CV【5】:Layer normalization
系列文章目录
Normalization 系列方法(一):CV【4】:Batch normalization
Normalization 系列方法(二):CV【5】:Layer normalization
文章目录
- 系列文章目录
- 前言
- 2. Layer normalization
- 2.1. Motivation
- 2.2. Method
- 2.2.1. Standardisation
- 2.2.2. Calculation preparation
- 2.2.3. Calculation process
- 2.3. Implement with PyTorch
- 总结
前言
对于早前的 CNN 模型来说,大多使用 batch normalization 进行归一化,随着 Transformer 在计算机视觉领域掀起的热潮, layer normalization 开始被用于提升传统的 CNN 的性能,在许多工作中展现了不错的提升
本文主要是对 layer normalization 用法的总结
2. Layer normalization
2.1. Motivation
Batch Normalization 使用 mini-batch 的均值和标准差对深度神经网络的隐藏层输入进行标准化,可有效地提升训练速度
BN 的效果受制于 batch 的大小,小 batch 未必能取得预期效果
- 对于前向神经网络可以很直接地应用
BN,因为其每一层具有固定的神经元数量,可直接地存储每层网络各神经元的均值、方差统计信息以应用于模型预测 - 在
RNNs网络中,不同的 mini-batch 可能具有不同的输入序列长度(深度),比如每句话的长短都不一定相同,所有很难去使用BN,计算统计信息比较困难,而且测试序列长度不能大于最大训练序列长度
Barch Normalization 也很难应用于在线学习模型,以及小 mini-batch 的分布式模型
Layer Normalization 是针对自然语言处理领域提出的,其计算是针对每个样本进行的, 不像 BN 那样依赖 batch 内所有样本的统计量, 可以更好地用到 RNN 和流式数据上(注意,在图像处理领域中 BN 比 LN 是更有效的,但现在很多人将自然语言领域的模型用来处理图像,比如 Vision Transformer,此时还是会涉及到 LN,有关 Vision Transformer 的部分可以参考我的另外一篇 blog:CV-Model【6】:Vision Transformer)
2.2. Method
2.2.1. Standardisation
网络层的输出经过线性变换作为下层网络的输入,网络输出直接影响下层网络输入分布,这是一种协变量转移的现象。我们可以通过 固定网络层的输入分布(固定输入的均值和方差) 来降低协变量转移的影响
BN 对同一 mini-batch 中对不同特征进行标准化(纵向规范化:每一个特征都有自己的分布),受限于 batch size,难以处理动态神经网络中的变长序列的 mini-bach
RNNs 不同时间步共享权重参数,使得 RNNs 可以处理不同长度的序列,RNNs 使用 layer normalization 对不同时间步进行标准化(横向标准化:每一个时间步都有自己的分布),从而可以处理单一样本、变长序列,而且训练和测试处理方式一致
2.2.2. Calculation preparation
LN 是基于 BN 转化而来的
对于一个多层前向神经网络中的某一层 HiH_iHi,计算方式如下所示:
ail=wilThlhil+1=f(ail+bil)a_i^l = w_i^{l^T}h^l \\ h_i^{l+1} = f(a_i^l + b_i^l)ail=wilThlhil+1=f(ail+bil)
针对深度学习,存在 covariate shift 现象,因此需要通过 normalize 操作,使 HiH_iHi 层的输入拥有固定的均值和方差,以此削弱协方差偏移现象对深度网络的训练时的影响,加快网络收敛。
normalize 对 HiH_iHi 层输入进行变换,计算方式如下所示:
aˉil=gilσil(ail−μil)μil=Ex∼P(x)[ail]σil=1H∑i=1H(ail−μl)2\bar{a}_i^l = \frac{g_i^l}{\sigma_i^l}(a_i^l - \mu_i^l) \\ \mu_i^l = \mathbb{E}_{x \sim P(x)} [a_i^l] \\ \sigma_i^l = \sqrt{\frac{1}{H} \displaystyle\sum_{i=1}^H (a_i^l - \mu^l)^2}aˉil=σilgil(ail−μil)μil=Ex∼P(x)[ail]σil=H1i=1∑H(ail−μl)2
直接使用上式进行 normalize 不现实,因为需要针对整个 trainingset 来进行计算,因此,BN 通过 mini-batch 的输入样本近似的计算 normalize 中的均值和方差,因此成为 batch normalization
2.2.3. Calculation process
与 BN 不同,LN 是针对深度网络的某一层的所有神经元的输入按以下公式进行 normalize 操作
如图所示。它综合考虑一层所有维度的输入,计算该层的平均输入值和输入方差,然后用同一个规范化操作来转换各个维度的输入

