chapter-7数据库事务
以下课程来源于MOOC学习—原课程请见:数据库原理与应用
考研复习
DBMS保证系统中一切事务的原子性、一致性、隔离性和持续性
DBMS必须对事务故障、系统故障和介质故障进行恢复
恢复中最经常使用的技术:数据库转储和登记日志文件
恢复的基本原理:利用存储在后备副本、日志文件和数据库镜像中的冗余数据来重建数据库
常用恢复技术
事务故障的恢复(UNDO)
系统故障的恢复(UNDO + REDO)
介质故障的恢复(重装备份并恢复到一致性状态 + REDO)
提高恢复效率的技术 检查点技术(
Ø可以提高系统故障的恢复效率
Ø可以在一定程度上提高利用动态转储备份进行介质故障恢复的效率)
镜像技术(镜像技术可以改善介质故障的恢复效率)
事务
定义的一个数据库操作序列,这些操作要么全做,要不都不做,不可分割
当多条SQL语句必须当作一个整体执行才能实现它的功能时,需要定义一个事务
目的:维护企业状态 和 数据库状态一致的与数据库交互的程序
事务是数据库系统的逻辑工作单元
定义事务
begin transaction
sql 语句序列
commit #提交事务,事务中所有操作均成功执行
rollback #回滚事务,事务夭折,不能继续执行,已经执行的更新操作撤销,恢复至原先状态
begin transactionupdate accounts set bal=bal-100 where accno='A'update accounts set bal=bal+100 where accno='b'//转账业务
commit
//只有两种结果:要么提交;要么回滚
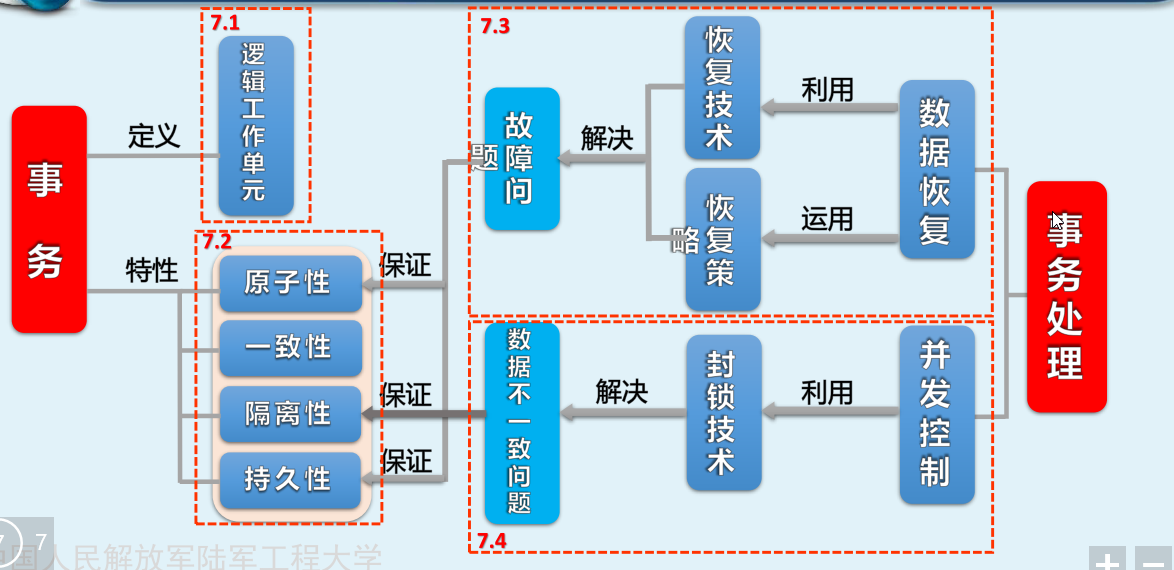
事务特性ACID
原子性:Atomicity
- 事务所有数据库操作 不可分割
- 所有操作要么都执行完;要么没有执行
一致性:Consistency
- 数据库的当前实例状态也是数据库的状态
- 用户对数据库操作 是从一个状态 到另一个状态
- 数据库初始状态是一致的
- 满足数据库的完整性约束;反映用户对数据库的操作
- 应用程序员的基本职责;维护企业状态 和 数据库状态一致
隔离性:Isolation
- 多用户的数据库系统 允许 多个事务并发执行
- 提高系统事务吞吐量,减少事务等待时间
- 并发执行的 事务中 的数据库 操作 可能会交错执行,可能会对同一个数据对象操作
- 隔离性就是指:一个事务正常执行而不被来自并发执行的数据库操作干扰,例如12306抢票
比如:若在并发执行的一个事务中,同一个查询的两次查询结果不一样, 请问是由于事务没有保持什么特性造成的?
持久性:Durability
- 事务一旦提交,事务对数据库的更新操作 永久保持在数据库(银行存钱的数据不能因为停电没)
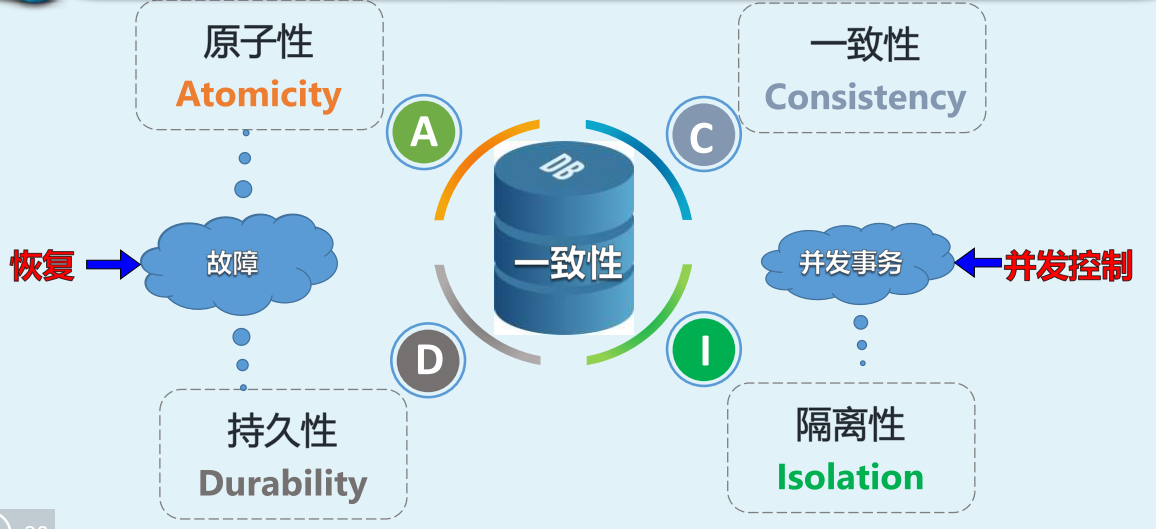
恢复机制
对发生故障后,对已经成功的结果进行恢复,保持原子性和持久性
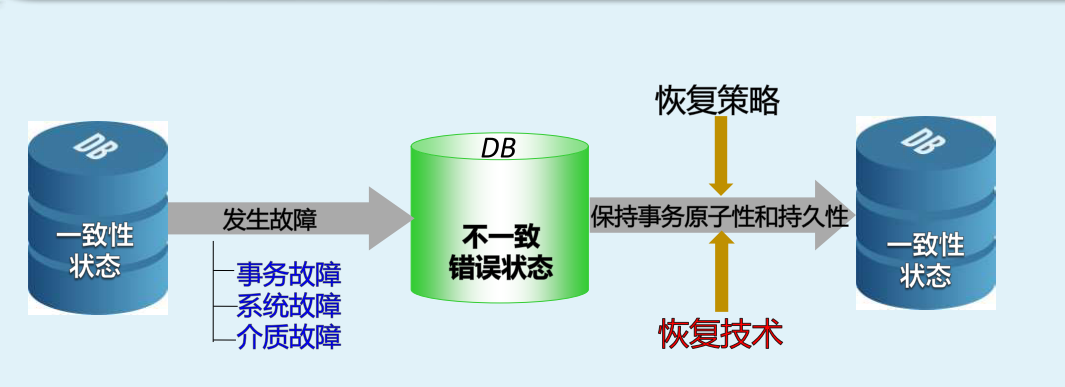
故障类型及原因
1.事务故障:执行过程中发生错误,导致事务夭折
- 内部错误:事物内部操作受限【违反完整性约束,访问不到数据,运算溢出】
- 系统错误:
- 破坏原子性
2.系统故障
- 造成系统停止运转的事件等,比如CPU故障,DBMS代码错误,操作系统故障
- 容易造成存储器内容丢失
- 破坏原子性,破坏持久性(已经更新的结果可能还在缓冲区未写入磁盘)
3.介质故障:使数据存储介质 完全毁坏的硬故障
比如数据库服务器毁坏,瞬时磁场干扰,磁头碰撞损坏,等
破坏持久性(已经更新的结果不能持久写入磁盘中)
4.不一致错误
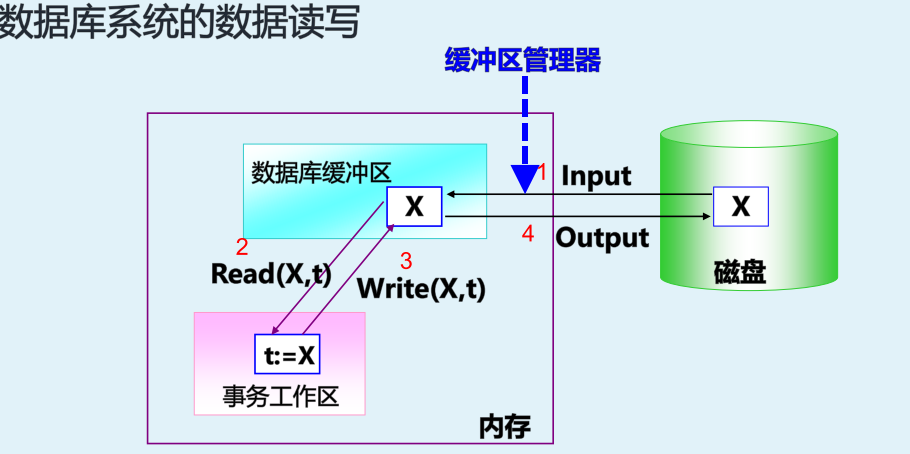
窃取/不强制的缓冲区管理策略【缓冲器置换算法比如LRU】
1.为了从磁盘上输入事务B 所需要的数据放到内存,需要先将未提交的事务A所处理的数据输出到磁盘上,以腾出空间给B,即B窃取A的空间
2.事务提交狗,更新结果没有及时到磁盘上,即不强制的执行output操作
窃取/不强制的缓冲区管理策略导致:
1.事务提交之前, 部分执行结果可能已经被更新到数据库中
2.事务提交后,事务执行结果并没有立即更新到磁盘中
- 破坏事务的原子性和持久性、
问:如果缓冲区管理器不采用课件里的窃取/不强制的管理策略,而采用延迟更新策略,即直到事务提交,更新结果才会被写到数据库中,那么发生故障后,系统中不一致错误状态表现是什么?
答:已提交的事务对数据库的更新结果有一部分甚至全部还在缓冲区中,尚未写到磁盘上的数据库中,破坏了事务的持久性。或者已提交的事务对数据库的更新结果不能持久的保存在磁盘上,破坏了事务的持久性
问:更新日志记录:如果缓冲区管理器不采用课件里的窃取/不强制的管理策略,而采用延迟更新策略,即直到事务提交,更新结果才会被写到数据库中,那么更新日志记录里是否仍需要包括更新前的值?
