SpringBoot配置slf4j + logback
文章目录
- 日志体系结构
- 在SpringBoot中使用slf4j + logback日志框架
- 四种常用的日志输出
- 1. ConsoleAppender
- 2. FileAppender
- 3. RollingFileAppender之TimeBasedRollingPolicy
- 4. RollingFileAppender之SizeAndTimeBasedRollingPolicy
- 日志过滤
- 1. 级别介绍
- 2. 过滤节点filter介绍
- SpringBoot日志输出的最终使用
日志体系结构
对于一个web项目来说二,日志框架是必不可少的,日志的记录可以帮助我们在开发以及维护过程中快速的定位错误。相信很多人听说过slf4j,log4j,logback,JDK Logging等跟日志框架有关的词语,所以这里也简单介绍下他们之间的关系。
首先slf4j可以理解为规则的制定者,是一个抽象层,定义了日志相关的接口,log4j,logback,JDK Logging都是slf4j的实现层,只是处于不同。
其中slf4j + logback是当下最流行的日志框架。
在SpringBoot中使用slf4j + logback日志框架
在SpringBoot使用是非常方便的,不需要我们有复杂的配置,因为Spring Boot默认支持的就是slf4j + logback日志框架,而我们只需要在src/main/resources下添加配置文件logback-spring.xml即可。
logback-spring.xml配置规则
<configuration><!-- 一般根节点不需要写属性了,使用默认的就好 --> <scan>当配置文件发生修改时,是否重新加载该配置文件,默认为true</scan><scanPeriod>检测“配置文件是否被修改”的时间周期,默认为1min,只有在scan = true时才生效</scanPeriod><debug>是否打印logback内部日志,默认为false</debug><!--重要子节点,正式这些节点的不同组合构成配置文件的基本框架--><!--定义策略的子节点:一个日志策略对应一个appender标签,一个配置文件可以有零个或者多个appender--><!--如果没有定义至少一个appender标签,程序不会报错,但是不会有任何的日志信息输出--><appender><name>指定该节点的名称,方便之后的使用</name><class>指定日志策略的类型的全限定名</class></appender><!--用来设置某各包或者类的日志打印级别--><logger><name>用来指定受此约束的包或者类</name><!--ALL < TRACE < DEBUG < INFO < WARN < ERROR < FATAL < OFF--><level>用来指定日志的输出级别,默认继承上级的级别</level><additivity>是否向上级传递输出信息,默认为true</additivity></logger><!--根root是一个特殊的logger,默认name为root,同时因为是根,所以也没有上级传递一说,故没有additivity属性--><root><!--ALL < TRACE < DEBUG < INFO < WARN < ERROR < FATAL < OFF--><level>用来指定日志的输出级别,默认继承上级的级别</level></root><!--用来定义变量的节点,可以使用${}来使用变量--><property><name>变量名</name><value>变量值</value></property></configuration>
logback-spring.xml配置示例:定义了一个输出到控制台的ConsoleAppender以及输出到文件的FileAppender
<?xml version="1.0" encoding="UTF-8"?><!-- 一般根节点不需要写属性了,使用默认的就好 -->
<configuration><contextName>demo</contextName><!-- 该变量代表日志文件存放的目录名 --><property name="log.dir" value="logs"/><!-- 该变量代表日志文件名 --><property name="log.appname" value="eran"/><!--定义一个将日志输出到控制台的appender,名称为STDOUT --><appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender"><!-- 内容待定 --></appender><!--定义一个将日志输出到文件的appender,名称为FILE_LOG --><appender name="FILE_LOG" class="ch.qos.logback.core.FileAppender"><!-- 内容待定 --></appender><!-- 指定com.demo包下的日志打印级别为INFO,但是由于没有引用appender,所以该logger不会打印日志信息,日志信息向上传递 --><logger name="com.demo" level="INFO"/><!-- 指定最基础的日志输出级别为DEBUG,并且绑定了名为STDOUT的appender,表示将日志信息输出到控制台 --><root level="debug"><appender-ref ref="STDOUT" /></root>