对于 RNN 的每个时间步,其输入都会包含两部分,即当前的输入 xtx^{t}xt 和上一个时刻的隐藏状态 ht−1\mathbf{h}^{t-1}ht−1,记 at=Whhht−1+Wxhxt\mathbf{a}^{t}=W_{h h} h^{t-1}+W_{x h} \mathbf{x}^{t}at=Whhht−1+Wxhxt,其中,WhhW_{hh}Whh 和 WxhW_{x h}Wxh 为对应的权重矩阵,则在每一个时刻,Layer Normalization 对每一个样本都分别计算所有神经元的均值和标准差如下:

参数含义:
- at\mathbf{a}^{t}at 表示输入向量(前层网络输出加权后的向量)
- HHH 表示隐藏单元数量(
RNN层的维度)
对于标准 RNN,若当前输入为 xt\mathbf{x}^{t}xt,上一隐藏状态为 ht−1\mathbf{h}^{t-1}ht−1,则加权输入向量(非线性单元的输入)为:

对输入向量进行层标准化,再进行缩放和平移(用于恢复非线性)得标准化后的输入 y\mathbf{y}y:

将标准化后的输入传入非线性激活函数:

其中, ggg 和 bbb 为引入的自适应增益和偏置参数,其作用与 batch normalization 中的参数一样,为了保留模型的非线性能力, ggg 和 bbb 的维度均为 HHH
值得注意的是,在每个时间步,同层网络的所有隐藏单元共享均值和方差
Layer Normalization 对 ggg 和 bbb 的初始化不敏感,一般默认将 ggg 初始化为 1,将 bbb 初始化为 0
2.3. Implement with PyTorch
在 Pytorch 的 LayerNorm 类中有个 normalized_shape 参数,可以指定你要 Norm 的维度(注意,函数说明中 the last certain number of dimensions,指定的维度必须是从最后一维开始)。
比如我们的数据的 shape 是 [4,2,3][4, 2, 3][4,2,3],那么 normalized_shape 可以是 [3][3][3](最后一维上进行 Norm 处理),也可以是 [2,3][2, 3][2,3](Norm 最后两个维度),也可以是 [4,2,3][4, 2, 3][4,2,3](对整个维度进行 Norm),但不能是 [2][2][2] 或者 [4,2][4, 2][4,2],否则会报以下错误(以 normalized_shape = [2] 为例):
RuntimeError:
Given normalized_shape=[2],
expected input with shape [*, 2],
but got input of size[4, 2, 3]
提示我们传入的 normalized_shape = [2],接着系统根据我们传入的 normalized_shape 推理出期待的输入数据 shape 应该为 [∗,2][*, 2][∗,2]即最后的一个维度大小应该是 222,但我们实际传入的数据 shape 是 [4,2,3][4, 2, 3][4,2,3] 所以报错了
接着,我们再来看个示例,分别使用官方的 LN 方法和自己实现的 LN 方法进行比较:
import torch
import torch.nn as nndef layer_norm_process(feature: torch.Tensor, beta=0., gamma=1., eps=1e-5):var_mean = torch.var_mean(feature, dim=-1, unbiased=False)# 均值mean = var_mean[1]# 方差var = var_mean[0]# layer norm processfeature = (feature - mean[..., None]) / torch.sqrt(var[..., None] + eps)feature = feature * gamma + betareturn featuredef main():t = torch.rand(4, 2, 3)print(t)# 仅在最后一个维度上做norm处理norm = nn.LayerNorm(normalized_shape=t.shape[-1], eps=1e-5)# 官方layer norm处理t1 = norm(t)# 自己实现的layer norm处理t2 = layer_norm_process(t, eps=1e-5)print("t1:\n", t1)print("t2:\n", t2)if __name__ == '__main__':main()
经测试可以发现,结果是一样的
总结
参考资料1
参考资料2
相关文章:
CV【5】:Layer normalization
系列文章目录 Normalization 系列方法(一):CV【4】:Batch normalization Normalization 系列方法(二):CV【5】:Layer normalization 文章目录系列文章目录前言2. Layer normalizati…...
跳跃游戏 II 解析
题目描述给定一个长度为 n 的 0 索引整数数组 nums。初始位置为 nums[0]。每个元素 nums[i] 表示从索引 i 向前跳转的最大长度。换句话说,如果你在 nums[i] 处,你可以跳转到任意 nums[i j] 处:0 < j < nums[i] i j < n返回到达 nums[n - 1] 的…...

