机器学习入门实例-加州房价预测-1(数据准备与可视化)
问题描述
数据来源:California Housing Prices dataset from the StatLib repository,1990年加州的统计数据。
要求:预测任意一个街区的房价中位数
缩小问题:superwised multiple regressiong(用到人口、收入等特征) univariate regression(只预测一个数据)plain batch learning(数据量不大+不咋变动)
准备数据
下载数据
可以去github,也可以自动下载。
import os
import tarfile
import urllib.request
import pandas as pddown_root = "https://raw.githubusercontent.com/ageron/handson-ml2/master/"
HOUSING_PATH = "datasets"
HOUSING_URL = down_root + "datasets/housing/housing.tgz"def fetch_housing_data(housing_url=HOUSING_URL, housing_path=HOUSING_PATH):tgz_path = os.path.join(housing_path, "housing.tgz")urllib.request.urlretrieve(housing_url, tgz_path)housing_tgz = tarfile.open(tgz_path)housing_tgz.extractall(path=housing_path)housing_tgz.close()
查看数据
def load_housing_data(housing_path=HOUSING_PATH):csv_path = os.path.join(housing_path, "housing.csv")return pd.read_csv(csv_path)housing = load_housing_data()
# housing.head() 默认打印前5行信息,中间列可能省略
# housing.info() 打印行列信息、类型等
housing.info()可以简单查看数据情况。可以看到,total_bedrooms里有数据缺失,而ocean_proximity的类型是object。因为文件是csv格式,所以肯定是字符串类型。
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 20640 entries, 0 to 20639
Data columns (total 10 columns):# Column Non-Null Count Dtype
--- ------ -------------- ----- 0 longitude 20640 non-null float641 latitude 20640 non-null float642 housing_median_age 20640 non-null float643 total_rooms 20640 non-null float644 total_bedrooms 20433 non-null float645 population 20640 non-null float646 households 20640 non-null float647 median_income 20640 non-null float648 median_house_value 20640 non-null float649 ocean_proximity 20640 non-null object
