数据密集型应用存储与检索设计
本文内容翻译自《数据密集型应用系统设计》,豆瓣评分高达 9.7 分。

什么是「数据密集型应用系统」?
当数据(数据量、数据复杂度、数据变化速度)是一个应用的主要挑战,那么可以把这个应用称为数据密集型的。与之相对的是计算密集型——处理器速度是主要瓶颈。
其实我们平时遇到的大部分系统都是数据密集型的——应用代码访问内存、硬盘、数据库、消息队列中的数据,经过业务逻辑处理,再返回给用户。
这本书并不是针对某个具体的数据库,而是自顶向下展开各项技术的共性和区别,把所有跟「数据」有关的知识点做了剖析、整理、总结。

查询类型
Online analytical processing和Online analytical processing。
查询类型主要分为两大类:
| 引擎类型 | 请求数量 | 数据量 | 瓶颈 | 存储格式 | 用户 | 场景举例 | 产品举例 |
| OLTP | 相对频繁,侧重在线交易 | 总体和单次查询都相对较小 | Disk Seek | 多用行存 | 比较普遍,一般应用用的比较多 | 银行交易 | MySQL |
| OLAP | 相对较少,侧重离线分析 | 总体和单次查询都相对巨大 | Disk Bandwidth | 列存逐渐流行 | 多为商业用户 | 商业分析 | ClickHouse |
其中,OLTP 侧,常用的存储引擎又有两种流派:
| 流派 | 主要特点 | 基本思想 | 代表 |
| log-structured 流 | 只允许追加,所有修改都表现为文件的追加和文件整体增删 | 变随机写为顺序写 | Bitcask、LevelDB、RocksDB、Cassandra、Lucene |
| update-in-place 流 | 以页(page)为粒度对磁盘数据进行修改 | 面向页、查找树 | B 族树,所有主流关系型数据库和一些非关系型数据库 |
此外,针对 OLTP, 还探索了常见的建索引的方法,以及一种特殊的数据库 —— 全内存数据库。
对于数据仓库,本章分析了它与 OLTP 的主要不同之处。数据仓库主要侧重于聚合查询,需要扫描很大量的数据,此时,索引就相对不太有用。需要考虑的是存储成本、带宽优化等,由此引出列式存储。
驱动数据库的底层数据结构
本节由一个 shell 脚本出发,到一个相当简单但可用的存储引擎 Bitcask,然后引出 LSM-tree,他们都属于日志流范畴。之后转向存储引擎另一流派 ——B 族树,之后对其做了简单对比。最后探讨了存储中离不开的结构 —— 索引。
首先来看,世界上 “最简单” 的数据库,由两个 Bash 函数构成:
| 1 2 3 4 5 6 7 8 | #!/bin/bash db_set () { echo "$1,$2" >> database } db_get () { grep "^$1," database | sed -e "s/^$1,//" | tail -n 1 } |
这两个函数实现了一个基于字符串的 KV 存储(只支持 get/set,不支持 delete):
| 1 2 3 4 | $ db_set 123456 '{"name":"London","attractions":["Big Ben","London Eye"]}' $ db_set 42 '{"name":"San Francisco","attractions":["Golden Gate Bridge"]}' $ db_get 42 {"name":"San Francisco","attractions":["Golden Gate Bridge"]} |
来分析下它为什么 work,也反映了日志结构存储的最基本原理:
- set:在文件末尾追加一个 KV 对。
- get:匹配所有 Key,返回最后(也即最新)一条 KV 对中的 Value。
可以看出:写很快,但是读需要全文逐行扫描,会慢很多。典型的以读换写。为了加快读,我们需要构建索引:一种允许基于某些字段查找的额外数据结构。
索引从原数据中构建,只为加快查找。因此索引会耗费一定额外空间,和插入时间(每次插入要更新索引),即,重新以空间和写换读取。
这便是数据库存储引擎设计和选择时最常见的权衡(trade off):
- 恰当的存储格式能加快写(日志结构),但是会让读取很慢;也可以加快读(查找树、B 族树),但会让写入较慢。
- 为了弥补读性能,可以构建索引。但是会牺牲写入性能和耗费额外空间。
存储格式一般不好动,但是索引构建与否,一般交予用户选择。
哈希索引
本节主要基于最基础的 KV 索引。
依上小节的例子,所有数据顺序追加到磁盘上。为了加快查询,我们在内存中构建一个哈希索引:
- Key 是查询 Key
- Value 是 KV 条目的起始位置和
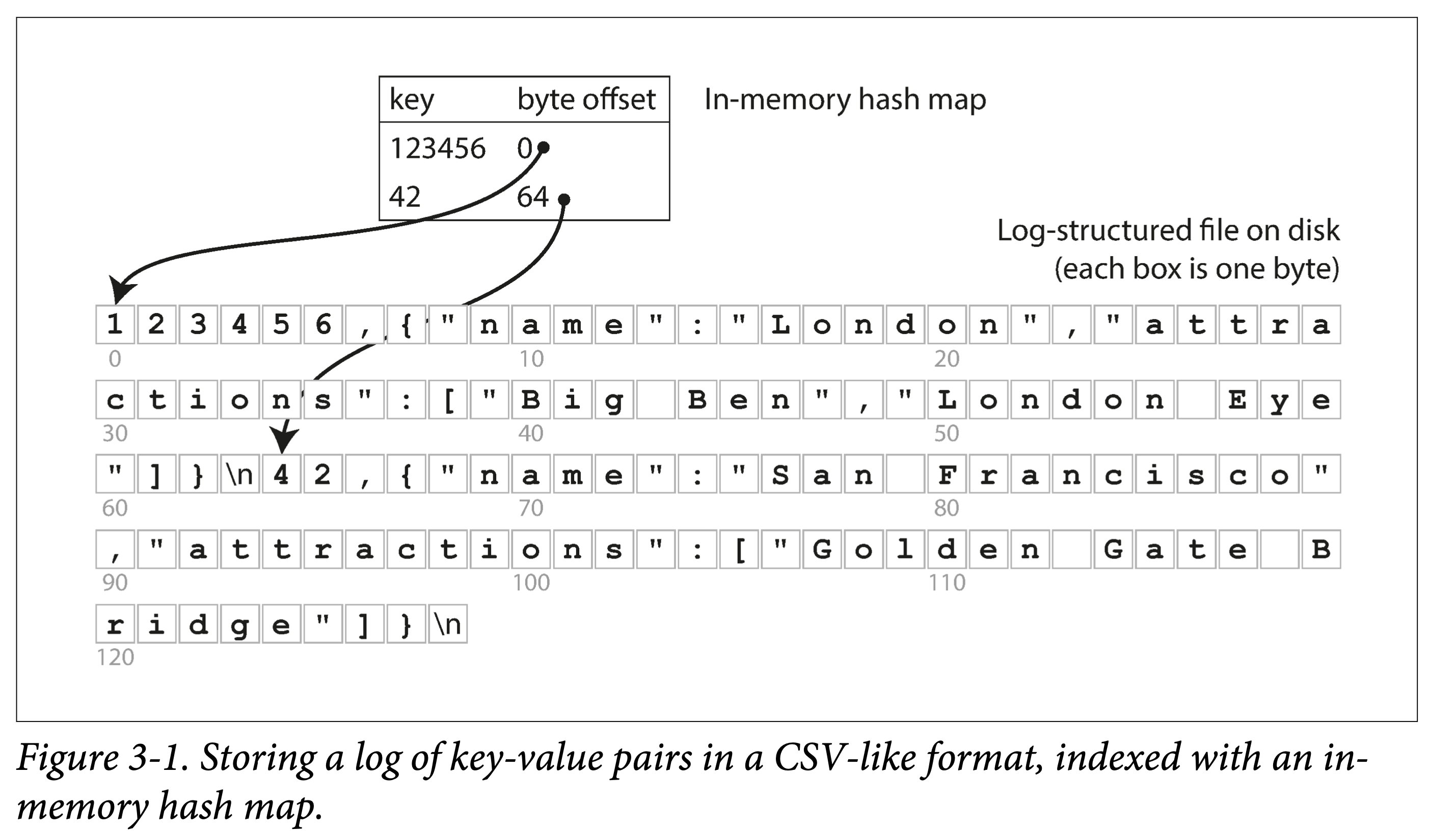
看来很简单,但这正是 Bitcask 的基本设计,但关键是,他 Work(在小数据量时,即所有 key 都能存到内存中时):能提供很高的读写性能:
- 写:文件追加写。
- 读:一次内存查询,一次磁盘 seek;如果数据已经被缓存,则 seek 也可以省掉。
如果你的 key 集合很小(意味着能全放内存),但是每个 key 更新很频繁,那么 Bitcask 便是你的菜。举个栗子:频繁更新的视频播放量,key 是视频 url,value 是视频播放量。
但有个很重要问题,单个文件越来越大,磁盘空间不够怎么办?
在文件到达一定尺寸后,就新建一个文件,将原文件变为只读。同时为了回收多个 key 多次写入的造成的空间浪费,可以将只读文件进行紧缩( compact ),将旧文件进行重写,挤出 “水分”(被覆写的数据)以进行垃圾回收。