答:不需要,如果磁盘上的数据库中有更新后的值,说明事物已成功提交,因此在恢复时不需要做UNDO操作,也不需要存储更新前的值
恢复策略
日志
每个数据库维护一个日志,记录所有事务对该数据更新操作
格式:1. 以记录为单位的日志文件(事务标识,操作类型,操作对象,更新前数据的旧值,更新后数据的新值);
2.以数据表为单位的日志文件(事务标识,被更新的数据块)
内容:1 各个事务的开始标记;2 各个事务的结束标记;3 各个事务所有的更新操作
作用:1 进行事务故障恢复;2 进行系统故障恢复;3 协助后备副本进行介质故障恢复
注:日志记录的登记社会魂虚必须严格按照各个事务的操作执行的先后
注:更新之前,需要将日志记录先写入
数据转储
转储是指DBA将整个数据库复制到磁带或另一个磁盘上保存起来的过程,
备用的数据成为后备副本或后援副本
数据转储的使用
数据库遭到破坏后可以将后备副本重新装入;重装后备副本只能将数据库恢复到转储时的状态
转储方法
1.静态转储
- 系统中无运行事务时进行的转储操作;转储期间不允许对数据库进行操作
- 转储开始时数据库处于一致性状态
- 得到的一定是一个数据一致性的副本
优点:实现简单
缺点:1.降低了数据库的可用性 2.转储必须等待正运行的用户事务结束 3.新的事务必须等转储结束
2.动态转储
- 转储操作与用户并发进行
- 转储期间允许对数据库进行存取或修改
优点:1.不用等待正在进行的事务结束 2.转储期间允许对数据库进行存取或修改
缺点:不能保证副本中的数据正确有效
**动态转储进行故障恢复,**需要把动态转储期间各事务对数据库的修改活动登记下来,建立日志文件;后备副本加上日志文件才能把数据库恢复到某一时刻的正确状态
海量转储:每次转储全部数据库,又称完全转储
增量转储:只转储上次转储之后,更新过的数据
海量转储与增量转储的比较
1.从恢复角度看,使用海量转储得到的后备副本进行恢复往往更方便
2.如果数据库很大,事务处理又十分频繁,则增量转储更有效
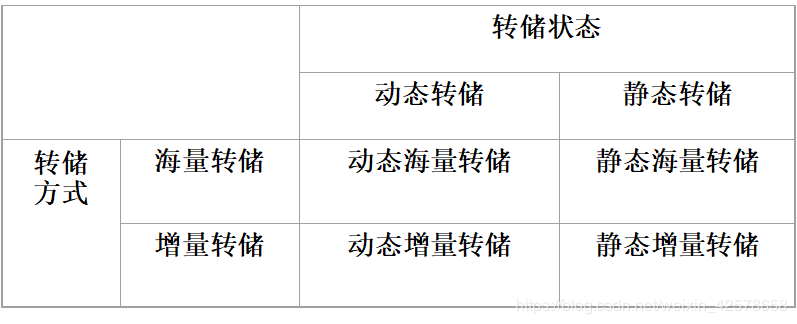
利用静态转储副本和日志文件进行恢复
对上图进行说明:
- 系统在Ta时刻停止运行事务,进行数据库转储
- 在Tb时刻转储完毕,得到Tb时刻的数据库一致性副本
- 系统运行到Tf时刻发生故障
- 为恢复数据库,首先由DBA重装数据库后备副本,将数据库恢复到Tb时刻的状态
- 重新运行自Tb~Tf时刻的所有更新事务,把数据库恢复到故障发生前的一致状态
数据的不一致错误导致
- 夭折的事务 部分执行结果 已经更新数据库;需要撤销
- 已经提交的事务,对数据库的更新结果可能有一部分甚至全部还在缓冲区中,尚未写入磁盘;需要执行
撤销事务UNDO
- 利用日志撤销事务对数据库的更新**,更新前旧值写回**
- 保持事务原子性,事务以rollback方式结束
重做事务REDO
- 利用日志对数据库的更新,更新后的新值写入
- 保持事务持久性,事务以commit方式结束
事务故障后恢复UNDO
事务故障:事务运行至正常终止点前被终止
恢复方法:由恢复子系统利用日志文件撤销(UNDO)此事务已对数据库进行的修改
注:事务故障的恢复由系统自动完成,对用户是透明的,不需要用户干预
恢复步骤
- **反向扫描文件日志(**从后往前扫描),查找该事务的更新操作
- 对该事务的更新操作执行逆操作,即将日志记录中“更新前的值”写入数据库
- 继续反向扫描日志文件,查找该事务的其他更新操作,并做同样处理。
- 如此处理下去,直至读到此事务的开始标记,事务故障恢复就完成了。
系统故障后恢复UNDO+REDO
系统故障:
- 未完成事务对数据库的更新已写入数据库
- 已提交事务对数据库的更新还留在缓存区没来得及写入数据库
恢复方法:
- UNDO故障发生时未完成的事务
- Redo已完成的事务
注:系统故障的恢复由系统在重新启动时自动完成,不需要用户干预
恢复步骤:
- 正向扫描日志文件(1.将在故障发生前已经提交的事务加入重做(REDO)队列,这些事务既有begin transaction记录,也有commit记录;2.将在故障发生时未完成的事务加入撤销(Undo)队列,这些事务中只有begin transaction记录,无相应的commit记录)
- 对撤销(Undo)队列事务进行撤销(Undo)处理(1.反向扫描日志文件,对每个undo事务的更新操作进行逆操作;2.将日志记录中“更新前的值”写入数据库)
- 对重做(Redo)队列事务进行重做(Redo)处理(1.正向扫描日志文件,对每个REDO事务重新执行登记的操作;2.将日志记录中“更新后的值”写入数据库)
介质故障后恢复[需要DBA]
- 重装数据库
- 重做已完成的事务
具有检查点的恢复技术
解决问题:
- 搜索整个日志将耗费大量的时间
- REDO处理:重新执行,浪费了大量时间
