【ARMv8 编程】A64 数据处理指令——位域字节操作指令
有些指令将字节、半字或字扩展到寄存器大小,可以是 X 或 W。这些指令存在于有符号(SXTB、SXTH、SXTW)和无符号(UXTB、UXTH)变体中,并且是适当的位域操作指令。
这些指令的有符号和无符号变体都将字节、半字或字(尽管只有 SXTW 对字进行操作)扩展到寄存器大小。源始终是 W 寄存器。目标寄存器是 X 或 W 寄存器,但 SXTW 除外,它必须是 X 寄存器。
例如:SXTB X0, W1 —— 通过重复字节的最左边的位,将寄存器 W1 的最低有效字节从 8 位符号扩展为 64 位。
位域指令类似于 ARMv7 中存在的指令,包括位域插入 (BFI) 以及有符号和无符号位域提取 ((S/U)BFX)。还有额外的位域指令,例如 BFXIL(低位域提取和插入)、UBFIZ(无符号位域插入零)和 SBFIZ(有符号位域插入零)。
还有 BFM、UBFM 和 SBFM 指令。 这些是 ARMv8 新增的位域移动指令。但是,不需要明确使用这些指令,因为为所有情况提供了别名。这些别名是已经描述的位域操作:[SU]XT[BHWX]、ASR/LSL/LSR immediate、BFI、BFXIL、SBFIZ、SBFX、UBFIZ 和 UBFX。
CLZ —— 计数寄存器中的前导零位。
RBIT —— 反转所有位。
REV —— 反转寄存器的字节顺序。
REV16 —— 反转寄存器中每个半字的字节顺序。
REV32 —— 反转寄存器中每个字的字节顺序。
REV、REV16、可以在字(32 位)或双字(64 位)大小的寄存器上执行,REV32 仅适用于 64 位寄存器。
1. SXTB
SXTB(Signed Extend Byte)指令从寄存器中提取一个 8 位值,将其符号扩展到寄存器的大小,并将结果写入目标寄存器。该指令是 SBFM 指令的别名。

32-bit (sf == 0 && N == 0)
SXTB <Wd>, <Wn>
等价指令
SBFM <Wd>, <Wn>, #0, #7
64-bit (sf == 1 && N == 1)
SXTB <Xd>, <Wn>
等价指令
SBFM <Xd>, <Xn>, #0, #7
<Wd> 是通用目标寄存器的 32 位名称,在“Rd”字段中编码。
<Xd> 是通用目标寄存器的 64 位名称,在“Rd”字段中编码。
<Xn> 是通用源寄存器的 64 位名称,在“Rn”字段中编码。
<Wn> 是通用源寄存器的 32 位名称,在“Rn”字段中编码。
下面是使用 SXTB 指令的例子。
long long int x = 0;int y = 0x7080;asm volatile("SXTB %x[x], %w[y]\n":[x] "+r"(x),[y] "+r"(y):: "cc", "memory");
执行 SXTB %x[x], %w[y] 将 %w[y] 的最低 8 位符号扩展为 64 位,也就是 0x7080 中的 0x80(0b1000 0000)符号位为 1,扩展到 64 位,即 0xFFFF FFFF FFFF FF80,十进制为 -128,这也是最终 x 的值。
2. SXTH
SXTH(Sign Extend Halfword —— 符号扩展半字)指令提取一个 16 位值,将其符号扩展到寄存器的大小,并将结果写入目标寄存器。该指令是 SBFM 指令的别名。

32-bit (sf == 0 && N == 0)
SXTH <Wd>, <Wn>
等价指令
SBFM <Wd>, <Wn>, #0, #15
64-bit (sf == 1 && N == 1)
SXTH <Xd>, <Wn>
等价指令
SBFM <Xd>, <Xn>, #0, #15
<Wd> 是通用目标寄存器的 32 位名称,在“Rd”字段中编码。
<Xd> 是通用目标寄存器的 64 位名称,在“Rd”字段中编码。
<Xn> 是通用源寄存器的 64 位名称,在“Rn”字段中编码。
<Wn> 是通用源寄存器的 32 位名称,在“Rn”字段中编码。
下面是使用 SXTH 指令的例子。
long long int x = 0;int y = 0x7080;asm volatile("SXTH %x[x], %w[y]\n":[x] "+r"(x),[y] "+r"(y):: "cc", "memory");
执行 SXTH %x[x], %w[y] 将 %w[y] 的最低 16 位符号扩展为 64 位,也就是 0x7080 中的 0x7080(0b0111 0000 1000 0000)符号位为 0,扩展到 64 位,还是 0x7080,十进制为 28800,这也是最终 x 的值。
3. SXTW
SXTW(Sign Extend Word —— 符号扩展字)指令将一个字符号扩展到寄存器的大小,并将结果写入目标寄存器。该指令是 SBFM 指令的别名。

64-bit
SXTW <Xd>, <Wn>
等价指令
SBFM <Xd>, <Xn>, #0, #31
<Xd> 是通用目标寄存器的 64 位名称,在“Rd”字段中编码。
<Xn> 是通用源寄存器的 64 位名称,在“Rn”字段中编码。
<Wn> 是通用源寄存器的 32 位名称,在“Rn”字段中编码。
下面是使用 SXTW 指令的例子。
long long int x = 0;int y = 0x7080;asm volatile("SXTW %x[x], %w[y]\n":[x] "+r"(x),[y] "+r"(y):: "cc", "memory");
执行 SXTW %x[x], %w[y] 将 %w[y] 符号扩展为 64 位,也就是 0x7080 中的 0x7080(0b0000 0000 0000 0000 0111 0000 1000 0000)符号位为 0,扩展到 64 位,还是 0x7080,十进制为 28800,这也是最终 x 的值。
4. UXTB
UXTB(Unsigned Extend Byte —— 无符号扩展字节) 从寄存器中提取一个 8 位值,将其零扩展到寄存器的大小,并将结果写入目标寄存器。该指令是 UBFM 指令的别名。