当然,如果我们想让其工业可用,还有很多问题需要解决:
- 文件格式。对于日志来说,CSV 不是一种紧凑的数据格式,有很多空间浪费。比如,可以用 length + record bytes 。
- 记录删除。之前只支持 put\get,但实际还需要支持 delete。但日志结构又不支持更新,怎么办呢?一般是写一个特殊标记(比如墓碑记录,tombstone)以表示该记录已删除。之后 compact 时真正删除即可。
- 宕机恢复。在机器重启时,内存中的哈希索引将会丢失。当然,可以全盘扫描以重建,但通常一个小优化是,对于每个 segment file, 将其索引条目和数据文件一块持久化,重启时只需加载索引条目即可。
- 记录写坏、少写。系统任何时候都有可能宕机,由此会造成记录写坏、少写。为了识别错误记录,我们需要增加一些校验字段,以识别并跳过这种数据。为了跳过写了部分的数据,还要用一些特殊字符来标识记录间的边界。
- 并发控制。由于只有一个活动(追加)文件,因此写只有一个天然并发度。但其他的文件都是不可变的(compact 时会读取然后生成新的),因此读取和紧缩可以并发执行。
乍一看,基于日志的存储结构存在折不少浪费:需要以追加进行更新和删除。但日志结构有几个原地更新结构无法做的优点:
- 以顺序写代替随机写。对于磁盘和 SSD,顺序写都要比随机写快几个数量级。
- 简易的并发控制。由于大部分的文件都是不可变(immutable)的,因此更容易做并发读取和紧缩。也不用担心原地更新会造成新老数据交替。
- 更少的内部碎片。每次紧缩会将垃圾完全挤出。但是原地更新就会在 page 中留下一些不可用空间。
当然,基于内存的哈希索引也有其局限:
- 所有 Key 必须放内存。一旦 Key 的数据量超过内存大小,这种方案便不再 work。当然你可以设计基于磁盘的哈希表,但那又会带来大量的随机写。
