机器学习——数据处理
机器学习简介
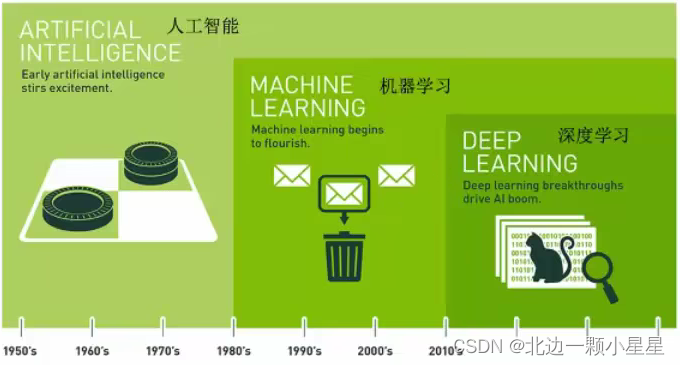
- 机器学习是人工智能的一个实现途径
- 深度学习是机器学习的一个方法发展而来
机器学习:从数据中自动分析获得模型,并利用模型对未知数据进行预测。
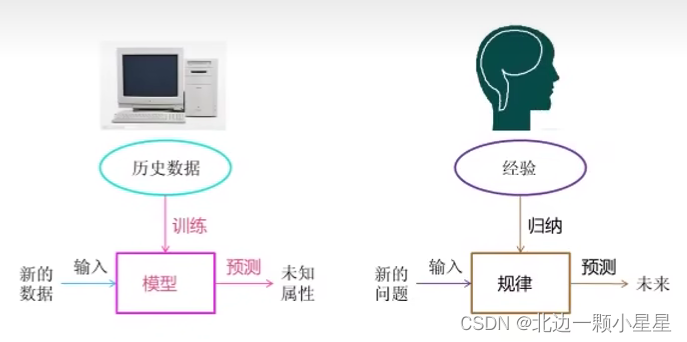
数据集的格式:
特征值+目标值
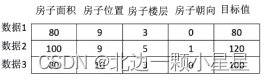
比如上图中房子的各种属性是特征值,然后房屋价格是目标值。
注:
- 对于每一行数据我们可以称之为样本
- 有些数据集可以没有目标值——聚类
深度学习与机器学习的关系:
深度学习是使用深度神经网络的机器学习。
——机器学习里面有种结构叫神经网络,神经网络多层的就叫深度学习,深度就是多层次的意思。
机器学习算法分类:
有目标值-监督学习
目标值是类别(如猫、狗)——分类问题
目标值是连续型的数据(如房屋价格)——回归问题
无目标值-无监督学习
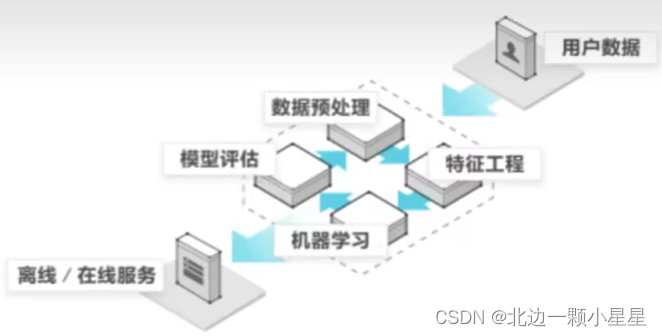
机器学习开发流程:
数据集的使用
常用数据集有sklearn、kaggle和UCI,这里以sklearn举例 :
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_splitdef datasets_demo():# 获取数据集iris = load_iris() # load获取小规模数据集,fetch获取大规模数据集print("鸢尾花数据集:\n", iris)print("查看数据集描述:\n", iris.DESCR) # 除了 .属性 的方式也可以用字典键值对的方式 iris["DESCR"]print("查看特征值的名称:\n", iris.feature_names)print("查看特征值:\n", iris.data, iris.data.shape)# 数据集划分x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=22)# 四个x、y分别是训练集特征值,测试集特征值,训练集目标集和测试集目标集,这同时也是这个API的返回值的顺序# test_size为测试集大小(float),默认是0.25,将大多的数据用于训练,测试集一般占20~30%,用于模型评估# 伪随机,random_state是随机数种子(不同的种子会造成不同的随机采样结果,相同的种子采样结果相同),如果后面要比较不同算法的优劣,那么数据划分方式要一样,即随机数种子一样以控制变量print("训练集的特征值:\n", x_train, x_train.shape)return Noneif __name__ == "__main__":datasets_demo()
特征工程
特征工程是使用专业背景知识和技巧处理数据,使得特征能在机器学习算法上更好的作用的过程。
数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。
特征提取:
将任意数据(文本或图像)转换为可用于机器学习的数字特征。
特征值化是为了让计算机更好的去理解数据。
- 字典特征提取(特征离散化)
- 文本特征提取
- 图像特征提取(深度学习再介绍)
矩阵 matrix 二维数组
向量 vector 一维数组
类别——> one-hot编码(即独热编码)
如果将类别直接表示成数字,那么数字有大小会误将类别也分大小,为了使各类别公平,让几个类别就几个位置,是这个类别就置1,不是就置0,即one-hot编码处理。
字典特征提取
from sklearn.feature_extraction import DictVectorizerdef dict_demo():data = [{'city': '北京', 'temperature': 10}, {'city': '上海', 'temperature': 15}, {'city': '深圳', 'temperature': 20}]# 实例化一个转换器类transfer = DictVectorizer(sparse=False) # 默认返回sparse稀疏矩阵(只将非零值按位置表示出来,节省内存,提高加载效率)# 调用fit_transform(),实现数据转换data_new = transfer.fit_transform(data)print("data_new:\n", data_new)print("特征名字:\n", transfer.get_feature_names_out())return Noneif __name__ == "__main__":dict_demo()
文本特征提取
英文特征提取样例:
from sklearn.feature_extraction.text import CountVectorizerdef count_demo():data = ["I like C++,C++ like me", "I like python,python also like me"] # 一般以单词作为特征,会忽略单个字母的单词# 如果是中文则还需要分词将词语隔开(按空格识别),如data = ["我 爱 中国"],同样也会忽略单个中文字# 实例化一个转换器类transfer = CountVectorizer() # CountVectorizer(),统计每个样本特征词出现的个数,没有sparse=False这个参数# 如果transfer = CountVectorizer(stop_words=["also","me"])意为特征词里去掉also、me这些词,表示这些词不适合作特征# 调用fit_transform(),实现数据转换data_new = transfer.fit_transform(data)print("data_new:\n", data_new.toarray()) # 用toarray方法等效于sparse=Falseprint("特征词:\n", transfer.get_feature_names_out())return Noneif __name__ == "__main__":count_demo()
中文特征提取样例:
from sklearn.feature_extraction.text import CountVectorizer
import jiebadef cut_word(text):return " ".join(list(jieba.cut(text))) # 先转成list列表再转成字符串,jieba是中文分词组件def count_demo():data = ["我爱广东", "我爱中国"]data_new = []for sent in data:data_new.append(cut_word(sent))# 实例化一个转换器类transfer = CountVectorizer()# 调用fit_transform(),实现数据转换data_final = transfer.fit_transform(data_new)print("data_new:\n", data_final.toarray()) # 用toarray方法等效于sparse=Falseprint("特征词:\n", transfer.get_feature_names_out())return Noneif __name__ == "__main__":jieba.setLogLevel(jieba.logging.INFO) # 去除报错count_demo()