32-bit
UXTB <Wd>, <Wn>
等价指令
UBFM <Wd>, <Wn>, #0, #7
<Wd> 是通用目标寄存器的 32 位名称,在“Rd”字段中编码。
<Wn> 是通用源寄存器的 32 位名称,在“Rn”字段中编码。
下面是使用 UXTB 指令的例子。
int x = 0;int y = 0x7080;asm volatile("UXTB %w[x], %w[y]\n":[x] "+r"(x),[y] "+r"(y):: "cc", "memory");
执行 UXTB %w[x], %w[y] 将 %w[y] 扩展为 32 位,也就是 0x7080 中的 0x80(0b1000 0000)扩展到 32 位(以零填充扩展位),最终还为 0x80,这也是最终 x 的值。
5. UXTH
UXTH(Unsigned Extend Halfword —— 无符号扩展半字) 从寄存器中提取一个 16 位值,将其零扩展到寄存器的大小,并将结果写入目标寄存器。该指令是 UBFM 指令的别名。

32-bit
UXTH <Wd>, <Wn>
等价指令
UBFM <Wd>, <Wn>, #0, #15
<Wd> 是通用目标寄存器的 32 位名称,在“Rd”字段中编码。
<Wn> 是通用源寄存器的 32 位名称,在“Rn”字段中编码。
下面是使用 UXTH 指令的例子。
int x = 0;int y = 0x77777080;asm volatile("UXTH %w[x], %w[y]\n":[x] "+r"(x),[y] "+r"(y):: "cc", "memory");
执行 UXTH %w[x], %w[y] 将 %w[y] 扩展为 32 位,也就是 0x77777080 的低 16 位,即 0x7080(0b0111 0000 1000 0000)扩展到 32 位(以零填充扩展位),最终还为 0x7080,这也是最终 x 的值。
6. BFI
BFI(Bitfield Insert —— 位域插入)指令将 <width> 位的位域从源寄存器的最低有效位复制到目标寄存器的位位置 <lsb>,而其他目标位保持不变。该指令是 BFM 指令的别名。

32-bit (sf == 0 && N == 0)
BFI <Wd>, <Wn>, #<lsb>, #<width>
等价指令
BFM <Wd>, <Wn>, #(-<lsb> MOD 32), #(<width>-1)
64-bit (sf == 1 && N == 1)
BFI <Xd>, <Xn>, #<lsb>, #<width>
等价指令
BFM <Xd>, <Xn>, #(-<lsb> MOD 64), #(<width>-1)
<Wd> 是通用目标寄存器的 32 位名称,在“Rd”字段中编码。
<Wn> 是通用源寄存器的 32 位名称,在“Rn”字段中编码。
<Xd> 是通用目标寄存器的 64 位名称,在“Rd”字段中编码。
<Xn> 是通用源寄存器的 64 位名称,在“Rn”字段中编码。
<lsb> 对于 32 位变体:是目标位域的 lsb 的位数,范围为 0 到 31。对于 64 位变体:是目标位域的 lsb 的位数,范围为 0 到 63。
<width> 对于 32 位变体:是位域的宽度,范围为 1 到 32-<lsb>。对于 64 位变体:是位域的宽度,范围为 1 到 64-<lsb>。
下图是 BFI W0, W0, #9, #6 指令操作示意图:

下面是使用 BFI 指令的例子。
long long int x = -1;long long int y = 0x77777080;asm volatile("BFI %x[x], %x[y], #16, #16\n":[x] "+r"(x),[y] "+r"(y):: "cc", "memory");
执行 BFI %x[x], %x[y], #16, #16 将 %x[y] 最低 16 位复制到 %x[x] 的 16 ~ 31 位,也就是 0x77777080 的低 16 位,即 0x7080(0b0111 0000 1000 0000)复制到 %x[x] 的 16 ~ 31 位,最终的结果就是 0xFFFF FFFF 7080 FFFF,这也是最终 x 的值。
7. BFC
BFC(Bitfield Clear —— 位域清零) 将目标寄存器的位位置 <lsb> 处的 <width> 位的位域设置为零,而其他目标位保持不变。该指令是 BFM 指令的别名。

32-bit (sf == 0 && N == 0)
BFC <Wd>, #<lsb>, #<width>
等价指令
BFM <Wd>, WZR, #(-<lsb> MOD 32), #(<width>-1)
64-bit (sf == 1 && N == 1)
BFC <Xd>, #<lsb>, #<width>
等价指令
BFM <Xd>, XZR, #(-<lsb> MOD 64), #(<width>-1)
<Wd> 是通用目标寄存器的 32 位名称,在“Rd”字段中编码。
<Xd> 是通用目标寄存器的 64 位名称,在“Rd”字段中编码。
<lsb> 对于 32 位变体:是目标位域的 lsb 的位数,范围为 0 到 31。对于 64 位变体:是目标位域的 lsb 的位数,范围为 0 到 63。
<width> 对于 32 位变体:是位域的宽度,范围为 1 到 32-<lsb>。对于 64 位变体:是位域的宽度,范围为 1 到 64-<lsb>。
下图是 BFC W1, #3, #4 指令操作示意图:

下面是使用 BFC 指令的例子。
long long int x = -1;asm volatile("BFC %x[x], #8, #8\n":[x] "+r"(x):: "cc", "memory");
执行 BFC %x[x], #8, #8 将 %x[x] 寄存器的 8 ~ 15 位(宽度为 8)清零,即 0xFFFF FFFF FFFF 00FF,这也是最终 x 的值。
8. SBFX
SBFX(Signed Bitfield Extract —— 有符号位域提取) 指令复制一个 <width> 位的位域,从源寄存器中的位位置 <lsb> 开始到目标寄存器的最低有效位,并将位域前面的目标位设置为位域最高有效位的副本。该指令是 SBFM 指令的别名。