解决方法:
- 在日志文件中增加检查点记录
- 增加重新开始文件
- 恢复子系统在登录日志文件期间动态地维护日志
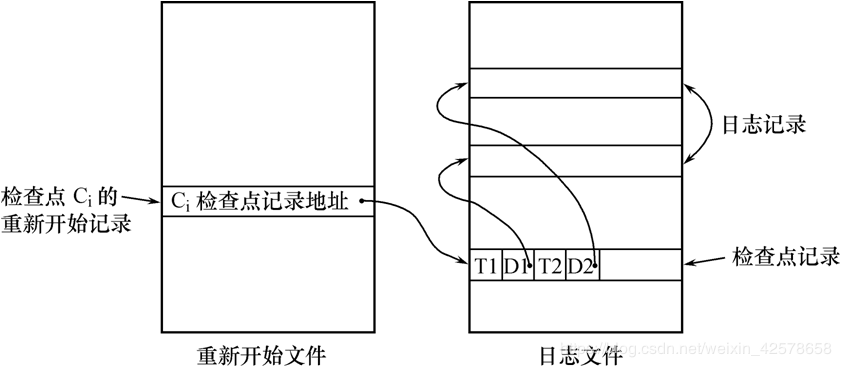
建立检查点:
恢复子系统可以定期或不定期地建立检查点,保存数据库状态
- 定期:按照预定的一个时间间隔,如每隔一小时建立一个检查点
- 不定期:按照某种规则,如日志文件已写满一半建立一个检查点
恢复:
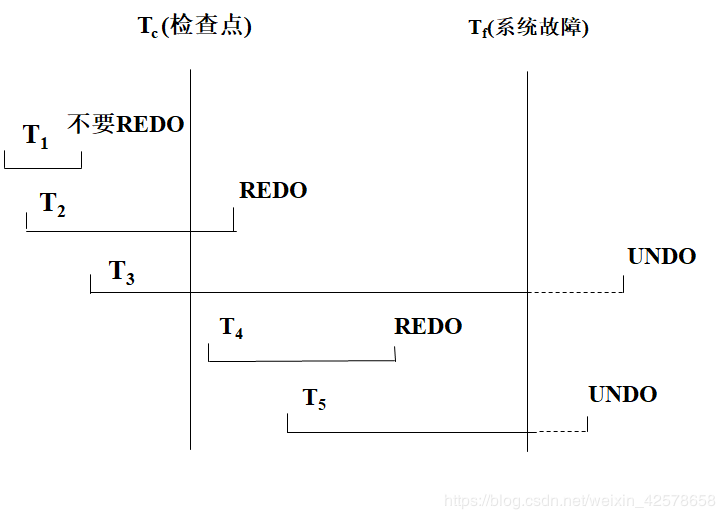
T1:在检查点之前提交
T2:在检查点之前开始执行,在检查点之后故障点之前提交
T3:在检查点之前开始执行,在故障点时还未完成
T4:在检查点之后开始执行,在故障点之前提交
T5:在检查点之后开始执行,在故障点时还未完成
利用检查点的恢复步骤
- 从重新开始文件中找到最后一个检查点记录在日志文件中的地址,由该地址在日志文件中找到最后一个检查点记录
- 由该检查点记录得到检查点建立时刻所有正在执行的事务清单ACTIVE-LIST
- 建立两个事务队列
- UNDO-LIST
- REDO-LIST
- 把ACTIVE-LIST暂时放入UNDO-LIST队列,REDO队列暂为空。
- 建立两个事务队列
- 从检查点开始正向扫描日志文件,直到日志文件结束
- 如有新开始的事务Ti,把Ti暂时放入UNDO-LIST队列
- 如有提交的事务Tj,把Tj从UNDO-LIST队列移到REDO-LIST队列
- 对UNDO-LIST中的每个事务执行UNDO操作
- 对REDO-LIST中的每个事务执行REDO操作
数据镜像[补充]
数据库镜像
-
DBMS自动把整个数据库或其中的关键数据复制到另一个磁盘上
-
DBMS自动保证镜像数据与主数据库的一致性,每当主数据库更新时,DBMS自动把更新后的数据复制过去,如图
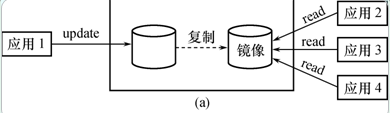
出现介质故障时
- 可由镜像磁盘继续提供使用
- 同时DBMS自动利用镜像磁盘数据进行数据库的恢复
- 不需要关闭系统和重装数据库副本
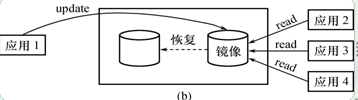
没有出现故障时
- 可用于并发操作
- 一个用户对数据加排他锁修改数据,其他用户可以读镜像数据库上的数据,而不必等待该用户释放锁
问:系统故障的恢复
如果缓冲区管理器不采用课件里的窃取/不强制的管理策略,而采用延迟更新策略,即直到事务提交,更新结果才会被写到数据库中,那么发生系统故障后,如何进行恢复?
答:已提交的事务用REDO, 未提交的事务用UNDO
并发控制
多个事务如何一起执行呢?
- 事务串行执行:每个时刻只有一个事务运行,其他事务必须等到这个事务结束后方能运行。(事务一个接一个的运行)
- 交叉并发方式:在单处理机系统中,并行事务并行操作轮流交叉运行。 这种并行执行方式称为交叉并发方式。
- 同时并方式:在多处理机系统中,每个处理机可以运行一个事务,多个处理机可以同时运行多个事务,实现多个事务真正的并行运行,这种并行执行方式称为同时并发方式。
事务是并发控制的基本单位,如果不考虑隔离性,会发生什么事呢?
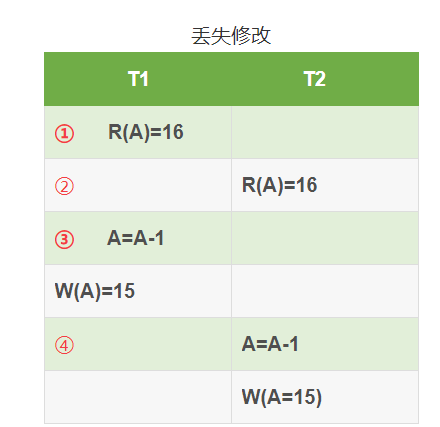
丢失数据:两个事务T1、T2同时读入同一数据并修改,T2提交的结果破坏了T1提交的结果,导致T1的修改被丢失
不可重复读:对于数据库中的某个数据,一个事务范围内的多次查询却返回了不同的结果,这是由于在查询过程中,数据被另外一个事务修改并提交了。
脏读:一个事务在处理数据的过程中,读取到另一个为提交事务的数据。
注意:不可重复读和脏读的区别是,脏读读取到的是一个未提交的数据,而不可重复读读取到的是前一个事务提交的数据。
注意:而不可重复读在一些情况也并不影响数据的正确性,比如需要多次查询的数据也是要以最后一次查询到的数据为主。
注意:丢失数据和不可重复读都是读取了另一条已经提交的事务(这点就脏读不同),所不同的是不可重复读查询的都是同一个数据项,而丢失数据针对的是一批数据整体(比如数据的个数)。
不可重复读和幻读是初学者不易分清的概念,我也是看了详细的解读才明白的,总的来说,解决不可重复读的方法是 锁行,解决丢失数据的方式是 锁表。
1. 丢失数据,幻读(W-W)
两个事务T1、T2同时读入同一数据并修改,T2提交的结果破坏了T1提交的结果,导致T1的修改被丢失
2.不可重复读(R-W)
事务T1读取某一个数据后,事务T2执行更新操作,使T1无法再现前一次读取结果,包括三种情况:
⑴. T2执行修改操作,T1再次读数据时,得到与前一次不同的值
⑵. T2执行删除操作,T1再次读数据时,发现某些记录神秘的消失了
⑶. T2执行插入操作,T1再次读数据时,发现多了一些记录
(2)(3)发生的不可重复读有时也称为幻影现象。

