Django-ORM-select_related
Django-ORM-select_related
- 作用
- 使用场景
- 示例
- 无 select_related 的查询
- 有 select_related 的查询
- 如何理解 "只发起一次查询,包含所有相关作者信息"
- 1. select_related 的工作原理
- 2. 具体示例解析
- 3. 为什么只发起一次查询
- 数据库中的books量巨大,使用`select_related`导致服务崩掉,如何解决
- 程序层面优化
- 1. 优化 select_related 的使用
- 2. 限制查询字段
- 3. 分页(Pagination)
- 使用 Django 内置的分页器
- 使用基于游标的分页(Cursor-based Pagination)
- 4. 批量处理(Batch Processing)
- 5. 使用 iterator
- 6. 使用 prefetch_related 结合 select_related
- 7. 数据库索引优化
- 8. 缓存机制
- 9. 异步处理
- 数据库层面优化
- 10. 数据库层面的优化
作用
select_related 主要用于优化一对一(OneToOneField) 和 外键(ForeignKey) 关系中的查询。
它通过SQL的JOIN操作,在单个查询中获取相关对象的数据,从而减少数据库查询次数。
使用场景
• 当你需要访问外键或一对一关系的相关对象时。
• 适用于深度较浅的关系(通常一层或两层)。
示例
假设有以下模型:
from django.db import modelsclass Author(models.Model):name = models.CharField(max_length=100)class Book(models.Model):title = models.CharField(max_length=100)author = models.ForeignKey(Author, on_delete=models.CASCADE)
无 select_related 的查询
books = Book.objects.all()
for book in books:print(book.author.name) # 每次循环都会发起一次数据库查询
上述代码会对每个 book 对象的 author 执行一次额外的查询,导致“N+1查询问题”。
有 select_related 的查询
books = Book.objects.select_related('author').all()
for book in books:print(book.author.name) # 只发起一次查询,包含所有相关作者信息
通过 select_related,Django 在单个查询中使用JOIN语句同时获取 Book 和对应的 Author 数据,避免了多次查询。
当然,理解 select_related 如何实现“只发起一次查询,包含所有相关作者信息”对于掌握Django的查询优化至关重要。让我们深入探讨这一过程,包括Django如何构建SQL查询、执行查询以及处理结果。
如何理解 “只发起一次查询,包含所有相关作者信息”
1. select_related 的工作原理
select_related 通过SQL JOIN 操作将主查询和相关模型的查询合并为一个单一的数据库查询。这意味着,当你调用 select_related 时,Django会在后台构造一个包含JOIN的SQL语句,一次性从数据库中获取所有需要的数据。
2. 具体示例解析
当你执行 Book.objects.select_related('author').all() 时,Django会生成一个包含JOIN的SQL查询。
SELECT book.id, book.title, book.author_id, author.id, author.name
FROM book
INNER JOIN author ON book.author_id = author.id;
这个查询通过 INNER JOIN 将 book 表和 author 表连接起来,一次性获取所有书籍及其对应的作者信息。
Django将上述SQL语句发送到数据库执行。数据库处理JOIN操作并返回一个包含所有书籍和作者信息的结果集。
Django的ORM会将查询结果映射到相应的Python对象中。具体来说:
• 每个 Book 实例都会包含其相关联的 Author 实例。
• 这些 Author 实例已经被预先加载,不需要额外的数据库查询。
因此,当你迭代 books 并访问 book.author.name 时,Django已经拥有了所有必要的数据,直接从内存中获取 author.name,而不会发起新的数据库查询。
3. 为什么只发起一次查询
关键在于 select_related 使用了JOIN操作,将多个表的数据合并到一个结果集中。这意味着:
• 单一查询:只需要执行一次SQL查询,就可以获取所有相关的数据。
• 减少开销:避免了“N+1查询问题”,即避免了对每个 Book 对象都执行一次额外的查询来获取其 Author。
数据库中的books量巨大,使用select_related导致服务崩掉,如何解决
程序层面优化
拿时间换空间:
- 通过加一些条件只在必要的时候使用 select_related
- 只查询必要字段
- 分页
- 分批
- 迭代器
- 缓存
- 异步
1. 优化 select_related 的使用
如果某些关联数据不需要,可以避免使用 select_related,或者在必要时才使用。
# 只在需要时使用 select_related
books = Book.objects.all()
for book in books:if some_condition(book):author = book.author # 触发单独的查询print(author.name)
或者分情况使用 select_related:
books = Book.objects.filter(some_field=some_value).select_related('author')
for book in books:print(book.author.name)
2. 限制查询字段
只选择需要的字段,减少每次查询的数据量。
books = Book.objects.select_related('author').only('title', 'author__name')
for book in books:print(book.author.name)
或者使用 values 或 values_list:
books = Book.objects.select_related('author').values('title', 'author__name')
for book in books:print(book['author__name'])
