基于Tensorflow的最基本GAN网络模型
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
import glob
import os#(1)创建输入管道
# 导入原始数据
(train_images, train_labels),(_, _) = tf.keras.datasets.mnist.load_data()
# 查看原始数据大小与数据格式
# 60000张图片,每一张图片都是28*28像素
# print(train_images.shape)
# dtype('uint8'),每一位的范围都是0-255的整数,由于图像的一个通道中rgb颜色值就是0-255不等,因此uint8就是图像的标准数字格式
# print(train_images.dtype)#(1.1)数据预处理
# 转换数据类型
train_images = train_images.reshape(train_images.shape[0], 28,28,1)
train_images = train_images.astype('float32')# 归一化0-255>>[-1,1]
train_images = (train_images - 127.5)/127.5#(1.2)确定训练时的BATCH_SIZE与BUFFER_SIZE
BATCH_SIZE = 256 # 每一个batch指一次训练,batch_size表示一次训练所需的数据个数。这里一次训练需要256张图片
BUFFER_SIZE = 60000 # 目前不知道buffer是干什么的#(1.3)将归一化后的图像转化为tf内置的一种数据形式
datasets = tf.data.Dataset.from_tensor_slices(train_images)#(1.4)将训练模型的数据集进行打乱的操作:shuffle
datasets = datasets.shuffle(BUFFER_SIZE).batch(BATCH_SIZE)#(2)生成器模型
def Generator_Model():model = keras.Sequential() # 顺序模型# dense 全连接层# 输入:长度为100的随机数向量(自己定义)# 输出:长度为256的向量model.add(layers.Dense(256, input_shape = (100,), use_bias = False))model.add(layers.BatchNormalization()) # 归一化层model.add(layers.LeakyReLU()) # 激活层model.add(layers.Dense(512, use_bias = False))model.add(layers.BatchNormalization()) # 归一化层model.add(layers.LeakyReLU()) # 激活层model.add(layers.Dense(28*28*1, use_bias = False, activation = 'tanh'))model.add(layers.BatchNormalization()) # 归一化层model.add(layers.Reshape((28,28,1))) # 写为元组的形式return model
#(3)判别器模型
def Discriminator_Model():model = keras.Sequential()model.add(layers.Flatten()) # 将3维图像拉伸为一维图像model.add(layers.Dense(512, use_bias = False))model.add(layers.BatchNormalization()) # 归一化层model.add(layers.LeakyReLU()) # 激活层model.add(layers.Dense(256, use_bias = False))model.add(layers.BatchNormalization()) # 归一化层model.add(layers.LeakyReLU()) # 激活层model.add(layers.Dense(1)) # 输出1或者0return modelcross_entropy = tf.keras.losses.BinaryCrossentropy(from_logits = True)#(4)判别器的损失函数:对于真是图片,判定为1;对于生成图片,判定为0
def discriminator_loss(real_out, fake_out):real_loss = cross_entropy(tf.ones_like(real_out),real_out)fake_loss = cross_entropy(tf.zeros_like(fake_out),fake_out)return real_loss+fake_loss#(5)生成器损失函数:对于生成图片,判定为1
def generator_loss(fake_out):fake_loss = cross_entropy(tf.ones_like(fake_out),fake_out)return fake_loss#(6)创建判别器和生成器的优化器,定义参数的学习速率
generator_opt = tf.keras.optimizers.Adam(1e-4)
discriminator_opt = tf.keras.optimizers.Adam(1e-4)EPOCHS = 100
noise_dim = 100
num_exp_to_generate = 16
seed = tf.random.normal([num_exp_to_generate, noise_dim])# 实例化生成器与判别器
Generator = Generator_Model()
Discriminator = Discriminator_Model()#(7)训练GAN网络
# 每一个batch
def train_step(images):noise = tf.random.normal([BATCH_SIZE, noise_dim])with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:real_output = Discriminator(images, training = True)gen_image = Generator(noise, training = True)fake_output = Discriminator(gen_image, training = True)gen_loss = generator_loss(fake_output)disc_loss = discriminator_loss(real_output, fake_output)#优化gradient_gen = gen_tape.gradient(gen_loss, Generator.trainable_variables)gradient_disc = disc_tape.gradient(disc_loss, Discriminator.trainable_variables)generator_opt.apply_gradients(zip(gradient_gen, Generator.trainable_variables))discriminator_opt.apply_gradients(zip(gradient_disc, Discriminator.trainable_variables))# 可视化函数
def generator_plt_img(gen_model, test_noise):pre_images = gen_model(test_noise, training = False)fig = plt.figure(figsize=(4, 4))for i in range(pre_images.shape[0]):plt.subplot(4,4,i+1)plt.imshow((pre_images[i,:,:,0]+1)/2, cmap = 'gray')plt.axis('off')plt.show()# 完整的训练模型的函数
def train(dataset, epochs):for epoch in range(epochs):for img_batch in dataset:train_step(img_batch)print('.',end='')generator_plt_img(Generator, seed)
# 训练模型
train(datasets, EPOCHS)视频链接:https://www.bilibili.com/video/BV1f7411E7wU/?spm_id_from=333.999.0.0
相关文章:

基于Tensorflow的最基本GAN网络模型
import tensorflow as tf from tensorflow import keras from tensorflow.keras import layers import matplotlib.pyplot as plt %matplotlib inline import numpy as np import glob import os #(1)创建输入管道 # 导入原始数据 (train_images, train…...

数据质量管理概述
1、数据质量的概念 指的是在组织业务,管理要求下,符合数据使用者满足业务,管理需求的评价方式 2、数据质量管理的概念 3、4种常见低质量数据情况 1)重要数据缺失 有些信息暂时无法获取或者获取代价太大信息在采集输入中遗漏属…...

C++ const、volatile和mutable关键字详解
对于cv(const 与 volatile)类型限定符和关键字mutable在《cppreference》中的定义为: cv可出现于任何类型说明符中,以指定被声明对象或被命名类型的常量性(constness)或易变性(volatility&#…...

MySQL实验四:数据更新
MySQL实验四:数据更新 目录MySQL实验四:数据更新导读表结构sql建表语句模型图1、 SQL更新:将所有学生的年龄增加1岁代码2、SQL更新:修改“高等数学”课程倒数三名成绩,在原来分数上减5分代码解析3、SQl更新:…...

商汤科技推出“日日新SenseNova”,大模型体系赋能人工智能新未来
2023年4月10日,商汤科技SenseTime技术交流日活动在上海举行,分享了以“大模型大算力”推进AGI(通用人工智能)发展的战略布局,并公布了商汤在该战略下的“日日新SenseNova”大模型体系。 公开信息显示,商汤科…...

【中创AI】斯坦福人工智能年度报告:AI论文发表量中国世界第一!
斯坦福以人为本人工智能研究所 (HAI) 发布了最新一期的 2023 AI 指数 (2023 AI Index) 报告,探讨了过去一年机器学习的发展。 (斯坦福HAI于2019年初成立,致力于研究新的AI方法,并研究该技术对社会的影响。其每年发布一份AI指数报…...
Java基础(五)面向对象编程(基础)
学习面向对象内容的三条主线 Java类及类的成员:(重点)属性、方法、构造器;(熟悉)代码块、内部类面向对象的特征:封装、继承、多态、(抽象)其他关键字的使用:…...

