【图片分割】【深度学习】Windows10下SAM官方代码Pytorch实现
【图片分割】【深度学习】Windows10下SAM官方代码Pytorch实现
提示:最近开始在【图片分割】方面进行研究,记录相关知识点,分享学习中遇到的问题已经解决的方法。
文章目录
- 【图片分割】【深度学习】Windows10下SAM官方代码Pytorch实现
- 前言
- SAM模型运行环境安装
- 打开cmd,执行下面的指令查看CUDA版本号
- 2.安装GPU版本的torch:【[官网](https://pytorch.org/)】
- 3.博主安装环境参考
- SAM代码使用
- predictor_example
- 步骤一:查看测试图片
- 步骤二:显示前景和背景的标记点
- 步骤三:标记点完成前景目标的分割
- 步骤四:标定框完成前景目标的分割
- 步骤五:标定框和标记点联合完成前景目标的分割
- 步骤六:多标定框完成前景目标的分割
- 步骤六:图片批量完成前景目标的分割
- automatic_mask_generator_example
- 步骤一:自动掩码生成
- 步骤一:自动掩码生成参数调整
- 总结
前言
SAM是由谷歌的Kirillov, Alexander等人在《Segment Anything》【论文地址】一文中提出的模型,模块化交互式VOS(MiVOS)框架将交互到掩码和掩码传播分离,从而实现更高的泛化性和更好的性能。
在详细解析SAM网络之前,首要任务是搭建SAM【Pytorch-demo地址】所需的运行环境,并模型完成训练和测试工作,展开后续工作才有意义。
SAM模型运行环境安装

代码运行这里提了要求,python要大于等于3.8,pytorch大于等于1.7,torchvision大于等于0.8。
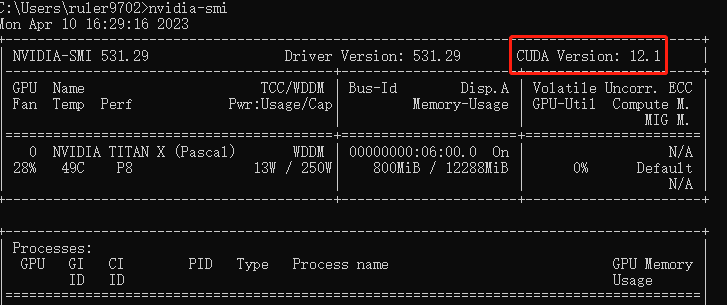
打开cmd,执行下面的指令查看CUDA版本号
nvidia-smi
2.安装GPU版本的torch:【官网】
博主的cuda版本是12.1,但这里cuda版本最高也是11.8,博主选的11.7也没问题。
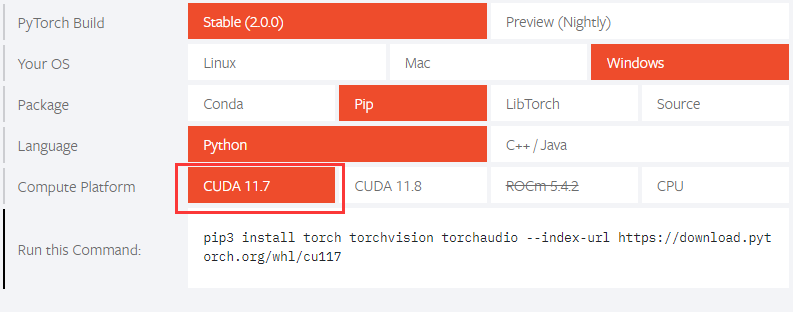
其他cuda版本的torch在【以前版本】找对应的安装命令,其他包安装就用githup源码教程给出的方式安装即可:
cd segment-anything; pip install -e .
# 这里是选装包,但是博主还是都装了
pip install opencv-python pycocotools matplotlib onnxruntime onnx
3.博主安装环境参考
根据个人电脑配置环境运行环境,这里博主提供了本人运行环境安装的包,假设你的cuda版本是11.7及其以上,个人觉得可以直接用博主的yaml安装。
# 使用Anaconda导出环境yaml文件(这步是博主导出自己的安装包,可忽略)
conda env export --name SAM >environment.yaml
# 使用yaml创建虚拟环境
conda env create -f environment.yaml
conda下载超时自动断开处理方法
#把连接超时的时间设置成100s,读取超时的时间修改成100s
conda config --set remote_connect_timeout_secs 100
conda config --set remote_read_timeout_secs 100
environment.yml文件内容,注意"name: SAM"是自定义虚拟环境名。假如有些包实现安装不了,单独pip安装,这里只是作为一个参考。
name: SAM
channels:- conda-forge- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/- defaults
dependencies:- bzip2=1.0.8=h8ffe710_4- ca-certificates=2022.12.7=h5b45459_0- libffi=3.4.2=h8ffe710_5- libsqlite=3.40.0=hcfcfb64_0- libzlib=1.2.13=hcfcfb64_4- openssl=3.1.0=hcfcfb64_0- pip=23.0.1=pyhd8ed1ab_0- python=3.9.16=h4de0772_0_cpython- setuptools=67.6.1=pyhd8ed1ab_0- tk=8.6.12=h8ffe710_0- tzdata=2023c=h71feb2d_0- ucrt=10.0.22621.0=h57928b3_0- vc=14.3=hb6edc58_10- vs2015_runtime=14.34.31931=h4c5c07a_10- wheel=0.40.0=pyhd8ed1ab_0- xz=5.2.6=h8d14728_0- pip:- certifi==2022.12.7- charset-normalizer==2.1.1- coloredlogs==15.0.1- contourpy==1.0.7- cycler==0.11.0- filelock==3.9.0- flatbuffers==23.3.3- fonttools==4.39.3- humanfriendly==10.0- idna==3.4- importlib-resources==5.12.0- jinja2==3.1.2- kiwisolver==1.4.4- markupsafe==2.1.2- matplotlib==3.7.1- mpmath==1.3.0- networkx==3.0- numpy==1.24.2- onnx==1.13.1- onnxruntime==1.14.1- opencv-python==4.7.0.72- packaging==23.0- pillow==9.5.0- protobuf==3.20.3- pycocotools==2.0.6- pyparsing==3.0.9- pyreadline3==3.4.1- python-dateutil==2.8.2- requests==2.28.1- six==1.16.0- sympy==1.11.1- torch==2.0.0+cu117- torchaudio==2.0.1+cu117- torchvision==0.15.1+cu117- typing-extensions==4.5.0- urllib3==1.26.13- zipp==3.15.0
prefix: D:\ProgramData\Anaconda\Miniconda3\envs\SAM
最终的环境安装所有的包与yaml文件一致。
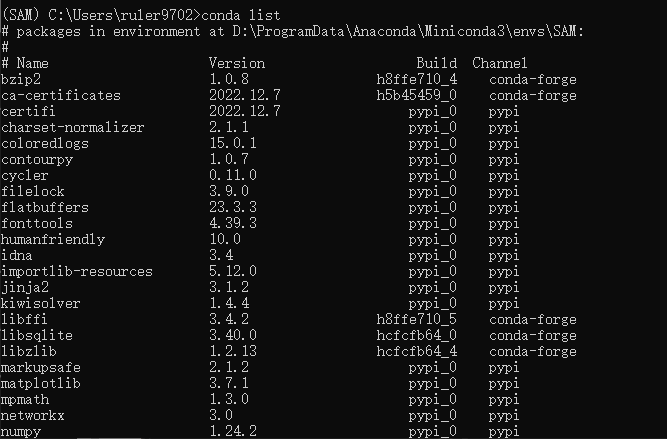
# 查看所有安装的包
pip list
conda list
SAM代码使用
下载githup源码以及所提供的权重文件

predictor_example
源码在notebooks文件内提供了一个Jupyter Notebook的使用教程,博主现在就以官方使用教程为模板,测试自己的数据集。
predictor_example.ipynb源码在notebooks文件目录下,可以本地运行测试或者直接在githup上查看教程。
步骤一:查看测试图片
import cv2
import matplotlib.pyplot as plt
image = cv2.imread('img.png')
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
plt.figure(figsize=(10, 10))
plt.imshow(image)
plt.axis('on')
plt.show()