dtypes: float64(9), object(1)
memory usage: 1.6+ MB
None
打印一下ocean_proximity的分类及统计,可以看到是标签,category
print(housing["ocean_proximity"].value_counts())<1H OCEAN 9136
INLAND 6551
NEAR OCEAN 2658
NEAR BAY 2290
ISLAND 5
Name: ocean_proximity, dtype: int64housing.describe()可以计算各个数值列的count,mean,std,min,25%、50%和75%(中位数)、max。计算时null会被忽略。
也可以通过绘制柱形图观察数据。
import matplotlib.pyplot as plt
housing.hist(bins=50, figsize=(20,15))
plt.show()
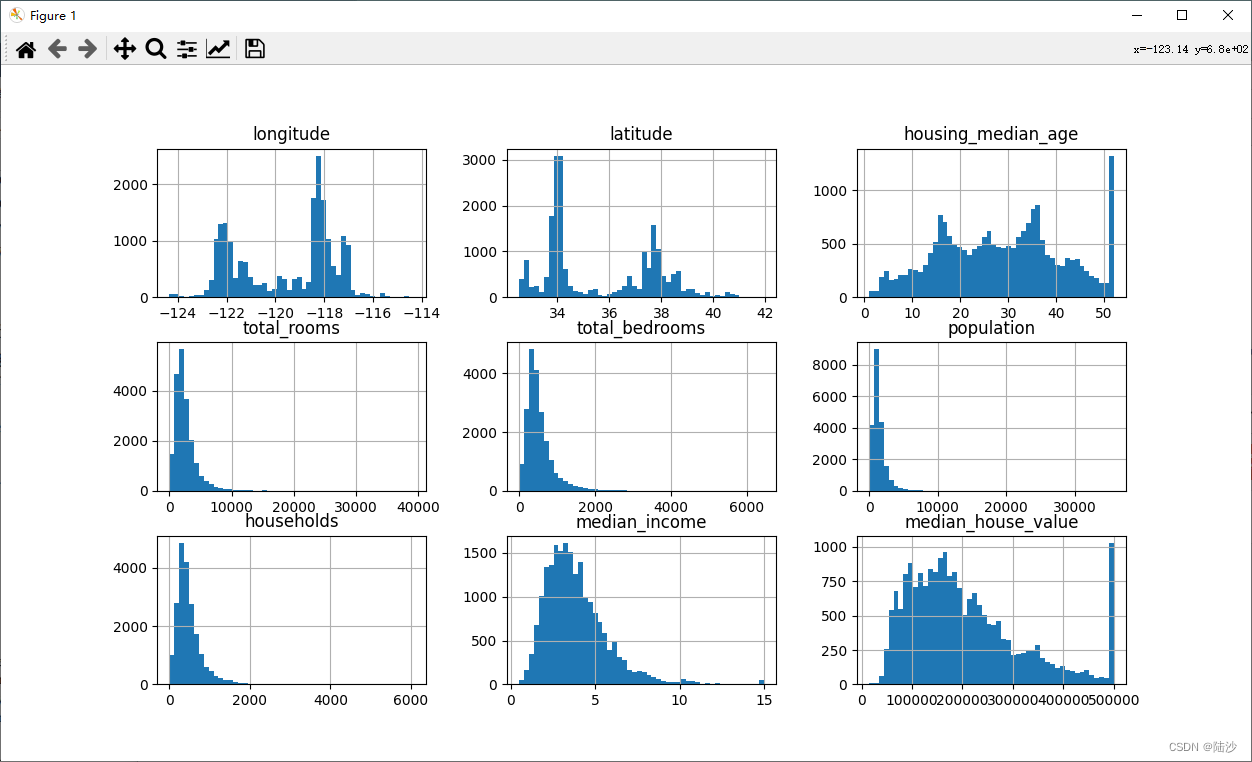
要看柱形图是因为某些机器学习算法更适合用正态数据,如果是tail-heavy(左偏)需要通过一些方法修正。
划分测试集与训练集
最简单的是直接随机挑选。但是要设置seed,因为如果不设置的话,每次运行得到的训练集不一样,时间长了整个训练集都是已知了,那测试集就失去意义了。
import numpy as np
def get_train_set(data, ratio=0.2):# 可以先设置seed以保持shuffled不变np.random.seed(42)shuffled = np.random.permutation(len(data))test_set_size = int(len(data) * ratio)test_indices = shuffled[:test_set_size]train_indices = shuffled[test_set_size:]return data.iloc[train_indices], data.iloc[test_indices]
同时scikit learn也提供了方法:random_state就跟前面设seed的功能一样。
from sklearn.model_selection import train_test_split
# random_state是随机种子,如果两次设置相同,则划分结果相同
train_set, test_set = train_test_split(housing, test_size=0.2, random_state=42)
但是,随机挑选的数据可以不够有代表性。假设median income是一个重要的特性,需要对它进行分层抽样。先看一下数据分布:
housing["income_cat"] = pd.cut(housing["median_income"], bins=[0., 1.5, 3.0, 4.5, 6., np.inf],labels=[1,2,3,4,5])
housing["income_cat"].hist()
plt.show()
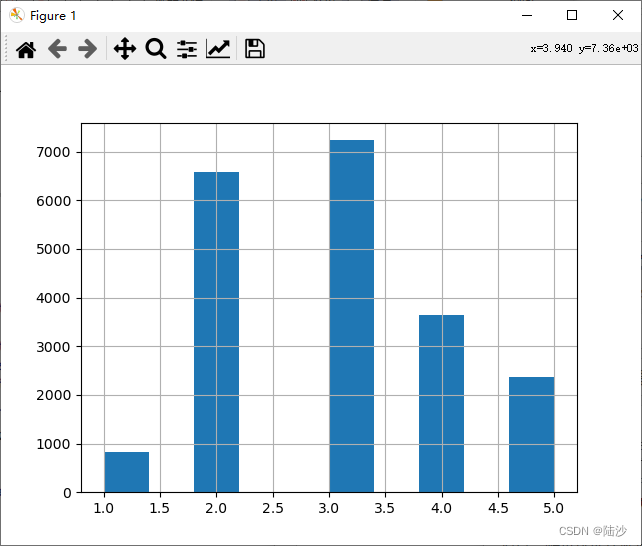