关键词:在某一类别的文章中出现的次数很多,而在其他类别的文章中出现类别很少的词。
Tf-idf文本特征提取
- TF-IDF的主要思想:如果某个词或短语在一篇文章中出现的概率高,并且在其他文章中很少出现,则认为此词或短语具有很好的类别区分能力,适合用来分类。
- TF-IDF的作用:用以评估一个词对于一个文件集或一个语料库中的其中一份文件的重要程度。
公式
- 词频(term frequency,tf)指的是某一个给定的词语在该文件中出现的频率
- 逆向文档频率(inverse document frequency,idf)是一个词语普遍重要性的度量。某一特定词语的idf,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取以10为底的对数得到
最终得出结果可以理解为重要程度。
from sklearn.feature_extraction.text import TfidfVectorizer
import jiebadef cut_word(text):return " ".join(list(jieba.cut(text)))def tfidf_demo():data = ["相遇,是一种美丽,像一座小城向晚,映着夕阳的绚烂。","对执着的人来说,最难莫过于放弃,在间断间续的挣扎中,感谢时间的治愈。","过去无法重写,但它却让我更加坚强。感谢每一次改变,每一次心碎,每一块伤疤。"]data_new = []for sent in data:data_new.append(cut_word(sent))# 实例化一个转换器类transfer = TfidfVectorizer()# 调用fit_transform(),实现数据转换data_final = transfer.fit_transform(data_new)print("data_new:\n", data_final.toarray())print("特征词:\n", transfer.get_feature_names_out())return Noneif __name__ == "__main__":jieba.setLogLevel(jieba.logging.INFO) # 去除报错tfidf_demo()
特征预处理
通过一些转换函数将特征数据转换成更加适合算法模型的特征数据过程 。
数值型数据的无量纲化:
- 归一化
- 标准化
为什么要进行归一化/标准化?
特征的单位或者大小相差较大,或者某特征的方差相比其他的特征要大出几个数量级,容易影响(支配)目标 结果,使得一些算法无法学习到其他特征。
测试数据(data.txt):
height,weight,sex
178,60,1
173,60,2
180,65,1
182,70,1
168,55,2
归一化
通过对原始数据进行变换把数据映射到(默认为[0,1])之间。
作用于每一列,为一列的最大值,
为一列的最小值,
,
分别为指定区间值,默认
为1,
为0,
为最终结果。
from sklearn.preprocessing import MinMaxScaler
import pandas as pddef minmax_demo():# 读取数据data = pd.read_csv("data.txt")data = data.iloc[:, :2] # 提取所需数据,行全部都要,列要前两列print("data:\n", data)# 实例化一个转换器类transfer = MinMaxScaler() # 默认是transfer = MinMaxScaler(feature_range=(0,1))即区间[0,1]# 调用fit_transform()data_new = transfer.fit_transform(data)print("data_new:\n", data_new)return Noneif __name__ == "__main__":minmax_demo()
如果最大值/最小值刚好是异常值,那么归一化的结果就不准确,这种方法鲁棒性较差,只适用于传统精确小数据场景。
标准化
通过对原始数据进行变换,把数据变换到均值为0,标准差为1的范围里。
为均值,
为标准差 。
如果数据量较大,少量的异常值对均值和标准差的影响均很小。
from sklearn.preprocessing import StandardScaler
import pandas as pddef stand_demo():# 读取数据data = pd.read_csv("data.txt")data = data.iloc[:, :2] print("data:\n", data)# 实例化一个转换器类transfer = StandardScaler()# 调用fit_transform()data_new = transfer.fit_transform(data)print("data_new:\n", data_new)return Noneif __name__ == "__main__":stand_demo()
在已有样本足够多的情况下比较稳定,适合现代嘈杂大数据场景。
特征降维
降维是指在某些限定条件下,降低随机变量(特征)个数,得到一组“不相关”主变量(特征与特征之间不相关)的过程。
特征太多会造成数据的冗余,故需降维,而在训练都是用特征进行学习,如果特征之间相关性较强,会对算法的结果影响较大,相关的特征比如相对湿度与降雨量。
特征选择
Filter过滤式
- 方差选择法
- 相关系数
Embeded嵌入式
- 决策树
- 正则化
- 深度学习
方差选择法:低方差特征过滤
- 特征方差小:某个特征大多样本的值比较相近——如鸟是否有爪子这个特征,方差为0,去除
- 特征方差大:某个特征很多样本的值都有差别——保留
from sklearn.feature_selection import VarianceThreshold
import pandas as pddef variance_demo():# 读取数据data = pd.read_csv("data.txt")print("data:\n", data)# 实例化一个转换器类transfer = VarianceThreshold(threshold=1) # 表示方差小于threshold的特征都会被删掉(阈值),默认threshold=0# 调用fit_transform()data_new = transfer.fit_transform(data)print("data_new:\n", data_new)return Noneif __name__ == "__main__":variance_demo()
相关系数
举例:皮尔逊相关系数——适用于连续型数据
其中,,性质如下:

from scipy.stats import pearsonr
import pandas as pddef pearsonr_demo():# 读取数据data = pd.read_csv("data.txt")print("data:\n", data)# 计算两个变量之间的皮尔逊相关系数r = pearsonr(data["height"], data["weight"])print("相关系数:\n", r) # 第一个为相关系数,第二个为相关系数显著性,p值越小表示相关系数越显著return Noneif __name__ == "__main__":pearsonr_demo()
主成分分析(PCA)
- 定义:高维数据转化为低维数据的过程,在此过程中可能会舍弃原有数据,创造新的变量。
- 作用:是数据维度压缩,用损失少量信息(尽可能保留更多的信息)的代价尽可能降低原数据的维度(复杂度)。
from sklearn.decomposition import PCAdef pca_demo():# 读取数据data = [[2, 8, 4, 5], [6, 3, 0, 8], [5, 4, 9, 1]]# 实例化一个转换器类transfer = PCA(n_components=2) # n_components如果传的是整数就代表降为几个特征(降为几维),如果传的是小数就代表要保留百分之几的信息# 调用fit_transform()data_new = transfer.fit_transform(data)print("data_new:\n", data_new)return Noneif __name__ == "__main__":pca_demo()
相关文章:
机器学习——数据处理
机器学习简介 机器学习是人工智能的一个实现途径深度学习是机器学习的一个方法发展而来 机器学习:从数据中自动分析获得模型,并利用模型对未知数据进行预测。 数据集的格式: 特征值目标值 比如上图中房子的各种属性是特征值,然…...
多种文字翻译软件-翻译常用软件
整篇文档翻译软件 整篇文档翻译软件是一种实现全文翻译的自动翻译工具,它能够快速、准确地将整篇文档的内容翻译成目标语言。与单词、句子翻译不同,整篇文档翻译软件不仅需要具备准确的语言识别和翻译技术,还需要考虑上下文语境和文档格式等多…...
)
Baumer工业相机堡盟工业相机如何通过BGAPI SDK将相机图像数据用二进制的方式保存到本地(C++)
Baumer工业相机堡盟工业相机如何通过BGAPI SDK将相机图像数据用二进制的方式保存到本地(C)Baumer工业相机Baumer工业相机将图像保存为二进制图像的技术背景代码分析第一步:先转换Byte*图像为二进制图像第二步:在回调函数里进行Buf…...

