大数据开发必备面试题Spark篇01
1、Hadoop 和 Spark 的相同点和不同点?
Hadoop 底层使用 MapReduce 计算架构,只有 map 和 reduce 两种操作,表达能力比较欠缺,而且在 MR 过程中会重复的读写 hdfs,造成大量的磁盘 io 读写操作,所以适合高时延环境下批处理计算的应用;
Spark 是基于内存的分布式计算架构,提供更加丰富的数据集操作类型,主要分成转化操作和行动操作,包括 map、reduce、filter、flatmap、groupbykey、reducebykey、union 和 join 等,数据分析更加快速,所以适合低时延环境下计算的应用;
Spark 与 hadoop 最大的区别在于迭代式计算模型。基于 mapreduce 框架的Hadoop 主要分为 map 和 reduce 两个阶段,两个阶段完了就结束了,所以在一个 job 里面能做的处理很有限;Spark 计算模型是基于内存的迭代式计算模型,可以分为 n 个阶段,根据用户编写的 RDD 算子和程序,在处理完一个阶段后可以继续往下处理很多个阶段,而不只是两个阶段。所以 Spark 相较于mapreduce,计算模型更加灵活,可以提供更强大的功能。
但是 Spark 也有劣势,由于 Spark 基于内存进行计算,虽然开发容易,但是真正面对大数据的时候,在没有进行调优的情况下,可能会出现各种各样的问题,比如 OOM 内存溢出等情况,导致 Spark程序可能无法运行起来,而 mapreduce虽然运行缓慢,但是至少可以慢慢运行完。
2、Hadoop 和 Spark 使用场景?
Hadoop/MapReduce 和 Spark 最适合的都是做离线型的数据分析,但 Hadoop 特别适合是单次分析的数据量“很大”的情景,而 Spark 则适用于数据量不是很大的情景。
(1) 一般情况下,对于中小互联网和企业级的大数据应用而言,单次分析的数量都不会“很大”,因此可以优先考虑使用 Spark。
(2)业务通常认为 Spark 更适用于机器学习之类的“迭代式”应用,80GB 的压缩数据(解压后超过 200GB),10 个节点的集群规模,跑类似“sum+group-by”的应用,MapReduce 花了 5 分钟,而 spark 只需要 2分钟。
3、Spark 如何保证宕机迅速恢复?
(1)适当增加 spark standby master;
(2)编写 shell 脚本,定期检测 master 状态,出现宕机后对 master 进行重启操作。
4、Spark 有哪些组件?
(1)master:管理集群和节点,不参与计算;
(2)worker:计算节点,进程本身不参与计算,和 master 汇报;
(3)Driver:运行程序的 main 方法,创建 spark context 对象;
(4)spark context:控制整个 application 的生命周期,包括 dagsheduler 和 taskscheduler 等组件;
(5)client:用户提交程序的入口。
5、简述下Spark的运行流程。
(1)SparkContext 向资源管理器注册并向资源管理器申请运行 Executor;
(2) 资源管理器分配 Executor,然后资源管理器启动 Executor;
(3)Executor 发送心跳至资源管理器;
(4)SparkContext 构建 DAG 有向无环图;
(5)将 DAG 分解成 Stage(TaskSet);
(6)把 Stage 发送给 TaskScheduler;
(7)Executor 向 SparkContext 申请 Task;
(8)TaskScheduler 将 Task 发送给 Executor 运行;
(9)同时 SparkContext 将应用程序代码发放给 Executor;
(10)Task 在 Executor 上运行,运行完毕释放所有资源。
6、简述下Spark 中的 RDD 机制。
RDD分布式弹性数据集,简单的理解成一种数据结构,是 spark 框架上的通用货币。所有算子都是基于 RDD来执行的,不同的场景会有不同的 RDD实现类,但是都可以进行互相转换。RDD 执行过程中会形成 dag 图,然后形成 lineage 保证容错性等。从物理的角度来看 RDD 存储的是 block 和 node 之间的映射。
RDD 是 spark 提供的核心抽象,全称为弹性分布式数据集。
RDD 在逻辑上是一个 hdfs 文件,在抽象上是一种元素集合,包含了数据。它是被分区的,分为多个分区,每个分区分布在集群中的不同结点上,从而让 RDD中的数据可以被并行操作(分布式数据集)。
7、 RDD 中 reduceBykey 与 groupByKey 哪个性能好,为什么?
(1)reduceByKey:reduceByKey 会在结果发送至 reducer 之前会对每个 mapper 在本地进行 merge,有点类似于在 MapReduce 中的 combiner。这样做的好处在于,在 map 端进行一次 reduce 之后,数据量会大幅度减小,从而减小传输,保证reduce 端能够更快的进行结果计算。
(2)groupByKey:groupByKey 会对每一个 RDD 中的 value 值进行聚合形成一个序列(Iterator),此操作发生在 reduce 端,所以势必会将所有的数据通过网络进行传输,造成不必要的浪费。同时如果数据量十分大,可能还会造成 OutOfMemoryError。所以在进行大量数据的 reduce 操作时候建议使用 reduceByKey。不仅可以提高速度,还可以防止使用 groupByKey 造成的内存溢出问题。
8、简述下cogroup RDD 实现原理。
(1)cogroup:对多个(2~4)RDD 中的 KV 元素,每个 RDD 中相同 key 中的元素分别聚合成一个集合。
(2)与 reduceByKey 不同的是:reduceByKey 针对一个 RDD 中相同的 key 进行合并。而 cogroup 针对多个 RDD 中相同的 key 的元素进行合并。
(3)cogroup 的函数实现:这个实现根据要进行合并的两个 RDD 操作,生成一个CoGroupedRDD 的实例,这个 RDD 的返回结果是把相同的 key 中两个 RDD分别进行合并操作,最后返回的 RDD 的 value 是一个 Pair 的实例,这个实例包含两个 Iterable 的值,第一个值表示的是 RDD1 中相同 KEY 的值,第二个值表示的是 RDD2 中相同 key 的值。
(4)由于做 cogroup 的操作,需要通过 partitioner 进行重新分区的操作,因此,执行这个流程时,需要执行一次 shuffle 的操作(如果要进行合并的两个 RDD 的都已经是 shuffle 后的 RDD,同时他们对应的 partitioner 相同时,就不需要执行shuffle)。
9、在哪里用过cogroup RDD 。
表关联查询或者处理重复的 key。
10、如何区分 RDD 的宽窄依赖?
(1)窄依赖:父 RDD 的一个分区只会被子 RDD 的一个分区依赖;
(2)宽依赖:父 RDD 的一个分区会被子 RDD 的多个分区依赖(涉及到 shuffle)。
11、为什么要设计宽窄依赖?
(1)窄依赖:
A、窄依赖的多个分区可以并行计算;
B、窄依赖的一个分区的数据如果丢失只需要重新计算对应的分区的数据就可以了。