3. 分页(Pagination)
将查询结果分批加载,每次只处理一部分数据,避免一次性加载所有记录。
使用 Django 内置的分页器
from django.core.paginator import Paginatorbooks = Book.objects.select_related('author').all()paginator = Paginator(books, 100) # 每页100条记录page_number = 1
while True:page = paginator.get_page(page_number)if not page:breakfor book in page:print(book.author.name)page_number += 1
使用基于游标的分页(Cursor-based Pagination)
对于大数据量且需要高效分页的场景,基于游标的分页更为适用。
from django.db import connectionbooks = Book.objects.select_related('author').order_by('id') # 确保有排序字段batch_size = 1000
offset = 0while True:batch = books[offset:offset + batch_size]if not batch:breakfor book in batch:print(book.author.name)offset += batch_size
注意:对于非常大的数据集,建议使用基于游标的分页库,如 django-elasticsearch-dsl 或其他支持高效分页的工具。
4. 批量处理(Batch Processing)
将数据分成较小的批次进行处理,避免一次性加载所有数据。
from django.db import transactionbatch_size = 1000
books = Book.objects.select_related('author').all()for i in range(0, books.count(), batch_size):batch = books[i:i + batch_size]with transaction.atomic(): # 根据需要使用事务for book in batch:print(book.author.name)
5. 使用 iterator
iterator 方法可以逐批从数据库中获取数据,减少内存消耗。
books = Book.objects.select_related('author').all().iterator()for book in books:print(book.author.name)
注意:使用 iterator 后,无法再次遍历查询集,且缓存机制会有所不同。
6. 使用 prefetch_related 结合 select_related
在某些复杂查询中,可以结合使用 select_related 和 prefetch_related 来优化性能。
books = Book.objects.select_related('author').prefetch_related('other_related_field')
for book in books:print(book.author.name)
但对于大数据量,通常建议优先考虑分页或批量处理。
7. 数据库索引优化
确保在 Book 表的 author_id 字段上有索引,以加快 JOIN 操作的速度。
class Book(models.Model):title = models.CharField(max_length=100)author = models.ForeignKey(Author, on_delete=models.CASCADE, db_index=True) # 确保有索引
8. 缓存机制
对于不经常变化的数据,可以使用缓存来减少数据库查询次数。
from django.core.cache import cachedef get_books():books = cache.get('all_books')if not books:books = list(Book.objects.select_related('author').all().iterator())cache.set('all_books', books, timeout=60*15) # 缓存15分钟for book in books:print(book.author.name)
注意:缓存大数据量可能会占用大量内存,需谨慎使用。
9. 异步处理
将耗时的处理任务放到异步队列中执行,如 Celery,避免阻塞主线程。
# tasks.py
from celery import shared_task
from .models import Book@shared_task
def process_books():books = Book.objects.select_related('author').all().iterator()for book in books:print(book.author.name)# 在视图中调用
process_books.delay()
,
数据库层面优化
10. 数据库层面的优化
https://blog.csdn.net/2303_78378466/article/details/145123310
• 分表分库:将 books 表拆分成多个子表或数据库,减少单个查询的压力。
• 读写分离:将读操作和写操作分离到不同的数据库实例,提升查询性能。
• 使用更高效的数据库:如 PostgreSQL 在处理复杂查询时性能更优,可以考虑切换数据库。
Django-ORM-select_related
- 作用
- 使用场景
- 示例
- 无 select_related 的查询
- 有 select_related 的查询
- 如何理解 "只发起一次查询,包含所有相关作者信息"
- 1. select_related 的工作原理
- 2. 具体示例解析
- 3. 为什么只发起一次查询
- 数据库中的books量巨大,使用`select_related`导致服务崩掉,如何解决
- 程序层面优化
- 1. 优化 select_related 的使用
- 2. 限制查询字段
- 3. 分页(Pagination)
- 使用 Django 内置的分页器
- 使用基于游标的分页(Cursor-based Pagination)
- 4. 批量处理(Batch Processing)
- 5. 使用 iterator
- 6. 使用 prefetch_related 结合 select_related
- 7. 数据库索引优化
- 8. 缓存机制
- 9. 异步处理
- 数据库层面优化
- 10. 数据库层面的优化
相关文章:

Django-ORM-select_related
Django-ORM-select_related 作用使用场景示例无 select_related 的查询有 select_related 的查询 如何理解 "只发起一次查询,包含所有相关作者信息"1. select_related 的工作原理2. 具体示例解析3. 为什么只发起一次查询 数据库中的books量巨大࿰…...

蓝桥杯 k倍区间
题目描述 给定一个长度为 NN 的数列,A1,A2,⋯ANA1,A2,⋯AN,如果其中一段连续的子序列 Ai,Ai1,⋯AjAi,Ai1,⋯Aj ( i≤ji≤j ) 之和是 KK 的倍数,我们就称这个区间 [i,j][i,j] 是 K 倍区间。 你能求出数列中总共有多少个 KK 倍区间…...
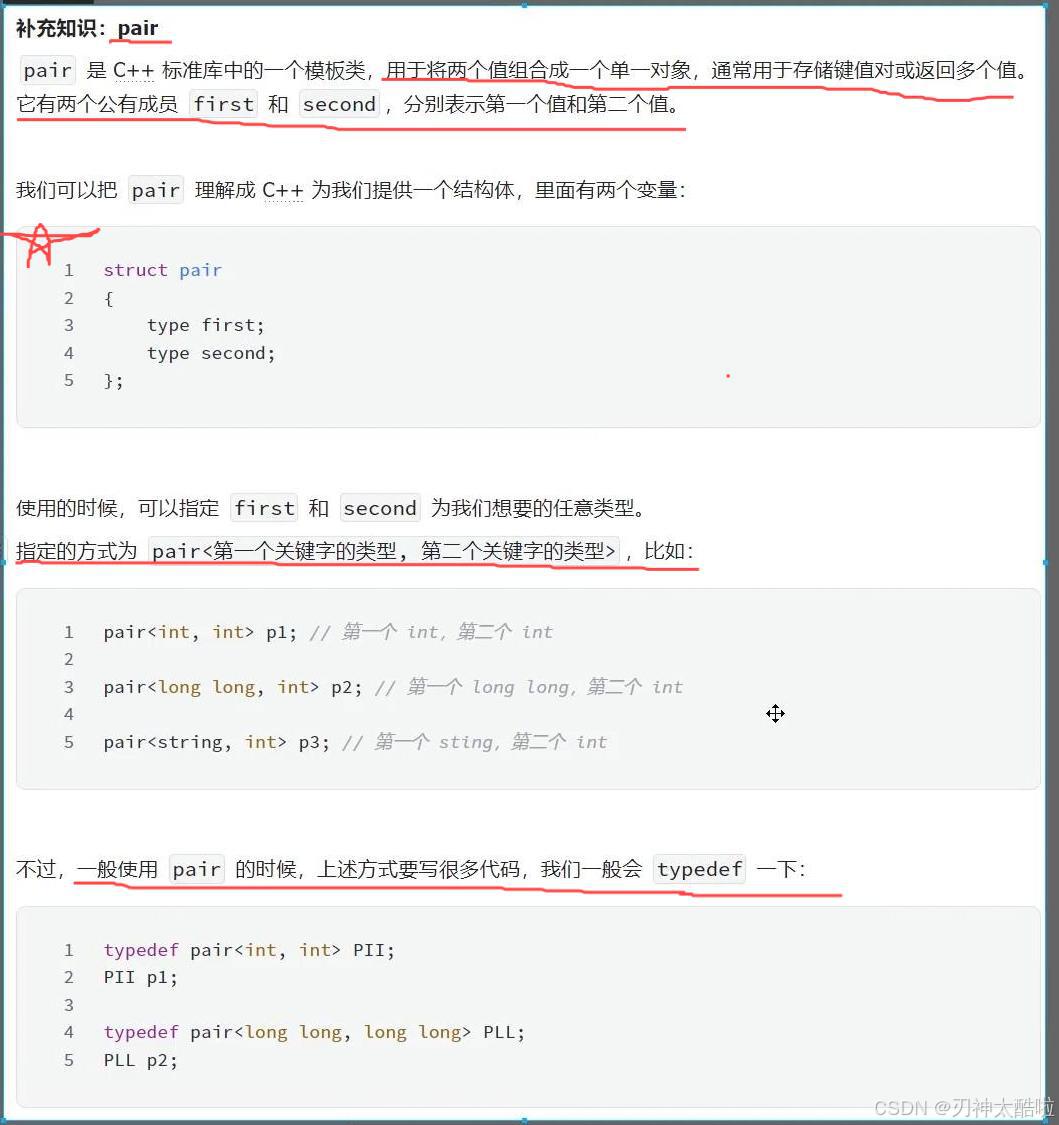
数据结构(蓝桥杯常考点)
数据结构 前言:这个是针对于蓝桥杯竞赛常考的数据结构内容,基础算法比如高精度这些会在下期给大家总结 数据结构 竞赛中,时间复杂度不能超过10的7次方(1秒)到10的8次方(2秒) 空间限制&#x…...

