游戏引擎学习第147天
仓库:https://gitee.com/mrxiao_com/2d_game_3
上一集回顾
具体来说,我们通过隐式计算来解决问题,而不是像数字微分分析器那样逐步增加数据。我们已经涵盖了这个部分,并计划继续处理音量问题。不过,实际上我们现在不需要继续处理音量的问题,虽然我们可以修复它,但它没有给我们带来实际的麻烦,在音量混合器中也没有遇到问题。
关于如何高效管理编程时间
我们现在先暂时假设声音混音器已经足够好了。就像引擎的其他部分一样,如果在游戏开发的过程中发现引擎无法完成需要的功能,我们会在那个时候进行修订。这种方式通常是比较好的,因为你不想花大量时间去实现一些根本不会用到的引擎功能,或者实现一些实际上不需要的引擎功能。因此,我总是建议采取探索式的方法,只在实际需要时才去做,这样可以确保不会浪费大量时间在那些不必要的工作上,或者是花很多时间做的功能,最后却发现它并不适合任务。
在开发引擎的过程中,我们始终努力采取这种方法,只有在看到确切的使用场景时,才会加入新功能。对于不确定的部分,我们尽量保持简单。我们不想花时间去做那些最终可能对游戏没有影响或者无关紧要的部分。
无论做什么,当你在编程,或者在做游戏时,每花费的一小时都是在做某件事。如果最终这件事没有出现在最终的游戏里,那就是浪费了这一小时。因此,在编程时,确保自己不花太多时间做那些最后不会在游戏中体现的内容是非常重要的。总之,这是我们在这个项目中所尝试的方式。
混音器与游戏的接口尚未最终确定,但我们已经知道它需要从资源系统中获得什么
现在我们想要回到资产系统。我们已经写了声音混音器,目的是让大家了解资产系统可能需要的功能,因此我们可能会从另一个方向来处理声音系统。当我们真正开始将声音融入游戏时,像环境音、背景音乐等内容会加入游戏,那时我们再回过头来审视声音混音器,看看是否需要做什么调整。所以,我们目前需要从两个不同的角度来看待这个问题。
第一个角度是声音混音器可能需要资产系统提供什么功能。通过这样做,我们可以完成资产系统的开发。接下来,我们会从游戏代码的需求出发来看待声音系统,预计到时候我们对声音混音器的修改不会很多,因为目前它的工作方式已经很直接,且与资产混音器已经对接得很好。不过,声音混音器的接口部分,比如播放声音的结构,可能会发生显著的变化。现在的声音混音器其实只是一个非常简单的层,它能做的事情非常基础,目的只是为了能让声音播放出来。因此,声音混音器的接口部分会在后续有所扩展。
我们不打算现在就对声音混音器做太多修改,因为更合适的时机是在游戏中加入一定的声音环境时,这时我们才会清楚知道声音混音器的接口应该是什么样子的。因此,现在更专注于资产系统,直到我们有更清晰的需求时,才会进一步完善声音混音器的功能,尤其是在如何驱动混音代码这部分。
今天的计划:定义资源系统
我们现在计划回顾一下资源系统,并重新整理我们的思路,讨论我们希望资源系统具备哪些功能,并可能开始编写一些代码,将目前的测试代码逐步迁移到资源系统中,逐步定义其结构和功能。
在正式开始之前,我们会先在黑板上进行一些讨论,介绍一下资源系统的背景和我们接下来要做的事情,和以往一样,在进入新的模块之前,先打下一些理论基础。如果我们今天能够顺利完成这些讨论,并有时间开始编程的话。
接下来我们将集中讨论资源系统的内容,并定义我们期望它实现的功能。目前,我们已经对资源系统的基本工作方式进行了初步定义,但现在我们需要做的是更深入地设计它的结构。
资源系统的两个方面:文件管理和内存管理
目前我们已经有了一个初步的资源系统,并且我们对它的实现效果感到相当满意。目前系统中基于标签的资源匹配机制运行得非常好,这种匹配方式我们认为非常不错,效果出乎意料的理想。而接下来我们要做的,就是将资源系统推进到一个更完整的状态,使其更加完善。
接下来有两个主要任务需要完成:
第一,定义资源文件的格式
我们需要确定资源文件的具体格式,也就是如何组织和存储游戏中的资源内容。资源文件主要包含的就是游戏中使用的所有素材,包括纹理、声音、模型、动画等等。这些文件将是资源系统的核心内容,因此我们需要确定一种合适的文件格式,使得资源系统能够方便地加载、解析和管理这些资源内容。
我们的目标是尽可能让资源文件的格式清晰且易于扩展,并确保资源系统能够快速解析这些文件,同时满足不同平台或不同设备的运行需求。这也是我们接下来需要讨论和规划的重要内容之一。
第二,解决资源系统中的内存管理问题
内存管理是资源系统中更复杂、更关键的一个部分。我们的目标是让资源系统像操作系统的虚拟内存管理机制一样,但同时具备更高的可预测性和可控性。也就是说,我们希望资源系统能够灵活地管理资源加载和卸载的过程,避免内存占用超出设备的可用范围,同时保证游戏运行过程中需要的资源始终可用。
我们设想了一种极端情况:假设游戏中存在 16GB未压缩的资源,而玩家的设备可能只有 2GB或4GB内存,在这种情况下,我们的资源系统需要具备类似虚拟内存的功能,即只加载当前游戏场景所需的资源,而不会一次性将所有资源加载进内存中。
资源系统需要允许我们设定一个工作集大小(Working Set Size),例如我们可以指定最大只能占用 2GB内存,那么无论游戏拥有多少资源,比如64GB甚至更多,资源系统都能够动态调整,使其只加载当前游戏状态下所需要的资源,将其他暂时用不到的资源释放或保持在硬盘中。
我们目前无法确定在实际游戏中是否真的会达到如此庞大的资源规模,但我们希望提前为这种情况做好准备。即使目前的游戏资源规模远小于16GB,甚至仅有4GB,但未来如果资源量激增,或者游戏内容持续扩展,资源系统仍然具备良好的可扩展性和适应性。
即使最终所有用户的设备都有足够的内存,并且游戏的资源总量也不会达到64GB,但我们仍然希望通过设计这样一个灵活的资源系统,使游戏可以轻松应对不同硬件环境下的运行需求,并保持良好的内存利用率。
因此,我们将资源系统的内存管理目标定义为:
- 允许设置固定的工作集大小,即无论游戏资源总量多大,资源系统只占用设定的内存上限。
- 动态加载和卸载资源,确保只有当前游戏状态下需要的资源保留在内存中,其他资源暂时保存在硬盘中或者压缩状态中。
- 最大化利用内存,在确保不溢出的情况下尽可能加载更多的资源,以保证游戏流畅运行。
这一点将是整个资源系统中最复杂、最具挑战性的部分。我们需要设计一套类似虚拟内存管理机制的资源加载方案,使其既能满足游戏资源庞大的需求,又能确保设备内存占用处于合理范围。
我们也不确定在实际开发过程中,游戏是否真的会达到需要动态分页加载的程度。但我们想通过这种设计,让资源系统具有更高的可扩展性和灵活性,从而确保即使未来资源规模激增,游戏依然能够在有限内存中顺畅运行。
总结
接下来我们需要完成两个核心任务:
- 定义资源文件格式,确保资源内容易于管理、解析和加载。
- 设计内存管理机制,确保资源系统具备类似虚拟内存的能力,能够动态加载和卸载资源,同时允许我们设定固定的工作集大小,使游戏在有限内存下依然能够运行流畅。
我们预计内存管理将是最大的挑战,而资源文件格式的设计相对简单。因此,我们会优先将内存管理方案设计好,然后再着手定义资源文件的格式。
最终目标是确保:
- 无论游戏资源总量多大,内存占用始终可控。
- 动态加载和释放资源,保证游戏流畅性。
- 资源系统具备高扩展性和可控性,为未来的资源规模扩展做好准备。
这是我们当前需要解决的两个核心问题,接下来我们将重点推进内存管理的开发工作,使资源系统具备更强的可扩展性和控制力。
重点关注资源文件
目前我们需要专注处理资源文件部分的问题,虽然它与内存管理有关联,但我们现在主要聚焦于资源文件的结构设计。我们目前的资源管理方式仍然比较零散,主要表现在:
当前资源存储方式的局限性
目前我们在磁盘上存放资源的方式非常原始,所有资源文件(如位图、音频等)都是独立的文件,随意分布在磁盘的不同目录中。而游戏中的一小段代码负责将这些文件与特定的ID、标签或段关联起来。这种方式存在以下几个问题:
- 文件分散:资源在磁盘上的分布是随机的,导致游戏加载资源时需要频繁进行文件系统的访问,增加了I/O开销。
- 难以分发:如果我们需要将游戏分发出去,必须保证每个用户的文件路径和资源布局一致,否则游戏无法正常加载资源。
- 缺乏统一管理:目前的资源并没有形成一个统一的结构,游戏无法快速定位资源,也无法通过一个集中化的管理文件来索引所有资源。
- 加载效率低:由于资源是零散的,加载时需要多次打开和关闭文件,从而导致加载效率低下。
新的目标:统一的资源文件格式
为了彻底解决这些问题,我们的目标是将所有资源打包成一个统一的文件,即一个资源包文件(Packed Asset File),其中包含:
- 所有的位图、音频、模型等资源数据。
- 资源的元数据(Metadata),包括资源的ID、标签、类型、尺寸等信息。
- 资源的分区信息,用于快速定位文件中某个资源的位置。
通过设计这种资源包文件,我们可以使游戏在读取资源时只需要打开一个文件,然后通过内部的索引快速定位到需要的资源数据,从而大幅提升资源加载的速度并简化资源分发流程。
资源文件的结构设计
我们打算将资源包文件设计成分区结构,整体类似一个小型的虚拟文件系统,主要由以下几个部分组成:
-
文件头(Header):
- 包含资源包的基本信息,如文件版本号、资源数量、索引表的偏移量等。
- 文件头是固定大小的,方便我们在游戏启动时快速解析。
-
资源索引表(Asset Index Table):
- 包含所有资源的元数据(如资源名称、ID、大小、类型、偏移量等)。
- 游戏加载时只需要读取索引表,就能快速定位资源在文件中的位置。
- 这部分是资源包中最重要的部分,直接决定了资源加载的速度和准确性。
-
资源数据区(Asset Data Block):
- 存放实际的资源数据,包括位图、音频、模型等二进制数据。
- 每个资源在数据区中按照固定的偏移量存储,索引表会记录这些偏移量和大小信息。
- 通过这种方式,游戏可以直接跳转到某个资源的位置,而无需逐个扫描所有文件。