使用scikit learn带的分层抽样函数进行分层:
from sklearn.model_selection import StratifiedShuffleSplit# n_splits 参数指定了要生成的划分数量. 1就是生成1种随机划分
split = StratifiedShuffleSplit(n_splits=1, test_size=0.2, random_state=42)
for train_index, test_index in split.split(housing, housing["income_cat"]):strat_train_set = housing.loc[train_index]strat_test_set = housing.loc[test_index]
print(strat_test_set)
此时可以看到,
longitude latitude ... ocean_proximity income_cat
5241 -118.39 34.12 ... <1H OCEAN 5
17352 -120.42 34.89 ... <1H OCEAN 4
3505 -118.45 34.25 ... <1H OCEAN 3
7777 -118.10 33.91 ... <1H OCEAN 3
14155 -117.07 32.77 ... NEAR OCEAN 3
... ... ... ... ... ...
12182 -117.29 33.72 ... <1H OCEAN 2
7275 -118.24 33.99 ... <1H OCEAN 2
17223 -119.72 34.44 ... <1H OCEAN 4
10786 -117.91 33.63 ... <1H OCEAN 4
3965 -118.56 34.19 ... <1H OCEAN 3[4128 rows x 11 columns]
验证一下是否正确分层抽样了:
print(strat_test_set["income_cat"].value_counts() / len(strat_test_set))3 0.350533
2 0.318798
4 0.176357
5 0.114341
1 0.039971
Name: income_cat, dtype: float64
最终函数为:
def get_train_test_split(data, test_size):# 完全随机分类# from sklearn.model_selection import train_test_split# random_state是随机种子,如果两次设置相同,则划分结果相同# test_size是测试集所占的比例 0-1# train_set, test_set = train_test_split(data, test_size=test_size, random_state=42)# return train_set, test_set# 需要对某一列进行分层抽样# 先创造一个新列,根据某列内容,给各行打上标签data["income_cat"] = pd.cut(housing["median_income"],bins=[0., 1.5, 3.0, 4.5, 6., np.inf],labels=[1, 2, 3, 4, 5])from sklearn.model_selection import