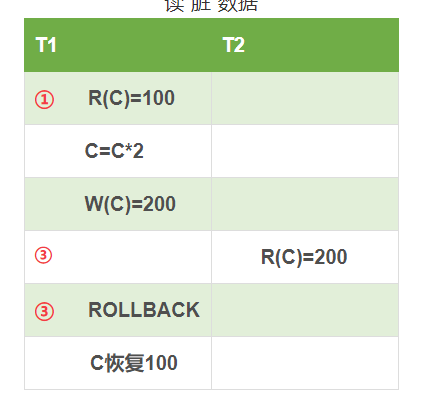
3. 读“脏”数据(W-R)
事务T1修改某一数据并将其写回磁盘,事务T2读取同一数据后,T1由于某种原因被撤销,这时被T1修改过的数据恢复原值,T2读到的数据就与数据库中的数据不一致,则T2读到的数据就为“脏”数据,即不正确的数据。
如何避免发生这种数据不一致的现象?——DBMS必须提供并发控制机制
并发控制机制的任务:对并发操作进行正确调度、保证事务的隔离性、保证数据库的一致性。
并发控制的主要技术有:封锁、时间戳、乐观控制法、多版本并发控制。
问:数据不一致问题:对于“更新丢失”、“脏读”和“不可重复读”三种数据不一致问题,认为哪种是绝不允许发生的?给出理由。
答:应该绝不允许“更新丢失”发生,因为“脏读”和“不可重复读”的后果虽然有时很严重,但有时也是无关紧要的,可以通过控制事务的隔离级别来避免,但是“更新丢失”一旦发生,后面所有需要对丢失的数据进行操作的事务都会受影响,必须重做或者利用数据备份来恢复。
封锁技术
封锁是实现并发控制的一个有效措施,那么什么是封锁呢?
封锁是事务T在对某个数据对象(例如表、记录等操作时)。先向系统发出请求,对其加锁。加锁后事务T就对该数据对象有了一定的控制,在事务T释放它的锁之前,其他事务不能更新此数据对象。
封锁有哪些类型呢?
排他锁:简称X锁(又称写锁),若事务T对数据对象A加上X锁,则只允许T读取和修改A,其他任何事务都不能再对A加任何锁。直到T释放A上的锁。
共享锁:简称S锁(又称读锁),若事务T对数据对象A加上S锁,则事务T可以读A但不能修改A,其他事务只能再对A加S锁,而不能加X锁,直到T释放A上的S锁为止。
有了封锁的类型,如何加锁才能使并发操作不会出现数据不一致现象呢?
封锁协议:约定了对数据对象何时申请X锁或S锁,持续时间、何时释放等一系列规则。
三级封锁见yaunwen
问:封锁技术实现冲突可串行化:封锁技术是如何实现并发事务的冲突可串行化的?
答:封锁技术通过在数据对象上维护“锁”以防止非可串行化的行为。基于锁的并发控制的基本思想是:当一个事务在对其需要访问的数据对象(例如关系、元组)进行操作之前,先向系统发出请求,获得在它所访问的数据库对象上的锁,以防止其他事务几乎在同一时间访问这些数据并因此引入非可行化的可能。封锁技术可实现冲突可串行化。
死锁
封锁会带来哪些问题呢?
- 活锁:如果事务T1封锁了数据R,事务T2又请求封锁数据R,于是T2等待;T3也请求封锁数据R,当T1释放了R上的锁之后,系统首先批准了T3的请求,T2任然等待;然后T4又请求封锁R,当T3释放R上的锁之后,系统又批准了T4的请求……T2有可能永远等待,这就是活锁的情况。
避免活锁的简单方法是:采用先来先服务策略
- 死锁:如果事务T1封锁了数据R1,T2封锁了数据R2,然后T1又请求封锁R2,因T2封锁了R2,
于是T1等待T2释放R2上的锁;接着T2又请求封锁R1,因T1封锁了R1,于是T2等待T1释放R1上的锁。这样就出现了T1在等待T2,而T2又在等待T1,的局面,T1、T2两个事务永远不能结束,形成死锁