(2)宽依赖:
划分 Stage(阶段)的依据:对于宽依赖,必须等到上一阶段计算完成才能计算下一阶段。
12、简述下DAG。
DAG(Directed Acyclic Graph 有向无环图)指的是数据转换执行的过程,有方向,无闭环(其实就是 RDD 执行的流程);
原始的 RDD 通过一系列的转换操作就形成了 DAG 有向无环图,任务执行时,可以按照 DAG 的描述,执行真正的计算(数据被操作的一个过程)。
13、DAG 中为什么要划分 Stage?
为了实现并行计算。
一个复杂的业务逻辑如果有 shuffle,那么就意味着前面阶段产生结果后,才能执行下一个阶段,即下一个阶段的计算要依赖上一个阶段的数据。那么我们按照shuffle 进行划分(也就是按照宽依赖就行划分),就可以将一个 DAG 划分成多个Stage/阶段,在同一个 Stage 中,会有多个算子操作,可以形成一个 pipeline 流水线,流水线内的多个平行的分区可以并行执行。
14、如何划分 DAG 的 stage?
(1)对于窄依赖,partition 的转换处理在 stage 中完成计算,不划分(将窄依赖尽量放在在同一个 stage 中,可以实现流水线计算)。
(2)对于宽依赖,由于有 shuffle 的存在,只能在父 RDD 处理完成后,才能开始接下来的计算,也就是说需要要划分 stage。
15、简述下DAG 划分 Stage 的算法。
核心算法:回溯算法。
从后往前回溯/反向解析,遇到窄依赖加入本 Stage,遇见宽依赖进行 Stage 切分。Spark 内核会从触发 Action 操作的那个 RDD 开始从后往前推,首先会为最后一个 RDD 创建一个 Stage,然后继续倒推,如果发现对某个 RDD 是宽依赖,那么就会将宽依赖的那个 RDD 创建一个新的 Stage,那个 RDD 就是新的Stage 的最后一个 RDD。 然后依次类推,继续倒推,根据窄依赖或者宽依赖进行 Stage 的划分,直到所有的 RDD 全部遍历完成为止。
16、 如何解决Spark 中的数据倾斜问题?
前提是定位数据倾斜,是 OOM 了,还是任务执行缓慢,看日志,看 WebUI。
(1)避免不必要的 shuffle,如使用广播小表的方式,将 reduce-side-join 提升为 map-side-join;
(2)分拆发生数据倾斜的记录,分成几个部分进行,然后合并 join 后的结果;
(3)改变并行度,可能并行度太少了,导致个别 task 数据压力大;
(4)两阶段聚合,先局部聚合,再全局聚合;
(5)自定义 paritioner,分散 key 的分布,使其更加均匀。
17、简述下Spark 中的 OOM 问题。
(1)map 类型的算子执行中内存溢出如 flatMap,mapPatitions。
原因:map 端过程产生大量对象导致内存溢出;这种溢出的原因是在单个 map 中产生了大量的对象导致的针对这种问题。
解决方案:
A、增加堆内内存。
B、在不增加内存的情况下,可以减少每个 Task 处理数据量,使每个 Task产生大量的对象时,Executor 的内存也能够装得下。具体做法可以在会产生大量对象的 map 操作之前调用 repartition 方法,分区成更小的块传入map。
(2)shuffle 后内存溢出如 join,reduceByKey,repartition。
shuffle 内存溢出的情况可以说都是 shuffle 后,单个文件过大导致的。在shuffle 的使用,需要传入一个 partitioner,大部分 Spark 中的 shuffle 操作,默认的 partitioner 都是 HashPatitioner,默认值是父 RDD 中最大的分区数.这个参数 spark.default.parallelism 只对 HashPartitioner 有效.如果是别的 partitioner 导致的 shuffle 内存溢出就需要重写 partitioner 代码了。
(3)driver 内存溢出。
A、 用户在 Dirver 端口生成大对象,比如创建了一个大的集合数据结构。解决方案:将大对象转换成 Executor 端加载,比如调用 sc.textfile 或者评估大对象占用的内存,增加 dirver 端的内存
B、从 Executor 端收集数据(collect)回 Dirver 端,建议将 driver 端对 collect回来的数据所作的操作,转换成 executor 端 rdd 操作。
18、Spark 中数据的位置是被谁管理的?
每个数据分片都对应具体物理位置,数据的位置是被 blockManager 管理,无论数据是在磁盘,内存还是 tacyan,都是由 blockManager 管理。
19、Spaek 程序执行,有时候默认为什么会产生很多 task,怎么修改默认 task 执行个数?
(1)输入数据有很多 task,尤其是有很多小文件的时候,有多少个输入 block就会有多少个 task 启动;
(2)spark 中有 partition 的概念,每个 partition 都会对应一个 task,task 越多,在处理大规模数据的时候,就会越有效率。不过 task 并不是越多越好,如果平时测试,或者数据量没有那么大,则没有必要 task 数量太多。
(3)参数可以通过 spark_home/conf/spark-default.conf 配置文件设置:
A、针对 spark sql 的 task 数量:spark.sql.shuffle.partitions=50;
B、非 spark sql 程序设置生效:spark.default.parallelism=10。
20、介绍一下 join 操作优化经验?
join 其实常见的就分为两类: map-side join 和 reduce-side join。
当大表和小表 join 时,用 map-side join 能显著提高效率。
将多份数据进行关联是数据处理过程中非常普遍的用法,不过在分布式计算系统中,这个问题往往会变的非常麻烦,因为框架提供的 join 操作一般会将所有数据根据 key 发送到所有的 reduce 分区中去,也就是 shuffle 的过程。造成大量的网络以及磁盘 IO 消耗,运行效率极其低下,这个过程一般被称为reduce-side-join。
如果其中有张表较小的话,我们则可以自己实现在 map 端实现数据关联,跳过大量数据进行 shuffle 的过程,运行时间得到大量缩短,根据不同数据可能会有几倍到数十倍的性能提升。
在大数据量的情况下,join 是一中非常昂贵的操作,需要在 join 之前应尽可能的先缩小数据量。
对于缩小数据量,有以下几条建议:
(1) 若两个 RDD 都有重复的 key,join 操作会使得数据量会急剧的扩大。所有,最好先使用 distinct 或者 combineByKey 操作来减少 key 空间或者用 cogroup 来处理重复的 key,而不是产生所有的交叉结果。在 combine时,进行机智的分区,可以避免第二次 shuffle。
(2)如果只在一个 RDD 出现,那你将在无意中丢失你的数据。所以使用外连接会更加安全,这样你就能确保左边的 RDD 或者右边的 RDD 的数据完整性,在 join 之后再过滤数据。
(3) 如果我们容易得到 RDD 的可以的有用的子集合,那么我们可以先用filter 或者 reduce,如何在再用 join。
相关文章:

大数据开发必备面试题Spark篇01
1、Hadoop 和 Spark 的相同点和不同点? Hadoop 底层使用 MapReduce 计算架构,只有 map 和 reduce 两种操作,表达能力比较欠缺,而且在 MR 过程中会重复的读写 hdfs,造成大量的磁盘 io 读写操作,所以适合高时…...
SpringBoot整合xxl-job详细教程
SrpingBoot整合xxl-job,实现任务调度说明调度中心执行器调试整合SpringBoot说明 Xxl-Job是一个轻量级分布式任务调度平台,其核心设计目标是开发迅速、学习简单、轻量级、易扩展。现已开放源代码并接入多家公司线上产品线,开箱即用。Xxl-Job有…...
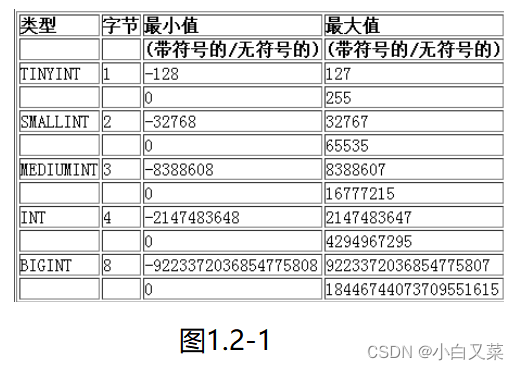
【MySQL--04】数据类型
文章目录1.数据类型1.1数据类型分类1.2数值类型1.2.1tinyint类型1.2.2bit类型1.2.3小数类型1.2.3.1 float1.2.3.2 decimal1.3字符串类型1.3.1 char1.3.2 varchar1.3.3char和varchar的比较1.4日期和时间类型1.5 enum和set1.5.1 enum1.5.2 set1.5.3 示例1.数据类型 1.1数据类型分…...