资源文件的优点
通过采用统一的资源文件格式,我们可以获得以下几个核心优点:
1. 提升加载效率
将所有资源集中打包成一个文件,游戏只需要打开该文件即可进行所有资源的读取,大大减少了文件系统的访问次数,从而提升加载速度。
2. 便于分发
游戏的所有资源都打包在一个文件中,当我们需要将游戏分发给玩家时,只需要分发一个资源包文件即可,无需担心文件路径或依赖文件丢失的问题。
3. 便于管理
在开发过程中,我们可以使用一个专用工具(Asset Packager)将所有资源打包成一个文件,并生成索引表,使资源管理更加系统化、可控化。
4. 方便扩展
如果将来需要添加新的资源,只需要重新打包生成新的资源包文件即可,无需修改游戏代码。
5. 减少内存碎片化
当游戏加载资源时,可以一次性加载大量数据并存入内存中,避免频繁的内存分配和释放,从而减少内存碎片化问题,提高内存利用率。
资源加载流程
在游戏运行时,资源加载的流程将如下:
- 打开资源包文件,读取文件头和索引表。
- 解析索引表,将资源名称与内存地址进行映射。
- 当游戏需要某个资源时,通过索引表快速定位资源在文件中的偏移量,并直接读取数据加载到内存。
- 关闭文件,释放文件句柄。
由于游戏只打开一个文件,并通过索引表快速定位资源,这样可以大幅减少I/O操作,提高加载速度。
预加载和动态加载
为了进一步优化内存利用率,我们还可以设计预加载和动态加载两种模式:
- 预加载(Preloading):在游戏启动时,将部分核心资源(如UI、菜单、背景音乐等)预加载到内存中,保证基础功能的流畅性。
- 动态加载(Streaming Load):在游戏运行过程中,根据游戏场景的需求,动态加载当前需要的资源并卸载不需要的资源,确保内存使用处于合理范围。
这种设计类似于操作系统的虚拟内存机制,使得游戏能够加载超出物理内存容量的资源集,而不会导致内存溢出。
未来的优化方向
在完成资源文件的基本设计后,我们还计划对其进行以下优化:
-
压缩资源:
- 将资源数据进行无损或有损压缩,减少资源文件的体积,提高加载速度。
- 在加载资源时实时解压,保持资源质量。
-
异步加载:
- 将资源加载过程放入单独的线程中,避免阻塞游戏主线程,提高流畅性。
-
分层加载:
- 根据资源的优先级(如UI资源优先、背景资源次之),分层加载资源,保证关键内容优先可用。
-
热更新支持:
- 将资源包文件拆分成多个小文件,使游戏可以通过网络更新某个资源包文件,而无需重新下载整个游戏。
总结
我们当前的主要目标是将零散的资源文件打包成一个统一的资源包文件,并设计索引表和数据分区,使游戏在加载资源时更加高效、可控,同时便于资源的管理和分发。
后续我们将:
- 定义资源文件格式,确保其易读、易写、易解析。
- 编写资源打包工具,将所有资源打包成一个文件并生成索引表。
- 实现资源加载系统,确保游戏能够快速解析资源包并加载所需资源。
最终我们希望实现的目标是:
- 游戏分发时只包含一个资源包文件。
- 加载资源时只需一次文件打开操作。
- 动态加载内存中所需资源,避免内存溢出。
- 资源包可扩展、可更新,方便未来增加内容。
接下来我们将正式开始编写资源打包工具,并实现资源加载系统。
类型和标签将游戏代码与资源表解耦
我们目前正在解决的核心问题是资源匹配机制,即如何让游戏代码通过类型(Type)和标签(Tag)来请求资源,而不直接依赖于具体的资源文件,从而实现资源与游戏逻辑的解耦。
游戏资源匹配机制的核心思想
在我们的游戏设计中,游戏代码在处理资源时只关心类型(Type)和标签(Tag),而不直接操作具体的资源文件(如位图、音频等)。这种方式的核心思想是:
- 游戏代码只描述需求:游戏代码不需要关心资源的具体文件是什么,也不需要知道该资源在哪里,它只需要描述想要的资源类型以及资源的特征。
- 资源系统负责匹配:资源系统根据游戏代码提供的类型和标签信息,从资源表(Asset Table)中找到最符合需求的资源并返回给游戏代码。
- 解耦:游戏代码和资源文件是完全解耦的,这意味着:
- 游戏代码不需要因为新增资源而修改。
- 艺术家可以随时增加、调整或替换资源,而无需修改游戏代码。
- 游戏内容可以更加动态,只需要调整资源文件即可改变游戏内容,而无需重新编译代码。
资源匹配机制的工作方式
1. 资源类型(Type)
资源类型是指游戏代码需要的资源类别,例如:
- 英雄角色(Hero)
- 武器(Weapon)
- 背景音乐(Background Music)
- UI按钮(UI Button)
当游戏代码请求资源时,它首先会指定资源类型,表示需要的是哪类资源。
例如:
RequestAsset(Type_Hero)
表示游戏需要一个英雄角色的资源,但不关心具体是哪个英雄。
2. 资源标签(Tag)
资源标签是对资源的特征描述,它用来进一步限定所需资源的具体特征。
比如在请求英雄角色时,可能需要指定以下标签:
- 性别:男(Male)、女(Female)、非二元(Non-binary)等。
- 年龄:儿童(4岁)、青年(20岁)、中年(50岁)、老年(80岁)等。
- 性取向:异性恋(Straight)、同性恋(Gay)、双性恋(Bisexual)等。
- 头发颜色:金发(Blonde)、黑发(Black Hair)、红发(Red Hair)等。
请求示例:
RequestAsset(Type_Hero, Tag_Gender_Male, Tag_Age_20, Tag_HairColor_Blonde)
此时游戏引擎会返回一个尽量符合这些标签的英雄资源。
3. 模糊匹配机制
由于资源文件并不总是能完全匹配所有标签,因此我们采用模糊匹配机制,即尽量返回最符合条件的资源,而不是强制匹配所有标签。
例如:
- 游戏代码请求:
RequestAsset(Type_Hero, Tag_Age_20) - 资源表中没有20岁的英雄,但有18岁和22岁的英雄。
- 资源系统会优先选择最接近20岁的资源返回。
这就是模糊匹配机制的核心,它允许我们:
- 避免资源缺失导致游戏崩溃。
- 允许艺术家不断新增资源而不影响游戏运行。
资源表的结构
为了支持这种匹配机制,我们需要设计一个**资源表(Asset Table)**来存储所有资源的元数据。该资源表的核心结构如下:
1. 资源项(Asset Entry)
每个资源在资源表中都有一个资源项,包含:
- 资源ID:该资源在资源表中的唯一标识符。
- 资源类型:该资源属于哪种资源类型(英雄、武器、音乐等)。
- 资源路径:该资源在磁盘中的位置。
- 标签列表:该资源所拥有的所有标签。
示例:
| 资源ID | 类型 | 资源路径 | 标签 |
|---|---|---|---|
| 1 | Hero | assets/hero1.bmp | 男性、20岁、金发 |
| 2 | Hero | assets/hero2.bmp | 女性、25岁、红发 |
| 3 | Hero | assets/hero3.bmp | 男性、50岁、黑发 |
2. 标签表(Tag Table)
标签表用于描述所有可用的标签类型以及它们的可能取值:
| 标签类型 | 取值 |
|---|---|
| 性别 | 男、女、非二元 |
| 年龄 | 4岁、20岁、50岁 |
| 发色 | 金发、红发、黑发 |
| 性取向 | 异性恋、同性恋、双性恋 |
资源匹配的具体过程
当游戏代码发出一个资源请求时,资源系统的匹配过程如下:
- 读取资源表:加载资源表中的所有资源项。
- 过滤资源类型:根据请求的资源类型,过滤出所有符合该类型的资源。
- 计算匹配分数:遍历所有符合类型的资源,对每个资源计算与请求标签的匹配程度(匹配分数)。
- 选择最佳匹配:根据匹配分数,选择最接近请求条件的资源并返回。
匹配分数计算
为了确定最符合请求的资源,我们采用**匹配分数(Matching Score)**的方式,计算公式类似:
匹配分数 = 满足的标签数量 / 总标签数量
例如:
请求:RequestAsset(Type_Hero, Tag_Gender_Male, Tag_Age_20)
资源A:Male, 20岁 → 匹配分数 = 2/2 = 100%
资源B:Male, 25岁 → 匹配分数 = 1/2 = 50%
资源C:Female, 20岁 → 匹配分数 = 1/2 = 50%
最终资源A的匹配分数最高,因此它会被优先返回。
动态更新资源表
最大优势是资源表可以动态更新,而无需修改游戏代码。例如:
- 艺术家增加新资源:
- 艺术家绘制一个全新的
老年英雄角色。 - 只需要将该资源添加到资源表中即可。
- 艺术家绘制一个全新的
- 游戏代码无需修改:
- 游戏代码仍然请求
Tag_Age_50的英雄角色。 - 资源系统会自动找到新添加的老年英雄资源。
- 游戏代码仍然请求
这样就达到了游戏代码与资源的完全解耦。
优点总结
采用类型+标签的资源匹配机制带来了以下核心优势:
| 优势 | 描述 |
|---|---|
| 解耦 | 游戏代码不依赖具体资源文件,资源可动态增加/替换。 |
| 动态扩展 | 新增资源只需更新资源表,无需重新编译游戏代码。 |
| 最大匹配 | 即使资源不完全匹配,也能找到最接近的资源返回。 |
| 艺术家友好 | 艺术家可以自由增加资源,无需工程师干预。 |
复习资源系统代码
我们现在的目标是将游戏中的资源数据以一种有结构、易加载、可扩展的方式存储到磁盘上,并在游戏运行时快速加载这些数据,从而实现游戏代码与资源数据的解耦。为此,我们需要从数据结构的设计开始,确定资源类型(Asset Type)、**资源标签(Asset Tag)以及资源本体(Asset)**之间的映射关系,并将这些数据打包成一个统一的文件格式,使游戏能够高效加载和使用这些资源。
数据的存储结构设计
我们在存储数据时,采用的是一种层级结构,这种结构的核心思想是:
- 最底层是资源本体(Asset),即具体的图像、音频、模型等数据。
