【NLP实战】基于Bert和双向LSTM的情感分类【下篇】
文章目录
- 前言
- 简介
- 第一部分
- 关于pytorch lightning保存模型的机制
- 关于如何读取保存好的模型
- 完善测试代码
- 第二部分
- 第一次训练出的模型的过拟合问题
- 如何解决过拟合
- 后记
前言
本文涉及的代码全由博主自己完成,可以随意拿去做参考。如对代码有不懂的地方请联系博主。
博主page:issey的博客 - 愿无岁月可回首
本系列文章中不会说明环境和包如何安装,这些应该是最基础的东西,可以自己边查边安装。
许多函数用法等在代码里有详细解释,但还是希望各位去看它们的官方文档,我的代码还有很多可以改进的方法,需要的函数等在官方文档都有说明。
简介
本系列将带领大家从数据获取、数据清洗,模型构建、训练,观察loss变化,调整超参数再次训练,并最后进行评估整一个过程。我们将获取一份公开竞赛中文数据,并一步步实验,到最后,我们的评估可以达到排行榜13位的位置。但重要的不是排名,而是我们能在其中学到很多。
本系列共分为三篇文章,分别是:
- 上篇:数据获取,数据分割与数据清洗
- 中篇:模型构建,改进pytorch结构,开始第一次训练
- 下篇:测试与评估,绘图与过拟合,超参数调整
本文为该系列第三篇文章,也是最后一篇。本文共分为两部分,在第一部分,我们将学习如何使用pytorch lightning保存模型的机制、如何读取模型与对测试集做测试。第二部分,我们将探讨前文遇到的过拟合问题,调整我们的超参数,进行第二轮训练,并对比两次训练的区别。我们还将基于pytorch lightning实现回调函数,保存训练过程中val_loss最小的模型。最后,将我们第二轮训练的best model进行评估,这一次,模型在测试集上的表现将达到排行榜第13位。
第一部分
关于pytorch lightning保存模型的机制
官方文档:Saving and loading checkpoints (basic) — PyTorch Lightning 2.0.1 documentation
简单来说,每次用lightning进行训练时,他都会自动保存最近epoch训练出的model参数在checkpoints里。而checkpoints默认在lightning_logs目录下。
你还可以同时保存某次训练的参数,或者写回调函数改变它保存模型的机制(这个我们待会儿会用到)。当然你也可以设置不让它自动保存模型。这一切都在官方文档里。博主就不细讲这些细节了,建议读者自己做实验。
现在我们知道了重要的两件事:
- 默认情况下,它会自动保存最近一次epoch训练结束后的模型。
- 我们只需要写回调函数,就可以改变它保存模型的机制。
关于如何读取保存好的模型
官方文档:Deploy models into production (basic) — PyTorch Lightning 2.0.1 documentation
根据文档,你还可以不用pytorch lightning,将模型读取到单纯的pytorch中,也可以使用。
感觉这部分讲的有点水?因为都在文档里,感觉没有需要逐一说明的地方。
现在,完善我们进行测试的代码。
完善测试代码
有几点需要说明:我们在测试时还计算了常用的评估标准:acc,recall,pre,f1。这里博主将通常需要用到的评估标准写法逐一列出了。我是根据函数说明一点一点摸索出来的,所以一并写出来方便以后用。
import torch
from datasets import load_dataset # hugging-face dataset
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
import torch.nn as nn
from transformers import BertTokenizer, BertModel
import torch.optim as optim
from torch.nn.functional import one_hot
import pytorch_lightning as pl
from pytorch_lightning import Trainer
from torchmetrics.functional import accuracy, recall, precision, f1_score # lightning中的评估
from pytorch_lightning.callbacks.early_stopping import EarlyStopping
from pytorch_lightning.callbacks import ModelCheckpoint# todo:自定义数据集
class MydataSet(Dataset):def __init__(self, path, split):self.dataset = load_dataset('csv', data_files=path, split=split)def __getitem__(self, item):text = self.dataset[item]['text']label = self.dataset[item]['label']return text, labeldef __len__(self):return len(self.dataset)# todo: 定义批处理函数
def collate_fn(data):sents = [i[0] for i in data]labels = [i[1] for i in data]# 分词并编码data = token.batch_encode_plus(batch_text_or_text_pairs=sents, # 单个句子参与编码truncation=True, # 当句子长度大于max_length时,截断padding='max_length', # 一律补pad到max_length长度max_length=200,return_tensors='pt', # 以pytorch的形式返回,可取值tf,pt,np,默认为返回listreturn_length=True,)# input_ids:编码之后的数字# attention_mask:是补零的位置是0,其他位置是1input_ids = data['input_ids'] # input_ids 就是编码后的词attention_mask = data['attention_mask'] # pad的位置是0,其他位置是1token_type_ids = data['token_type_ids'] # (如果是一对句子)第一个句子和特殊符号的位置是0,第二个句子的位置是1labels = torch.LongTensor(labels) # 该批次的labels# print(data['length'], data['length'].max())return input_ids, attention_mask, token_type_ids, labels# todo: 定义模型,上游使用bert预训练,下游任务选择双向LSTM模型,最后加一个全连接层
class BiLSTMClassifier(nn.Module):def __init__(self, drop, hidden_dim, output_dim):super(BiLSTMClassifier, self).__init__()self.drop = dropself.hidden_dim = hidden_dimself.output_dim = output_dim# 加载bert中文模型,生成embedding层self.embedding = BertModel.from_pretrained('bert-base-chinese')# 去掉移至gpu# 冻结上游模型参数(不进行预训练模型参数学习)for param in self.embedding.parameters():param.requires_grad_(False)# 生成下游RNN层以及全连接层self.lstm = nn.LSTM(input_size=768, hidden_size=self.hidden_dim, num_layers=2, batch_first=True,bidirectional=True, dropout=self.drop)self.fc = nn.Linear(self.hidden_dim * 2, self.output_dim)# 使用CrossEntropyLoss作为损失函数时,不需要激活。因为实际上CrossEntropyLoss将softmax-log-NLLLoss一并实现的。def forward(self, input_ids, attention_mask, token_type_ids):embedded = self.embedding(input_ids=input_ids, attention_mask=attention_mask, token_type_ids=token_type_ids)embedded = embedded.last_hidden_state # 第0维才是我们需要的embedding,embedding.last_hidden_state = embedding[0]out, (h_n, c_n) = self.lstm(embedded)output = torch.cat((h_n[-2, :, :], h_n[-1, :, :]), dim=1)output = self.fc(output)return output# todo: 定义pytorch lightning