32-bit (sf == 0 && N == 0)
SBFX <Wd>, <Wn>, #<lsb>, #<width>
等价指令
SBFM <Wd>, <Wn>, #<lsb>, #(<lsb>+<width>-1)
64-bit (sf == 1 && N == 1)
SBFX <Xd>, <Xn>, #<lsb>, #<width>
等价指令
SBFM <Xd>, <Xn>, #<lsb>, #(<lsb>+<width>-1)
<Wd> 是通用目标寄存器的 32 位名称,在“Rd”字段中编码。
<Wn> 是通用源寄存器的 32 位名称,在“Rn”字段中编码。
<Xd> 是通用目标寄存器的 64 位名称,在“Rd”字段中编码。
<Xn> 是通用源寄存器的 64 位名称,在“Rn”字段中编码。
<lsb> 对于 32 位变体:是源位域的 lsb 的位数,范围为 0 到 31。对于 64 位变体:是源位域的 lsb 的位数,范围为 0 到 63。
<width> 对于 32 位变体:是位域的宽度,范围为 1 到 32-<lsb>。对于 64 位变体:是位域的宽度,范围为 1 到 64-<lsb>。
下面是使用 SBFX 指令的例子。
long long int x = 0;long long int y = 0x87;asm volatile("SBFX %x[x], %x[y], #4, #4\n":[x] "+r"(x),[y] "+r"(y):: "cc", "memory");
执行 SBFX %x[x], %x[y], #4, #4,首先将 %x[y] 寄存器内的 0x87 的 4 ~ 7 位复制到 %x[x] 寄存器的 0 ~ 3 位,又因为 0x87 的第七位为 1,所以使用 1 扩展 %x[x] 的 4 ~ 63 位(这里体现了符号位),即 0xFFFF FFFF FFFF FF80,这也是最终 x 的值。
9. UBFX
UBFX(Unsigned Bitfield Extract —— 无符号位域提取)指令复制一个 <width> 位的位域,从源寄存器中的位位置 <lsb> 开始到目标寄存器的最低有效位,并将位域前面的目标位设置为零。该指令是 UBFM 指令的别名。

32-bit (sf == 0 && N == 0)
UBFX <Wd>, <Wn>, #<lsb>, #<width>
等价指令
UBFM <Wd>, <Wn>, #<lsb>, #(<lsb>+<width>-1)
64-bit (sf == 1 && N == 1)
UBFX <Xd>, <Xn>, #<lsb>, #<width>
等价指令
UBFM <Xd>, <Xn>, #<lsb>, #(<lsb>+<width>-1)
<Wd> 是通用目标寄存器的 32 位名称,在“Rd”字段中编码。
<Wn> 是通用源寄存器的 32 位名称,在“Rn”字段中编码。
<Xd> 是通用目标寄存器的 64 位名称,在“Rd”字段中编码。
<Xn> 是通用源寄存器的 64 位名称,在“Rn”字段中编码。
<lsb> 对于 32 位变体:是源位域的 lsb 的位数,范围为 0 到 31。对于 64 位变体:是源位域的 lsb 的位数,范围为 0 到 63。
<width> 对于 32 位变体:是位域的宽度,范围为 1 到 32-<lsb>。对于 64 位变体:是位域的宽度,范围为 1 到 64-<lsb>。
下图是 UBFX W1, W0, #18, #7 指令操作示意图:

下面是使用 UBFX 指令的例子。
long long int x = 0;long long int y = 0x87;asm volatile("UBFX %x[x], %x[y], #4, #4\n":[x] "+r"(x),[y] "+r"(y):: "cc", "memory");
执行 UBFX %x[x], %x[y], #4, #4,首先将 %x[y] 寄存器内的 0x87 的 4 ~ 7 位复制到 %x[x] 寄存器的 0 ~ 3 位,接着使用 0 扩展 %x[x] 的 4 ~ 63 位,即 0x8,这也是最终 x 的值。
10. BFXIL
位域提取并在低端插入,其他位不变。该指令是 BFM 指令的别名。

32-bit (sf == 0 && N == 0)
BFXIL <Wd>, <Wn>, #<lsb>, #<width>
等价指令
BFM <Wd>, <Wn>, #<lsb>, #(<lsb>+<width>-1)
64-bit (sf == 1 && N == 1)
BFXIL <Xd>, <Xn>, #<lsb>, #<width>
等价指令
BFM <Xd>, <Xn>, #<lsb>, #(<lsb>+<width>-1)
<Wd> 是通用目标寄存器的 32 位名称,在“Rd”字段中编码。
<Wn> 是通用源寄存器的 32 位名称,在“Rn”字段中编码。
<Xd> 是通用目标寄存器的 64 位名称,在“Rd”字段中编码。
<Xn> 是通用源寄存器的 64 位名称,在“Rn”字段中编码。
<lsb> 是源位域的“lsb”的位数。对于 32 位变体:范围为 0 到 31;对于 64 位变体:范围为 0 到 63。
<width> 是位域的宽度。对于 32 位变体:范围为 1 到 32-<lsb>;对于 64 位变体:范围为 1 到 64-<lsb>。
下面是使用 BFXIL 指令的例子。
long long int x = 0x4444;long long int y = 0x87;asm volatile("BFXIL %x[x], %x[y], #4, #4\n":[x] "+r"(x),[y] "+r"(y):: "cc", "memory");
执行 BFXIL %x[x], %x[y], #4, #4,首先将 %x[y] 寄存器内的 0x87 的 4 ~ 7 位复制到 %x[x] 寄存器的 0 ~ 3 位,其它位保持不变,所以最终 %x[x] 的值为 0x4448。
11. UBFIZ
无符号位域插入零,左右为零。该指令是 UBFM 指令的别名。