- 上层是资源标签(Tag),用来描述资源的属性,比如性别、年龄、颜色等。
- 最顶层是资源类型(Asset Type),用来对资源进行分类,比如英雄(Hero)、阴影(Shadow)、武器(Weapon)等。
通过这种层级结构,我们就可以将游戏代码和资源数据解耦,让游戏代码只关心资源类型和标签,而不关心资源本体,从而使资源可以随时更新而无需修改游戏代码。
资源类型(Asset Type)的定义
首先,我们需要定义资源类型(Asset Type),它是最上层的概念,用来表示游戏中某一类资源。
例如:
- Shadow:表示阴影资源,可能用于角色、物品的投影。
- Head:表示角色的头部资源。
- Cape:表示角色的披风资源。
- Torso:表示角色的身体资源。
我们使用**枚举(Enum)**来表示这些资源类型,使得游戏代码在请求资源时,可以直接使用枚举,而无需关心具体的资源文件。
示例:
enum AssetType
{AssetType_Shadow,AssetType_Head,AssetType_Cape,AssetType_Torso,AssetType_Count
};
这里AssetType_Count只是用来记录总数,方便遍历所有类型。
资源类型的索引表
在磁盘文件中,所有的资源都会按照资源类型进行索引。
例如:
| 索引 (Index) | 资源类型 (Asset Type) |
|---|---|
| 0 | Shadow |
| 1 | Head |
| 2 | Cape |
| 3 | Torso |
这种结构是**扁平化(Flat)**的,即所有资源都是连续存储在磁盘上的。
游戏代码只需要知道索引,就可以快速找到该类型的资源。
资源标签(Asset Tag)的定义
**资源标签(Asset Tag)**是描述资源特征的属性,例如:
- 性别:男(Male)、女(Female)、非二元(Non-binary)。
- 年龄:4岁、20岁、50岁、80岁。
- 颜色:黑发、金发、红发。
- 风格:像素风、写实风、漫画风。
标签的作用是在同一资源类型中进一步区分资源,确保游戏代码可以通过标签找到更符合需求的资源。
标签的结构
每个资源都拥有一个标签数组(Tag Array),其中包含:
- 标签ID:表示该标签的唯一标识。
- 标签值:表示该标签的具体取值。
示例:
enum AssetTag
{AssetTag_Gender,AssetTag_Age,AssetTag_HairColor,AssetTag_Style,AssetTag_Count
};
标签的取值可以是动态的,资源表中只记录标签ID和取值,而不存储标签名称。
例如:
| 标签ID | 标签值 |
|---|---|
| 0 | Male |
| 1 | 20岁 |
| 2 | 金发 |
| 3 | 像素风 |
资源本体(Asset)的定义
资源本体(Asset)是指实际存储的文件,比如图像、音频、模型等。
每个资源都具备以下属性:
- 资源ID:该资源的唯一标识符。
- 资源路径:该资源在磁盘中的文件路径。
- 资源类型:该资源对应的
AssetType。 - 资源标签:该资源的所有标签及取值。
示例结构:
struct Asset
{uint32 ID;char* FilePath;AssetType Type;Tag Tags[MAX_TAGS];
};
资源在磁盘中的存储形式
我们需要将所有资源信息存储到一个**打包文件(Packed File)**中,便于游戏快速加载。
文件结构
[资源类型表]
[资源索引表]
[资源标签表]
[资源文件路径]
[资源数据]
举个例子,假设我们有三个资源:
- 20岁男性金发英雄(Hero)
- 50岁女性红发英雄(Hero)
- 20岁男性金发阴影(Shadow)
存储形式大致如下:
AssetType: Hero
AssetID: 1
Tags: {Gender: Male, Age: 20, HairColor: Blonde}
FilePath: assets/hero1.bmpAssetType: Hero
AssetID: 2
Tags: {Gender: Female, Age: 50, HairColor: Red}
FilePath: assets/hero2.bmpAssetType: Shadow
AssetID: 3
Tags: {Gender: Male, Age: 20}
FilePath: assets/shadow1.bmp
游戏代码只需调用:
RequestAsset(AssetType_Hero, Tag_Gender_Male, Tag_Age_20)
资源系统会自动找到最匹配的资源返回。
加载资源时的匹配过程
当游戏需要加载资源时,匹配过程如下:
- 读取资源表:将所有资源的类型、标签、路径加载到内存。
- 过滤资源类型:根据请求的
AssetType筛选所有该类型的资源。 - 计算匹配分数:遍历该类型下的资源,计算与标签的匹配程度。
- 选择最优资源:返回匹配分数最高的资源。
匹配分数计算公式:
匹配分数 = 匹配的标签数量 / 总标签数量
例如:
请求:Hero + Male + 20岁 + 金发
资源A:Hero + Male + 20岁 + 金发 → 匹配分数 = 4/4 = 100%
资源B:Hero + Male + 25岁 + 金发 → 匹配分数 = 3/4 = 75%
最终返回匹配分数最高的资源。
为什么采用这种设计
| 优势 | 描述 |
|---|---|
| 资源与游戏代码解耦 | 新增资源不需要修改游戏代码,只需更新资源文件即可。 |
| 动态扩展 | 资源文件可随时新增、修改、删除,游戏无需重新编译。 |
| 高效加载 | 所有资源打包成一个文件,游戏加载速度更快。 |
| 灵活匹配 | 通过标签匹配,游戏可根据需求动态选择最合适的资源。 |
下一步工作
我们接下来要完成的内容包括:
- 定义磁盘文件格式:确定资源打包文件的结构。
- 实现资源加载器:编写解析打包文件的代码,将资源加载到内存中。
- 实现资源匹配算法:基于
类型+标签进行资源匹配,并返回最佳资源。 - 优化加载速度:确保资源的加载和匹配足够快,以支持游戏流畅运行。
最终,我们希望实现:资源与游戏代码完全解耦,使资源可独立更新,游戏内容可动态变化,从而大幅降低开发和更新成本。
资源类型引用一个连续范围的实际资源,这些资源存储在单独的表中
在设计和存储游戏资源(Asset)的过程中,我们需要考虑如何高效地组织和引用资源,使得游戏在加载资源时能够快速找到所需的内容,同时保证存储结构简洁且易于扩展。为此,我们采用了一种类似数据库的设计思想,通过资产类型(Asset Type)、**资产表(Asset Table)以及子地址索引(Sub Addressing)**来实现资源的高效管理和加载。
资源类型(Asset Type)与子地址索引
首先,我们定义了一个资源类型表(Asset Type Table),该表的作用是将资源按照类型进行分类,例如:
- Shadow:表示阴影资源。
- Head:表示角色的头部资源。
- Cape:表示角色的披风资源。
- Torso:表示角色的身体资源。
这个资源类型表本质上是一个索引表,每个资源类型都有一个唯一的索引编号。例如:
索引 资源类型
------------------
0 Shadow
1 Head
2 Cape
3 Torso
在游戏加载资源时,程序只需要知道资源类型编号,就可以通过该编号快速找到该类型资源在资源表中的起始地址以及资源数量。
资产表(Asset Table)的作用
我们在磁盘上存储的所有资源数据被打包成一个资源表(Asset Table),该表存储的是所有资源的具体信息,包括:
- 资源编号(Asset Index)。
- 资源文件地址(File Path 或 Offset)。
- 资源标签(Tag)。
- 资源大小(Size)。
资源表在磁盘上的形式类似于:
索引 文件地址 标签信息 文件大小
-------------------------------------------
0 offset_0 [Tag1,Tag2] 2MB
1 offset_1 [Tag3,Tag4] 3MB
2 offset_2 [Tag1,Tag5] 1MB
3 offset_3 [Tag2,Tag3] 4MB
所有资源以连续存储的方式存在磁盘中,通过索引快速定位资源的起始地址和大小,实现高效加载。
子地址索引(Sub Addressing)的作用
由于我们采用的是资源类型分类存储的方式,即同一类型的资源集中存放,因此我们需要一种方法来记录每种资源类型在资源表中的起始位置和数量。
为什么需要子地址索引
假设我们有以下资源:
资源类型 资源编号
-------------------
Shadow 0
Shadow 1
Shadow 2
Head 3
Head 4
Cape 5
Cape 6
Cape 7
Torso 8
如果游戏需要加载所有 Shadow 资源,我们希望通过资源类型表直接找到Shadow 类型的起始地址,并知道该类型资源的数量。
子地址索引的存储形式
我们在资源类型表中添加两个额外字段:
- 起始索引(First Asset Index):表示该资源类型的第一个资源在资源表中的索引。
- 资源数量(Asset Count):表示该资源类型的资源数量。
最终的资源类型表如下:
资源类型 起始索引 资源数量
-------------------------------
Shadow 0 3
Head 3 2
Cape 5 3
Torso 8 1
这意味着:
- Shadow类型资源从索引0开始,有3个资源。
- Head类型资源从索引3开始,有2个资源。
- Cape类型资源从索引5开始,有3个资源。
- Torso类型资源从索引8开始,有1个资源。
游戏只需要根据资源类型查找起始索引和数量,就可以快速找到所有同类型资源。