步骤二:显示前景和背景的标记点
import numpy as np
import matplotlib.pyplot as plt
import cv2def show_points(coords, labels, ax, marker_size=375):# 筛选出前景目标标记点pos_points = coords[labels == 1]# 筛选出背景目标标记点neg_points = coords[labels == 0]# x-->pos_points[:, 0] y-->pos_points[:, 1]ax.scatter(pos_points[:, 0], pos_points[:, 1], color='green', marker='*', s=marker_size, edgecolor='white',linewidth=1.25) # 前景的标记点显示ax.scatter(neg_points[:, 0], neg_points[:, 1], color='red', marker='*', s=marker_size, edgecolor='white',linewidth=1.25) # 背景的标记点显示image = cv2.imread('img.png')
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)# 鼠标标定(x,y)位置
# 因为可以有多个标定,所以有多个坐标点
input_point = np.array([[230, 194], [182, 63], [339, 279]])
# 1表示前景目标,0表示背景
# input_point和input_label一一对应
input_label = np.array([1, 1, 0])plt.figure(figsize=(10, 10))
plt.imshow(image)
show_points(input_point, input_label, plt.gca())
plt.axis('on')
plt.show()
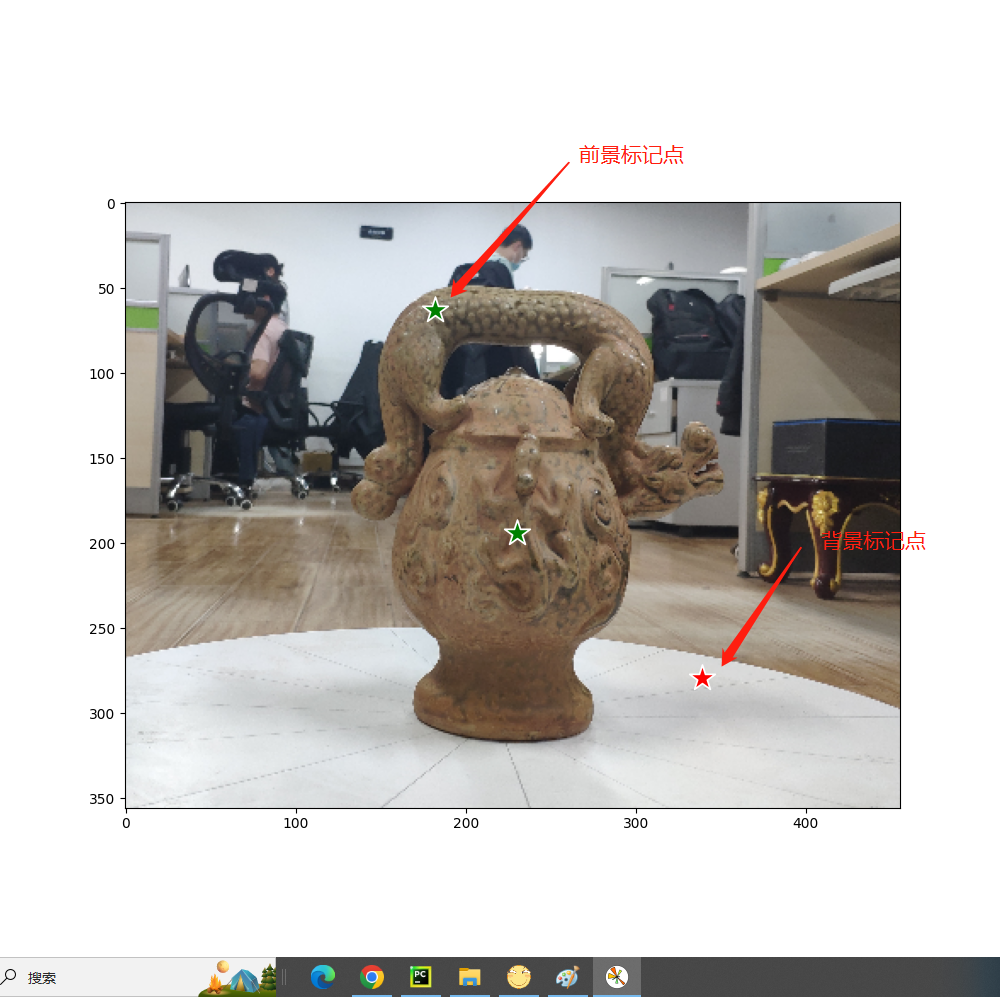
这里图片可以用画图软件打开查看像素坐标辅助标定
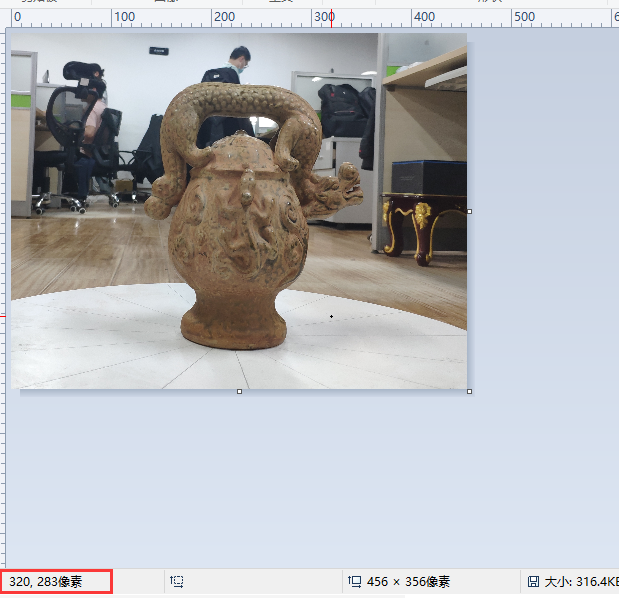
步骤三:标记点完成前景目标的分割
简单的调用源码模型,就能完成前景目标的分割,源码提供了三中不同大小的模型,读者可以自己去尝试不同的模型效果。
博主在阅读源码后,后续会根据自己的理解讲解源码
import numpy as np
import matplotlib.pyplot as plt
import cv2def show_mask(mask, ax, random_color=False):if random_color: # 掩膜颜色是否随机决定color = np.concatenate([np.random.random(3), np.array([0.6])], axis=0)else:color = np.array([30 / 255, 144 / 255, 255 / 255, 0.6])h, w = mask.shape[-2:]mask_image = mask.reshape(h, w, 1) * color.reshape(1, 1, -1)ax.imshow(mask_image)def show_points(coords, labels, ax, marker_size=375):# 筛选出前景目标标记点pos_points = coords[labels == 1]# 筛选出背景目标标记点neg_points = coords[labels == 0]# x-->pos_points[:, 0] y-->pos_points[:, 1]ax.scatter(pos_points[:, 0], pos_points[:, 1], color='green', marker='*', s=marker_size, edgecolor='white',linewidth=1.25) # 前景的标记点显示ax.scatter(neg_points[:, 0], neg_points[:, 1], color='red', marker='*', s=marker_size, edgecolor='white',linewidth=1.25) # 背景的标记点显示
import sys
sys.path.append("..")
from segment_anything import sam_model_registry, SamPredictorimage = cv2.imread('img.png')
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)#------加载模型
# 权重文件保存地址
sam_checkpoint = "model_save/sam_vit_b_01ec64.pth"
# sam_checkpoint = "model_save/sam_vit_h_4b8939.pth"
# sam_checkpoint = "model_save/sam_vit_l_0b3195.pth"
# 模型类型
model_type = "vit_b"
# model_type = "vit_h"
# model_type = "vit_l"
device = "cuda"
sam = sam_model_registry[model_type](checkpoint=sam_checkpoint)
sam.to(device=device)
predictor = SamPredictor(sam)
predictor.set_image(image)
#------加载模型# 鼠标标定(x,y)位置
# 因为可以有多个标定,所以有多个坐标点
input_point = np.array([[230, 194], [182, 63], [339, 279]])
# 1表示前景目标,0表示背景
# input_point和input_label一一对应
input_label = np.array([1, 1, 0])masks, scores, logits = predictor.predict(point_coords=input_point,point_labels=input_label,multimask_output=True,
)
for i, (mask, score) in enumerate(zip(masks, scores)):plt.figure(figsize=(10, 10))plt.imshow(image)show_mask(mask, plt.gca())show_points(input_point, input_label, plt.gca())plt.title(f"Mask {i + 1}, Score: {score:.3f}", fontsize=18)plt.axis('off')plt.show()
这里会输出三个结果