StratifiedShuffleSplit# n_splits 参数指定了要生成的划分数量split = StratifiedShuffleSplit(n_splits=1, test_size=test_size, random_state=42)for train_index, test_index in split.split(data, data["income_cat"]):strat_train_set = data.loc[train_index]strat_test_set = data.loc[test_index]# 删除刚才创造的新列for set_ in (strat_train_set, strat_test_set):# axis=1表示删除列set_.drop("income_cat", axis=1, inplace=True)return strat_train_set, strat_test_set
数据可视化
train_set, test_set = get_train_test_split(housing, 0.2)visual_data = train_set.copy()# alpha=0是透明,1是实心visual_data.plot(kind="scatter", x="longitude", y="latitude", alpha=0.1)plt.show()
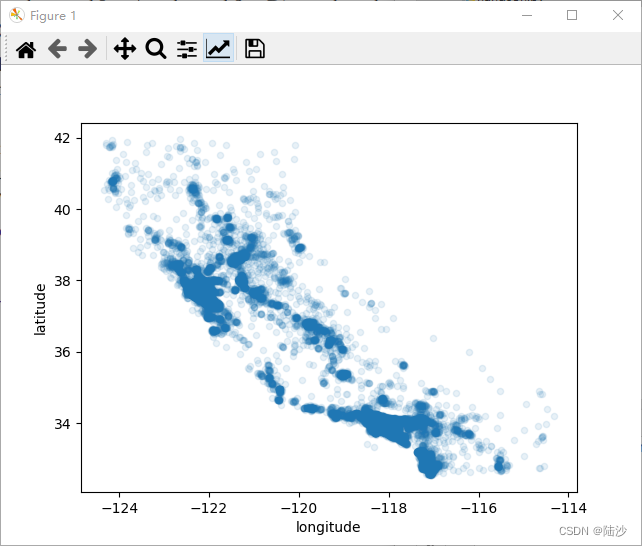
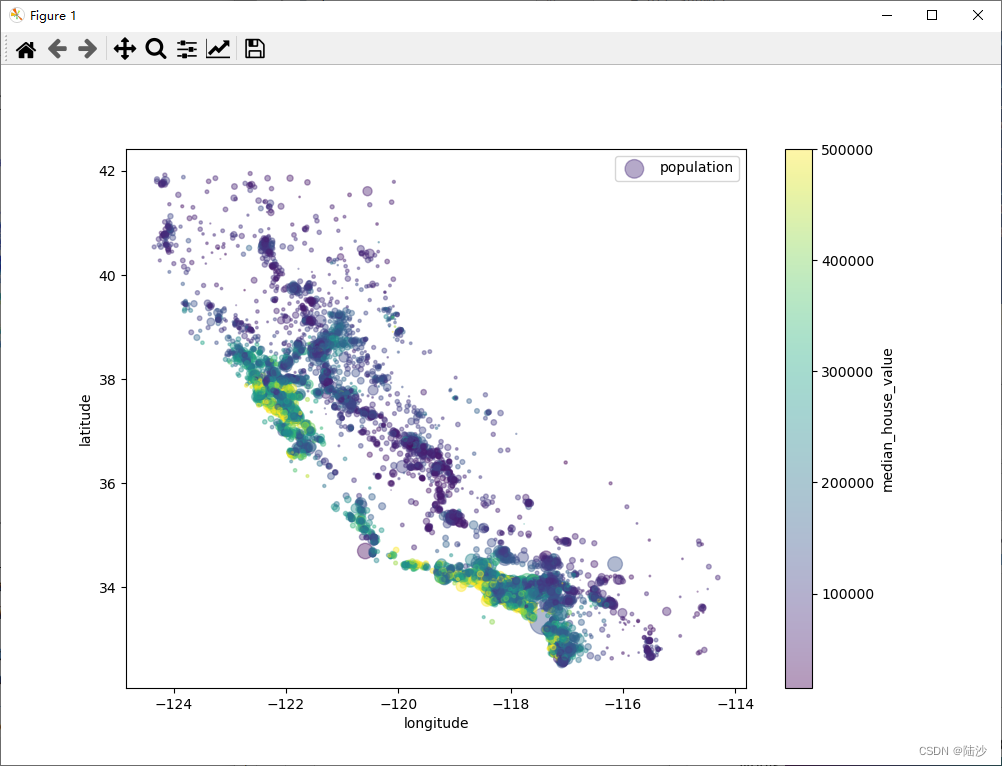
换一种包含信息更多的方式:令散点的直径大小表示人口,颜色表示房价中位值。
# s是指定散点图中点的大小,figsize默认(6.4, 4.8)格式(width, height)# c是散点图中点的颜色# cmp是将数据映射到颜色的方式. jet 是一种常用的 colormap,但是它在一些情况下可能会导致误导性# 的视觉效果,例如在颜色变化过程中的亮度或暗度变化不均匀。因此,在科学可视化领域,已经不推荐使用# jet 了。相反,viridis、plasma、magma 等 colormap 更适合用于科学可视化。# 具体来说,viridis 可以在不失真的情况下传达数据的渐变,# 而 plasma 和 magma 可以在强调数据的变化时保持不同的亮度和暗度。visual_data.plot(kind="scatter", x="longitude", y="latitude", alpha=0.4,s=visual_data["population"]/100, label="population",c="median_house_value", cmap=plt.get_cmap("viridis"),colorbar=True,figsize=(10,7))plt.legend()plt.show()
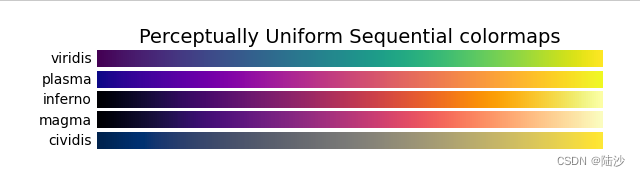
关于几种colormap代表的颜色如下图所示:
相关文章:
机器学习入门实例-加州房价预测-1(数据准备与可视化)
问题描述 数据来源:California Housing Prices dataset from the StatLib repository,1990年加州的统计数据。 要求:预测任意一个街区的房价中位数 缩小问题:superwised multiple regressiong(用到人口、收入等特征) univariat…...