git 将其它分支的文件检出到工作区
主要是使用如下命令: git checkout [-f|--ours|--theirs|-m|--conflict<style>] [<tree-ish>] [--] <pathspec>…覆盖与 pathspec 匹配的文件的内容。当没有给出<tree-ish> (通常是一个commit)时,用 index 中的内容覆盖工作树…...

人工智能的最大危险是什么?
作者:GPT(AI智学习) 链接:https://www.zhihu.com/question/592107303/answer/2966857095 来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 首先:人工智能为人类带来了很多益处&…...
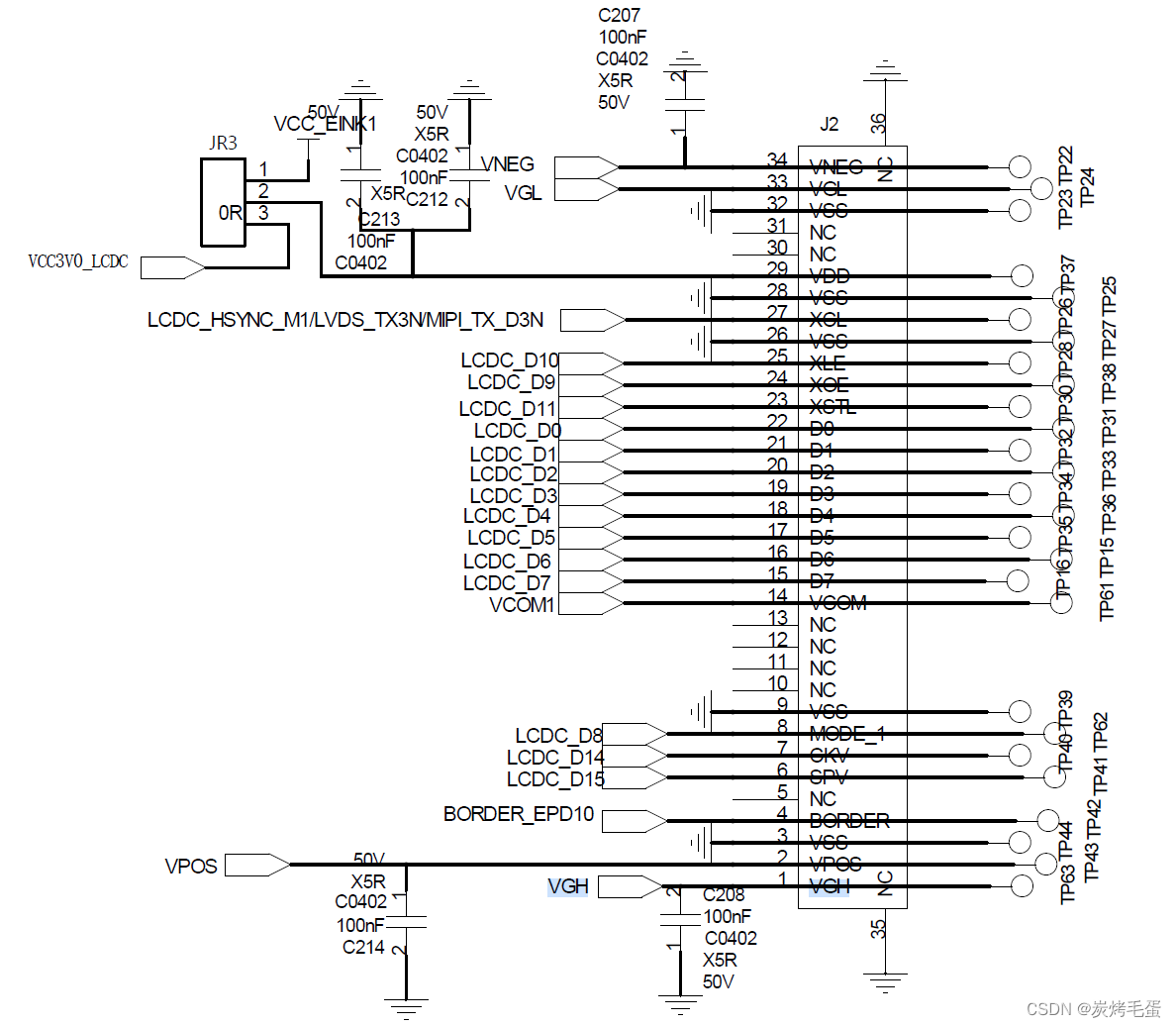
rk3568点亮E-ink
rk3568 Android11/12 适配 E-ink “EINK”是英语ElectronicInk的缩写。翻译成中文为“电子墨水”。电子墨水由数百万个微胶囊(Microcapsules)所构成,微胶囊的大小约等同于人类头发的直径。每个微胶囊里含有电泳粒子──带负电荷的白色以及带正电荷的黑色粒子&#…...
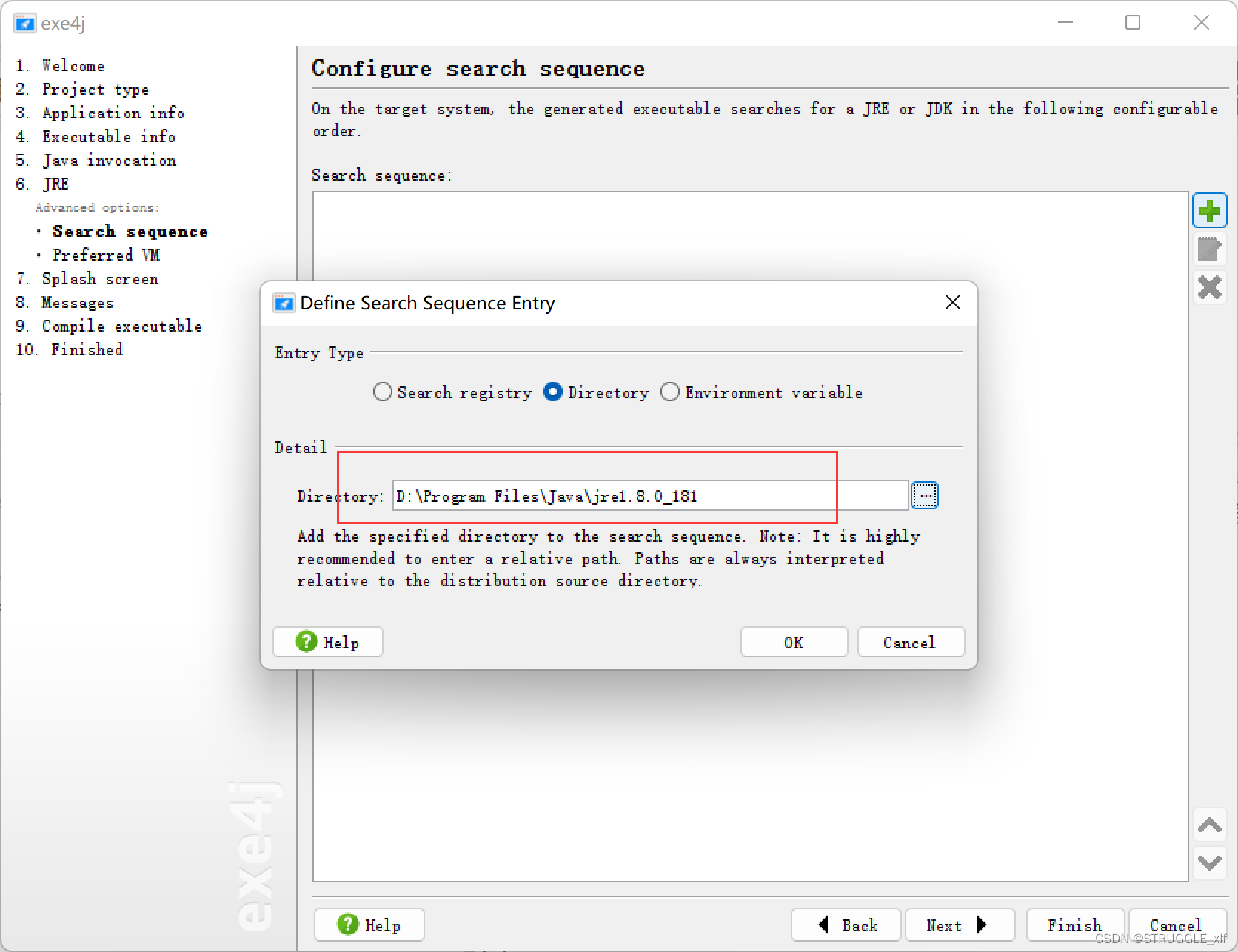
如何将Springboot项目通过IDEA打包成jar包,并且转换成可执行文件
首先在IDEA打开你的项目,需要确认项目可以正常运行,然后点击页面右侧的Maven,运行Lifecycle下的package, 此时在项目的target目录下就可以看到一个jar包 这个时候你可以在jar包所在目录下执行cmd窗口,运行 java -jar campus-market-0.0.1-S…...