class BiLSTMLighting(pl.LightningModule):def __init__(self, drop, hidden_dim, output_dim):super(BiLSTMLighting, self).__init__()self.model = BiLSTMClassifier(drop, hidden_dim, output_dim) # 设置modelself.criterion = nn.CrossEntropyLoss() # 设置损失函数self.train_dataset = MydataSet('./data/archive/train_clean.csv', 'train')self.val_dataset = MydataSet('./data/archive/val_clean.csv', 'train')self.test_dataset = MydataSet('./data/archive/test_clean.csv', 'train')def configure_optimizers(self):optimizer = optim.AdamW(self.parameters(), lr=lr)return optimizerdef forward(self, input_ids, attention_mask, token_type_ids): # forward(self,x)return self.model(input_ids, attention_mask, token_type_ids)def train_dataloader(self):train_loader = DataLoader(dataset=self.train_dataset, batch_size=batch_size, collate_fn=collate_fn,shuffle=True)return train_loaderdef training_step(self, batch, batch_idx):input_ids, attention_mask, token_type_ids, labels = batch # x, y = batchy = one_hot(labels + 1, num_classes=3)# 将one_hot_labels类型转换成floaty = y.to(dtype=torch.float)# forward passy_hat = self.model(input_ids, attention_mask, token_type_ids)y_hat = y_hat.squeeze() # 将[128, 1, 3]挤压为[128,3]loss = self.criterion(y_hat, y) # criterion(input, target)self.log('train_loss', loss, prog_bar=True, logger=True, on_step=True, on_epoch=True) # 将loss输出在控制台return loss # 必须把log返回回去才有用def val_dataloader(self):val_loader = DataLoader(dataset=self.val_dataset, batch_size=batch_size, collate_fn=collate_fn, shuffle=False)return val_loaderdef validation_step(self, batch, batch_idx):input_ids, attention_mask, token_type_ids, labels = batchy = one_hot(labels + 1, num_classes=3)y = y.to(dtype=torch.float)# forward passy_hat = self.model(input_ids, attention_mask, token_type_ids)y_hat = y_hat.squeeze()loss = self.criterion(y_hat, y)self.log('val_loss', loss, prog_bar=False, logger=True, on_step=True, on_epoch=True)return lossdef test_dataloader(self):test_loader = DataLoader(dataset=self.test_dataset, batch_size=batch_size, collate_fn=collate_fn, shuffle=False)return test_loaderdef test_step(self, batch, batch_idx):input_ids, attention_mask, token_type_ids, labels = batchtarget = labels + 1 # 用于待会儿计算acc和f1-scorey = one_hot(target, num_classes=3)y = y.to(dtype=torch.float)# forward passy_hat = self.model(input_ids, attention_mask, token_type_ids)y_hat = y_hat.squeeze()pred = torch.argmax(y_hat, dim=1)acc = (pred == target).float().mean()loss = self.criterion(y_hat, y)self.log('loss', loss)# task: Literal["binary", "multiclass", "multilabel"],对应[二分类,多分类,多标签]# average=None分别输出各个类别, 不加默认算平均re = recall(pred, target, task="multiclass", num_classes=class_num, average=None)pre = precision(pred, target, task="multiclass", num_classes=class_num, average=None)f1 = f1_score(pred, target, task="multiclass", num_classes=class_num, average=None)def log_score(name, scores):for i, score_class in enumerate(scores):self.log(f"{name}_class{i}", score_class)log_score("recall", re)log_score("precision", pre)log_score("f1", f1)self.log('acc', accuracy(pred, target, task="multiclass", num_classes=class_num))self.log('avg_recall', recall(pred, target, task="multiclass", num_classes=class_num, average="weighted"))self.log('avg_precision', precision(pred, target, task="multiclass", num_classes=class_num, average="weighted"))self.log('avg_f1', f1_score(pred, target, task="multiclass", num_classes=class_num, average="weighted"))def test():# 加载之前训练好的最优模型参数model = BiLSTMLighting.load_from_checkpoint(checkpoint_path=PATH,drop=dropout, hidden_dim=rnn_hidden, output_dim=class_num)trainer = Trainer(fast_dev_run=False)result = trainer.test(model)print(result)
输出:也就是上一篇末尾提前剧透的截图。