易基因|猪肠道组织的表观基因组功能注释增强对复杂性状和人类疾病的生物学解释:Nature子刊
大家好,这里是专注表观组学十余年,领跑多组学科研服务的易基因。2021年10月6日,《Nat Commun》杂志发表了题为“Pig genome functional annotation enhances the biological interpretation of complex traits and human disease”的研究论文…...
)
01- NumPy 数据库 (机器学习)
numpy 数据库重点: numpy的主要数据格式: ndarray 列表转化为ndarray格式: np.array() np.save(x_arr, x) # 使用save可以存一个 ndarray np.savetxt(arr.csv, arr, delimiter ,) # 存储为 txt 文件 np.array([1, 2, 5, 8, 19], dtype float32) # 转换…...

RapperBot僵尸网络最新进化:删除恶意软件后仍能访问主机
自 2022 年 6 月中旬以来,研究人员一直在跟踪一个快速发展的 IoT 僵尸网络 RapperBot。该僵尸网络大量借鉴了 Mirai 的源代码,新的样本增加了持久化的功能,保证即使在设备重新启动或者删除恶意软件后,攻击者仍然可以通过 SSH 继续…...
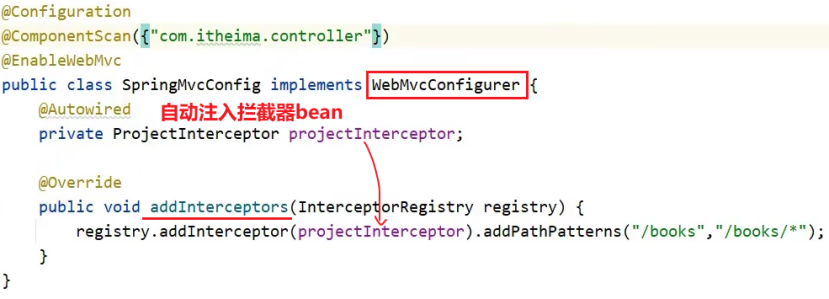
拦截器interceptor总结
拦截器一. 概念拦截器和AOP的区别:拦截器和过滤器的区别:二. 入门案例2.1 定义拦截器bean2.2 定义配置类2.3 执行流程2.4 简化配置类到SpringMvcConfig中一. 概念 引入: 消息从浏览器发送到后端,请求会先到达Tocmat服务器&#x…...
轻松实现微信小程序上传多文件/图片到腾讯云对象存储COS(免费额度)
概述 对象存储(Cloud Object Storage,COS)是腾讯云提供的一种存储海量文件的分布式存储服务,用户可通过网络随时存储和查看数据。个人账户首次开通COS可以免费领取50GB 标准存储容量包6个月(180天)的额度。…...
)
Golang中defer和return的执行顺序 + 相关测试题(面试常考)
参考文章: 【Golang】defer陷阱和执行原理 GO语言defer和return 的执行顺序 深入理解Golang defer机制,直通面试 面试富途的时候,遇到了1.2的这个进阶问题,没回答出来。这种题简直是 噩梦\color{purple}{噩梦}噩梦,…...

