文本聚类与摘要,让AI帮你做个总结
你好,我是徐文浩。
上一讲里,我们用上了最新的ChatGPT的API,注册好了HuggingFace的账号,也把我们的聊天机器人部署了出去。希望通过这个过程,你对实际的应用开发过程已经有了充足的体验。那么这一讲里,我们会回到OpenAI的各个接口能够提供的能力。我们分别看看怎么通过Embedding进行文本聚类,怎么利用提示语(Prompt)做文本的总结。
基于Embedding向量进行文本聚类
我先给不太了解技术的同学简单科普一下什么叫做文本聚类,文本聚类就是把很多没有标注过的文本,根据它们之间的相似度,自动地分成几类。基于GPT系列的模型进行文本聚类很简单,因为我们可以通过Embedding把文本变成一段向量。而对于向量我们自然可以用一些简单的聚类算法,比如我们采用最简单的K-Means算法就可以了。
这一次,我们选用的数据集,是很多老的机器学习教程里常用的20 newsgroups数据集,也就是一个带了标注分好类的英文新闻组的数据集。这个数据集,其实不是最自然的自然语言,里面的数据是经过了预处理的,比如去除了标点符号、停用词等等。我们正好可以拿来看看,面对这样其实不太“自然语言”的数据,OpenAI的GPT系列模型处理的效果怎么样。
首先,我们先通过scikit-learn这个Python库来拿到数据,数据集就内置在这个库里面。scikit-learn也是非常常用的一个机器学习库,我们直接把数据下载下来,存储成CSV文件。对应的代码在下面可以看到。
from sklearn.datasets import fetch_20newsgroups
import pandas as pddef twenty_newsgroup_to_csv():newsgroups_train = fetch_20newsgroups(subset='train', remove=('headers', 'footers', 'quotes'))df = pd.DataFrame([newsgroups_train.data, newsgroups_train.target.tolist()]).Tdf.columns = ['text', 'target']targets = pd.DataFrame( newsgroups_train.target_names, columns=['title'])out = pd.merge(df, targets, left_on='target', right_index=True)out.to_csv('20_newsgroup.csv', index=False)twenty_newsgroup_to_csv()接着,我们要对数据做预处理,我们需要过滤掉数据里面有些文本是空的情况。以及和我们前面进行文本分类一样,把Token数量太多的给过滤掉。
from openai.embeddings_utils import get_embeddings
import openai, os, tiktoken, backoffopenai.api_key = os.environ.get("OPENAI_API_KEY")
embedding_model = "text-embedding-ada-002"
embedding_encoding = "cl100k_base" # this the encoding for text-embedding-ada-002
batch_size = 2000
max_tokens = 8000 # the maximum for text-embedding-ada-002 is 8191df = pd.read_csv('20_newsgroup.csv')
print("Number of rows before null filtering:", len(df))
df = df[df['text'].isnull() == False]
encoding = tiktoken.get_encoding(embedding_encoding)df["n_tokens"] = df.text.apply(lambda x: len(encoding.encode(x)))
print("Number of rows before token number filtering:", len(df))
df = df[df.n_tokens <= max_tokens]
print("Number of rows data used:", len(df))输出结果:
Number of rows before null filtering: 11314
Number of rows before token number filtering: 11096
Number of rows data used: 11044然后,我们仍然是通过Embedding的接口,拿到文本的Embedding向量,然后把整个数据存储成parquet文件。
@backoff.on_exception(backoff.expo, openai.error.RateLimitError)
def get_embeddings_with_backoff(prompts, engine):embeddings = []for i in range(0, len(prompts), batch_size):batch = prompts[i:i+batch_size]embeddings += get_embeddings(list_of_text=batch, engine=engine)return embeddingsprompts = df.text.tolist()
prompt_batches = [prompts[i:i+batch_size] for i in range(0, len(prompts), batch_size)]embeddings = []
for batch in prompt_batches:batch_embeddings = get_embeddings_with_backoff(prompts=batch, engine=embedding_model)embeddings += batch_embeddingsdf["embedding"] = embeddings
df.to_parquet("data/20_newsgroup_with_embedding.parquet", index=False)这一部分代码基本和前面我们做文本分类一样,我就不再做详细讲解了。不理解代码为什么要这么写的同学,可以去看前面的第 05 讲。
通常,在使用Jupyter Notebook或者Python去做机器学习类的任务的时候,我们往往会把一些中间步骤的数据结果给存下来。这样,我们可以避免在后面步骤写了Bug或者参数设错的时候从头开始。在这里,我们就把原始数据,以及Embedding处理完的数据都存了一份。这样,如果后面的聚类程序要做修改,我们不需要再花钱让OpenAI给我们算一次Embedding了。
接着,我们就可以用K-Means算法来进行聚类了。因为原本的数据来自20个不同的新闻组,那么我们也不妨就聚合成20个类,正好我们看看自动聚类出来的分类会不会就和原始分类差不多。
import numpy as np
from sklearn.cluster import KMeansembedding_df = pd.read_parquet("data/20_newsgroup_with_embedding.parquet")matrix = np.vstack(embedding_df.embedding.values)
num_of_clusters = 20kmeans = KMeans(n_clusters=num_of_clusters, init="k-means++", n_init=10, random_state=42)
kmeans.fit(matrix)
