【目标检测论文阅读笔记】Reducing Label Noise in Anchor-Free Object Detection
(Augmentation for small object detection)
Abstract
当前的 anchor-free无锚目标检测器 将空间上落在真值框预定义中心区域内的所有特征标记为正。这种方法会在训练过程中产生 标签噪声,因为这些 正标记的特征中的一些 可能位于背景或遮挡物目标上,或者它们根本不是判别性特征。在本文中,我们提出了一种新的标记策略,旨在减少无锚检测器中的标签噪声。我们将源自单个特征的预测汇总为单个预测。这允许模型在训练期间减少非判别性特征的贡献。我们开发了一种新的单阶段无锚目标检测器 PPDet,以在训练期间采用这种标记策略,并在推理期间采用类似的预测池化方法。在 COCO 数据集上,PPDet 在 anchor-free 自上而下检测器中实现了最佳性能,并且与其他最先进的方法性能相当。它还优于所有主要的单阶段和两阶段小目标检测方法 (APS 31.4)。
代码可在 https://github.com/nerminsamet/ppdet 获得。
1 Introduction
早期基于深度学习的目标检测器是两阶段的、候选框proposal驱动的方法 [7、22]。在第一阶段,生成一组稀疏的候选框,并在第二阶段使用卷积神经网络 (CNN) 对它们进行分类。后来,在单个阶段进行统一检测的想法得到了越来越多的关注 [6、14、16、21],其中 候选框被预定义的锚框所取代。一方面,锚框必须密集地覆盖图像(在位置、形状和尺度方面)以 最大化召回率;另一方面,它们的数量应该保持在最低限度,以减少推理时间和它们在训练过程中产生的不平衡问题[19]。
在 解决 anchors 的缺点上花费了大量的努力:已经提出了几种方法来提高 anchors 的质量 [27、29],以解决极端的前景-背景不平衡 [14、19、24],最近,已经开发了单阶段无锚方法。 anchor-free 目标检测中主要有两组突出的方法。第一组是 基于关键点 的自下而上方法,在开创性工作 CornerNet [11] 之后得到推广。这些检测器 [4、11、17、32] 首先检测对象的关键点(例如角点、中心点和极点),然后将它们分组以产生整个目标的检测。第二组 无锚目标检测器 [10、25、33] 采用自上而下的方法,直接预测最终特征图中每个位置的类和边界框坐标。
目标检测器训练的一个重要方面是 用于标记候选对象的策略,它 可以是最终特征图中的proposals、锚点 或 位置(即特征)。为了在训练期间将候选者标记为“正”(前景)或“负”(背景),基于交并比(IoU)[3、14、16、22],关键点 [ 4, 11, 17, 32] 和 相对于真值框的位置 [10, 25, 26]。特别是在自上而下的无锚目标检测器中,在输入图像通过主干特征提取器和 FPN [13] 后,空间上落在真值框内的特征被标记为正,其他标记为负——有两者之间还有一个“忽略”区域。这些 正标记的特征中的每一个 都作为单独的预测 对损失函数做出贡献。这种方法的 问题在于,其中一些正标签可能是明显错误的或质量很差,因此,它们会 在训练过程中注入标签噪声。