JavaScript模块的导出和导入之export和module.exports的区别
export和module.exports (需要前面的export没有“s”,后面的module.exports 有“s”) 使用两者根本区别是 **exports **返回的是模块函数 **module.exports **返回的是模块对象本身,返回的是一个类 使用上的区别是exports的方法可以直接调用module.exports需要new…...
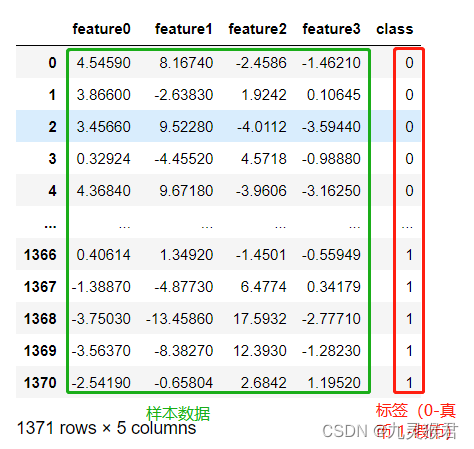
基于朴素贝叶斯分类器的钞票真伪识别模型
基于朴素贝叶斯分类器的钞票真伪识别模型 内容 本实验通过实现钞票真伪判别案例来展开学习朴素贝叶斯分类器的原理及应用。 本实验的主要技能点: 1、 朴素贝叶斯分类器模型的构建 2、 模型的评估与预测 3、 分类概率的输出 源码下载 环境 操作系统…...