【ROS2指南-20】了解ROS2组件的用法
在单个进程中组合多个节点 目录 背景 运行演示 发现可用组件 使用 ROS 服务 (1.) 与发布者和订阅者的运行时组合 使用 ROS 服务 (1.) 与服务器和客户端的运行时组合 使用 ROS 服务的编译时组合 (2.) 使用 dlopen 的运行时组合 使用启动动作组合 高级主题 卸载组件 重新…...
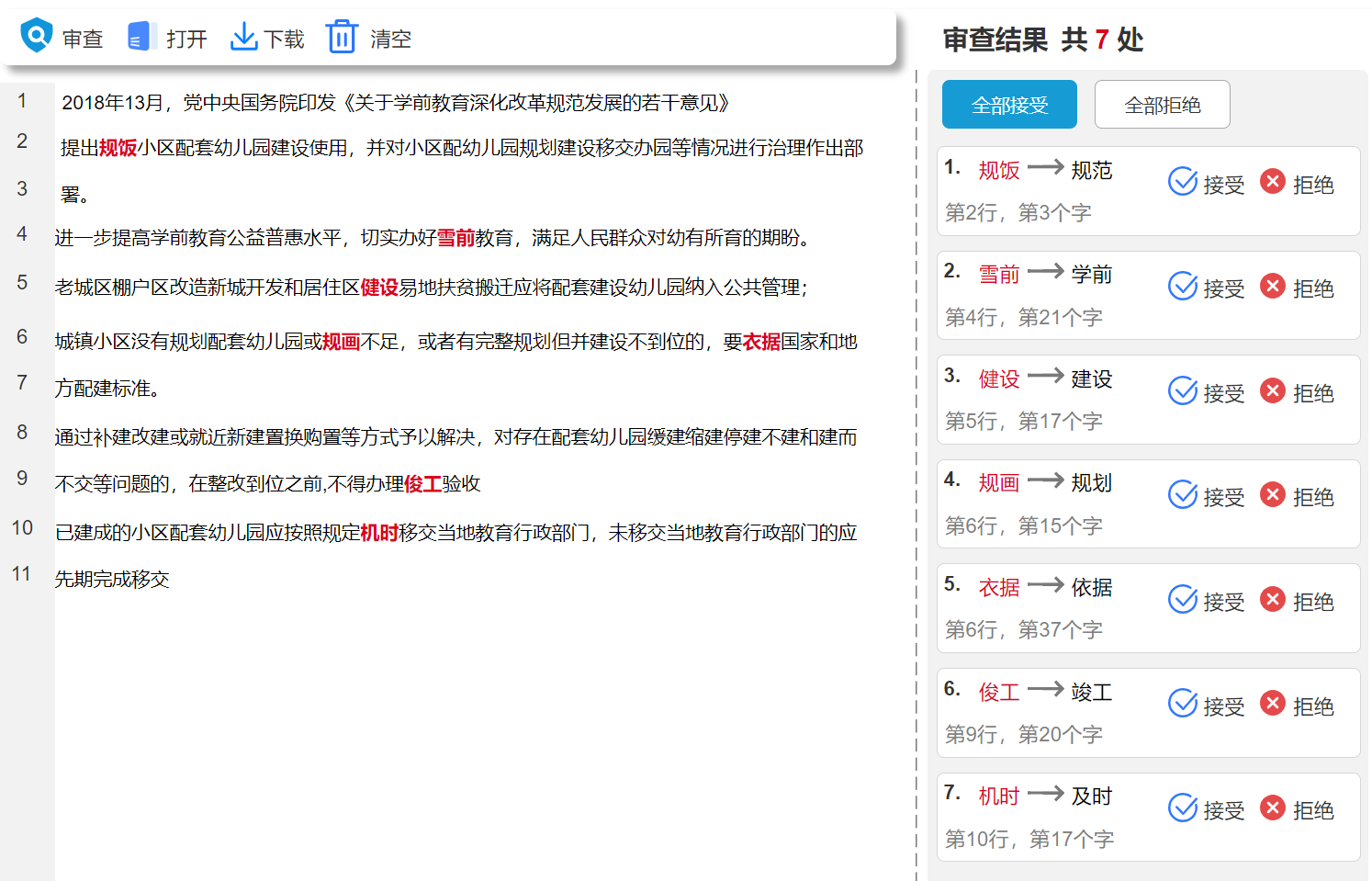
使用AI进行“文本纠错”
AI在现实中的应用有很多,你有没有想过,它还可以进行文本纠错呢?传统的校对既耗时又枯燥,通过“AI纠错”,不仅能更快完成,还能提高准确度。那么AI“文本纠错”背后的原理是什么呢?和我一起看看吧…...