32-bit (sf == 0 && N == 0)
UBFIZ <Wd>, <Wn>, #<lsb>, #<width>
等价指令
UBFM <Wd>, <Wn>, #(-<lsb> MOD 32), #(<width>-1)
64-bit (sf == 1 && N == 1)
UBFIZ <Xd>, <Xn>, #<lsb>, #<width>
等价指令
UBFM <Xd>, <Xn>, #(-<lsb> MOD 64), #(<width>-1)
<Wd> 是通用目标寄存器的 32 位名称,在“Rd”字段中编码。
<Wn> 是通用源寄存器的 32 位名称,在“Rn”字段中编码。
<Xd> 是通用目标寄存器的 64 位名称,在“Rd”字段中编码。
<Xn> 是通用源寄存器的 64 位名称,在“Rn”字段中编码。
<lsb> 是源位域的“lsb”的位数。对于 32 位变体:范围为 0 到 31;对于 64 位变体:范围为 0 到 63。
<width> 是位域的宽度。对于 32 位变体:范围为 1 到 32-<lsb>;对于 64 位变体:范围为 1 到 64-<lsb>。
下面是使用 UBFIZ 指令的例子。
long long int x = 0x444444;long long int y = 0x89;asm volatile("UBFIZ %x[x], %x[y], #8, #8\n":[x] "+r"(x),[y] "+r"(y):: "cc", "memory");
执行 UBFIZ %x[x], %x[y], #8, #8,首先将 %x[y] 寄存器内的 0x89 低 8 位复制到 %x[x] 寄存器的 8 ~ 15 位,其它位全部清零,所以最终 %x[x] 的值为 0x8900。
12. SBFIZ
带符号的位域插入零,符号复制到左边,零复制到右边。该指令是 SBFM 指令的别名。

32-bit (sf == 0 && N == 0)
SBFIZ <Wd>, <Wn>, #<lsb>, #<width>
等价指令
SBFM <Wd>, <Wn>, #(-<lsb> MOD 32), #(<width>-1)
64-bit (sf == 1 && N == 1)
SBFIZ <Xd>, <Xn>, #<lsb>, #<width>
等价指令
SBFM <Xd>, <Xn>, #(-<lsb> MOD 64), #(<width>-1)
<Wd> 是通用目标寄存器的 32 位名称,在“Rd”字段中编码。
<Wn> 是通用源寄存器的 32 位名称,在“Rn”字段中编码。
<Xd> 是通用目标寄存器的 64 位名称,在“Rd”字段中编码。
<Xn> 是通用源寄存器的 64 位名称,在“Rn”字段中编码。
<lsb> 是源位域的“lsb”的位数。对于 32 位变体:范围为 0 到 31;对于 64 位变体:范围为 0 到 63。
<width> 是位域的宽度。对于 32 位变体:范围为 1 到 32-<lsb>;对于 64 位变体:范围为 1 到 64-<lsb>。
下面是使用 SBFIZ 指令的例子。
long long int x = 0x444444;long long int y = 0x89;asm volatile("SBFIZ %x[x], %x[y], #8, #8\n":[x] "+r"(x),[y] "+r"(y):: "cc", "memory");
执行 SBFIZ %x[x], %x[y], #8, #8,首先将 %x[y] 寄存器内的 0x89 低 8 位复制到 %x[x] 寄存器的 8 ~ 15 位,接着由于 0x89 符号位为 1,所以 16 ~ 63 位全部复制为 1, 0 ~ 7 位则清零,所以最终 %x[x] 的值为 0xFFFF FFFF FFFF 8900。
13. BFM
BFM(Bitfield move —— 位域移动)位域移动,其他位不变。该指令由别名 BFC、BFI 和 BFXIL 使用。
-
如果
<imms>大于或等于<immr>,则将从源寄存器中的位位置<immr>开始的(<imms>-<immr>+ 1)位的位域复制到目标寄存器的最低有效位。 -
如果
<imms>小于<immr>,则将源寄存器的最低有效位中的(<imms>+ 1)位的位域复制到目标寄存器的位位置(regsize -<immr>),其中 regsize 是 32 或 64 位的目标寄存器大小。
在这两种情况下,目的寄存器的其他位保持不变。

32-bit (sf == 0 && N == 0)
BFM <Wd>, <Wn>, #<immr>, #<imms>
64-bit (sf == 1 && N == 1)
BFM <Xd>, <Xn>, #<immr>, #<imms>
<Wd> 是通用目标寄存器的 32 位名称,在“Rd”字段中编码。
<Wn> 是通用源寄存器的 32 位名称,在“Rn”字段中编码。
<Xd> 是通用目标寄存器的 64 位名称,在“Rd”字段中编码。
<Xn> 是通用源寄存器的 64 位名称,在“Rn”字段中编码。
<immr> 是循环右移量,在“immr”字段中编码。对于 32 位变体:在 0 到 31 的范围内;对于 64 位变体:是在 0 到 63 范围内。
<imms> 是要从源移动的最左边的位数(the leftmost bit number to be moved from the source),编码在“imms”字段中。对于 32 位变体:在 0 到 31 的范围内;对于 64 位变体:范围从 0 到 63。
下面是使用 BFM 指令的例子。
long long int x = 0x444444;long long int y = 0x79;asm volatile("BFM %x[x], %x[y], #8, #4\n":[x] "+r"(x),[y] "+r"(y):: "cc", "memory");
执行 BFM %x[x], %x[y], #8, #4,将 0x79(0b01111001) 中的 0 ~ 4 位(4 + 1 = 5 共 5 位)(0b11001)移动到目标寄存器 %x[x],也就是将 0x19 移动到 %x[x] 的最左边(从 64 - 8 = 56 位开始复制),其它位保持不变,最终为 0x1900 0000 0044 4444。
14. UBFM
UBFM(Unsigned Bitfield Move —— 无符号位域移动)指令通常通过其别名之一进行访问,该别名始终是反汇编的首选。
-
如果
<imms>大于或等于<immr>,则将从源寄存器中的位位置<immr>开始的(<imms>-<immr>+ 1)位的位域复制到目标寄存器的最低有效位。 -
如果
<imms>小于<immr>,则将源寄存器的最低有效位中的(<imms>+ 1)位的位域复制到目标寄存器的位位置(regsize -<immr>),其中 regsize 是 32 或 64 位的目标寄存器大小。
在这两种情况下,位域前面和后面的目标位都设置为零。
该指令由别名 LSL(立即数)、LSR(立即数)、UBFIZ、UBFX、UXTB 和 UXTH 使用。