谁说菜鸟不会数据分析,不用Python,不用代码也轻松搞定
作为一个菜鸟,你可能觉得数据分析就是做表格的,或者觉得搞个报表很简单。实际上,当前有规模的公司任何一个岗位如果没有数据分析的思维和能力,都会被淘汰,数据驱动分析是解决日常问题的重点方式。很多时候,…...
php mysql保健品购物商城系统
目 录 1 绪论 1 1.1 开发背景 1 1.2 研究的目的和意义 1 1.3 研究现状 2 2 开发技术介绍 2 2.1 B/S体系结构 2 2.2 PHP技术 3 2.3 MYSQL数据库 4 2.4 Apache 服务器 5 2.5 WAMP 5 2.6 系统对软硬件要求 6 …...
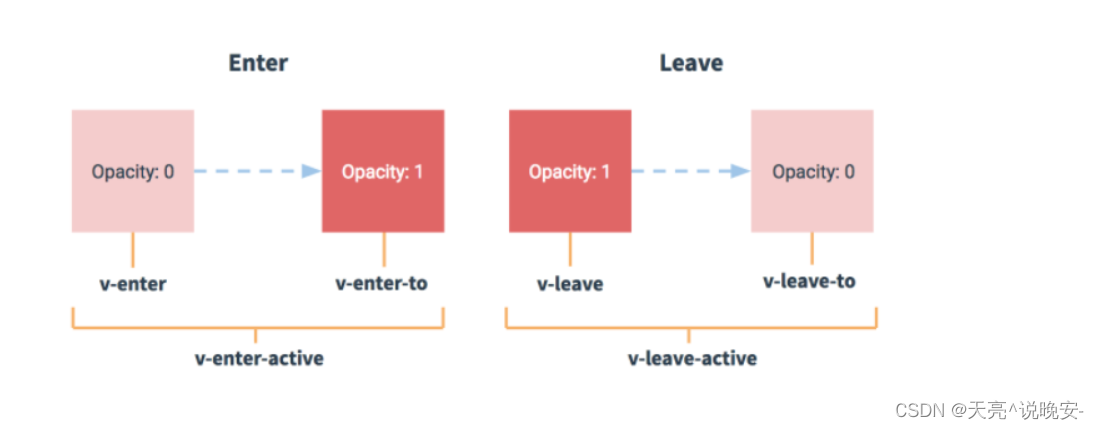
Vue3电商项目实战-首页模块6【22-首页主体-补充-vue动画、23-首页主体-面板骨架效果、4-首页主体-组件数据懒加载、25-首页主体-热门品牌】
文章目录22-首页主体-补充-vue动画23-首页主体-面板骨架效果24-首页主体-组件数据懒加载25-首页主体-热门品牌22-首页主体-补充-vue动画 目标: 知道vue中如何使用动画,知道Transition组件使用。 当vue中,显示隐藏,创建移除&#x…...