labels = kmeans.labels_
embedding_df["cluster"] = labels聚类的代码非常简单,我们通过NumPy的stack函数,把所有的Embedding放到一个矩阵里面,设置一下要聚合出来的类的数量,然后运行一下K-Means算法的fit函数,就好了。不过,聚类完,我们怎么去看它聚类的结果是不是合适呢?每个聚合出来的类代表什么呢?
在这里,我们的数据之前就有分组。那么我们就可以用一个取巧的思路。我们统计一下聚类之后的每个类有多少条各个newsgroups分组的数据。然后看看这些数据里面,排名第一的分组是什么。如果我们聚类聚合出来的类,都是从某一个newsgroup分组出来的文章,那么说明这个聚合出来的类其实就和那个分组的内容差不多。使用这个思路的代码,我也放在下面了,我们一起来看一看。
# 统计每个cluster的数量
new_df = embedding_df.groupby('cluster')['cluster'].count().reset_index(name='count')# 统计这个cluster里最多的分类的数量
title_count = embedding_df.groupby(['cluster', 'title']).size().reset_index(name='title_count')
first_titles = title_count.groupby('cluster').apply(lambda x: x.nlargest(1, columns=['title_count']))
first_titles = first_titles.reset_index(drop=True)
new_df = pd.merge(new_df, first_titles[['cluster', 'title', 'title_count']], on='cluster', how='left')
new_df = new_df.rename(columns={'title': 'rank1', 'title_count': 'rank1_count'})# 统计这个cluster里第二多的分类的数量
second_titles = title_count[~title_count['title'].isin(first_titles['title'])]
second_titles = second_titles.groupby('cluster').apply(lambda x: x.nlargest(1, columns=['title_count']))
second_titles = second_titles.reset_index(drop=True)
new_df = pd.merge(new_df, second_titles[['cluster', 'title', 'title_count']], on='cluster', how='left')
new_df = new_df.rename(columns={'title': 'rank2', 'title_count': 'rank2_count'})
new_df['first_percentage'] = (new_df['rank1_count'] / new_df['count']).map(lambda x: '{:.2%}'.format(x))
# 将缺失值替换为 0
new_df.fillna(0, inplace=True)
# 输出结果
display(new_df)这个代码也不难写,我们可以分成几步来做。
- 我们通过groupby可以把之前的DataFrame按照cluster进行聚合,统计每个cluster里面数据的条数。
- 而要统计某一个cluster里面排名第一的分组名称和数量的时候,我们可以通过groupby,把数据按照 cluster + title 的方式聚合。
- 再通过 cluster 聚合后,使用 x.nlargest 函数拿到里面数量排名第一的分组的名字和数量。
- 为了方便分析,我还把数据里排名第一的去掉之后,又统计了一下排名第二的分组,放在一起看一下。
输出结果:
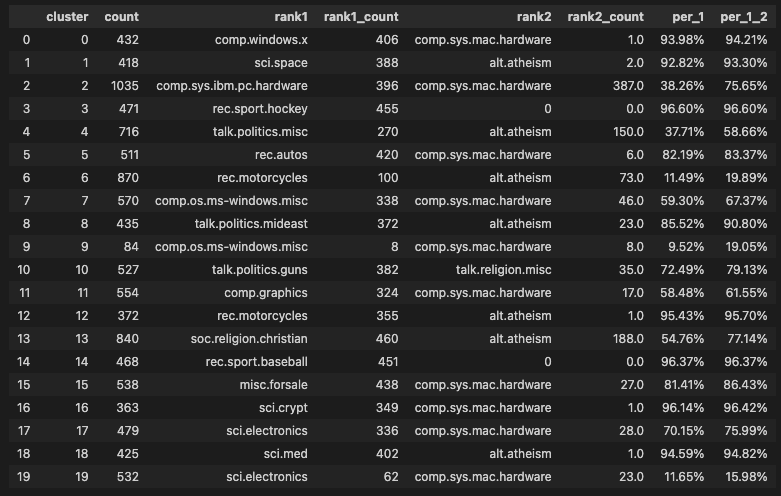
从这个统计数据的结果来看,大部分聚类的结果,能够对应到某一个原本新闻组的分类。比如,cluster 0就有93.98%来自 comp.windows.x 这个分类。在20个聚合出来的类里面,有10个类80%来自原本newsgroup的某一个分类。剩下的分类中,比如cluster 2,前两个分组加在一起占了75%,这两个分组的名称分别是 pc.hardware 和 mac.hardware 其实都是聊电脑硬件的,不过是newsgroups里按照硬件不同做了区分而已。我们只有3个类,对应的分组比较分散,分别是cluster 6、9和19。
从这个结果来看,我们直接使用文本的Embedding来进行聚类,效果还算不错。
使用提示语对文本进行总结
不过啊,在真实的应用场景里,我们拿来进行文本聚类的数据,多半并没有什么分组信息。过去,我们要去给聚合出来的类取一个名字,往往只能选择看看各个类里面的文本是什么内容。靠我们的“人脑”给“电脑”做出的选择起一个我们觉得合适的名字。比如,对应到这里的20个分类的数据,往往我们只能每个挑上几篇内容,人工读一遍,再取一个名字。而如果你英文不太好,那可就太痛苦了。
不过,既然有了OpenAI的Completion接口,我们完全可以让AI给我们聚合出来的类起一个名字。我们可以随机在每个聚合出来的类里面,挑上3~5条,然后请AI总结一下该取什么名字,然后再挑一两条文本让AI给我们翻译成中文,看看名字取的是不是合理。
items_per_cluster = 10
COMPLETIONS_MODEL = "text-davinci-003"for i in range(num_of_clusters):cluster_name = new_df[new_df.cluster == i].iloc[0].rank1print(f"Cluster {i}, Rank 1: {cluster_name}, Theme:", end=" ")content = "\n".join(embedding_df[embedding_df.cluster == i].text.sample(items_per_cluster, random_state=42).values)response = openai.Completion.create(model=COMPLETIONS_MODEL,prompt=f'''我们想要给下面的内容,分组成有意义的类别,以便我们可以对其进行总结。请根据下面这些内容的共同点,总结一个50个字以内的新闻组的名称。比如 “PC硬件”\n\n内容:\n"""\n{content}\n"""新闻组名称:''',temperature=0,max_tokens=100,top_p=1,)print(response["choices"][0]["text"].replace("\n", ""))我们可以用这样一段代码通过Completion接口来实现我们的需求。
- 我们随机从聚类结果里的每一个类里面,都挑上10条记录,然后分行将这些记录拼在一起。
- 然后,我们给AI这样一段提示语,告诉AI这些内容来自新闻组,请AI根据它们的共性给这些新闻组的内容取一个50个字以内的名字。
- 输出的内容,我们用Cluster,Cluster里原先排名第一的分组英文,以及AI给出的新闻组名称,对应的输出结果在下面。
输出结果:
Cluster 0, Rank 1: comp.windows.x, Theme: Xlib编程
Cluster 1, Rank 1: sci.space, Theme: 太空技术与航空
Cluster 2, Rank 1: comp.sys.ibm.pc.hardware, Theme: PC硬件与系统