解决死锁的方法:有两种思路
- 预防死锁的发生
① 一次封锁法:一次性将所有要使用的数据全部加锁,否则就不能继续执行
存在的问题:扩大了封锁范围,降低了系统的并发度;
② 顺序封锁法:预先对数据对象规定一个封锁顺序,所有事务都按照这个顺序实施封锁。
存在的问题:
1.数据库在动态地不断变化,要维护这样的资源的封锁顺序非常困难,成本很高。
2.事务的封锁请求可以随着事务的执行而动态地决定,很难实现确定每一个事务要封锁哪些对象,因此很难按规定的顺序去施加封锁。
- 死锁的诊断与解除(普遍采用的方法)
① 超时法:如果一个事务的等待时间超过了规定的时限,就认为发生了死锁
存在的问题:
1.时间设置太短,有可能误判死锁
2.时间设置太长,死锁发生后不能及时发现
② 等待图法:事务等待图是一个有向图G=(T,U),T为结点的集合,每个结点表示正在运行的事务;U为边的集合,表示事务等待情况,若事务T1等待T2,则在T1、T2之间画一条有向边,从T1指向T2。
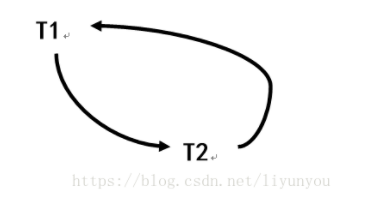
事务等待图动态地反映了所有事务的等待情况。并发控制子系统周期性地(如每隔数秒)生成事务等待图,并进行检测。如果发现图中存在回路,则表示系统中出现了死锁。并发控制子系统一旦检测到系统中存在死锁,就要设法解除。通常采用的方法是选择一个处理死锁代价最小的事务,将其撤销,释放此事务持有的所有的锁,使其他事务得以运行下去
问:“若事务等待图出现环路,则该并发调度不是冲突可串行化的。”你认为这个判断是否正确?理由
答:不正确,事务等待图出现环路表明系统中存在死锁,即事务在申请数据对象上的锁时互相等待,但这并不能说明该并发调度不是和另一个串行调度冲突等价的
多粒度封锁
- 封锁的粒度:封锁对象的大小
在一个系统中同时支持多种封锁粒度供不同的事务选择是比较理想的,这种方法称为多粒度封锁。
- 封锁的对象有哪些?
-
物理单元:页(数据页或索引页)、物理记录等
-
逻辑单元:属性值、属性值的集合、元组、关系、索引项、整个索引、整个数据库
-
如何进行封锁的?
多粒度树:根节点是整个数据库,表示最大的数据粒度,叶节点表示最小的封锁粒度。
多粒度封锁协议
允许多粒度树中的每个结点被独立的加锁,对每一个结点加锁(显式封锁)意味着这个结点的所有后裔结点也被加以同样类型的锁(隐式封锁)。
对某个数据加锁时,系统要检查该数据对象上有无显示封锁与之冲突,同时还要上下检查是否存在隐式封锁,这样的检查效率太低,因此提出了——意向锁
意向锁:如果对一个结点加意向锁,则说明该结点的下层结点正在被加锁;对任意一结点加锁时,必须先岁它的上层结点加意向锁。
意向锁有哪些种类?
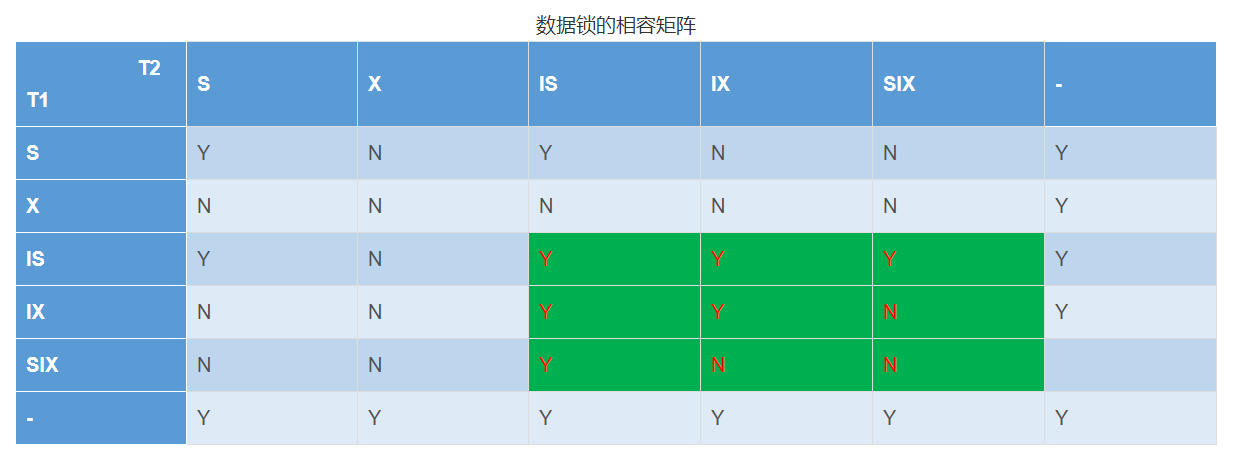
IS锁(意向共享锁):如果对一个数据对象加IS锁,表示它的后裔结点拟(意向)加S锁。
IX锁(意向排他锁):如果对一个数据对象加IX锁,表示它的后裔结点拟(意向)加X锁。
SIX锁(共享意向排他锁):如果对一个数据对象加SIX锁,表示对它加S锁,再加IX锁,即SIX=S+IX。
申请封锁时应该按自上而下的次序进行,释放封锁时应该按自下而上的次序进行
问:基于DBMS提供的多粒度封锁技术,在实际应用中,何时使用粗粒度锁(如关系锁),何时使用细粒度锁(如元组锁)?
答:需要处理少量元组的事务应采用细粒度锁,需要处理大量元组的事务应采用粗粒度锁 细粒度锁比粗粒度锁有更好的并发度,但是开销较大,并发控制管理器需要更多的空间来保持关于细粒度锁的信息,选择时需同时考虑等所开销和并发度两个因素
隔离级别
什么是事务的隔离性(Isolation)呢?
隔离性是指,多个用户的并发事务访问同一个数据库时,一个用户的事务不应该被其他用户的事务干扰,多个并发事务之间要相互隔离。
四种事务隔离级别解决了上述问题;大部分都适用中间两种
读未提交(Read uncommitted):【隔离级别最低】**
- 此时select语句不加锁。可能读取到不一致的数据,即“读脏 ”。并发最高,一致性最差。
读已提交(Read committed):【常用】
- 可避免 脏读 的发生。在互联网大数据量,高并发量的场景下,几乎 不会使用 上述两种隔离级别。
可重复读(Repeatable read):【常用】
- MySql默认隔离级别。可避免 脏读 、不可重复读 的发生。
串行化(Serializable ):【隔离级别最高】
- 可避免 脏读、不可重复读、幻读 的发生;一致性最好的,但并发性最差的隔离级别。
当然级别越高,执行效率就越低。像 Serializable 这样的级别,就是以 锁表 的方式(类似于Java多线程中的锁)使得其他的线程只能在锁外等待,所以平时选用何种隔离级别应该根据实际情况。
问:默认隔离级别的选择:SQLSever 和Oracle都把默认隔离级别设置为Read Committed(读已提交),MySQL把默认隔离级别设置Repeatable Read(可重复读),而不是设置为更高的或者更低隔离级别, 你觉得这样设置是基于什么考虑呢?
d):【隔离级别最低】**
- 此时select语句不加锁。可能读取到不一致的数据,即“读脏 ”。并发最高,一致性最差。
读已提交(Read committed):【常用】
- 可避免 脏读 的发生。在互联网大数据量,高并发量的场景下,几乎 不会使用 上述两种隔离级别。
可重复读(Repeatable read):【常用】
- MySql默认隔离级别。可避免 脏读 、不可重复读 的发生。
串行化(Serializable ):【隔离级别最高】
- 可避免 脏读、不可重复读、幻读 的发生;一致性最好的,但并发性最差的隔离级别。
当然级别越高,执行效率就越低。像 Serializable 这样的级别,就是以 锁表 的方式(类似于Java多线程中的锁)使得其他的线程只能在锁外等待,所以平时选用何种隔离级别应该根据实际情况。
问:默认隔离级别的选择:SQLSever 和Oracle都把默认隔离级别设置为Read Committed(读已提交),MySQL把默认隔离级别设置Repeatable Read(可重复读),而不是设置为更高的或者更低隔离级别, 你觉得这样设置是基于什么考虑呢?
答:通过设置数据库的事务隔离级别可以解决多个事务并发情况下出现的脏读、不可重复读和幻读问题,数据库事务隔离级别由低到高依次为Read uncommitted、Read committed、Repeatable read和Serializable等四种。数据库不同,其支持的事务隔离级别亦不相同:MySQL数据库支持上面四种事务隔离级别,默认为Repeatable read;Oracle 数据库支持Read committed和Serializable两种事务隔离级别,默认为Read committed
相关文章:
chapter-7数据库事务
以下课程来源于MOOC学习—原课程请见:数据库原理与应用 考研复习 DBMS保证系统中一切事务的原子性、一致性、隔离性和持续性 DBMS必须对事务故障、系统故障和介质故障进行恢复 恢复中最经常使用的技术:数据库转储和登记日志文件 恢复的基本原理&#…...

