大数据技术——spark集群搭建
目录
spark概述
spark集群搭建
1.Spark安装
2.环境变量配置
3.Spark集群配置
4.启动Spark集群
存在问题及解决方案
请参考以下文章
spark概述
Spark是一个开源的大数据处理框架,它可以在分布式计算集群上进行高效的数据处理和分析。Spark的特点是速度快、易用性高、支持多种编程语言和数据源。Spark的核心是基于内存的计算模型,可以在内存中快速地处理大规模数据。Spark支持多种数据处理方式,包括批处理、流处理、机器学习和图计算等。Spark的生态系统非常丰富,包括Spark SQL、Spark Streaming、MLlit
GraphX等组件,可以满足不同场景下的数据处理需求。
spark集群搭建
在部署spark集群时,我们知道有三种:
一种是本地模式,一种是Standalone 集群,还有一种是云端。
1.Spark安装
首先我们需要在master节点上进行Spark的安装。
其中1台机器(节点)作为Master节点,主机名为hadoop1,另外两台机器(节点)作为Slave节点(即作为Worker节点),主机名分别为hadoop2和hadoop3。
在Master节点机器上,访问Spark官方下载地址Downloads | Apache Spark,按照如下图下载:
我们选择2.1.0的版本,也可以选择其他的版本,但是需要注意的是,如果你选择的Spark版本过高,可能导致无法与你的hadoop版本适配。
完成下载后,进行如下的命令行操作,和hadoop安装时十分类似。
$ tar -zxvf scala.2.11.8.tgz #解压到当前路径

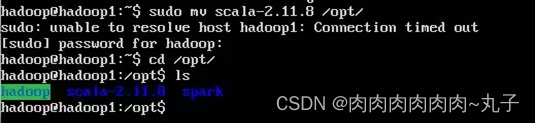
$ cd /usr/local
$ sudo mv ./spark-2.1.0-bin-without-hadoop/ ./spark #重命名
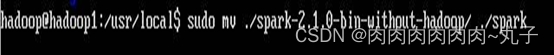
spark安装与上述Scala步骤一致
2.环境变量配置
同样在master机器上,打开bashrc文件进行环境变量配置。
$ vim ~/.bashrc
在文件中添加如下内容
export PATH=$PATH:/usr/local/scala/bin并使其生效。

保存文件并退出vim编辑器,执行如下命令让改环境变量生效:
$ source ~/.bashrc
设置好后,可以使用Scala命令来检验一下是否设置正确:
$ scala

输入scala命令以后,屏幕上会显示Scala和java版本信息,并进入“scala>”提示符状态,这时就可以开始使用Scala解释器了,可以输入scala语句来调试scala代码。
3.Spark集群配置
进入到/usr/local/spark的conf路径下,进行以下文件的配置。
a)配置slaves文件
但是由于其开始并没有这个文件,而只有slaves.template文件,所以我们需要先拷贝重命名一下。
$ cd /usr/local/spark/conf/
$ cp ./slaves.template ./slaves

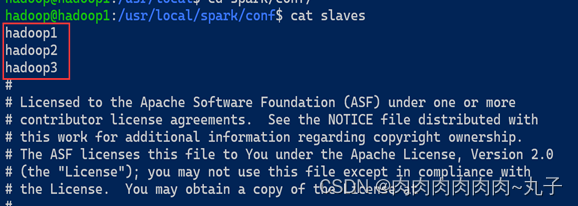
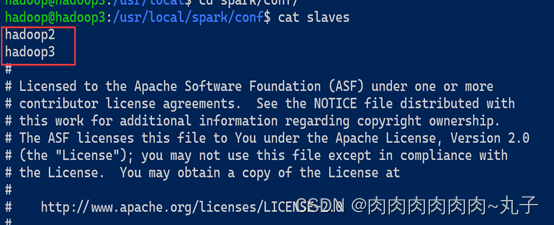
然后打开这个slaves文件,并将默认的localhost替换相应的两个slave结点:
hadoop2
hadoop3
分别在三台虚拟机上修改slaves文件:
hadoop1:
hadoop2:

hadoop3:
b)配置spark-env.sh文件
同样的,我们需要先将template文件拷贝重命名。
将 spark-env.sh.template 拷贝到 spark-env.sh
$ cp ./spark-env.sh.template ./spark-env.sh
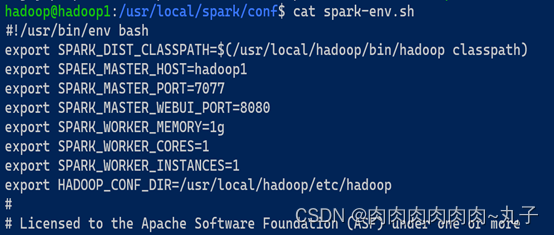
然后在文件中添加如下内容
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
export SPAEK_MASTER_HOST=hadoop1
export SPARK_MASTER_PORT=7077
export SPARK_MASTER_WEBUI_PORT=8080
export SPARK_WORKER_MEMORY=1g
export SPARK_WORKER_CORES=1
export SPARK_WORKER_INSTANCES=1
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop分别在三台虚拟机上修改spark-env.sh文件:
hadoop1:
hadoop2:

hadoop3:

c)集群规划
| 节点 | spark节点 | hadoop节点 |
| hadoop1 | master worker | datanode namenode secondarynamenode(hadoop) resourcemanager nodemanager(yarn) |
| hadoop2 | worker | datanode nodemanager |
| hadoop3 | worker | datanode nodemanager |
4.启动Spark集群
因为我们的Spark是基于hadoop来运行的,因此我们首先需要将hadoop启动起来。
启动Hadoop集群

在master机器上运行如下指令启动hadoop集群
$ cd /usr/local/hadoop/
$ sbin/start-all.sh
hadoop1:
hadoop2:
hadoop3:

启动spark集群
然后我们再再master机器上启动Spark的master进程。
$ cd /usr/local/spark/
$ sbin/start-master.sh
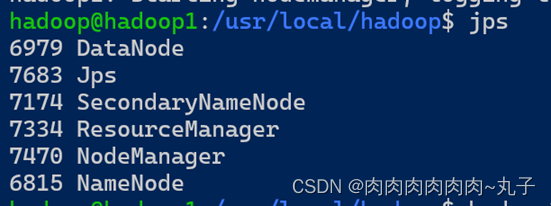
使用jps命令查看master机器上的进程情况,结果如下。
hadoop1:
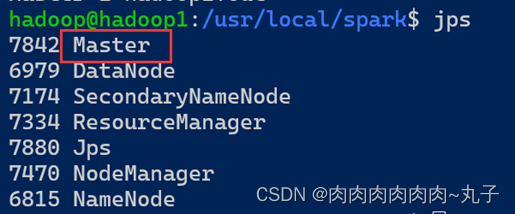
我们发现,除了hadoop的相关进程之外,还多了一个Master进程,证明master节点已经成功启动。
然后我们同样在master机器上再启动worker进程。
用以下命令启动所有的slave节点
$ sbin/start-slaves.sh
hadoop1:
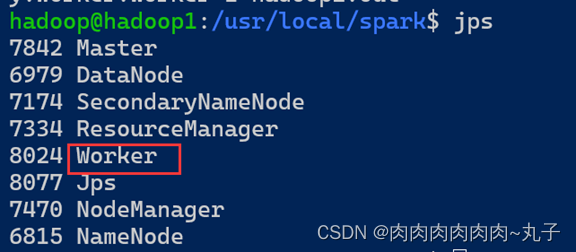
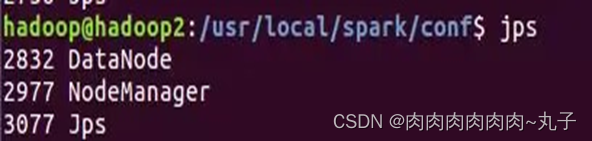
分别在hadoop2、hadoop3节点上运行jps命令,可以看到多了个Worker进程
hadoop2:
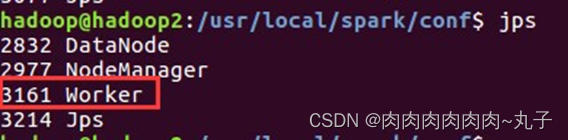
hadoop3:

我们发现,同样的除了hadoop的相关进程,多出来一个Worker进程,证明worker节点也已经成功启动。
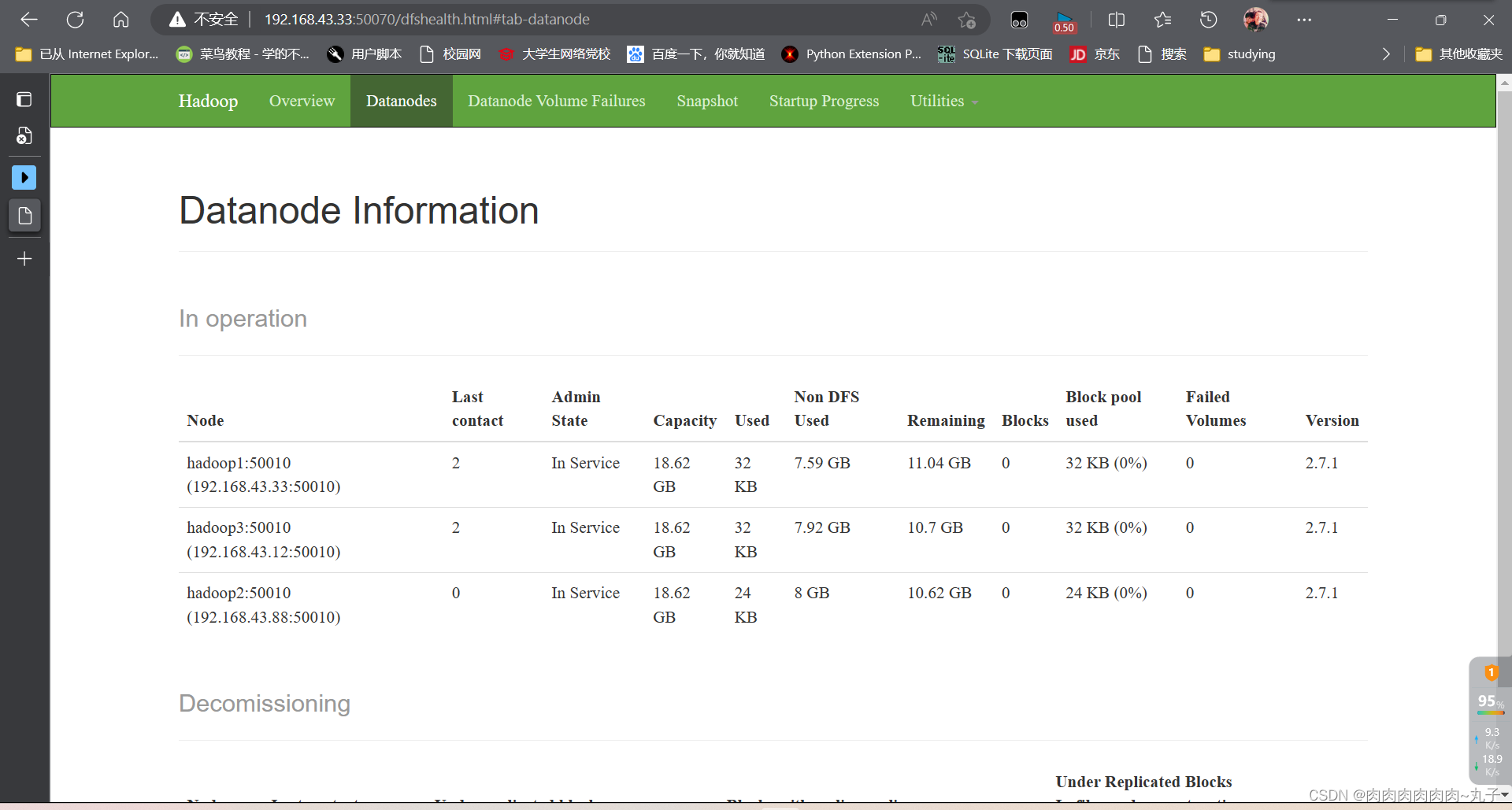
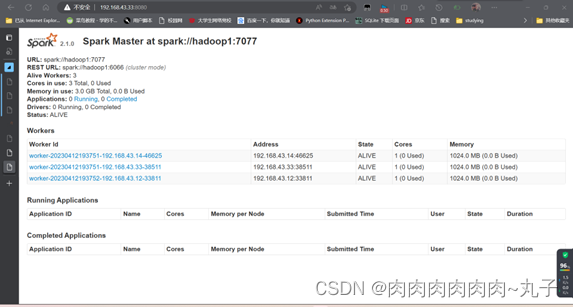
在浏览器上查看Spark独立集群管理器的集群信息
在master主机上打开浏览器,
分别访问http://192.168.43.33:50070,如下图:
分别访问http://192.168.43.33:8080,如下图:
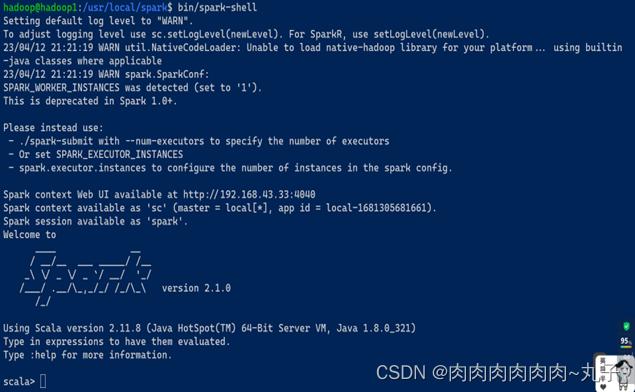
$ spark-shell #进入shell
关闭spark集群
①关闭master节点
$ sbin/stop-master.sh
②关闭worker节点
$ sbin/stop-slaves.sh
③关闭Hadoop集群
$ cd /usr/local/hadoop/
$ sbin/stop-all.sh