总结:网卡
一、背景 经常听到eth0,bond0这些概念,好奇他们的区别,于是有了此篇文章记录下。 二、介绍 网卡:即网络接口板,又称网络适配器或NIC (网络接口控制器),是一块被设计用来允许计算机在计算机网络上进行通讯…...

Java这么卷,还有前景吗?
“Java很卷”、“大家不要再卷Java了”,经常听到同学这样抱怨。但同时,Java的高薪也在吸引越来越多的同学。不少同学开始疑惑:既然Java这么卷,还值得我入行吗? 首先先给你吃一颗定心丸:现在选择Java依然有…...
--gocron)
后端简易定时任务框架选择(Python/Go)--gocron
文章目录前言实现后语前言 在使用Python的web框架中,包括flask/Django,其中大量用到celery;celery作为异步任务使用的多,同时也会用celery来跑些定时任务,比如每晚定时跑脚本、跑数据统计等闲时任务。但随着任务量的增…...

【GStreamer学习】之GStreamer基础教程
目标 没有什么比在屏幕上打印出“Hello World”更能获得对软件库的第一印象了! 但是由于我们正在学习多媒体框架,所以我们将输出“Hello World!”改为播放视频。 不要被下面的代码量吓到:只有 4 行是真正需要的, 其…...

各类Round-Robin总结,含Verilog实现
1. Fixed Priority Arbitrary 固定优先级就是指每个req的优先级是不变的,即优先级高的先被处理,优先级低的必须是在没有更高优先级的req的时候才会被处理。所以转化为数学模型就是找出req序列中第一个为1的位置,然后将其转换为onehot。 例如: req[3:0] = 4b1100 ==> g…...

