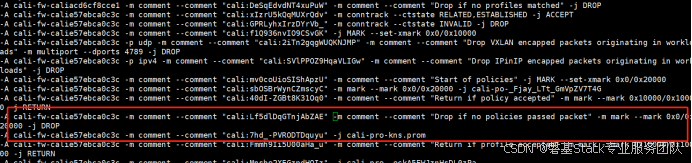
Kubernetes中的 iptables 规则介绍
#作者:邓伟 文章目录 一、Kubernetes 网络模型概述二、iptables 基础知识三、Kubernetes 中的 iptables 应用四、查看和调试 iptables 规则五、总结 在 Kubernetes 集群中,iptables 是一个核心组件, 用于实现服务发现和网络策略。iptables 通…...
解决VScode 连接不上问题
问题 :VScode 连接不上 解决方案: 1、手动杀死VS Code服务器进程,然后重新尝试登录 打开xshell ,远程连接服务器 ,查看vscode的进程 ,然后全部杀掉 [cxqiZwz9fjj2ssnshikw14avaZ ~]$ ps ajx | grep vsc…...

AI 驱动的软件测试革命:从自动化到智能化的进阶之路
🚀引言:软件测试的智能化转型浪潮 在数字化转型加速的今天,软件产品的迭代速度与复杂度呈指数级增长。传统软件测试依赖人工编写用例、执行测试的模式,已难以应对快速交付与高质量要求的双重挑战。人工智能技术的突破为测试领域注…...
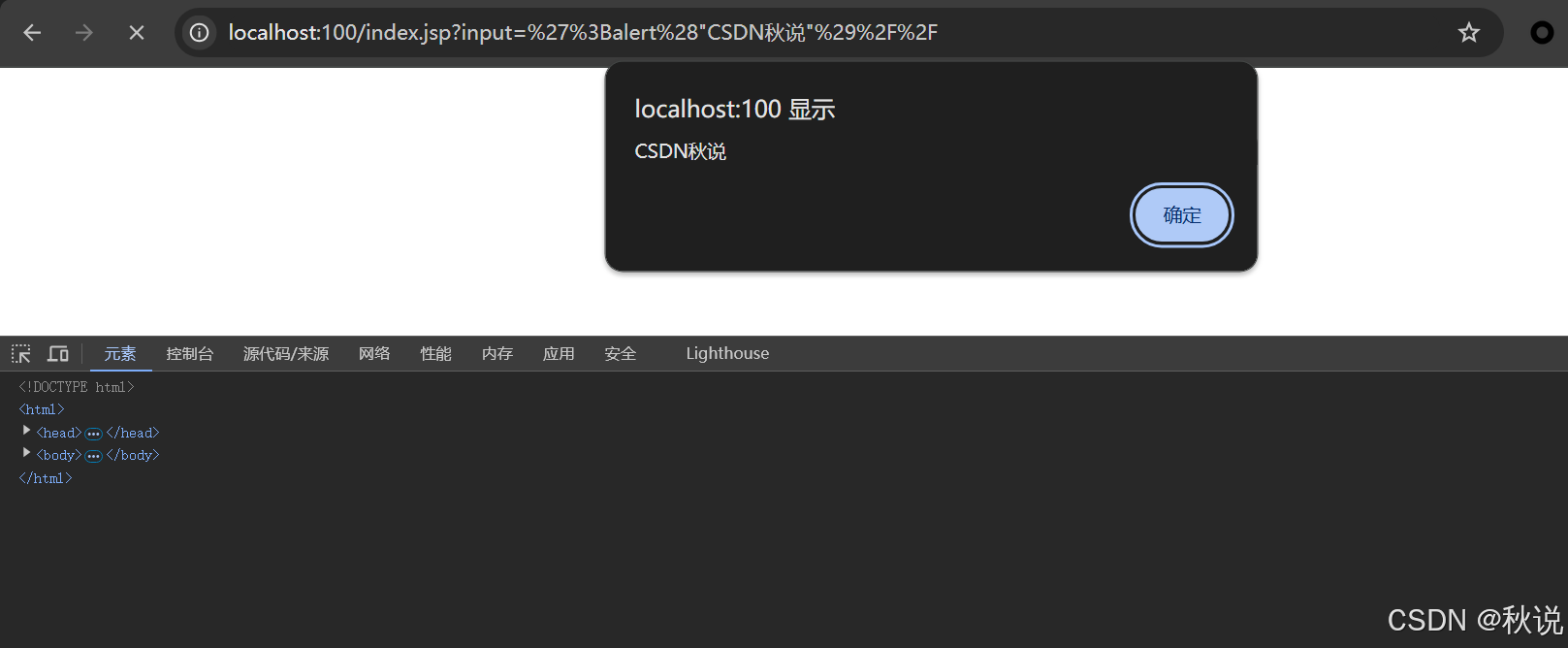
【Java代码审计 | 第六篇】XSS防范
文章目录 XSS防范使用HTML转义使用Content Security Policy (CSP)输入验证使用安全的库和框架避免直接使用用户输入构建JavaScript代码 XSS防范 使用HTML转义 在输出用户输入时,对特殊字符进行转义,防止它们被解释为HTML或JavaScript代码。 例如&…...