资源的连续存储
这里的核心设计是同类型的资源在磁盘中是连续存储的,即:
索引 资源类型 文件地址
--------------------------
0 Shadow offset_0
1 Shadow offset_1
2 Shadow offset_2
3 Head offset_3
4 Head offset_4
5 Cape offset_5
6 Cape offset_6
7 Cape offset_7
8 Torso offset_8
这带来了几个重要优势:
- 同类型资源连续存储,保证加载速度更快。
- 通过索引+数量即可快速找到所有同类型资源。
- 资源表结构紧凑,存储效率更高。
多个资源文件的考虑
目前的设计假设所有资源都存储在同一个文件中,但如果资源非常庞大,我们可能需要拆分成多个文件(如asset_file_1和asset_file_2)。
多个文件的加载问题
如果我们直接使用连续存储的方式,多个文件将导致问题:
- 文件1存储
Shadow, Head。 - 文件2存储
Cape, Torso。 - 加载
Shadow时,文件偏移将失效。
解决方法:文件偏移地址(File Offset)
为了解决这个问题,我们将文件偏移地址加入资源表:
索引 资源类型 文件索引 文件偏移
--------------------------------------
0 Shadow file_1 offset_0
1 Shadow file_1 offset_1
2 Shadow file_1 offset_2
3 Head file_1 offset_3
4 Head file_1 offset_4
5 Cape file_2 offset_0
6 Cape file_2 offset_1
7 Cape file_2 offset_2
8 Torso file_2 offset_3
这样,游戏在加载资源时:
- 先通过资源类型表找到起始索引和数量。
- 再通过资源表找到文件索引和文件偏移。
- 最后打开文件,按偏移读取资源数据。
这种设计的优势
| 优势 | 描述 |
|---|---|
| 快速索引 | 通过资源类型+索引快速定位资源地址。 |
| 连续存储 | 同类型资源连续存储,加载速度快。 |
| 文件拆分 | 支持多个资源文件分批加载,避免单文件过大。 |
| 资源解耦 | 游戏代码与资源数据完全分离,方便更新和扩展。 |
未来的扩展考虑
目前我们采用的结构非常适合中小型游戏,但如果资源量进一步增加,可以考虑:
- 资源分页加载:按需加载,避免占用内存过多。
- 资源压缩存储:使用zlib等压缩算法减少磁盘占用。
- 资源热更新:通过增量更新文件,支持动态更新资源。
- 标签索引优化:引入倒排索引,使资源匹配更高效。
最终的目标是实现:
- 游戏代码与资源数据完全解耦。
- 资源加载速度足够快。
- 资源存储结构紧凑且易扩展。
- 支持多文件、按需加载和热更新。
这种结构类似于数据库,通过类型表+索引表+资源表的设计,确保资源可快速加载,同时支持文件分拆和动态更新,为大型游戏开发提供了强大的灵活性和可扩展性。
将资源系统通用化,允许在不同的资源文件中拥有相同资源类型的多个范围
当我们处理资产文件时,我们需要考虑在磁盘上和内存中对资产数据的组织方式。首先,我们在磁盘上的资产表实际上有点类似数据库,因为它以结构化的方式存储数据。我们在这里将资产分为不同的资产类型,并通过表格进行索引管理。在资产类型表中,每个条目代表一种资产类型,并指向一个连续的资产范围。例如,如果我们有一种资产类型,其资产索引范围为4到6,则该条目会存储第一个资产的索引以及该类型包含的资产数量。
这种连续索引的方式在只有一个资产文件时是非常方便的,因为我们可以确保相同类型的所有资产在磁盘上是连续存储的,这样可以提高加载效率。然而,当我们引入多个资产文件时,例如游戏的DLC或扩展包时,这种方式就会出现问题。
假设我们最初的资产文件中包含了一种名为“巧克力酒”的资产类型,并且该资产的索引范围为16到22,共有7个条目。当我们发布一个新的DLC时,其中又增加了930种新的巧克力酒资产,如果我们继续沿用连续索引的方式,就无法表示这些新的资产,因为它们不再与原文件中的资产连续。
为了解决这个问题,我们需要在磁盘上的资产类型表中存储更多信息,使其支持合并加载。在原始资产文件中,每个条目仅包含索引范围信息,而在新的结构中,每个条目需要记录它所表示的具体资产类型(例如巧克力酒)的枚举值,以及该类型在文件中的索引范围。这样,当我们加载多个资产文件时,可以在内存中合并同一类型的资产,使其形成连续的内存结构,方便游戏使用。
这种合并加载的过程是这样的:
- 加载第一个资产文件时,将其资产类型表和资产数据加载到内存中。
- 加载第二个资产文件时,检查资产类型表中的枚举值,如果发现与内存中已有的资产类型匹配(如“巧克力酒”),就将其资产数据追加到内存中已存在的同类型资产之后。
- 如果枚举值是新的,则创建新的资产类型条目并添加资产数据。
这种方式的优点是:
- 支持扩展包:我们可以在不修改原始资产文件的情况下直接加载新的资产文件并合并数据。
- 内存结构优化:在内存中我们仍然可以保持同类型的资产连续存储,以便高效地访问和渲染。
- 增量加载:当我们需要增量更新资产文件时(例如添加新内容或修复旧内容),只需要将新资产追加到文件末尾,无需重写整个文件。
此外,我们还需要处理资产的具体信息。每个资产都有一个信息结构体(Info Struct),用于存储该资产的具体数据,例如:
- 位图:宽度、高度、像素数据等。
- 声音:通道数、采样率、数据偏移等。
- 通用数据:数据块在文件中的偏移量、数据大小等。
这些信息需要直接存储在磁盘上的资产文件中,并在加载时解析到内存中,便于游戏直接使用。我们还需要移除一些无用的信息,例如文件名,因为我们已经将所有数据打包到资产文件中,因此不再需要外部文件路径。
关于标签(Tags),我们将其设计成简单的整数和浮点数的数组,每个资产都可以拥有一组标签,用于快速定位或筛选资产。例如:
- 标签1:颜色类型(0=红色,1=蓝色等)。
- 标签2:适用场景(0=室内,1=户外等)。
- 标签3:品质等级(0=普通,1=稀有等)。
在磁盘上,标签也是以二进制形式直接存储的,加载时无需解析或转换,可以直接映射到内存中使用。
在处理加载流程时,我们需要特别注意的是:
- 在磁盘上的资产类型表只作为临时数据,加载时会根据枚举值重新组合形成新的内存资产类型表。
- 在内存中保证相同类型的资产连续存储,以提高访问效率。
- 当出现多个资产文件(如DLC)时,需要合并相同类型的资产,使其在内存中保持连续。
未来我们可能还会考虑对资产文件进行压缩,以减少文件大小。通常我们可以使用LZ压缩算法在保存时对数据进行压缩,在加载时解压缩,以达到最优的加载效率和存储空间利用率。
接下来,我们需要设计一个标准的资产文件格式,以便存储这些数据,并编写加载代码,使其能够正确地合并加载多个资产文件。我们还需要确保加载过程中不会影响游戏的运行状态,因此我们可以先保留当前内存模拟的加载代码,待新格式加载流程完善后再替换。
编写一个生成虚拟资源文件的程序
我们现在需要做的一件重要的事情是,将之前在内存中模拟资产文件的代码拆分出来,单独创建一个生成资产包文件(Asset Pack File)的程序。这个新程序的唯一任务就是生成一个虚拟的资产包文件,以便我们进行加载和测试。这样可以确保我们的游戏在加载资产文件时,流程是完整且正确的,并且也有助于我们验证后续的加载逻辑。
我们要做的第一步是在我们的构建脚本(CMakeLists.txt)中添加一个新的构建目标,即专门用来生成资产包文件的工具。这个工具的名称暂定为 test_asset_builder.cpp,它将是一个独立的可执行文件,用来生成测试用的资产文件。
在构建脚本中,我们可以看到目前已有的多个构建目标,例如游戏的主可执行文件等。我们的目标是增加一个新的构建项,使其编译生成 test_asset_builder.exe 文件。我们不打算为它生成映射文件(map file)或其他调试文件,因为它只是一个测试工具,只需要最基本的可执行文件。
添加新的构建目标
我们在 test_asset_builder.cpp 文件中添加一行新的构建:
# test_asset
add_executable(test_asset "test_asset_builder.cpp")
该命令指定了编译器参数,确保新程序可以生成 test_asset_builder.exe,我们暂时不关注其他构建配置或调试配置。
创建测试资产生成器的代码文件
接下来,我们在项目根目录下创建一个名为 test_asset_builder.cpp 的新文件,该文件将专门用于生成资产包文件。为了保持清晰性,以示其独立性,也避免和主游戏逻辑混淆。
文件路径:
/game/test_asset_builder.cpp
文件内容:
#include <iostream>
int main(int argc, char* argv[]) {(void)argc;(void)argv;std::cout << "Test Asset Builder Running..." << std::endl;
}
我们现在只写了最简单的模板代码,目的是确保该程序可以被编译和运行。
测试可执行文件
然后我们切换到 build 目录,通过命令行执行:
.\test_asset_builder.exe
如果一切顺利,它应该输出:
Test Asset Builder Running...
这说明我们的新程序已经被正确编译和生成,并且能够正常运行。
设置路径
由于 test_asset_builder.exe 目前未被添加到系统路径中,因此在命令行中我们需要通过:
.\build\test_asset_builder.exe
保存文件自动会编译 生成