噪声标签来自(i)目标上的非判别性特征,(ii)真值框内的背景特征,以及(iii)遮挡物(图1)。在本文中,我们提出了一种 anchor-free 目标检测方法,该方法放宽了正标记策略,使模型能够在训练过程中减少非判别性特征的贡献。根据这种训练策略,我们的目标检测器采用了一种推理方法,其中高度重叠的预测相互强制。
在我们的方法中,在训练期间,我们在真值 (GT) 框内定义了一个“正区域”,该区域与 GT 框同心且具有相同的形状。我们通过实验 调整 正区域 相对于 GT 框的大小。由于这是一种无锚方法,每个特征(即最终特征图中的位置)预测一个类概率向量 和 边界框坐标。来自 GT 框正区域的类别预测汇集在一起,并作为单个预测对损失做出贡献。由于来自非目标(背景或遮挡)区域的特征的贡献 和 非判别性特征 在训练期间会自动降低权重,因此这种 sum-pool 总和池化 减轻了上述噪声标签问题。在推断时,高度重叠框的类别概率 再次汇集在一起 以获得最终类别概率。我们将我们的方法命名为“PPDet”,它是“prediction pooling detector”的缩写。
我们对这项工作的贡献有两个:
(i) 一种宽松的标签策略,它允许模型在训练过程中减少非判别性特征的贡献,以及
(ii) 一种新的目标检测方法 PPDet,它将这种策略 用于训练 和 基于预测池化的新推理过程。
我们展示了我们的提案在 COCO 数据集上的有效性。 PPDet 优于所有 anchor-free top-down 检测器,并且与其他最先进的方法性能相当。 PPDet 对于检测小目标特别有效(31.4 APS,优于最先进的技术)。
2 Related Work
除了目标检测器的经典一阶段 [6, 14, 16, 21] 与两阶段 [3, 7, 22] 分类之外,我们还可以将当前的方法分为两类:基于锚点和无锚点。
自上而下的无锚目标检测器 通过 消除复杂的 IoU 操作 并专注于识别可能包含对象的区域 来简化训练过程。从这个意义上讲,FCOS [25]、FSAF [33] 和 FoveaBox [10] 首先将 GT 框映射到 FPN 级别,然后 根据它们是否在 GT 框内将位置(即特征)标记为正或负。边界框预测仅适用于正标记的位置。FoveaBox [10] 和 FSAF [33] 为每个对象实例定义了三个区域;正面积、忽略面积和负面积。 FoveaBox 将正(fovea 凹)区域定义为与 GT 框同心的区域,其尺寸按(收缩)因子 0.3 缩放。此正区域内的所有位置都标记为正样本。类似地,使用 0.4 的收缩系数获得另一个区域。该区域之外的任何位置都被标记为负值。如果一个位置既不是正的也不是负的,它在训练过程中被忽略。 FSAF 遵循相同的方法并分别使用收缩因子 0.2 和 0.5。 FCOS 没有像 [10、26、33] 那样预先定义离散区域,而是使用 centerness中心度 分支 根据它们到中心的距离来降低特征的权重。 FCOS 和 FoveaBox 实现 静态的特征金字塔层选择,它们分别根据 GT 框尺度 和 GT 框回归距离 将对象分配到层。与它们不同的是,FSAF 放宽了特征选择步骤,并动态地 将每个目标分配到最合适的特征金字塔层级。
自下而上的无锚目标检测方法 [4、11、17、32] 旨在 检测目标的某些关键点,例如 角点 和 中心。他们的标记策略使用热图heatmaps,从这个意义上说,它与自上而下的无锚方法有很大不同。最近,HoughNet 是一种新颖的、自下而上的基于投票的方法,可以利用近距离和远程证据来检测目标中心,它显示出与主要的单阶段和两阶段自上而下方法相当的性能 [23]。
在基于锚点的方法 [3、14、16、21、22、26、31] 中,目标是从回归锚框预测的。在训练期间,anchor boxes 的标签是根据它与 GT boxes 的交并比 (IoU) 来确定的。不同的检测器使用不同的标准,例如如果 IoU > 0.7,Faster RCNN [22] 将锚标记为正,如果 IoU < 0.3,则标记为负; R-FCN [3]、SSD [16] 和 Retinanet [14] 使用 IoU > 0.5 进行正标记,但负标记的标准略有不同。有两种突出的基于锚点的方法可以直接解决标签问题。 Guided Anchoring [26] 引入了一种新的自适应锚定方案,该方案学习任意形状的框而不是密集和预定义的框。类似于 FSAF [33]、FoveaBox [10] 和我们的方法 PPDet,Guided Anchoring 遵循基于区域的标记 并为每个真值目标定义三种类型的区域;中心区域,忽略区域 和 外部区域,如果生成的锚点位于中心区域内部,则将其标记为正,如果位于外部区域,则标记为负,并忽略其余部分。另一方面,FreeAnchor [31] 将放宽正标签的想法应用于基于锚点的检测器。这是和我们最相似的方法。它用最大似然估计程序取代了手工制作的锚点分配,其中锚点可以自由选择他们的 GT 框。由于 FreeAnchor 正在使用自定义损失函数优化目标锚点匹配,因此它 不能直接应用于无锚点目标检测器。
3 Methods
标签策略和训练。
无锚Anchor-free检测器 通过根据 它们的尺度 [10] 或 目标回归距离 [25] 将它们分配到适当的 FPN 级别来限制 GT 框的预测。在这里,我们遵循基于比例的分配策略 [10],因为它是一种自然地将 GT 框与特征金字塔级别相关联的方法。然后,我们为每个 GT 框构建两个不同的区域。我们将“正区域”定义为与 GT 框同心且与 GT 框具有相同形状的区域。我们通过实验设置“正区域”的大小。然后,我们将空间上落在 GT 框“正区域”内的所有位置(即特征)识别为“正(前景)”特征,其余为“负(背景)”特征。每个正特征都被分配给包含它的真值框。在图 2 中,蓝色和红色单元格代表前景单元格,其余(空白或白色)是背景单元格。蓝色单元格分配给飞盘对象,红色单元格分配给人对象。为了获得对象实例的最终检测分数,我们汇集了分配给该对象的所有特征的分类分数,将它们加在一起以获得最终的 C 维向量,其中 C 是类的数量。除了正标记的特征外,所有特征都是负的。每个负特征都会单独影响损失(即没有合并)。这个最终的预测向量被馈送到 焦点Focal损失(FL)。例如,假设 ![]() 表示分配给图 2 中人物对象的红色前景特征。令 y 为人类类别person class。然后,这个特定的对象实例将“
表示分配给图 2 中人物对象的红色前景特征。令 y 为人类类别person class。然后,这个特定的对象实例将“![]() ”贡献给训练中的损失函数。每个对象实例都用一个单独的预测表示。
”贡献给训练中的损失函数。每个对象实例都用一个单独的预测表示。