步骤四:标定框完成前景目标的分割
绿色的框是用户自己标定的,根据框选的区域完成前景目标的分割。
import numpy as np
import matplotlib.pyplot as plt
import cv2def show_mask(mask, ax, random_color=False):if random_color: # 掩膜颜色是否随机决定color = np.concatenate([np.random.random(3), np.array([0.6])], axis=0)else:color = np.array([30 / 255, 144 / 255, 255 / 255, 0.6])h, w = mask.shape[-2:]mask_image = mask.reshape(h, w, 1) * color.reshape(1, 1, -1)ax.imshow(mask_image)def show_points(coords, labels, ax, marker_size=375):# 筛选出前景目标标记点pos_points = coords[labels == 1]# 筛选出背景目标标记点neg_points = coords[labels == 0]# x-->pos_points[:, 0] y-->pos_points[:, 1]ax.scatter(pos_points[:, 0], pos_points[:, 1], color='green', marker='*', s=marker_size, edgecolor='white',linewidth=1.25) # 前景的标记点显示ax.scatter(neg_points[:, 0], neg_points[:, 1], color='red', marker='*', s=marker_size, edgecolor='white',linewidth=1.25) # 背景的标记点显示
def show_box(box, ax):# 画出标定框 x0 y0是起始坐标x0, y0 = box[0], box[1]# w h 是框的尺寸w, h = box[2] - box[0], box[3] - box[1]ax.add_patch(plt.Rectangle((x0, y0), w, h, edgecolor='green', facecolor=(0, 0, 0, 0), lw=2))import sys
sys.path.append("..")
from segment_anything import sam_model_registry, SamPredictor
image = cv2.imread('img.png')
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)#------加载模型
# 权重文件保存地址
sam_checkpoint = "model_save/sam_vit_b_01ec64.pth"
# sam_checkpoint = "model_save/sam_vit_h_4b8939.pth"
# sam_checkpoint = "model_save/sam_vit_l_0b3195.pth"
# 模型类型
model_type = "vit_b"
# model_type = "vit_h"
# model_type = "vit_l"
device = "cuda"
sam = sam_model_registry[model_type](checkpoint=sam_checkpoint)
sam.to(device=device)
predictor = SamPredictor(sam)
predictor.set_image(image)
#------加载模型# 标定框的起始坐标和终点坐标
input_box = np.array([112, 41, 373, 320])masks, _, _ = predictor.predict(point_coords=None,point_labels=None,box=input_box[None, :],multimask_output=False,
)plt.figure(figsize=(10, 10))
plt.imshow(image)
show_mask(masks[0], plt.gca())
show_box(input_box, plt.gca())
plt.axis('off')
plt.show()

步骤五:标定框和标记点联合完成前景目标的分割
对于一些复杂的目标,可能需要联合使用提高前景目标的分割精度。
import numpy as np
import matplotlib.pyplot as plt
import cv2def show_mask(mask, ax, random_color=False):if random_color: # 掩膜颜色是否随机决定color = np.concatenate([np.random.random(3), np.array([0.6])], axis=0)else:color = np.array([30 / 255, 144 / 255, 255 / 255, 0.6])h, w = mask.shape[-2:]mask_image = mask.reshape(h, w, 1) * color.reshape(1, 1, -1)ax.imshow(mask_image)def show_points(coords, labels, ax, marker_size=375):# 筛选出前景目标标记点pos_points = coords[labels == 1]# 筛选出背景目标标记点neg_points = coords[labels == 0]# x-->pos_points[:, 0] y-->pos_points[:, 1]ax.scatter(pos_points[:, 0], pos_points[:, 1], color='green', marker='*', s=marker_size, edgecolor='white',linewidth=1.25) # 前景的标记点显示ax.scatter(neg_points[:, 0], neg_points[:, 1], color='red', marker='*', s=marker_size, edgecolor='white',linewidth=1.25) # 背景的标记点显示def show_box(box, ax):# 画出标定框 x0 y0是起始坐标x0, y0 = box[0], box[1]# w h 是框的尺寸w, h = box[2] - box[0], box[3] - box[1]ax.add_patch(plt.Rectangle((x0, y0), w, h, edgecolor='green', facecolor=(0, 0, 0, 0), lw=2))import sys
sys.path.append("..")
from segment_anything import sam_model_registry, SamPredictorimage = cv2.imread('img.png')
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)#------加载模型
# 权重文件保存地址
sam_checkpoint = "model_save/sam_vit_b_01ec64.pth"
# sam_checkpoint = "model_save/sam_vit_h_4b8939.pth"
# sam_checkpoint = "model_save/sam_vit_l_0b3195.pth"
# 模型类型
model_type = "vit_b"
# model_type = "vit_h"
# model_type = "vit_l"
device = "cuda"
sam = sam_model_registry[model_type](checkpoint=sam_checkpoint)
sam.to(device=device)
predictor = SamPredictor(sam)
predictor.set_image(image)
#------加载模型# 标定框的起始坐标和终点坐标
input_box = np.array([112, 41, 373, 320])
# 鼠标标定(x,y)位置
# 因为可以有多个标定,所以有多个坐标点
input_point = np.array([[230, 194], [182, 63], [339, 279]])
# 1表示前景目标,0表示背景
# input_point和input_label一一对应
input_label = np.array([1, 1, 0])# 标定框和标记点联合使用
masks, _, _ = predictor.predict(point_coords=input_point,point_labels=input_label,box=input_box,multimask_output=False,
)plt.figure(figsize=(10, 10))
plt.imshow(image)
show_mask(masks[0], plt.gca())
show_box(input_box, plt.gca())
show_points(input_point, input_label, plt.gca())
plt.axis('off')
plt.show()