保存文件会自动编译cmake

何时使用库的一个例子
我们通常不使用库或引擎,几乎完全从零开始编写代码。这不仅是出于教育目的,同时也是为了避免在长期维护项目中遇到的依赖问题。在实际项目中,如果使用第三方库,可能会因为库停止维护、存在兼容性问题或引入新的bug,从而增加维护成本。因此,对于希望长期运行的代码,我们倾向于避免使用第三方库。但如果是临时测试、原型开发或其他不影响核心功能的场景,我们是愿意使用标准库的。
在这里,我们决定创建一个测试用的资源打包工具,该工具的作用是生成一个资源包文件,以供游戏加载测试使用。这个工具完全独立,不影响核心游戏的构建逻辑,因此可以放心地使用C标准库进行开发。
然后,我们创建test_asset_builder.cpp,并为其添加标准的main函数。此工具的作用是模拟游戏运行时打包的过程,只是这次打包的内容是提前定义的。这样我们就可以快速测试资源加载功能,同时也为将来创建资源打包工具提供参考。
接下来,我们在该工具中使用fopen打开一个名为test.hha的文件,模式为wb,表示以二进制写入方式打开文件。如果文件不存在则创建,存在则覆盖。然后,我们计划将所有资源的数据写入该文件中。在这里,使用C标准库的fwrite、fclose等函数处理文件操作。由于我们不关心此工具的长期维护,因此不考虑封装文件操作或做任何抽象。
在生成资源包之前,我们需要整理一下资源数据结构。在游戏中,资源包括位图、声音、字体等,但在这里我们仅关心位图数据的存储。我们定义一个结构bitmap_asset,包含位图的文件名、对齐方式、资源类型等信息。然后,我们遍历所有资源,将这些信息写入资源包文件中。
为了简化操作,我们直接复制了游戏原有的资源加载代码,将其稍作修改以适应当前需求。首先删除了原有的引用代码和不必要的资源槽位,并将所有数据转换为全局变量存储。我们不再关心模块化或抽象,只关注快速生成资源文件。
在资源定义部分,我们直接从原游戏代码中提取资源加载的函数AddBitmapInfo、BeginAssetType等,并将其嵌入该工具中,但去除了所有的引用和游戏内存管理相关内容,只保留简单的数组存储资源数据。所有资源都存储在一个全局数组中,最终通过fwrite一次性写入文件中。
对于资源包格式,我们参考了游戏内的资源结构,但进行了简化。例如,我们不再记录资源ID,而是简单地使用资源索引;不使用复杂的对齐或内存布局,而是直接写入文件中。这样一来,可以快速生成资源包文件并供游戏加载测试。
此外,为了避免包含不必要的游戏代码,我们将资源类型枚举拆分成单独的头文件asset_type_id.h,并在工具中直接引用它。这样,我们既能保证资源类型的定义一致,又避免包含其他无关代码。
最后,我们清理了代码,使其不再依赖游戏内的资源系统。所有资源信息都直接写入文件,并在关闭文件后完成资源包生成过程。在测试阶段,我们不考虑代码质量、性能或可维护性,只关注生成测试资源包的功能。
后续我们可能还需要调整资源包的格式,使其支持增量更新或者追加资源,但目前我们优先保证能够生成基础资源包,以供游戏加载测试。未来,如果我们需要增加其他资源类型(如声音、字体),可以直接扩展此工具的写入逻辑即可。



通过去除SlotID简化资源结构
我们目前正在对资源加载系统进行一个重要的架构调整,目的是简化代码结构,减少不必要的复杂性,提高运行时的效率。在之前的实现中,我们使用了一个所谓的 Slot ID(槽位ID) 的概念,用来表示游戏运行时资源的加载状态及对应的内存位置。但在当前的文件结构中,Slot ID 似乎变得没有实际意义,因此我们决定将其移除,并通过更直接的方式来定位资源数据的位置,从而简化代码和数据结构的设计。
问题的起源
在之前的实现中,我们有两个重要的数组:
- Bitmaps数组:存储游戏中的所有位图资源(如图片、纹理等)。
- Sounds数组:存储游戏中的所有声音资源(如背景音乐、音效等)。
同时我们还为每个资源分配了一个 Slot ID,该 Slot ID 负责在运行时跟踪资源的加载状态,以及与内存中的特定位置相对应。
但是在实际查看代码时我们发现,Slot ID 的存在并没有明显的必要性。
为什么 Slot ID 没有必要?
我们意识到,资源本身(比如位图、声音)和其加载状态是两回事。资源本身应该有一个固定的索引,而不需要一个额外的 Slot ID。
原先的做法是:
- Slot ID 是独立于资源索引的,它指向内存中的某个位置。
- 资源数组 存储的是具体资源。
- 加载状态数组 存储的是加载状态,并通过 Slot ID 索引对应的资源。
但仔细想想,我们完全可以直接用资源数组的索引代替 Slot ID,因为:
- 资源索引本身就唯一且确定。
- 在加载资源时,我们本来就是通过资源索引去获取资源内容的。
- Slot ID 实际上是多余的,它只是做了一层无意义的映射。
换句话说,Slot ID 本质上是资源索引的冗余表示,而我们完全可以直接使用资源数组的索引来替代 Slot ID。
解决方案
我们决定移除 Slot ID,并将所有资源(包括位图和声音)统一存放在同一个数组中,并通过资源索引直接访问数据。
具体修改的内容
1. 移除 Slot ID
我们首先将 Slot ID 的概念彻底移除,包括:
- 将原本分开的 Bitmap 数组 和 Sound 数组,合并成一个资源数组 (
Assets[])。 - 将原本的 Slot ID 替换为资源索引,直接通过索引访问资源。
- 将原来的 加载状态数组 与资源数组合并,避免冗余的内存访问。
2. 合并资源数组
我们决定将所有资源(位图、声音)合并成同一个数组,并通过联合体 (union) 表示资源的具体类型。
新的结构如下:
struct asset
{union{asset_bitmap_info Bitmap;asset_sound_info Sound;};
};
这意味着:
- 每个资源无论是位图还是声音,都会存在同一个
Assets[]数组中。 - 通过联合体 (
union) 的方式区分资源的类型。
例如:
Assets[Index].Bitmap
Assets[Index].Sound
无需再维护单独的 Bitmaps 数组 或 Sounds 数组,只需要维护一个统一的 Assets 数组。
3. 移除 BitmapsCount 和 SoundsCount
在旧的实现中,我们有两个计数器:
int BitmapCount;
int SoundCount;
分别记录位图和声音资源的数量。
但在新的实现中,所有资源都合并成同一个数组,因此我们只需要一个总的 AssetCount 即可:
int AssetCount;
通过 AssetCount 我们就能遍历所有资源,无需区分位图或声音。
4. 移除加载状态数组
在旧的实现中,我们有一个单独的 加载状态数组,通过 Slot ID 去索引资源的加载状态:
slots[SlotID].State
但在新的实现中,加载状态完全可以直接附加在资源结构体上:
struct asset
{asset_state State;
};
因此,加载状态数组也就不再需要了。
5. 资源的定位
在新的实现中,我们直接通过资源索引来访问资源,无需 Slot ID。
旧的访问方式:
Bitmap = Assets.Slots[SlotID].Bitmap;
新的访问方式:
bitmap_id ID
Assets->Slots[ID.Value].Bitmap
简单、直接、无需映射。
6. 更新 AddSoundAsset 和 AddBitmapAsset
在旧版本中,我们的 AddSoundAsset() 和 AddBitmapAsset() 都会返回一个 Slot ID:
uint32 AddSoundAsset(...)
{uint32 SlotID = GetNextAvailableSlot();Assets.Slots[SlotID].Sound = ...return SlotID;
}
现在我们将其改成直接返回资源索引:
uint32 AddSoundAsset(...)
{uint32 AssetIndex = AssetCount++;Assets[AssetIndex].Sound = ...return AssetIndex;
}
这种方式更加直观,也避免了不必要的 Slot ID。
7. 减少解引用操作
在旧版本中,由于通过 Slot ID 找资源,存在解引用的过程:
Bitmap = Assets.Slots[SlotID].Bitmap;
现在我们直接通过索引访问资源,省去解引用的过程:
Bitmap = Assets[AssetIndex].Bitmap;
这样不仅代码简化,运行效率也会更高。
8. 保留索引 ID(SoundID、BitmapID)
虽然我们移除了 Slot ID,但我们仍然需要一种方式来标识资源,比如SoundID和BitmapID。
我们决定直接使用索引值作为 ID:
struct asset_id
{uint32 Value;
};
在添加资源时,直接返回索引即可:
SoundID = AddSoundAsset(...);
访问时直接通过索引访问:
Assets[SoundID.Value].Sound;
这样做的好处是:
- 没有 Slot ID,避免无意义的映射。
- 资源索引即 ID,简化所有逻辑。
9. 资源状态和加载的处理
在原先的实现中,我们通过 Slot ID 管理加载状态。
现在我们直接将加载状态挂在资源上:
Assets[Index].State = Loaded;
加载完成的资源直接可用,无需通过 Slot ID 管理。
10. 其他调整
我们还对以下内容进行了调整:
- 移除了 BitmapCount/SoundCount,改用 AssetCount。
- 移除了 Slot ID 的所有代码,直接用索引代替。
- 减少了解引用操作,访问更快。
最终的好处
通过这次改动,我们实现了:
✅ 减少不必要的数组:Bitmaps/Sounds 数组合并成 Assets[]。
✅ 移除 Slot ID:直接使用资源索引,避免冗余映射。
✅ 减少代码复杂性:不再需要单独的加载状态数组、Slot ID 数组。
✅ 访问更简单:直接通过索引访问资源,无需解引用。
✅ 内存布局更紧凑:Assets[] 是一个连续内存块,访问更高效。
下一步计划
接下来我们要做的是:
- 修改资源加载器,让其生成一个文件,将所有资源写入该文件。
- 修改游戏引擎,使其从文件中加载资源。
- 完善内存映射和资源回收机制。
我们的目标是让整个资源管理逻辑更加清晰高效,避免冗余设计,最终实现更优雅的资源加载系统。




