【Python】【进阶篇】二十二、Python爬虫的BS4解析库
目录
- 二十二、Python爬虫的BS4解析库
- 22.1 BS4下载安装
- 22.2 BS4解析对象
- 22.3 BS4常用语法
- 1) Tag节点
- 22.4 遍历节点
- 22.5 find_all()与find()
- 1) find_all()
- 2) find()
- 22.6 CSS选择器
二十二、Python爬虫的BS4解析库
Beautiful Soup 简称 BS4(其中 4 表示版本号)是一个 Python 第三方库,它可以从 HTML 或 XML 文档中快速地提取指定的数据。Beautiful Soup 语法简单,使用方便,并且容易理解,因此您可以快速地学习并掌握它。
22.1 BS4下载安装
由于 Bautiful Soup 是第三方库,因此需要单独下载,下载方式非常简单,执行以下命令即可安装:
pip install bs4
由于 BS4 解析页面时需要依赖文档解析器,所以还需要安装 lxml 作为解析库:
pip install lxml
Python 也自带了一个文档解析库 html.parser, 但是其解析速度要稍慢于 lxml。除了上述解析器外,还可以使用 html5lib解析器,安装方式如下:
pip install html5lib
该解析器生成 HTML 格式的文档,但速度较慢。
“解析器容错”指的是被解析的文档发生错误或不符合格式时,通过解析器的容错性仍然可以按照既定的正确格式实现解析。
22.2 BS4解析对象
创建 BS4 解析对象是万事开头的第一步,这非常地简单,语法格式如下所示:
#导入解析包
from bs4 import BeautifulSoup
#创建beautifulsoup解析对象
soup = BeautifulSoup(html_doc, 'html.parser')
上述代码中,html_doc 表示要解析的文档,而 html.parser 表示解析文档时所用的解析器,此处的解析器也可以是 ‘lxml’ 或者’html5lib’,示例代码如下所示:
#coding:utf8
html_doc = """
<html><head><title>"c语言中文网"</title></head>
<body>
<p class="title"><b>c.biancheng.net</b></p>
<p class="website">一个学习编程的网站
<a href="http://c.biancheng.net/python/" id="link1">python教程</a>
<a href="http://c.biancheng.net/c/" id="link2">c语言教程</a>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_doc, 'html.parser')
#prettify()用于格式化输出html/xml文档
print(soup.prettify())
输出结果:
<html>
<head><title>"c语言中文网"</title>
</head>
<body><p class="title"><b>c.biancheng.net</b></p><p class="website">一个学习编程的网站<a href="http://c.biancheng.net/python/" id="link1">python教程</a><a href="http://c.biancheng.net/c/" id="link2">c语言教程</a>
</body>
</html>
如果是外部文档,您也可以通过 open() 的方式打开读取,语法格式如下:
soup = BeautifulSoup(open('html_doc.html', encoding='utf8'), 'lxml')
22.3 BS4常用语法
下面对爬虫中经常用到的 BS4 解析方法做详细介绍。
Beautiful Soup 将 HTML 文档转换成一个树形结构,该结构有利于快速地遍历和搜索 HTML 文档。下面使用树状结构来描述一段 HTML
文档:
<html><head><title>c语言中文网</title></head><h1>c.biancheng.net</h1><p><b>一个学习编程的网站</b></p></body></html>
树状图如下所示:

文档树中的每个节点都是 Python 对象,这些对象大致分为四类:Tag , NavigableString , BeautifulSoup ,Comment 。其中使用最多的是 Tag 和 NavigableString。
- Tag:标签类,HTML 文档中所有的标签都可以看做 Tag 对象。
- NavigableString:字符串类,指的是标签中的文本内容,使用 text、string、strings 来获取文本内容。
- BeautifulSoup:表示一个 HTML 文档的全部内容,您可以把它当作一个人特殊的 Tag 对象。
- Comment:表示 HTML 文档中的注释内容以及特殊字符串,它是一个特殊的 NavigableString。
1) Tag节点
标签(Tag)是组成 HTML 文档的基本元素。在 BS4 中,通过标签名和标签属性可以提取出想要的内容。看一组简单的示例:
from bs4 import BeautifulSoup
soup = BeautifulSoup('<p class="Web site url"><b>c.biancheng.net</b></p>', 'html.parser')
#获取整个p标签的html代码
print(soup.p)
#获取b标签
print(soup.p.b)
#获取p标签内容,使用NavigableString类中的string、text、get_text()
print(soup.p.text)
#返回一个字典,里面是多有属性和值
print(soup.p.attrs)
#查看返回的数据类型
print(type(soup.p))
#根据属性,获取标签的属性值,返回值为列表
print(soup.p['class'])
#给class属性赋值,此时属性值由列表转换为字符串
soup.p['class']=['Web','Site']
print(soup.p)
输出结果如下:
soup.p输出结果:
<p class="Web site url"><b>c.biancheng.net</b></p>soup.p.b输出结果:
<b>c.biancheng.net</b>soup.p.text输出结果:
c.biancheng.netsoup.p.attrs输出结果:
{'class': ['Web', 'site', 'url']}type(soup.p)输出结果:
<class 'bs4.element.Tag'>soup.p['class']输出结果:
['Web', 'site', 'url']class属性重新赋值:
<p class="Web Site"><b>c.biancheng.net</b></p>
22.4 遍历节点
Tag 对象提供了许多遍历 tag 节点的属性,比如 contents、children 用来遍历子节点;parent 与 parents 用来遍历父节点;而 next_sibling 与 previous_sibling 则用来遍历兄弟节点 。示例如下:
#coding:utf8
from bs4 import BeautifulSouphtml_doc = """
<html><head><title>"c语言中文网"</title></head>
<body>
<p class="title"><b>c.biancheng.net</b></p>
<p class="website">一个学习编程的网站</p>
<a href="http://c.biancheng.net/python/" id="link1">python教程</a>,
<a href="http://c.biancheng.net/c/" id="link2">c语言教程</a> and
"""
soup = BeautifulSoup(html_doc, 'html.parser')
body_tag=soup.body
print(body_tag)
#以列表的形式输出,所有子节点
print(body_tag.contents)
输出结果:
<body>
<p class="title"><b>c.biancheng.net</b></p>
<p class="website">一个学习编程的网站</p>
<a href="http://c.biancheng.net/python/" id="link1">python教程</a>,
<a href="http://c.biancheng.net/c/" id="link2">c语言教程</a> and
</body>
#以列表的形式输出
['\n', <p class="title"><b>c.biancheng.net</b></p>, '\n', <p class="website">一个学习编程的网站</p>, '\n', <a href="http://c.biancheng.net/python/" id="link1">python教程</a>, '\n', <a href="http://c.biancheng.net/c/" id="link2">c语言教程</a>, '\n']
Tag 的 children 属性会生成一个可迭代对象,可以用来遍历子节点,示例如下:
for child in body_tag.children:print(child)
输出结果:
#注意此处已将换行符"\n"省略
<p class="title"><b>c.biancheng.net</b></p>
<p class="website">一个学习编程的网站</p>
想了解更多相关示例可参考官方文档:点击前往
22.5 find_all()与find()
find_all() 与 find() 是解析 HTML 文档的常用方法,它们可以在 HTML 文档中按照一定的条件(相当于过滤器)查找所需内容。find() 与 find_all() 的语法格式相似,希望大家在学习的时候,可以举一反三。
BS4 库中定义了许多用于搜索的方法,find() 与 find_all() 是最为关键的两个方法,其余方法的参数和使用与其类似。
1) find_all()
find_all() 方法用来搜索当前 tag 的所有子节点,并判断这些节点是否符合过滤条件,最后以列表形式将符合条件的内容返回,语法格式如下:
find_all( name , attrs , recursive , text , limit )
参数说明:
- name:查找所有名字为 name 的 tag 标签,字符串对象会被自动忽略。
- attrs:按照属性名和属性值搜索 tag 标签,注意由于 class 是 Python 的关键字吗,所以要使用 “class_”。
- recursive:find_all() 会搜索 tag 的所有子孙节点,设置 recursive=False 可以只搜索 tag 的直接子节点。
- text:用来搜文档中的字符串内容,该参数可以接受字符串 、正则表达式 、列表、True。
- limit:由于 find_all() 会返回所有的搜索结果,这样会影响执行效率,通过 limit 参数可以限制返回结果的数量。
find_all() 使用示例如下:
from bs4 import BeautifulSoup
import rehtml_doc = """
<html><head><title>"c语言中文网"</title></head>
<body>