Cluster 3, Rank 1: rec.sport.hockey, Theme: 欧洲冰球vs北美冰球
Cluster 4, Rank 1: talk.politics.misc, Theme: 社会观点与自由
Cluster 5, Rank 1: rec.autos, Theme: 汽车硬件
Cluster 6, Rank 1: rec.motorcycles, Theme: 数学与文化冲击
Cluster 7, Rank 1: comp.os.ms-windows.misc, Theme: PC软件与硬件
Cluster 8, Rank 1: talk.politics.mideast, Theme: “穆斯林大屠杀”
Cluster 9, Rank 1: comp.os.ms-windows.misc, Theme: 科技产品"""
Cluster 10, Rank 1: talk.politics.guns, Theme: 枪支管制与安全
Cluster 11, Rank 1: comp.graphics, Theme: 计算机编程与硬件
Cluster 12, Rank 1: rec.motorcycles, Theme: 骑行安全与技巧
Cluster 13, Rank 1: soc.religion.christian, Theme: 宗教信仰与实践
Cluster 14, Rank 1: rec.sport.baseball, Theme: 棒球联盟
Cluster 15, Rank 1: misc.forsale, Theme: 购物优惠和出售
Cluster 16, Rank 1: sci.crypt, Theme: 关于加密政策的讨论
Cluster 17, Rank 1: sci.electronics, Theme: 电子设备技术
Cluster 18, Rank 1: sci.med, Theme: 药物和疾病
Cluster 19, Rank 1: sci.electronics, Theme: 电子邮件使用者研究可以看到,机器给出的中文分类名称,大部分是合理的。我们还可以挑一些里面的文本内容,看看它们的中文翻译是不是和上面取的名字是一致的。翻译的代码和上面类似,少数的几个差别是:
- 我们在每个分类的抽样数据里只找了1条,而不是总结时候选的10条。
- 我们限制了这段文本的Token数量不超过100个,免得太占地方。
- 输出的内容我们放大了字数到500字,确保翻译能提供足够的内容。
items_per_cluster = 1
COMPLETIONS_MODEL = "text-davinci-003"for i in range(num_of_clusters):cluster_name = new_df[new_df.cluster == i].iloc[0].rank1print(f"Cluster {i}, Rank 1: {cluster_name}, 抽样翻译:", end=" ")content = "\n".join(embedding_df[(embedding_df.cluster == i) & (embedding_df.n_tokens > 100)].text.sample(items_per_cluster, random_state=42).values)response = openai.Completion.create(model=COMPLETIONS_MODEL,prompt=f'''请把下面的内容翻译成中文\n\n内容:\n"""\n{content}\n"""翻译:''',temperature=0,max_tokens=2000,top_p=1,)print(response["choices"][0]["text"].replace("\n", ""))输出结果:
Cluster 0, Rank 1: comp.windows.x, 抽样翻译: 没有实际执行它?不知怎么回事,我的一个xterminal用户使得只要点击鼠标右键,就会自动杀死所有客户端-哦,我的:-(谢谢,Fish
Cluster 1, Rank 1: sci.space, 抽样翻译: 韦恩·马森和他的团伙在阿拉巴马州发生了什么?我还听说有一个未经证实的谣言,即航空大使们已经消失了。有其他人可以证实吗?
Cluster 2, Rank 1: comp.sys.ibm.pc.hardware, 抽样翻译: 我怀疑这不是一个特定于Quadra的问题。去年我不得不放弃我“古老”的Bernoulli 20(每个磁带的价格大约是90美元,使整个事情的价值超过我的整个电脑;)。Ocean Microsystems的技术支持人员建议可以使用一些第三方驱动程序来解决这个问题 - 在我的情况下,磁带无法格式化/挂载/分区用于A / UX。
Cluster 3, Rank 1: rec.sport.hockey, 抽样翻译: 我相信那是4-1。罗德·布林道·阿莫尔在第三节19.59时分攻入一球。
Cluster 4, Rank 1: talk.politics.misc, 抽样翻译: 为了确保每个人都清楚:“它从未有过”是指“保护”,而不是“未能保护”;即,在我的一生中,我从未见过美国政府始终保护美国公民的利益,除非是意外。
Cluster 5, Rank 1: rec.autos, 抽样翻译: 噢,来吧,傻瓜,你要做的就是在你的引擎罩上割一个洞,然后把一个管子放进去,这样你就可以把机油倒进去了。你觉得那些热门车上的大空气进气装置是干什么的?它们只是为了外观,没有人知道,它们提供了进入机油填充孔的途径。
Cluster 6, Rank 1: rec.motorcycles, 抽样翻译: 你真是个失败者
Cluster 7, Rank 1: comp.os.ms-windows.misc, 抽样翻译: 偶尔你需要为表现良好的东西说句好话。我的东西桥3401没有任何问题。它在DOS和OS/2上运行得很好。对于OS/2,你不需要加载任何特殊的驱动程序。安装会检测到它是一个东西桥驱动器,然后就完成了。顺便说一句,它也很快!
Cluster 8, Rank 1: talk.politics.mideast, 抽样翻译: Avi, 供你参考,伊斯兰教允许宗教自由——在宗教上没有强制。犹太教是否也允许宗教自由(即是否认可非犹太人)?只是好奇而已。
Cluster 9, Rank 1: comp.os.ms-windows.misc, 抽样翻译: 每个人都有自己的梦想,但只有勇敢追求梦想的人才能实现它。
Cluster 10, Rank 1: talk.politics.guns, 抽样翻译: 不一定,特别是如果强奸犯被认定为此。例如,如果你有意地把手指伸进一个装满了老鼠夹的地方,然后被夹住,这是谁的错?
Cluster 11, Rank 1: comp.graphics, 抽样翻译: 帮帮我!!我需要代码/包/任何东西来处理3D数据,并将其转换为带有隐藏线的线框表面。我正在使用DOS机器,代码可以是ANSI C或C ++,ANSI Fortran或Basic。我使用的数据形成一个矩形网格。请将您的回复发布到网络上,以便其他人受益。我的个人观点是,这是一个普遍的兴趣问题。谢谢!!!!!
Cluster 12, Rank 1: rec.motorcycles, 抽样翻译: 这是一段心理学,对于任何长期骑行者来说都是必不可少的。人们不会去想“如果我这么做会有其他人受到影响吗?”他们只会评估“如果我这么做会受到影响吗?”
Cluster 13, Rank 1: soc.religion.christian, 抽样翻译: 这是一个非常薄弱的论点,因为没有独立的支持文本(关于关键事件)。至于新约最古老的现存文本的日期......如果现在只有一个关于美国内战的现存文本,你会怎么想?现在考虑一个大部分文盲的人口,每一份手稿都是手工复制的......--Hal
Cluster 14, Rank 1: rec.sport.baseball, 抽样翻译: 这个赔率意味着你下注5美元赌反败者赢8美元,或者下注9美元赌胜者赢5美元。