Tomcat+Servlet运行后出现404错误解决方案
TomcatServlet运行后出现404错误解决方案 一、错误效果复现 后续的解决方案,仅仅针对我遇到的情况。对不能涵盖大部分情况感到抱歉。 二、错误分析 先看看源代码? package com.example.secondclass.Servlet; import java.io.*; import jakarta.servl…...
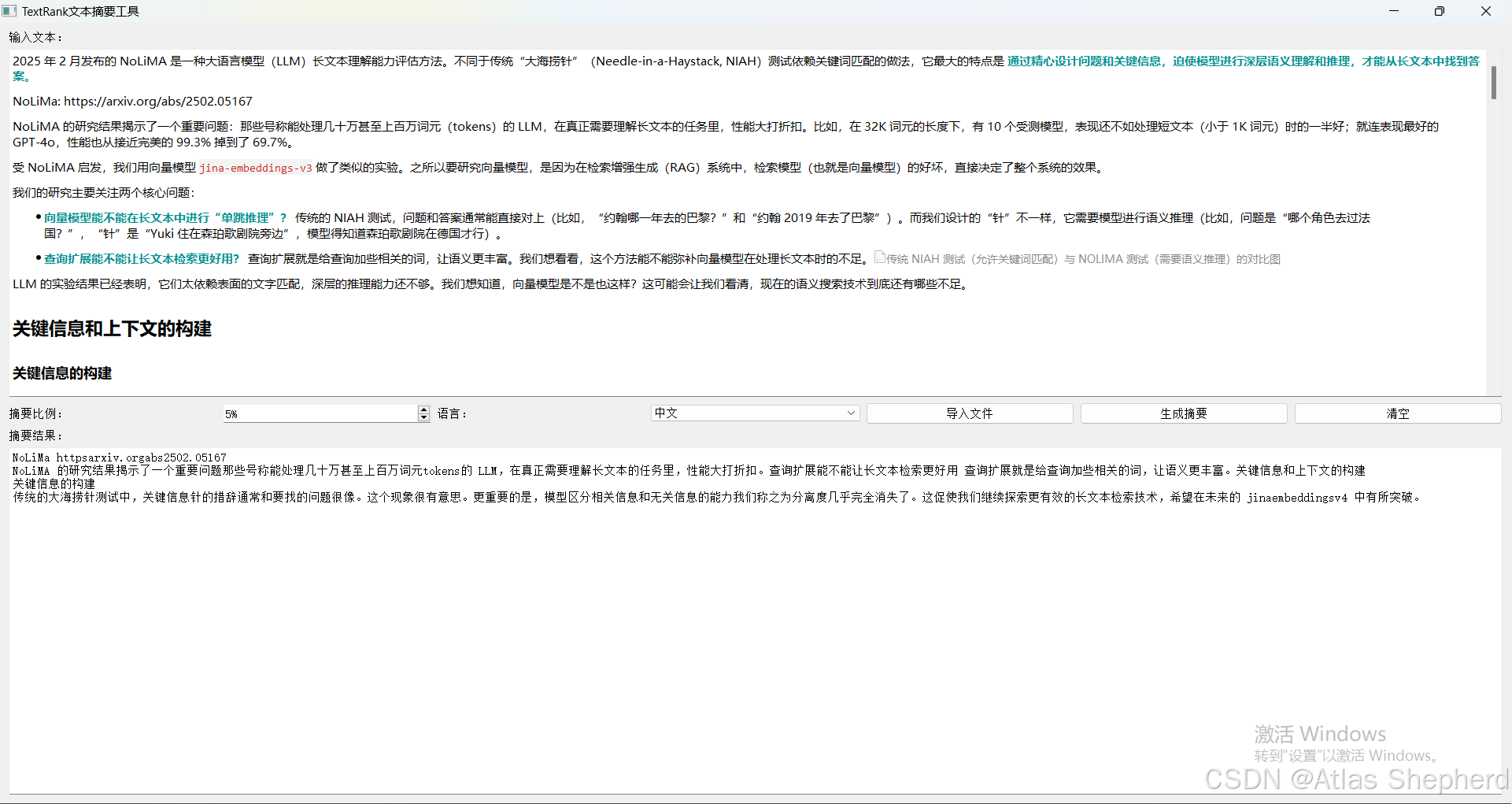
论文摘要生成器:用TextRank算法实现文献关键信息提取
我们基于python代码,使用PyQt5创建图形用户界面(GUI),同时支持中英文两种语言的文本论文文献关键信息提取。 PyQt5:用于创建GUI应用程序。 jieba:中文分词库,用于中文文本的处理。 reÿ…...