第二部分
第一次训练出的模型的过拟合问题
为什么提到之前的模型有过拟合问题呢?让我们打开tensorboard,观察train_loss和val_loss。
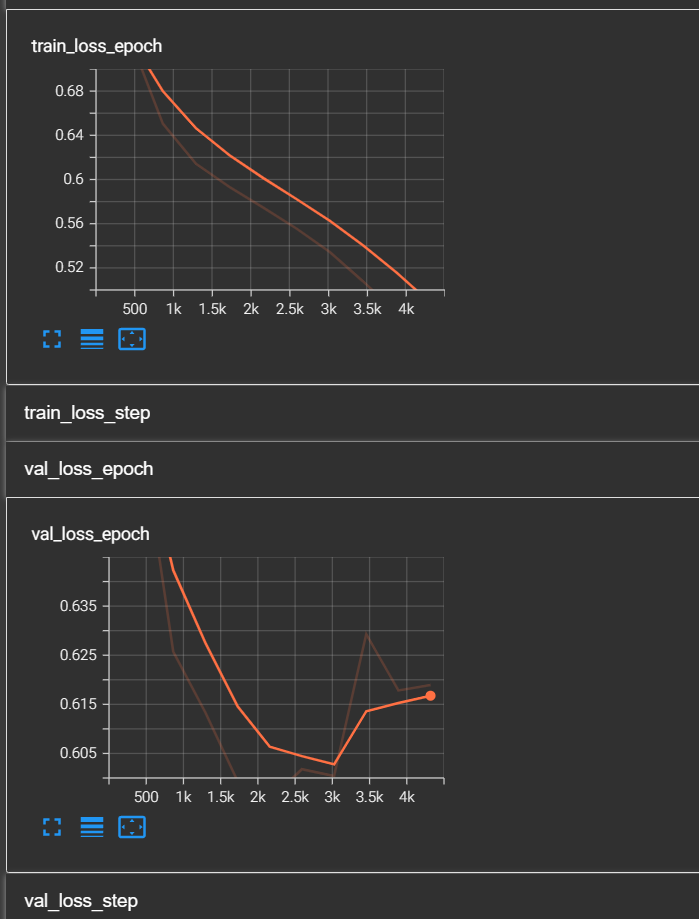
train_loss还没有收敛的趋势,但是val_loss已经出现了反弹的趋势。如果这还不算过拟合的预兆,博主做了第二个实验,我读取了第一次模型训练好的参数,并在次基础上继续训练,于是出现了以下的图像:
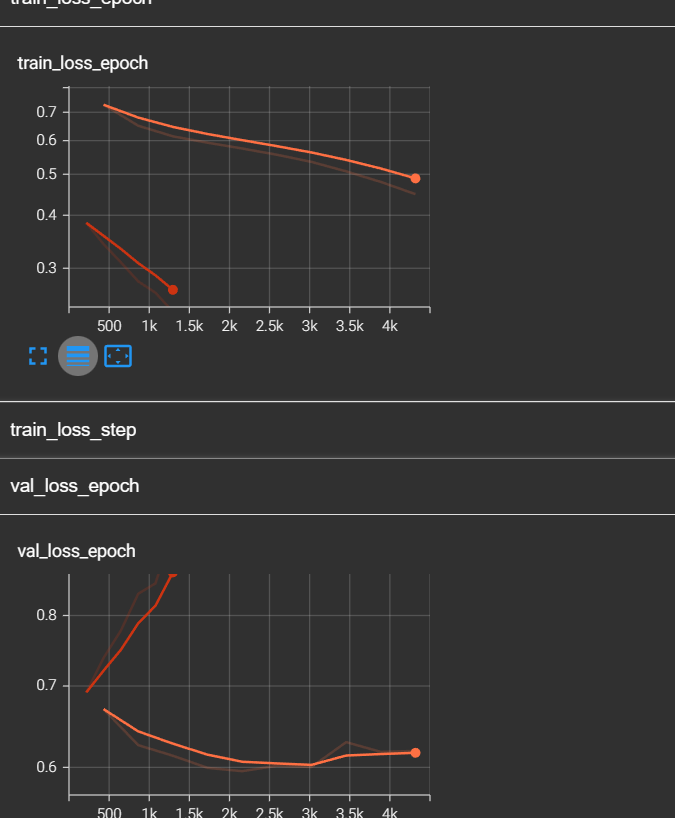
红色的线。可以看到,train_loss跟着橙色的线继续下降的,而val_loss直线上升,并且train_loss低于0.3时,val_loss高达0.9+。于是我们可以断定,过拟合了!
如何解决过拟合
最简单的方式是调参,我将batch_size由128调整到了256,将drop从0.4调整到了0.5,再次进行训练。同时,为了防止第二次也过拟合,我加入了回调函数,这个回调函数将保存过拟合之前最好的一组模型。这个回调函数的作用极为重要。下面给出最终版本的train代码:
def train():# 增加过拟合回调函数,提前停止,经过测试发现不太好用,因为可能会停止在局部最优值early_stop_callback = EarlyStopping(monitor='val_loss', # 监控对象为'val_loss'patience=4, # 