- 不支持范围查询。由于 key 是无序的,要进行范围查询必须全表扫描。
后面讲的 LSM-Tree 和 B+ 树,都能部分规避上述问题。
- 想想,会如何进行规避?
SSTables 和 LSM-Trees
这一节层层递进,步步做引,从 SSTables 格式出发,牵出 LSM-Trees 全貌。
对于 KV 数据,前面的 BitCask 存储结构是:
- 外存上日志片段
- 内存中的哈希表
其中外存上的数据是简单追加写而形成的,并没有按照某个字段有序。
假设加一个限制,让这些文件按 key 有序。我们称这种格式为:SSTable(Sorted String Table)。
这种文件格式有什么优点呢?
高效的数据文件合并。即有序文件的归并外排,顺序读,顺序写。不同文件出现相同 Key 怎么办?
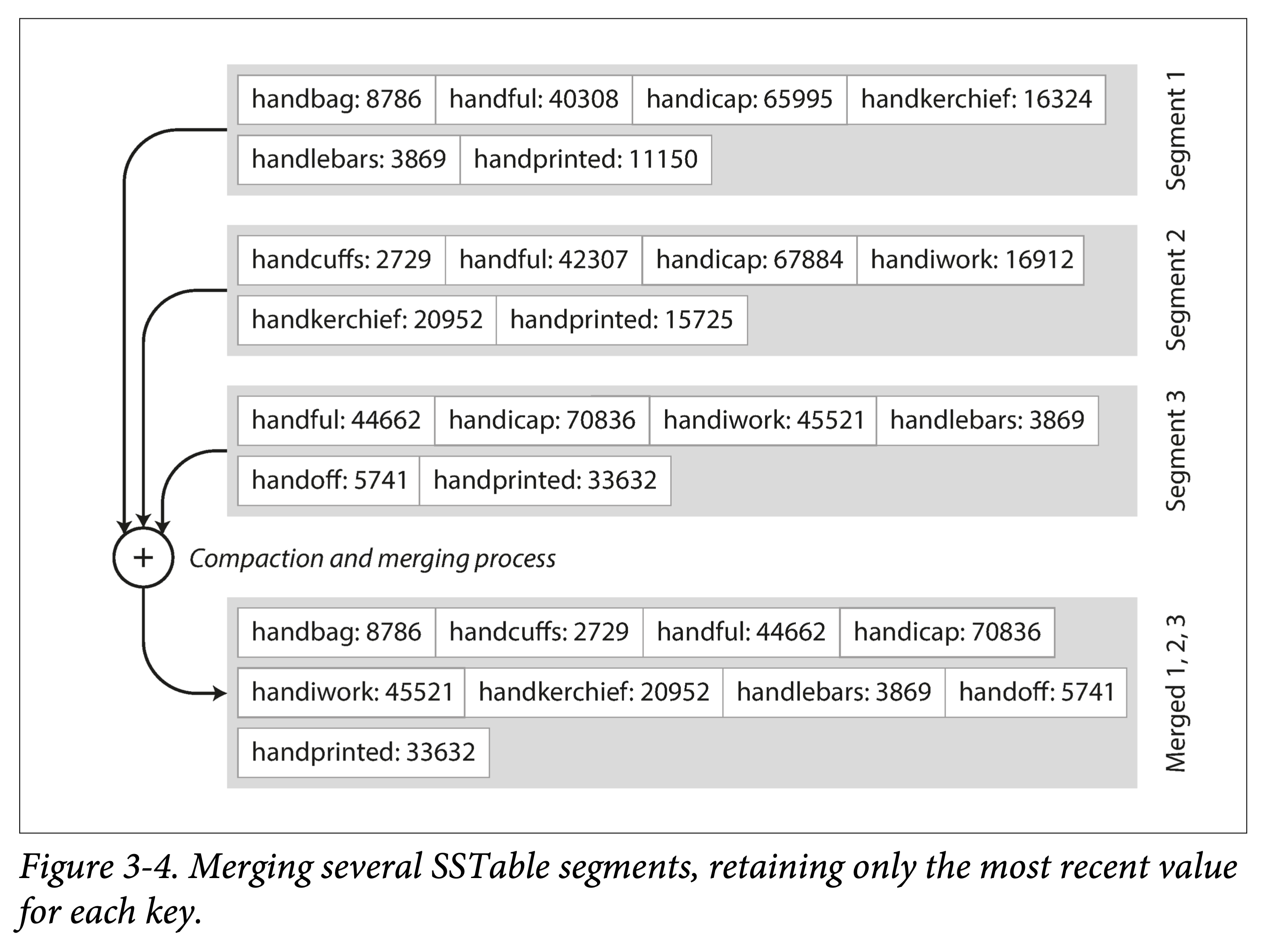
不需要在内存中保存所有数据的索引。仅需要记录下每个文件界限(以区间表示:[startKey, endKey],当然实际会记录的更细)即可。查找某个 Key 时,去所有包含该 Key 的区间对应的文件二分查找即可。
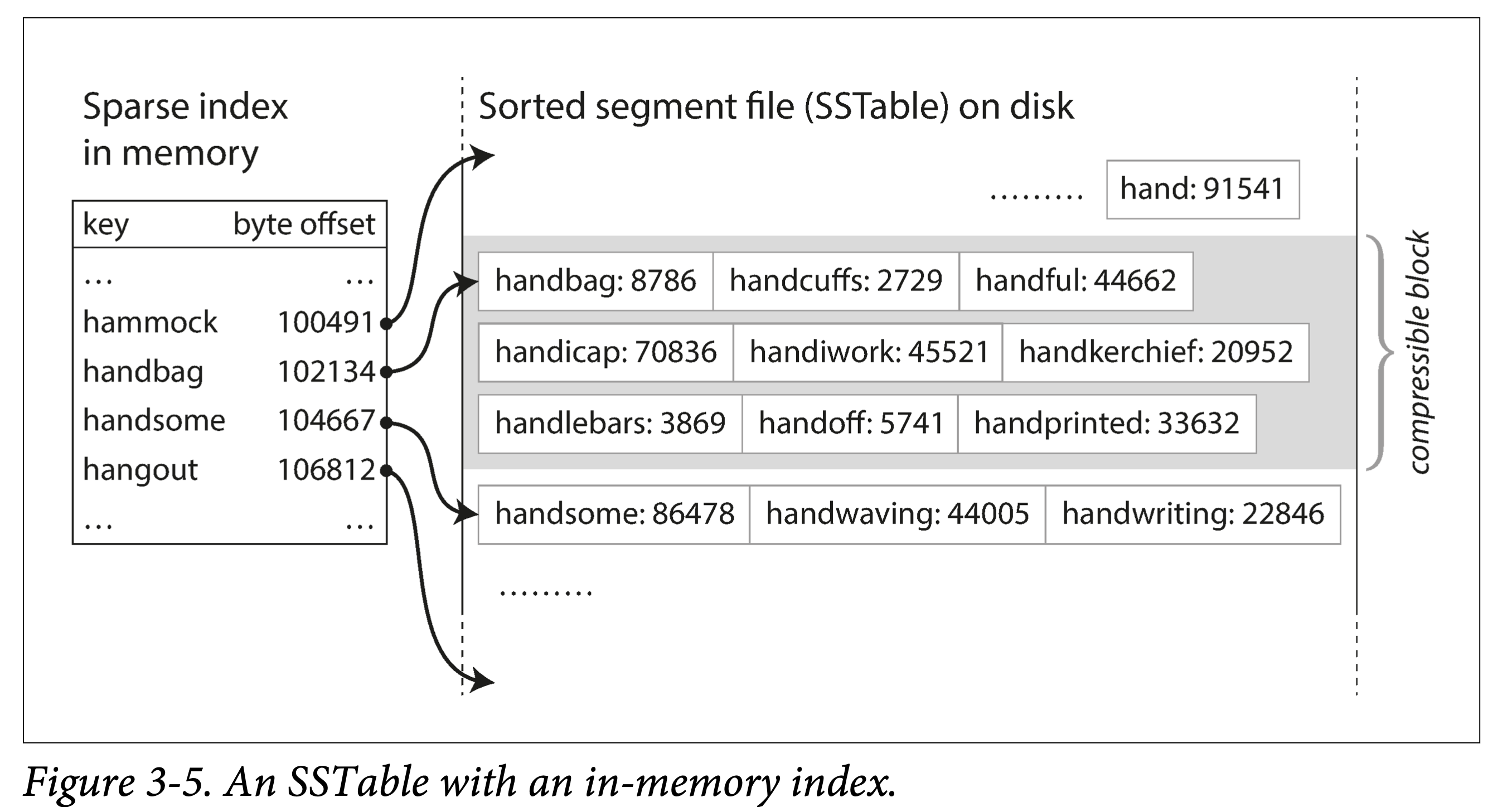
分块压缩,节省空间,减少 IO。相邻 Key 共享前缀,既然每次都要批量取,那正好一组 key batch 到一块,称为 block,且只记录 block 的索引。
构建和维护 SSTables
SSTables 格式听起来很美好,但须知数据是乱序的来的,我们如何得到有序的数据文件呢?
这可以拆解为两个小问题:
- 如何构建。
- 如何维护。
构建 SSTable 文件。将乱序数据在外存(磁盘 or SSD)中上整理为有序文件,是比较难的。但是在内存就方便的多。于是一个大胆的想法就形成了:
- 在内存中维护一个有序结构(称为 MemTable)。红黑树、AVL 树、条表。
- 到达一定阈值之后全量 dump 到外存。
维护 SSTable 文件。为什么需要维护呢?首先要问,对于上述复合结构,我们怎么进行查询:
- 先去 MemTable 中查找,如果命中则返回。
- 再去 SSTable 按时间顺序由新到旧逐一查找。
如果 SSTable 文件越来越多,则查找代价会越来越大。因此需要将多个 SSTable 文件合并,以减少文件数量,同时进行 GC,我们称之为紧缩( Compaction)。
该方案的问题:如果出现宕机,内存中的数据结构将会消失。 解决方法也很经典:WAL。
从 SSTables 到 LSM-Tree
将前面几节的一些碎片有机的组织起来,便是时下流行的存储引擎 LevelDB 和 RocksDB 后面的存储结构:LSM-Tree:
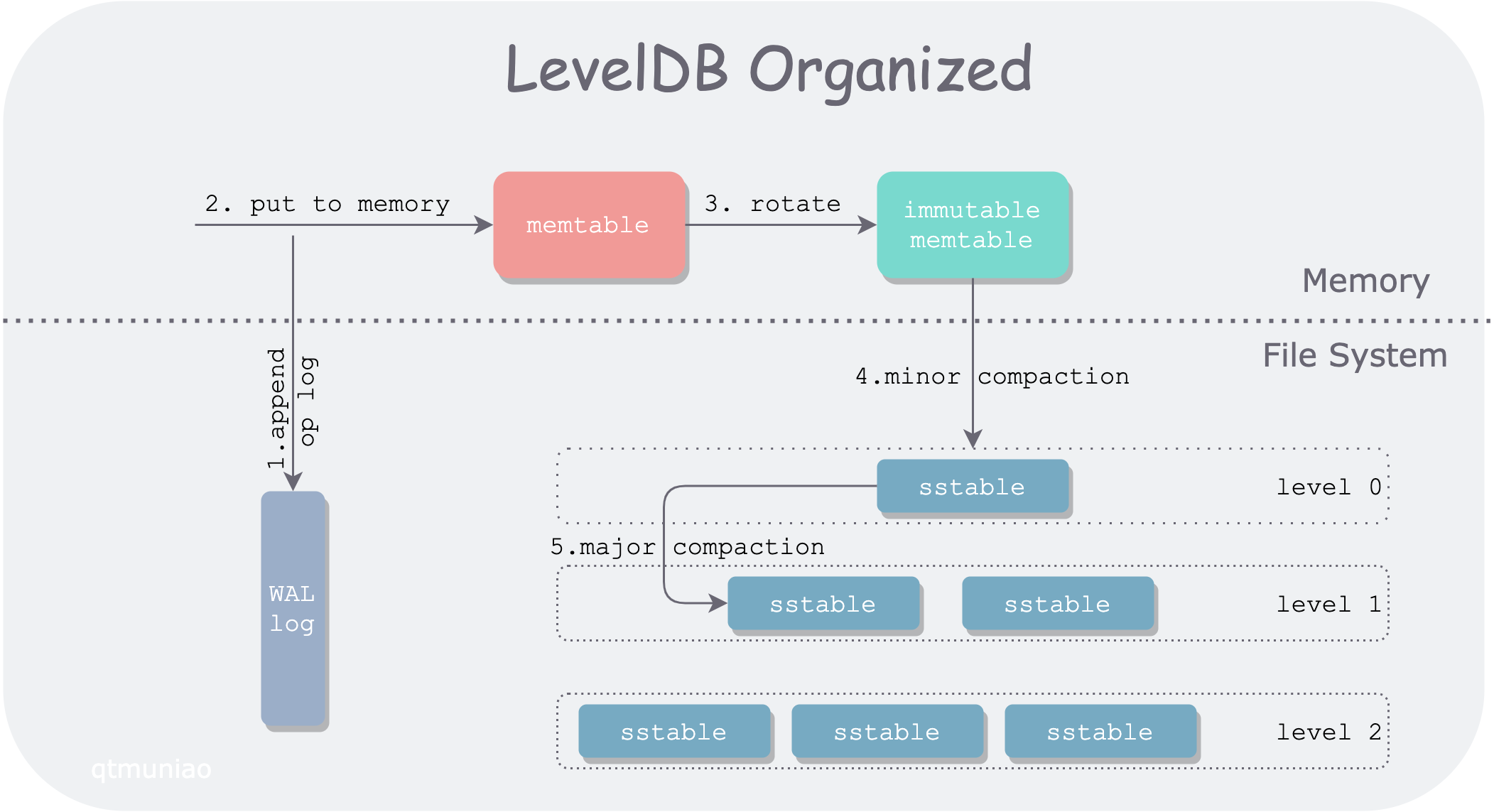
这种数据结构是 Patrick O’Neil 等人,在 1996 年提出的:The Log-Structured Merge-Tree。
Elasticsearch 和 Solr 的索引引擎 Lucene,也使用类似 LSM-Tree 存储结构。但其数据模型不是 KV,但类似:word → document list。
性能优化
如果想让一个引擎工程上可用,还会做大量的性能优化。对于 LSM-Tree 来说,包括:
优化 SSTable 的查找。常用 Bloom Filter。该数据结构可以使用较少的内存为每个 SSTable 做一些指纹,起到一些初筛的作用。
层级化组织 SSTable。以控制 Compaction 的顺序和时间。常见的有 size-tiered 和 leveled compaction。LevelDB 便是支持后者而得名。前者比较简单粗暴,后者性能更好,也因此更为常见。