存在问题及解决方案
请参考以下文章
大数据技术——搭建spark集群出现的问题_肉肉肉肉肉肉~丸子的博客-CSDN博客
相关文章:
大数据技术——spark集群搭建
目录 spark概述 spark集群搭建 1.Spark安装 2.环境变量配置 3.Spark集群配置 4.启动Spark集群 存在问题及解决方案 请参考以下文章 spark概述 Spark是一个开源的大数据处理框架,它可以在分布式计算集群上进行高效的数据处理和分析。Spark的特点是速度快、易…...

嵌入式学习笔记汇总
本文整理STM32、STM8和uCOS-III的所有文章链接。 STM32学习笔记目录 源码:mySTM32-learn STM32学习笔记(1)——LED和蜂鸣器 STM32学习笔记(2)——按键输入实验 STM32学习笔记(3)——时钟系统 …...

Python 全栈系列220 Tornado的服务搭建
说明 想法变的真快 本来是没打算用Tornado的,主要是想节约时间。但是现在看来不用还是不行:目前用gevent flask部署的时候,启动多核的worker似乎存在问题。 另外,有很多内部基础的数据服务,其实并不需要flask的各种组…...
ESXi安装CentOS
ESXi安装 参考:https://blog.csdn.net/tongxin_tongmeng/article/details/129466704 CentOS安装 镜像:http://mirrors.aliyun.com/centos/7/isos/x86_64-->CentOS-7-x86_64-DVD-2009.iso CentOS配置 FinalShell连接 ESXi简介 1.ESXi是由VMware公司…...

WebTest搭建
0.前言 此框架为真实项目实战,所以有些数据不便展示,只展示架构和思想 工具:pythonseleniumddtunittest 1.架构说明 2.代码封装 Commom层 base_page.py #__author__19044168 #date2021/8/26 import logging import datetime from sele…...
)
什么性格的人适合报考机械类专业?(高考志愿填报选专业)
机械类专业 是指涉及机械设计、制造、加工、维护等方面的专业,是工程类专业中的一类。机械类专业的学生主要学习机械工程的基础知识,包括机械设计、力学、材料力学、热力学、流体力学等,同时也会学习机械制造、机电一体化、机器人技术等实践性…...

进程概念详解
目录 进程是什么? 描述进程:进程控制块-PCB task_struct task_struct 是什么? task_struct内容分类 组织进程 查看进程 fork创建子进程 进程状态 僵尸进程 孤儿进程 进程优先级 其他概念 进程是什么? 一般书上…...