耐心观察4个epochmin_delta=0.0, # 默认为0.0,指模型性能最小变化量verbose=True, # 在输出中显示一些关于early stopping的信息,如为何停止等)# 增加回调最优模型,这个比较好用checkpoint_callback = ModelCheckpoint(monitor='val_loss', # 监控对象为'val_loss'dirpath='checkpoints/', # 保存模型的路径filename='model-{epoch:02d}-{val_loss:.2f}', # 最优模型的名称save_top_k=1, # 只保存最好的那个 mode='min' # 当监控对象指标最小时)# Trainer可以帮助调试,比如快速运行、只使用一小部分数据进行测试、完整性检查等,# 详情请见官方文档https://lightning.ai/docs/pytorch/latest/debug/debugging_basic.html# auto自适应gpu数量trainer = Trainer(max_epochs=epochs, log_every_n_steps=10, accelerator='gpu', devices="auto", fast_dev_run=False,precision=16, callbacks=[checkpoint_callback])model = BiLSTMLighting(drop=dropout, hidden_dim=rnn_hidden, output_dim=class_num)trainer.fit(model)if __name__ == '__main__':# todo:定义超参数batch_size = 256epochs = 30dropout = 0.5rnn_hidden = 768rnn_layer = 1class_num = 3lr = 0.001PATH = 'PATH'token = BertTokenizer.from_pretrained('bert-base-chinese')train()# test()把他加入到上面的代码就行了。
关于回调函数的说明在代码里。
在第二天早上,我拿到了这次训练的结果:
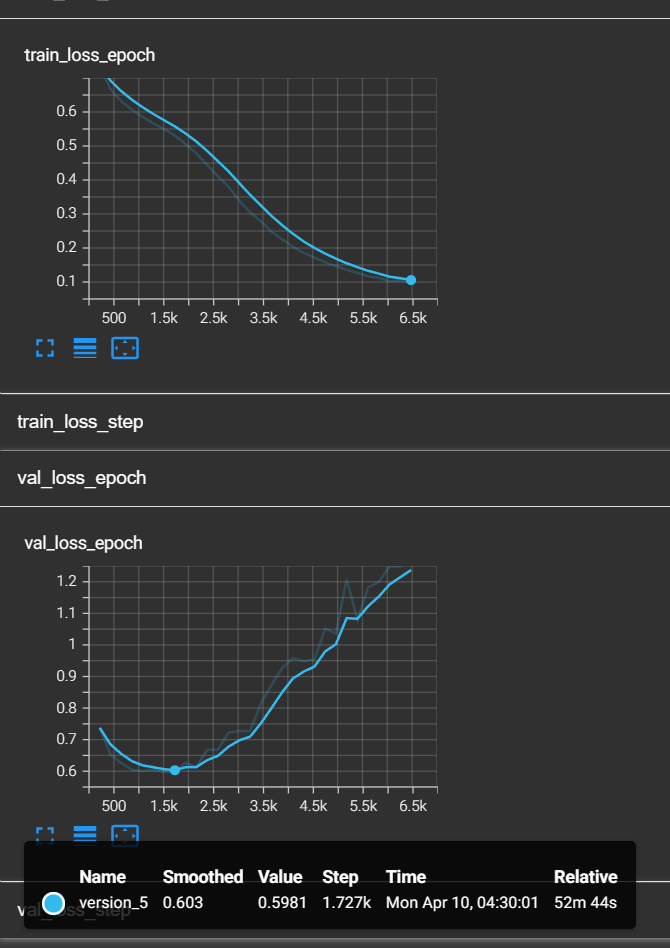
对比第一个模型:
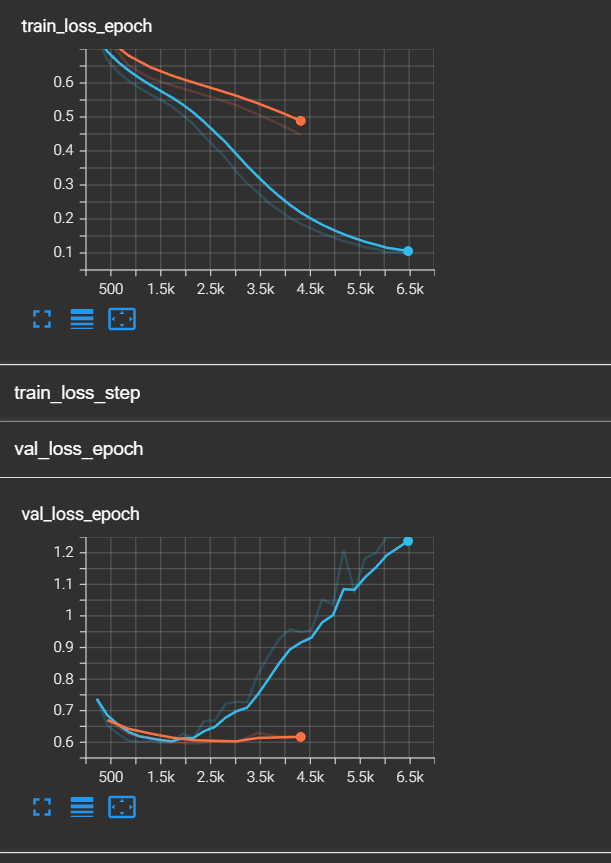
好吧,这次还是过拟合了,而且train loss居然低于了0.1,说明模型太复杂了。不过!由于我们的回调函数的存在,我们及时保存了val_loss最小时的模型。现在,将我们的模型路径换成best model,再次对测试集进行评估,我们会得到以下结果:
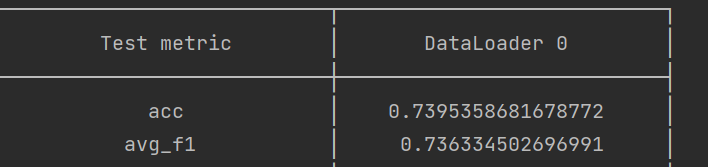
现在,它在排行榜第13位。