对于 RocksDB 来说,工程上的优化和使用上的优化就更多了。在其 Wiki 上随便摘录几点:
- Column Family
- 前缀压缩和过滤
- 键值分离,BlobDB
但无论有多少变种和优化,LSM-Tree 的核心思想 —— 保存一组合理组织、后台合并的 SSTables —— 简约而强大。可以方便的进行范围遍历,可以变大量随机为少量顺序。
B 族树
虽然先讲的 LSM-Tree,但是它要比 B+ 树新的多。
B 树于 1970 年被 R. Bayer and E. McCreight 提出后,便迅速流行了起来。现在几乎所有的关系型数据中,它都是数据索引标准一般的实现。
与 LSM-Tree 一样,它也支持高效的点查和范围查。但却使用了完全不同的组织方式。
其特点有:
- 以页(在磁盘上叫 page,在内存中叫 block,通常为 4k)为单位进行组织。
- 页之间以页 ID 来进行逻辑引用,从而组织成一颗磁盘上的树。

查找。从根节点出发,进行二分查找,然后加载新的页到内存中,继续二分,直到命中或者到叶子节点。 查找复杂度,树的高度 —— O (lgn),影响树高度的因素:分支因子(分叉数,通常是几百个)。

插入 or 更新。和查找过程一样,定位到原 Key 所在页,插入或者更新后,将页完整写回。如果页剩余空间不够,则分裂后写入。
分裂 or 合并。级联分裂和合并。
一个记录大于一个 page 怎么办?
- 树的节点是逻辑概念,page or block 是物理概念。一个逻辑节点可以对应多个物理 page。
让 B 树更可靠
B 树不像 LSM-Tree ,会在原地修改数据文件。
在树结构调整时,可能会级联修改很多 Page。比如叶子节点分裂后,就需要写入两个新的叶子节点,和一个父节点(更新叶子指针)。
- 增加预写日志(WAL),将所有修改操作记录下来,预防宕机时中断树结构调整而产生的混乱现场。
- 使用 latch 对树结构进行并发控制。
B 树的优化
B 树出来了这么久,因此有很多优化:
- 不使用 WAL,而在写入时利用 Copy On Write 技术。同时,也方便了并发控制。如 LMDB、BoltDB。
- 对中间节点的 Key 做压缩,保留足够的路由信息即可。以此,可以节省空间,增大分支因子。
- 为了优化范围查询,有的 B 族树将叶子节点存储时物理连续。但当数据不断插入时,维护此有序性的代价非常大。
- 为叶子节点增加兄弟指针,以避免顺序遍历时的回溯。即 B+ 树的做法,但远不局限于 B+ 树。
- B 树的变种,分形树,从 LSM-tree 借鉴了一些思想以优化 seek。
B-Trees 和 LSM-Trees 对比
| 存储引擎 | B-Tree | LSM-Tree | 备注 |
| 优势 | 读取更快 | 写入更快 | |
| 写放大 | 1. 数据和 WAL 2. 更改数据时多次覆盖整个 Page | 1. 数据和 WAL 2. Compaction | SSD 不能过多擦除。因此 SSD 内部的固件中也多用日志结构来减少随机小写。 |
| 写吞吐 | 相对较低: 1. 大量随机写。 | 相对较高: 1. 较低的写放大(取决于数据和配置) 2. 顺序写入。 3. 更为紧凑。 | |