《软件设计师-知识点》
1、指令流水线 (一)一条指令的执行过程可分为三个阶段:取指、分析、执行。 取指:根据PC(程序计数器)内容访问主存储器,取出一条指令送到IR(指令寄存器)中。 分析&…...

mysql 同义词_数据库中的同义词synonym
一、Oracle数据只有一个实例(简单理解就是Oracle 只能建立一个数据库,不像MySQL,它下面可以创建N个库),那么Oracle是根据用户灵活去管理的;这点读起来、理解 起来也不那么难,但是除非自己亲自实现一把才理解深入点&…...
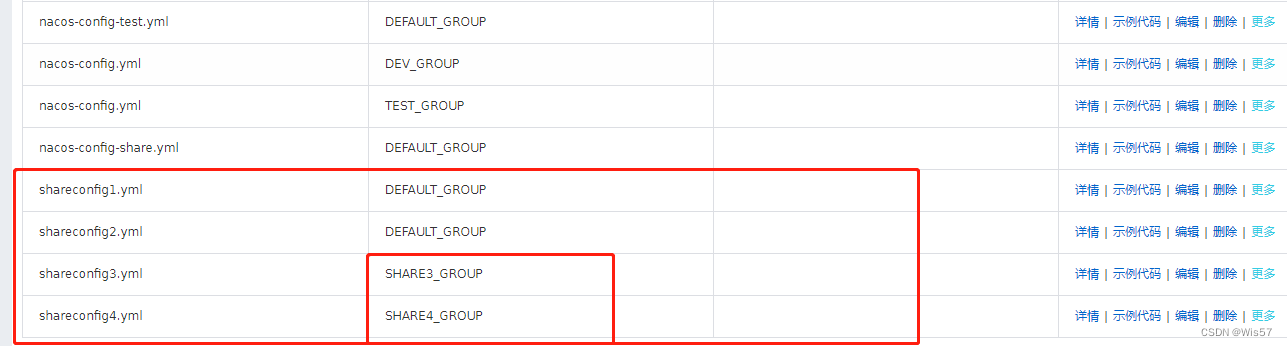
Nacos共享配置
本文介绍一下Nacos作为配置中心时,如何读取共享配置 我的环境 Windows10JDK8SpringCloud:Finchley.RELEASESpringBoot:2.0.4.RELEASEspring-cloud-alibaba-dependencies:0.2.2.RELEASENacos-server:1.0.1 本文的项目…...
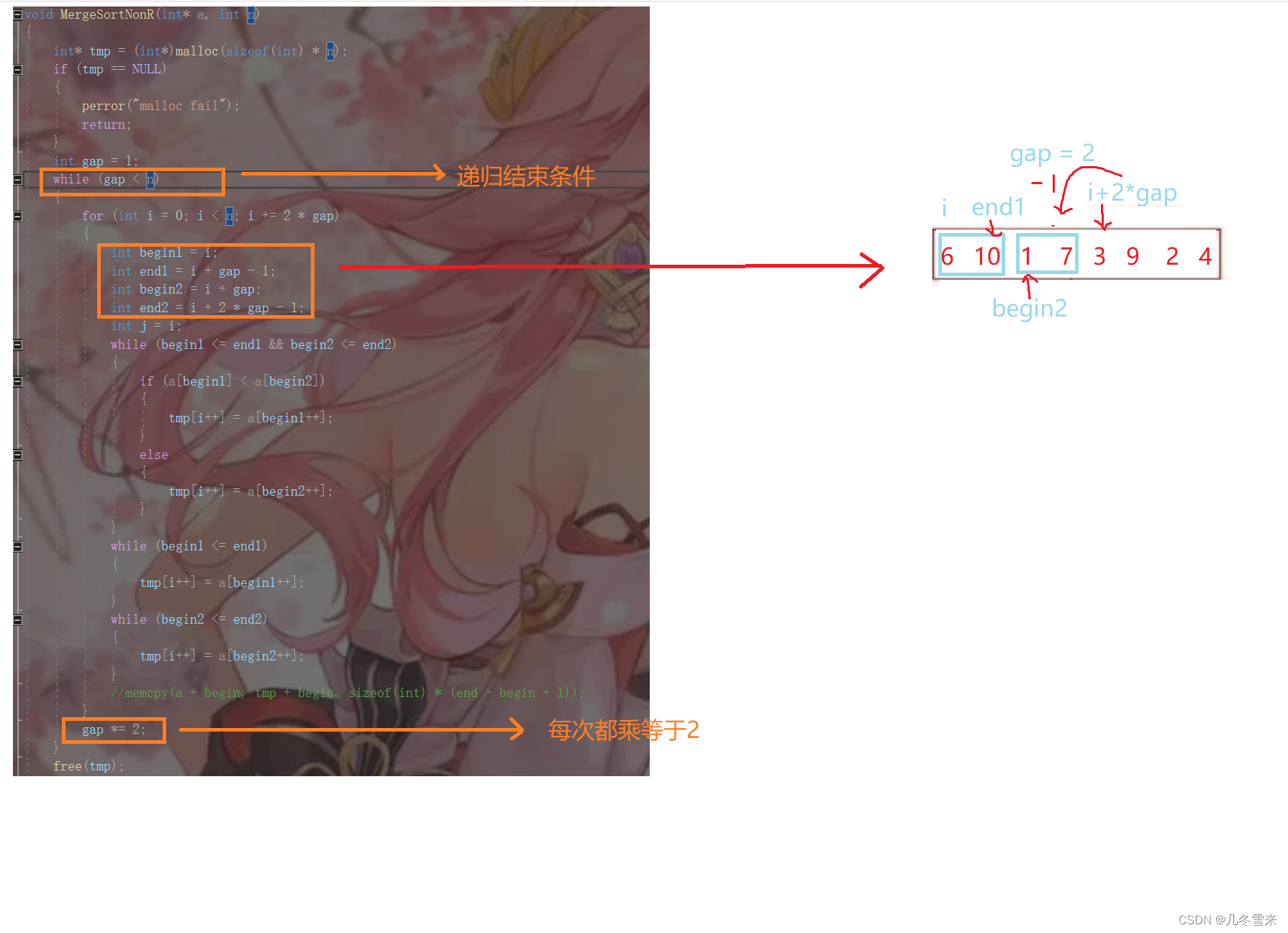
数据结构——排序(4)
作者:几冬雪来 时间:2023年4月12日 内容:数据结构排序内容讲解 目录 前言: 1.快速排序中的递归: 2.小区间优化: 3.递归改非递归: 4.归并排序: 5.归并排序的非递归形式&…...