寻找CSDN平行世界的另一个你
本文由 大侠(AhcaoZhu)原创,转载请声明。 链接: https://blog.csdn.net/Ahcao2008 寻找CSDN平行世界的另一个你摘要前言列表测试目的摘要 本文作了一个测试,看看在 CSDN 的博文中,艾特()某个好友,TA是否能够…...
ChatGPT的发展对客户支持能提供什么帮助?
多数组织认为客户服务是一种开销,实际上还可以将客户服务看成是一种机会。它可以让你在销售后继续推动客户的价值。成功的企业深知,客户服务不仅可以留住客户,还可以增加企业收入。客户服务是被低估的手段,它可以通过推荐、见证和…...
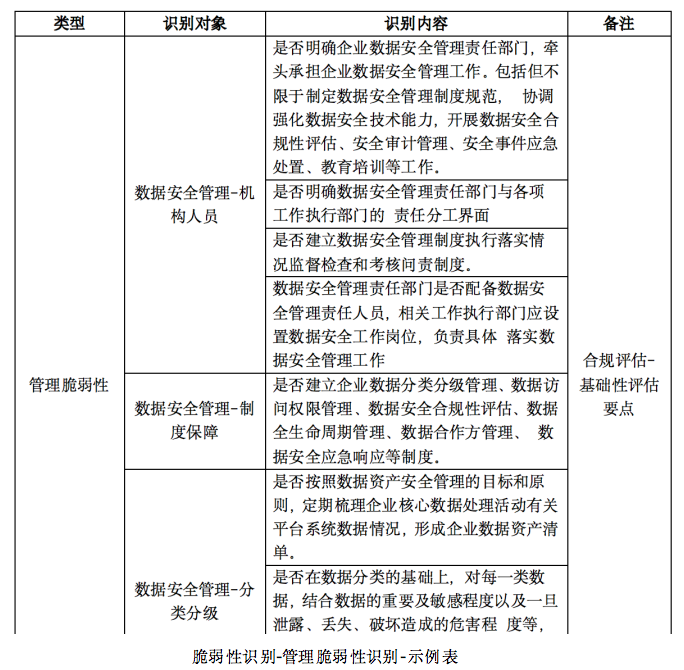
数据安全评估体系建设
数据安全评估是指对重要数据、个人信息等数据资产的价值与权益、合规性、威胁、脆弱性、防护等进行分析和判断,以评估数据安全事件发生的概率和可能造成的损失,并采取相应的措施和建议。 数据安全评估的重要性和背景 1.国家法律法规下的合规需要 目前数…...
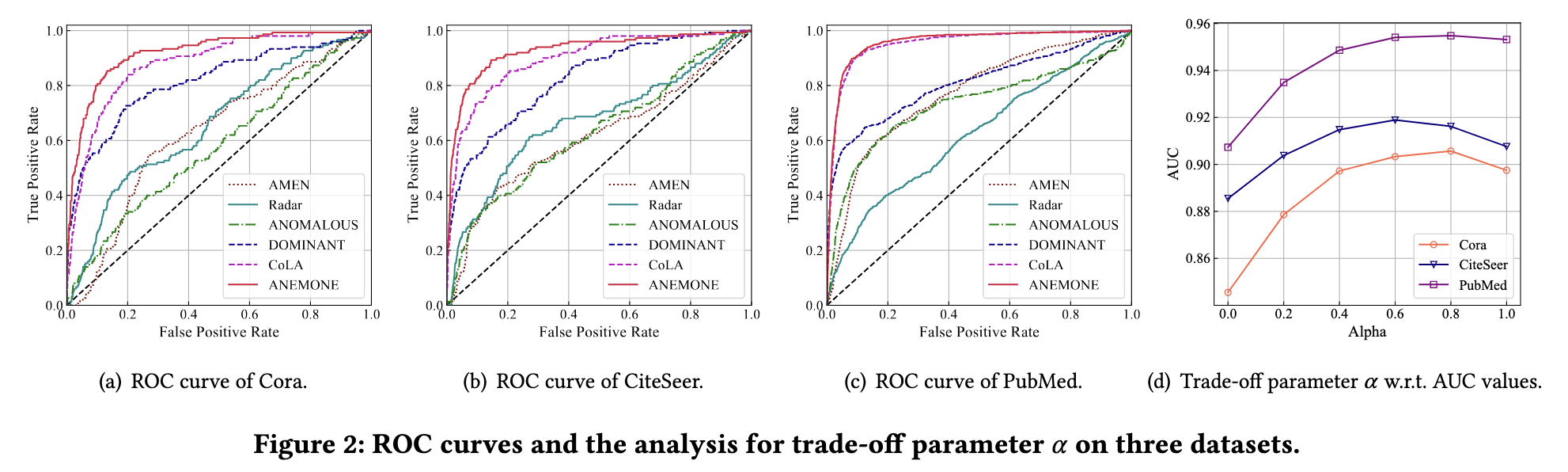
论文阅读 - ANEMONE: Graph Anomaly Detection with Multi-Scale Contrastive Learning
目录 摘要 1 简介 2 问题陈述 3 PROPOSED ANEMONE FRAMEWORK 3.1 多尺度对比学习模型 3.1.1 增强的自我网络生成 3.1.2 补丁级对比网络 3.1.3 上下文级对比网络 3.1.4 联合训练 3.2 统计异常估计器 4 EXPERIMENTS 4.1 Experimental Setup 4.1.1 Datasets 4.1.2 …...