C语言基础——指针
文章目录一、指针1.指针的意义2.指针类型表示3.一些操作3.1打印1个变量地址3.2通过地址查看改地址的内容以及修改改地址的内容3.3操作某个空间 -- 4个字节,给他赋值为100,只知道该空间的地址0x8000 00004.指针变量的定义5.指针类型的大小6.指针变量的使用6.1 指针变…...
之Java反序列化漏洞)
反序列化渗透与攻防(二)之Java反序列化漏洞
Java反序列化漏洞 反序列化漏洞 JAVA反序列化漏洞到底是如何产生的? 1、由于很多站点或者RMI仓库等接口处存在java的反序列化功能,于是攻击者可以通过构造特定的恶意对象序列化后的流,让目标反序列化,从而达到自己的恶意预期行为,包括命令执行,甚至 getshell 等等。 …...
优先级队列的模拟实现(仿函数)
目录: 1.priority_queue接口的实现(先建大堆) 1.push 加 向上调整的实现 2.pop 3.迭代器区间的构造 2.仿函数 3.仿函数优化我们的优先级队列 -------------------------------------------------------------------------------------------…...
Python pandas和numpy用法参考(转)
以下是转载:Python pandas用法 - 简书介绍 在Python中,pandas是基于NumPy数组构建的,使数据预处理、清洗、分析工作变得更快更简单。pandas是专门为处理表格和混杂数据设计的,而NumPy更适合处...https://www.jianshu.com/p/840ba1…...

mysql数据库的在线数据备份与数据恢复
MySQL是一种常用的关系型数据库管理系统,它支持在线备份和恢复数据。在线备份指的是在MySQL数据库运行时备份数据,而不会中断或影响现有的数据库服务。在本文中,我们将介绍MySQL数据库的在线数据备份和恢复的原理和操作步骤。 一、备份原理 …...

Vue3自定义指令之前端水印功能实现
一、前置知识 — Vue 中的自定义指令 先来说说 vue2和vue3中自定义全局指令的区别 相同点:指令的应用场景,原理是一致的; 不同点:生命周期钩子函数名,指令定义的格式不一样。 vue2中自定义全局指令: 定义…...

文章生成器写出来的原创文章
文章生成机器人 文章生成机器人是一种基于人工智能技术和自然语言处理算法的程序,可以自动地生成高质量、原创的文章。 文章生成机器人的优点如下: 提高工作效率:文章生成机器人能够在较短的时间内自动帮助用户生成大量的文章,提…...