<p class="title"><b>c.biancheng.net</b></p>
<p class="website">一个学习编程的网站</p>
<a href="http://c.biancheng.net/python/" id="link1">python教程</a>
<a href="http://c.biancheng.net/c/" id="link2">c语言教程</a>
<a href="http://c.biancheng.net/django/" id="link3">django教程</a>
<p class="vip">加入我们阅读所有教程</p>
<a href="http://vip.biancheng.net/?from=index" id="link4">成为vip</a>
"""
#创建soup解析对象
soup = BeautifulSoup(html_doc, 'html.parser')
#查找所有a标签并返回
print(soup.find_all("a"))
#查找前两条a标签并返回
print(soup.find_all("a",limit=2))
#只返回两条a标签最后以列表的形式返回输出结果,如下所示:
[<a href="http://c.biancheng.net/python/" id="link1">python教程</a>, <a href="http://c.biancheng.net/c/" id="link2">c语言教程</a>, <a href="http://c.biancheng.net/django/" id="link3">django教程</a>, <a href="http://vip.biancheng.net/?from=index" id="link4">成为vip</a>][<a href="http://c.biancheng.net/python/" id="link1">python教程</a>, <a href="http://c.biancheng.net/c/" id="link2">c语言教程</a>]
按照标签属性以及属性值查找 HTML 文档,如下所示
print(soup.find_all("p",class_="website"))
print(soup.find_all(id="link4"))
输出结果:
[<p class="website">一个学习编程的网站</p>]
[<a href="http://vip.biancheng.net/?from=index" id="link4">成为vip</a>]
正则表达式、列表,以及 True 也可以当做过滤条件,使用示例如下:
#列表行书查找tag标签
print(soup.find_all(['b','a']))
#正则表达式匹配id属性值
print(soup.find_all('a',id=re.compile(r'.\d')))
print(soup.find_all(id=True))
#True可以匹配任何值,下面代码会查找所有tag,并返回相应的tag名称
for tag in soup.find_all(True):print(tag.name,end=" ")
#输出所有以b开始的tag标签
for tag in soup.find_all(re.compile("^b")):print(tag.name)
输出结果如下:
第一个print输出:
[<b>c.biancheng.net</b>, <a href="http://c.biancheng.net/python/" id="link1">python教程</a>, <a href="http://c.biancheng.net/c/" id="link2">c语言教程</a>, <a href="http://c.biancheng.net/django/" id="link3">django教程</a>, <a href="http://vip.biancheng.net/?from=index" id="link4">成为vip</a>]
第二个print输出:
[<a href="http://c.biancheng.net/python/" id="link1">python教程</a>, <a href="http://c.biancheng.net/c/" id="link2">c语言教程</a>, <a href="http://c.biancheng.net/django/" id="link3">django教程</a>, <a href="http://vip.biancheng.net/?from=index" id="link4">成为vip</a>]
第三个print输出:
[<a href="http://c.biancheng.net/python/" id="link1">python教程</a>, <a href="http://c.biancheng.net/c/" id="link2">c语言教程</a>, <a href="http://c.biancheng.net/django/" id="link3">django教程</a>, <a href="http://vip.biancheng.net/?from=index" id="link4">成为vip</a>]
第四个print输出:
html head title body p b p a a a p a
最后一个输出:
body b
BS4 为了简化代码,为 find_all() 提供了一种简化写法,如下所示:
#简化前
soup.find_all("a")
#简化后
soup("a")
上述两种的方法的输出结果是相同的。
2) find()
find() 方法与 find_all() 类似,不同之处在于 find_all() 会将文档中所有符合条件的结果返回,而 find()
仅返回一个符合条件的结果,所以 find() 方法没有limit参数。使用示例如下:
from bs4 import BeautifulSoup
import rehtml_doc = """
<html><head><title>"c语言中文网"</title></head>
<body>
<p class="title"><b>c.biancheng.net</b></p>
<p class="website">一个学习编程的网站</p>
<a href="http://c.biancheng.net/python/" id="link1">python教程</a>
<a href="http://c.biancheng.net/c/" id="link2">c语言教程</a>
<a href="http://c.biancheng.net/django/" id="link3">django教程</a>
<p class="vip">加入我们阅读所有教程</p>
<a href="http://vip.biancheng.net/?from=index" id="link4">成为vip</a>
"""
#创建soup解析对象
soup = BeautifulSoup(html_doc, 'html.parser')
#查找第一个a并直接返回结果
print(soup.find('a'))
#查找title
print(soup.find('title'))
#匹配指定href属性的a标签