Cluster 15, Rank 1: misc.forsale, 抽样翻译: 嗯,标题就是这样......我正在寻找便宜的二手TG-16游戏,它们支持2个或更多玩家(同时)....请给我发送所有带有价格的报价。
Cluster 16, Rank 1: sci.crypt, 抽样翻译: 哪里?老实说,我没有看到任何……我不同意,至少有其他标准已经存在。此外,即使他们限制NREN上的加密,谁在乎呢?大部分互联网都是商业的。NREN只适用于政府和大学研究(阅读提案-它是一条“数据高速公路”,与互联网无关)。
Cluster 17, Rank 1: sci.electronics, 抽样翻译: 动态RAM不是基于翻转锁存器;基本上每个位只有一个晶体管和电容来存储!静态RAM是基于翻转锁存器,更加昂贵,密度也更低。如果忽略电子和热膨胀,两者都没有任何“移动”的部件...Chris
Cluster 18, Rank 1: sci.med, 抽样翻译: 化学品已经消失,感谢所有的回应。
Cluster 19, Rank 1: sci.electronics, 抽样翻译: 尝试lyman.pppl.gov--/pub/8051从输出的结果来看,我们选取的内容和AI总结的标题的确八九不离十。不知道这个过程,有没有重新让你回忆起Completion这个接口的强大之处。我们只要给出合适的指令,它就能按照我们的心意给出合理的结果。
利用文本摘要支持无限轮数的聊天
不知道你是否还记得上一讲里的思考题,如果不只是保留过去几轮对话,我们怎么在对话轮数越来越多的时候让AI记住尽量多的上下文?有一个办法,就是将过去几轮的上下文内容,先交给AI做一个100字的总结。然后,把这个总结也作为对话的Prompt信息,告诉AI这是聊天的背景,再重新开始新的一轮对话。
在这里我们不妨试一下。
- 我们拿上一讲的一段聊天记录,让AI先总结一下,可以看到AI总结了User和Assistant之间聊了什么。
history = """User : 你是谁?
Assistant : 我是一个人工智能语言模型,可以回答各种问题,包括做菜的问题。User : 请问鱼香肉丝怎么做?
Assistant : 鱼香肉丝的做法:1. 猪里脊肉切丝,加入盐、淀粉、料酒搅拌均匀,腌制10分钟
2. 胡萝卜、青椒、木耳切丝备用
3. 热锅凉油,放入蒜末、姜末煸炒出香味,加入肉丝翻炒至变色
4. 加入胡萝卜、青椒、木耳翻炒,加入酱油、糖、醋、盐、味精、水淀粉搅拌均匀,倒入锅中翻炒均匀即可。提示:鱼香肉丝的关键是调料的配比,酱油、糖、醋、盐、味精的比例要适合自己的口味。User : 那蚝油牛肉呢?
Assistant : 蚝油牛肉的做法:1. 将牛肉切成薄片,加入盐、淀粉、料酒腌制10分钟
2. 葱姜切末,蒜切片,青红椒切丝备用
3. 热锅凉油,放入葱姜末、蒜片煸炒出香味,加入牛肉翻炒至变色
4. 加入蚝油、酱油、糖、水淀粉调味,加入青红椒翻炒均匀即可。提示:蚝油牛肉的关键是牛肉要切薄,翻炒时火候要快,保证牛肉口感鲜嫩。调味时,蚝油和酱油的比例也要适合自己的口味。
"""def summarize(text, max_tokens=200):response = openai.Completion.create(model=COMPLETIONS_MODEL,prompt=text + "\n\n请总结一下上面User和Assistant聊了些什么:\n",max_tokens=max_tokens,)return response["choices"][0]["text"]summarized = summarize(history)
print(summarized)输出结果:
User和Assistant聊了鱼香肉丝和蚝油牛肉的制作方法。User问了Assistant两个关于如何做鱼香肉丝和蚝油牛肉的问题,Assistant给出了回答并介绍了每道菜的具体制作方法,同时也提示了调料的配比和牛肉制作时要注意的细节。- 然后,我们再新建一个Conversation,这次的提示语里,我们先加上了总结的内容,然后告诉AI把对话继续下去。
prompt = summarized + "\n\n请你根据已经聊了的内容,继续对话:" conversation = Conversation(prompt, 5)
question = "那宫保鸡丁呢?" answer = conversation.ask(question) print("User : %s" % question) print("Assistant : %s\n" % answer)
注意,如果你是在Notebook里面执行的话,你需要把上一讲的Conversation类的代码复制过来先执行一下。这里,我们启动了一个新的对话对象,将之前的几轮对话的内容总结了一下,放在Prompt的最前面,然后让AI根据已经聊了的内容,继续往下聊。3. 当我们直接问,“那宫保鸡丁呢?”,AI会正确回答出宫保鸡丁的做法。
输出结果:```python
User : 那宫保鸡丁呢?
Assistant : 宫保鸡丁的制作方法也比较简单。首先,将鸡肉切成小丁状,用料酒、盐、生抽腌制一下。然后将青椒、红椒、葱姜蒜切成丁状备用。接着,将花生米炒香备用。
热锅凉油,油温七成热时放入鸡丁煸炒至变色,捞出备用。再将葱姜蒜爆香,加入青红椒丁翻炒一下,然后加入鸡丁,翻炒均匀。最后加入适量的糖、盐、醋、生抽、老抽、料酒、水淀粉炒匀,最后加入炒香的花生米即可。
需要注意的是,炒鸡丁的时候要用大火,这样鸡肉会更嫩。另外,调料的配比也很关键,需要根据个人口味适量调整。而如果我们没有加上AI总结的之前的对话,只是让AI对话,它只能和你闲扯一些别的。
conversation = Conversation("请你根据已经聊了的内容,继续对话:", 5)question = "那宫保鸡丁呢?"
answer = conversation.ask(question)
print("User : %s" % question)
print("Assistant : %s\n" % answer)输出结果:
User : 那宫保鸡丁呢?
Assistant : 宫保鸡丁是一道非常有名的川菜,口感麻辣鲜香,非常美味。你喜欢吃辣的食物吗?如果没有给它已经总结了的内容,AI只会和你瞎扯,告诉你宫保鸡丁很好吃。
小结
不知道今天教的这些技巧你学会了吗?这一讲里,我们先是快速实验了一下通过Embedding拿到的向量进行文本聚类。对于聚类的结果,我们不用再像以前那样人工看成百上千条数据,然后拍个脑袋给这个类取个名字。我们直接利用了Completion接口可以帮我们总结内容的能力,给分类取了一个名字。从最终的效果来看,还算不错。
而类似的技巧,也可以用在多轮的长对话中。我们将历史对话,让AI总结成一小段文本放到提示语里面。这样既能够让AI记住过去的对话内容,又不会因为对话越来越长而超出模型可以支持的Token数量。这个技巧也是使用大语言模型的一种常见模式。
课后练习
- 这一讲里,我们使用了让AI概括聚类文本内容和聊天记录的提示语。你自己在体验GPT系列模型的时候,有什么觉得特别有用的提示语吗?欢迎你分享自己的体验。
- 在文本聚类里面,有三个聚合出来的类,和原先的分组没有很明显的对应关系。你能利用现在学到的知识,写一些代码看看数据,研究一下是为什么吗?
文章来源:极客时间《AI 大模型之美》
相关文章:
文本聚类与摘要,让AI帮你做个总结
你好,我是徐文浩。 上一讲里,我们用上了最新的ChatGPT的API,注册好了HuggingFace的账号,也把我们的聊天机器人部署了出去。希望通过这个过程,你对实际的应用开发过程已经有了充足的体验。那么这一讲里,我们…...
leaflet实现波动的marker效果(131)
第131个 点击查看专栏目录 本示例的目的是介绍如何在vue+leaflet中显示波动的marker效果。 直接复制下面的 vue+leaflet源代码,操作2分钟即可运行实现效果. 文章目录 示例效果配置方式示例源代码(共76行)安装插件相关API参考:专栏目标示例效果 配置方式 1)查看基础设置…...