Android WebSocket工具类:重连、心跳、消息队列一站式解决方案
依赖库 使用 OkHttp 的WebSocket支持。 在 build.gradle 中添加依赖: implementation com.squareup.okhttp3:okhttp:4.9.3WebSocket工具类实现 import okhttp3.*; import android.os.Handler; import android.os.Looper; import android.util.Log;import java.ut…...

认识vue2脚手架
1.认识脚手架结构 使用VSCode将vue项目打开: package.json:包的说明书(包的名字,包的版本,依赖哪些库)。该文件里有webpack的短命令: serve(启动内置服务器) build命令…...
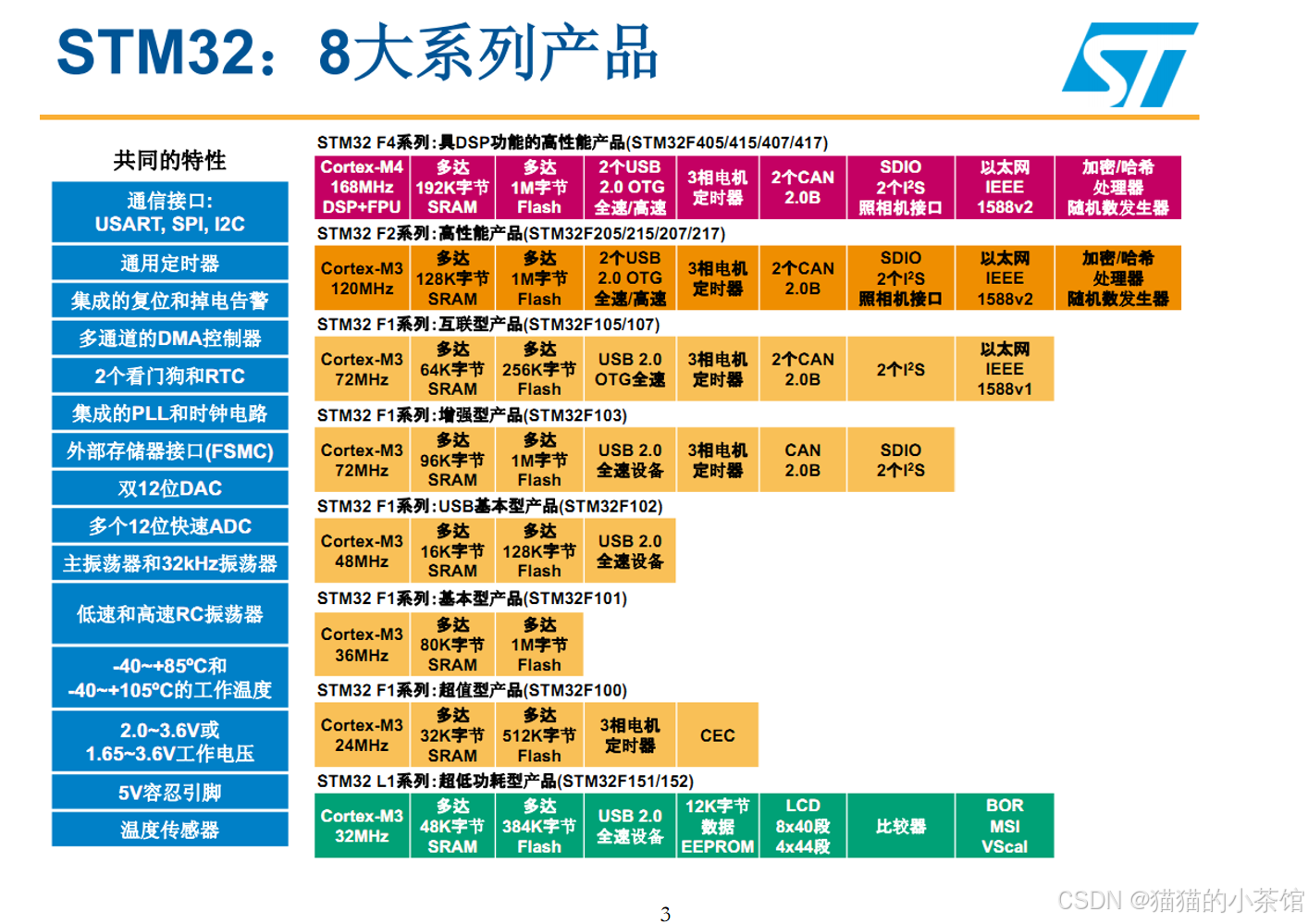
【STM32】STM32系列产品以及新手入门的STM32F103
📢 STM32F103xC/D/E 系列是一款高性能、低功耗的 32 位 MCU,适用于工业、汽车、消费电子等领域;基于 ARM Cortex-M3,主频最高 72MHz,支持 512KB Flash、64KB SRAM,适合复杂嵌入式应用,提供丰富的…...
<建模软件安装教程1>Blender4.2系列
Blender4.2安装教程 0注意:Windows环境下安装 第一步,百度网盘提取安装包。百度网盘链接:通过网盘分享的文件:blender.zip 链接: https://pan.baidu.com/s/1OG0jMMtN0qWDSQ6z_rE-9w 提取码: 0309 --来自百度网盘超级会员v3的分…...