默认情况下,我们将正特征分配给它们所在框的对象实例。此时,不同 GT 框的交叉区域中的特征分配是一个需要处理的问题。在这种情况下,我们 将这些特征分配给与其中心距离最小的 GT 框。与其他无锚方法 [10、25、32、33] 类似,在我们的模型中,分配给对象的每个前景特征都经过训练以预测其对象 GT 框的坐标。
我们对分类分支使用 focal loss 焦点损失 [14](α = 0.4 和 γ = 1.5),对回归分支使用 平滑 L1 损失 [7]。
Inference.

PPDet 的推理管道如图 3 所示。首先,输入图像被馈送到主干神经网络模型(在下一节中描述),该模型产生初始检测集。每个检测都与 (i) 边界框、(ii) 对象类别(选择为具有最大概率的类别)和 (iii) 置信度得分 相关联。在这些检测中,那些标有背景类别的检测被淘汰。我们将此阶段的每个剩余检测视为对其所属对象的投票,其中框是目标位置的假设,置信度分数是投票的强度。接下来,这些检测按如下方式汇集在一起。如果属于同一对象类的两个检测重叠超过一定数量(即交并比(IoU)> 0.6),则我们将它们视为对同一对象的投票,并且每个检测的分数增加了另一个检测的分数的 ![]() 倍,其中 k 是常数。 IoU 越多,增加的幅度越大。将此过程应用于每对检测后,我们获得最终检测的分数。此步骤之后是产生最终检测的类感知非极大值抑制 (NMS) 操作。
倍,其中 k 是常数。 IoU 越多,增加的幅度越大。将此过程应用于每对检测后,我们获得最终检测的分数。此步骤之后是产生最终检测的类感知非极大值抑制 (NMS) 操作。
请注意,尽管推断中使用的预测池化prediction pooling 似乎与训练中使用的pooling不同,但实际上它们是相同的过程。训练中使用的池化 假设正区域中的特征预测的边界框彼此完美重叠(即 IoU = 1)。
网络架构。
PPDet 使用 RetinaNet [14] 的网络模型,它由一个主干卷积神经网络 (CNN) 和一个特征金字塔网络 (FPN) [13] 组成。 FPN 计算多尺度特征表示 并生成五个不同尺度的特征图。每个 FPN 层的顶部有两个独立的并行网络,即分类网络和回归网络。分类网络输出一个 W × H × C 张量,其中 W 和 H 是空间维度(分别是宽度和高度),C 是类别数。类似地,回归网络输出一个 W × H × 4 张量,其中 4 是边界框坐标的数量。我们将这些张量中的每个像素 称为一个特征。
4 Experiments
本节描述了我们为展示我们提出的方法的有效性而进行的实验。首先,我们提出消融实验以找到 GT 框内正区域的最佳相对面积 和 回归损失权重。接下来,我们将在 COCO 数据集上进行几个性能比较。最后,我们提供了样本热图,它显示了负责正确检测的特征的 GT 框相对位置。
实施细节。
我们在 ResNet [9] 和 ResNeXt [28] 之上使用特征金字塔网络 (FPN) [13] 作为我们的主干网络,分别用于消融和最先进的比较。对于所有实验,我们调整图像的大小,使其短边为 800 像素,长边最大为 1300 像素。投票聚合中使用的常量 k(即 )实验性地设置为 40。我们在 4 个 Tesla V100 GPU 上训练了所有实验,并使用单个 Tesla V100 GPU 进行了测试。我们使用 MMDetection [2] 框架和 Pytorch [20] 来实现我们的模型。
4.1 消融实验
除非另有说明,否则在消融实验中,我们使用具有 FPN 主干的 ResNet-50。他们使用权重衰减为 0.0001 和 动量为 0.9 的随机梯度下降 (SGD) 以 16 的批量大小训练 12 个时期。初始学习率 0.01 在第 8 轮和第 11 轮下降了 10 倍。所有消融模型都在 COCO [12] train2017 数据集上进行训练,并在 val2017 集上进行测试。
“正区域”的大小。
如前所述,我们将“正区域”定义为 与 GT 框同心且与 GT 框具有相同形状的区域。我们通过将其宽度和高度乘以收缩因子来调整此“正区域”的大小。我们试验了 1.0 到 0.2 之间的收缩因子。性能结果如表 1 所示。从收缩因子 1.0 到 0.4,AP 增加,但是,在那之后性能急剧下降。基于这种消融,我们将其余实验的收缩因子设置为 0.4。