| 压缩率 | 1. 存在较多内部碎片。 | 1. 更加紧凑,没有内部碎片。 2. 压缩潜力更大(共享前缀)。 | 但紧缩不及时会造成 LSM-Tree 存在很多垃圾 |
| 后台流量 | 1. 更稳定可预测,不会受后台 compaction 突发流量影响。 | 1. 写吞吐过高,compaction 跟不上,会进一步加重读放大。 2. 由于外存总带宽有限,compaction 会影响读写吞吐。 3. 随着数据越来越多,compaction 对正常写影响越来越大。 | RocksDB 写入太过快会引起 write stall,即限制写入,以期尽快 compaction 将数据下沉。 |
| 存储放大 | 1. 有些 Page 没有用满 | 1. 同一个 Key 存多遍 | |
| 并发控制 | 1. 同一个 Key 只存在一个地方 2. 树结构容易加范围锁。 | 同一个 Key 会存多遍,一般使用 MVCC 进行控制。 |
相关文章:
数据密集型应用存储与检索设计
本文内容翻译自《数据密集型应用系统设计》,豆瓣评分高达 9.7 分。 什么是「数据密集型应用系统」? 当数据(数据量、数据复杂度、数据变化速度)是一个应用的主要挑战,那么可以把这个应用称为数据密集型的。与之相对的是…...
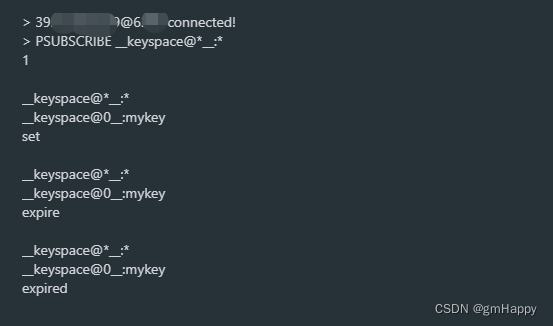
Spring Boot集成Redis实现keyspace监听 | Spring Cloud 34
一、前言 在前面我们通过以下章节对Redis的keyevent(键事件通知)使用有了基础的了解: Spring Boot集成Redis实现keyevent监听 | Spring Cloud 33 现在开始我们正式学习Redis的keyspace(键空间通知),在本…...
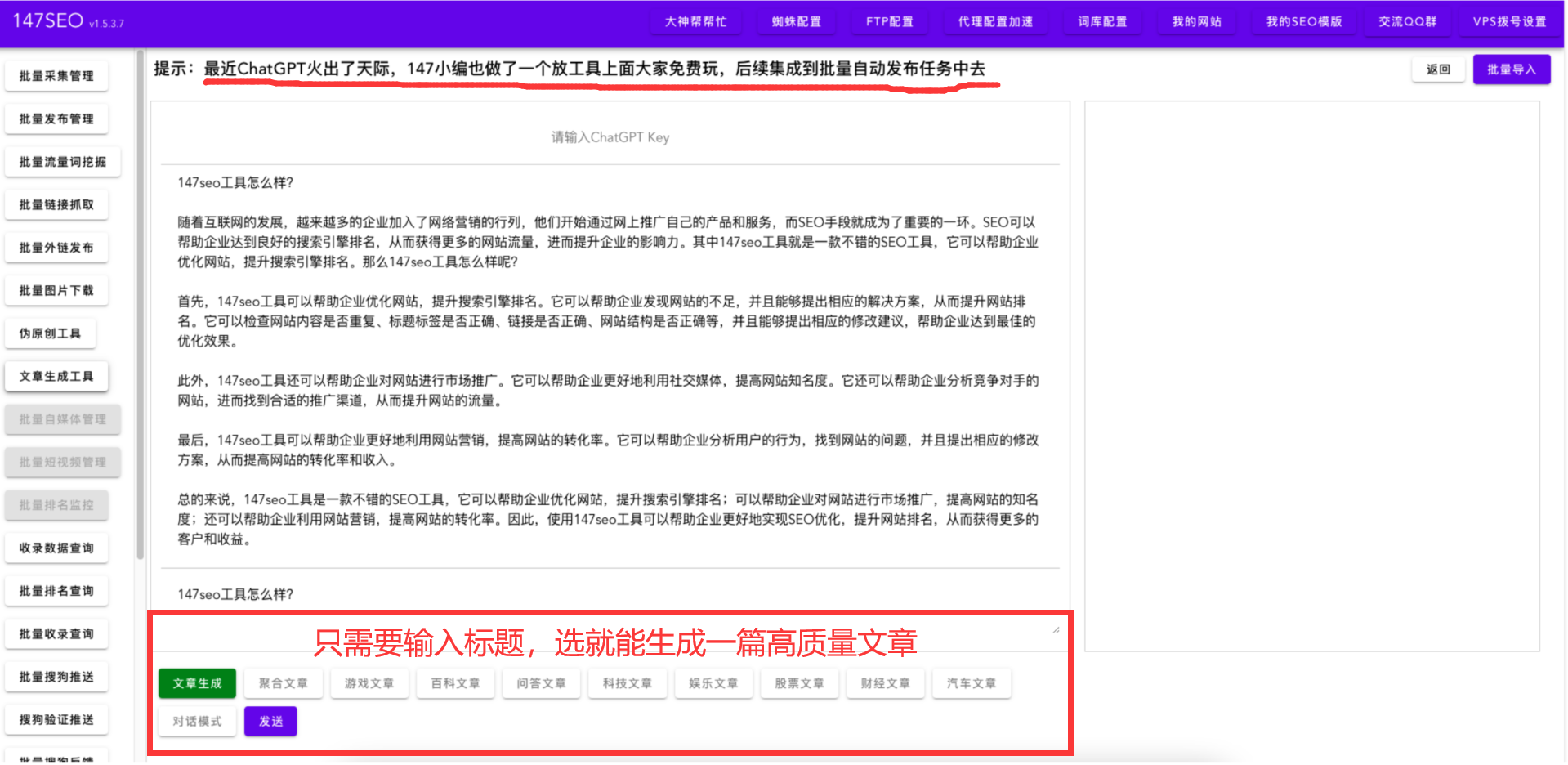
如何搭建chatGPT4.0模型-国内如何用chatGPT4.0
国内如何用chatGPT4.0 在国内,目前可以通过以下途径使用 OpenAI 的 ChatGPT 4.0: 自己搭建模型:如果您具备一定的技术能力,可以通过下载预训练模型和相关的开发工具包,自行搭建 ChatGPT 4.0 模型。OpenAI提供了相关的…...
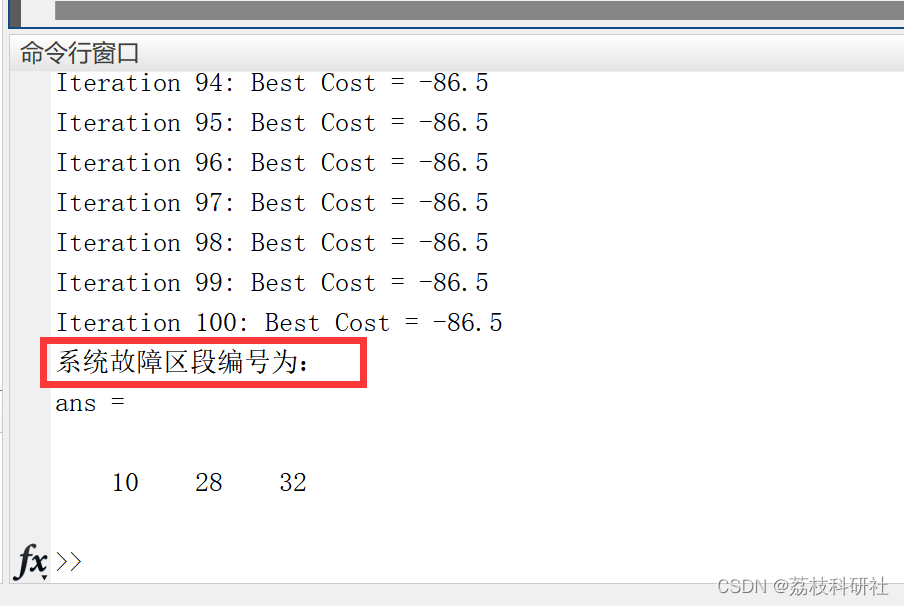
【故障定位】基于多元宇宙算法的主动配电网故障定位方法研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
基于html+css的自适应展示1
准备项目 项目开发工具 Visual Studio Code 1.44.2 版本: 1.44.2 提交: ff915844119ce9485abfe8aa9076ec76b5300ddd 日期: 2020-04-16T16:36:23.138Z Electron: 7.1.11 Chrome: 78.0.3904.130 Node.js: 12.8.1 V8: 7.8.279.23-electron.0 OS: Windows_NT x64 10.0.19044 项目…...