数据密集型应用存储与检索设计
本文内容翻译自《数据密集型应用系统设计》,豆瓣评分高达 9.7 分。 什么是「数据密集型应用系统」? 当数据(数据量、数据复杂度、数据变化速度)是一个应用的主要挑战,那么可以把这个应用称为数据密集型的。与之相对的是…...
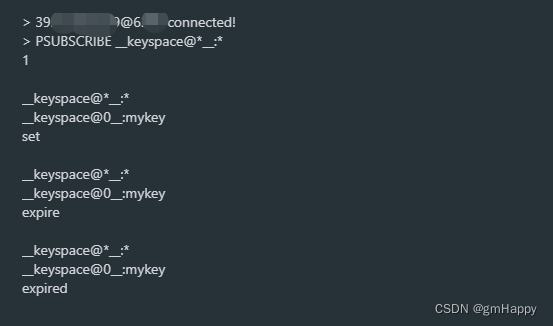
Spring Boot集成Redis实现keyspace监听 | Spring Cloud 34
一、前言 在前面我们通过以下章节对Redis的keyevent(键事件通知)使用有了基础的了解: Spring Boot集成Redis实现keyevent监听 | Spring Cloud 33 现在开始我们正式学习Redis的keyspace(键空间通知),在本…...
如何搭建chatGPT4.0模型-国内如何用chatGPT4.0
国内如何用chatGPT4.0 在国内,目前可以通过以下途径使用 OpenAI 的 ChatGPT 4.0: 自己搭建模型:如果您具备一定的技术能力,可以通过下载预训练模型和相关的开发工具包,自行搭建 ChatGPT 4.0 模型。OpenAI提供了相关的…...
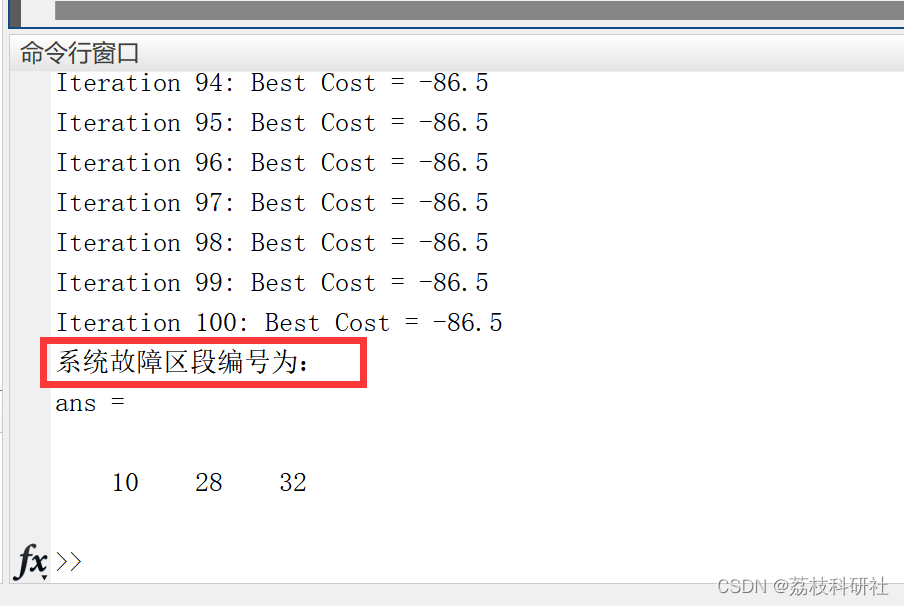
【故障定位】基于多元宇宙算法的主动配电网故障定位方法研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
基于html+css的自适应展示1
准备项目 项目开发工具 Visual Studio Code 1.44.2 版本: 1.44.2 提交: ff915844119ce9485abfe8aa9076ec76b5300ddd 日期: 2020-04-16T16:36:23.138Z Electron: 7.1.11 Chrome: 78.0.3904.130 Node.js: 12.8.1 V8: 7.8.279.23-electron.0 OS: Windows_NT x64 10.0.19044 项目…...

DolphinDB +Python Airflow 高效实现数据清洗
DolphinDB 作为一款高性能时序数据库,其在实际生产环境中常有数据的清洗、装换以及加载等需求,而对于该如何结构化管理好 ETL 作业,Airflow 提供了一种很好的思路。本篇教程为生产环境中 ETL 实践需求提供了一个解决方案,将 Pytho…...

pip3 升级软件包时遇到超时错误解决方法
如果你在使用 pip3 升级软件包时遇到超时错误,可能是因为下载速度缓慢或网络不稳定。以下是解决方法: 更改 pip3 源:你可以切换到其他 pip3 源,例如清华、阿里等等,以提高下载速度。 pip3 install -i https://pypi.tun…...