</configuration>
四种常用的日志输出
1. ConsoleAppender
ConsoleAppender的功能
将日志输出到控制台
ConsoleAppender配置实例
<!--定义一个将日志输出到控制台的appender,名称为STDOUT -->
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender"><encoder><!--pattern作用就是定义日志的格式,即定义一条日志信息包含哪些内容--><pattern>[Eran]%date [%thread %line] %level >> %msg >> %logger{10}%n</pattern></encoder>
</appender>
ConsoleAppender的规则制定
%date{}:输出时间,可以在花括号内指定时间格式,例如-%data{yyyy-MM-dd HH:mm:ss}
%logger{}:日志的logger名称
%thread:产生日志的线程名,可简写为%t
%line:当前打印日志的语句在程序中的行号,可简写为%L
%level:日志级别,可简写为%le,%p
%message:程序员定义的日志打印内容,可简写为%msg,%m
%n:换行,即一条日志信息占一行
2. FileAppender
FileAppender的功能
FileAppender表示将日志输出到文件
FileAppender的配置实例
<!--定义一个将日志输出到文件的appender,名称为FILE_LOG -->
<appender name="FILE_LOG" class="ch.qos.logback.core.FileAppender"> <file>D:/test.log</file><append>true</append> <encoder> <pattern>[Eran]%date [%thread %line] %level >> %msg >> %logger{10}%n</pattern></encoder>
</appender>
FileAppender的规则制定
<file>:定义文件名和路径,可以是相对路径 , 也可以是绝对路径 , 如果路径不存在则会自动创建
<append>:两个值true和false,默认为true,表示每次日志输出到文件走追加在原来文件的结尾,false则表示清空现存文件
<encoder>:和ConsoleAppender一样
3. RollingFileAppender之TimeBasedRollingPolicy
看示例就能懂其作用了
<appender name="ROL-FILE-LOG" class="ch.qos.logback.core.rolling.RollingFileAppender"> <!--滚动策略,按照时间滚动 TimeBasedRollingPolicy--><rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"><fileNamePattern>D:/logs/test.%d{yyyy-MM-dd}.log</fileNamePattern><!-- 只保留近七天的日志 --><maxHistory>7</maxHistory><!-- 用来指定日志文件的上限大小,那么到了这个值,就会删除旧的日志 --><totalSizeCap>1GB</totalSizeCap></rollingPolicy> <encoder><pattern>[Eran]%date [%thread %line] %level >> %msg >> %logger{10}%n</pattern></encoder>
</appender>
TimeBasedRollingPolicy的规则制定
<fileNamePattern>:指定日志的路径以及日志文件名的命名规则,一般根据日志文件名+%d{}.log来命名,这边日期的格式默认为yyyy-MM-dd表示每天生成一个文件,即按天滚动yyyy-MM,表示每个月生成一个文件,即按月滚动
<maxHistory>:可选节点,控制保存的日志文件的最大数量,超出数量就删除旧文件,比如设置每天滚动,且<maxHistory> 是7,则只保存最近7天的文件,删除之前的旧文件
<encoder>:同上
<totalSizeCap>:这个节点表示设置所有的日志文件最多占的内存大小,当超过我们设置的值时,logback就会删除最早创建的那一个日志文件。
4. RollingFileAppender之SizeAndTimeBasedRollingPolicy
看示例就能看懂作用
<appender name="ROL-SIZE-FILE-LOG" class="ch.qos.logback.core.rolling.RollingFileAppender"><rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy"><fileNamePattern>D:/logs/test.%d{yyyy-MM-dd}.%i.log</fileNamePattern><!-- 单个文件的最大内存 --><maxFileSize>100MB</maxFileSize><!-- 只保留近七天的日志 --><maxHistory>7</maxHistory><!-- 用来指定日志文件的上限大小,那么到了这个值,就会删除旧的日志 --><totalSizeCap>1GB</totalSizeCap></rollingPolicy><encoder><pattern>[Eran]%date [%thread %line] %level >> %msg >> %logger{10}%n</pattern></encoder>