后记
终于写完了,一天肝完三篇文章。前面实验时在边实验边记录,所以写的比较快。
好像也没什么要写成后记的,该说的也都说完了。这三篇文章,其实就是这次实验的后记(笑)。
歇一歇,累~
还有很多不知道和要改进的地方,继续努力吧。
相关文章:
【NLP实战】基于Bert和双向LSTM的情感分类【下篇】
文章目录前言简介第一部分关于pytorch lightning保存模型的机制关于如何读取保存好的模型完善测试代码第二部分第一次训练出的模型的过拟合问题如何解决过拟合后记前言 本文涉及的代码全由博主自己完成,可以随意拿去做参考。如对代码有不懂的地方请联系博主。 博主…...

程序设计方法学
体育竞技分析 问题分析 体育竞技分析 需求:毫厘是多少? 如何科学分析体育竞技比赛? 输入:球员的水平 输出:可预测的比赛成绩 体育竞技分析:模拟N场比赛 计算思维:抽象 自动化 模拟&am…...

Hadoop之Yarn篇
目录 编辑 Yarn的工作机制: 全流程作业: Yarn的调度器与调度算法: FIFO调度器(先进先出): 容量调度器(Capacity Scheduler): 容量调度器资源分配算法࿱…...

Spring Cloud Nacos使用总结
目录 安装Nacos服务器 服务发现与消费 服务发现与消费-添加依赖 服务发现-配置文件 服务发现-注解 服务发现-Controller 服务消费-配置文件 服务消费-注解与Ribbon消费代码 服务消费-运行 配置管理 配置管理-添加依赖 配置管理-配置文件 配置管理-注解 配置管理-…...

目标检测框架yolov5环境搭建
目前,目标检测框架中,yolov5 是很火的,它基于pytorch框架,集成opencv等框架,项目地址:https://github.com/ultralytics/yolov5,对我来说,机器学习、深度学习才开始接触,本…...
Vulnhub:Digitalworld.local (JOY)靶机
kali:192.168.111.111 靶机:192.168.111.130 信息收集 端口扫描 nmap -A -v -sV -T5 -p- --scripthttp-enum 192.168.111.130 使用enum4linux枚举目标smb服务,发现两个系统用户 enum4linux -a 192.168.111.130 ftp可以匿名登陆ÿ…...

STL源码剖析-六大部件, 部件的关系,复杂度, 区间表示
C标准库-体系结构与内核分析 根据源代码来分析 介绍 自学C侯捷老师的STL源码剖析的个人笔记,方便以后进行学习,查询。 为什么要学STL?按侯捷老师的话来说就是:使用一个东西,却不明白它的道理,不高明&…...

总有一个可用的连接,metaIPC1.2进入智能连接新时代
概述 metaIPC有1.0和2.0两个产品系列,2.0版本是可视对讲IPC,1.0新版本1.2在全面兼容ICE规范基础上进行了扩展,使metaIPC1.2进入智能化连接新时代。 metaIPC1.2在host/stun/turn/srs/zlm/janus/freeswitch等p2p/sfu/mcu进行全方位连通测试&a…...

棋盘问题c
在一个给定形状的棋盘(形状可能是不规则的)上面摆放棋子,棋子没有区别。要求摆放时任意的两个棋子不能放在棋盘中的同一行或者同一列,请编程求解对于给定形状和大小的棋盘,摆放k个棋子的所有可行的摆放方案C。 Input …...

华纳云:Linux系统下怎么创建普通用户并更改用户组
本篇内容主要讲解“Linux系统下怎么创建普通用户并更改用户组”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“Linux系统下怎么创建普通用户并更改用户组”吧! 要求 项目做权限管理,不用root部…...

「她时代」背后的欧拉力量
2018年大热电视剧《北京女子图鉴》,讲述了一群在北京打拼的职业女性,她们背井离乡,被现实包裹,被压力、责任困扰,但依旧用倔强的个性、不屈的进取心和深厚的知识技能努力营造、交织出一片励志的天空,既激昂…...

kubespray v2.21.0 在线部署 kubernetes v1.24.0 集群【2】
文章目录创建 虚拟机模板虚拟机名称配置静态地址配置代理yum 配置配置主机名安装 git安装 docker安装 ansible配置内核参数安装 k8s定制安装新增节点配置主机名配置代理配置互信更新 inventory报错kubespray v2.21.0 部署 kubernetes v1.24.0 集群 【1】在 Rocky linux 8.7 使用…...

