Linux·gcc 编译优化简介
1、gcc 编译优化简介
gcc 提供了为了满足用户不同程度的的优化需要,提供了近百种优化选项,用来对 { 编译时间,目标文件长度,执行效率 } 这个三维模型进行不同的取舍和平衡。优化的方法不一而足,总体上将有以下几类:
1) 精简操作指令;
2) 尽量满足 cpu 的流水操作;
3) 通过对程序行为地猜测,重新调整代码的执行顺序;
4) 充分使用寄存器;
5) 对简单的调用进行展开等等。
想全部了解这些编译选项,并在其中挑选适合的选项进行优化,无疑像个噩梦般的过程。单从 gnu 的官方网站上得到的手册来看,描述依然比较苍白,不足以完全了解选项的使用范围和原理。(GCC has well over a hundred individual optimization flags and it would be insane to try and describe them all)
幸而 gcc 提供了从 O0-O3 以及 Os 这几种不同的优化级别供大家选择,在这些选项中,包含了大部分有效的编译优化选项,并且可以在这个基础上,对某些选项进行屏蔽或添加,从而大大降低了使用的难度,毕竟,在一定基础上进行取舍,比万事从头开始要好得多。下面着重围绕这几个不同的级别进行简单介绍。(由于 gcc 不同版本手册差异比较大,以下主要以 gcc-3.4.6 为参考)
-O0: 不做任何优化,这是默认的编译选项。
-O和-O1: 对程序做部分编译优化,对于大函数,优化编译占用稍微多的时间和相当大的内存。使用本项优化,编译器会尝试减小生成代码的尺寸,以及缩短执行时间,但并不执行需要占用大量编译时间的优化。
打开的优化选项:
<span style="color:#000000"><span style="background-color:#282c34"><code class="language-bash">l -fdefer-pop:延迟栈的弹出时间。当完成一个函数调用,参数并不马上从栈中弹出,而是在多个函数被调用后,一次性弹出。 l -fmerge-constants:尝试横跨编译单元合并同样的常量<span style="color:#999999">(</span>string constants and floating point constants<span style="color:#999999">)</span> l -fthread-jumps:如果某个跳转分支的目的地存在另一个条件比较,而且该条件比较包含在前一个比较语句之内,那么执行本项优化.根据条件是 <span style="color:#56b6c2">true</span> 或者 false, 前面那条分支重定向到第二条分支的目的地或者紧跟在第二条分支后面. l -floop-optimize:执行循环优化,将常量表达式从循环中移除,简化判断循环的条件,并且 optionally <span style="color:#c678dd">do</span> strength-reduction,或者将循环打开等。在大型复杂的循环中,这种优化比较显著。 l -fif-conversion:尝试将条件跳转转换为等价的无分支型式。优化实现方式包括条件移动,min,max,设置标志,以及 abs指令,以及一些算术技巧等。 l -fif-conversion2 基本意义相同,没有找到更多的解释。 l -fdelayed-branch:这种技术试图根据指令周期时间重新安排指令。 它还试图把尽可能多的指令移动到条件分支前, 以便最充分的利用处理器的治理缓存。 l -fguess-branch-probability:当没有可用的 profiling feedback或__builtin_expect 时,编译器采用随机模式猜测分支被执行的可能性,并移动对应汇编代码的位置,这有可能导致不同的编译器会编译出迥然不同的目标代码。 l -fcprop-registers:因为在函数中把寄存器分配给变量, 所以编译器执行第二次检查以便减少调度依赖性<span style="color:#999999">(</span>两个段要求使用相同的寄存器<span style="color:#999999">)</span>并且删除不必要的寄存器复制操作。 </code></span></span>-O2: 是比 O1 更高级的选项,进行更多的优化。
Gcc 将执行几乎所有的不包含时间和空间折中的优化。当设置 O2 选项时,编译器并不进行循环打开 loop unrolling 以及函数内联。与 O1 比较而言,O2 优化增加了编译时间的基础上,提高了生成代码的执行效率。
O2打开所有的O1选项,并打开以下选项:
<span style="color:#000000"><span style="background-color:#282c34"><code class="language-bash">l -fforce-mem:在做算术操作前,强制将内存数据copy到寄存器中以后再执行。这会使所有的内存引用潜在的共同表达式,进而产出更高效的代码,当没有共同的子表达式时,指令合并将排出个别的寄存器载入。这种优化对于只涉及单一指令的变量, 这样也许不会有很大的优化效果. 但是对于再很多指令<span style="color:#999999">(</span>必须数学操作<span style="color:#999999">)</span>中都涉及到的变量来说, 这会时很显著的优化, 因为和访问内存中的值相比 ,处理器访问寄存器中的值要快的多。 l -foptimize-sibling-calls:优化相关的以及末尾递归的调用。通常, 递归的函数调用可以被展开为一系列一般的指令, 而不是使用分支。 这样处理器的指令缓存能够加载展开的指令并且处理他们, 和指令保持为需要分支操作的单独函数调用相比, 这样更快。 l -fstrength-reduce:这种优化技术对循环执行优化并且删除迭代变量。 迭代变量是捆绑到循环计数器的变量, 比如使用变量, 然后使用循环计数器变量执行数学操作的for-next循环。 l -fcse-follow-jumps:在公用子表达式消元时,当目标跳转不会被其他路径可达,则扫描整个的跳转表达式。例如,当公用子表达式消元时遇到if<span style="color:#999999">..</span>.else<span style="color:#999999">..</span>.语句时,当条为false时,那么公用子表达式消元会跟随着跳转。 l -fcse-skip-blocks:与-fcse-follow-jumps类似,不同的是,根据特定条件,跟随着cse跳转的会是整个的blocks l -frerun-cse-after-loop:在循环优化完成后,重新进行公用子表达式消元操作。 l -frerun-loop-opt:两次运行循环优化 l -fgcse:执行全局公用子表达式消除pass。这个pass还执行全局常量和copy propagation。这些优化操作试图分析生成的汇编语言代码并且结合通用片段, 消除冗余的代码段。如果代码使用计算性的goto, gcc指令推荐使用-fno-gcse选项。 l-fgcse-lm:全局公用子表达式消除将试图移动那些仅仅被自身存储kill的装载操作的位置。这将允许将循环内的load/store操作序列中的load转移到循环的外面(只需要装载一次),而在循环内改变成copy/store序列。在选中-fgcse后,默认打开。 l -fgcse-sm:当一个存储操作pass在一个全局公用子表达式消除的后面,这个pass将试图将store操作转移到循环外面去。如果与-fgcse-lm配合使用,那么load/store操作将会转变为在循环前load,在循环后store,从而提高运行效率,减少不必要的操作。 l -fgcse-las:全局公用子表达式消除pass将消除在store后面的不必要的load操作,这些load与store通常是同一块存储单元(全部或局部) l-fdelete-null-pointer-checks:通过对全局数据流的分析,识别并排出无用的对空指针的检查。编译器假设间接引用空指针将停止程序。 如果在间接引用之后检查指针,它就不可能为空。 l -fexpensive-optimizations:进行一些从编译的角度来说代价高昂的优化(这种优化据说对于程序执行未必有很大的好处,甚至有可能降低执行效率,具体不是很清楚) l -fregmove:编译器试图重新分配move指令或者其他类似操作数等简单指令的寄存器数目,以便最大化的捆绑寄存器的数目。这种优化尤其对双操作数指令的机器帮助较大。 l -fschedule-insns:编译器尝试重新排列指令,用以消除由于等待未准备好的数据而产生的延迟。这种优化将对慢浮点运算的机器以及需要load memory的指令的执行有所帮助,因为此时允许其他指令执行,直到load memory的指令完成,或浮点运算的指令再次需要cpu。 l -fschedule-insns2:与-fschedule-insns相似。但是当寄存器分配完成后,会请求一个附加的指令计划pass。这种优化对寄存器较小,并且load memory操作时间大于一个时钟周期的机器有非常好的效果。 l -fsched-interblock:这种技术使编译器能够跨越指令块调度指令。 这可以非常灵活地移动指令以便等待期间完成的工作最大化。 l -fsched-spec-load:允许一些load指令进行一些投机性的动作。(具体不详)相同功能的还有-fsched-spec-load-dangerous,允许更多的load指令进行投机性操作。这两个选项在选中-fschedule-insns时默认打开。 l -fcaller-saves:通过存储和恢复call调用周围寄存器的方式,使被call调用的value可以被分配给寄存器,这种只会在看上去能产生更好的代码的时候才被使用。(如果调用多个函数, 这样能够节省时间, 因为只进行一次寄存器的保存和恢复操作, 而不是在每个函数调用中都进行。) l -fpeephole2:允许计算机进行特定的观察孔优化<span style="color:#999999">(</span>这个不晓得是什么意思<span style="color:#999999">)</span>,-fpeephole与-fpeephole2的差别在于不同的编译器采用不同的方式,由的采用-fpeephole,有的采用-fpeephole2,也有两种都采用的。 l -freorder-blocks:在编译函数的时候重新安排基本的块,目的在于减少分支的个数,提高代码的局部性。 l -freorder-functions:在编译函数的时候重新安排基本的块,目的在于减少分支的个数,提高代码的局部性。这种优化的实施依赖特定的已存在的信息:.text.hot用于告知访问频率较高的函数,.text.unlikely用于告知基本不被执行的函数。 