</appender>
规则制定
1. 仔细观察上边demo中的<fileNamePattern>会发现比TimeBasedRollingPolicy中定义的
<fileNamePattern>多了.%i的字符,这个很关键,在SizeAndTimeBasedRollingPolicy中是必不可少的。
日志过滤
1. 级别介绍
我们开发测试一般输出DEBUG级别的日志,生产环境配置只输出INFO级别的日志。
ALL < TRACE < DEBUG < INFO < WARN < ERROR < FATAL < OFF
2. 过滤节点filter介绍
过滤器通常配置在Appender中,一个Appender可以配置一个或者多个过滤器,有多个过滤器时按照配置顺序依次执行,其实大多数情况下我们都不需要配置,但是有的情况下又必须配置,所以这里也介绍下常用的也是笔者曾经使用过的两种过率机制:级别过滤器LevelFilter和临界值过滤器ThresholdFilter。
级别过滤器LevelFilter
设置了级别为INFO,满足的日志返回ACCEPT即立即处理,不满足条件的日志则返回DENY即丢弃掉,这样经过这一个过滤器就只有INFO级别的日志会被打印出输出。
<filter class="ch.qos.logback.classic.filter.LevelFilter"> <!--日志级别--><level>INFO</level> <!--DENY:日志将被过滤掉,并且不经过下一个过滤器NEUTRAL:日志将会到下一个过滤器继续过滤ACCEPT:日志被立即处理,不再进入下一个过滤器--><!--配置满足过滤条件的处理方式--> <onMatch>ACCEPT</onMatch> <!--配置不满足过滤条件的处理方式--><onMismatch>DENY</onMismatch>
</filter>
临界值过滤器ThresholdFilter
只处理INFO级别之上的日志,当日志级别等于或高于临界值时,过滤器返回NEUTRAL,当日志级别低于临界值时,返回DENY。
<filter class="ch.qos.logback.classic.filter.ThresholdFilter"> <level>INFO</level>
</filter>
SpringBoot日志输出的最终使用
spring-logback.xml日志文件配置
<?xml version="1.0" encoding="UTF-8"?>
<configuration> <!--定义一个将日志输出到控制台的appender,名称为STDOUT --><appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender"><encoder><pattern>[%contextName]%date [%thread %line] %level >> %msg >> %logger{10}%n</pattern></encoder></appender> <!--定义一个将日志输出到文件的appender,名称为FILE_LOG --><appender name="FILE_LOG" class="ch.qos.logback.core.FileAppender"> <file>D:/test.log</file><append>true</append> <encoder> <pattern>[Eran]%date [%thread %line] %level >> %msg >> %logger{10}%n</pattern></encoder></appender> <!-- 按时间滚动产生日志文件 --><appender name="ROL-FILE-LOG" class="ch.qos.logback.core.rolling.RollingFileAppender"> <!--滚动策略,按照时间滚动 TimeBasedRollingPolicy--><rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"><fileNamePattern>D:/logs/test.%d{yyyy-MM-dd}.log</fileNamePattern><!-- 只保留近七天的日志 --><maxHistory>7</maxHistory><!-- 用来指定日志文件的上限大小,那么到了这个值,就会删除旧的日志 --><totalSizeCap>1GB</totalSizeCap></rollingPolicy> <encoder><pattern>[Eran]%date [%thread %line] %level >> %msg >> %logger{10}%n</pattern></encoder></appender><!