关于Dataset和DataLoader的概念
关于Dataset和DataLoader的概念 在机器学习中,Dataset和DataLoader是两个很重要的概念,它们通常用于训练和测试模型时的数据处理。 Dataset是指用于存储和管理数据的类。在深度学习中,通常将数据存储在Dataset中,并使用Dataset提…...

前端与JS变量
前端开发是当今互联网发展的重要组成部分,而JavaScript变量则是前端开发中不可或缺的一部分。在前端开发中,变量的作用不仅仅是存储数据,还可以用来控制程序流程、实现动态效果等。因此,学习前端与JavaScript变量是非常必要的。 …...
初始SpringBoot
初始SpringBoot1. SpringBoot创建和运行1.1. SpringBoot的概念1.2. SpringBoot的优点1.3. SpringBoot的创建1.3.0. 前置工作:安装插件(这是社区版需要做的工作, 专业版可以忽略)1.3.1. 社区版创建方式1.3.2. 专业版创建方式1.3.3. 网页版创建方式1.4. 项目目录介绍1.5. SpringB…...
vue+springboot 上传文件、图片、视频,回显到前端。
效果图 预览: 视频: 设计逻辑 数据库表 前端vue html <div class"right-pannel"><div class"data-box"><!--上传的作业--><div style"display: block" id""><div class"tit…...
)
java入门-W3(K81-K143)
一. 什么是对象 什么是对象?之前我们讲过,对象就是计算机中的虚拟物体。例如 System.out,System.in 等等。然而,要开发自己的应用程序,只有这些现成的对象还远远不够。需要我们自己来创建新的对象。 例如,…...