32-bit (sf == 0 && N == 0)
UBFM <Wd>, <Wn>, #<immr>, #<imms>
64-bit (sf == 1 && N == 1)
UBFM <Xd>, <Xn>, #<immr>, #<imms>
<Wd> 是通用目标寄存器的 32 位名称,在“Rd”字段中编码。
<Wn> 是通用源寄存器的 32 位名称,在“Rn”字段中编码。
<Xd> 是通用目标寄存器的 64 位名称,在“Rd”字段中编码。
<Xn> 是通用源寄存器的 64 位名称,在“Rn”字段中编码。
<immr> 是循环右移量,在“immr”字段中编码。对于 32 位变体:在 0 到 31 的范围内;对于 64 位变体:是在 0 到 63 范围内。
<imms> 是要从源移动的最左边的位数(the leftmost bit number to be moved from the source),编码在“imms”字段中。对于 32 位变体:在 0 到 31 的范围内;对于 64 位变体:范围从 0 到 63。
下面是使用 UBFM 指令的例子。
long long int x = 0x444444;long long int y = 0x79;asm volatile("UBFM %x[x], %x[y], #8, #4\n":[x] "+r"(x),[y] "+r"(y):: "cc", "memory");
执行 UBFM %x[x], %x[y], #8, #4,将 0x79(0b01111001) 中的 0 ~ 4 位(4 + 1 = 5 共 5 位)(0b11001)移动到目标寄存器 %x[x],也就是将 0x19 移动到 %x[x] 的最左边(从 64 - 8 = 56 位开始复制),其它位清零,最终为 0x1900 0000 0000 0000。
15. SBFM
SBFM(Signed Bitfield Move —— 有符号位域移动)指令通常通过其别名之一访问,该别名始终是反汇编的首选。
-
如果
<imms>大于或等于<immr>,则将从源寄存器中的位位置<immr>开始的(<imms>-<immr>+ 1)位的位域复制到目标寄存器的最低有效位。 -
如果
<imms>小于<immr>,则将源寄存器的最低有效位中的(<imms>+ 1)位的位域复制到目标寄存器的位位置(regsize -<immr>),其中 regsize 是 32 或 64 位的目标寄存器大小。
在这两种情况下,位域后面的目的位被设置为零,位域前面的位被设置到位域的最高有效位的拷贝。
该指令由别名 ASR(立即数)、SBFIZ、SBFX、SXTB、SXTH 和 SXTW 使用。

32-bit (sf == 0 && N == 0)
SBFM <Wd>, <Wn>, #<immr>, #<imms>
64-bit (sf == 1 && N == 1)
SBFM <Xd>, <Xn>, #<immr>, #<imms>
<Wd> 是通用目标寄存器的 32 位名称,在“Rd”字段中编码。
<Wn> 是通用源寄存器的 32 位名称,在“Rn”字段中编码。
<Xd> 是通用目标寄存器的 64 位名称,在“Rd”字段中编码。
<Xn> 是通用源寄存器的 64 位名称,在“Rn”字段中编码。
<immr> 是循环右移量,在“immr”字段中编码。对于 32 位变体:在 0 到 31 的范围内;对于 64 位变体:是在 0 到 63 范围内。
<imms> 是要从源移动的最左边的位数(the leftmost bit number to be moved from the source),编码在“imms”字段中。对于 32 位变体:在 0 到 31 的范围内;对于 64 位变体:范围从 0 到 63。
下面是使用 SBFM 指令的例子。
long long int x = 0x444444;long long int y = 0x79;asm volatile("SBFM %x[x], %x[y], #8, #4\n":[x] "+r"(x),[y] "+r"(y):: "cc", "memory");
执行 SBFM %x[x], %x[y], #8, #4,将 0x79(0b01111001) 中的 0 ~ 4 位(4 + 1 = 5 共 5 位)(0b11001)移动到目标寄存器 %x[x],也就是将 0x19 移动到 %x[x] 的最左边(从 64 - 8 = 56 位开始复制),它的后面的位清零,前面的位由于符号位为 1,因此全部复制为 1,最终为 0xF900 0000 0000 0000。
16. CLZ
计算前导零位数:Rd = CLZ(Rn)。

32-bit (sf = 0)
CLZ <Wd>, <Wn>
64-bit (sf = 1)
CLZ <Xd>, <Xn>
<Wd> 是通用目标寄存器的 32 位名称,在“Rd”字段中编码。
<Wn> 是通用源寄存器的 32 位名称,在“Rn”字段中编码。
<Xd> 是通用目标寄存器的 64 位名称,在“Rd”字段中编码。
<Xn> 是通用源寄存器的 64 位名称,在“Rn”字段中编码。
下面是使用 CLZ 指令的例子。
long long int x = 0;long long int y = 0x79;asm volatile("CLZ %x[x], %x[y]\n":[x] "+r"(x),[y] "+r"(y):: "cc", "memory");
执行 CLZ %x[x], %x[y],计算 %x[y] 前导零的位数,即 0x79(0b01111001)中前导零的位数,也就是 64 - 7 = 57,最终将 57 写入 %x[x]。
17. RBIT
RBIT 指令反转所有位(反转位序)。