聚焦运营商信创运维,美信时代监控易四大亮点值得一试!
2021年11月《“十四五”信息通信行业发展规划》提出,到2025年,我国将建立高速泛在、集成互联、智能绿色、安全可靠的新型数字基础设施体系。 此《规划》让我国运营商信创进一步加速,中国移动、中国电信、中国联通等都先后加入信创大军&#x…...

[python刷题模板] 博弈入门-记忆化搜索/dp/打表
[python刷题模板] 博弈入门-记忆化搜索/dp/打表 一、 算法&数据结构1. 描述2. 复杂度分析3. 常见应用4. 常用优化二、 模板代码1. 打表贪心的博弈2. 464. 我能赢吗3. Nim游戏--最最基础版n1。三、其他四、更多例题五、参考链接一、 算法&数据结构 1. 描述 博弈一直没…...
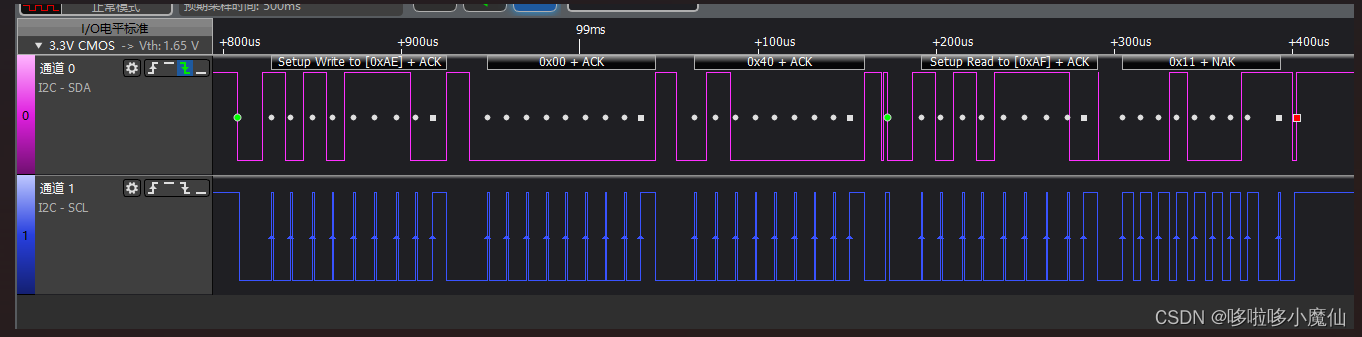
I2C通信
一、理论上了解I2C时序 I2C写数据时序如图: 通过解析器解析I2C通信如上图(SCL和SDA反了)。 1---起始信号 2、3---应答信号ACK 5---停止信号 起始信号:SCL线是高电平时,SDA线从高电平向低电平切换。 停…...
【Linux】man什么都搜不了,No manual entry for xxx的解决方案
本文首发于 慕雪的寒舍 man什么都搜不了,No manual entry for xxx的解决方案 系统 CentOS 7.6 1.问题描述 今天查手册的时候,发现man什么都查不了。不管是系统接口还是函数,都显示没有入口文档(No manual entry for)…...

STM32 库函数 GPIO_SetBits、GPIO_ResetBits、GPIO_WriteBit、GPIO_Write 区别
问题:当我使用STM32库函数对 I/O 口进行赋值时,在头文件中发现有四个相关的函数可以做这个操作,那么它们有什么区别呢? 一、GPIO_SetBits //eg: GPIO_SetBits(GPIOA, GPIO_Pin_1 | GPIO_Pin_2);解释:置位(置1)选择的数…...

在 RISC-V Linux 内核中添加模块
在 RISC-V Linux 内核中添加模块 flyfish 本例以添加helloworld字符设备为例 一 源码配置 1 源码 源码文件helloworld.c拷贝到 drivers/char 目录中 源码主要是输出Hello world init 2 Kconfig 打开drivers/char 目录下的Kconfig文件 在endmenu之前加上 config HELLO…...
利用AOP实现统一功能处理
目录 一、实现用户登录校验 实现自定义拦截器 将自定义的拦截器添加到框架的配置中,并且设置拦截的规则 二、实现统一异常处理 三、实现统一数据格式封装 一、实现用户登录校验 在之前的项目中,在需要验证用户登录的部分,每次都需要利…...