【Python】【进阶篇】二十二、Python爬虫的BS4解析库
目录二十二、Python爬虫的BS4解析库22.1 BS4下载安装22.2 BS4解析对象22.3 BS4常用语法1) Tag节点22.4 遍历节点22.5 find_all()与find()1) find_all()2) find()22.6 CSS选择器二十二、Python爬虫的BS4解析库 Beautiful Soup 简称 BS4(其中 4 表示版本号࿰…...

UDS统一诊断服务【五】诊断仪在线0X3E服务
文章目录前言一、诊断仪在线服务介绍二、数据格式2.1,请求报文2.2,子功能2.3,响应报文前言 本文介绍UDS统一诊断服务的0X3E服务,希望能对你有所帮助 一、诊断仪在线服务介绍 诊断仪在线服务比较简单,其功能就是告诉服…...
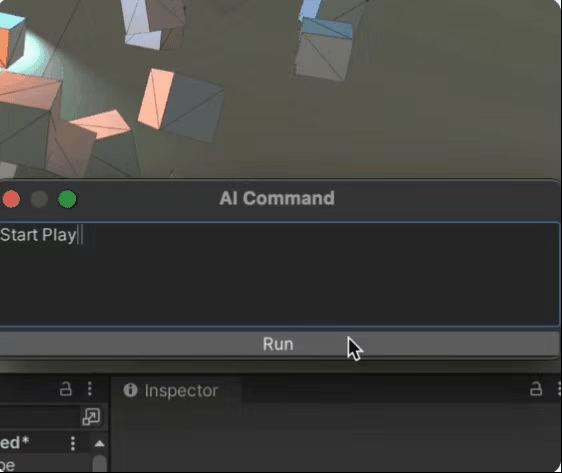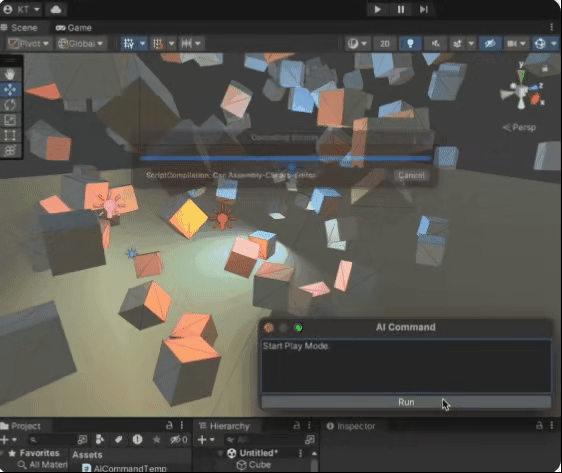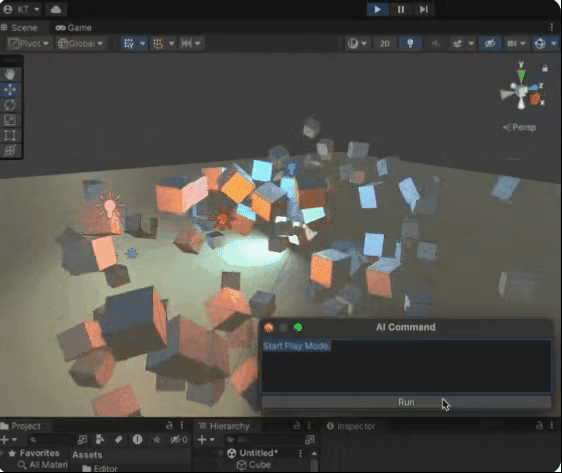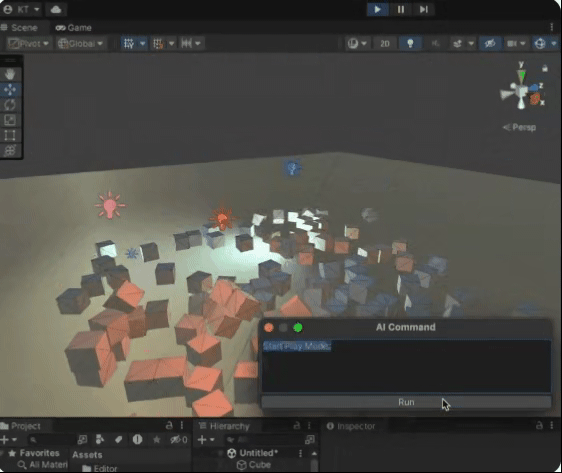
我的创作纪念日:Unity CEO表示生成式AI将是Unity近期发展重点,发布神秘影片预告
PICK 未来的AI技术将会让人类迎来下一个生产力变革,这其中也包括生成型AI的突破性革新。各大公司也正在竞相推出AIGC工具,其中微软的Copilot、Adobe的Firefly、Github的chatGPT等引起了人们的关注。然而,游戏开发领域似乎还没有一款真正针对性…...

秩亏自由网平差的直接解法
目录 一、原理概述二、案例分析三、代码实现四、结果展示一、原理概述 N = B T P B N=B^TPB N=<...

大数据开发必备面试题Spark篇合集
1、Hadoop 和 Spark 的相同点和不同点? Hadoop 底层使用 MapReduce 计算架构,只有 map 和 reduce 两种操作,表达能力比较欠缺,而且在 MR 过程中会重复的读写 hdfs,造成大量的磁盘 io 读写操作,所以适合高时…...