回归损失权重
为了找到分类和回归损失之间的最佳平衡,我们对回归损失权重进行了消融实验。如表 2 所示,0.75 产生最佳结果。对于其余实验,我们将回归损失的权重设置为 0.75。

改进。
我们 还采用了其他最先进的目标检测器 [10、25、32] 中使用的改进。首先,我们使用带有 FPN 主干的 ResNet-101 训练我们的基线模型。后来,我们 用可变形卷积层替换了分类分支中类别预测之前的最后一个卷积层。此修改将所有 AP 的性能提高了 0.3 左右(见表 3)。后来,在此修改之上,我们添加了另一个修改,在回归和分类分支中的每个卷积层之后采用组归一化。如表 3 所示,此修改将 AP 提高了 0.6,将 AP50 提高了 1.1。在此表中,我们还提供了最近引入的 moLRP [18] 指标的结果,该指标将定位、精度和召回率结合在一个指标中。值越低越好。使用权重衰减为 0.0001 和动量为 0.9 的随机梯度下降 (SGD),以 16 的批量大小训练模型 24 个时期。初始学习率 0.01 在第 16 轮和第 22 轮下降了 10 倍。我们在最终模型中包含了这两个修改。

类别不平衡。
PPDet 将预测汇总为每个对象实例的单个预测,这减少了训练期间的正样本数。人们可能会认为它进一步加剧了类别不平衡 [19]。为了分析这个问题,我们计算了每张图像的平均正数,PPDet 为 7,FoveBox 为 41,RetinaNet 为 165。 PPDet 大大减少了正样本的数量。然而,与负样本的数量(数万)相比,这仍然很小,因此,它不会加剧现有的类别不平衡问题。我们 使用 焦点损失 来解决不平衡问题。
4.2 最先进的比较
为了将我们的模型与最先进的方法进行比较,我们使用了带有 FPN 的 ResNet-101 和带有 FPN 主干的 ResNeXt-101-64x4d。他们分别使用权重衰减为 0.0001 和动量为 0.9 的 SGD,以 16 和 8 的批量大小分别训练 24 和 16 个时期。对于 ResNet 主干,初始学习率 0.01 在第 16 和 22 轮下降了 10 倍。对于 ResNeXt 主干,初始学习率 0.005 在第 11 和 14 轮下降了 10 倍。模型在 COCO [12] train2017 数据集和在测试开发集上测试。我们使用了(800,480)、(1067,640)、(1333,800)、(1600,960)、(1867,1120)、(2133,1280)个尺度进行多尺度测试。表 4 显示了 PPDet 和几个已建立的最先进检测器的性能。