CentOS Docker 安装指南
CentOS Docker 安装指南 引言 Docker 是一个开源的应用容器引擎,它允许开发者打包他们的应用以及应用的依赖包到一个可移植的容器中,然后发布到任何流行的 Linux 机器上,也可以实现虚拟化。Docker 容器是完全使用沙箱机制,相互之…...

分布式ID生成方案:数据库号段、Redis与第三方开源实现
分布式ID生成方案:数据库号段、Redis与第三方开源实现 引言 在分布式系统中,全局唯一ID生成是核心基础能力之一。本文针对三种主流分布式ID生成方案(数据库号段模式、Redis方案、第三方开源框架)进行解析,从实现原理…...
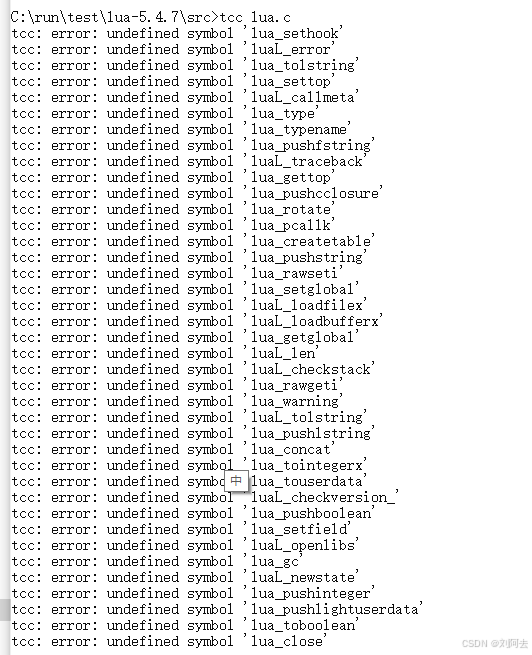
tcc编译器教程2 编译lua解释器
本文主要介绍了使用tcc编译器编译lua解释器源码。 1 介绍 lua是一门编程语言,开源且源码很容易编译,我平时用来测试C语言编程环境时经常使用。一般能编译成功就说明编程环境设置正常。下面用之前设置好的tcc编程环境进行测试。 2 获取源码 我一般有保留多个版本的lua源码进…...