print(soup.find('a',href='http://c.biancheng.net/python/'))
#根据属性值正则匹配
print(soup.find(class_=re.compile('tit')))
#attrs参数值
print(soup.find(attrs={'class':'vip'}))
输出结果如下:
a标签:
<a href="http://c.biancheng.net/python/" id="link1">python教程</a>
指定href属性:
<a href="http://c.biancheng.net/python/" id="link1">python教程</a>
title:
<title>"c语言中文网"</title>
正则匹配:
<p class="title"><b>c.biancheng.net</b></p>
#attrs参数值
<p class="vip">加入我们阅读所有教程</p>
使用 find() 时,如果没有找到查询标签会返回 None,而 find_all() 方法返回空列表。示例如下:
print(soup.find('bdi'))
print(soup.find_all('audio'))
输出结果如下:
None
[]
BS4 也为 find()提供了简化写法,如下所示:
#简化写法
print(soup.head.title)
#上面代码等价于
print(soup.find("head").find("title"))
两种写法的输出结果相同,如下所示:
<title>"c语言中文网"</title>
<title>"c语言中文网"</title>
22.6 CSS选择器
BS4 支持大部分的 CSS 选择器,比如常见的标签选择器、类选择器、id 选择器,以及层级选择器。Beautiful Soup 提供了一个
select() 方法,通过向该方法中添加选择器,就可以在 HTML 文档中搜索到与之对应的内容。应用示例如下:
#coding:utf8
html_doc = """
<html><head><title>"c语言中文网"</title></head>
<body>
<p class="title"><b>c.biancheng.net</b></p>
<p class="website">一个学习编程的网站</p>
<a href="http://c.biancheng.net/python/" id="link1">python教程</a>
<a href="http://c.biancheng.net/c/" id="link2">c语言教程</a>
<a href="http://c.biancheng.net/django/" id="link3">django教程</a>
<p class="vip">加入我们阅读所有教程</p>
<a href="http://vip.biancheng.net/?from=index" id="link4">成为vip</a>
<p class="introduce">介绍:
<a href="http://c.biancheng.net/view/8066.html" id="link5">关于网站</a>
<a href="http://c.biancheng.net/view/8092.html" id="link6">关于站长</a>
</p>
"""
from bs4 import BeautifulSoupsoup = BeautifulSoup(html_doc, 'html.parser')
#根据元素标签查找
print(soup.select('title'))
#根据属性选择器查找
print(soup.select('a[href]'))
#根据类查找
print(soup.select('.vip'))
#后代节点查找
print(soup.select('html head title'))
#查找兄弟节点
print(soup.select('p + a'))
#根据id选择p标签的兄弟节点
print(soup.select('p ~ #link3'))
#nth-of-type(n)选择器,用于匹配同类型中的第n个同级兄弟元素
print(soup.select('p ~ a:nth-of-type(1)'))
#查找子节点
print(soup.select('p > a'))
print(soup.select('.introduce > #link5'))
输出结果:
第一个输出:
[<title>"c语言中文网"</title>]第二个输出:
[<a href="http://c.biancheng.net/python/" id="link1">python教程</a>, <a href="http://c.biancheng.net/c/" id="link2">c语言教程</a>, <a href="http://c.biancheng.net/django/" id="link3">django教程</a>, <a href="http://vip.biancheng.net/?from=index" id="link4">成为vip</a>, <a href="http://c.biancheng.net/view/8066.html" id="link5">关于网站</a>, <a href="http://c.biancheng.net/view/8092.html" id="link6">关于站长</a>]第三个输出:
[<p class="vip">加入我们阅读所有教程</p>]第四个输出:
[<title>"c语言中文网"</title>]第五个输出:
[<a href="http://c.biancheng.net/python/" id="link1">python教程</a>, <a href="http://vip.biancheng.net/?from=index" id="link4">成为vip</a>]第六个输出:
[<a href="http://c.biancheng.net/django/" id="link3">django教程</a>]第七个输出:
[<a href="http://c.biancheng.net/python/" id="link1">python教程</a>]第八个输出:
[<a href="http://c.biancheng.net/view/8066.html" id="link5">关于网站</a>, <a href="http://c.biancheng.net/view/8092.html" id="link6">关于站长</a>]最后的print输出:
[<a href="http://c.biancheng.net/view/8066.html" id="link5">关于网站</a>]
如果想了解更多关于 BS4 库的使用方法,可以参考官方文档
相关文章:
【Python】【进阶篇】二十二、Python爬虫的BS4解析库
目录二十二、Python爬虫的BS4解析库22.1 BS4下载安装22.2 BS4解析对象22.3 BS4常用语法1) Tag节点22.4 遍历节点22.5 find_all()与find()1) find_all()2) find()22.6 CSS选择器二十二、Python爬虫的BS4解析库 Beautiful Soup 简称 BS4(其中 4 表示版本号࿰…...