2023年全国最新高校辅导员精选真题及答案49
百分百题库提供高校辅导员考试试题、辅导员考试预测题、高校辅导员考试真题、辅导员证考试题库等,提供在线做题刷题,在线模拟考试,助你考试轻松过关。 76.气质就是我们平常所说的脾气秉性。 答案:正确 77.社会心理通常是通过社会…...
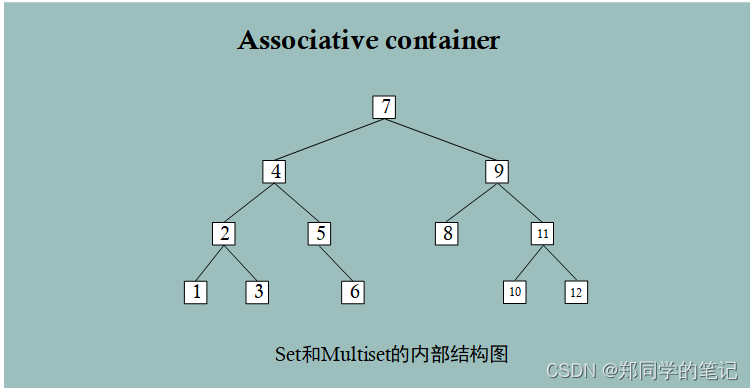
【STL十】关联容器——set容器、multiset容器
【STL十】关联容器——set容器、multiset容器一、set简介二、头文件三、模板类四、set的内部结构五、成员函数1、迭代器2、元素访问3、容量4、修改操作~~5、操作~~5、查找6、查看操作六、demo1、查找find2、修改操作insert3、修改操作erase、clear七、multisetset和multiset会根…...
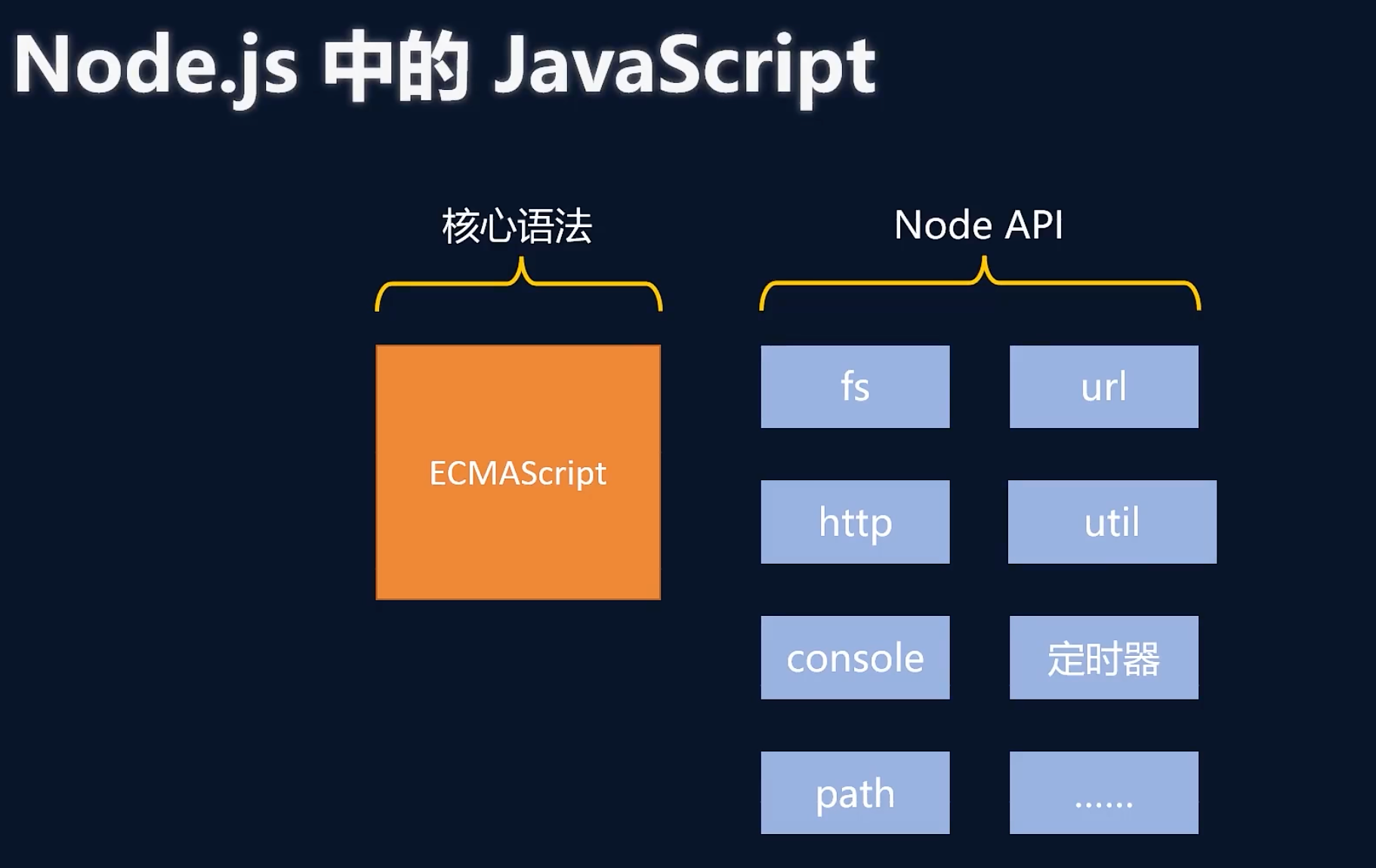
什么是Node.js
文章目录什么是Node.js简介常用命令Node内置模块Node.js和JavaScript的区别什么是Node.js 简介 Node.js是一个基于Chrome V8引擎的JavaScript运行环境。它允许开发者使用JavaScript编写服务器端代码,而不仅仅是浏览器端的代码。Node.js的出现使得JavaScript可以在…...

比GPT-4 Office还炸裂,阿里版GPT全家桶来袭
疯狂3月的那一天,一切还历历在目。 微软突然在发布会上放出大招,用Microsoft 365 Copilot掀起了办公软件革命。 而今天,阿里也放出一枚重磅炸弹——阿里版的Copilot也要来了! 并且比微软更彻底的是,阿里全系产品也都…...

mysql 建表约束
主键约束 -- 主键约束 -- 使某个字段不重复且不得为空,确保表内所有数据的唯一性。 CREATE TABLE user (id INT PRIMARY KEY,name VARCHAR(20) );-- 联合主键 -- 联合主键中的每个字段都不能为空,并且加起来不能和已设置的联合主键重复。 CREATE TABLE …...
在Vue项目中使用tinymce富文本编辑器
TinyMC编辑器简介 TinyMCE是一款易用、且功能强大的所见即所得的富文本编辑器。跟其他富文本编辑器相比,有着丰富的插件,支持多种语言,能够满足日常的业务需求并且免费。 TinyMCE的优势: 开源可商用,基于LGPL2.1 插…...