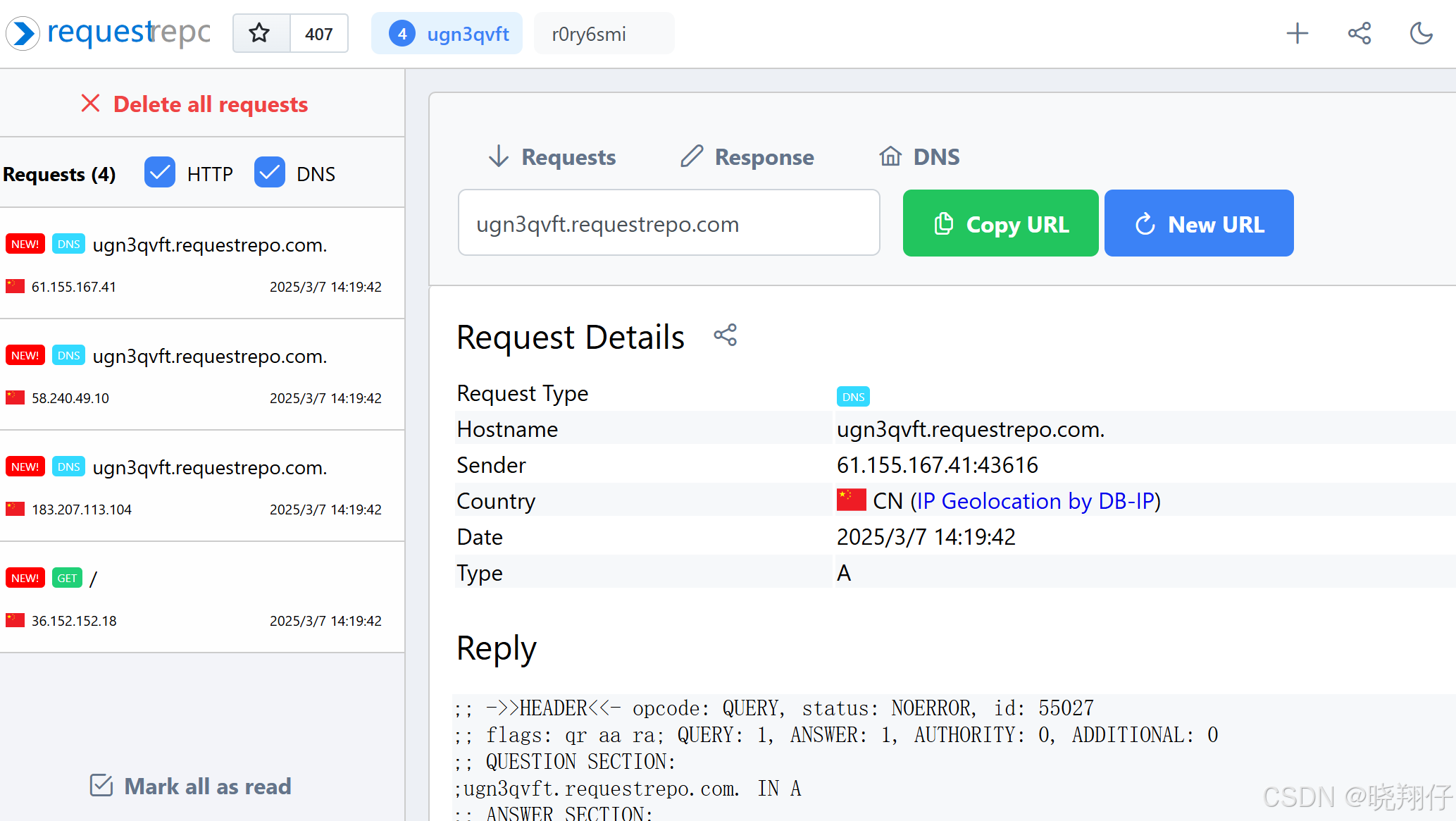
利用 requestrepo 工具验证 XML外部实体注入漏洞
1. 前言 在数字化浪潮席卷的当下,网络安全的重要性愈发凸显。应用程序在便捷生活与工作的同时,也可能暗藏安全风险。XXE(XML外部实体)漏洞作为其中的典型代表,攻击者一旦利用它,便能窃取敏感信息、掌控服务…...

在 Maven 中使用 <scope> 元素:全面指南
目录 前言 在 Maven 中, 元素用于定义依赖项的作用范围,即依赖项在项目生命周期中的使用方式。正确使用 可以帮助我们优化项目的构建过程,减少不必要的依赖冲突,并提高构建效率。本文将详细介绍 的使用步骤、常见作用范围、代码…...

uni_app实现下拉刷新
1. 在页面配置中启用下拉刷新 首先,你需要在页面的 pages.json 文件中启用下拉刷新功能。 {"pages": [{"path": "pages/index/index","style": {"navigationBarTitleText": "首页","enablePull…...