l -fstrict-aliasing:这种技术强制实行高级语言的严格变量规则。 对于c和c++程序来说, 它确保不在数据类型之间共享变量. 例如, 整数变量不和单精度浮点变量使用相同的内存位置。 l -funit-at-a-time:在代码生成前,先分析整个的汇编语言代码。这将使一些额外的优化得以执行,但是在编译器间需要消耗大量的内存。(有资料介绍说:这使编译器可以重新安排不消耗大量时间的代码以便优化指令缓存。) l -falign-functions:这个选项用于使函数对准内存中特定边界的开始位置。 大多数处理器按照页面读取内存,并且确保全部函数代码位于单一内存页面内, 就不需要叫化代码所需的页面。 l -falign-jumps:对齐分支代码到2的n次方边界。在这种情况下,无需执行傀儡指令(dummy operations) l -falign-loops:对齐循环到2的n次幂边界。期望可以对循环执行多次,用以补偿运行dummy operations所花费的时间。 l -falign-labels:对齐分支到2的n次幂边界。这种选项容易使代码速度变慢,原因是需要插入一些dummy operations当分支抵达usual flow of the code. l -fcrossjumping:这是对跨越跳转的转换代码处理, 以便组合分散在程序各处的相同代码。 这样可以减少代码的长度, 但是也许不会对程序性能有直接影响。 </code></span></span>-O3: 比 O2 更进一步的进行优化。
在包含了 O2 所有的优化的基础上,又打开了以下优化选项:
<span style="color:#000000"><span style="background-color:#282c34"><code class="language-bash">
l -finline-functions:内联简单的函数到被调用函数中。由编译器启发式的决定哪些函数足够简单可以做这种内联优化。默认情况下,编译器限制内联的尺寸,3.4.6中限制为600(具体含义不详,指令条数或代码size?)可以通过-finline-limit<span style="color:#669900">=</span>n改变这个长度。这种优化技术不为函数创建单独的汇编语言代码, 而是把函数代码包含在调度程序的代码中。 对于多次被调用的函数来说, 为每次函数调用复制函数代码。 虽然这样对于减少代码长度不利, 但是通过最充分的利用指令缓存代码, 而不是在每次函数调用时进行分支操作, 可以提高性能。 l -fweb:构建用于保存变量的伪寄存器网络。 伪寄存器包含数据, 就像他们是寄存器一样, 但是可以使用各种其他优化技术进行优化, 比如cse和loop优化技术。这种优化会使得调试变得更加的不可能,因为变量不再存放于原本的寄存器中。 l -frename-registers:在寄存器分配后,通过使用registers left over来避免预定代码中的虚假依赖。这会使调试变得非常困难,因为变量不再存放于原本的寄存器中了。 l -funswitch-loops:将无变化的条件分支移出循环,取而代之的将结果副本放入循环中。 </code></span></span>-Os: 主要是对程序的尺寸进行优化。打开了大部分 O2 优化中不会增加程序大小的优化选项,并对程序代码的大小做更深层的优化。(通常我们不需要这种优化)Os 会关闭如下选项:
-falign-functions
-falign-jumps
-falign-loops
-falign-labels
-freorder-blocks
-fprefetch-loop-arrays
2、优化介绍小结
O0 选项不进行任何优化,在这种情况下,编译器尽量的缩短编译消耗(时间,空间),此时,debug 会产出和程序预期的结果。当程序运行被断点打断,此时程序内的各种声明是独立的,我们可以任意的给变量赋值,或者在函数体内把程序计数器指到其他语句,以及从源程序中 精确地获取你期待的结果。
O1 优化会消耗少多的编译时间,它主要对代码的分支,常量以及表达式等进行优化。
O2 会尝试更多的寄存器级的优化以及指令级的优化,它会在编译期间占用更多的内存和编译时间。
O3 在 O2 的基础上进行更多的优化,例如使用伪寄存器网络,普通函数的内联,以及针对循环的更多优化。
Os 主要是对代码大小的优化,我们基本不用做更多的关心。 通常各种优化都会打乱程序的结构,让调试工作变得无从着手。并且会打乱执行顺序,依赖内存操作顺序的程序需要做相关处理才能确保程序的正确性。
3、优化代码有可能带来的问题
1.调试问题:正如上面所提到的,任何级别的优化都将带来代码结构的改变。例如:对分支的合并和消除,对公用子表达式的消除,对循环内 load/store 操作的替换和更改等,都将会使目标代码的执行顺序变得面目全非,导致调试信息严重不足。
2.内存操作顺序改变所带来的问题:在 O2 优化后,编译器会对影响内存操作的执行顺序。例如:
-fschedule-insns 允许数据处理时先完成其他的指令;
-fforce-mem 有可能导致内存与寄存器之间的数据产生类似脏数据的不一致等。
对于某些依赖内存操作顺序而进行的逻辑,需要做严格的处理后才能进行优化。例如,采用 volatile 关键字限制变量的操作方式,或者利用 barrier 迫使 cpu 严格按照指令序执行的。
相关文章:

Linux·gcc 编译优化简介
1、gcc 编译优化简介 gcc 提供了为了满足用户不同程度的的优化需要,提供了近百种优化选项,用来对 { 编译时间,目标文件长度,执行效率 } 这个三维模型进行不同的取舍和平衡。优化的方法不一而足,总体上将有以下几类&…...

【电子学会】2022年12月图形化一级 -- 潜水
潜水 暑假小雨和爸爸去玩了潜水,他见到了各种各样的海洋生物。 1. 准备工作 (1)添加背景“Underwater 2”; (2)删除小猫角色,添加角色“Diver2”、“Fish”、“Jellyfish”、“Shark”; (3)为背景添加声音“Xylo2”。 2. 功能实现 (1)点击绿旗,播放背景音乐…...
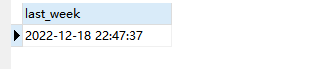
MySQL日期时间函数汇总、时间格式转换方法
MySQL日期时间函数汇总、时间格式转换方法时间函数日期时间格式转换date_format函数EXTRACT()DATE_ADD()DATE_SUB()DATEDIFF函数时间函数 函数描述NOW()返回当前的日期和时间CURDATE()返回当前的日期CURTIME()返回当前的时间DATE()返回日期或日期/时间表达式的日期部分HOUR()获…...
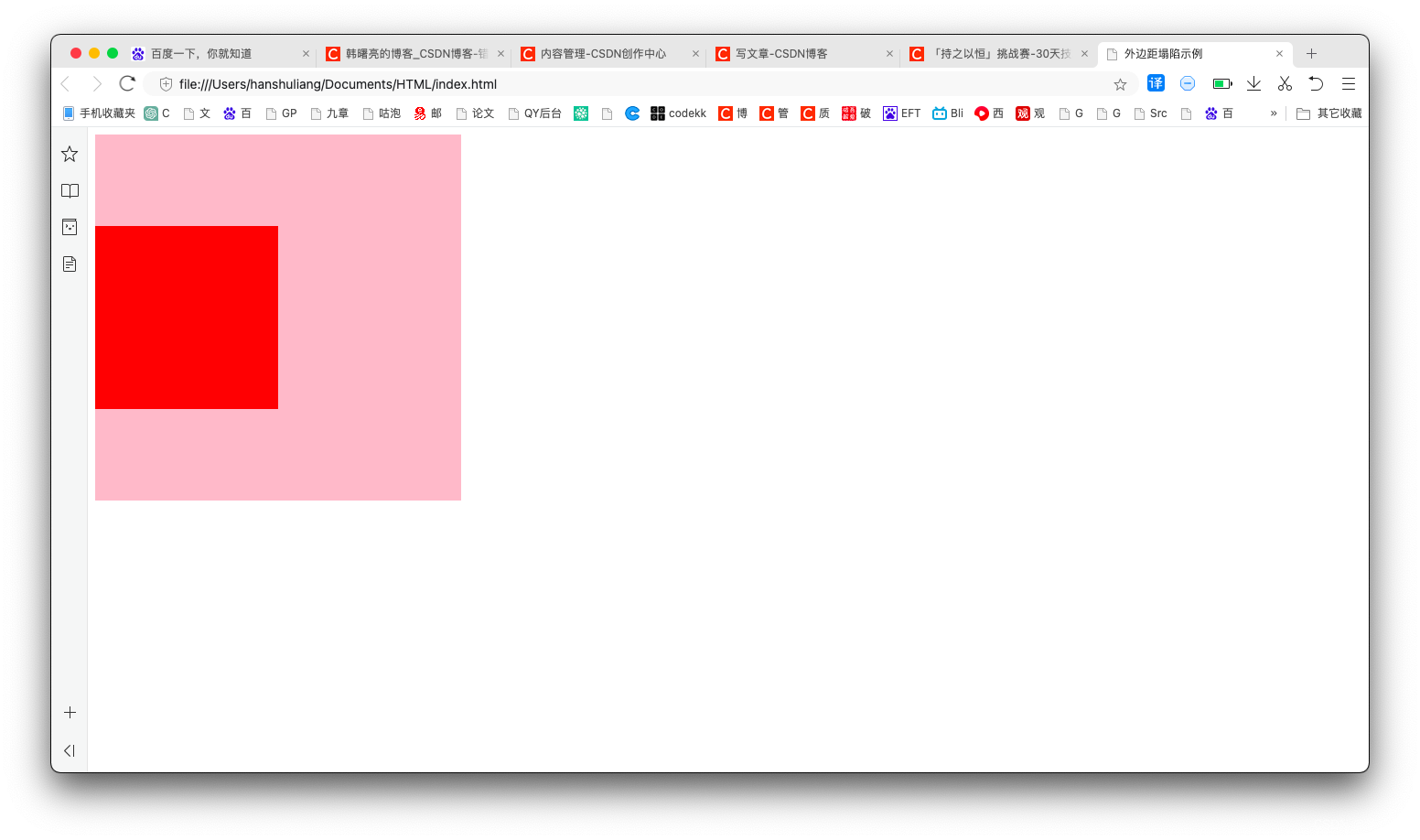
【CSS】使用绝对定位 / 浮动解决外边距塌陷问题 ( 为父容器 / 子元素设置内边距 / 边框 | 为子元素设置浮动 | 为子元素设置绝对定位 )
文章目录一、外边距塌陷描述1、没有塌陷的情况2、外边距塌陷情况二、传统方法解决外边距塌陷 - 为父容器 / 子元素设置内边距 / 边框三、使用浮动解决外边距塌陷 - 为子元素设置浮动四、使用绝对定位解决外边距塌陷 - 为子元素设置绝对定位一、外边距塌陷描述 在 标准流的父盒子…...