 FSAF [33] 和 FoveaBox [10] 使用与我们类似的方法来构建“正区域”。虽然 PPDet 的单尺度测试性能与 FSAF 在具有 FPN 骨干的相同 ResNeXt-101-64x4d 上的性能相当,但 PPDet 的多尺度测试性能比 FSAF 的多尺度测试性能高 1.7 个 AP 点。我们使用单尺度测试的两个模型都比 FoveaBox 获得了更好的结果,同时在小目标上的表现优于它 1.0 以上。我们的多尺度测试结果在具有 FPN 主干的同一 ResNet-101 上优于 FoveaBox 1 个 AP。
FSAF [33] 和 FoveaBox [10] 使用与我们类似的方法来构建“正区域”。虽然 PPDet 的单尺度测试性能与 FSAF 在具有 FPN 骨干的相同 ResNeXt-101-64x4d 上的性能相当,但 PPDet 的多尺度测试性能比 FSAF 的多尺度测试性能高 1.7 个 AP 点。我们使用单尺度测试的两个模型都比 FoveaBox 获得了更好的结果,同时在小目标上的表现优于它 1.0 以上。我们的多尺度测试结果在具有 FPN 主干的同一 ResNet-101 上优于 FoveaBox 1 个 AP。
我们的多尺度性能是所有无锚自上而下方法中最好的。此外,我们在小目标(即 APS)上的多尺度性能在表 4 中的所有检测器中设置了新的最新技术水平。
我们进行了实验来分析 预测池化prediction pooling 对训练和推理的影响。当我们从 ResNet-101-FPN 主干模型的推理管道中 删除 预测池 prediction pooling 时,我们观察到 val2017 集上的 AP 下降了 2.5 个点。为了分析预测池对训练的影响,我们仅在推理期间向 RetinaNet [14] 和 FoveaBox [10] 添加了预测池(因此,训练中没有 PP)。这导致 RetinaNet 和 FoveaBox 的 AP 分别下降了 0.5 和 2.8 分。
我们还进行了另一个实验来测试 sum-pooling 相对于 max-pooling 的有效性。对于最大池化,我们确定了正区域内的特征,其预测框与 GT 框重叠最多。然后,只有这个特征被包含在 focal loss 中,以在训练期间代表它的 GT box。该策略将 AP 降低了 2 个多点,使用 FPN 主干的 ResNet101 产生了 38.4。
作为附加结果,我们展示了 PPDet 在 PASCAL VOC 数据集 [5] 上的性能。对于训练,我们使用了 PASCAL VOC 2007 trainval 和 VOC 2012 trainval 图像的联合集(“07+12”)。为了进行测试,我们使用了 PASCAL VOC 2007 的测试集。当两者都使用 ResNet-50 主干时,我们的 PPDet 模型达到了 77.8 的平均精度 (mAP),优于 FoveaBox [10] 的 76.6 mAP,我们将其视为此处的基线。

图 4 显示了 单元格cell中心 相对于负责检测的真值框 的热图。 RetinaNet 的热图集中在真值对象框的中心。相比之下,PPDet 的最终检测是 由相对更广泛的区域形成的,验证了其在 为正区域的特征 分配权重时的 动态和自动特性。除了来自真值框中心的检测外,它们还可能大量来自真值框的不同部分。
5 Conclusion
在这项工作中,我们引入了一种用于训练无锚目标检测器的新型标记策略。虽然当前的无锚方法在真值框的预定义中心区域内的所有特征上强制使用正标签,但我们的标签策略通过将源自单个特征的预测 sum-pooling总和合并 为单个预测来放宽此约束。这允许模型在训练期间减少非判别性特征的贡献。我们开发了 PPDet,这是一种单阶段无锚目标检测器,它在训练期间采用新的标记策略 和 基于池化预测的新推理方法。我们通过进行几个消融实验来分析我们的想法。我们在 COCO test-dev 上报告了结果,表明 PPDet 的性能与最先进的水平相当,并在小目标上取得了最先进的结果 (APS 31.4)。我们通过可视化检查进一步验证了我们方法的有效性。
相关文章:
【目标检测论文阅读笔记】Reducing Label Noise in Anchor-Free Object Detection
(Augmentation for small object detection) Abstract 当前的 anchor-free无锚目标检测器 将空间上落在真值框预定义中心区域内的所有特征标记为正。这种方法会在训练过程中产生 标签噪声,因为这些 正标记的特征中的一些 可能位于背景或遮挡…...