PCIe协议之RCB、MPS、MRRS详解
✨前言: PCIe总线的存储器写请求、存储器读完成等TLP中含有数据负载,即Data Payload。Data Payload的长度和MPS(Max Payload Size)、MRRS(Max Read Request Size)和RCB(Read Completion Bounda…...
达梦数据库在Linux,信创云 安装,备份,还原
(一)系统环境检查 1操作系统:确认使用的是国产麒麟操作系统,检查系统版本是否兼容达梦数据库 V8。可以通过以下命令查看系统版本: cat /etc/os-release 2硬件资源:确保服务器具备足够的硬件资源࿰…...
使用Dockerfile打包java项目生成镜像部署到Linux_java项目打docker镜像的dockerfile
比起容器、镜像来说,Dockerfile 非常普通,它就是一个纯文本,里面记录了一系列的构建指令,比如选择基础镜像、拷贝文件、运行脚本等等,每个指令都会生成一个 Layer,而 Docker 顺序执行这个文件里的所有步骤&…...

爬虫案例九js逆向爬取CBA中国篮球网
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、CBA网站分析二、代码 前言 提示:这里可以添加本文要记录的大概内容: 爬取CBA中国篮球网 提示:以下是本篇文章正文内容…...

除了ulimit -c unlimited:深入理解Linux core dump机制与高级配置指南
深入Linux核心转储:从基础配置到生产环境实战指南当服务器上的关键应用突然崩溃时,系统管理员最需要的就是一份完整的"事故现场记录"。Linux的core dump机制正是为此而生,它能保存程序崩溃时的内存状态、寄存器值和调用堆栈&#x…...

Kerberos身份认证原理与企业级排错实战指南
1. 这不是“另一个登录框”,而是一套精密运转的身份验证齿轮系统很多人第一次听说 Kerberos,是在公司内网登录邮箱或访问内部系统时,看到那个带小盾牌图标的弹窗——“正在使用 Kerberos 协议进行身份验证”。于是下意识觉得:“哦…...
到底在‘看’什么?)
从社交关系到分子结构:图解GCN(图卷积网络)到底在‘看’什么?
从社交关系到分子结构:图解GCN(图卷积网络)到底在‘看’什么?想象一下,你刚搬到一个新社区,想快速了解周围的邻居。最直接的方式是什么?不是挨家挨户敲门,而是通过社区活动认识几位关…...
)
ThinkPad开机报错0183/0253?别慌,手把手教你搞定EFI变量错误(附BIOS重置教程)
ThinkPad开机报错0183/0253?EFI变量错误全面解决方案当你按下ThinkPad的电源键,期待熟悉的开机画面时,屏幕上却突然跳出一串神秘代码——"0183: Bad CRC of Security Settings in EFI Variable"或"0253: EFI Variable Block D…...

新能源车轻量化为什么开始盯上高强镁合金?
续航,是悬在每一台纯电动汽车头上的达摩克利斯之剑。多充一度电、多堆一些正极材料,是一条路;但还有另一条路——把车造得更轻。 SAE(美国汽车工程师学会)的测算已经被反复引用:整车每减重100千克ÿ…...

翻译 GDB 官方文档
翻译 GDB 官方文档项目地址官方文档地址下载源码包编译html运行翻译程序项目地址 https://github.com/shootercheng/gdb-translate.git 项目结构 $ tree -L 1 . ├── cmd ├── go.mod ├── input ├── internal ├── LICENSE ├── output ├── README.md ├─…...

神经网络与深度学习 第3周课程总结
深度学习视觉应用课程总结 一、常用计算机视觉数据集数据集名称发布方/年份规模图像规格类别数主要用途核心特点MNIST美国国家标准与技术研究院60k训练10k测试2828灰度图10类(0-9手写数字)入门级图像分类最经典的手写数字识别基准数据集Fashion-MNISTZalando(2017)60k训练10k测…...

DIY四路自动音频源切换器:从信号检测到继电器隔离的完整设计
1. 项目概述与核心需求解析作为一个喜欢在工作室里捣鼓各种音频设备的玩家,我经常遇到一个挺烦人的问题:我的功放只有一组输入,但我想接的设备却有好几个——台式电脑、平板、蓝牙接收模块,还有一台树莓派。每次想切换音源&#x…...

DeepSeek模型微调全链路解析:从数据准备、LoRA配置到推理部署的7大关键步骤
更多请点击: https://intelliparadigm.com 第一章:DeepSeek模型微调全链路概览 DeepSeek系列大语言模型(如DeepSeek-V2、DeepSeek-Coder)凭借其开源特性、高性能推理能力与丰富的领域适配性,已成为工业界与学术界微调…...

Arduino ADC自检:用RC电路诊断模数转换器故障
1. 项目概述:当你的体重秤开始“说谎”你有没有遇到过这样的情况:站上家里的电子体重秤,屏幕上跳出来的数字让你瞬间怀疑人生?要么是轻得离谱,要么是重得吓人,更诡异的是,它可能只在两个固定的、…...