DolphinDB +Python Airflow 高效实现数据清洗
DolphinDB 作为一款高性能时序数据库,其在实际生产环境中常有数据的清洗、装换以及加载等需求,而对于该如何结构化管理好 ETL 作业,Airflow 提供了一种很好的思路。本篇教程为生产环境中 ETL 实践需求提供了一个解决方案,将 Pytho…...

pip3 升级软件包时遇到超时错误解决方法
如果你在使用 pip3 升级软件包时遇到超时错误,可能是因为下载速度缓慢或网络不稳定。以下是解决方法: 更改 pip3 源:你可以切换到其他 pip3 源,例如清华、阿里等等,以提高下载速度。 pip3 install -i https://pypi.tun…...

Linux环境开机自启动
1.制作服务 在/etc/systemd/system/路径下创建kkFile.service文件 cd /etc/systemd/system/ vim kkFile.service2.写入如下内容 [Unit] DescriptionkkFile service [Service] Typeforking ExecStart/sinosoft/yjya/kkFileView-4.0.0/bin/startup.sh [Install] WantedBymulti…...

字节8年测试经验,送给想要学习自动化测试的同学6条建议
我的职业生涯开始和大多数测试人一样,开始接触都是纯功能界面测试。那时候在一家电商公司做测试,做了有一段时间,熟悉产品的业务流程以及熟练测试工作流程规范之后,效率提高了,工作比较轻松,也得到了更好的…...
快速搭建springboot websocket客户端
一、前言WebSocket 是 HTML5 开始提供的一种在单个 TCP 连接上进行全双工通讯的协议。HTML5 定义的 WebSocket 协议,能更好的节省服务器资源和带宽,并且能够更实时地进行通讯。HTML5 定义的 WebSocket 协议,能更好的节省服务器资源和带宽&…...

Python 操作 MongoDB 详解
嗨害大家好鸭!我是芝士❤ 一、前言 MongoDB属于 NoSQL(非关系型数据库), 是一个基于分布式文件存储的开源数据库系统。 二、操作 MongoDB 1. 安装 pymongo python 使用第三方库来连接操作 MongoDB, 所以我们首先安…...

虹科案例 | 丝芙兰xDomo:全球美妆巨头商业智能新玩法
全球美妆行业的佼佼者丝芙兰,其走向成功绝非仅依靠品牌知名度和营销手段。身为数据驱动型企业,2018年以来,丝芙兰就率先在行业内采用虹科提供的Domo商业智能进行数据分析和决策,并首先享受了运营优化、效率提升所带来的商业价值。…...

10种优雅的MyBatis写法,同事用了都说好
用来循环容器的标签forEach,查看例子 foreach元素的属性主要有item,index,collection,open,separator,close。 item:集合中元素迭代时的别名, index:集合中元素迭代时的索引 open…...
SQL删除记录方式汇总
大家好,我是RecordLiu! 今天给大家分享的是SQL中删除记录的不同方式,我会用几道真题来给大家讲解。 题目直达链接: 牛客网在线SQL编程练习 切换到SQL篇就能看到了。 我这里先列下知识点: SQL中进行简单删除的语法是什么?SQL…...

用in函数嵌入子查询作为条件时查出结果为空
用in函数嵌入子查询作为条件时查出结果为空 问题: SELECT * FROM SGGCDB_VIEW sv WHERE RES_ID IN (SELECT urrv.RES_ID FROM IBPS_ERP.USER_ROLE_RES_VIEW urrv WHERE urrv.ID_ 1069978138403930112 )结果未空值。 原因: 首先,SELECT u…...
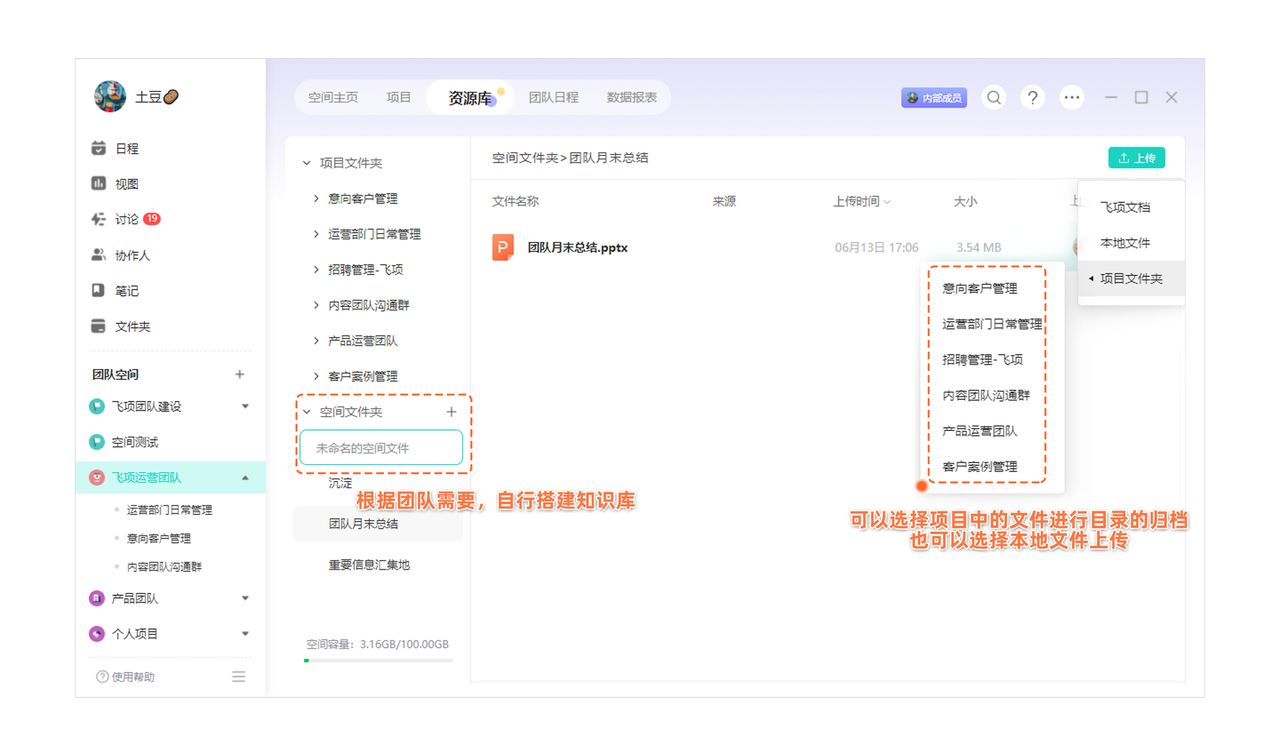
电商行业如何利用飞项解决跨部门协作难题
在电商行业中,跨部门合作是最常见的事。从产品方案到设计方案,从市场定价到销售策略,从采购需求到成本清单……在电商新品研发到正式售卖的过程中,存在着大量跨部门协作与逆向流程,但任务零碎、沟通难、进度难同步、文…...
全网最详细,Jmeter性能测试-性能基础详解,参数化函数取值(二)
目录:导读前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜)前言 参数化详解 Jmeter中…...
选择排序的简单理解
详细描述 选择排序的工作原理是:首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾…...