Linux环境开机自启动
1.制作服务 在/etc/systemd/system/路径下创建kkFile.service文件 cd /etc/systemd/system/ vim kkFile.service2.写入如下内容 [Unit] DescriptionkkFile service [Service] Typeforking ExecStart/sinosoft/yjya/kkFileView-4.0.0/bin/startup.sh [Install] WantedBymulti…...

字节8年测试经验,送给想要学习自动化测试的同学6条建议
我的职业生涯开始和大多数测试人一样,开始接触都是纯功能界面测试。那时候在一家电商公司做测试,做了有一段时间,熟悉产品的业务流程以及熟练测试工作流程规范之后,效率提高了,工作比较轻松,也得到了更好的…...

对比直接使用厂商 API 体验 Taotoken 在路由容灾上的价值
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用厂商 API 体验 Taotoken 在路由容灾上的价值 在开发依赖大模型能力的应用时,服务的连续性与稳定性是保障用…...

荣品RV1126 SDK编译避坑指南:从环境配置到分区调整,手把手解决常见编译错误
RV1126 SDK编译实战:从环境搭建到分区优化的全流程解决方案 1. 开发环境配置与初始化 RV1126开发环境的搭建是整个开发流程的第一步,也是后续所有工作的基础。一个稳定、高效的开发环境能够显著提升开发效率,减少不必要的错误。 首先需要确保…...

Unlock Music Electron:3步解锁你的加密音乐文件,重获音乐自由终极指南
Unlock Music Electron:3步解锁你的加密音乐文件,重获音乐自由终极指南 【免费下载链接】unlock-music-electron Unlock Music Project - Electron Edition 在Electron构建的桌面应用中解锁各种加密的音乐文件 项目地址: https://gitcode.com/gh_mirro…...

百度网盘直链解析工具:告别限速,实现高速下载的Python解决方案
百度网盘直链解析工具:告别限速,实现高速下载的Python解决方案 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 在数字资源共享日益频繁的今天ÿ…...

如何用Sunshine打造个人游戏云:终极自托管游戏串流解决方案
如何用Sunshine打造个人游戏云:终极自托管游戏串流解决方案 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 你是否曾经梦想在任何设备上畅玩PC游戏?无论是想…...

Gopeed下载器深度解析:从零开始构建你的全平台高速下载解决方案
Gopeed下载器深度解析:从零开始构建你的全平台高速下载解决方案 【免费下载链接】gopeed A fast, modern download manager for HTTP, BitTorrent, Magnet, and ed2k. Cross-platform, built with Golang and Flutter. 项目地址: https://gitcode.com/GitHub_Tre…...

m4s-converter终极指南:如何无损转换B站缓存视频并保留弹幕
m4s-converter终极指南:如何无损转换B站缓存视频并保留弹幕 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 在数字内容日益丰富的今天…...

避坑指南:在Unity 2022 LTS中配置XCharts插件时遇到的3个常见问题及解决方法
Unity 2022 LTS中XCharts插件实战避坑手册 当数据可视化成为现代应用的核心需求时,Unity开发者常会选择XCharts这类开源图表插件来快速实现专业级图表展示。但在实际项目落地过程中,版本兼容性、环境配置和平台适配等问题往往会让开发进程意外卡壳。本文…...

基于Kubernetes Lease构建分布式部署锁:解决CI/CD环境下的资源竞争
1. 项目概述:从“clawfight”看一场被遗忘的社区技术博弈看到“2019-02-18/clawfight”这个标题,很多人的第一反应可能是困惑。它不像一个标准的软件项目名,没有清晰的版本号,也没有指明具体的技术栈。但恰恰是这种看似随意的命名…...

基于NestJS与Next.js的自托管电影管理应用Story Flicks部署与实战
1. 项目概述:一个为影迷打造的私人观影档案库 如果你和我一样,是个重度电影爱好者,那么你一定经历过这样的时刻:看完一部好片子,内心澎湃,想写点什么记录一下,却发现豆瓣、IMDb的评论区要么太嘈…...