项目到目前为止有多少行代码?
目前的进展比较顺利,代码量相对可控。虽然我总是忘记如何运行这个工具,但只要指定好目录并执行命令,就能正常运行。我们估计到最后,游戏代码可能会达到大约300行,虽然这个数字可能会随着开发的深入有所变化。通常,游戏代码在开发过程中容易膨胀,但引擎代码可能会控制在2万行以内,甚至可能会更少。虽然游戏代码量可能会更大,但这对引擎本身的开发不会造成太大影响。



你提到对资源进行LZ压缩,我们会自己编写压缩算法吗?
在讨论LZ压缩算法时,提到是否需要自己编写压缩算法。压缩部分的实现并不在当前范围内,重点是我们会编写解压缩部分的代码。至于压缩部分,考虑到现有需求,可能并不会专门编写压缩器,更多的是关注如何解压已经压缩的数据。
在处理资产文件时,假设已经有一个符合我们定义规范的资产文件格式,因此一旦期望的资产文件被读取完毕,后续的处理就结束了。在这个过程中,解压缩部分会被实现,而文件的编写和规范定义则假设由其他地方负责。因此,我们的工作范围集中在如何正确解压资产文件数据。
我们使用位图的原因仅仅是因为它们容易处理吗?
目前使用位图的主要原因是因为它们处理起来相对简单,方便用作示例,尤其是在教学基础编程时,展示如何加载文件时,位图是一个很好的选择。然而,实际的资产包文件并不会以BMP格式存储数据,而是会以原始像素数据的形式存储。因此,未来的实际发布代码中,位图将不再被使用,可能从下周开始就不再涉及位图。
唯一可能仍然会使用位图的地方是在打包资产文件时,可能会加载位图进行处理,但这部分处理并不影响实际的游戏代码。简而言之,位图只是作为一种简化和示范工具存在,最终的资产文件将存储原始像素数据,而不依赖于位图格式。
在结构体中使用“union”有什么作用?
在结构体中使用 union 的意思是这两个变量在内存中是重叠存储的。具体来说,当我们声明一个 union 时,编译器知道这两个成员变量不会同时使用,因此它们在内存中共享同一块区域。换句话说,结构体中某个变量的内存空间如果用到了 union,那么另一个变量将会占用相同的内存区域。
以实际代码为例,当我们定义一个 asset 结构体时,它有两个成员变量,分别是一个 sound 和一个 bitmap,我们知道在任何时刻,一个资产只能是声音或位图中的一个。因此,使用 union 关键字,编译器会将这两个成员放在内存的同一位置,只会使用其中一个。
在实际操作中,可以看到,在内存中这两个变量地址是重叠的。举个例子,当我们分别查看 FirstTagIndex 和 OnePastLastTagIndex 的地址时,它们是分开的,表示这两个变量各自占用了不同的内存空间。如果我们改变其中一个变量的值,另一个不会受影响,因为它们是分别存储的。
但是,当我们使用 union 时,情况就不同了。例如,在访问 bitmap file name 和 sound file name 时,我们发现它们指向的是相同的内存位置,改变其中一个会导致另一个值也发生变化。这是因为它们共享同一块内存区域。当一个值发生改变时,另一个值也会随之更新。
总结来说,union 是一种内存共享技术,它允许多个成员变量使用相同的内存区域。我们通过 union 来告诉编译器,我们知道在任何时刻这些成员中只有一个会被使用,因此它们可以重叠存储,而不需要分别占用不同的内存空间。

我看到bitmap_id赋值时有一个越界错误吗?bitmap_id 结果 = {…->variable++} 这个递增正确吗?
在这段代码中,主要是处理位图 ID 的分配和递增问题。具体来说,代码的目标是确保每次分配一个新的 ID 时,这个 ID 是可用的,并且在分配后会自动递增,确保该 ID 不会被重复使用。也就是说,每次请求一个新的 ID 时,系统会选择当前可用的下一个 ID,然后将其标记为已使用,并递增 ID 以供下次使用。
这种机制保证了 ID 的唯一性,并且每次分配的 ID 都是按顺序递增的,不会发生重复分配的问题。如果有其他的代码或场景与此相关,可能会有不同的处理方式,但就当前的代码而言,它的功能就是按照这种方式管理 ID 的分配。

对专门的游戏开发大学有什么看法,比如DigiPen?
没有去过任何专门的大学,也没有作为学生去过任何大学,所以对这些学校并不了解。
对虚幻引擎4有什么想法?
没有使用过Unreal Engine 4,所以不清楚它的具体情况。
你是怎么开始学习C/C++的?是学校学的还是自学的?
学习C和C++是自学的,从小就开始接触这些编程语言,没有通过学校教育来学习。
相关文章:
游戏引擎学习第147天
仓库:https://gitee.com/mrxiao_com/2d_game_3 上一集回顾 具体来说,我们通过隐式计算来解决问题,而不是像数字微分分析器那样逐步增加数据。我们已经涵盖了这个部分,并计划继续处理音量问题。不过,实际上我们现在不需要继续处理…...

Python自动点击器开发教程 - 支持键盘连按和鼠标连点
Python自动点击器开发教程 - 支持键盘连按和鼠标连点 这里写目录标题 Python自动点击器开发教程 - 支持键盘连按和鼠标连点项目介绍开发环境安装依赖核心代码解析1. 键盘模拟实现2. 鼠标点击实现 开发要点使用说明注意事项优化建议打包发布项目源码开发心得参考资料成品工具 项…...

C++ 链表List使用与实现:拷贝交换与高效迭代器细致讲解
目录 list的使用: 构造与赋值 元素访问 修改操作 容量查询 链表特有操作 拼接(Splice) C11 新增方法 注意: stl_list的模拟实现: 一、链表节点设计的艺术 1.1 结构体 vs 类的选择 二、迭代器实现的精髓 2…...

Manus联创澄清:我们并未使用MCP技术
摘要 近日,Manus联创针对外界关于其产品可能涉及“沙盒越狱”的疑问进行了正式回应。公司明确表示并未使用Anthropic的MCP(模型上下文协议)技术,并强调MCP是一个旨在标准化应用程序与大型语言模型(LLM)之间…...
ACE学习2——write transaction
用于处理缓存行的数据更新到主内存(main memory)的操作。 以下是用于更新主内存的几种事务类型: WriteBack: WriteBack事务用于将cache中的dirty态的cacheline写回主存,以释放cache中的cacheline,用于存…...

c++ 返回引用
在C中,返回引用是一种常见的做法,特别是在需要返回大型对象时,以避免不必要的复制,从而提高程序的效率。返回引用通常有两种情况:返回局部变量的引用和返回成员变量的引用。下面分别讨论这两种情况以及如何安全地实现它…...

Docker篇
1.docker环境搭建: 1.1软件仓库的配置rhel9: #cd/etc/yum.repos.d #vim docker.repo [docker] namedocker-ce baseurlhttps://mirrors.aliyun.com/docker-ce/linux/rhel/9/x86_64/stable gpgcheck0 1.2安装docker并且启动服务 yum install -y dock…...

TypeScript基础类型详解:与JavaScript的对比与核心价值
TypeScript作为JavaScript的超集,最大的特性是引入了静态类型系统。本文将基于TypeScript官网内容,解析其基础类型设计,并与ES/JavaScript进行对比,揭示类型系统的实际价值。 一、基础类型全景图 1. 原生类型的强化 JavaScript原…...

Linux《基础开发工具(中)》
在之前的Linux《基础开发工具(上)》当中已经了解了Linux当中到的两大基础的开发工具yum与vim;了解了在Linux当中如何进行软件的下载以及实现的基本原理、知道了编辑器vim的基本使用方式,那么接下来在本篇当中将接下去继续来了解另…...

CPU 负载 和 CPU利用率 的区别
简单记录下 top 命令中,CPU利用率核CPU负载的概念, (1)CPU利用率:指在一段时间内 表示 CPU 实际工作时间占总时间的百分比。表示正在执行进程的时间比例,包括用户空间和内核空间程序的执行时间。通常包含以…...
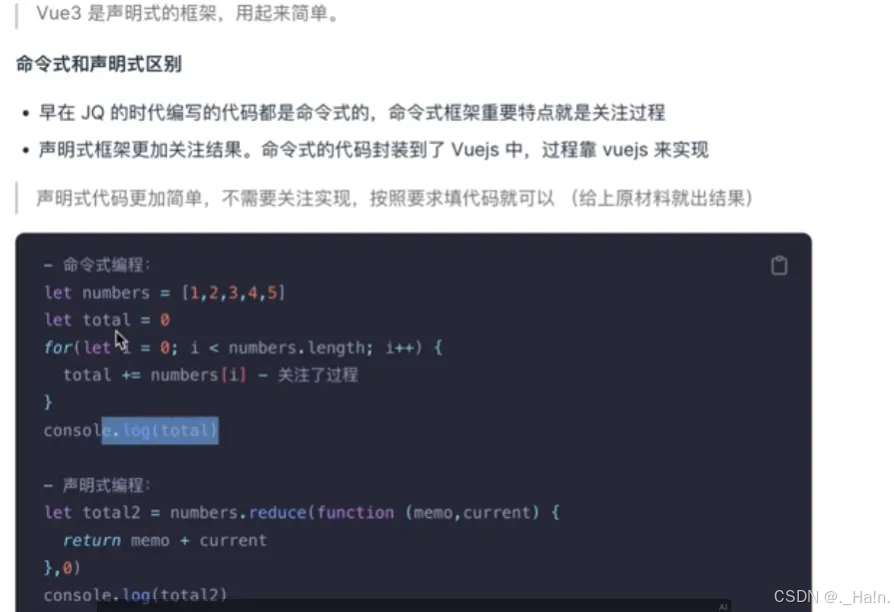
vue源码(二)
文章目录 数据代理示例 初始化组件实例计算属性基本用法ComputedReflmpl类计算属性的创建 Vue3的特点及优势声明式框架采用虚拟DOM区分编译时和进行时 Vue3设计思想 数据代理 示例 以下代码主要是有一个msg的响应式数据,点击按钮后修改msg的内容。根据代码可知有两…...