English Learning - L2 语音作业打卡 复习元音 [ɜː] [æ] 辅元连读技巧 Day42 2023.4.3 周一
English Learning - L2 语音作业打卡 复习元音 [ɜː] [] 辅元连读技巧 Day42 2023.4.3 周一💌发音小贴士:💌当日目标音发音规则/技巧:中元音 [ɜː]前元音 []辅元连读技巧🍭 Part 1【热身练习】🍭 Part2【练习内容】&…...

Thinkphp 6.0图像处理功能
本节课我们来学习一下图像处理功能,这功能是外置的,并非系统内置。 一.图像处理功能 1. 图像处理功能不是系统内置的功能了,需要通过 composer 引入进来; composer require topthink/think-image 2. 引入进来之后&…...

表格软件界的卷王,Excel、access、foxpro全靠边,WPS:真荣幸
Excel和Access就是表格软件的选择? 现在,铺天盖地的Excel的技能教程可谓是满天飞,有网上的教程,也有视频直播课程。 很多办公人员用Excel这种表格软件与VBA结合,甚至用不遗余力去学习Python编程语法,但Exce…...
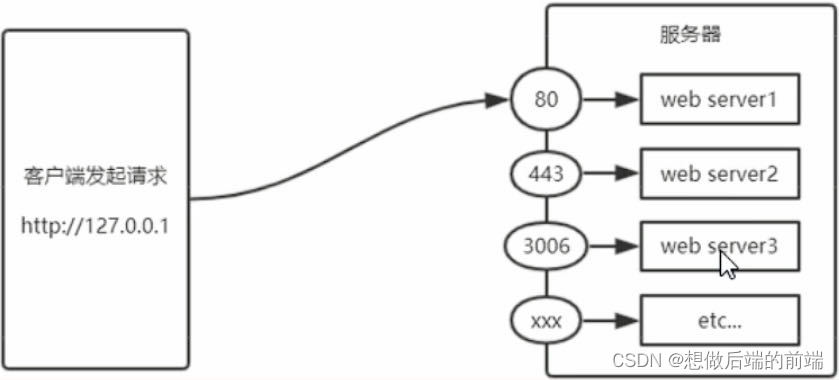
Node.js -- http模块
1. 什么是http模块 在网络节点中,负责消费资源的电脑,叫客户端;负责对外提供网络资源的电脑,叫做服务器。 http模块是Node.js官方提供的,用来创建web服务器的模块。通过http模块提供的http.createServer()方法&#…...
静态库与动态库
库是已经写好的、成熟的、可复用的代码。在我们的开发的应用中经常有一些公共代码是需要反复使用的,就把这些代码编译为库文件。库可以简单看成一组目标文件的集合,将这些目标文件经过压缩打包之后形成的一个可执行代码的二进制文件。库有两种࿱…...