步骤六:多标定框完成前景目标的分割
可以是多标定框对应多个目标,也可以是多标定框对应同一目标的不同部位。
import numpy as np
import matplotlib.pyplot as plt
import torch
import cv2def show_mask(mask, ax, random_color=False):if random_color: # 掩膜颜色是否随机决定color = np.concatenate([np.random.random(3), np.array([0.6])], axis=0)else:color = np.array([30 / 255, 144 / 255, 255 / 255, 0.6])h, w = mask.shape[-2:]mask_image = mask.reshape(h, w, 1) * color.reshape(1, 1, -1)ax.imshow(mask_image)def show_points(coords, labels, ax, marker_size=375):# 筛选出前景目标标记点pos_points = coords[labels == 1]# 筛选出背景目标标记点neg_points = coords[labels == 0]# x-->pos_points[:, 0] y-->pos_points[:, 1]ax.scatter(pos_points[:, 0], pos_points[:, 1], color='green', marker='*', s=marker_size, edgecolor='white',linewidth=1.25) # 前景的标记点显示ax.scatter(neg_points[:, 0], neg_points[:, 1], color='red', marker='*', s=marker_size, edgecolor='white',linewidth=1.25) # 背景的标记点显示def show_box(box, ax):# 画出标定框 x0 y0是起始坐标x0, y0 = box[0], box[1]# w h 是框的尺寸w, h = box[2] - box[0], box[3] - box[1]ax.add_patch(plt.Rectangle((x0, y0), w, h, edgecolor='green', facecolor=(0, 0, 0, 0), lw=2))import sys
sys.path.append("..")
from segment_anything import sam_model_registry, SamPredictorimage = cv2.imread('img.png')
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)#------加载模型
# 权重文件保存地址
sam_checkpoint = "model_save/sam_vit_b_01ec64.pth"
# sam_checkpoint = "model_save/sam_vit_h_4b8939.pth"
# sam_checkpoint = "model_save/sam_vit_l_0b3195.pth"
# 模型类型
model_type = "vit_b"
# model_type = "vit_h"
# model_type = "vit_l"
device = "cuda"
sam = sam_model_registry[model_type](checkpoint=sam_checkpoint)
sam.to(device=device)
predictor = SamPredictor(sam)
predictor.set_image(image)
#------加载模型# 存在多个目标标定框
input_boxes = torch.tensor([[121, 49, 361, 190],[143, 101, 308, 312],[366, 116, 451, 233],
], device=predictor.device)transformed_boxes = predictor.transform.apply_boxes_torch(input_boxes, image.shape[:2])
masks, _, _ = predictor.predict_torch(point_coords=None,point_labels=None,boxes=transformed_boxes,multimask_output=False,
)
plt.figure(figsize=(10, 10))
plt.imshow(image)
for mask in masks:show_mask(mask.cpu().numpy(), plt.gca(), random_color=True)
for box in input_boxes:show_box(box.cpu().numpy(), plt.gca())
plt.axis('off')
plt.show()

步骤六:图片批量完成前景目标的分割
源码支持图片的批量输入,大大提升了分割效率。
import numpy as np
import matplotlib.pyplot as plt
import torch
import cv2def show_mask(mask, ax, random_color=False):if random_color: # 掩膜颜色是否随机决定color = np.concatenate([np.random.random(3), np.array([0.6])], axis=0)else:color = np.array([30 / 255, 144 / 255, 255 / 255, 0.6])h, w = mask.shape[-2:]mask_image = mask.reshape(h, w, 1) * color.reshape(1, 1, -1)ax.imshow(mask_image)def show_points(coords, labels, ax, marker_size=375):# 筛选出前景目标标记点pos_points = coords[labels == 1]# 筛选出背景目标标记点neg_points = coords[labels == 0]# x-->pos_points[:, 0] y-->pos_points[:, 1]ax.scatter(pos_points[:, 0], pos_points[:, 1], color='green', marker='*', s=marker_size, edgecolor='white',linewidth=1.25) # 前景的标记点显示ax.scatter(neg_points[:, 0], neg_points[:, 1], color='red', marker='*', s=marker_size, edgecolor='white',linewidth=1.25) # 背景的标记点显示def show_box(box, ax):# 画出标定框 x0 y0是起始坐标x0, y0 = box[0], box[1]# w h 是框的尺寸w, h = box[2] - box[0], box[3] - box[1]ax.add_patch(plt.Rectangle((x0, y0), w, h, edgecolor='green', facecolor=(0, 0, 0, 0), lw=2))def prepare_image(image, transform, device):image = transform.apply_image(image)image = torch.as_tensor(image, device=device.device)return image.permute(2, 0, 1).contiguous()import sys
sys.path.append("..")
from segment_anything import sam_model_registry, SamPredictorimage1 = cv2.imread('img.png')
image1 = cv2.cvtColor(image1, cv2.COLOR_BGR2RGB)
image2 = cv2.imread('img_1.png')
image2 = cv2.cvtColor(image2, cv2.COLOR_BGR2RGB)#------加载模型
# 权重文件保存地址
sam_checkpoint = "model_save/sam_vit_b_01ec64.pth"
# sam_checkpoint = "model_save/sam_vit_h_4b8939.pth"
# sam_checkpoint = "model_save/sam_vit_l_0b3195.pth"
# 模型类型
model_type = "vit_b"
# model_type = "vit_h"
# model_type = "vit_l"
device = "cuda"
sam = sam_model_registry[model_type](checkpoint=sam_checkpoint)
sam.to(device=device)
from segment_anything.utils.transforms import ResizeLongestSide
resize_transform = ResizeLongestSide(sam.image_encoder.img_size)
#------加载模型# 存在多个目标标定框
image1_boxes = torch.tensor([[121, 49, 361, 190],[143, 101, 308, 312],[366, 116, 451, 233],
], device=sam.device)image2_boxes = torch.tensor([[24, 4, 333, 265],
], device=sam.device)# 批量输入
batched_input = [{'image': prepare_image(image1, resize_transform, sam),'boxes': resize_transform.apply_boxes_torch(image1_boxes, image1.shape[:2]),'original_size': image1.shape[:2]},{'image': prepare_image(image2, resize_transform, sam),'boxes': resize_transform.apply_boxes_torch(image2_boxes, image2.shape[:2]),'original_size': image2.shape[:2]}
]
batched_output = sam(batched_input, multimask_output=False)fig, ax = plt.subplots(1, 2, figsize=(20, 20))# 批量输出
ax[0].imshow(image1)
for mask in batched_output[0]['masks']:show_mask(mask.cpu().numpy(), ax[0], random_color=True)
for box in image1_boxes:show_box(box.cpu().numpy(), ax[0])
ax[0].axis('off')ax[1].imshow(image2)
for mask in batched_output[1]['masks']:show_mask(mask.cpu().numpy(), ax[1], random_color=True)
for box in image2_boxes:show_box(box.cpu().numpy(), ax[1])
ax[1].axis('off')
plt.tight_layout()
plt.show()

automatic_mask_generator_example
源码在notebooks文件内提供了一个Jupyter Notebook的自动分割教程,无需标定点和标定框的。
automatic_mask_generator_example.ipynb源码在notebooks文件目录下,可以本地运行测试或者直接在githup上查看教程。
步骤一:自动掩码生成
import numpy as np
import torch
import matplotlib.pyplot as plt
import cv2image = cv2.imread('img.png')
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)# 权重文件保存地址
sam_checkpoint = "model_save/sam_vit_b_01ec64.pth"
# sam_checkpoint = "model_save/sam_vit_h_4b8939.pth"
# sam_checkpoint = "model_save/sam_vit_l_0b3195.pth"
# 模型类型
model_type = "vit_b"
# model_type = "vit_h"
# model_type = "vit_l"
device = "cuda"def show_anns(anns):if len(anns) == 0:returnsorted_anns = sorted(anns, key=(lambda x: x['area']), reverse=True)ax = plt.gca()ax.set_autoscale_on(False)polygons = []color = []for ann in sorted_anns:m = ann['segmentation']img = np.ones((m.shape[0], m.shape[1], 3))color_mask = np.random.random((1, 3)).tolist()[0] # 产生随机颜色的maskfor i in range(3):img[:, :, i] = color_mask[i]ax.imshow(np.dstack((img, m*0.35)))from segment_anything import sam_model_registry, SamAutomaticMaskGenerator, SamPredictor
sam = sam_model_registry[model_type](checkpoint=sam_checkpoint)
sam.to(device=device)mask_generator = SamAutomaticMaskGenerator(sam)
masks = mask_generator.generate(image)plt.figure(figsize=(20, 20))
plt.imshow(image)
show_anns(masks)
plt.axis('off')
plt.show()