-- 按时间和文件大小滚动产生日志文件 --><appender name="ROL-SIZE-FILE-LOG" class="ch.qos.logback.core.rolling.RollingFileAppender"><rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy"><fileNamePattern>D:/logs/test.%d{yyyy-MM-dd}.%i.log</fileNamePattern><!-- 单个文件的最大内存 --><maxFileSize>100MB</maxFileSize><!-- 只保留近七天的日志 --><maxHistory>7</maxHistory><!-- 用来指定日志文件的上限大小,那么到了这个值,就会删除旧的日志 --><totalSizeCap>1GB</totalSizeCap></rollingPolicy><encoder><pattern>[Eran]%date [%thread %line] %level >> %msg >> %logger{10}%n</pattern></encoder><!-- 只处理INFO级别以及之上的日志 --><filter class="ch.qos.logback.classic.filter.ThresholdFilter"> <level>INFO</level> </filter><!-- 只处理INFO级别的日志 --><filter class="ch.qos.logback.classic.filter.LevelFilter"> <level>INFO</level> <onMatch>ACCEPT</onMatch> <onMismatch>DENY</onMismatch> </filter></appender><!-- 异步写入日志 --><appender name ="ASYNC" class= "ch.qos.logback.classic.AsyncAppender"> <!-- 不丢失日志.默认的,如果队列的80%已满,则会丢弃TRACT、DEBUG、INFO级别的日志 --> <discardingThreshold >0</discardingThreshold> <!-- 更改默认的队列的深度,该值会影响性能.默认值为256 --> <queueSize>512</queueSize> <!-- 添加附加的appender,最多只能添加一个 --> <appender-ref ref ="FILE_LOG"/></appender><!-- 指定com.demo包下的日志打印级别为DEBUG,但是由于没有引用appender,所以该logger不会打印日志信息,日志信息向上传递 --><logger name="com.example" level="DEBUG"></logger><!-- 这里的logger根据需要自己灵活配置 ,我这里只是给出一个demo--><!-- 指定开发环境基础的日志输出级别为DEBUG,并且绑定了名为STDOUT的appender,表示将日志信息输出到控制台 --><springProfile name="dev"><root level="DEBUG"><appender-ref ref="STDOUT" /></root></springProfile><!-- 指定生产环境基础的日志输出级别为INFO,并且绑定了名为ASYNC的appender,表示将日志信息异步输出到文件 --><springProfile name="prod"><root level="INFO"><appender-ref ref="ASYNC" /></root></springProfile>
</configuration>
当然,如果你的日志输出文件路径只填写了文件名,那输出日志就会默认存放在项目中
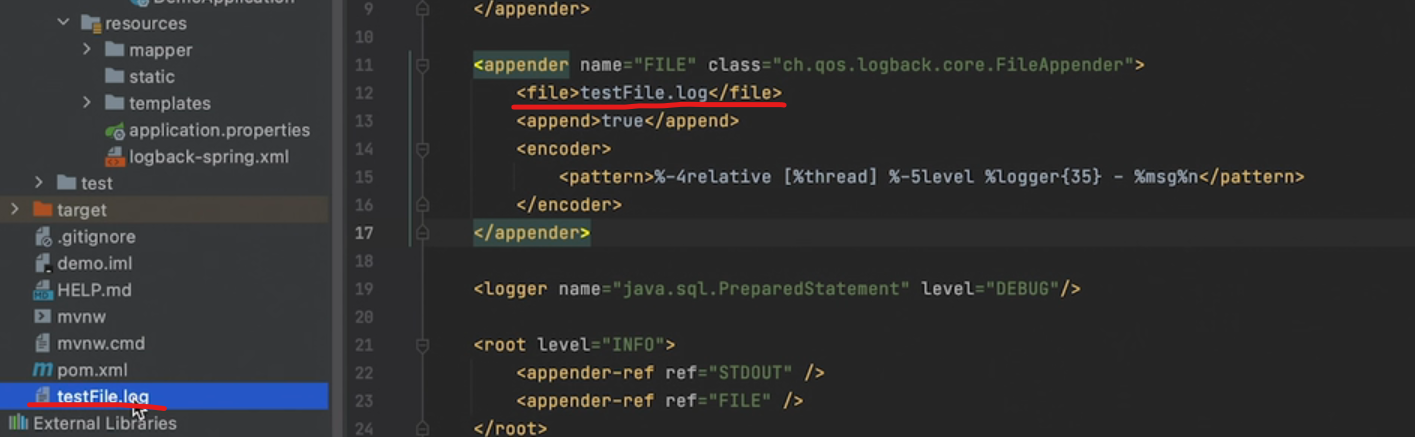
代码中使用日志
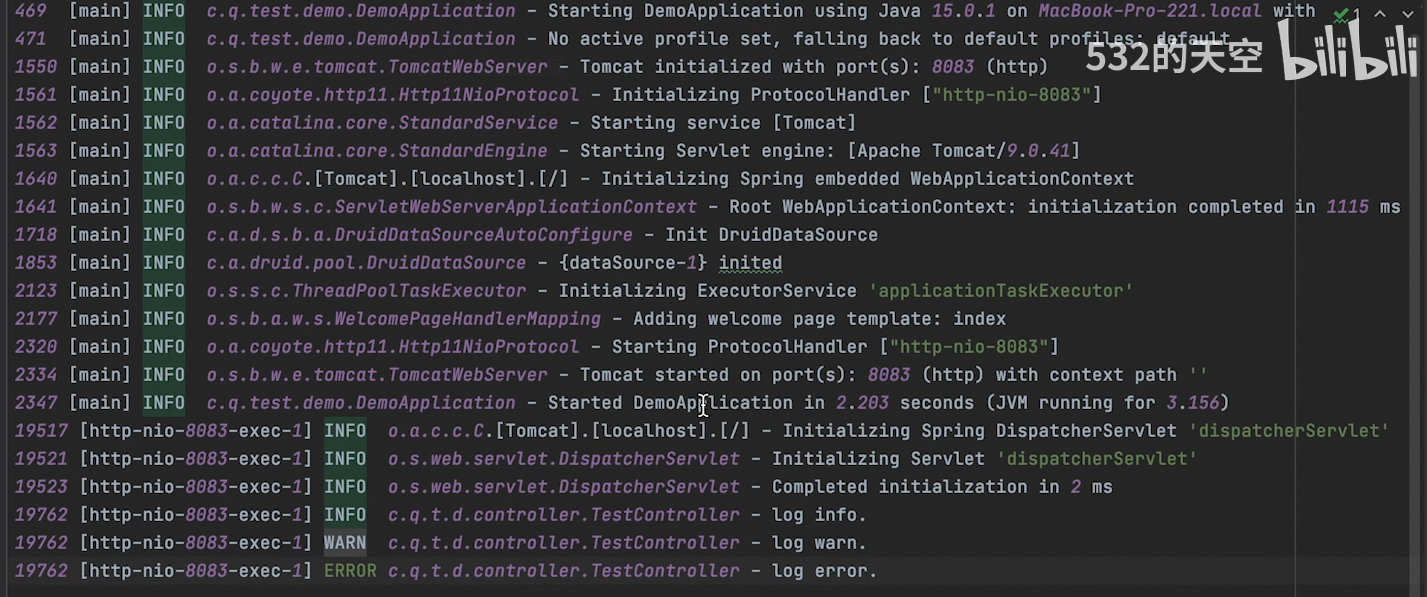
@Slf4j
public class App
{public static void main( String[] args ){log.trace("trace级别的日志");log.debug("debug级别日志");log.info("info级别日志");log.warn("warn级别的日志");log.error("error级别日志");String name = "bysen";Integer age = 24;log.info("姓名{}, 年龄{}",name,age);}
}
项目启动后,SpringBoot默认读取的日志文件是spring-logback,所以名字错误可能就读不到了,那么在项目运行之后,就会在制定路径下生成一个日志文件了。
相关文章:
SpringBoot配置slf4j + logback
文章目录日志体系结构在SpringBoot中使用slf4j logback日志框架四种常用的日志输出1. ConsoleAppender2. FileAppender3. RollingFileAppender之TimeBasedRollingPolicy4. RollingFileAppender之SizeAndTimeBasedRollingPolicy日志过滤1. 级别介绍2. 过滤节点filter介绍Spring…...