linux 使用
一、操作系统命令 1、版本命令:lsb_release -a 2、内核命令:cat /proc/version 二、debian与CentOS区别 debian德班和CentOS是Linux里两个著名的版本。两者的包管理方式不同。 debian安装软件是用apt(apt-get install),而CentOS是用yum de…...
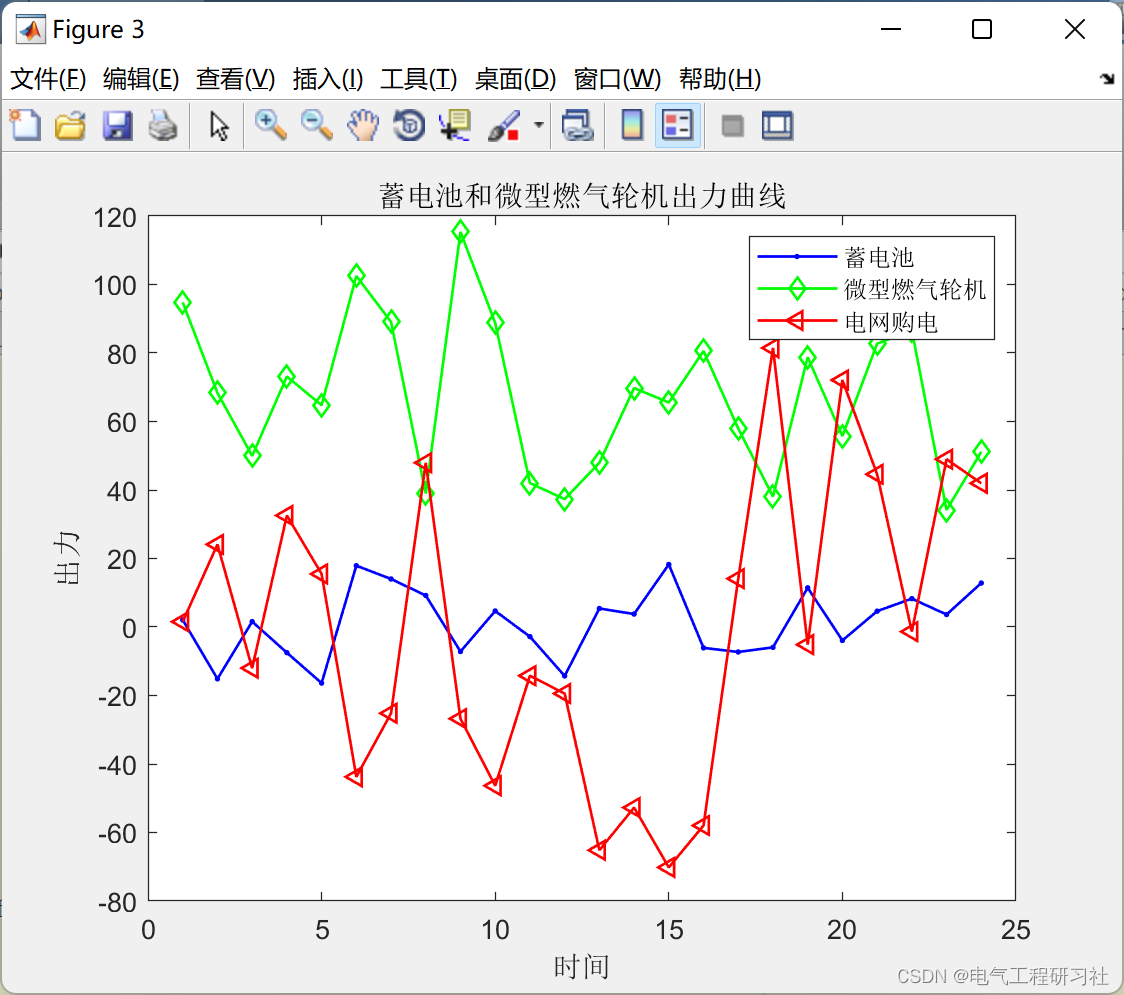
基于遗传算法的微电网调度(风、光、蓄电池、微型燃气轮机)(Matlab代码实现)
💥💥💥💞💞💞欢迎来到本博客❤️❤️❤️💥💥💥🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清…...
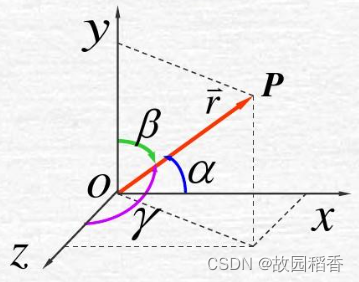
方向导数与梯度下降
文章目录方向角与方向余弦方向角方向余弦方向导数定义性质梯度下降梯度下降法(Gradient descent)是一个一阶最优化算法,通常也称为最速下降法。 要使用梯度下降法找到一个函数的局部极小值,必须向函数上当前点对应梯度(…...

