狮子座大数据分析(python爬虫版)
十二星座爱情性格 - 星座屋
首先找到一个星座网站,作为基础内容,来获取信息

网页爬取与信息提取
我们首先利用爬虫技术(如 Python 中的 requests 与 BeautifulSoup 库)获取页面内容。该页面(xzw.com/astro/leo/)中,除了狮子座基本属性外,还有两个重点部分:
- 狮子座女生:摘要中提到“特点:心地善良、爱心丰富”,“弱点:喜欢引人注目”,“爱情:不太懂得疼爱对方”。
- 狮子座男生:摘要中提到“特点:热情、组织能力、正义感”,“弱点:高傲、虚荣心”,“爱情:追求轰轰烈烈的爱情”。
通过解析这些文字,我们可以归纳:
- 狮子座男生:性格热情、具备较强的组织能力和正义感,但有时表现出高傲和虚荣,热衷于追求激情四溢的爱情。
- 狮子座女生:性格温暖、心地善良且富有爱心,但喜欢吸引他人注意,在爱情中可能表现得不够细腻体贴。
import requests
from bs4 import BeautifulSoup
import timebase_url = "https://www.xzw.com/astro/leo/"
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)"
}collected_texts = []
visited_urls = set()def scrape_page(url):global collected_textsif url in visited_urls:returntry:response = requests.get(url, headers=headers, timeout=10)response.encoding = 'utf-8'soup = BeautifulSoup(response.text, 'html.parser')page_text = soup.get_text(separator="\n", strip=True)collected_texts.append(page_text)visited_urls.add(url) # 标记该 URL 已访问print(f"已爬取: {url} (当前累计 {len(collected_texts)} 条文本)")for link in soup.find_all('a', href=True):full_link = link['href']if full_link.startswith("/"):full_link = "https://www.xzw.com" + full_linkif full_link.startswith(base_url) and full_link not in visited_urls:if len(collected_texts) >= 1000:returntime.sleep(1)scrape_page(full_link)except Exception as e:print(f"爬取 {url} 失败: {e}")scrape_page(base_url)with open("test.txt", "w", encoding="utf-8") as file:file.write("\n\n".join(collected_texts))print("🎉 爬取完成,数据已保存到 test.txt 文件!")
将爬取到的数据存入test.txt中后,进行分析
import jieba
import re
from collections import Counterdef read_file(file_path):with open(file_path, 'r', encoding='utf-8') as f:text = f.read()return textdef clean_text(text):text = re.sub(r'\s+', '', text)text = re.sub(r'[^\u4e00-\u9fa5]', '', text)return textdef tokenize(text):words = jieba.lcut(text)return wordsdef count_words(words):return Counter(words)POSITIVE_WORDS = {"自信", "阳光", "大方", "慷慨", "勇敢", "领导", "果断", "豪爽", "热情", "友善","善良"}
NEGATIVE_WORDS = {"自负", "霸道", "固执", "急躁", "冲动", "强势", "高傲", "爱面子", "争强好胜", "以自我为中心"}def analyze_personality(word_counts):total_words = sum(word_counts.values())pos_count = sum(word_counts[word] for word in POSITIVE_WORDS if word in word_counts)neg_count = sum(word_counts[word] for word in NEGATIVE_WORDS if word in word_counts)pos_percent = (pos_count / total_words) * 100 if total_words > 0 else 0neg_percent = (neg_count / total_words) * 100 if total_words > 0 else 0neutral_percent = 100 - pos_percent - neg_percentreturn pos_percent, neg_percent, neutral_percentdef evaluate_personality(pos_percent, neg_percent):if pos_percent > neg_percent:conclusion = "狮子座整体评价较好,正面特质占比更高。"elif neg_percent > pos_percent:conclusion = "狮子座评价存在较多负面特质,但也有正面评价。"else:conclusion = "狮子座评价较为中立,正负面评价相当。"return conclusiondef main():text = read_file("test.txt")text = clean_text(text)words = tokenize(text)word_counts = count_words(words)pos_percent, neg_percent, neutral_percent = analyze_personality(word_counts)conclusion = evaluate_personality(pos_percent, neg_percent)print("🔍 狮子座性格评价分析:")print(f"✅ 正面评价占比:{pos_percent:.2f}%")print(f"❌ 负面评价占比:{neg_percent:.2f}%")print(f"⚖ 中立评价占比:{neutral_percent:.2f}%")print(f"📢 结论:{conclusion}")if __name__ == "__main__":main()