Ubuntu切换lowlatency内核
文章目录 一. 前言二. 开发环境三. 具体操作 一. 前言 低延迟内核(Lowlatency Kernel) 旨在为需要低延迟响应的应用程序设计的内核版本。Linux-lowlatency特别适合音频处理、实时计算、游戏和其他需要及时响应的实时任务。其主要特点是优化了中断处理、调…...
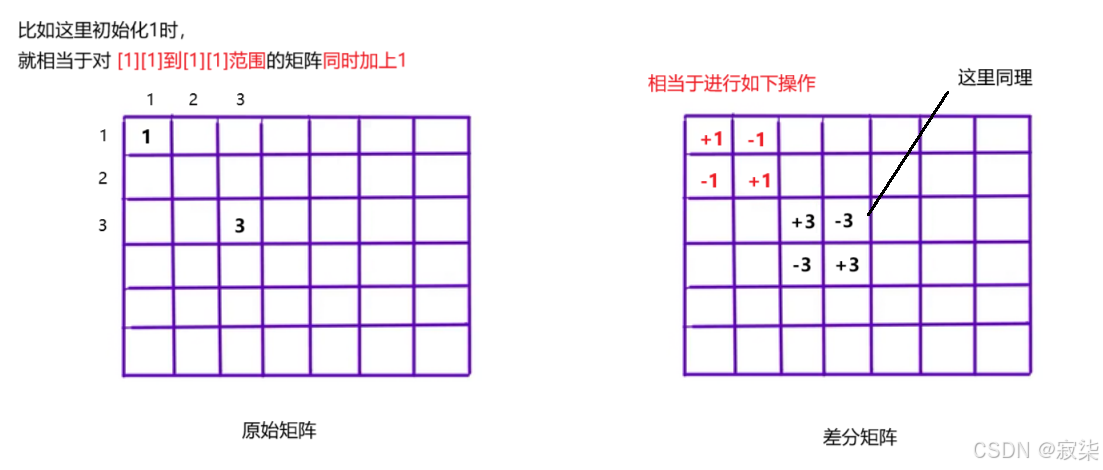
C++算法——差分
1.差分 差分与前缀和的核心思想相同,是预处理,可以在暴力枚举的过程中,快速给出查询的结果,从而优化时间复杂度。 是经典的用空间替换时间的做法。 2.一维差分数组 前缀和与差分是⼀对互逆的运算,对差分数组做前缀…...
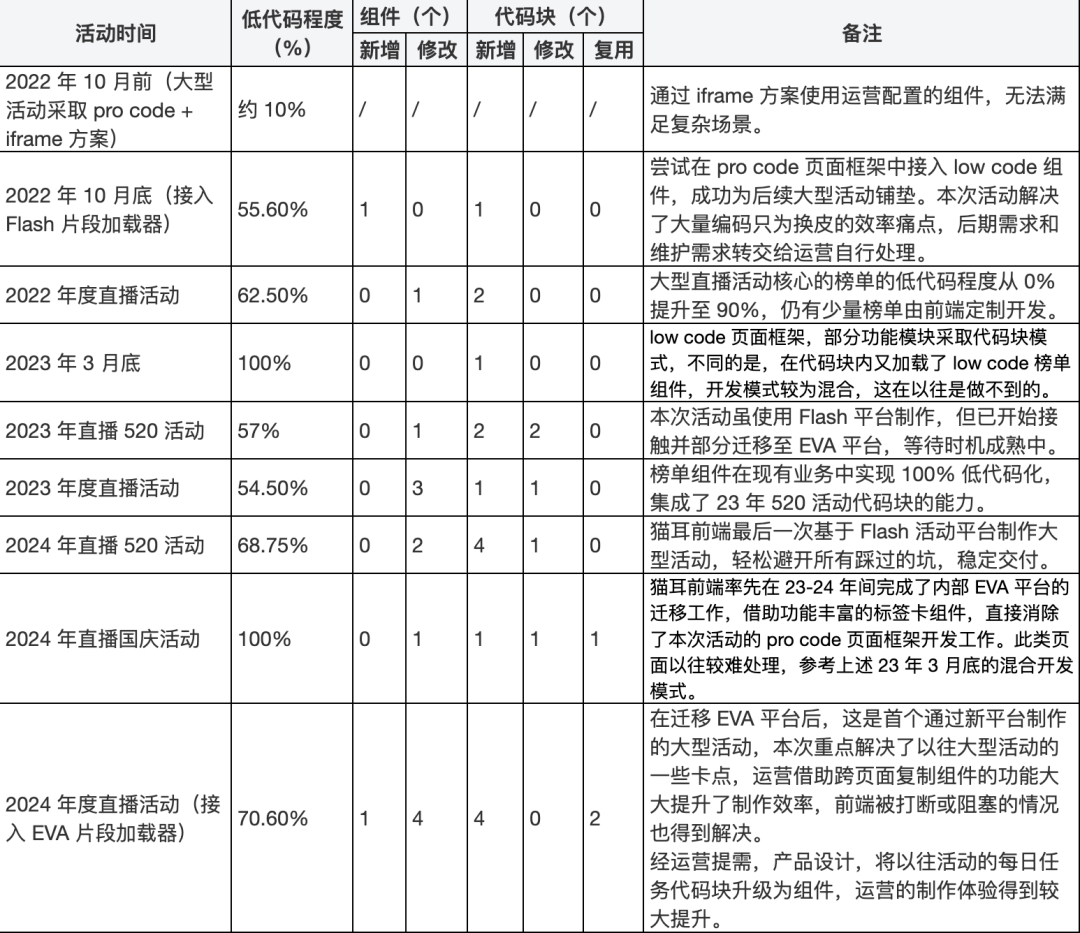
猫耳大型活动提效——组件低代码化
1. 引言 猫耳前端在开发活动的过程中,经历过传统的 pro code 阶段,即活动页面完全由前端开发编码实现,直到 2020 年接入公司内部的低代码活动平台,满足了大部分日常活动的需求,运营可自主配置活动并上线,释…...
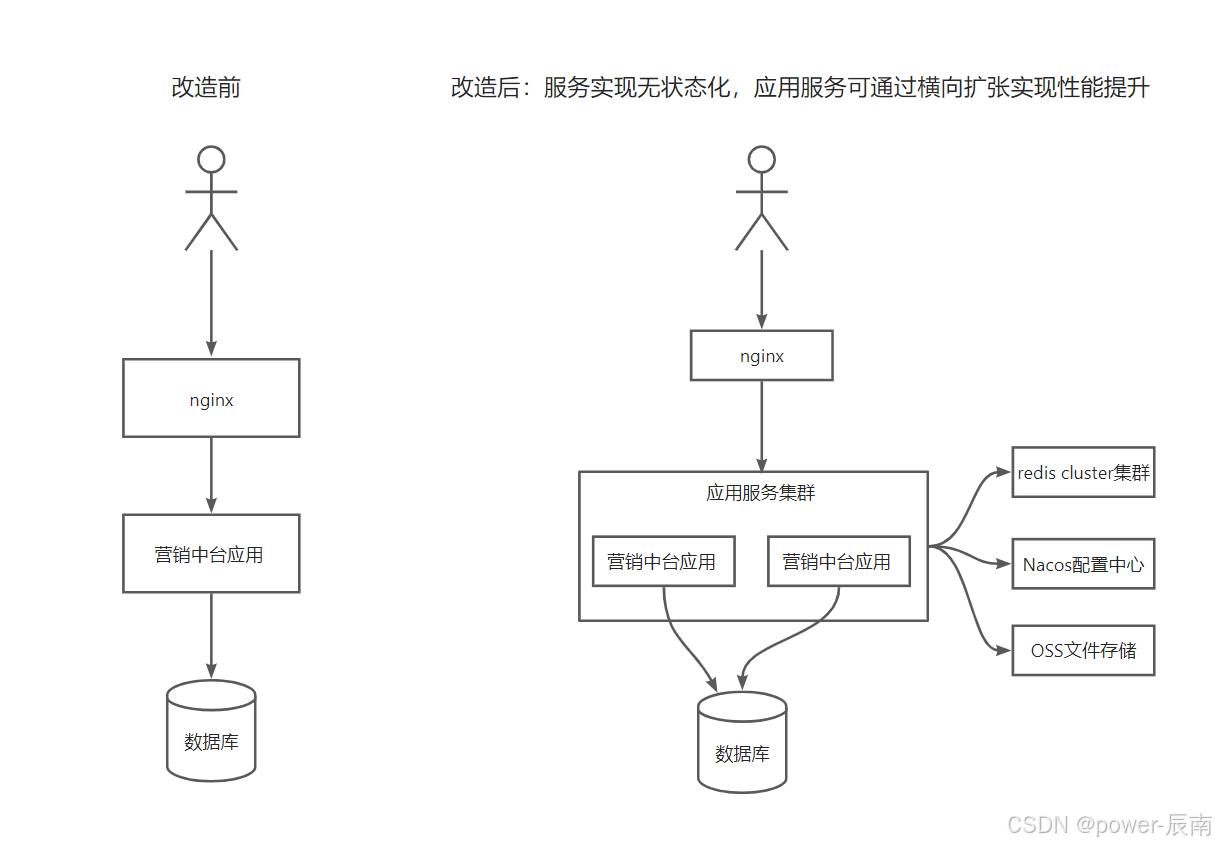
亿级分布式系统架构演进实战(二)- 横向扩展(服务无状态化)
亿级分布式系统架构演进实战(一)- 总体概要 服务无状态化详细设计 目标:确保服务实例完全无状态,可任意扩缩容 1. 会话存储改造(Session Management) 核心问题:传统单体应用中,用…...