Java岗面试题--Java基础(日积月累,每日三题)
目录面试题一:Java中有哪些容器(集合类)?追问:Java中的容器,线程安全和线程不安全的分别有哪些?面试题二: HashMap 的实现原理/底层数据结构? JDK1.7 和 JDK1.8追问一&am…...
java基础—Volatile关键字详解
java基础—Volatile关键字详解 文章目录java基础—Volatile关键字详解并发编程的三大特性:volatile的作用是什么volatile如何保证有可见性volatile保证可见性在JMM层面原理volatile保证可见性在CPU层面原理可见性问题的例子volatile如何保证有序性单例模式使用volat…...

内存检测工具Sanitizers
Sanitizers介绍 Sanitizers 是谷歌开源的内存检测工具,包括AddressSanitizer、MemorySanitizer、ThreadSanitizer、LeakSanitizer。 Sanitizers是LLVM的一部分。 gcc4.8:支持Address和Thread Sanitizer。 gcc4.9:支持Leak Sanitizer和UBSani…...

Triton : OpenAI 开发的用于Gpu开发语言
Triton : OpenAI 开发的用于Gpu开发语言https://openai.com/blog/triton/1、介绍 https://openai.com/blog/triton/ 2、git地址 https://github.com/openai/triton 3、论文 http://www.eecs.harvard.edu/~htk/publication/2019-mapl-tillet-kung-cox.pdf SIMD : Single Inst…...
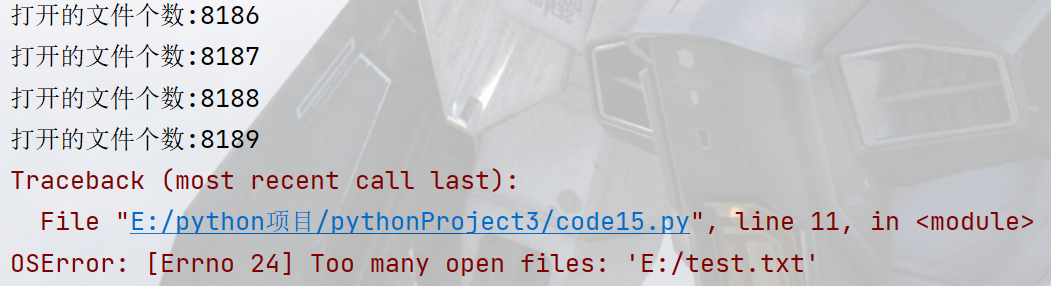
Python文件操作-代码案例
文章目录文件打开文件open写文件上下文管理器第三方库简单应用案例使用python生成二维码使用python操作excel程序员鼓励师学生管理系统文件 变量就在内存中,文件在硬盘中. 内存空间更小,访问速度快,成本贵,数据容易丢失,硬盘空间大,访问慢,偏移,持久化存储. \\在才是 \的含义…...

活动目录(Active Directory)管理,AD自动化
每个IT管理员几乎每天都在Active Directory管理中面临许多挑战,尤其是在管理Active Directory用户帐户方面。手动配置用户属性非常耗时、令人厌烦且容易出错,尤其是在大型、复杂的 Windows 网络中。Active Directory管理员和IT经理大多必须执行重复和世俗…...