进行评价:
import jieba
import jieba.posseg as pseg
import re
from collections import Counter
from wordcloud import WordCloud
import matplotlib.pyplot as pltdef read_file(file_path):with open(file_path, 'r', encoding='utf-8') as f:text = f.read()return textdef clean_text(text):text = re.sub(r'\s+', '', text) # 去除空格和换行符text = re.sub(r'[^\u4e00-\u9fa5]', '', text) # 只保留中文return textdef tokenize(text):words = pseg.lcut(text) # 使用 jieba 进行分词并标注词性adjectives = [word for word, flag in words if flag == 'a'] # 只保留形容词return adjectivesdef count_words(words):return Counter(words)def generate_wordcloud(word_counts):wordcloud = WordCloud(font_path='msyh.ttc', width=800, height=600, background_color='white').generate_from_frequencies(word_counts)plt.figure(figsize=(10, 8))plt.imshow(wordcloud, interpolation='bilinear')plt.axis('off')plt.show()def top_words(word_counts, top_n=10):return dict(word_counts.most_common(top_n))def main():text = read_file("test.txt")text = clean_text(text)words = tokenize(text)word_counts = count_words(words)top_n_words = top_words(word_counts, top_n=10)generate_wordcloud(top_n_words)if __name__ == "__main__":main()

多种图:
import matplotlib
matplotlib.use('TkAgg')
import matplotlib.pyplot as plt
import jieba
import jieba.posseg as pseg
import re
from collections import Counter
from wordcloud import WordCloud# 设置支持中文的字体(以黑体为例)
plt.rcParams['font.sans-serif'] = ['SimHei']
# 防止负号显示为方块
plt.rcParams['axes.unicode_minus'] = Falsedef read_file(file_path):with open(file_path, 'r', encoding='utf-8') as f:text = f.read()return textdef clean_text(text):text = re.sub(r'\s+', '', text)text = re.sub(r'[^\u4e00-\u9fa5]', '', text)return textdef tokenize(text):# 使用 jieba 对文本进行分词和词性标注words = pseg.lcut(text)# 仅保留形容词相关词性(例如 'a' 表示形容词),过滤掉名词等其它词性adjectives = [word for word, flag in words if flag in ['a', 'ad', 'an', 'ag']]return adjectivesdef count_words(words):return Counter(words)def generate_wordcloud(word_counts):wordcloud = WordCloud(font_path='msyh.ttc', width=800, height=600, background_color='white').generate_from_frequencies(word_counts)plt.figure(figsize=(10, 8))plt.imshow(wordcloud, interpolation='bilinear')plt.axis('off')plt.title("狮子座相关评价词云", fontsize=20, fontweight='bold', family='Microsoft YaHei')plt.show()def plot_bar_chart(word_counts, top_n=10):top_words = dict(word_counts.most_common(top_n))plt.figure(figsize=(10, 6))plt.bar(top_words.keys(), top_words.values(), color='skyblue')plt.title("狮子座最常见形容词柱状图", fontsize=18, fontweight='bold', family='Microsoft YaHei')plt.xlabel("形容词", fontsize=14, family='Microsoft YaHei')plt.ylabel("频率", fontsize=14, family='Microsoft YaHei')plt.xticks(rotation=45)plt.show()def plot_horizontal_bar_chart(word_counts, top_n=10):top_words = dict(word_counts.most_common(top_n))plt.figure(figsize=(10, 6))plt.barh(list(top_words.keys()), list(top_words.values()), color='lightcoral')plt.title("狮子座最常见形容词条形图", fontsize=18, fontweight='bold', family='Microsoft YaHei')plt.xlabel("频率", fontsize=14, family='Microsoft YaHei')plt.ylabel("形容词", fontsize=14, family='Microsoft YaHei')plt.show()def plot_pie_chart(word_counts, top_n=5):top_words = dict(word_counts.most_common(top_n))plt.figure(figsize=(8, 8))plt.pie(top_words.values(), labels=top_words.keys(), autopct='%1.1f%%', startangle=140,colors=['skyblue', 'lightgreen', 'lightcoral', 'gold', 'lightpink'])plt.title("狮子座最常见形容词饼状图", fontsize=18, fontweight='bold', family='Microsoft YaHei')plt.show()def main():text = read_file("test.txt")text = clean_text(text)words = tokenize(text)word_counts = count_words(words)generate_wordcloud(word_counts)plot_bar_chart(word_counts)plot_horizontal_bar_chart(word_counts)plot_pie_chart(word_counts)if __name__ == "__main__":main()