步骤一:自动掩码生成参数调整
在自动掩模生成中有几个可调参数,用于控制采样点的密度以及去除低质量或重复掩模的阈值。此外,生成可以在图像的裁剪上自动运行,以提高较小对象的性能,后处理可以去除杂散像素和孔洞。
import numpy as np
import torch
import matplotlib.pyplot as plt
import cv2image = cv2.imread('img.png')
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)# 权重文件保存地址
sam_checkpoint = "model_save/sam_vit_b_01ec64.pth"
# sam_checkpoint = "model_save/sam_vit_h_4b8939.pth"
# sam_checkpoint = "model_save/sam_vit_l_0b3195.pth"
# 模型类型
model_type = "vit_b"
# model_type = "vit_h"
# model_type = "vit_l"
device = "cuda"def show_anns(anns):if len(anns) == 0:returnsorted_anns = sorted(anns, key=(lambda x: x['area']), reverse=True)ax = plt.gca()ax.set_autoscale_on(False)polygons = []color = []for ann in sorted_anns:m = ann['segmentation']img = np.ones((m.shape[0], m.shape[1], 3))color_mask = np.random.random((1, 3)).tolist()[0] # 产生随机颜色的maskfor i in range(3):img[:, :, i] = color_mask[i]ax.imshow(np.dstack((img, m*0.35)))from segment_anything import sam_model_registry, SamAutomaticMaskGenerator, SamPredictor
sam = sam_model_registry[model_type](checkpoint=sam_checkpoint)
sam.to(device=device)# 默认版本
# mask_generator = SamAutomaticMaskGenerator(sam)
# 自定义参数版本
mask_generator_2 = SamAutomaticMaskGenerator(model=sam,points_per_side=32,pred_iou_thresh=0.86,stability_score_thresh=0.92,crop_n_layers=1,crop_n_points_downscale_factor=2,min_mask_region_area=100, # Requires open-cv to run post-processing
)masks = mask_generator_2.generate(image)plt.figure(figsize=(20, 20))
plt.imshow(image)
show_anns(masks)
plt.axis('off')
plt.show()

总结
尽可能简单、详细的介绍了SAM的安装流程以及SAM官方的基本使用方法。后续会根据自己学到的知识结合个人理解讲解SAM的原理和代码,目前只是拙劣的使用。
相关文章:
【图片分割】【深度学习】Windows10下SAM官方代码Pytorch实现
【图片分割】【深度学习】Windows10下SAM官方代码Pytorch实现 提示:最近开始在【图片分割】方面进行研究,记录相关知识点,分享学习中遇到的问题已经解决的方法。 文章目录【图片分割】【深度学习】Windows10下SAM官方代码Pytorch实现前言SAM模型运行环境安装打开cmd,执行下面的…...
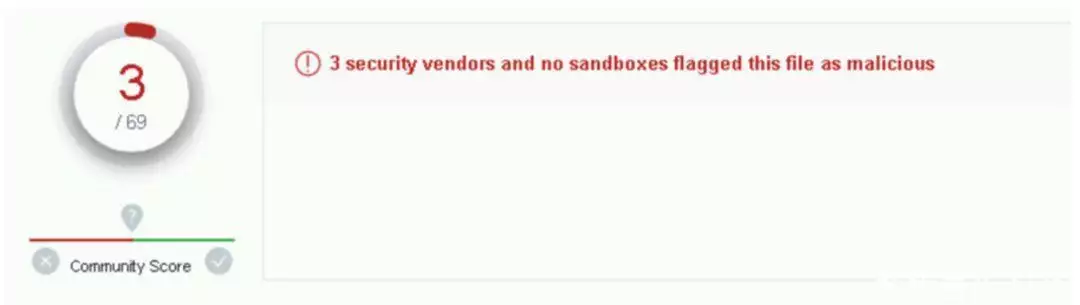
“我用 ChatGPT 造了一个零日漏洞,成功逃脱了 69 家安全机构的检测!”
一周以前,图灵奖得主 Yoshua Bengio、伯克利计算机科学教授 Stuart Russell、特斯拉 CEO 埃隆马斯克、苹果联合创始人 Steve Wozniak 等在内的数千名 AI 学者、企业家联名发起一则公开信,建议全球 AI 实验室立即停止训练比 GPT-4 更强大的模型࿰…...
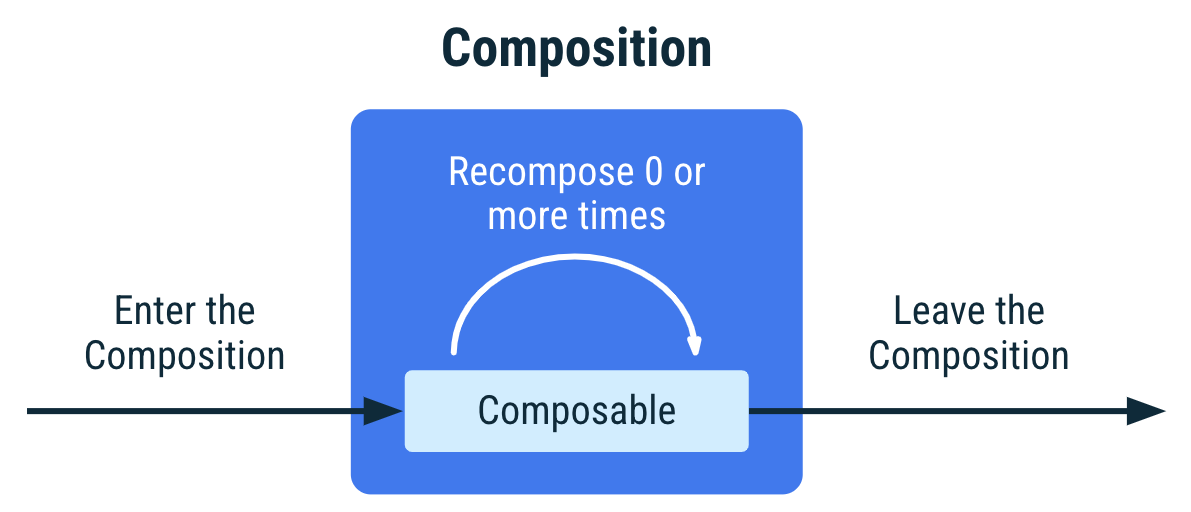
Compose (14/N) - 附带效应 EffectPI
一、概念 纯函数函数与外界交换数据只能通过形参和返回值进行,不会对外界环境产生影响。副作用函数内部与外界进行了交互,产生了其它结果(如修改外部变量)。组合函数是用来声明UI的,所以跟UI描述不相关的操作都是副作…...