构建多模型备用策略时Taotoken的聚合与路由能力价值
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 构建多模型备用策略时Taotoken的聚合与路由能力价值 在构建依赖大模型能力的生产应用时,服务的稳定性是核心考量之一。…...

Teamcenter: RAC插件开发实战——从环境搭建到BOM报表生成
1. 环境搭建:Target Platform配置实战 第一次接触Teamcenter RAC插件开发时,最让我头疼的就是环境配置。记得当时为了调试一个简单的菜单按钮,整整折腾了两天环境问题。下面分享我验证过的配置流程,帮你避开那些坑。 开发RAC插件需…...

从零打造互动徽章:激光切割与电容触摸的软硬件融合实践
1. 项目概述与核心思路如果你参加过技术大会或者创客市集,一定对那些闪烁着酷炫灯光、能与人互动的徽章印象深刻。这类被称为“Badge”的可穿戴设备,早已超越了单纯的身份标识功能,成为了展示技术、创意和社群文化的微型平台。今天要分享的&a…...

硬件原型开发实战:从面包板到洞洞板的完整迁移指南
1. 项目概述:从概念到实物的必经之路在电子设计的漫长旅程中,从一张画满符号的电路图,到一台能稳定运行、看得见摸得着的设备,中间横亘着一道看似简单、实则至关重要的鸿沟——原型制作。这道鸿沟,就是“面包板”和“洞…...

第15章:C++ 日志监控告警
第15章:C++ 日志监控告警 本章定位:第四卷《实战卷》第五篇"生产环境"第 16 章。 一个 C++ 服务上线后能不能"看见"它,能不能"听见"它喊救命,决定了你深夜会不会被叫起来还能在 30 分钟内修好。 目录 01.可观测性三件套 1.1 logs / metrics …...

https://github.com/langgenius/dify查看设置的apikey
现在我已经掌握了足够的信息,来做一个完整清晰的分析。好的,现在我来给出一个完整的分析。 Dify provider_model_credentials.encrypted_config 解密分析 整体加密架构 Dify 使用 PKCS1_OAEP 加密来保护 API key。每个用户(tenant)…...

如何用DouyinLiveWebFetcher三步实现抖音直播弹幕实时采集?终极免费工具使用指南
如何用DouyinLiveWebFetcher三步实现抖音直播弹幕实时采集?终极免费工具使用指南 【免费下载链接】DouyinLiveWebFetcher 抖音直播间网页版的弹幕数据抓取(2025最新版本) 项目地址: https://gitcode.com/gh_mirrors/do/DouyinLiveWebFetche…...

ARM Cortex-M3内存映射与外设配置详解
1. ARM Cortex-M3 SMM系统架构解析在嵌入式系统开发中,系统内存映射(System Memory Map, SMM)是连接处理器内核与各类外设的关键桥梁。ARM Cortex-M3处理器通过精心设计的SMM架构,为开发者提供了灵活而高效的硬件资源配置方案。V2M-MPS2开发板作为ARM官方…...

Arduino情绪交互与Flappy Bird游戏:Tone库与状态机实战
1. 项目概述:当Arduino学会“表达情绪”与“玩游戏”在嵌入式开发的世界里,让一块小小的微控制器板子“活”起来,发出声音、显示画面并与人互动,是件充满乐趣和挑战的事。我们常常追求功能的实现,但如何让交互本身变得…...

OpenClaw开源安全平台:模块化架构、插件化设计与企业级自动化安全运营实践
1. 项目概述:从开源安全工具到企业级安全基线的构建最近在梳理内部安全工具链时,又仔细研究了一下AtlasPA/openclaw-security这个项目。这不仅仅是一个简单的漏洞扫描器或者安全脚本集合,它更像是一个试图将安全左移理念、自动化响应和资产安…...