C ++匿名函数:揭开C++ Lambda表达式的神秘面纱
潜意识编程:揭秘C Lambda表达式的神秘面纱 Subconscious Programming: Unveiling the Mystery of C Lambda Expressions 引言:Lambda表达式的魅力 (The Charm of C Lambda Expressions)Lambda表达式简介与基本概念 (Introduction and Basic Concepts of …...
AOP使用场景记录总结(缓慢补充更新中)
测试项目结构: 目前是测试两个日志记录和 代码的性能测试 后面如果有其他的应用场景了在添加.其实一中就包括了二,但是没事,多练一遍 1. 日志记录 比如说对service层中的所有增加,删除,修改方法添加日志, 记录内容包括操作的时间 操作的方法, 方法的参数, 方法所在的类, 方法…...
FPGA基于XDMA实现PCIE X4的HDMI视频采集 提供工程源码和QT上位机程序和技术支持
目录1、前言2、我已有的PCIE方案3、PCIE理论4、总体设计思路和方案5、vivado工程详解6、驱动安装7、QT上位机软件8、上板调试验证9、福利:工程代码的获取1、前言 PCIE(PCI Express)采用了目前业内流行的点对点串行连接,比起 PCI …...

ArcGIS、ENVI、InVEST、FRAGSTATS等多技术融合提升环境、生态、水文、土地、土壤、农业、大气等领域的数据分析
查看原文>>>ArcGIS、ENVI、InVEST、FRAGSTATS等多技术融合提升环境、生态、水文、土地、土壤、农业、大气等领域的数据分析 目录 专题一、空间数据获取与制图 专题二、ArcGIS专题地图制作 专题三、空间数据采集与处理 专题四、遥感数据处理与应用 专题五、DEM数据…...

怎么找回回收站里已经删除的文件
作为忙忙碌碌的打工人,电脑办公是在所难免的,而将使电脑存储着大量的数据文件,不少小伙伴都养成了定期清理电脑的习惯。而清理简单快捷的方法,无疑是直接把文件拖进回收站里。再一键清空,清理工作就完成了。但如果发现…...

Spring Boot、Cloud、Alibaba 版本说明
Spring Boot、Cloud、Alibaba 版本说明 一、毕业版本依赖关系(推荐使用) 由于 Spring Boot 3.0,Spring Boot 2.7~2.4 和 2.4 以下版本之间变化较大,目前企业级客户老项目相关 Spring Boot 版本仍停留在 Spring Boot 2.4 以下,为了同时满足存…...
软件测试入门第一步:编写测试报告
什么是测试报告? 1、说明:是指把测试的过程和结果写成文档,对发现的问题和缺陷进行分析,为纠正软件的存在的质量问题提供依据,同时为软件验收和交付打下基础。 ps. 【测试过程和测试结果的分析报告,以及上线…...
)
【Vue】vue中的路由导航守卫(路由的生命周期)
文章目录全局前置守卫可选的第三个参数 next全局解析守卫router.beforeResolve全局后置钩子路由独享的守卫组件内的守卫可用的配置 API使用组合 API完整的导航解析流程正如其名,vue-router 提供的导航守卫主要用来通过跳转或取消的方式守卫导航。这里有很多方式植入…...

NumPy 基础知识 :6~10
原文:Numpy Essentials 协议:CC BY-NC-SA 4.0 译者:飞龙 六、NumPy 中的傅立叶分析 除其他事项外,傅立叶分析通常用于数字信号处理。 这要归功于它在将输入信号(时域)分离为以离散频率(频域&am…...
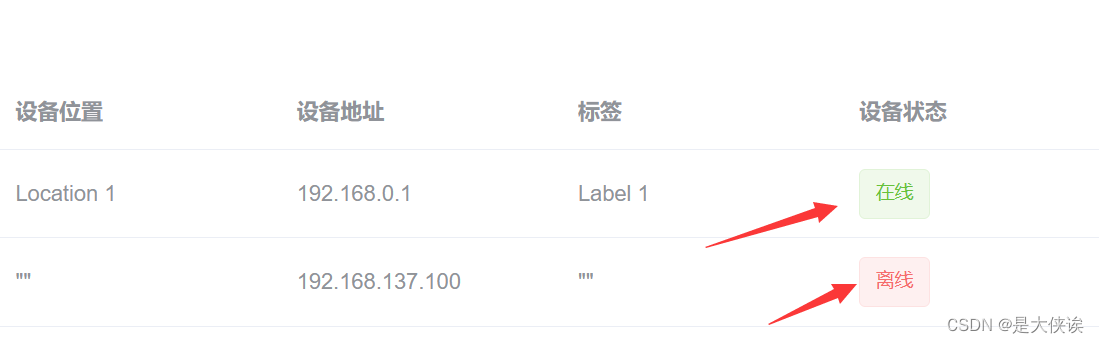
实现vue的条件渲染
我的需求是根据设备不同的状态 渲染不同的标签。设备状态用device_State表示。 在线上面是一个vue的标签,我有一个数据state ,如何让这个标签根据数据的取值 ,修改内容,如state1时,标签修改为离线 要根据数据的取值动态…...