云日记个人中心项目思路
验证昵称的唯一性 前台: 昵称文本框的失焦事件 blur 1. 获取昵称文本框的值 2. 判断值是否为空 如果为空,提示用户,禁用按钮,并return 3. 判断昵称是否做了修改…...
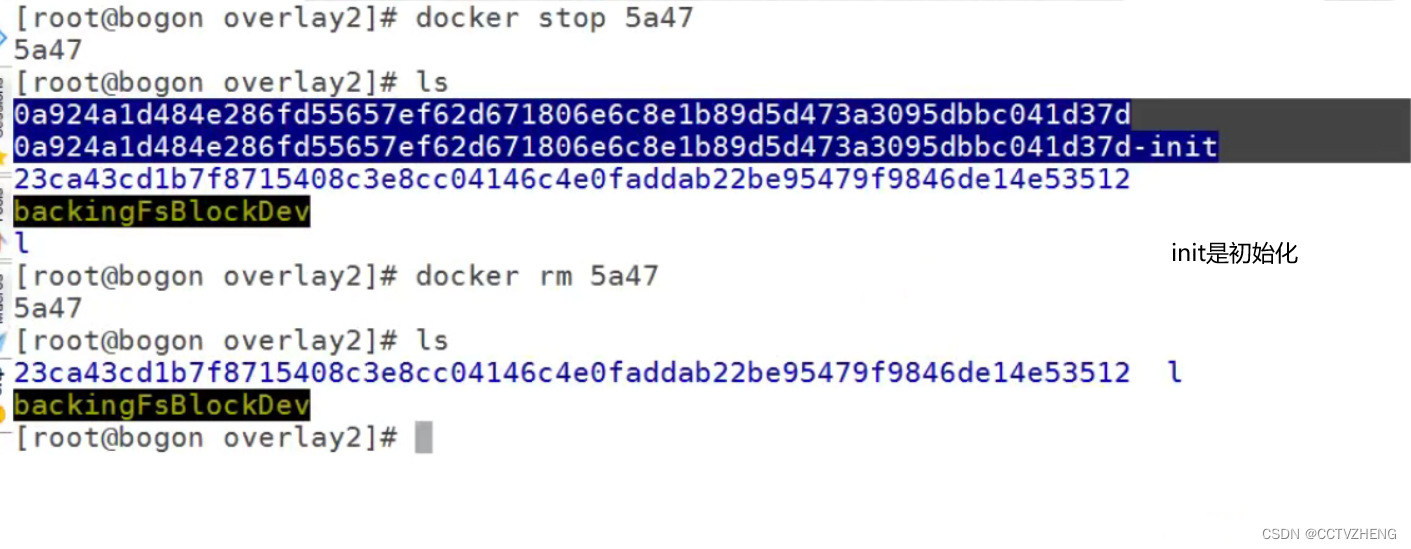
docker容器的相关环境及创建镜像1
一、容器管理工具介绍 LXC 2008 是第一套完整的容器管理解决方案 不需要任何补丁直接运行在linux内核之上管理容器。创建容器慢,不方便移植 Docker 是在LXC基础上发展起来的。拥有一套容器管理生态系统 生态系统包含︰容器镜像、注册表、RESTFUL API及命令行操作界…...
如何使用ChatGPT在1天内完成毕业论文
如何使用ChatGPT在1天内完成毕业论文 几天前,亲眼见证了到一位同学花了1天时间用ChatGPT完成了他的毕业论文,世道要变,要学会使用黑科技才能混的下去。废话到此结束,下面说明这么用AI生成自己的论文。 使用工具: 1. P…...

Debezium同步之实时数据采集必备工具
目录 简介 基础架构图片 Kafka Connect Debezium 特性 抽取原理 简介 RedHat(红帽公司) 开源的 Debezium 是一个将多种数据源实时变更数据捕获,形成数据流输出的开源工具。 它是一种 CDC(Change Data Capture)工具,工作原理类似大家所熟知的 Canal, DataBus, Maxwell…...
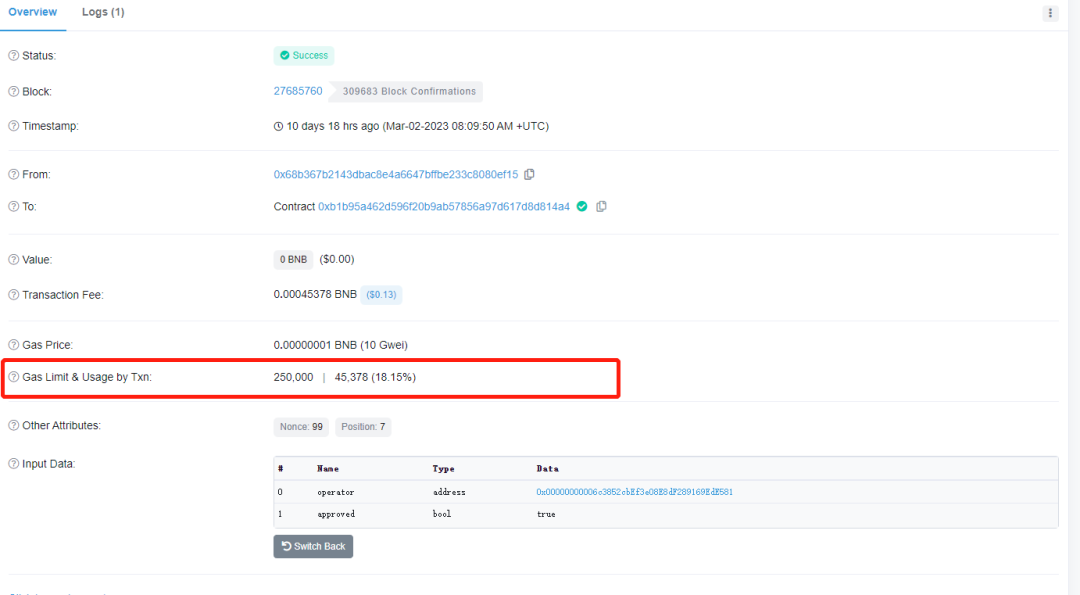
【区块链】走进web3的世界-gas费用
气体单位用于衡量在以太坊上执行交易所需的计算量。由于每笔交易都需要一些计算资源来执行,因此需要一笔费用,通常称为Gas fee或Transaction fee 。 汽油费以以太坊的本地货币——ether或ETH支付。汽油费的计算方式在伦敦升级前后略有不同。 注意&#…...

世界上最大的手工艺品连锁零售商Michaels验厂总结
【世界上最大的手工艺品连锁零售商Michaels验厂总结】 Michaels是世界上最大的手工艺品连锁企业,公司的总部位于美国德克萨斯州的Irving,公司现在有员工12500人。在美国49个州和加拿大经营着1200多家Michaels工艺品的连锁店。每家商店平均销售面积约为18…...
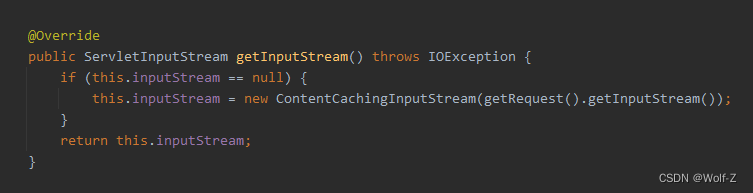
springboot如何优雅的打印项目日志
文章目录如何优雅的打印项目日志原理实现日志打印Filter注入容器如何优雅的打印项目日志 框架 springboot 原理 使用filter拦截请求,打印出请求、响应,及耗时 知识点 1、OncePerRequestFilter Filter base class that aims to guarantee a single …...