UDS统一诊断服务【五】诊断仪在线0X3E服务
文章目录前言一、诊断仪在线服务介绍二、数据格式2.1,请求报文2.2,子功能2.3,响应报文前言 本文介绍UDS统一诊断服务的0X3E服务,希望能对你有所帮助 一、诊断仪在线服务介绍 诊断仪在线服务比较简单,其功能就是告诉服…...
我的创作纪念日:Unity CEO表示生成式AI将是Unity近期发展重点,发布神秘影片预告
PICK 未来的AI技术将会让人类迎来下一个生产力变革,这其中也包括生成型AI的突破性革新。各大公司也正在竞相推出AIGC工具,其中微软的Copilot、Adobe的Firefly、Github的chatGPT等引起了人们的关注。然而,游戏开发领域似乎还没有一款真正针对性…...

秩亏自由网平差的直接解法
目录 一、原理概述二、案例分析三、代码实现四、结果展示一、原理概述 N = B T P B N=B^TPB N=<...

大数据开发必备面试题Spark篇合集
1、Hadoop 和 Spark 的相同点和不同点? Hadoop 底层使用 MapReduce 计算架构,只有 map 和 reduce 两种操作,表达能力比较欠缺,而且在 MR 过程中会重复的读写 hdfs,造成大量的磁盘 io 读写操作,所以适合高时…...

C ++匿名函数:揭开C++ Lambda表达式的神秘面纱
潜意识编程:揭秘C Lambda表达式的神秘面纱 Subconscious Programming: Unveiling the Mystery of C Lambda Expressions 引言:Lambda表达式的魅力 (The Charm of C Lambda Expressions)Lambda表达式简介与基本概念 (Introduction and Basic Concepts of …...
AOP使用场景记录总结(缓慢补充更新中)
测试项目结构: 目前是测试两个日志记录和 代码的性能测试 后面如果有其他的应用场景了在添加.其实一中就包括了二,但是没事,多练一遍 1. 日志记录 比如说对service层中的所有增加,删除,修改方法添加日志, 记录内容包括操作的时间 操作的方法, 方法的参数, 方法所在的类, 方法…...
FPGA基于XDMA实现PCIE X4的HDMI视频采集 提供工程源码和QT上位机程序和技术支持
目录1、前言2、我已有的PCIE方案3、PCIE理论4、总体设计思路和方案5、vivado工程详解6、驱动安装7、QT上位机软件8、上板调试验证9、福利:工程代码的获取1、前言 PCIE(PCI Express)采用了目前业内流行的点对点串行连接,比起 PCI …...

ArcGIS、ENVI、InVEST、FRAGSTATS等多技术融合提升环境、生态、水文、土地、土壤、农业、大气等领域的数据分析
查看原文>>>ArcGIS、ENVI、InVEST、FRAGSTATS等多技术融合提升环境、生态、水文、土地、土壤、农业、大气等领域的数据分析 目录 专题一、空间数据获取与制图 专题二、ArcGIS专题地图制作 专题三、空间数据采集与处理 专题四、遥感数据处理与应用 专题五、DEM数据…...

怎么找回回收站里已经删除的文件
作为忙忙碌碌的打工人,电脑办公是在所难免的,而将使电脑存储着大量的数据文件,不少小伙伴都养成了定期清理电脑的习惯。而清理简单快捷的方法,无疑是直接把文件拖进回收站里。再一键清空,清理工作就完成了。但如果发现…...