Flutter中网络图片加载显示Image.network的具体用法
Image.network的具体用法 Image.network 是 Flutter 中用于从网络加载图片的便捷方法。它基于 NetworkImage,可以快速加载并显示网络图片。以下是 Image.network 的具体用法和常见参数说明。 基本用法 最简单的用法是提供一个图片的 URL: dart 复制 …...
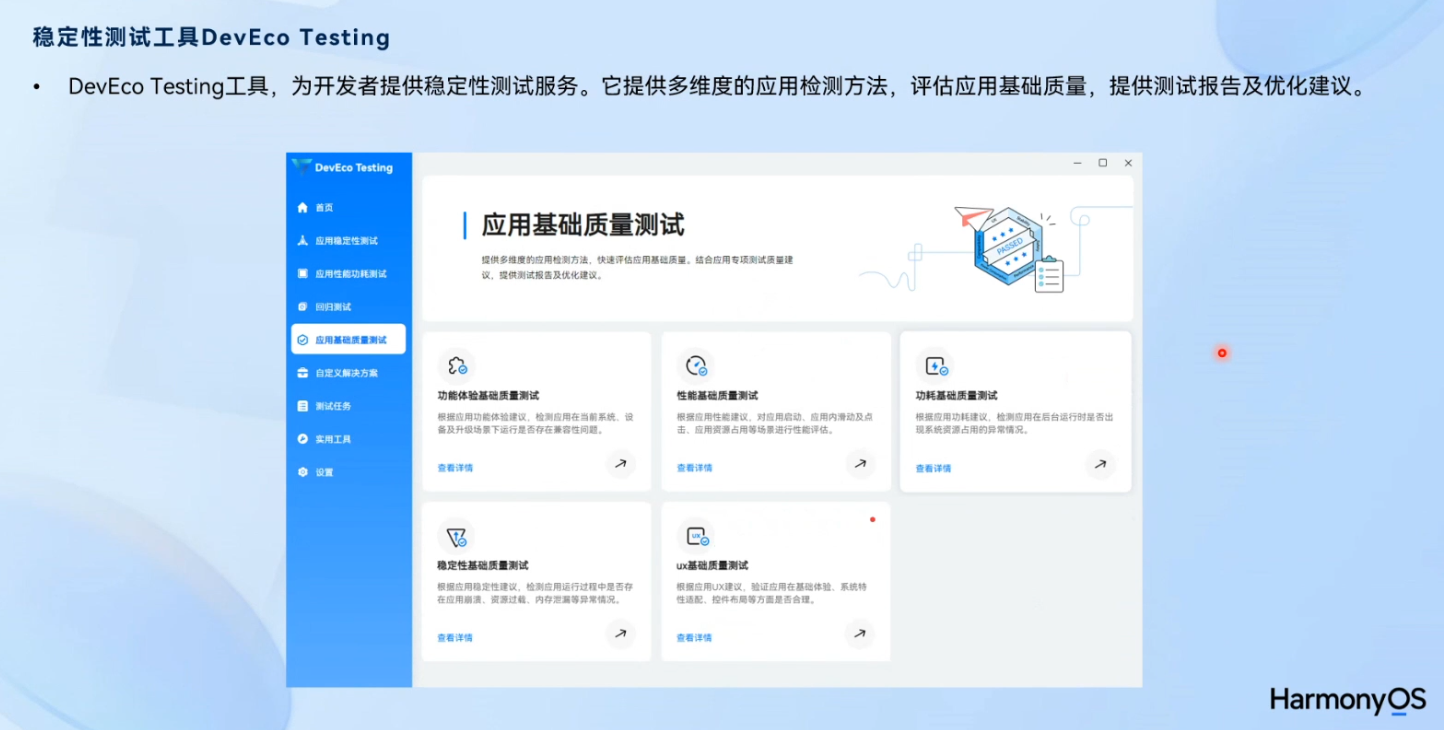
【HarmonyOS Next】鸿蒙应用故障处理思路详解
【HarmonyOS Next】鸿蒙应用崩溃处理思路详解 一、崩溃问题发现后定位 1. 崩溃现象: 常见的崩溃问题表现为,应用操作后白屏闪退,或者应用显示无响应卡死。 2.定位问题: 发现崩溃后,我们首先需要了解复现步骤&#x…...
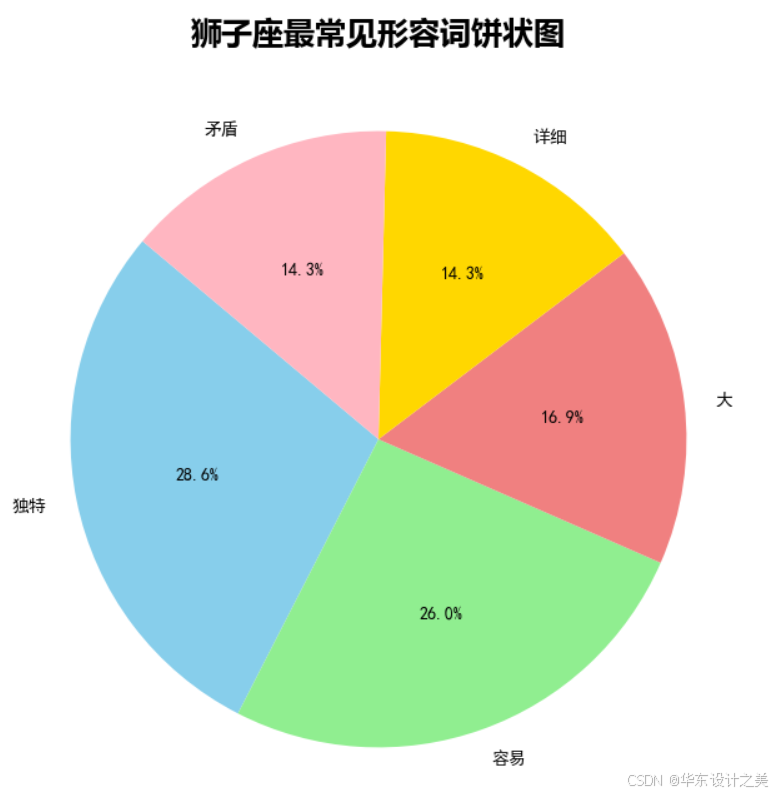
狮子座大数据分析(python爬虫版)
十二星座爱情性格 - 星座屋 首先找到一个星座网站,作为基础内容,来获取信息 网页爬取与信息提取 我们首先利用爬虫技术(如 Python 中的 requests 与 BeautifulSoup 库)获取页面内容。该页面(xzw.com/astro/leo/&…...
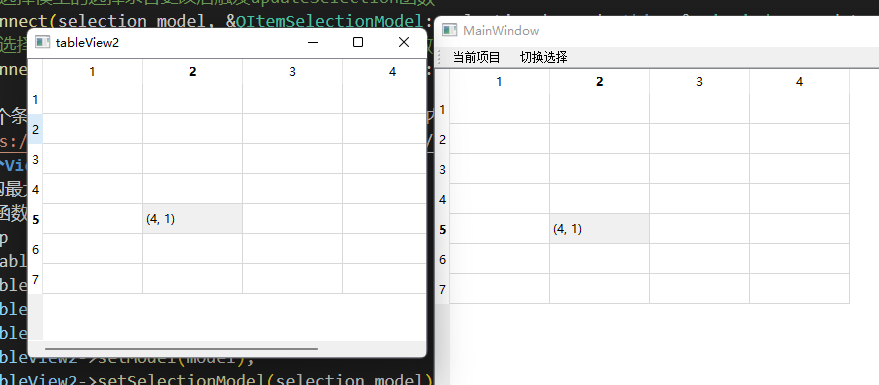
QT系列教程(18) MVC结构之QItemSelectionModel模型介绍
视频教程 https://www.bilibili.com/video/BV1FP4y1z75U/?vd_source8be9e83424c2ed2c9b2a3ed1d01385e9 QItemSelectionModel Qt的MVC结构支持多个View共享同一个model,包括该model的选中状态等。我们可以通过设置QItemSelectionModel,来更改View的选…...