第九章 法律责任与法律制裁
第九章 法律责任与法律制裁_副本 目录 第一节 法律责任的概念 一 法律责任的含义二 法律责任的特点 第二节 法律责任的分类与竞合 一 法律责任的分类 (一)根据责任行为所违反的法律的性质 民事责任:刑事责任行政责任违宪责任 (二…...

如何选择好用的海康视频恢复软件?综合考虑这几点
海康视频恢复通常是指从海康威视监控设备中恢复删除或丢失的视频。在使用海康设备进行监控时,一些重要的视频可能会被误删除或其他原因导致丢失,如果没有及时备份,数据就可能会“永久”丢失?其实不然,我们可以选择好用…...

前端学习:HTML颜色(什么是RGB、HEX、HSL)
一、什么是RGB、HEX、HSL? 无论是RGB、HEX、HSL,它们的作用只有一个:用数字表达出一种颜色。 1.RGB RGB通过输入的数值,将红色、绿色和蓝色的光源以一定的量混合在一起,形成颜色。 软件中通常让你输入Red、Green、B…...
zookeeper + kafka集群搭建详解
目录 1.消息队列介绍 1.为什么需要消息队列 (MO) 2.使用消息队列的好处 3.消息队列的两种模式 2.Kafka相关介绍 1.Kafka定义 2.Kafka简介 3. Kafka的特性 3.Kafka系统架构 1. Broker(服务器) 2. Topic(一个队…...