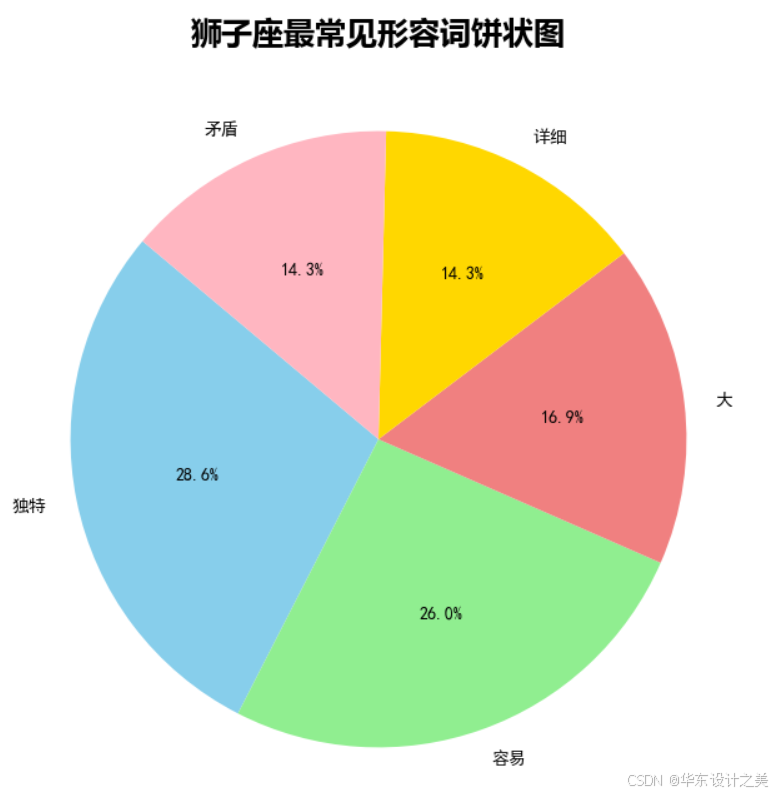
相关文章:
狮子座大数据分析(python爬虫版)
十二星座爱情性格 - 星座屋 首先找到一个星座网站,作为基础内容,来获取信息 网页爬取与信息提取 我们首先利用爬虫技术(如 Python 中的 requests 与 BeautifulSoup 库)获取页面内容。该页面(xzw.com/astro/leo/&…...
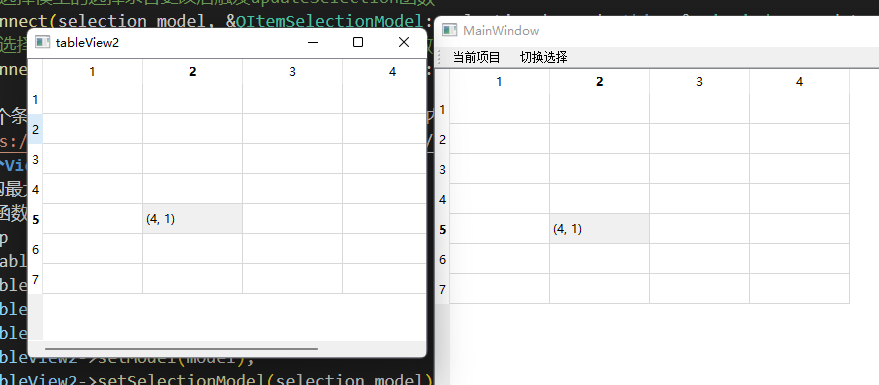
QT系列教程(18) MVC结构之QItemSelectionModel模型介绍
视频教程 https://www.bilibili.com/video/BV1FP4y1z75U/?vd_source8be9e83424c2ed2c9b2a3ed1d01385e9 QItemSelectionModel Qt的MVC结构支持多个View共享同一个model,包括该model的选中状态等。我们可以通过设置QItemSelectionModel,来更改View的选…...