JAVA——网络编程基本概念
🎉🎉🎉点进来你就是我的人了 博主主页:🙈🙈🙈戳一戳,欢迎大佬指点!人生格言:当你的才华撑不起你的野心的时候,你就应该静下心来学习! 欢迎志同道合的朋友一起加油喔🦾&am…...

[JavaEE]----Spring02
文章目录Spring_day021,IOC/DI配置管理第三方bean1.1 案例:数据源对象管理1.1.1 环境准备1.1.2 思路分析1.1.3 实现Druid管理步骤1:导入druid的依赖步骤2:配置第三方bean步骤3:从IOC容器中获取对应的bean对象步骤4:运行程序1.1.4 实现C3P0管理步骤1:导入C3P0的依赖步…...
笔记本可自行更换CPU、独显了,老外用它手搓了台“PS5”
前面说到微软打算在 Win12 出来前搞出个模块化的Windows:下一个系统不是Win12,微软要复活Win10X。 模块化不用小蝾再过多介绍了,就像积木一样拼在一起组成一个整体。 优势就很明显了,由于每个部分都是单独的模块,更新…...

Linux uart驱动框架
Linux内核提供了标准的UART驱动程序,可以通过以下步骤编写: 首先需要定义一个结构体来存储串口设备数据。在该结构体中,包含一个uart_port结构体,用于与Linux内核通信,并包含一些设备特定的数据(例如波特率…...
第一个禁止ChatGPT的西方国家
意大利成为第一个有效禁止 ChatGPT 的西方国家。 由于可能违反隐私和数据法,该国的数据监管机构已下令开发聊天机器人的 OpenAI 停止运营。 意大利数据保护局 (GPDP) 提到了一些担忧,包括大量收集用户数据和存储以训练 AI 算法。 ChatGPT 是一种大型语…...
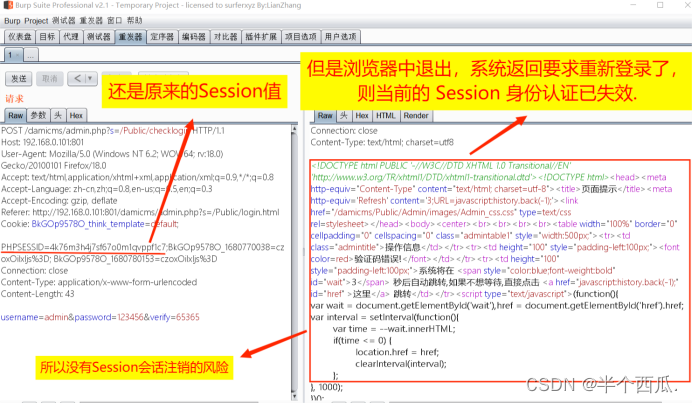
Web 攻防之业务安全:Session会话注销测试.
Web 攻防之业务安全:Session会话注销测试. 业务安全是指保护业务系统免受安全威胁的措施或手段。广义的业务安全应包括业务运行的软硬件平台(操作系统、数据库,中间件等)、业务系统自身(软件或设备)、业务所…...