32-bit (sf = 0)
RBIT <Wd>, <Wn>
64-bit (sf = 1)
RBIT <Xd>, <Xn>
<Wd> 是通用目标寄存器的 32 位名称,在“Rd”字段中编码。
<Wn> 是通用源寄存器的 32 位名称,在“Rn”字段中编码。
<Xd> 是通用目标寄存器的 64 位名称,在“Rd”字段中编码。
<Xn> 是通用源寄存器的 64 位名称,在“Rn”字段中编码。
下面是使用 RBIT 指令的例子。
long long int x = 0;long long int y = 0x79;asm volatile("RBIT %x[x], %x[y]\n":[x] "+r"(x),[y] "+r"(y):: "cc", "memory");
执行 RBIT %x[x], %x[y],反转 %x[y] 中的所有位(反转位序),即 0x79(0b01111001)反转为 0x9E00 0000 0000 0000,最终将 0x9E00 0000 0000 0000 写入 %x[x]。
18. REV
REV 指令反转所有字节。

32-bit (sf = 0)
REV <Wd>, <Wn>
64-bit (sf = 1)
REV <Xd>, <Xn>
<Wd> 是通用目标寄存器的 32 位名称,在“Rd”字段中编码。
<Wn> 是通用源寄存器的 32 位名称,在“Rn”字段中编码。
<Xd> 是通用目标寄存器的 64 位名称,在“Rd”字段中编码。
<Xn> 是通用源寄存器的 64 位名称,在“Rn”字段中编码。
下面是使用 REV 指令的例子。
long long int x = 0;long long int y = 0x12436579;asm volatile("REV %x[x], %x[y]\n":[x] "+r"(x),[y] "+r"(y):: "cc", "memory");
执行 REV %x[x], %x[y],反转 %x[y] 中的所有字节,即 0x12436579 反转为 0x7965 4312 0000 0000,最终将 0x7965 4312 0000 0000 写入 %x[x]。
19. REV16
REV16 指令反转 16 位半字中的字节。

32-bit (sf = 0)
REV16 <Wd>, <Wn>
64-bit (sf = 1)
REV16 <Xd>, <Xn>
<Wd> 是通用目标寄存器的 32 位名称,在“Rd”字段中编码。
<Wn> 是通用源寄存器的 32 位名称,在“Rn”字段中编码。
<Xd> 是通用目标寄存器的 64 位名称,在“Rd”字段中编码。
<Xn> 是通用源寄存器的 64 位名称,在“Rn”字段中编码。

下面是使用 REV16 指令的例子。
long long int x = 0;long long int y = 0x12436579;asm volatile("REV16 %x[x], %x[y]\n":[x] "+r"(x),[y] "+r"(y):: "cc", "memory");
执行 REV16 %x[x], %x[y],反转 %x[y] 中 16 位半字中的字节,即 0x12436579 反转为 0x43127965,最终将 0x43127965 写入 %x[x]。
20. REV32
REV32 指令反转 32 位字中的字节。

64-bit
REV32 <Xd>, <Xn>
<Xd> 是通用目标寄存器的 64 位名称,在“Rd”字段中编码。
<Xn> 是通用源寄存器的 64 位名称,在“Rn”字段中编码。

下面是使用 REV32 指令的例子。
long long int x = 0;long long int y = 0x12436579;asm volatile("REV32 %x[x], %x[y]\n":[x] "+r"(x),[y] "+r"(y):: "cc", "memory");
执行 REV32 %x[x], %x[y],反转 %x[y] 中 32 位字中的字节,即 0x12436579 反转为 0x79654312,最终将 0x79654312 写入 %x[x]。
参考资料
1.《ARMv8-A-Programmer-Guide》
2.《Arm® A64 Instruction Set Architecture Armv8, for Armv8-A architecture profile》
相关文章:
【ARMv8 编程】A64 数据处理指令——位域字节操作指令
有些指令将字节、半字或字扩展到寄存器大小,可以是 X 或 W。这些指令存在于有符号(SXTB、SXTH、SXTW)和无符号(UXTB、UXTH)变体中,并且是适当的位域操作指令。 这些指令的有符号和无符号变体都将字节、半字…...

ctfshow 愚人杯菜狗杯部分题目(flasksession伪造ssti)
目录 <1>愚人杯 (1) easy_signin (2) easy_ssti(无过滤ssti) (3) easy_flask(flash-session伪造) (4) easy_php(C:开头序列化数据) <2> 菜狗杯 (1) 抽老婆(flask_session伪造) (2) 一言既出,驷马难追(intval) (3) 传说之下(js控制台&…...

linux拓展笔记——【补充学习知识点】
文章目录1. ./configure --prefix中的prefix详解1. ./configure --prefix中的prefix详解 源码的安装一般由3个步骤组成:配置(configure)、编译(make)、安装(makeinstall)。 Configure是一个可执行脚本,在待安装的源码路径下使用命令./configure–help输…...

为何银行各岗位之间的薪酬差别如此之大?
银行里的职位种类相对较多,观观整理了5个最常见的职位,看一下你要申请的职位薪资水平到底是怎样的?根据如信银行考试中心发布: 1、客户经理岗 客户经理分为对公客户经理和对私客户经理,他们的主要工作不同࿰…...
TensorFlow 深度学习第二版:1~5
原文:Deep Learning with TensorFlow Second Edition 协议:CC BY-NC-SA 4.0 译者:飞龙 本文来自【ApacheCN 深度学习 译文集】,采用译后编辑(MTPE)流程来尽可能提升效率。 不要担心自己的形象,只…...
微前端micro-app的使用
演示效果 子应用的项目 基应用嵌入子应用效果图 目录 前言 一、微前端是什么? 它主要解决了两个问题: 二、使用步骤 1.安装依赖 2.在入口处引入 3.子应用的路由() 4.分配一个路由给子应用(重要)࿰…...

【JUC】Java内存模型之JMM
【JUC】Java内存模型之JMM 文章目录【JUC】Java内存模型之JMM1. 概念2. JMM三大特性2.1 可见性2.2 原子性2.3 有序性3. 多线程对变量的读写过程4. 先行发生原则——happens-before4.1 happens-before八条规则4.1.1 次序规则4.1.2 锁定规则4.1.3 volatile变量规则4.1.4 传递规则…...
Win11快速打开便签和使用技巧分享
Win11快速打开便签和使用技巧分享。Win11系统中为用户提供了一个非常实用的系统组件,就是便签功能,使用这个功能可以帮助我们便捷的进行一些重要内容的记录。那么如何去开启开启这个程序来使用呢?来看看以下的详情分享吧。 详细分享ÿ…...