【数据结构与算法】 - 双向链表 - 详细实现思路及代码
目录 一、概述 二、双向链表 三、双向链表实现步骤 📌3.1 C语言定义双向链表结点 📌3.2 双向链表初始化 📌3.3 双向链表插入数据 📌3.4 双向链表删除数据 📌3.5 双向链表查找数据 📌3.6 双向链…...

面试官在线点评4份留学生简历! 这些坑你中了几个?如何写项目描述才能被大厂发面试?转专业简历该咋写 | 还有优秀简历展示!
我们给大家展示一下 从材料的准备 也就是说到底包含哪些具体的项目 为什么说这些项目是不错的 第二呢就是说在陈述上 在整个这个简历的结构 他的完备性他的准确性 他的正确性 以及最后他的具体的这种项目的描述 那讲完了这个好的简历呢 我们另外搜集了几份简历 那这些简历呢其实…...
一觉醒后ChatGPT 被淘汰了
OpenAI 的 Andrej Karpathy 都大力宣传,认为 AutoGPT 是 prompt 工程的下一个前沿。 近日,AI 界貌似出现了一种新的趋势:自主人工智能。 这不是空穴来风,最近一个名为 AutoGPT 的研究开始走进大众视野。特斯拉前 AI 总监、刚刚回归…...

spring框架的事务
1.什么是事务? 事务:是数据库操作的最小工作单元,是作为单个逻辑工作单元执行的一系列操作;这些操作作为一个整体一起向系统提交,要么都执行、要么都不执行;事务是一组不可再分割的操作集合(工作逻辑单元…...

Spring配置数据源
Spring配置数据源数据源的作用环境准备手动创建c3p0数据源封装抽取关键信息,手动创建c3p0数据源使用Spring容器配置数据源数据源的作用 数据源(连接池)是提高程序性能如出现的 事先实例化数据源,初始化部分连接资源 使用连接资源时从数据源中获取 使用完…...

【前端之旅】Vue入门笔记
一名软件工程专业学生的前端之旅,记录自己对三件套(HTML、CSS、JavaScript)、Jquery、Ajax、Axios、Bootstrap、Node.js、Vue、小程序开发(Uniapp)以及各种UI组件库、前端框架的学习。 【前端之旅】Web基础与开发工具 【前端之旅】手把手教你安装VS Code并附上超实用插件…...
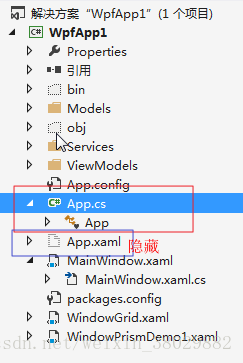
WPF教程(二)--Application WPF程序启动方式
1.Application介绍 WPF与WinForm一样有一个 Application对象来进行一些全局的行为和操作,并且每个 Domain (应用程序域)中仅且只有一个 Application 实例存在。和 WinForm 不同的是WPF Application默认由两部分组成 : App.xaml 和 App.xaml.…...

snmp 自定义子代理mib库
测试环境:centos8 1、安装软件 yum install -y net-snmp net-snmp-utils yum install -y net-snmp-perl net-snmp-devel net-snmp-libs 2、创建用户 net-snmp-create-v3-user 输入用户名 soft 输入密码 123456 输入密码 654321 service snmpd restart 3、创建…...

一文说透安全沙箱技术
在数字经济的东风中,数据安全至关重要。目前已经颁布了包括《数据安全法》、《个人信息保护法》和《数据安全管理办法》在内的国家政策,以促进整个数据要素的发展。 而近年来,随着移动应用程序的普及和小程序技术的崛起,安全沙箱…...
)
Java多线程基础面试总结(二)
创建三种线程的方式对比 使用实现Runnable、Callable接口的方式创建多线程。 优势 Java的设计是单继承的设计,如果使用继承Thread的方式实现多线程,则不能继承其他的类,而如果使用实现Runnable接口或Callable接口的方式实现多线程…...

NS32F407VGT6 NS32F407VET6软硬件通用STM32F407VGT6 407VET6
NS32F407VGT6 NS32F407VET6 器件基于高性能的 ARM Cortex-M4 32 位 RISC 内核,工作频率高达 168MHz 。 Cortex-M4 内核带有单精度浮点运算单元 (FPU) ,支持所有 ARM 单精度数据处理指令和数据类型。它还 具有一组 DSP 指令和提高应用安全性的一…...

Openstack: network: ovs: dpif/show 实例分析:interface
[TOC 实例 [cbis-adminovercloud–13 (overcloudrc) ~]$ sudo ovs-appctl dpif/show systemovs-system: hit:75198007884 missed:109924265 br-ex: br-ex 65534/3: (internal) ,65534 是port number; OpenFlow port number; 3 是 ofp_port_to_odp_port(ofproto, o…...