git设置本地仓库和远程仓库
设置本地仓库和远程仓库是使用Git进行版本控制的基本操作。以下是详细步骤: 创建本地仓库 初始化本地仓库: 打开命令行工具(如Terminal或Git Bash)。导航到你希望创建Git仓库的项目文件夹。运行以下命令来初始化一个新的Git仓库&…...

openharmony中HDF驱动框架源码梳理-驱动加载流程
要想大概了解一个公司,我们可能只需要知道它的运行逻辑即可,例如我们只需要知道它有财务有研发有运营等,财务报销、研发负责产品等即可,但是如果想深入具体的了解的话我们就要了解都有什么部门(对象)、各部门都包含哪些职责(对象方…...

golang 高性能的 MySQL 数据导出
需求导出方式对比方案1:快照导出(耗时:1.5s)方案2: 偏移分页(耗时:4s)方案 3:普通分页(耗时:4min40s) 需求 导出 MySQL 数据 分析: 一次性 select 大量数据带来的问题 性能问题: 数据库负载:大量数据查询会增加数据库的CPU、内存和I/O负担ÿ…...

31-判断子序列
给定字符串 s 和 t ,判断 s 是否为 t 的子序列。 字符串的一个子序列是原始字符串删除一些(也可以不删除)字符而不改变剩余字符相对位置形成的新字符串。(例如,"ace"是"abcde"的一个子序列&#x…...
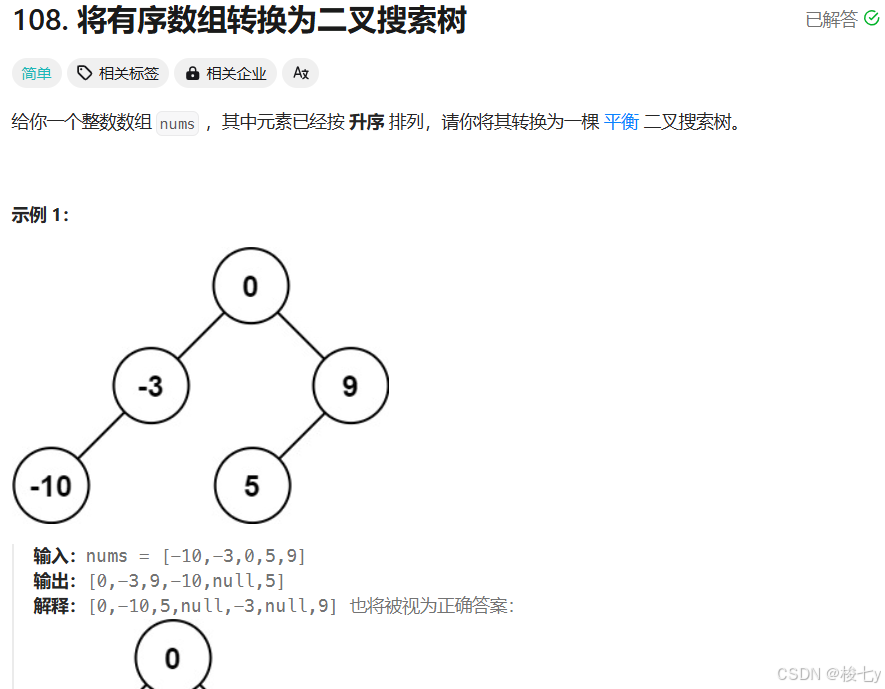
leetcode日记(95)将有序数组转换为二叉搜索树
很简单,感觉自己越来越适应数据结构题目了…… /*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : va…...