从CLIP到车辆检索:解锁ViT大模型在跨摄像头ReID中的实战潜力
1. 当CLIP遇上车辆检索:ViT大模型的跨界实战 第一次看到CLIP模型在车辆重识别任务上的表现时,我对着屏幕上的mAP 84.5数据反复确认了三遍。这就像给一辆普通家用车换上了F1赛车的引擎,性能提升简单粗暴。传统ReID方法需要精心设计网络结构、调…...

当贝叶斯遇见流数据:在线变点检测在IoT异常监控中的实战指南
贝叶斯在线变点检测:IoT实时异常监控的智能引擎 工厂车间里,数百个温度传感器正以每秒10次的频率向中央系统发送数据流。突然,3号机床的轴承温度读数开始出现微妙波动——这是设备过热的早期信号,但传统阈值报警系统却毫无反应。两…...

新手避坑指南:STM32用Makefile编译时,遇到‘junk at end of line’错误怎么办?
STM32 Makefile编译实战:彻底解决junk at end of line汇编错误 第一次用Makefile编译STM32项目时,看到满屏的junk at end of line错误提示,确实容易让人头皮发麻。这就像你兴冲冲地下载了一个开源项目准备大展身手,结果刚执行make…...

别再只问ChatGPT答案了!试试这个Prompt技巧,让大模型把解题思路‘说’给你听
解锁大模型思维密码:用Prompt技巧让AI展示完整推理路径 当你向ChatGPT抛出一个复杂问题时,是否曾对那个突然出现的最终答案感到困惑?就像看到魔术师从空帽子中变出兔子,却不知道机关在哪里。现代大型语言模型确实能给出惊人准确的…...
)
TVA视觉新范式:工业视觉的百年未有之大变局(2)
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

节日场景下慈善钓鱼与宠物诈骗机理及闭环防御研究
摘要 节日期间公众捐赠意愿上升、宠物领养需求旺盛,为网络钓鱼与社交欺诈提供了高发土壤。波士顿警方发布的节日安全预警显示,假冒慈善机构钓鱼、虚假宠物领养与交易诈骗已成为典型高发案件,两类攻击均依托情感诱导、域名仿冒、社交工程与支付…...

5分钟终极指南:用m4s-converter永久保存你的B站缓存视频
5分钟终极指南:用m4s-converter永久保存你的B站缓存视频 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾经遇到过这样的烦恼…...

保姆级教程:在CentOS 7上用极简包5分钟搞定openGauss数据库安装
5分钟极速部署:CentOS 7下openGauss数据库极简安装实战 当开发进度紧迫时,一个能快速搭建的数据库环境往往能挽救整个项目的时间线。本文将带您用官方极简安装包,在CentOS 7系统上5分钟内完成openGauss数据库的部署。这种方法特别适合需要立即…...

寒战1994电影完整版免费看,网盘在线观看完整版
寒战1994电影完整版免费看,转存到自己网盘后,可以网盘在线观看完整版链接:https://pan.baidu.com/s/1U7-U0Csp2BCc9NYXEHuQZw 提取码:8888操作方法:复制链接,打开百度网盘,便会自动跳转,转存到自己网盘就…...

Perplexity症状查询功能性能对比白皮书:横向测试12家竞品,它在罕见病关键词召回率上领先41.6%,但时间敏感场景响应超时率达23.8%
更多请点击: https://intelliparadigm.com 第一章:Perplexity症状查询功能概览 Perplexity 是一款面向开发者与临床信息学研究人员设计的轻量级症状语义推理工具,其核心能力在于将自然语言描述的症状短语映射至标准化医学本体(如…...