必要的项目管理软件因素
什么样的项目管理软件好?对于一个项目团队来说,从项目开始到项目结束,需要多个部门的配合。每个成员可能会参与一个以上的项目,这通常需要并行的多个项目。据介绍,国外90%以上的项目是用软件管理的,而中国只…...

别再死记硬背了!用Vivado 2022.1和Vitis搭建ZYNQ工程,这份避坑清单帮你省下3小时
ZYNQ开发实战:从Vivado到Vitis的高效避坑指南 当第一次打开Vivado和Vitis的开发者,往往会被复杂的界面和繁琐的配置流程所困扰。本文将以"按键控制LED"这一经典案例为主线,揭示ZYNQ开发中最容易踩中的12个深坑,并提供经…...

词达人自动化助手终极指南:10倍效率解放你的英语学习时间
词达人自动化助手终极指南:10倍效率解放你的英语学习时间 【免费下载链接】cdr 微信词达人,高正确率,高效简洁。支持班级任务及自选任务 项目地址: https://gitcode.com/gh_mirrors/cd/cdr 核心关键词:词达人自动化助手、P…...
)
告别环境配置烦恼:用PHPStudy+VSCode搭建PHP调试环境(含XDebug配置避坑指南)
告别环境配置烦恼:用PHPStudyVSCode搭建PHP调试环境(含XDebug配置避坑指南) 刚接触PHP开发时,最令人头疼的莫过于环境配置。明明跟着教程一步步操作,却总是卡在某个环节无法继续。特别是XDebug调试器的配置,…...

如何快速掌握哔哩下载姬Downkyi:面向新手的完整使用指南
如何快速掌握哔哩下载姬Downkyi:面向新手的完整使用指南 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水印等&…...

告别时序噩梦:Vivado的report_qor_suggestions从导出RQS到导入生效全流程避坑指南
告别时序噩梦:Vivado的report_qor_suggestions从导出RQS到导入生效全流程避坑指南 在FPGA设计流程中,时序收敛问题往往成为工程师的"最后一公里"难题。当设计复杂度达到一定规模时,传统的手动优化方式不仅效率低下,还可…...

对比官方直连体验Taotoken在模型调用稳定性上的差异感受
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比官方直连体验Taotoken在模型调用稳定性上的差异感受 作为一名长期与各类大模型API打交道的开发者,我习惯于直接调用…...

避开HAL库:STM32F103寄存器级PWM移相全桥配置避坑指南
STM32F103寄存器级PWM移相全桥实战:从原理到避坑指南 在嵌入式开发领域,许多工程师习惯使用HAL库或标准库进行STM32开发,这确实能提高开发效率。但当项目对时序精度、资源占用或性能有极致要求时,直接操作寄存器往往能带来更优的效…...

PSoC Creator开发实战:从组件配置到自定义模块设计
1. 项目概述与核心价值 作为一名在嵌入式领域摸爬滚打了十多年的老工程师,我接触过不少开发工具和平台。今天想和大家深入聊聊赛普拉斯(Cypress,现为英飞凌旗下)的 PSoC Creator 这款集成开发环境(IDE)。…...

uniapp地图组件map+nvue实战:从标点聚合到交互优化全解析
1. 为什么选择uniapp的map组件nvue开发地图应用 最近在做一个店铺地图功能时,我遇到了一个很典型的问题:在普通vue页面中使用map组件时,那些浮动在地图上的按钮、弹窗总是被地图遮挡。这个问题困扰了我整整两天,直到尝试了nvue方案…...

别再自己造轮子了!用BouncyCastle库在C#里快速搞定SM4国密加解密
用BouncyCastle在C#中高效实现SM4国密算法 金融级数据安全已成为现代企业系统的刚需,而国密算法作为我国自主研发的密码体系核心,正在政务、金融等高安全要求场景中快速普及。SM4作为国密标准中的对称加密算法,其128位分组长度和32轮非线性迭…...