使用SSH密钥连接本地git 和 github
目录 配置本地SSH,添加到github首先查看本地是否有SSH密钥生成SSH密钥,和邮箱绑定将 SSH 密钥添加到 ssh-agent:显示本地公钥*把下面这一串生成的公钥存到github上* 验证SSH配置是否成功终端跳转到本地仓库把http协议改为SSH(如果…...

C语言基础之【内存管理】
C语言基础之【内存管理】 存储类型作用域普通局部变量静态局部变量普通全局变量静态全局变量全局函数和静态函数 内存布局内存分区存储类型与内存四区内存操作函数memset()memcpy()memmove()memcmp() 堆区内存分配和释放malloc()free() 内存分区代码分析返回栈区地址返回data区…...

C盘清理技巧分享:释放空间,提升电脑性能
目录 1. 引言 2. C盘空间不足的影响 3. C盘清理的必要性 4. C盘清理的具体技巧 4.1 删除临时文件 4.2 清理系统还原点 4.3 卸载不必要的程序 4.4 清理下载文件夹 4.5 移动大文件到其他盘 4.6 清理系统缓存 4.7 使用磁盘清理工具 4.8 清理Windows更新文件 4.9 禁用…...
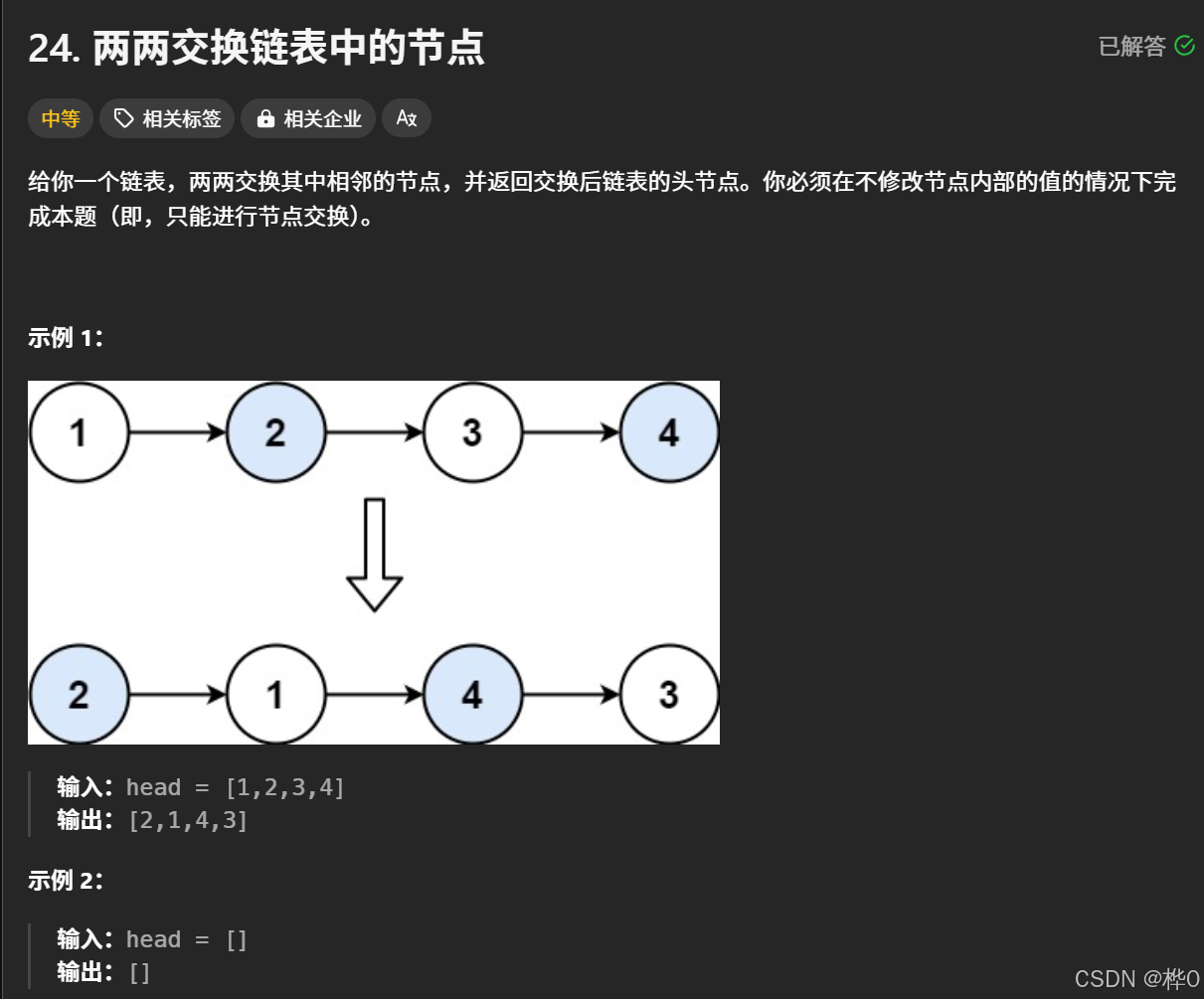
每天一道算法题【蓝桥杯】【两两交换链表中的节点】
思路 本质问题可以分成若干个子问题 即把前两个链表交换,并与后面的链表相连 故实现函数功能调用自身递归即可 #define _CRT_SECURE_NO_WARNINGS 1 struct ListNode {int val;ListNode *next;ListNode() : val(0), next(nullptr) {}ListNode(int x) : val(x), nex…...