金融数字新型基础设施创新开放联合体今日成立
4月18日,“金融数字新型基础设施创新开放联合体”(以下简称:联合体)在上海成立。联合体由上海银行、复旦大学金融科技研究院、中电金信共同发起,首批成员单位汇聚产业链与供给侧的中坚力量:国泰君安证券、太…...

编程语言的发展史
编程语言处在不断的发展和变化中,从最初的机器语言发展到如今的2500种以上的高级语言,每种语言都有其特定的用途和不同的发展轨迹。编程语言并不像人类自然语言发展变化一样的缓慢而又持久,其发展是相当快速的,这主要是计算机硬件…...

巧用千寻位置GNSS软件|点测量采集技巧
点测量是测量中重要的节点,在测量工作的信息处理分析中发挥着重要作用。本期将给各位带来使用千寻位置GNSS软件采集地形点、控制点、快速点、连续点、房角点和倾斜点的操作技巧。 地形点 地形点的设置如图 5.1-9所 示,每次采集一个点,该点需要…...
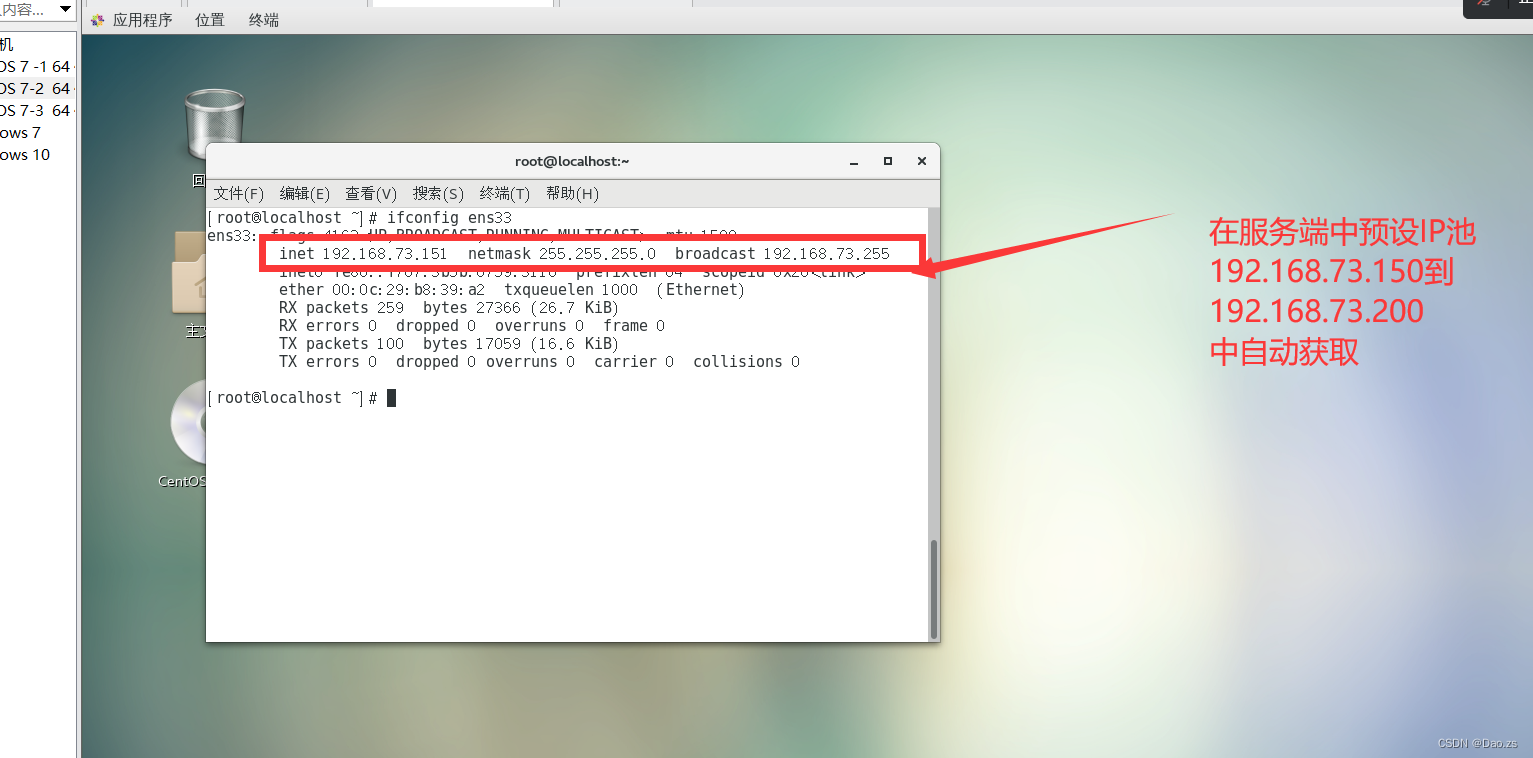
DHCP原理与配置
目录 一、DHCP工作原理 1)了解DHCP服务 使用DHCP的好处 DHCP的分配方式 2)DHCP的租约过程 分为四个步骤 二、DHCP服务器的配置 1)检查并且安装dhcp有关软件包 2)查看系统的配置文件,并且利用好官方给的参考案…...