前端手写综合考题
1 实现一个 // 使用 promise来实现 sleepconst sleep (time) > {return new Promise(resolve > setTimeout(resolve, time))}sleep(1000).then(() > {// 这里写你的骚操作}) sleep 函数,比如 sleep(1000) 意味着等待1000毫秒 2 给定两个数组,…...
数据结构-排序
本节目标: 1.排序的概念及其运用 2.常见排序算法的实现 3.排序算法复杂度及稳定性分析 1.排序的概念及其应用 1.1排序的概念 排序就是按照某个我们设定的关键字,或者关键词,递增或者递减,完成这样的操作就是排序。 1.2排…...

ROS话题通信自定义+发布订阅代码--03
话题通信自定义msg 在 ROS 通信协议中,数据载体是一个较为重要组成部分,ROS 中通过 std_msgs 封装了一些原生的数据类型,比如:String、Int32、Int64、Char、Bool、Empty… 但是,这些数据一般只包含一个 data 字段,结构的单一意味…...

【MySQL】实验七 视图
文章目录 1. 建立city值为上海、北京的顾客视图2. 建立城市为上海的客户2016年的订单信息视图3. SQL视图:建立视图AVG_CJ4. SQL视图:建立视图IS_STUDENT5. SQL视图:建立视图CJ_STUDENT6. SQL视图:根据视图CJ_STUDENT创建视图CJ_TJ1. 建立city值为上海、北京的顾客视图 建立…...

Linux常见操作命令【三】
一、系统资源 1.1 ps(process staus) ps -ef e显示所有进程、f全格式 ps -aux 显示所有包含其他使用者的进程 ps -ef | grep CCC 查找含有CCC进程的格式 ps -u username 显示指定进程用户信息1.2 kill kill 12345 杀死进程12345 kill -KILL…...