git设置本地仓库和远程仓库
设置本地仓库和远程仓库是使用Git进行版本控制的基本操作。以下是详细步骤: 创建本地仓库 初始化本地仓库: 打开命令行工具(如Terminal或Git Bash)。导航到你希望创建Git仓库的项目文件夹。运行以下命令来初始化一个新的Git仓库&…...

openharmony中HDF驱动框架源码梳理-驱动加载流程
要想大概了解一个公司,我们可能只需要知道它的运行逻辑即可,例如我们只需要知道它有财务有研发有运营等,财务报销、研发负责产品等即可,但是如果想深入具体的了解的话我们就要了解都有什么部门(对象)、各部门都包含哪些职责(对象方…...

golang 高性能的 MySQL 数据导出
需求导出方式对比方案1:快照导出(耗时:1.5s)方案2: 偏移分页(耗时:4s)方案 3:普通分页(耗时:4min40s) 需求 导出 MySQL 数据 分析: 一次性 select 大量数据带来的问题 性能问题: 数据库负载:大量数据查询会增加数据库的CPU、内存和I/O负担ÿ…...

31-判断子序列
给定字符串 s 和 t ,判断 s 是否为 t 的子序列。 字符串的一个子序列是原始字符串删除一些(也可以不删除)字符而不改变剩余字符相对位置形成的新字符串。(例如,"ace"是"abcde"的一个子序列&#x…...
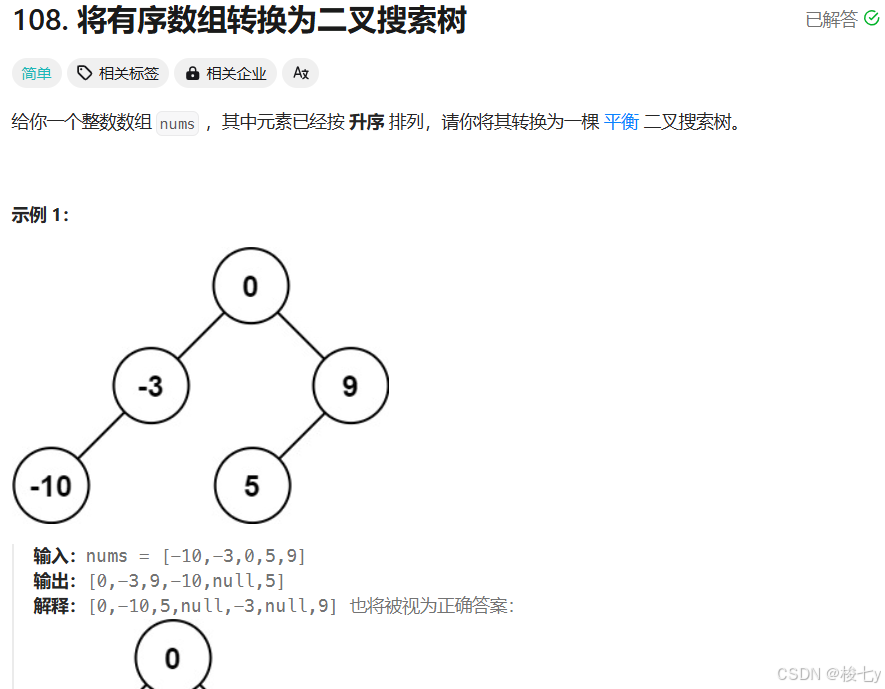
leetcode日记(95)将有序数组转换为二叉搜索树
很简单,感觉自己越来越适应数据结构题目了…… /*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : va…...

使用SSH密钥连接本地git 和 github
目录 配置本地SSH,添加到github首先查看本地是否有SSH密钥生成SSH密钥,和邮箱绑定将 SSH 密钥添加到 ssh-agent:显示本地公钥*把下面这一串生成的公钥存到github上* 验证SSH配置是否成功终端跳转到本地仓库把http协议改为SSH(如果…...

C语言基础之【内存管理】
C语言基础之【内存管理】 存储类型作用域普通局部变量静态局部变量普通全局变量静态全局变量全局函数和静态函数 内存布局内存分区存储类型与内存四区内存操作函数memset()memcpy()memmove()memcmp() 堆区内存分配和释放malloc()free() 内存分区代码分析返回栈区地址返回data区…...