软件测试今天你被内卷了吗?
认识一个人,大专学历非计算机专业的,是前几年环境好的时候入的行,那时候软件测试的要求真的很低,他那时好像是报了个班,然后入门的,但学的都是些基础,当时的他想的也简单,反正也能拿…...

做完自动化测试,但别让不会汇报毁了你...
pytest 是一个成熟的全功能Python测试工具,可以帮助您编写更好的程序。它与 python 自带的 unittest 测试框架类似,但 pytest 使用起来更简洁和高效,并且兼容 unittest 框架。pytest 能够支持简单的单元测试和复杂的功能测试,pyte…...
企业级信息系统开发讲课笔记2.4 利用MyBatis实现条件查询
文章目录 零、本节学习目标一、查询需求二、打开MyBatisDemo项目三、对学生表实现条件查询(一)创建学生映射器配置文件(二)配置学生映射器文件(三)创建学生映射器接口(四)测试学生映…...
)
【天梯赛—不想坑队友系列】L2-003 月饼(java)
目录 第一题: L2-003 月饼 输入格式: 输出格式: 输入样例: 输出样例: 题目分析 题目代码 第二题:德才论 输入格式: 输出格式: 输入样例: 输出样例ÿ…...
电磁兼容(EMC)的标准与测试内容
在国际范围上,电磁兼容标准的制定已经有了70多年的发展历程,最早为了保护无线电通信和广播,国际无线电干扰特别委员会(CISPR)对各种用电设备和系统提出了相关的电磁干扰发射限值和测量方法。到了20世纪60~7…...

滑动平均算法
class Solution { public static int[] maxSlidingWindow(int[] nums, int k) { int right 0; int[] res new int[nums.length -k 1]; int index0; LinkedList<Integer> list new LinkedList<>(); // 开始构造窗口 …...