会话技巧---英文单词
目录 前言原文表示同意、答应表示不同意表示建议与忠告鼓励称赞担心与忧虑赞美夸奖-单词前言 加油 原文 表示同意、答应 1.agree[əˈgri]vi. 同意(=approve of); 答应(= consent to) agreement [əˈgrimənt] n. (意见或看法)一致 agree with sb about / on sth…...

LM317电源模块的“隐藏参数”与实战避坑:为什么你的空载电压总是不稳?
LM317电源模块的“隐藏参数”与实战避坑:为什么你的空载电压总是不稳? 在电子设计领域,LM317作为经典的可调线性稳压器,几乎出现在每个工程师的备件库中。但当你按照标准电路搭好原型,却发现空载时输出电压飘忽不定——…...

Linux串口编程进阶:深入termios2结构体,搞定CH340/FTDI各种转接器的非标准波特率
Linux串口编程实战:破解CH340/FTDI非标准波特率适配难题 当你在工业物联网项目中尝试将某个9600bps的设备升级到115200bps时,可能会发现某些USB转串口适配器死活不配合——明明代码正确,波特率却始终无法生效。这不是你的错,而是…...

独立开发者一人全栈项目中的AI能力集成与运维简化思路
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者一人全栈项目中的AI能力集成与运维简化思路 对于独立开发者而言,一人承担全栈项目的设计、开发和运维是常态…...

CW32L083定时器中断全解析:从基础定时到PWM捕获的实战指南
1. 项目概述与核心价值最近在做一个基于CW32L083的低功耗数据采集项目,其中有一个核心需求是每隔100毫秒精确采集一次传感器数据。为了实现这个看似简单的定时功能,我不得不把CW32的定时器子系统从头到尾捋了一遍。这不捋不知道,一捋才发现&a…...

Keil MDK-ARM许可证错误-25的解决方案
1. 问题现象与背景解析最近在升级Keil MDK-ARM到新版本后,不少开发者遇到了一个棘手的许可证错误。当尝试编译项目时,系统会弹出如下错误提示:Error: A9555E: License checkout for feature mdk_xxx_compiler5 with version 5.0201411 has be…...

如何在Windows 11上免费安装安卓子系统:3步快速搭建跨平台应用中心
如何在Windows 11上免费安装安卓子系统:3步快速搭建跨平台应用中心 【免费下载链接】WSA Developer-related issues and feature requests for Windows Subsystem for Android 项目地址: https://gitcode.com/gh_mirrors/ws/WSA 想在Windows电脑上无缝运行手…...

向量:一篇文章带你看清数学中最有“方向感“的概念
一、先讲一个让我"开窍"的故事 高中时第一次接触向量,老师在黑板上画了一个箭头,说:“这就是向量。” 我看着那个箭头,心想:这有什么稀奇的?不就是带方向的线段吗? 然后老师开始讲向量…...
的时序数据分解与重构)
Python实战:基于奇异谱分析(SSA)的时序数据分解与重构
1. 奇异谱分析(SSA)入门指南 第一次接触奇异谱分析(SSA)时,我被它优雅的数学结构和强大的分析能力所吸引。SSA本质上是一种将时间序列分解为趋势、周期和噪声成分的非参数方法,特别适合处理那些传统方法难以应对的非线性、非平稳时序数据。 SSA的核心思想…...

C语言泛型编程与类型安全 - C11的高级特性
引言 C语言通常被认为不支持泛型编程,但实际上通过巧妙的设计模式和C11标准的新特性,我们可以在C语言中实现类型安全的泛型代码。 本文将深入讲解如何使用void指针、宏技巧和C11的_Generic关键字实现泛型编程,让你的代码更加灵活和可复用。 一、void指针泛型基础 1.1 vo…...
3分钟掌握Pixelle-Video:零基础AI视频制作终极指南
3分钟掌握Pixelle-Video:零基础AI视频制作终极指南 【免费下载链接】Pixelle-Video 🚀 AI 全自动短视频引擎 | AI Fully Automated Short Video Engine 项目地址: https://gitcode.com/GitHub_Trending/pi/Pixelle-Video 还在为视频制作烦恼吗&am…...