CSS:横向导航栏
横向导航栏(盗版导航栏,B站仿写。) 原视频链接 <html><head><title>demo</title><style>*{margin: 0;padding: 0;list-style: none;text-decoration: none;}body{display: flex;justify-content: center;a…...

视频动态库测试及心得
视频动态库测试及心得 这几天一直在弄动态库测试,h给的写好的动态库--预处理模块的库。视频处理项目一部分,需要连接实际情况测试。 需求: 1.把实际相机连接到,并读取实时数据流,保存到双循环链表里面; 2.测试背景建模…...
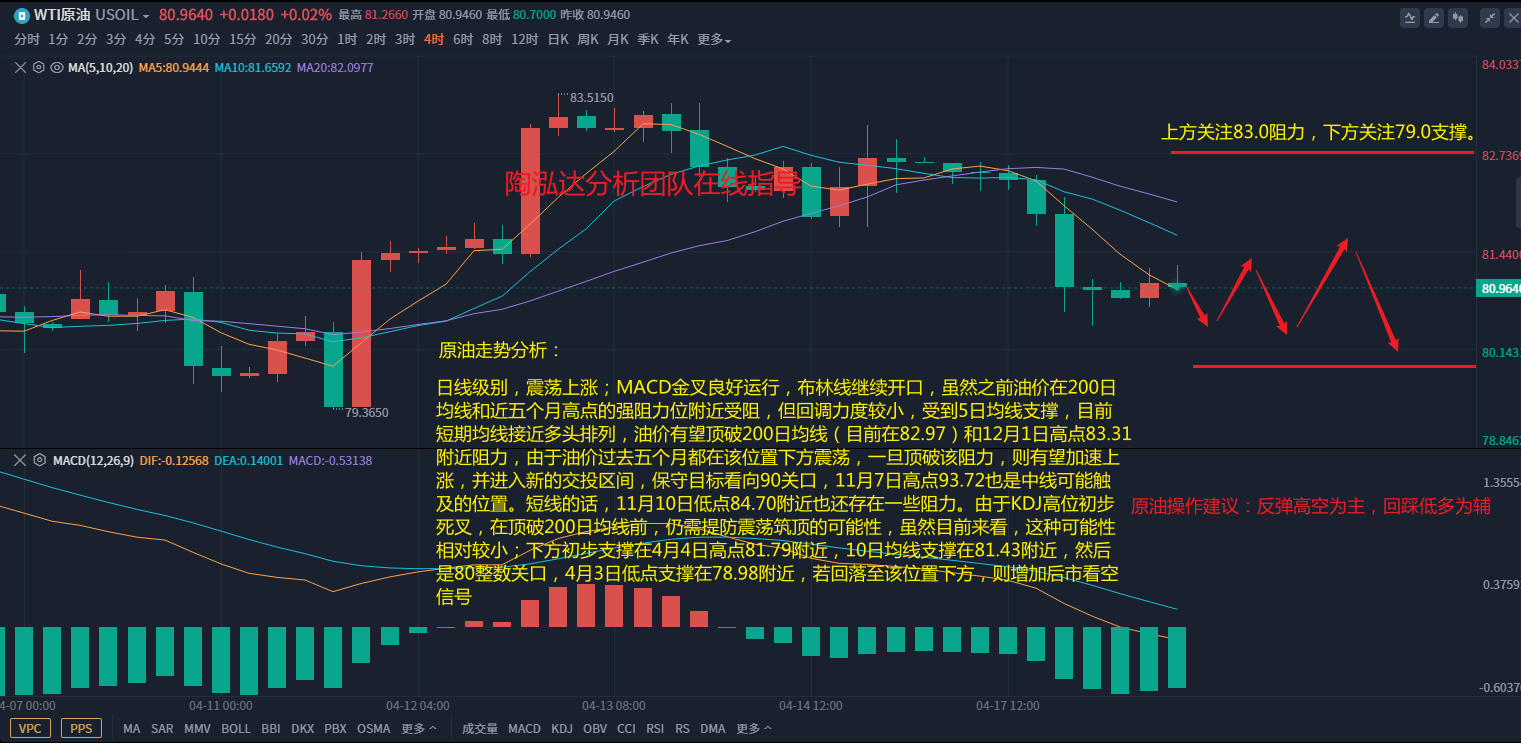
陶泓达:4.18午间欧盘黄金原油最新精准操作建议!
黄金方面: 黄金消息面解析:周一(4月17日)美市盘中,美国公布的4月纽约联储制造业指数和4月NAHB房产市场指数均超出预期,提振了美联储在5月继续加息的预期。数据公布之后,美元指数加速上扬&#x…...

环境变量相关知识
目录 目录 谢谢你的阅读,这是对我最大的鼓舞 先说结论: 开始论述: 让我们举个例子 相关指令 创建本地变量 创建环境变量 方法一: 方法二: 删除环境变量 子进程中也有环境变量 第一种: 第二种 …...

如何快速入门ChatGPT
作为一个AI模型,ChatGPT并不需要像人一样“学习”,它已经通过大量的训练数据和算法进行了预训练,可以回答广泛的问题。 然而,如果你想学习如何使用ChatGPT来进行对话或者问答,以下是一些建议: 一、了解Ch…...
方法)
Akka定时任务schedule()方法
Akka定时任务schedule()方法 文章目录Akka定时任务schedule()方法什么是Akka定时任务schedule()方法?如何使用Akka定时任务schedule()方法?如何在actor外部获取Scheduler对象为什么需要提供一个隐式的ExecutionContext对象,用于执行定时任务&…...