4月最新编程排行出炉,第一名ChatGPT都在用~
作为一名合格的(准)程序员,必做的一件事是关注编程语言的热度,编程榜代表了编程语言的市场占比变化,它的变化更预示着未来的科技风向和机会! 快跟着一起看看本月排行有何看点: 4月Tiobe排行榜前…...

生成不保存在服务器的附件,并以附件形式发送邮件
需求:从数据库中抓取需要的数据,将数据生成excel表格,并将此表格以附件的形式放置到邮件中发送 //发送带附件的邮件,同时附件不会生成到服务器中public static String sendFileEmail(String form, String code, String to, String…...

Golang Gin框架HTTP上传文件
Golang Gin框架HTTP上传文件解析 文章目录Golang Gin框架HTTP上传文件解析HTTP上传的文件的原理Gin框架文件上传Demo限制文件上传的大小文件类型验证文件上传进度-后台计算文件上传进度HTTP上传的文件的原理 HTTP协议的文件上传是通过HTTP POST请求实现的,使用mult…...
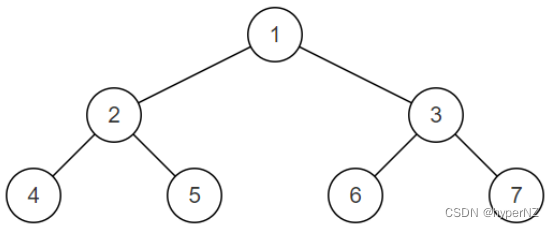
BM36-判断是不是平衡二叉树
题目 输入一棵节点数为 n 二叉树,判断该二叉树是否是平衡二叉树。 在这里,我们只需要考虑其平衡性,不需要考虑其是不是排序二叉树 平衡二叉树(Balanced Binary Tree),具有以下性质:它是一棵空…...

Quartz 单例定时任务
1、引入jar包,继承 Job 接口,编写需要执行的业务逻辑 <dependency><groupId>org.quartz-scheduler</groupId><artifactId>quartz</artifactId><version>2.3.2</version></dependency> public class D…...