问题 A: C语言11.1
题目描述: 完成一个对候选人得票的统计程序。假设有3个候选人,名字分别为Li,Zhang和Fun。使用结构体存储每一个候选人的名字和得票数。记录每一张选票的得票人名,输出每个候选人最终的得票数。结构体可以定义成如下的格式&#x…...
SLAM中后端优化的技术细节总结与回答
SLAM中后端优化的技术细节 本文档主要收集总结了一些SLAM大佬们讲解后端优化中偏理论的技术细节的博客和回答以及一些学习教材。 Written by wincent 位姿估计以及李群相关的概述 Lie theory is by no means simple ———— 谎言理论绝不简单doge 《A micro Lie theory for st…...
小白快速学习Markdown
这里写自定义目录标题欢迎使用Markdown编辑器新的改变功能快捷键合理的创建标题,有助于目录的生成如何改变文本的样式插入链接与图片如何插入一段漂亮的代码片生成一个适合你的列表创建一个表格设定内容居中、居左、居右SmartyPants创建一个自定义列表如何创建一个注…...

ToBeWritten之物联网WI-FI协议
也许每个人出生的时候都以为这世界都是为他一个人而存在的,当他发现自己错的时候,他便开始长大 少走了弯路,也就错过了风景,无论如何,感谢经历 转移发布平台通知:将不再在CSDN博客发布新文章,敬…...

C++模板元编程深度解析:探索编译时计算的神奇之旅
C模板元编程深度解析:探索编译时计算的神奇之旅引言C模板元编程的概念与作用模板元编程在现代C编程中的应用模板元编程基础类型萃取(Type Traits)编译时条件(静态if)模板元编程中的递归与终止条件模板元编程技巧与工具…...

姿态变换及坐标变换
目录0. 空见间变换&基变换0.0 空间变换0.1 基变换1.缩放、旋转、平移机器人齐次变换坐标系变换0. 空见间变换&基变换 这是矩阵分析的相关知识,有兴趣的参考第一篇知乎文章[1]. 0.0 空间变换 空间变换是指在同一组绝对基下的变换,可以想象为世…...

从命令行管理文件
目录标题文件命名规则创建、删除普通文件创建普通文件格式创建多个普通文件删除普通文件目录操作命令创建目录--mkdir命令统计目录及文件的空间占用情况--du命令删除目录文件复制、移动文件复制(copy)文件或目录--cp命令移动(mv)文…...
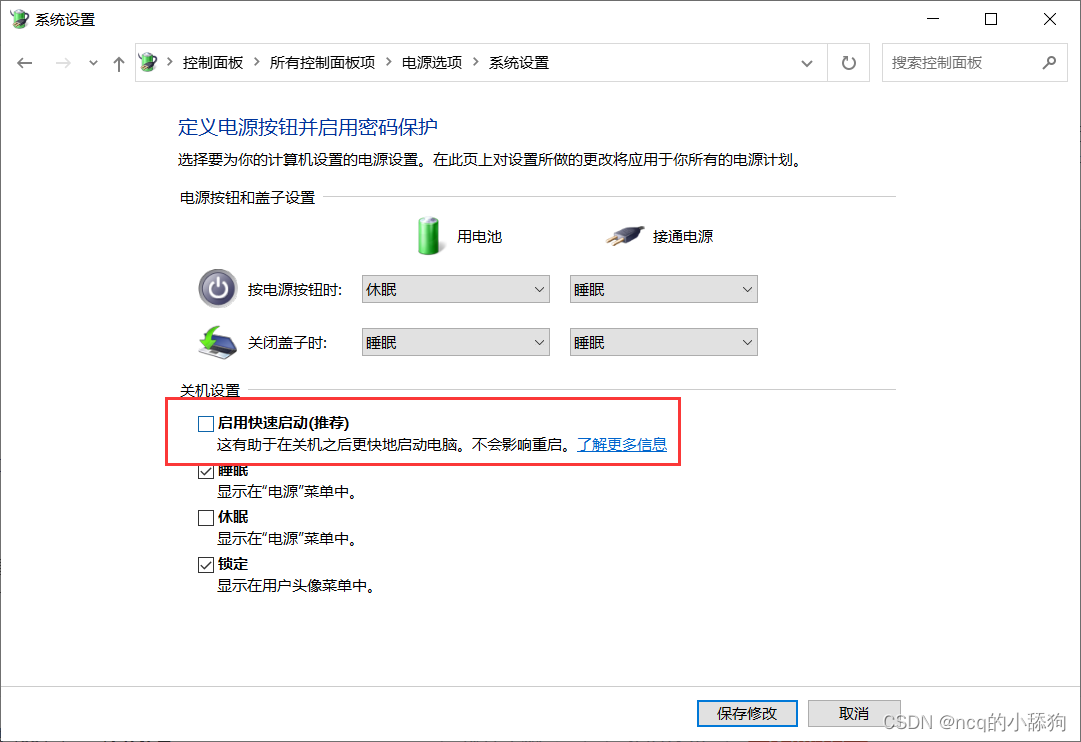
电脑无法正常关机?点了关机又会自动重启
“真木马”相信不少朋友遇到过电脑关机自动重启现象,一点关机,但随后电脑有会进入重启状态,就是一直不会停,属实是很难崩。 目录 一、问题症状 二、问题原因 三、解决方案 方法一: 1.关闭系统发生错误时电脑自动…...