阿里本地生活再出发:口碑入高德,备战美团、抖音
配图来自Canva可画 近日,有传言称高德地图将和阿里本地生活旗下的到店业务口碑正式合并,未来阿里旗下所有的本地生活到店业务都将统一整合在高德地图的入口中。3月22日,高德地图正式确认了此事,并表示高德地图作为“出门好生活开…...
SSM学习记录3:响应(注释方式 + SprigMVC项目 + 2022发布版本IDEA)
响应 ResponseBody注解的作用是将当前控制器中方法的返回值作为响应体 1.返回页面 无需在方法上进行ResponseBody注解,只需RequestMapping匹配地址,并且返回值为带后缀的页面名字符串 前面学习中除了json数据,所有带ResponseBody注解的方法…...

Linux·gcc 编译优化简介
1、gcc 编译优化简介 gcc 提供了为了满足用户不同程度的的优化需要,提供了近百种优化选项,用来对 { 编译时间,目标文件长度,执行效率 } 这个三维模型进行不同的取舍和平衡。优化的方法不一而足,总体上将有以下几类&…...

【电子学会】2022年12月图形化一级 -- 潜水
潜水 暑假小雨和爸爸去玩了潜水,他见到了各种各样的海洋生物。 1. 准备工作 (1)添加背景“Underwater 2”; (2)删除小猫角色,添加角色“Diver2”、“Fish”、“Jellyfish”、“Shark”; (3)为背景添加声音“Xylo2”。 2. 功能实现 (1)点击绿旗,播放背景音乐…...
MySQL日期时间函数汇总、时间格式转换方法
MySQL日期时间函数汇总、时间格式转换方法时间函数日期时间格式转换date_format函数EXTRACT()DATE_ADD()DATE_SUB()DATEDIFF函数时间函数 函数描述NOW()返回当前的日期和时间CURDATE()返回当前的日期CURTIME()返回当前的时间DATE()返回日期或日期/时间表达式的日期部分HOUR()获…...
【CSS】使用绝对定位 / 浮动解决外边距塌陷问题 ( 为父容器 / 子元素设置内边距 / 边框 | 为子元素设置浮动 | 为子元素设置绝对定位 )
文章目录一、外边距塌陷描述1、没有塌陷的情况2、外边距塌陷情况二、传统方法解决外边距塌陷 - 为父容器 / 子元素设置内边距 / 边框三、使用浮动解决外边距塌陷 - 为子元素设置浮动四、使用绝对定位解决外边距塌陷 - 为子元素设置绝对定位一、外边距塌陷描述 在 标准流的父盒子…...