C盘清理技巧分享:释放空间,提升电脑性能
目录 1. 引言 2. C盘空间不足的影响 3. C盘清理的必要性 4. C盘清理的具体技巧 4.1 删除临时文件 4.2 清理系统还原点 4.3 卸载不必要的程序 4.4 清理下载文件夹 4.5 移动大文件到其他盘 4.6 清理系统缓存 4.7 使用磁盘清理工具 4.8 清理Windows更新文件 4.9 禁用…...
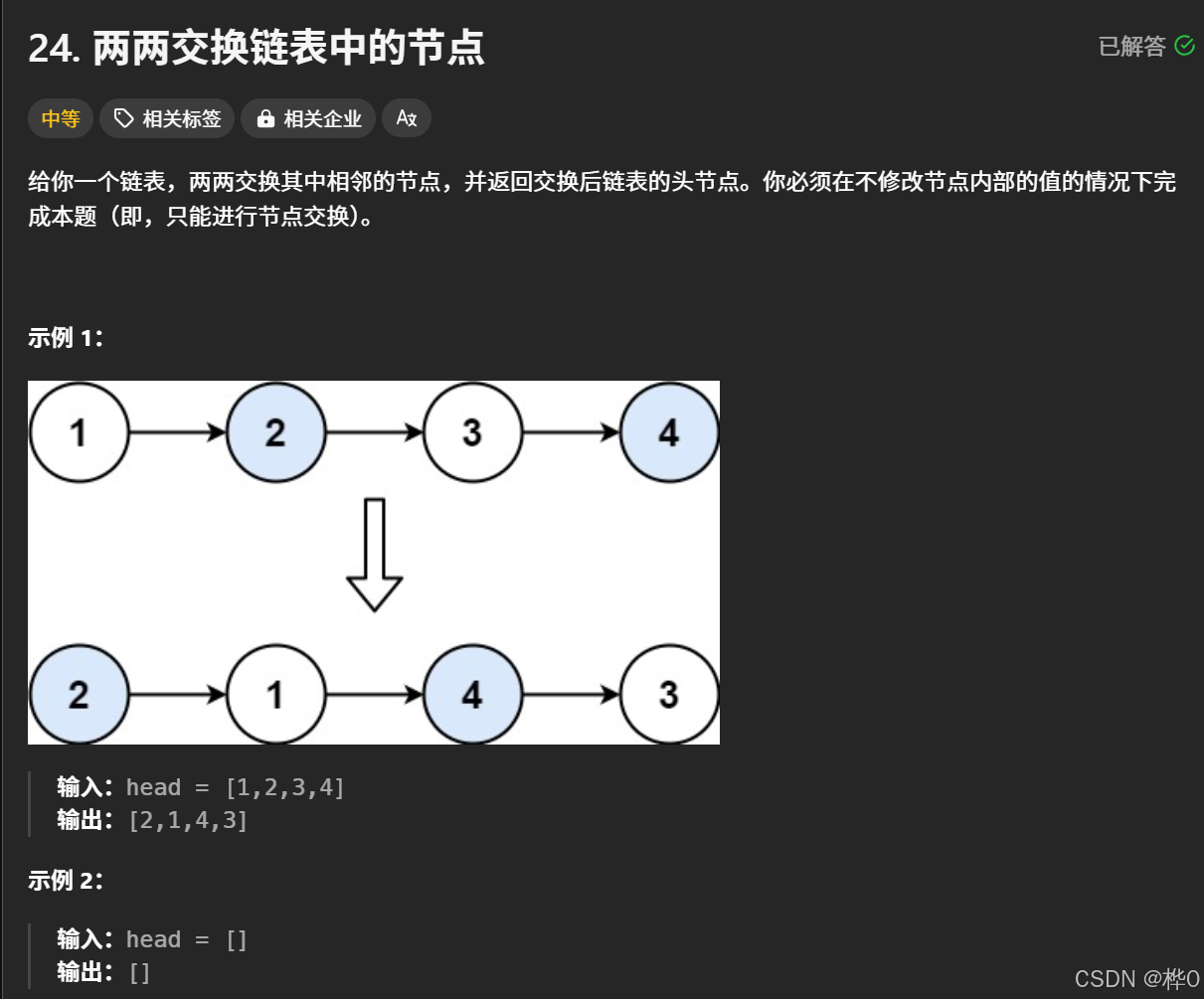
每天一道算法题【蓝桥杯】【两两交换链表中的节点】
思路 本质问题可以分成若干个子问题 即把前两个链表交换,并与后面的链表相连 故实现函数功能调用自身递归即可 #define _CRT_SECURE_NO_WARNINGS 1 struct ListNode {int val;ListNode *next;ListNode() : val(0), next(nullptr) {}ListNode(int x) : val(x), nex…...

mIoU Class与mIoU Category的区别
mIoU(mean Intersection over Union)是语义分割任务中常用的评估指标,用于衡量模型预测的分割结果与真实标签之间的重叠程度。mIoU Class 和 mIoU Category 的区别主要体现在计算方式和应用场景上: 1. mIoU Class 定义ÿ…...