【JAVA程序设计】(C00127)基于SSM+vue开发的音乐播放管理系统-有文档
基于SSMvue开发的音乐管理系统-有文档项目简介项目获取开发环境项目技术运行截图项目简介 基于ssm框架vue以及html前台的开发的音乐管理系统共分为二个角色:管理员、用户 管理员角色包含以下功能: 登录、个人中心(修改密码、个人信息修改&am…...
C#|调用C/C++动态库
参考:C#总结(四)调用C动态库(https://www.shuzhiduo.com/A/A2dmV49qze/) 文章目录C#加载C动态库C#加载C#动态库涉及到的概念知识:托管DLL和非托管DLL的区别(https://www.tinymind.net.cn/articl…...
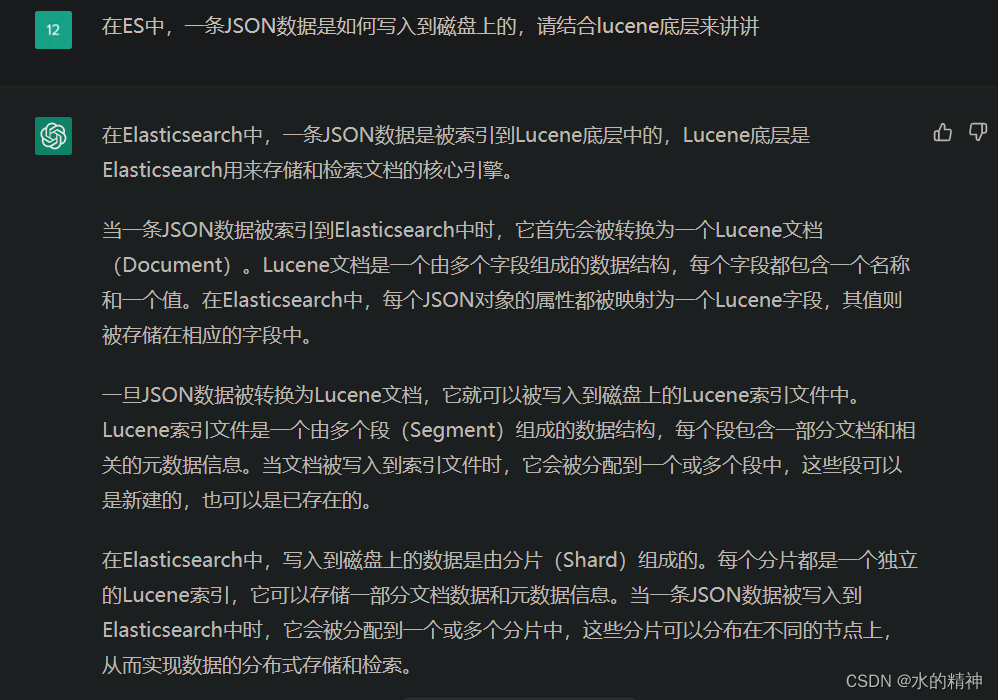
让chatGPT当我的老师如何? 通过和chatGPT交互式学习,了解在ES中,一条JSON数据是如何写到磁盘上的
最近一直有一个问题,如鲠在喉。争取早一天解决,早一天踏踏实实的睡觉。 问题是:在ES中,一条JSON数据是如何写入到磁盘上的? 如何解决这个问题?我想到了chatGPT,还有lucene的学习资料。这篇文章&…...
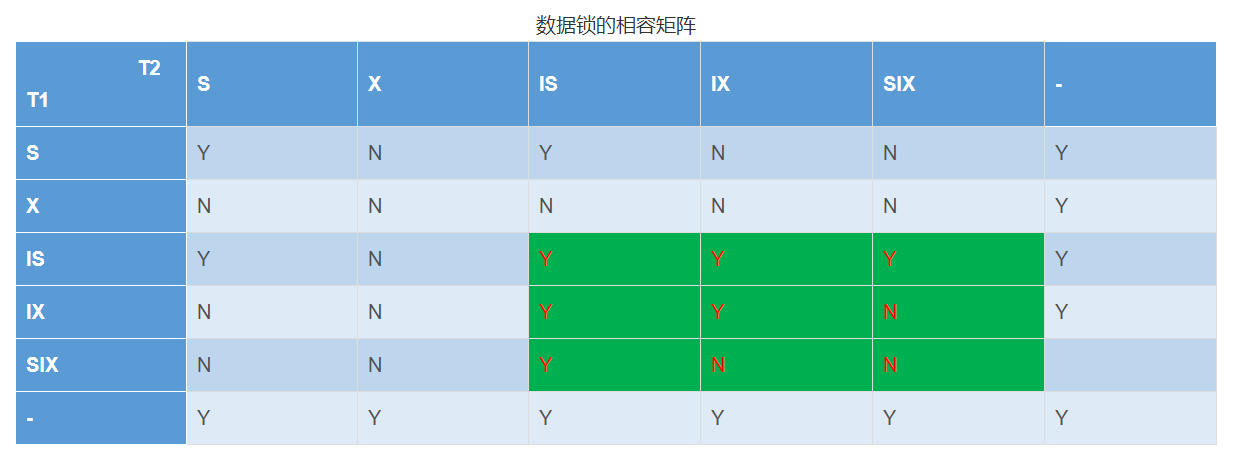
chapter-7数据库事务
以下课程来源于MOOC学习—原课程请见:数据库原理与应用 考研复习 DBMS保证系统中一切事务的原子性、一致性、隔离性和持续性 DBMS必须对事务故障、系统故障和介质故障进行恢复 恢复中最经常使用的技术:数据库转储和登记日志文件 恢复的基本原理&#…...

阿里本地生活再出发:口碑入高德,备战美团、抖音
配图来自Canva可画 近日,有传言称高德地图将和阿里本地生活旗下的到店业务口碑正式合并,未来阿里旗下所有的本地生活到店业务都将统一整合在高德地图的入口中。3月22日,高德地图正式确认了此事,并表示高德地图作为“出门好生活开…...
SSM学习记录3:响应(注释方式 + SprigMVC项目 + 2022发布版本IDEA)
响应 ResponseBody注解的作用是将当前控制器中方法的返回值作为响应体 1.返回页面 无需在方法上进行ResponseBody注解,只需RequestMapping匹配地址,并且返回值为带后缀的页面名字符串 前面学习中除了json数据,所有带ResponseBody注解的方法…...

Linux·gcc 编译优化简介
1、gcc 编译优化简介 gcc 提供了为了满足用户不同程度的的优化需要,提供了近百种优化选项,用来对 { 编译时间,目标文件长度,执行效率 } 这个三维模型进行不同的取舍和平衡。优化的方法不一而足,总体上将有以下几类&…...