Python实现处理和分析大规模文本数据集,包括数据清洗、标注和预处理
处理和分析大规模文本数据集,包括数据清洗、标注和预处理,是自然语言处理(NLP)中非常重要的一步。Python 是一种非常流行的编程语言,拥有丰富的 NLP 库和工具,可以帮助我们完成这些任务。以下是一个简单的实现示例,包括数据清洗、标注和预处理: import re import nltk…...

灌区量测水系统
1)灌区量测水 灌区量测水是水资源管理的基础,是推进节水农业和水价改革的重要手段。常规在主要水闸处,监测闸前和闸后水位及闸门开启状态(闸位),通过实时监测数据,计算过闸流量。要实现全灌区水资源动态配置、精准灌溉࿰…...

3.3 泰勒公式
学习目标: 复习微积分基础知识。泰勒公式是微积分的一个重要应用,因此在学习泰勒公式之前,需要复习微积分的基本概念和技能,包括函数的导数和微分、极限、定积分等。可以参考MIT的微积分课程进行复习和加强。 学习泰勒级数和泰勒…...

ubuntu中通过vscode编译调试ORB-SLAM3
为了在orb-slam3的基础上进行二次开发,这几天花了不少精力,终于搞懂怎么在ubuntu系统中像windows里visual studio中一样方便的打断点调试了,在这里把整个过程再重新梳理一下。 1 首先从安装ubuntu 22.04开始 因为是从实验室毕业先辈那里继承…...
阿里版 ChatGPT 突然上线!
转自:纯洁的微笑 其实早本月初,就传出过不少阿里要推出类ChatGPT的消息。 前几天率先流出的天猫精灵“鸟鸟分鸟”脱口秀版GPT,就是基于大模型的“压缩版”,已经以其惊艳表现吸引了众目光。 如今“原版大菜”上桌,自然一点即着&a…...

《Kubernetes部署篇:Ubuntu20.04基于containerd部署kubernetes1.24.12单master集群》
一、架构图 如下图所示: 二、环境信息 主机名K8S版本系统版本内核版本IP地址备注k8s-master-621.24.12Ubuntu 20.04.5 LTS5.15.0-69-generic192.168.1.62master节点k8s-worker-631.24.12Ubuntu 20.04.5 LTS5.15.0-69-generic192.168.1.63worker节点k8s-worker-641…...

VIGOR:跨越“一对一”检索的理想假设,面向真实场景的跨视角地理定位数据集
一、数据集背景与开创性意义 VIGOR (Cross-View Image Geo-localization beyond One-to-one Retrieval) 是一个面向真实世界应用的全新大规模跨视角图像地理定位基准数据集,由 Sijie Zhu, Taojiannan Yang 和 Chen Chen 提出,相关论文发表于 CVPR 2021。…...

FRED应用:背散射教程
这个教程描述一个有散射性质的简单plano-plano透镜,这样一条入射光就会散射回发射方向。教程首先,在FRED中创建一个新的系统,在树视图中的Geometry上右击,选择“Create New Lens…”并在出现的对话框上点OK按钮,在全局…...
)
树莓派I2C保姆级教程:从命令行工具到Python脚本,一次搞定多个传感器(附避坑指南)
树莓派I2C实战指南:从硬件调试到Python自动化控制 第一次接触树莓派的I2C接口时,我对着密密麻麻的引脚和传感器数据手册发呆了半小时。直到成功读取到第一个温湿度数据,才意识到I2C这种看似复杂的通信协议,其实就像一位耐心的翻译…...

如何用Univer在3小时内构建企业级电子表格应用?5个实战技巧分享
如何用Univer在3小时内构建企业级电子表格应用?5个实战技巧分享 【免费下载链接】univer Build AI-native spreadsheets. Univer is a full-stack framework for creating and editing spreadsheets on both web and server. With Univer Platform, Univer Spreadsh…...

2026 AI低代码实测:原理拆解+主流形态,避坑指南
2026年,AI低代码早已不是“概念炒作”,而是企业数字化转型的核心工具。Gartner预测,2026年全球70%以上新应用将采用低代码/无代码构建,较2023年45%的渗透率实现跨越式增长;IDC数据显示,同期全球AI低代码市场…...

为什么你的Perplexity自定义主题总被覆盖?揭秘其CSS优先级陷阱与3层覆盖防护机制
更多请点击: https://codechina.net 第一章:Perplexity自定义主题失效的典型现象与归因初判 当用户在 Perplexity 桌面端或浏览器扩展中配置了 CSS 主题(如通过 userChrome.css 或注入式样式脚本),却未观察到预期视觉…...
)
ArcGIS Pro脚本工具实战:5分钟用arcpy给要素批量‘改名’(保姆级参数配置指南)
ArcGIS Pro脚本工具实战:5分钟用arcpy给要素批量‘改名’(保姆级参数配置指南) 当你在处理上百个GIS图层时,是否曾被重复的"右键-属性-修改别名"操作折磨到崩溃?上周我接手一个城市管网项目,需要…...
可视化STM32引脚波形)
告别盲调!用Keil自带的逻辑分析仪(Debug Simulator)可视化STM32引脚波形
告别盲调!用Keil自带的逻辑分析仪(Debug Simulator)可视化STM32引脚波形 在嵌入式开发中,调试环节往往占据整个开发周期的40%以上时间。对于STM32开发者而言,传统的调试方式主要依赖LED闪烁观察或串口打印输出,这种方式不仅效率低…...

初次接触大模型API的开发者选择Taotoken作为起点的主要考量与体验
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初次接触大模型API的开发者选择Taotoken作为起点的主要考量与体验 对于初次接触大模型API的开发者而言,面对众多服务商…...

三星固件下载器Bifrost:三分钟掌握跨平台官方固件获取指南
三星固件下载器Bifrost:三分钟掌握跨平台官方固件获取指南 【免费下载链接】Bifrost Cross-platform tool for downloading Samsung mobile device firmware. 项目地址: https://gitcode.com/gh_mirrors/sa/Bifrost 还在为三星设备找不到官方固件而烦恼吗&am…...