使用js封装一个循环链表
直接不说废话,直接上代码,这里继承了单向链表的类LinkList ,可以查看之前的文章,点这里 class Node {constructor(element) {this.element element;this.next null;} }class CirularLinkedList extends LinkList {constructor(…...
NumPy 秘籍中文第二版:二、高级索引和数组概念
原文:NumPy Cookbook - Second Edition 协议:CC BY-NC-SA 4.0 译者:飞龙 在本章中,我们将介绍以下秘籍: 安装 SciPy安装 PIL调整图像大小比较视图和副本翻转 Lena花式索引位置列表索引布尔值索引数独的步幅技巧广播数…...
)
用Python复现FAST天眼数学建模:从坐标变换到促动器伸缩量计算(附完整代码)
用Python复现FAST天眼数学建模:从坐标变换到促动器伸缩量计算(附完整代码) 中国天眼FAST作为全球最大单口径射电望远镜,其主动反射面调节系统堪称现代工程奇迹。当观测不同方位天体时,需要通过促动器精确控制4450块反射…...

3分钟上手RePKG:轻松提取Wallpaper Engine壁纸资源的终极指南
3分钟上手RePKG:轻松提取Wallpaper Engine壁纸资源的终极指南 【免费下载链接】repkg Wallpaper engine PKG extractor/TEX to image converter 项目地址: https://gitcode.com/gh_mirrors/re/repkg 你是否曾经遇到过这样的困扰?在Wallpaper Engi…...

激光切割外壳设计全流程:从创客工具到产品级制造的实战指南
1. 项目概述:为什么选择激光切割来做外壳?如果你和我一样,捣鼓过不少电子项目,从简单的Arduino温湿度计到复杂的树莓派家庭服务器,那你一定为“给它们找个家”这件事头疼过。3D打印太慢,开模注塑成本又高得…...

AI Agent产品经理的新思维:从功能设计到AI原生产品的方法论转型
AI Agent产品经理的新思维:从功能设计到AI原生产品的方法论转型 各位产品同行、AI从业者,大家好!我是连续3年深耕AI工具Agent产品、从C端信息流(今日头条/抖音生态)PM成功转型AI原生垂直工具PM的张小白——过去两年&am…...

解锁Midjourney V6黑白摄影隐藏指令:5个未公开--stylize与--sref协同技法,92%用户至今不会用
更多请点击: https://intelliparadigm.com 第一章:Midjourney V6黑白摄影的美学本质与技术觉醒 黑白摄影在 Midjourney V6 中已超越简单的色彩剥离,成为一场基于对比度张力、纹理显影与光影叙事的深度建模重构。V6 的隐式扩散架构强化了灰阶…...

3分钟快速上手:ESP32 Arduino开发环境完整配置指南
3分钟快速上手:ESP32 Arduino开发环境完整配置指南 【免费下载链接】arduino-esp32 Arduino core for the ESP32 family of SoCs 项目地址: https://gitcode.com/GitHub_Trending/ar/arduino-esp32 想在熟悉的Arduino环境中开发强大的ESP32物联网项目吗&…...

AI赋能安全分析:hexstrike-ai项目实战与提示词工程详解
1. 项目概述:一个为安全研究而生的AI助手如果你是一名安全研究员、逆向工程师或者渗透测试人员,那么你肯定对“工具链”这个词深有体会。我们的工作台就像是一个复杂的车间,摆满了IDA Pro、Ghidra、x64dbg、Burp Suite、Wireshark……这些工具…...
)
C语言结构体:从‘学生信息管理‘到‘链表实现‘的保姆级跃迁指南(含typedef避坑)
C语言结构体:从学生信息管理到链表实现的实战进阶 在C语言的世界里,结构体就像是一个神奇的收纳盒,它能够将不同类型的数据打包成一个整体。想象一下,当你需要管理学生信息时,不再需要为姓名、学号、成绩等分别定义变量…...

Spring Kafka监听多个Topic时,如何避免消费者‘摸鱼’?聊聊Range和RoundRobin分配策略的选择
Spring Kafka多Topic监听场景下消费者分配策略深度优化 1. 问题背景:当消费者开始"摸鱼" 在分布式消息系统中,Kafka凭借其高吞吐、低延迟的特性成为众多企业的首选。然而在实际开发中,不少团队遇到过这样的尴尬场景:明明…...
)
救砖实录:河南联通B860AV2.1U变砖后,我是如何通过线刷救活的(S905LB+NAND闪存方案)
从绝望到重生:B860AV2.1U机顶盒线刷救砖全流程拆解 那天晚上十一点半,当我第七次按下机顶盒电源键却依然只看到指示灯诡异闪烁时,后背的冷汗已经浸透了T恤——这个价值四百多的联通定制设备,在我尝试刷入第三方固件后彻底变成了一…...