前端手写综合考题
1 实现一个 // 使用 promise来实现 sleepconst sleep (time) > {return new Promise(resolve > setTimeout(resolve, time))}sleep(1000).then(() > {// 这里写你的骚操作}) sleep 函数,比如 sleep(1000) 意味着等待1000毫秒 2 给定两个数组,…...
数据结构-排序
本节目标: 1.排序的概念及其运用 2.常见排序算法的实现 3.排序算法复杂度及稳定性分析 1.排序的概念及其应用 1.1排序的概念 排序就是按照某个我们设定的关键字,或者关键词,递增或者递减,完成这样的操作就是排序。 1.2排…...

ROS话题通信自定义+发布订阅代码--03
话题通信自定义msg 在 ROS 通信协议中,数据载体是一个较为重要组成部分,ROS 中通过 std_msgs 封装了一些原生的数据类型,比如:String、Int32、Int64、Char、Bool、Empty… 但是,这些数据一般只包含一个 data 字段,结构的单一意味…...

【MySQL】实验七 视图
文章目录 1. 建立city值为上海、北京的顾客视图2. 建立城市为上海的客户2016年的订单信息视图3. SQL视图:建立视图AVG_CJ4. SQL视图:建立视图IS_STUDENT5. SQL视图:建立视图CJ_STUDENT6. SQL视图:根据视图CJ_STUDENT创建视图CJ_TJ1. 建立city值为上海、北京的顾客视图 建立…...

Linux常见操作命令【三】
一、系统资源 1.1 ps(process staus) ps -ef e显示所有进程、f全格式 ps -aux 显示所有包含其他使用者的进程 ps -ef | grep CCC 查找含有CCC进程的格式 ps -u username 显示指定进程用户信息1.2 kill kill 12345 杀死进程12345 kill -KILL…...

C-关键字(下)
文章目录循环控制switch-case-break-defaultdo-while-forgetchar()break-continuegotovoidvoid*returnconstconst修饰变量const修饰数组const修饰指针指针补充const 修饰返回值volatilestruct柔型数组union联合体联合体空间开辟问题利用联合体的性质,判断机器是大端还是小端enu…...
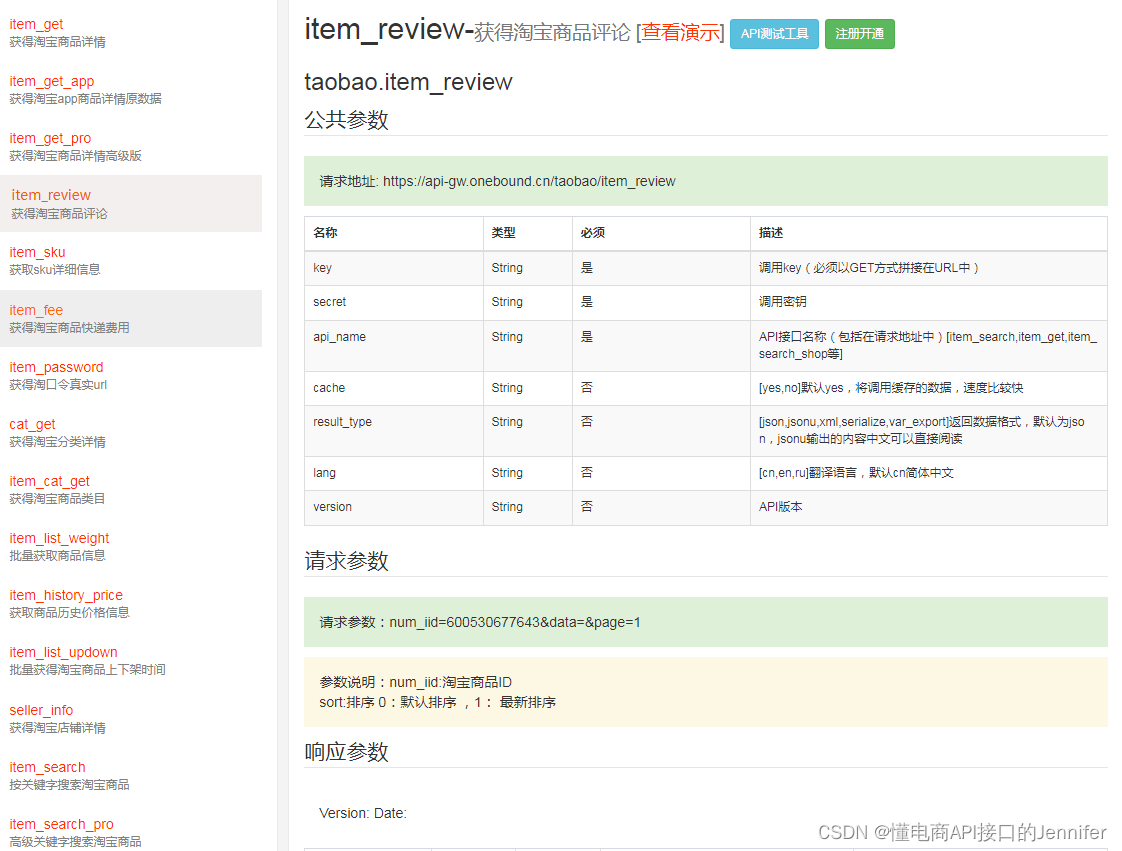
关于电商商品数据API接口列表,你想知道的(详情页、Sku信息、商品描述、评论问答列表)
目录 一、商品数据API接口列表 二、商品详情数据API调用代码item_get 三、获取sku详细信息item_sku 四、获得淘宝商品评论item_review 五、数据说明文档 进入 一、商品数据API接口列表 二、商品详情数据API调用代码item_get <?php// 请求示例 url 默认请求参数已经URL…...