SPSS数据合并避坑指南:键变量设置、缺失值处理与常见错误解析
SPSS数据合并实战避坑手册:从原理到解决方案 数据合并是SPSS分析过程中最基础也最容易出错的环节之一。许多用户在按照网络教程操作后,常常发现合并结果与预期不符——变量丢失、数据错乱、大量缺失值涌现。这些问题往往源于对合并原理的理解不足和关键细…...

从‘相似三角形’到3D点云:手把手用Python+OpenCV模拟激光三角法三维重建
从相似三角形到3D点云:PythonOpenCV激光三角法三维重建实战 激光三角测量法在工业检测、逆向工程等领域有着广泛应用。本文将带您从零开始,用Python和OpenCV实现一个完整的激光三角法三维重建系统。不同于简单的位移测量,我们将重点放在如何通…...

英雄联盟智能助手League Akari:重新定义你的游戏体验边界
英雄联盟智能助手League Akari:重新定义你的游戏体验边界 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 在英雄联盟的竞技世界中&…...
)
别再硬算公式了!用Excel搞定STM32 NTC测温的ADC查表法(附完整表格)
用Excel玩转STM32 NTC测温:查表法实战指南 嵌入式开发中,温度测量是个永恒的话题。NTC热敏电阻因其成本低廉、响应迅速,成为工程师们的首选传感器。但每次项目都要重新推导温度计算公式,不仅耗时费力,还容易在数学转换…...

从模型训练到推理服务全链路编排,SITS 2026定义的K8s for ML新标准:为什么92%的MLOps团队将在Q3前强制升级?
更多请点击: https://intelliparadigm.com 第一章:AI原生Kubernetes编排:SITS 2026 K8s for ML工作负载 SITS 2026 引入了专为机器学习工作负载深度优化的 AI 原生 Kubernetes 控制平面,其核心在于将训练任务生命周期、弹性资源调…...

GPT-5.5批量生成的Prompt工程,别再让模糊指令变成Token烧金窟
在技术领域,我们常常被那些闪耀的、可见的成果所吸引。今天,这个焦点无疑是大语言模型技术。它们的流畅对话、惊人的创造力,让我们得以一窥未来的轮廓。然而,作为在企业一线构建、部署和维护复杂系统的实践者,我们深知…...

从编码器线数到电子齿轮比:一份给PLC编程员的伺服电机脉冲计算避坑指南
从编码器线数到电子齿轮比:PLC工程师的伺服电机脉冲计算实战手册 在工业自动化领域,伺服系统的精确定位控制一直是工程师面临的核心挑战。当机械臂需要以0.001mm的精度进行装配,或是数控机床要完成微米级的切削时,脉冲计算的准确…...

ExplorerPatcher:三分钟打造你的专属Windows界面
ExplorerPatcher:三分钟打造你的专属Windows界面 【免费下载链接】ExplorerPatcher This project aims to enhance the working environment on Windows 项目地址: https://gitcode.com/GitHub_Trending/ex/ExplorerPatcher 还在为Windows 11的新界面感到困扰…...

CoverM深度解析:如何高效配置PacBio HiFi宏基因组数据覆盖率分析的完整指南
CoverM深度解析:如何高效配置PacBio HiFi宏基因组数据覆盖率分析的完整指南 【免费下载链接】CoverM Read alignment statistics for metagenomics 项目地址: https://gitcode.com/gh_mirrors/co/CoverM CoverM作为一款专业的宏基因组读长覆盖率计算工具&…...

ChatGPT 2023年3月14日更新解读:GPT-4接入Plus,正式进入GPT-4时代
🔥个人主页:杨利杰YJlio❄️个人专栏:《Sysinternals实战教程》《Windows PowerShell 实战》《WINDOWS教程》《IOS教程》《微信助手》《锤子助手》 《Python》 《Kali Linux》 《那些年未解决的Windows疑难杂症》🌟 让复杂的事情更…...