Spring Boot、Cloud、Alibaba 版本说明
Spring Boot、Cloud、Alibaba 版本说明 一、毕业版本依赖关系(推荐使用) 由于 Spring Boot 3.0,Spring Boot 2.7~2.4 和 2.4 以下版本之间变化较大,目前企业级客户老项目相关 Spring Boot 版本仍停留在 Spring Boot 2.4 以下,为了同时满足存…...
软件测试入门第一步:编写测试报告
什么是测试报告? 1、说明:是指把测试的过程和结果写成文档,对发现的问题和缺陷进行分析,为纠正软件的存在的质量问题提供依据,同时为软件验收和交付打下基础。 ps. 【测试过程和测试结果的分析报告,以及上线…...
)
【Vue】vue中的路由导航守卫(路由的生命周期)
文章目录全局前置守卫可选的第三个参数 next全局解析守卫router.beforeResolve全局后置钩子路由独享的守卫组件内的守卫可用的配置 API使用组合 API完整的导航解析流程正如其名,vue-router 提供的导航守卫主要用来通过跳转或取消的方式守卫导航。这里有很多方式植入…...

NumPy 基础知识 :6~10
原文:Numpy Essentials 协议:CC BY-NC-SA 4.0 译者:飞龙 六、NumPy 中的傅立叶分析 除其他事项外,傅立叶分析通常用于数字信号处理。 这要归功于它在将输入信号(时域)分离为以离散频率(频域&am…...
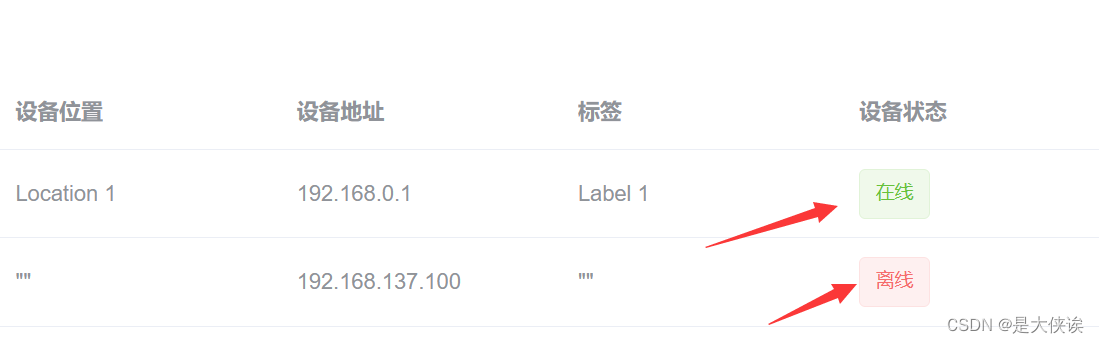
实现vue的条件渲染
我的需求是根据设备不同的状态 渲染不同的标签。设备状态用device_State表示。 在线上面是一个vue的标签,我有一个数据state ,如何让这个标签根据数据的取值 ,修改内容,如state1时,标签修改为离线 要根据数据的取值动态…...
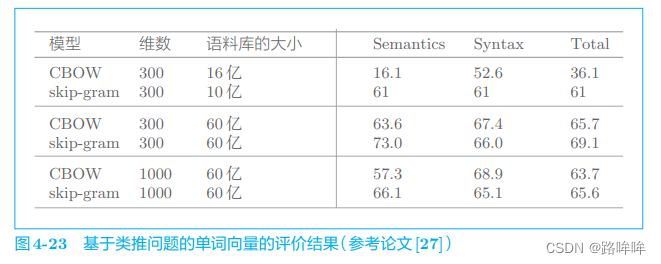
第四章 word2vec 的高速化
目录4.1 word2vec 的改进①4.1.1 Embedding 层4.1.2 Embedding 层的实现4.2 word2vec 的改进②4.2.1 中间层之后的计算问题4.2.2 从多分类到二分类4.2.3 sigmoid 函数和交叉熵误差4.2.4 多分类到二分类的实现4.2.5 负采样4.2.6 负采样的采样方法4.2.7 负采样的实现4.3 改进版 w…...
/copy_object_model_3d()算子)
【四】3D Object Model之创建Creation——clear_object_model_3d()/copy_object_model_3d()算子
😊😊😊欢迎来到本博客😊😊😊 🌟🌟🌟 Halcon算子太多,学习查找都没有系统的学习查找路径,本专栏主要分享Halcon各类算子含义及用法,有…...