mIoU Class与mIoU Category的区别
mIoU(mean Intersection over Union)是语义分割任务中常用的评估指标,用于衡量模型预测的分割结果与真实标签之间的重叠程度。mIoU Class 和 mIoU Category 的区别主要体现在计算方式和应用场景上: 1. mIoU Class 定义ÿ…...

深入解析 C 语言中含数组和指针的构造体与共同体内存计算
在 C 语言中,构造体(struct)和共同体(union)允许我们将多种数据类型组合到一起。除了常见的基本数据类型之外,经常还会在它们中嵌入数组和指针。由于数组的内存是连续分配的,而指针的大小与平台…...

双强联袂,数智共舞 | 中聚信 × 金蝶启联巅峰对话,共探财税未来新航道
3 月 26 日,由金蝶软件(中国)有限公司、贵州启联科技有限公司联合主办,中聚信财税技术研究中心协办的「AI 时代 先进管理用金蝶」主题峰会,在贵阳国际生态会议中心圆满落幕。这场聚焦制造企业数字化转型与 AI 赋能管理…...

LangGraph大模型脚手架实战:揭秘6种爆款智能体设计模式,玩转生产级Agent开发!
最近Herness大火,我就在反思,我们在日常进行智能体开发的过程中,是否也在做类似的事,我们用过claude code sdk、codex sdk、copilot cli等通用agent做封装,也用过dify或者coze搭工作流,也用过langchain做过…...

硬件工程师实战指南:工业物联网安全、无线充电与TSN网络设计解析
1. 项目概述:一场面向硬件工程师的线上技术盛宴最近在整理行业资料时,翻到了EE Times几年前发布的一个“即将到来的线上技术活动”汇总页面。虽然发布时间是2018年,但里面提到的几个技术主题——工业物联网安全、硬件身份认证、工业以太网演进…...
)
告别头像上传模糊!用Cropper.js打造完美头像裁剪上传功能(附完整前后端代码)
从零构建高精度头像裁剪系统:Cropper.js全栈实战指南 每次上传头像时,你是否遇到过这样的尴尬——精心选择的图片上传后变得模糊不清,或者被强制拉伸变形?这种糟糕的用户体验在社交平台、企业系统中尤为常见。本文将带你从零构建…...

3步解锁网易云音乐NCM文件:ncmdump让你的音乐自由播放
3步解锁网易云音乐NCM文件:ncmdump让你的音乐自由播放 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 还在为网易云音乐下载的加密NCM文件无法在其他设备播放而烦恼吗?ncmdump作为一款专业的网易云音乐NCM文件…...

BurstGPT:大语言模型驱动高性能计算,实现自然语言科学仿真
1. 项目概述:当大语言模型遇上高性能计算最近在AI和HPC(高性能计算)的交叉领域,一个名为BurstGPT的项目引起了我的注意。乍一看这个标题,你可能会觉得有点“缝合怪”的味道——Burst通常指代计算资源的突发式使用或高性…...

Windows 11终极优化指南:一键清理系统臃肿,免费提升51%性能
Windows 11终极优化指南:一键清理系统臃肿,免费提升51%性能 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to …...

Python3.8环境下的OpenOPC实战:从模拟服务器搭建到KEPServerEX数据读写一条龙
Python3.8环境下的OpenOPC实战:从模拟服务器搭建到KEPServerEX数据读写全流程指南 工业自动化领域的数据采集一直是开发者需要掌握的核心技能之一。对于没有硬件设备或OPC服务器许可的学习者来说,如何在本地搭建完整的测试环境成为入门的第一道门槛。本文…...
)
STM32+RS485实战:用Modbus RTU协议读取液压传感器数据(附自动收发电路避坑)
STM32与RS485实战:从电路设计到Modbus RTU协议解析 液压传感器数据采集在工业自动化领域有着广泛应用,而RS485总线因其抗干扰能力强、传输距离远等优势成为首选通信方式。本文将深入探讨如何基于STM32微控制器搭建RS485硬件电路,并通过Modbus…...

从 AI 电影到小说:《凰标》延续《第一大道》的东方梦@凤凰标志
科技为翼,文脉为魂; 大道开路,凰标定局。一、时代之问:当AI沦为流量收割机,谁来守护东方文脉? AI 正以惊人的速度渗透文娱产业,却多数被资本用作「快餐内容」的流水线。 海棠山铁哥反其道而行—…...