不要告诉同事你要离职!打算跳槽,新公司开出两倍薪资,私下告诉要好的同事,却被同事出卖给领导!...
职场上有真正的朋友吗?来看看这位网友的讲述:一位前同事本来打算跳槽,新公司开出的薪资是原来的两倍。她私下告诉了几位同事自己打算离职的消息,并跟同事们分享了工资翻倍的喜悦。可她万万没想到,两天之后的公司会议上…...
RK3399平台开发系列讲解(外设篇)Camera OV13850配置过程
🚀返回专栏总目录 文章目录 一、DTS 配置二、驱动说明三、配置原理四、cam_board.xml沉淀、分享、成长,让自己和他人都能有所收获!😄 📢我们以 OV13850/OV5640 摄像头为例,讲解在该开发板上的配置过程。 一、DTS 配置 isp0: isp@ff910000 {…status = "okay&quo…...

yolov8训练自己的数据集
yolov8训练自己的数据集 1. 标注自己的数据集1.1 确认标注格式1.2 开始标注1. 标注自己的数据集 1.1 确认标注格式 YOLOv8 所用数据集格式与 YOLOv5 YOLOv7 相同,采用格式如下: <object-class-id> <x> <y> <width> <height...
【产品经理】对接第三方平台,你应该怎么做?
作为产品经理,有时候你会接到需求、要求处理对接第三方平台的工作,那么你知道如何判断该不该接这个需求、如何处理第三方平台的对接工作吗? 一、Why 首先是为什么要选择对接第三方平台,这不是一个拍脑袋就可以做决定的事情&#…...

Hbase 介绍
Hbase 简介 Hbase 是一个开源的非关系型的分布式数据库,运用于HDFS文件系统之上,可以容错地存储海量稀疏的数据。Hbase是一个高可靠、高性能、面向列、可伸缩、实时读写的分布式数据库,主要用来存储非结构化和半结构化的松散数据 。 Hbase的…...

金三银四没把握住,凉了...
大家好,前两天跟朋友感慨,今年的铜三铁四、裁员、疫情导致好多人都没拿到offer!现在互联网大厂终于迎来了应届生集中求职季。 对于想跳槽的软件测试人来说,绝对是个找工作的好时机。这时候,很多高薪技术岗、管理岗的缺口和市场需…...
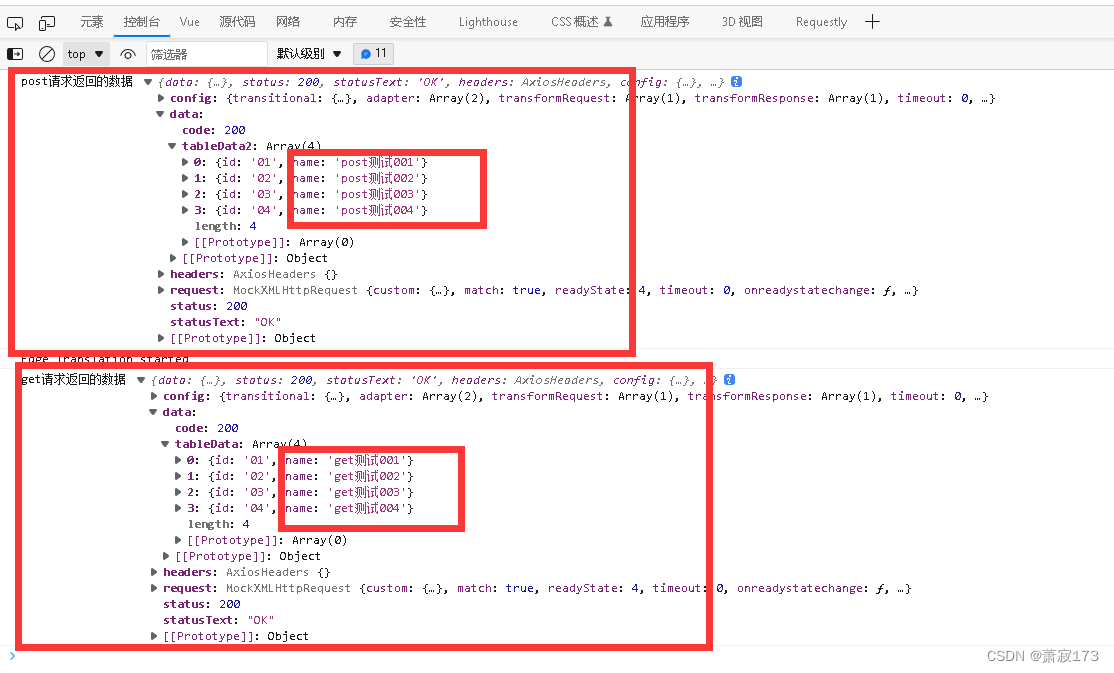
模拟axios请求的数据Mockjs在vue3的使用
1.安装mockjs和axios cnpm install mockjs -Scnpm install axios -S目录结构(这里的演示只用到这四个文件) 2.创建模拟返回的数据(src/mockjs/http.js),放入以下内容 //模拟的请求数据 export default {getData: () > {return {code: 200,tableData: [{id: "01",…...
Elasticsearch:索引状态是红色还是黄色?为什么?
在我之前文章 “Elasticsearch:如何调试集群状态 - 定位错误信息” 中,我有详细介绍如何调试集群状态。在今天的文章中,我将详细介绍如何故障排除和修复索引状态。 Elasticsearch 是一个伟大而强大的系统,特别是创建一个可扩展性极…...