深入解析 C 语言中含数组和指针的构造体与共同体内存计算
在 C 语言中,构造体(struct)和共同体(union)允许我们将多种数据类型组合到一起。除了常见的基本数据类型之外,经常还会在它们中嵌入数组和指针。由于数组的内存是连续分配的,而指针的大小与平台…...
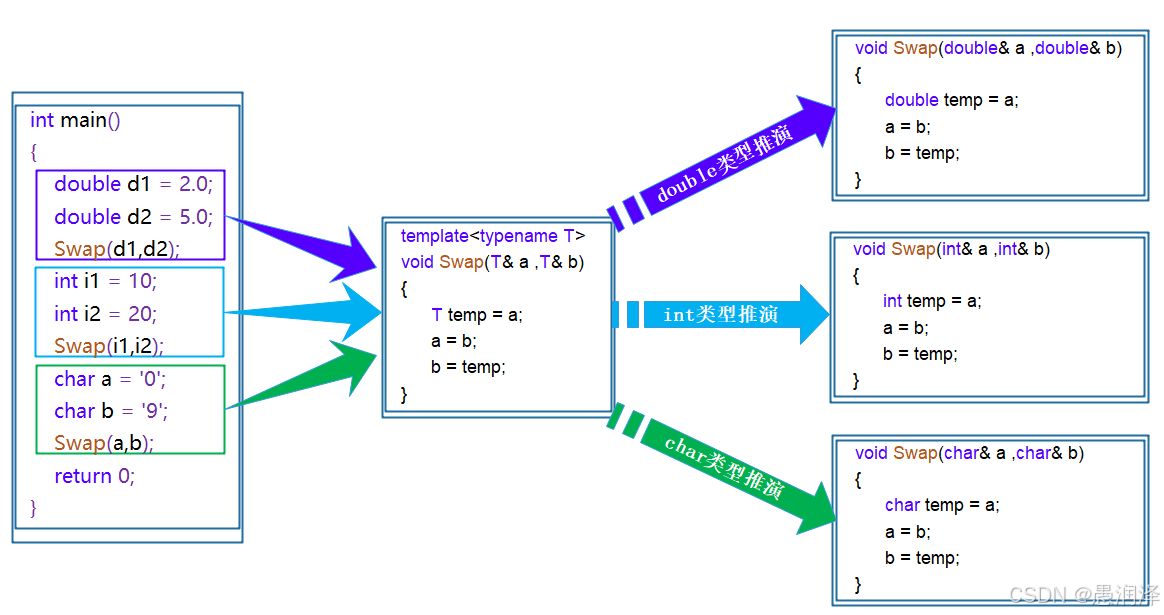
【C++模板】:开启泛型编程之门(函数模版,类模板)
📝前言: 在上一篇文章C内存管理中我们介绍了C的内存管理,重点介绍了与C语言的区别,以及new和delete。这篇文章我们将介绍C的利器——模板。 在C编程世界里,模板是一项强大的特性,它为泛型编程奠定了坚实基础…...