232:vue+openlayers选择左右两部分的地图,不重复,横向卷帘
第232个 点击查看专栏目录 本示例的目的是介绍演示如何在vue+openlayers项目中自定义js实现横向卷帘。这个示例中从左右两个选择框中来选择不同的地图,做了不重复的处理,即同一个数组,两部分根据选择后的状态做disabled处理,避免重复选择。 直接复制下面的 vue+openlayers…...
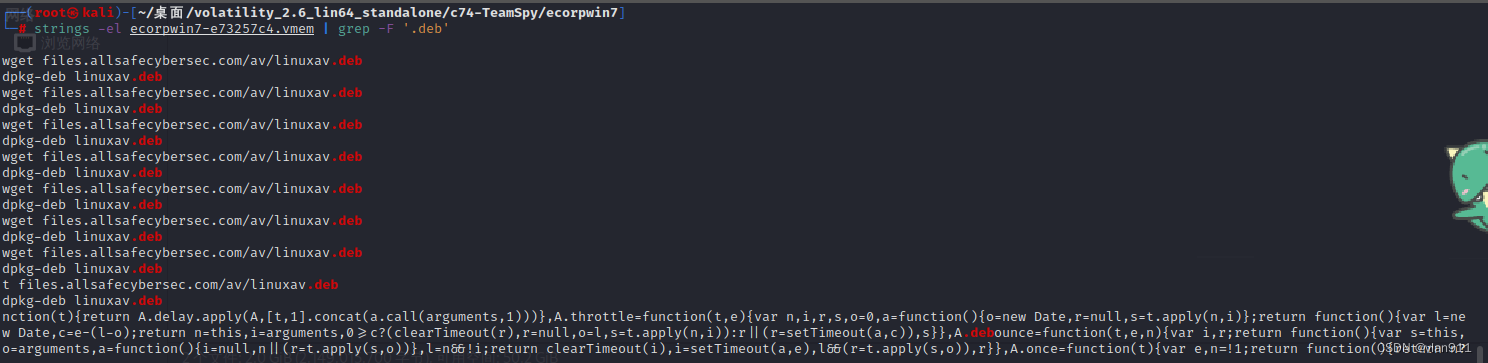
溯源取证-内存取证 高难度篇
今天的场景依然是windows场景,只不过此次场景分为两个镜像,本次学习主要学习如何晒别钓鱼邮件、如何提取钓鱼邮件、如何修复损坏的恶意文件、如何提取DLL动态链接库文件 本次需要使用的工具: volatility_2.6_lin64_standalone readpst clams…...

JAVA语言中的代理模式
代理可以进一步划分为静态代理和动态代理,代理模式在实际的生活中场景很多,例如中介、律师、代购等行业,都是简单的代理逻辑,在这个模式下存在两个关键角色: 目标对象角色:即代理对象所代表的对象。 代理…...

最后一步:渲染和绘制
浏览器的工作步骤如下: URL>字符流>词(token)流>DOM树(不含样式信息的 DOM)>DOM树CSS规则(含样式信息的 DOM)>根据样式信息,计算了每个元素的位置和大小>根据这些…...
C++类和对象终章——友元函数 | 友元类 | 内部类 | 匿名对象 | 关于拷贝对象时一些编译器优化
文章目录💐专栏导读💐文章导读🌷友元🌺概念🌺友元函数🍁友元函数的重要性质🌺友元类🍁友元类的重要性质🌷内部类(不常用)🌺内部类的性…...

拼多多按关键字搜索商品 API
一、拼多多平台优势: 1、独创拼团模式 拼团拼单是拼多多独创的营销模式,其特点是基于人脉社交的裂变传播,非常具有传播性。 由于本身走低价路线,加上拼单折扣,商品的分享和人群裂变效果非常明显,电商前期…...

数据挖掘与多层神经网络:极简学习路径,神经网络核心机制精要
核心理念:神经网络 可学习的多层次特征提取器 模式匹配器。它通过数据自动学习从输入到输出的复杂映射规则。一、 基础奠基(必须知道的概念)数学基础:线性代数(计算骨架):数据是向量/矩阵&…...
从CNN到Transformer:LeViT和LocalViT是如何把‘局部感知’这个CNN绝活‘偷’过来的?
从CNN到Transformer:LeViT和LocalViT如何实现局部感知的跨架构融合 视觉Transformer(ViT)的崛起彻底改变了计算机视觉领域的格局,但纯Transformer架构在图像处理中面临着一个根本性挑战——缺乏CNN与生俱来的局部感知能力。本文将…...

探索罗技鼠标宏:掌握PUBG压枪技术的完整路径
探索罗技鼠标宏:掌握PUBG压枪技术的完整路径 【免费下载链接】logitech-pubg PUBG no recoil script for Logitech gaming mouse / 绝地求生 罗技 鼠标宏 项目地址: https://gitcode.com/gh_mirrors/lo/logitech-pubg 在《绝地求生》这款竞技性极强的射击游戏…...

谷歌外链怎么发?靠1种图文形式自动吸引外链
写外链一直是SEO里最耗体力的活。很多公司招了三个实习生,每天坐在电脑前发几百封开发信,回复率往往不到0.5%。到了2026年,谷歌的算法已经能识别出绝大多数带有“交换”性质的人为链接。现在的行情是,想要稳住排名,得让…...

嵌入式GUI性能优化实战:LVGL贝塞尔曲线绘制中的定点数与移位运算避坑指南
嵌入式GUI性能优化实战:LVGL贝塞尔曲线绘制中的定点数与移位运算避坑指南 在嵌入式系统开发中,流畅的图形用户界面(GUI)往往需要面对资源受限的硬件环境。当我们在STM32或ESP32这类微控制器上实现复杂的动画效果时,贝塞尔曲线因其平滑的过渡…...

Vivado用户必看:中文用户名导致Vscode关联失效?手把手教你修改vivado.xml文件
Vivado与Vscode联动的终极解决方案:彻底攻克中文路径兼容性问题 在FPGA开发领域,Vivado作为Xilinx推出的旗舰级开发工具,与轻量级代码编辑器Vscode的联动已经成为提升开发效率的标准配置。然而,许多中文用户在实际操作中常常遇到…...
安装ROCm 4.5.2驱动及完整工具链)
保姆级教程:在Ubuntu 22.04上为DCU-Z100(ZiFang)安装ROCm 4.5.2驱动及完整工具链
国产AI加速卡DCU-Z100(ZiFang)全栈部署指南:从驱动安装到开发环境配置 在人工智能计算领域,国产硬件正逐步崭露头角。DCU-Z100(代号ZiFang)作为一款自主研发的深度学习计算单元,为开发者提供了全…...

i.MX6ULL LCD驱动适配实战:从设备树到时序调试全解析
1. 项目概述与核心价值最近在搞一个基于i.MX6ULL的工控HMI项目,屏幕显示是绕不开的一环。市面上很多教程要么只讲Framebuffer应用,要么直接给个现成的设备树文件让你照着改,至于里面的参数怎么来的、屏幕初始化序列怎么配,往往一笔…...

Bilibili视频转文字完整指南:一键将B站视频转为可编辑文字稿
Bilibili视频转文字完整指南:一键将B站视频转为可编辑文字稿 【免费下载链接】bili2text Bilibili视频转文字,一步到位,输入链接即可使用 项目地址: https://gitcode.com/gh_mirrors/bi/bili2text 你是否曾为观看Bilibili视频时需要做…...

嵌入式存储优化实战:从eMMC到NAND Flash的软件策略与性能提升
1. 项目概述:嵌入式存储的“软”实力较量在嵌入式开发这个行当里摸爬滚打了十几年,我见过太多项目在硬件选型上精打细算,却在软件优化上“一毛不拔”,最后性能瓶颈卡在存储上,整个系统跑起来像老牛拉破车。今天想和大家…...