VSCode光标主题定制指南:从颜色令牌到扩展开发
1. 项目概述:一个为开发者定制的光标主题集合如果你和我一样,每天有超过8小时的时间都泡在代码编辑器里,那么你一定会对编辑器里那个千篇一律的、闪烁的竖线光标感到审美疲劳。warrenwoodhouse/cursors这个项目,就是来解决这个“小…...

终极指南:如何免费解锁Cursor Pro完整功能 - 突破AI编辑器限制的完整方案
终极指南:如何免费解锁Cursor Pro完整功能 - 突破AI编辑器限制的完整方案 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youv…...

如何免费下载百度文库文档:三步搞定PDF保存的终极指南
如何免费下载百度文库文档:三步搞定PDF保存的终极指南 【免费下载链接】baidu-wenku fetch the document for free 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wenku 你是否经常在百度文库找到完美的学习资料或工作报告,却因为需要下载券…...

3分钟掌握:163MusicLyrics终极免费歌词解决方案全攻略
3分钟掌握:163MusicLyrics终极免费歌词解决方案全攻略 【免费下载链接】163MusicLyrics 云音乐歌词获取处理工具【网易云、QQ音乐】 项目地址: https://gitcode.com/GitHub_Trending/16/163MusicLyrics 想要快速获取网易云音乐和QQ音乐的歌词吗?1…...

从日志到环境变量:根治 Android Studio AVD 启动报错“The emulator process has terminated”
1. 从错误弹窗到日志分析:定位问题的第一步 当你兴冲冲地打开Android Studio准备启动AVD(Android Virtual Device)时,突然弹出一个冰冷的提示框:"The emulator process has terminated",这感觉就…...

告别showSoftInput失效:一文读懂Android 11+的WindowInsetsController输入法控制
Android输入法控制演进:从InputMethodManager到WindowInsetsController的深度解析 在移动应用开发中,输入法交互是最基础却又最容易被忽视的细节之一。许多开发者都曾遇到过这样的场景:精心设计的登录界面,光标在输入框闪烁&#…...

OpenCore Legacy Patcher终极指南:让老Mac免费运行最新macOS的完整教程
OpenCore Legacy Patcher终极指南:让老Mac免费运行最新macOS的完整教程 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher OpenCore Legacy Patcher是…...
在Windows下的详细评测与实战技巧)
Kafka运维新选择:Offset Explorer(Kafka Tool)在Windows下的详细评测与实战技巧
Kafka运维新选择:Offset Explorer在Windows下的深度评测与高阶实战 当Kafka集群规模从几个节点扩展到数十甚至上百个Broker时,命令行工具kafka-topics.sh和kafka-console-consumer.sh开始显得力不从心。这时,一个得力的可视化工具就像黑暗中的…...

跨越平台限制:如何用WorkshopDL免费获取Steam创意工坊模组
跨越平台限制:如何用WorkshopDL免费获取Steam创意工坊模组 【免费下载链接】WorkshopDL WorkshopDL - The Best Steam Workshop Downloader 项目地址: https://gitcode.com/gh_mirrors/wo/WorkshopDL 还在为Epic Games或GOG平台无法访问Steam创意工坊而烦恼吗…...

城通网盘高速解析终极指南:如何免费实现40倍下载提速
城通网盘高速解析终极指南:如何免费实现40倍下载提速 【免费下载链接】ctfileGet 获取城通网盘一次性直连地址 项目地址: https://gitcode.com/gh_mirrors/ct/ctfileGet 你是否厌倦了城通网盘那令人抓狂的蜗牛下载速度?每次下载大文件都要面对漫长…...