HEC-HMS水文建模全解析:气候变化与极端水文、离散化流域单元精准刻画地表径流、基流与河道演进过程
一、技术革新:数字流域的精密算法革命 在全球气候变化与极端水文事件频发的双重压力下,HEC-HMS模型凭借其半分布式建模架构与多尺度仿真能力,已成为现代流域管理的核心工具。该模型通过离散化流域单元精准刻画地表径流、基流与河…...
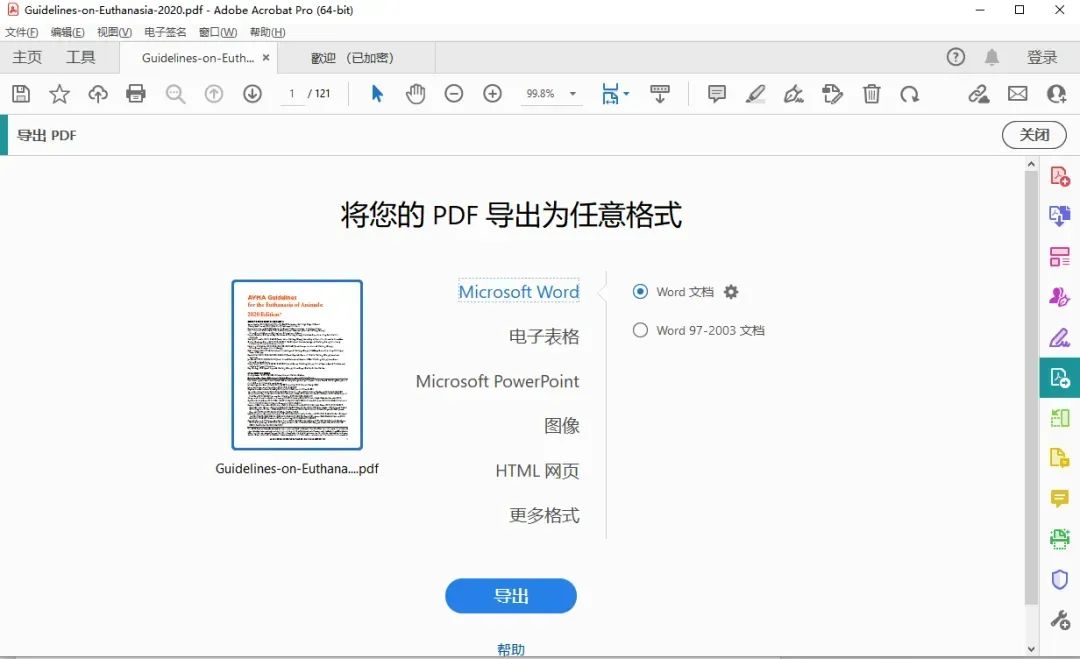
具备多种功能的PDF文件处理工具
软件介绍 在日常办公和学习场景中,PDF文件使用极为频繁,而一款功能强大的PDF编辑软件能大幅提升处理效率。 今天要介绍的Adobe Acrobat Pro DC 2024.005.20414,就具备像编辑Word文档一样便捷编辑PDF的能力。 PDF文档在学习和工作中广泛应用…...

【SpringMVC】SpringMVC的启动过程与原理分析:从源码到实战
SpringMVC的启动过程与原理分析:从源码到实战 SpringMVC是Spring框架中用于构建Web应用的核心模块,它基于MVC(Model-View-Controller)设计模式,提供了灵活且强大的Web开发能力。本文将深入分析SpringMVC的启动过程、核…...
转自南京日报:天洑软件创新AI+仿真技术变制造为“智造
以下文章来源:南京日报 进入3月,南京天洑软件有限公司(以下简称天洑软件)董事长张明更加忙碌。“公司强调工业软件在数字经济与先进制造业融合中的关键作用,并已广泛应用在能源、电力和航空等领域。”他说,…...

golang dlv调试工具
golang dlv调试工具 在goland2022.2版本 中调试go程序报错 WARNING: undefined behavior - version of Delve is too old for Go version 1.20.7 (maximum supported version 1.19) 即使你go install了新的dlv也无济于事 分析得出Goland实际使用的是 Goland安装目录下dlv 例…...
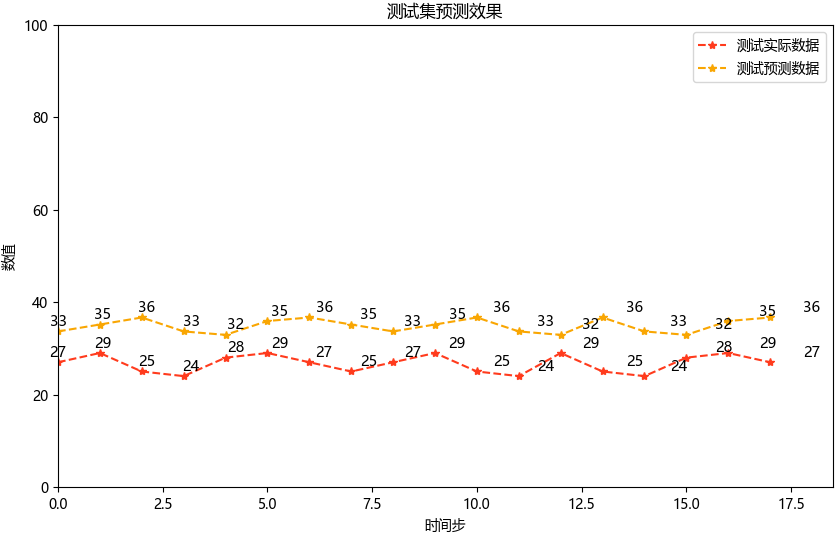
LSTM方法实践——基于LSTM的汽车销量时序建模与预测分析
Hi,大家好,我是半亩花海。本实验基于汽车销量时序数据,使用LSTM网络(长短期记忆网络)构建时间序列预测模型。通过数据预处理、模型训练与评估等完整流程,验证LSTM在短期时序预测中的有效性。 目录 一、实验…...