C++13:搜索二叉树
目录 搜索二叉树概念 模拟实现搜索二叉树 插入函数实现 插入函数实现(递归) 查找函数实现 删除函数实现 删除函数实现(递归) 中序遍历实现 拷贝构造函数实现 析构函数实现 赋值重载 我们在最开始学习二叉树的时候,…...
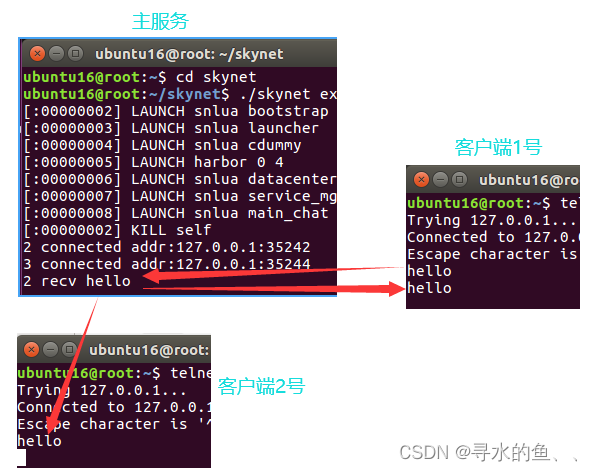
【从零开始学Skynet】基础篇(五):简易聊天室
在游戏中各玩家之间都可以进行聊天之类的交互,在这一篇中,我们就来实现一个简易的聊天室功能,这在上一篇代码的基础上很容易就能实现。1、功能需求 客户端发送一条消息,经由服务端转发,所有在线客户端都能收到…...
)
HDU - 2089 不要62(数位DP)
题目如下: 杭州人称那些傻乎乎粘嗒嗒的人为 626262(音:laoer)。 杭州交通管理局经常会扩充一些的士车牌照,新近出来一个好消息,以后上牌照,不再含有不吉利的数字了,这样一来&#x…...
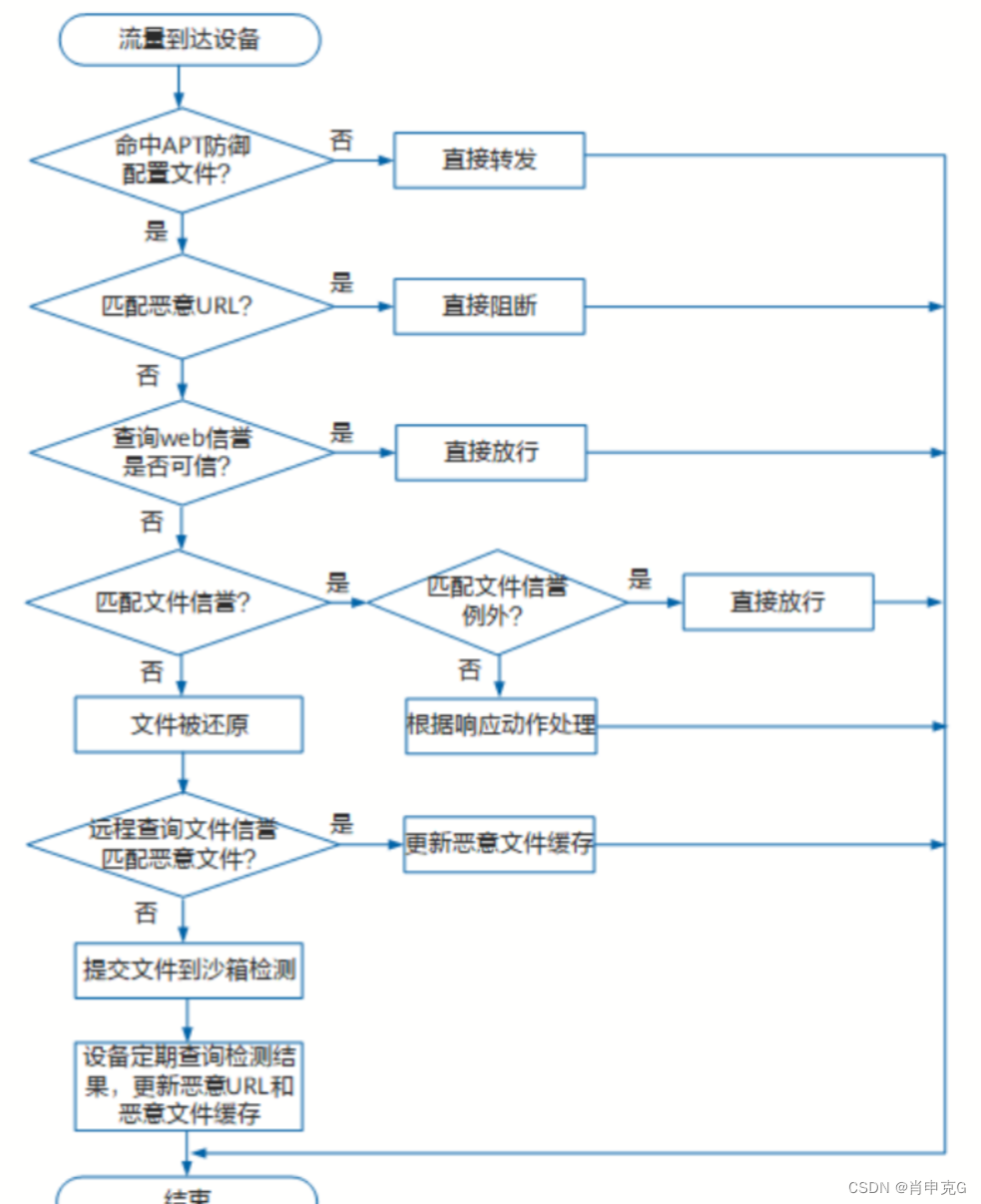
网络安全与防御
1. 什么是IDS? IDS(入侵检测系统):入侵检测是防火墙的合理补充,帮助系统对付网络攻击,扩展了系统管理员的安全管理能力,提高了信息安全基础结构的完整性。主要针对防火墙涉及不到的部分进行检测。 入侵检测主要面对的…...
)
别再只盯着PWM了!手把手教你为你的Arduino项目选择合适的DCDC调制方式(PFM/PWM/Burst Mode全解析)
别再只盯着PWM了!手把手教你为你的Arduino项目选择合适的DCDC调制方式(PFM/PWM/Burst Mode全解析) 当你为Arduino项目挑选电源模块时,是否曾被数据手册上PWM、PFM、Burst Mode这些术语搞得一头雾水?我曾在一个低功耗气…...