零成本短视频爆款制造手册
——Q版+情感+互动的流量密码拆解 适用平台:抖音/快手/视频号 核心指标:点赞率>10% | 完播率>40% | 涨粉成本<0.3元 一、底层逻辑框架 1. 爆款元素融合公式 [ 3秒钩子 ] + [ 7秒沉浸 ] + [ 5秒引爆 ] = 15秒黄金结构 │ │ └─▶ 互动指令+情感…...

红队思想:Live off the Land - 靠山吃山,靠水吃水
在网络安全领域,尤其是红队(Red Team)渗透测试中,“Live off the Land”(简称 LotL,中文可译为“靠山吃山,靠水吃水”)是一种极具隐秘性和实用性的攻击策略。这一理念源于现实生活中…...

C语言八股---预处理,编译,汇编与链接篇
前言 从多个.c文件到达一个可执行文件的四步: 预处理–>编译–>汇编–>链接 预处理 预处理过程就是预处理器处理这些预处理指令(要不然编译器完全不认识),最终会生成 main.i的文件 主要做的事情有如下几点: 展开头文件展开宏条件编译删除注释添加行号等信息保留…...
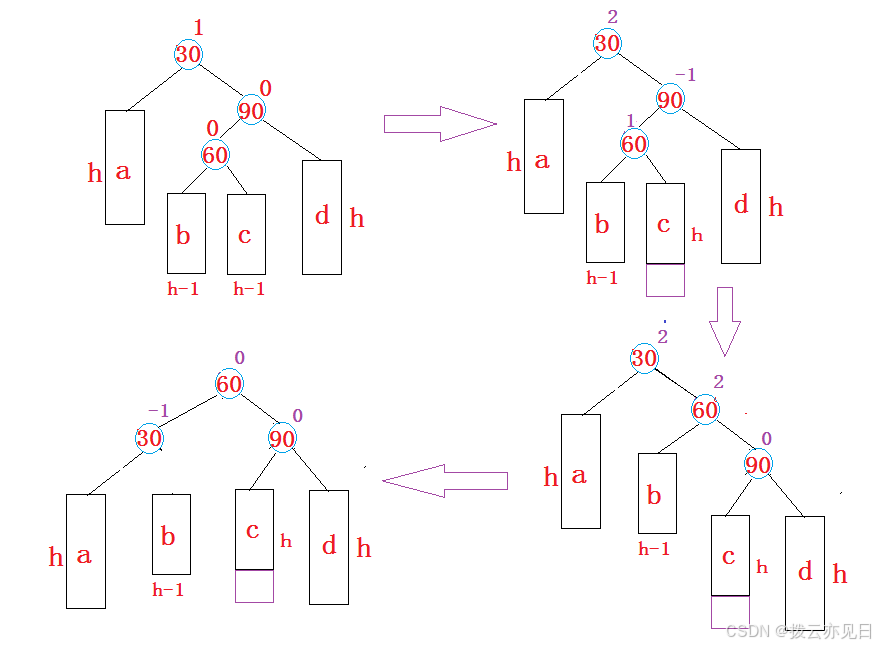
平衡二叉树(AVL树)
平衡二叉树是啥我就不多说了,本篇博客只讲原理与方法。 首先引入平衡因子的概念。平衡因子(Balance Factor),以下简称bf。 bf 右子树深度 - 左子树深度。平衡结点的平衡因子可为:-1,0,1。除此…...
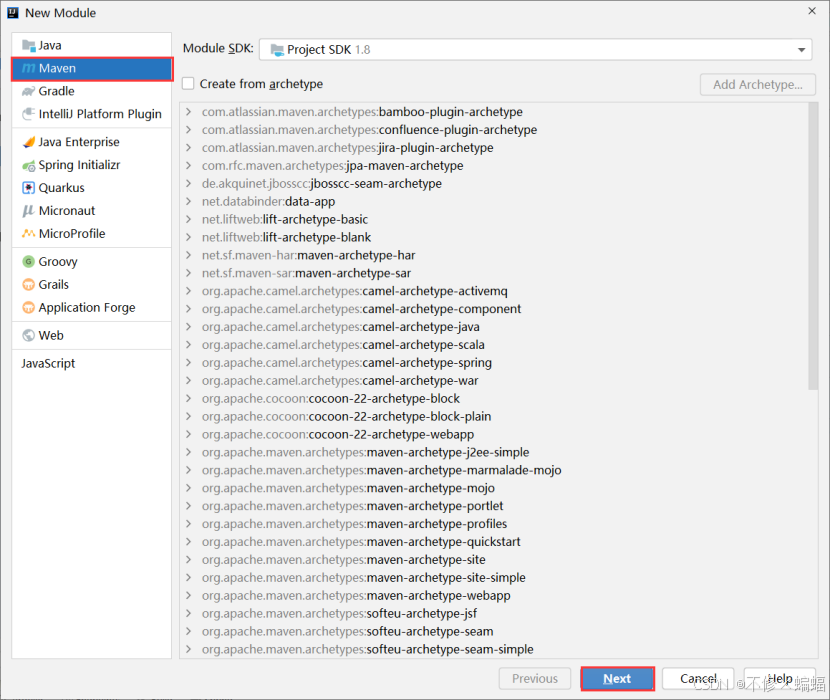
SpringBoot(一)--搭建架构5种方法
目录 一、⭐Idea从spring官网下载打开 2021版本idea 1.打开创建项目 2.修改pom.xml文件里的版本号 2017版本idea 二、从spring官网下载再用idea打开 三、Idea从阿里云的官网下载打开 编辑 四、Maven项目改造成springboot项目 五、从阿里云官网下载再用idea打开 Spri…...
)
Sora 2原生接入Unity 6.0:5步完成神经渲染管线嵌入,实测帧率提升47%(附GitHub认证插件)
更多请点击: https://kaifayun.com 第一章:Sora 2与Unity整合 Sora 2作为新一代AI视频生成引擎,其开放API设计天然支持与实时3D引擎的深度协同。Unity 2023.2版本通过URP(Universal Render Pipeline)与C# Job System提…...
)
Unity事件系统实战:用事件驱动重构你的金币拾取逻辑(告别硬编码)
Unity事件系统实战:用事件驱动重构你的金币拾取逻辑(告别硬编码)在游戏开发中,我们经常会遇到这样的场景:玩家拾取金币后,需要更新UI、播放音效、解锁成就、保存数据……如果把这些逻辑全部写在金币拾取的代…...
:3类高危使用场景+2个监管红线预警)
Claude SWOT分析(内部风控文档流出版):3类高危使用场景+2个监管红线预警
更多请点击: https://intelliparadigm.com 第一章:Claude SWOT分析(内部风控文档流出版):3类高危使用场景2个监管红线预警 高危使用场景识别 在企业级AI应用中,Claude模型若未经严格风控适配,…...

LoRa物联网与动态基线算法在养殖体温监测中的实战应用
1. 项目概述:为什么我们需要一个智能体温监测系统?在规模化养殖场里干了十几年,我见过太多因为体温异常没被及时发现而导致的损失。一头育肥猪突然不吃食,等饲养员第二天巡栏发现时,可能已经高烧好几天,继发…...
,锁定雾浓度≤0.38的7个关键阈值参数)
【云雾效果商业级交付标准】:基于Adobe Sensei图像雾度分析报告(N=1,247张MJ生成图),锁定雾浓度≤0.38的7个关键阈值参数
更多请点击: https://intelliparadigm.com 第一章:云雾效果商业级交付标准的定义与行业意义 云雾效果在现代数字体验中已超越视觉装饰范畴,成为空间感知建模、沉浸式交互与品牌情绪传达的核心媒介。商业级交付标准并非仅关注“是否可见雾气”…...

从API Key管理视角看Taotoken平台的安全与审计功能
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 从API Key管理视角看Taotoken平台的安全与审计功能 对于依赖大模型API进行开发的团队而言,API Key的管理与安全是项目稳…...
到底怎么设?附场景实测)
Unity新手避坑指南:NavMesh烘焙参数(Agent Radius/Height)到底怎么设?附场景实测
Unity导航系统深度解析:Agent参数设置与场景适配实战在Unity游戏开发中,导航系统(Navigation System)是实现角色智能移动的核心模块。对于刚接触Unity导航系统的开发者来说,Agent Radius(代理半径)和Agent Height(代理身高)这两个参数的设置往…...

终极Windows风扇控制指南:FanControl让你的电脑安静又高效
终极Windows风扇控制指南:FanControl让你的电脑安静又高效 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trendin…...

如何用Nucleus Co-Op让单机游戏变身本地多人分屏神器
如何用Nucleus Co-Op让单机游戏变身本地多人分屏神器 【免费下载链接】nucleuscoop Starts multiple instances of a game for split-screen multiplayer gaming! 项目地址: https://gitcode.com/gh_mirrors/nu/nucleuscoop 还在为想和朋友一起玩游戏却只有一台电脑而烦…...
从Stable Diffusion到DiT:为什么说Transformer是扩散模型的下一站?
从Stable Diffusion到DiT:Transformer如何重塑扩散模型的未来 在图像生成领域,扩散模型正经历着从U-Net架构向Transformer架构的范式转移。这一转变不仅仅是技术组件的简单替换,而是代表着生成式AI在可扩展性、训练效率和模型容量方面的重大突…...