立法强制技术目标为何违背工程创新规律?
1. 项目概述:当立法者试图为工程目标“画图纸”作为一名在电子工程领域摸爬滚打了十几年的工程师,我经常在技术社区和行业媒体上看到一种让我既无奈又担忧的讨论:立法机构试图通过一纸法令,来规定某个具体技术目标必须在未来某个时…...

90%的程序员都不知道,转大模型根本不用从头学深度学习
文章目录前言一、大模型时代,传统深度学习的学习路径已经彻底过时了1.1 以前做AI,确实得先学深度学习1.2 现在做AI,更像是开汽车1.3 90%的大模型岗位,根本不需要深度学习底层知识二、90%的大模型开发工作,到底在做什么…...

从零实现带霍尔传感器的BLDC方波调速系统
1. 从零搭建BLDC调速系统的硬件准备 第一次接触带霍尔传感器的无刷直流电机时,我对着桌上散落的电机、驱动板和STM32开发板发呆了半小时。这种看似简单的三线电机,内部却藏着精密的磁场控制和时序逻辑。我们先来认识下核心部件:BLDC电机通常有…...
)
从医学到金融:用Python实战Cox比例风险模型进行企业风险预测(附完整代码)
从医学到金融:用Python实战Cox比例风险模型进行企业风险预测 在医疗领域,Cox比例风险模型早已成为生存分析的金标准。但鲜为人知的是,这套强大的统计工具同样适用于金融风险评估——从预测企业破产概率到评估供应链中断风险,生存分…...

CANN/asc-devkit asc_select矢量选择函数
asc_select 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode.com…...

如何轻松解密Widevine加密视频:完整免费指南
如何轻松解密Widevine加密视频:完整免费指南 【免费下载链接】video_decrypter Decrypt video from a streaming site with MPEG-DASH Widevine DRM encryption. 项目地址: https://gitcode.com/gh_mirrors/vi/video_decrypter 还在为付费视频无法离线保存而…...

XUnity.AutoTranslator:5步实现Unity游戏实时翻译的完整解决方案
XUnity.AutoTranslator:5步实现Unity游戏实时翻译的完整解决方案 【免费下载链接】XUnity.AutoTranslator 项目地址: https://gitcode.com/gh_mirrors/xu/XUnity.AutoTranslator 你是否曾经因为语言障碍而错过心仪的外语游戏?XUnity.AutoTransla…...

前端状态管理:主流状态管理库对比与选型指南
前端状态管理:主流状态管理库对比与选型指南 前言 状态管理是前端开发中的核心问题。随着应用复杂度的增加,选择一个合适的状态管理库变得越来越重要。今天我就来给大家对比一下目前主流的状态管理库,帮助你做出最佳选择。 主流状态管理库概览…...

自建S3兼容对象存储:Shebe部署、集成与运维全指南
1. 项目概述:一个面向开发者的开源文件存储与分发解决方案最近在折腾个人项目,需要处理用户上传的图片、文档,还要能快速分发到前端展示。自己搭存储服务吧,从对象存储到CDN,配置起来一堆事儿,用第三方云服…...

基于Athena-Public框架的LLM全栈应用开发实践与架构解析
1. 项目概述与核心价值 最近在梳理一些开源项目时,发现了一个名为“Athena-Public”的仓库,作者是winstonkoh87。这个项目名听起来就很有意思,Athena(雅典娜)是智慧女神,一个公开的“智慧”项目,…...