2026年临沂GEO优化,哪家专业公司脱颖而出?
在当今数字化飞速发展的时代,GEO生成式引擎优化对于企业的重要性日益凸显。它能够让客户在第一时间找到公司、产品、品牌以及理念等。那么在2026年的临沂,哪家专业公司会在GEO优化领域脱颖而出呢?一、用户痛点亟待解决目前,众多企…...
)
NotebookLM审稿意见回复全链路避坑清单,含8个高频雷区+对应话术库(限时开放2024最新版PDF)
更多请点击: https://intelliparadigm.com 第一章:NotebookLM审稿意见回复全链路避坑清单导论 NotebookLM 作为 Google 推出的基于文档理解的 AI 助手,在学术协作与论文修订场景中展现出独特优势,但其在处理审稿意见回复时存在隐…...
)
从原理到实战:拆解LCR表如何实现0.1%精度的电容测量(附寄生效应消除指南)
从原理到实战:拆解LCR表如何实现0.1%精度的电容测量(附寄生效应消除指南) 在电子工程领域,精确测量电容值是一项基础却极具挑战性的任务。无论是研发高频电路的设计师,还是调试精密仪表的工程师,亦或是研究…...

进化智能体实战:从基因编码到种群优化的完整实现指南
1. 项目概述:从蓝图到智能体,一次开源协作的深度实践最近在开源社区里,一个名为planck-lab/hermes-evolving-agents-public-blueprint的项目引起了我的注意。乍一看这个标题,它像是一个技术蓝图或公开的设计文档,但深入…...

构建多链资产追踪器:Node.js与React实现链上资产聚合与估值
1. 项目概述:一个链上资产追踪器的诞生最近在整理自己的数字资产时,发现了一个挺普遍但有点烦人的问题:当你在不同的区块链网络(比如以太坊、BSC、Polygon)上持有多种代币(Token)和NFT时&#x…...

3步解锁鸣潮120帧:你的终极游戏体验优化指南
3步解锁鸣潮120帧:你的终极游戏体验优化指南 【免费下载链接】WaveTools 🧰鸣潮工具箱 项目地址: https://gitcode.com/gh_mirrors/wa/WaveTools 还在为《鸣潮》游戏中的60帧限制而烦恼吗?明明拥有强大的硬件配置,却无法充…...

攻克R与Python的壁垒:Giotto空间转录组分析环境一站式搭建指南
1. 为什么你的Giotto安装总是失败? 每次看到空间转录组数据就手痒想用Giotto分析,结果安装环节就被劝退?这可能是大多数生物信息学新手都会遇到的尴尬。作为一个在生信领域摸爬滚打多年的"环境配置工程师",我太理解这种…...
)
告别黑盒:5分钟为你的自定义CNN模型集成Grad-CAM可视化(附常见错误排查)
告别黑盒:5分钟为你的自定义CNN模型集成Grad-CAM可视化(附常见错误排查) 在深度学习项目中,我们常常陷入一个尴尬境地:模型准确率很高,但完全不知道它究竟"看"了图像的哪些部分做出决策。这种黑盒…...

5步实现AutoHotkey脚本独立运行:Ahk2Exe编译实战指南
5步实现AutoHotkey脚本独立运行:Ahk2Exe编译实战指南 【免费下载链接】Ahk2Exe Official AutoHotkey script compiler - written itself in AutoHotkey 项目地址: https://gitcode.com/gh_mirrors/ah/Ahk2Exe 你是否遇到过这样的困扰?精心编写的A…...
)
多语种出海必备,ElevenLabs菲律宾文语音质量实测对比:Wavenet vs. Instant Voice vs. Custom Model(附MOS评分表)
更多请点击: https://intelliparadigm.com 第一章:多语种出海语音技术演进与菲律宾语本地化挑战 随着全球数字服务加速出海,语音交互系统正从单语种向多语种、低资源语言深度拓展。菲律宾语(Filipino/Tagalog)作为东…...