C-关键字(下)
文章目录循环控制switch-case-break-defaultdo-while-forgetchar()break-continuegotovoidvoid*returnconstconst修饰变量const修饰数组const修饰指针指针补充const 修饰返回值volatilestruct柔型数组union联合体联合体空间开辟问题利用联合体的性质,判断机器是大端还是小端enu…...
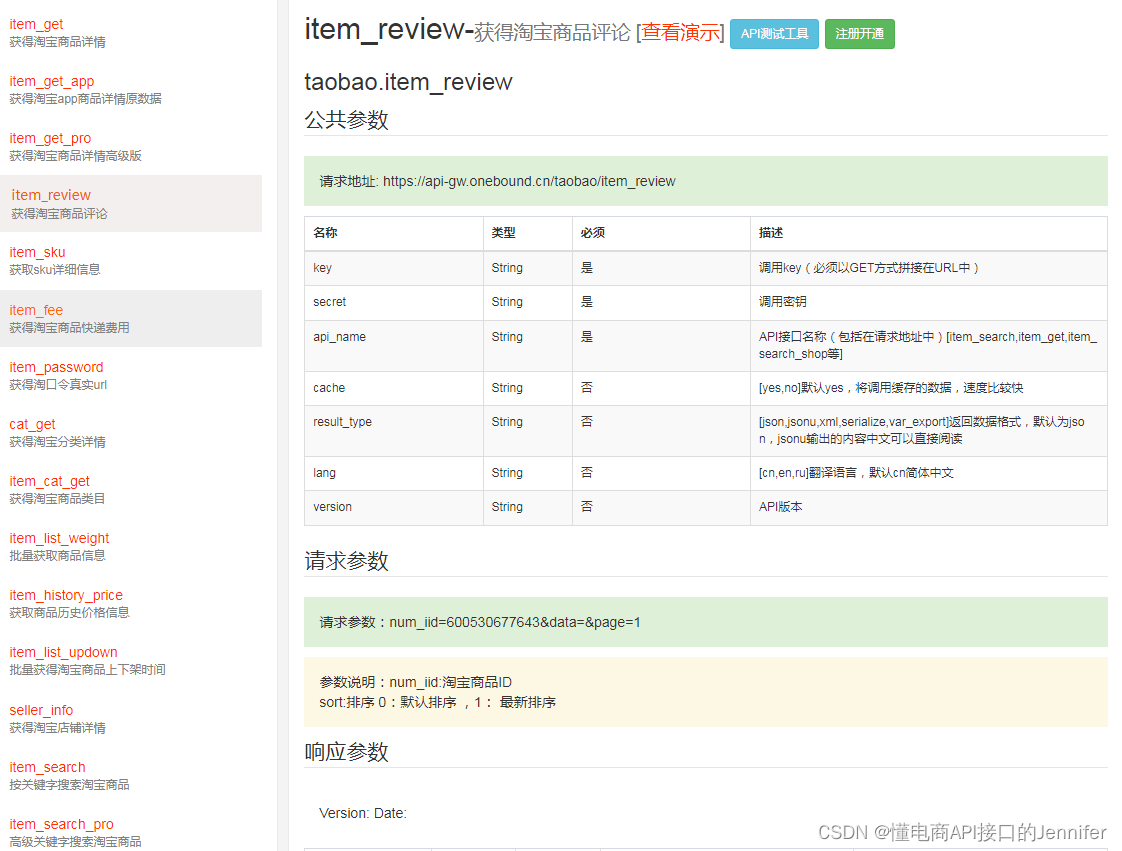
关于电商商品数据API接口列表,你想知道的(详情页、Sku信息、商品描述、评论问答列表)
目录 一、商品数据API接口列表 二、商品详情数据API调用代码item_get 三、获取sku详细信息item_sku 四、获得淘宝商品评论item_review 五、数据说明文档 进入 一、商品数据API接口列表 二、商品详情数据API调用代码item_get <?php// 请求示例 url 默认请求参数已经URL…...