【电子学会】2022年12月图形化一级 -- 潜水
潜水 暑假小雨和爸爸去玩了潜水,他见到了各种各样的海洋生物。 1. 准备工作 (1)添加背景“Underwater 2”; (2)删除小猫角色,添加角色“Diver2”、“Fish”、“Jellyfish”、“Shark”; (3)为背景添加声音“Xylo2”。 2. 功能实现 (1)点击绿旗,播放背景音乐…...
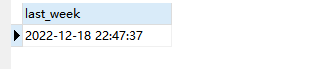
MySQL日期时间函数汇总、时间格式转换方法
MySQL日期时间函数汇总、时间格式转换方法时间函数日期时间格式转换date_format函数EXTRACT()DATE_ADD()DATE_SUB()DATEDIFF函数时间函数 函数描述NOW()返回当前的日期和时间CURDATE()返回当前的日期CURTIME()返回当前的时间DATE()返回日期或日期/时间表达式的日期部分HOUR()获…...
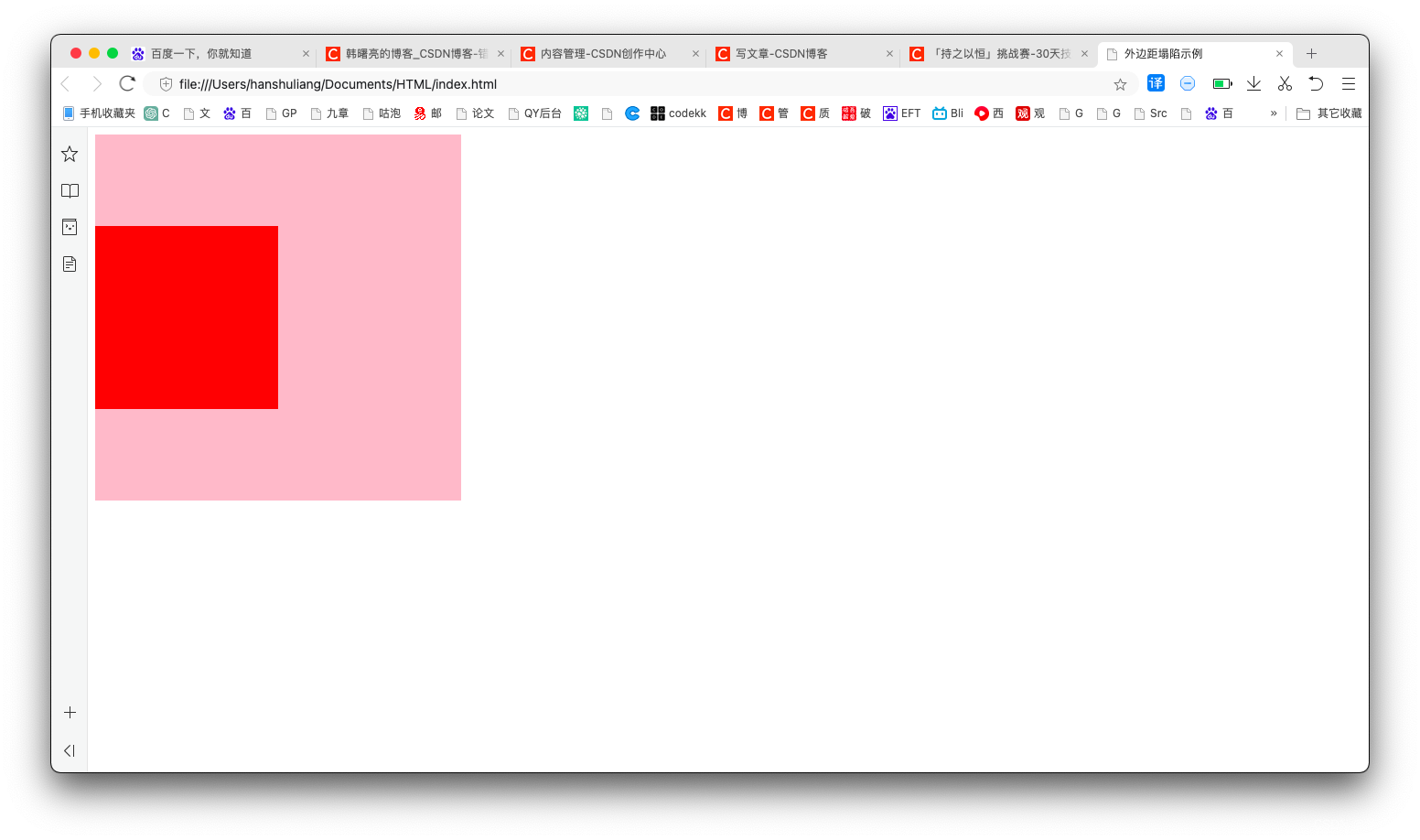
【CSS】使用绝对定位 / 浮动解决外边距塌陷问题 ( 为父容器 / 子元素设置内边距 / 边框 | 为子元素设置浮动 | 为子元素设置绝对定位 )
文章目录一、外边距塌陷描述1、没有塌陷的情况2、外边距塌陷情况二、传统方法解决外边距塌陷 - 为父容器 / 子元素设置内边距 / 边框三、使用浮动解决外边距塌陷 - 为子元素设置浮动四、使用绝对定位解决外边距塌陷 - 为子元素设置绝对定位一、外边距塌陷描述 在 标准流的父盒子…...

StockSharp开源量化交易平台:C#/.NET生态的一站式解决方案
1. 项目概述:一个开源的量化交易与市场数据平台 如果你在金融科技、量化交易或者自动化交易系统开发领域摸爬滚打过一段时间,那么“StockSharp”这个名字大概率会出现在你的雷达上。它不是一个简单的库,而是一个庞大、成熟且野心勃勃的开源项…...

Wand-Enhancer:解锁WeMod全部潜力的开源增强工具
Wand-Enhancer:解锁WeMod全部潜力的开源增强工具 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 在游戏辅助工具的世界里,WeMod无…...

阿里HR面被问:“说下怎么设计一个招聘Agent”?”我愣了一下,从概念、核心模块和坑都娓娓道来,这波应该稳了
前些天一个研究生的师妹面了Agent岗位,最后一面。就是HR面,不过这个HR竟然问到了一个技术问题:“你可否介绍下如果你来设计一个招聘Agent,你会怎么做”。师妹当时还挺惊讶的,因为理论上这一论不会面技术的,…...

AI Agent技能开发实战:将安全审计工具封装为智能体可调用模块
1. 项目概述:从代码仓库到AI技能生态的跨越最近在GitHub上闲逛,发现了一个挺有意思的项目:nsasoft/nsauditor-ai-agent-skill。乍一看,这名字有点“缝合怪”的感觉,把“nsasoft”、“nsauditor”、“AI Agent”和“ski…...

生物记录仪能耗优化:机器学习与传感器融合实践
1. 生物记录仪能耗挑战与机器学习解决方案在野生动物行为研究领域,生物记录仪(bio-logger)已成为不可或缺的工具。这些小型电子设备通常搭载多种传感器,如加速度计、陀螺仪和磁力计等,用于记录动物的运动轨迹和行为模式。然而,这类…...

Godot 4动态网格切割:实现实时物理破坏效果
1. 项目概述与核心价值 最近在Godot社区里,一个名为 cloudofoz/godot-smashthemesh 的开源项目引起了我的注意。乍一看这个标题,可能会觉得有些抽象——“粉碎网格”?但当你深入了解后,会发现它精准地解决了一个在3D游戏开发&am…...

【Linux系统编程】Ext2文件系统
上图中的外设,每个设备都可以有自己的read、write,但一定是对应着不同的操作方法!!但通过struct file 下 file_operation 中的各种函数回调,让我们开发者只用file便可调取 Linux 系统中绝⼤部分的资源!&…...

单片机开发者如何通过Taotoken快速接入大模型API提升代码效率
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 单片机开发者如何通过Taotoken快速接入大模型API提升代码效率 对于单片机开发者而言,嵌入式开发工作往往伴随着大量重复…...

Chapter 13:企业实战 - 完整案例演练
Chapter 13:企业实战 - 完整案例演练 学习目标 掌握从需求分析到落地实施的完整流程 能够综合运用 Rules、Skills、MCP、Subagent 理解企业级项目的完整解决方案设计 具备独立设计企业扩展方案的能力 概念讲解(Why) 1.1 实战演练概述 案例背景: 某电商公司"极速商…...

现代开发脚手架Forge:可组合蓝图与插件化架构解析
1. 项目概述:一个能“自动施法”的开发脚手架如果你是一名开发者,尤其是经常需要从零开始搭建新项目的前端或全栈工程师,那么“重复造轮子”和“繁琐的初始化配置”这两个词,一定是你职业生涯中挥之不去的梦魇。每次新建一个项目&…...