第三十一章 配置镜像 - 删除镜像成员时删除镜像数据库属性
文章目录第三十一章 配置镜像 - 删除镜像成员时删除镜像数据库属性删除镜像成员时删除镜像数据库属性编辑或删除异步成员第三十一章 配置镜像 - 删除镜像成员时删除镜像数据库属性 删除镜像成员时删除镜像数据库属性 当从镜像中删除成员时,始终可以选择从属于该镜…...
自动写作ai-自动写作神器
自动生成文章 自动生成文章是指使用自然语言处理和人工智能技术,通过算法来自动生成文章的过程。一些自动生成文章的工具可以使用大量数据,学习数据背后的语言规范和知识结构,从而生成高质量和有用的文章。这种技术能够减少写作时间和人力成…...
)
P1368 【模板】最小表示法(SAM 求最小循环移位)
【模板】最小表示法 题目描述 小敏和小燕是一对好朋友。 他们正在玩一种神奇的游戏,叫 Minecraft。 他们现在要做一个由方块构成的长条工艺品。但是方块现在是乱的,而且由于机器的要求,他们只能做到把这个工艺品最左边的方块放到最右边。…...

三步完成微信好友关系一键检测:发现谁偷偷删除了你
三步完成微信好友关系一键检测:发现谁偷偷删除了你 【免费下载链接】WechatRealFriends 微信好友关系一键检测,基于微信ipad协议,看看有没有朋友偷偷删掉或者拉黑你 项目地址: https://gitcode.com/gh_mirrors/we/WechatRealFriends 你…...

Textractor:3分钟掌握游戏文本提取,轻松跨越语言障碍!
Textractor:3分钟掌握游戏文本提取,轻松跨越语言障碍! 【免费下载链接】Textractor Extracts text from video games and visual novels. Highly extensible. 项目地址: https://gitcode.com/gh_mirrors/te/Textractor 还在为看不懂日…...

科研抢发期必看:Perplexity图书推荐查询速效组合技——3分钟生成带引用格式的跨学科书单
更多请点击: https://codechina.net 第一章:科研抢发期必看:Perplexity图书推荐查询速效组合技——3分钟生成带引用格式的跨学科书单 在论文投稿前的关键窗口期,快速定位权威参考文献是提升学术严谨性与跨学科说服力的核心能力。…...

CG-65 剖面细管式温度传感器 小巧便携 多层温度同监测
一、产品概述:小巧便携,功能集成在农业生产、环境监测等诸多领域,土壤温度是一项至关重要的参数。一款性能优异的土壤温度监测设备,能够为相关工作提供精准的数据支持。我们的多深度土壤温度监测仪,正是这样一款专为精…...

保姆级教程:解决PyTorchViz安装报错,手把手教你用AlexNet模型可视化
PyTorch模型可视化实战:从安装报错到AlexNet结构解析全指南 在深度学习模型开发过程中,可视化工具如同开发者的"第二双眼睛"。PyTorchViz作为PyTorch生态中轻量级但功能强大的可视化工具,能直观展示模型的计算图结构,帮…...

全志V853开发板驱动7寸RGB屏:Linux DRM设备树配置与调试实战
1. 项目概述:当开发板遇上七寸RGB屏最近在折腾百问网的100ASK_V853-PRO开发板,发现一个挺有意思的需求:让它驱动一块七寸的RGB接口屏幕。这听起来像是个简单的“接线-点亮”的活儿,但真上手了才发现,从硬件引脚匹配、设…...

生物医学英文文献去哪查?
想追踪领域前沿,国际数据库访问不稳定,找篇文献要翻三四个平台;想梳理本土研究进展,中文核心资源分散在不同库,检索起来浪费大半天;要做学科趋势分析,各种工具功能碎片化,导出数据还…...

5分钟搭建拼多多商品数据采集系统:电商从业者的完整解决方案
5分钟搭建拼多多商品数据采集系统:电商从业者的完整解决方案 【免费下载链接】scrapy-pinduoduo 拼多多爬虫,抓取拼多多热销商品信息和评论 项目地址: https://gitcode.com/gh_mirrors/sc/scrapy-pinduoduo 在电商竞争日益激烈的今天,…...

保姆级教程:用QGIS的SRTM-Downloader插件,5分钟搞定中国区域地形图下载与渲染
5分钟极速出图:QGIS地形图制作全流程实战指南 当你在凌晨三点赶制项目报告,或是课程作业截止前两小时突然需要一张专业地形图时,传统GIS软件的复杂操作流程往往让人抓狂。本文将带你用QGIS的SRTM-Downloader插件,像点外卖一样简单…...

初次使用 Taotoken 模型广场进行模型选型与测试的流程指引
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初次使用 Taotoken 模型广场进行模型选型与测试的流程指引 对于刚接触大模型服务的开发者而言,面对众多厂商和模型&…...