232:vue+openlayers选择左右两部分的地图,不重复,横向卷帘
第232个 点击查看专栏目录 本示例的目的是介绍演示如何在vue+openlayers项目中自定义js实现横向卷帘。这个示例中从左右两个选择框中来选择不同的地图,做了不重复的处理,即同一个数组,两部分根据选择后的状态做disabled处理,避免重复选择。 直接复制下面的 vue+openlayers…...
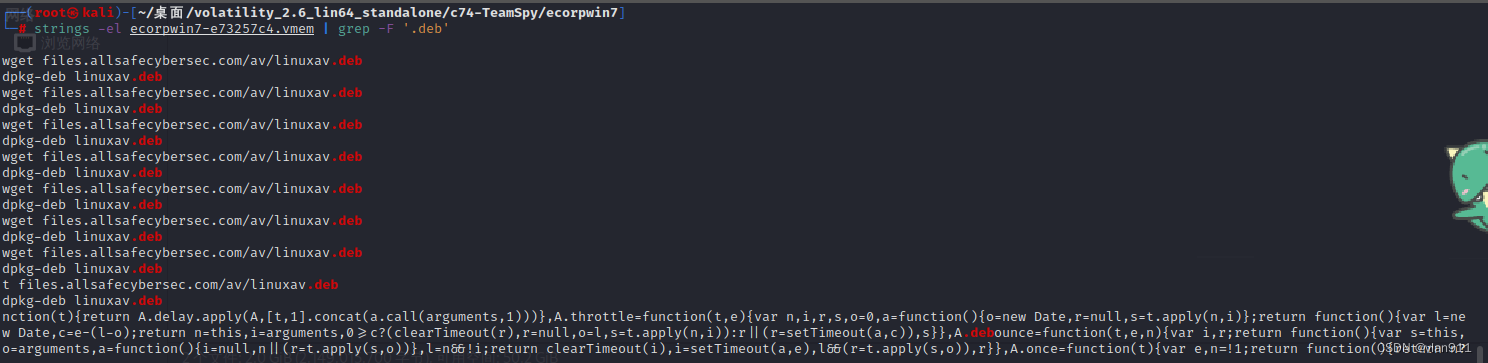
溯源取证-内存取证 高难度篇
今天的场景依然是windows场景,只不过此次场景分为两个镜像,本次学习主要学习如何晒别钓鱼邮件、如何提取钓鱼邮件、如何修复损坏的恶意文件、如何提取DLL动态链接库文件 本次需要使用的工具: volatility_2.6_lin64_standalone readpst clams…...

JAVA语言中的代理模式
代理可以进一步划分为静态代理和动态代理,代理模式在实际的生活中场景很多,例如中介、律师、代购等行业,都是简单的代理逻辑,在这个模式下存在两个关键角色: 目标对象角色:即代理对象所代表的对象。 代理…...

最后一步:渲染和绘制
浏览器的工作步骤如下: URL>字符流>词(token)流>DOM树(不含样式信息的 DOM)>DOM树CSS规则(含样式信息的 DOM)>根据样式信息,计算了每个元素的位置和大小>根据这些…...
C++类和对象终章——友元函数 | 友元类 | 内部类 | 匿名对象 | 关于拷贝对象时一些编译器优化
文章目录💐专栏导读💐文章导读🌷友元🌺概念🌺友元函数🍁友元函数的重要性质🌺友元类🍁友元类的重要性质🌷内部类(不常用)🌺内部类的性…...

拼多多按关键字搜索商品 API
一、拼多多平台优势: 1、独创拼团模式 拼团拼单是拼多多独创的营销模式,其特点是基于人脉社交的裂变传播,非常具有传播性。 由于本身走低价路线,加上拼单折扣,商品的分享和人群裂变效果非常明显,电商前期…...

全链路日志追踪
背景 最近线上的日志全局追踪 traceId 不好使了,不同请求经常出现重复的 traceId,或者通过某个请求的 traceId 追踪搜索,检索出了与该请求完全不相干的日志。我领导叫我去排查解决这个问题,这里我把我排查的过程思路以及如何解决…...
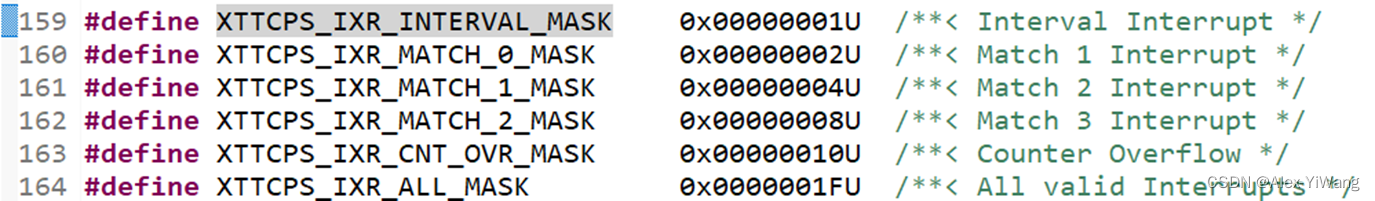
ZYNQ:【1】深入理解PS端的TTC定时器(Part1:原理+官方案例讲解)
碎碎念:好久不见,甚是想念!本期带来的是有关ZYNQ7020的内容,我们知道ZYNQ作为一款具有硬核的SOC,PS端很强大,可以更加便捷地实现一些算法验证。本文具体讲解一下里面的TTC定时器,之后发布的Part…...