ncmdump终极解决方案:解锁网易云音乐NCM格式的完整指南
ncmdump终极解决方案:解锁网易云音乐NCM格式的完整指南 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 还在为网易云音乐下载的NCM加密文件无法在其他设备播放而烦恼吗?ncmdump工具使用为你提供了完美的NCM格…...

基于龙芯2K1000LA的可信计算在工业边缘安全中的实践
1. 项目概述:当“可信计算”遇上工业边缘 最近在做一个工业数据采集与边缘处理的项目,客户对数据安全的要求提到了前所未有的高度。他们不仅担心数据在传输过程中被窃取,更担心边缘设备本身被恶意篡改,导致采集的数据在源头就“失…...

终极暗黑破坏神II角色编辑器:5分钟打造你的完美英雄
终极暗黑破坏神II角色编辑器:5分钟打造你的完美英雄 【免费下载链接】diablo_edit Diablo II Character editor. 项目地址: https://gitcode.com/gh_mirrors/di/diablo_edit 还在为暗黑破坏神II中无尽的刷装备、练级而烦恼吗?Diablo Edit2是一款功…...

RT-Thread aarch64虚拟平台文件系统移植实战:从QEMU virt到LittleFS
1. 项目概述与核心价值最近在折腾RT-Thread的aarch64虚拟平台,特别是qemu-virt64-aarch64这个BSP(Board Support Package,板级支持包)上的文件系统支持。这看起来像是一个很具体的移植工作,但实际上,它触及…...

如何用茉莉花插件实现Zotero中文文献元数据一键抓取:终极解决方案
如何用茉莉花插件实现Zotero中文文献元数据一键抓取:终极解决方案 【免费下载链接】jasminum A Zotero add-on to retrive CNKI meta data. 一个简单的Zotero 插件,用于识别中文元数据 项目地址: https://gitcode.com/gh_mirrors/ja/jasminum 还在…...

使用 Taotoken 后模型 API 响应延迟与稳定性效果实测观察
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用 Taotoken 后模型 API 响应延迟与稳定性效果实测观察 作为一名需要频繁调用大模型 API 的开发者,模型服务的响应速…...

嵌入式游戏开发实战:在4x8 LED点阵上用CircuitPython复刻FlappyBird
1. 项目概述:在4x8的像素矩阵上“复活”FlappyBird如果你玩过嵌入式开发,尤其是用那些小巧的微控制器板子,可能会觉得游戏开发离它们很远——资源有限,没有图形库,怎么搞?但恰恰是这种限制,最能…...

Polymarket预测市场模拟交易工具:零风险学习链上金融衍生品
1. 项目概述与核心价值最近在研究链上预测市场,发现一个挺有意思的开源项目:jchimbor/polymarket-paper-trader。简单来说,这是一个针对Polymarket预测市场的“模拟交易”或“纸面交易”工具。Polymarket本身是一个基于Polygon链的去中心化预…...

帆软报表FineReport连接Elasticsearch避坑指南:从插件安装到SQL编写的完整流程
帆软报表FineReport连接Elasticsearch全流程实战指南 在企业级数据分析领域,帆软报表FineReport与Elasticsearch的集成能够显著提升海量数据的可视化分析能力。本文将基于实际项目经验,系统梳理从环境准备到生产部署的完整链路,特别针对配置过…...