蓝牙设备如何自定义UUID
如何自定义UUID 所有 BLE 自定义服务和特性必须使用 128 位 UUID 来识别,并且要确保基本 UUID 与 BLE 定义的基本 UUID(00000000-0000-1000-8000-00805F9B34FB)不一样。基本 UUID 是一个 128 位的数值,根据该值可定义标准UUID&am…...

AI驱动的智能监控:从时序异常检测到自动化运维实战
1. 项目概述:AI驱动的系统守护者最近在折腾一个服务器监控项目时,发现了一个挺有意思的开源工具,叫bhusingh/ai-watchdog。这个名字直译过来就是“AI看门狗”,听起来就很有画面感。它本质上是一个利用人工智能技术来监控系统、预测…...

基于ROS的6-DOF KUKA机器人高效抓取方案:运动学算法与仿真实现
基于ROS的6-DOF KUKA机器人高效抓取方案:运动学算法与仿真实现 【免费下载链接】pick-place-robot Object picking and stowing with a 6-DOF KUKA Robot using ROS 项目地址: https://gitcode.com/gh_mirrors/pi/pick-place-robot 本项目是一个基于ROS&…...

LinkSwift:重新定义网盘文件下载体验的本地化革命
LinkSwift:重新定义网盘文件下载体验的本地化革命 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云盘…...
)
告别手动!用Windows批处理脚本批量搞定MKVToolNix音轨修改(附完整代码)
告别手动!用Windows批处理脚本批量搞定MKVToolNix音轨修改(附完整代码) 每次下载完一整季剧集或动漫,最头疼的就是音轨标签乱七八糟——日语、英语、中文混在一起,默认音轨设置也不对。手动在MKVToolNix里一集集调整&a…...

基于多模态视觉模型和图文向量模型的工业图像知识库研究与应用
目录1 概述... 12 单一模型分析的局限性... 23 多模态视觉模型和图文向量模型的优势... 34 多模态视觉模型和图文向量模型应用场景... 45 多模态视觉模型和图文向量模型原理... 46 多模态视觉模型和图文向量模型应用... 86.1 图片知识库... 86.2 检索图片... 117.总结... 13…...

构建跨平台桌面自动化命令行技能集:从原理到Python实现
1. 项目概述:一个桌面操作员的命令行技能集 最近在整理自己的自动化工具箱时,我重新审视了一个名为 cua_desktop_operator_cli_skill 的项目。这个名字听起来有点长,但拆解一下就能明白它的核心价值:“CUA”通常指代一种通用的用…...

软考资料全集
距离2026年上半年软考(5月开考)已不算遥远,现在正是着手准备的好时机。回顾这几年的备考历程,我也曾为找资料花费不少时间。趁着这次整理,我把手头积累的各科目复习资料——全部来自互联网公开渠道——系统地归拢了一下…...
)
ElevenLabs古吉拉特文语音合成失效排查手册(97.3%开发者忽略的ISO 639-2语言码陷阱)
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs古吉拉特文语音合成失效的根本诱因 ElevenLabs 官方 API 文档明确标注支持 Gujarati(gu-IN)语言标识,但实际调用时持续返回 400 Bad Request 或静音音频&…...

Canvas动画实战:从零构建动态星空效果与性能优化
1. 项目概述:从静态到动态的视觉魔法“Animated_star”这个项目名,听起来就充满了趣味和想象力。它不是一个复杂的商业应用,也不是一个深奥的算法研究,而是一个纯粹关于“视觉创造”的实践。简单来说,这个项目的核心目…...
广东省人民医院刘再毅amp;南方医科大学南方医院梁莉等团队:基于可解释深度学习模型预测胶质瘤分子改变)
Lancet Digit Health(IF=24.1)广东省人民医院刘再毅amp;南方医科大学南方医院梁莉等团队:基于可解释深度学习模型预测胶质瘤分子改变
01文献学习今天分享的文献是由广东省人民医院放射科刘再毅、南方医科大学南方医院梁莉等团队于2026年5月11日在柳叶刀旗下数字健康领域顶刊《The Lancet Digital Health》(中科院1区top,IF24.1)上发表的研究“Molecular alterations predicti…...