个人职业发展
职业的本质就是人和社会的交换关系。选择什么职业,等于选择了用什么方式和世界交换。 比如,快递员、小时工靠“体力”;大多数打工者靠“体力智力”;网红靠“资源、平台”;各领域的大神、科学家、艺术家靠“天赋”。 这…...
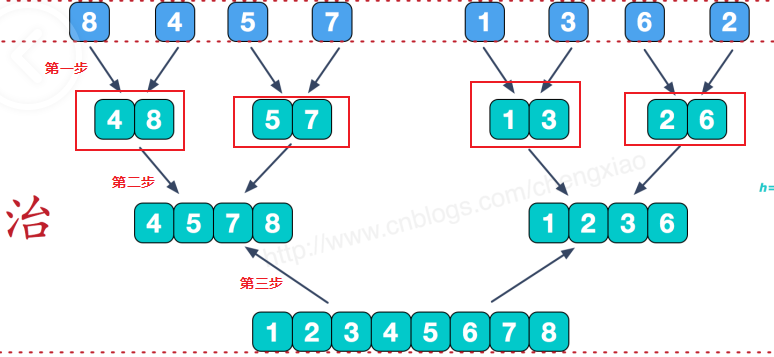
剑指 Offer 51. 数组中的逆序对
剑指 Offer 51. 数组中的逆序对 难度:hard\color{red}{hard}hard 题目描述 在数组中的两个数字,如果前面一个数字大于后面的数字,则这两个数字组成一个逆序对。输入一个数组,求出这个数组中的逆序对的总数。 示例 1: 输入: [7…...
数字化转型迫在眉睫!药企如何应用AI技术加速创新?
导语 | 近年来,随着 AI 等技术的发展应用,数字化、智能化日渐成为各行各业转型升级的新兴力量,其与医药产业的融合创新也逐渐成为当前的新趋势,众多医药制造企业蓄势待发,搭乘数字化的快车,驶入高速发展的快…...

电脑显示屏是怎么显示出图像的?CPU与GPU又是什么关系?
文章目录电脑显示屏是怎么显示出图像的?CPU与GPU又是什么关系?显卡作用明明有了CPU为什么还要GPU?电脑显示屏是怎么显示出图像的?内存与显存所有运算都交给GPU处理可以吗?参考:电脑显示屏是怎么显示出图像的ÿ…...

报名截至在即 | “泰迪杯”挑战赛最后一场赛前指导直播!
为推广我国高校数据挖掘实践教学,培养学生数据挖掘的应用和创新能力,增加校企交流合作和信息共享,提升我国高校的教学质量和企业的竞争能力,第十一届“泰迪杯”数据挖掘挑战赛(以下简称挑战赛)已于2023年3月…...

经验分享:如何有效应对Facebook广告数据波动问题?
Facebook广告作为一种重要的数字营销工具,可以帮助企业和品牌快速获得目标受众的关注和转化。然而,由于广告投放过程的不稳定性,Facebook广告数据波动问题也经常出现。 对于广告主而言,如何应对Facebook广告数据波动问题…...
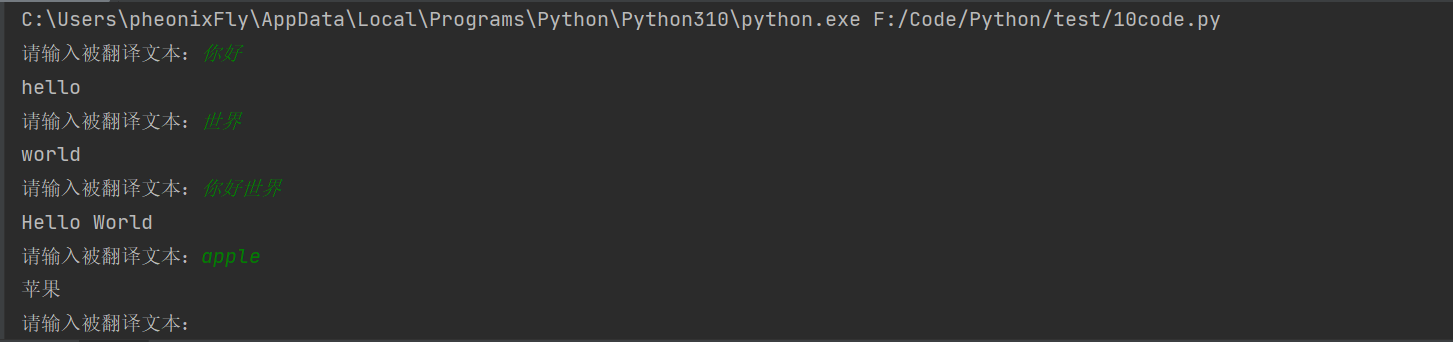
【Python】逆向解析js代码
目录 1. 打开百度翻译网页,查找翻译结果的网络资源包 2. 获取翻译结果网络资源包的url、请求头、请求体,解析json文件数据 3. 观察请求体字段,发现 query 字段便是我们输入的需要翻译的值 4. ctrl F 快捷键搜索sign值的网络资源包&#x…...
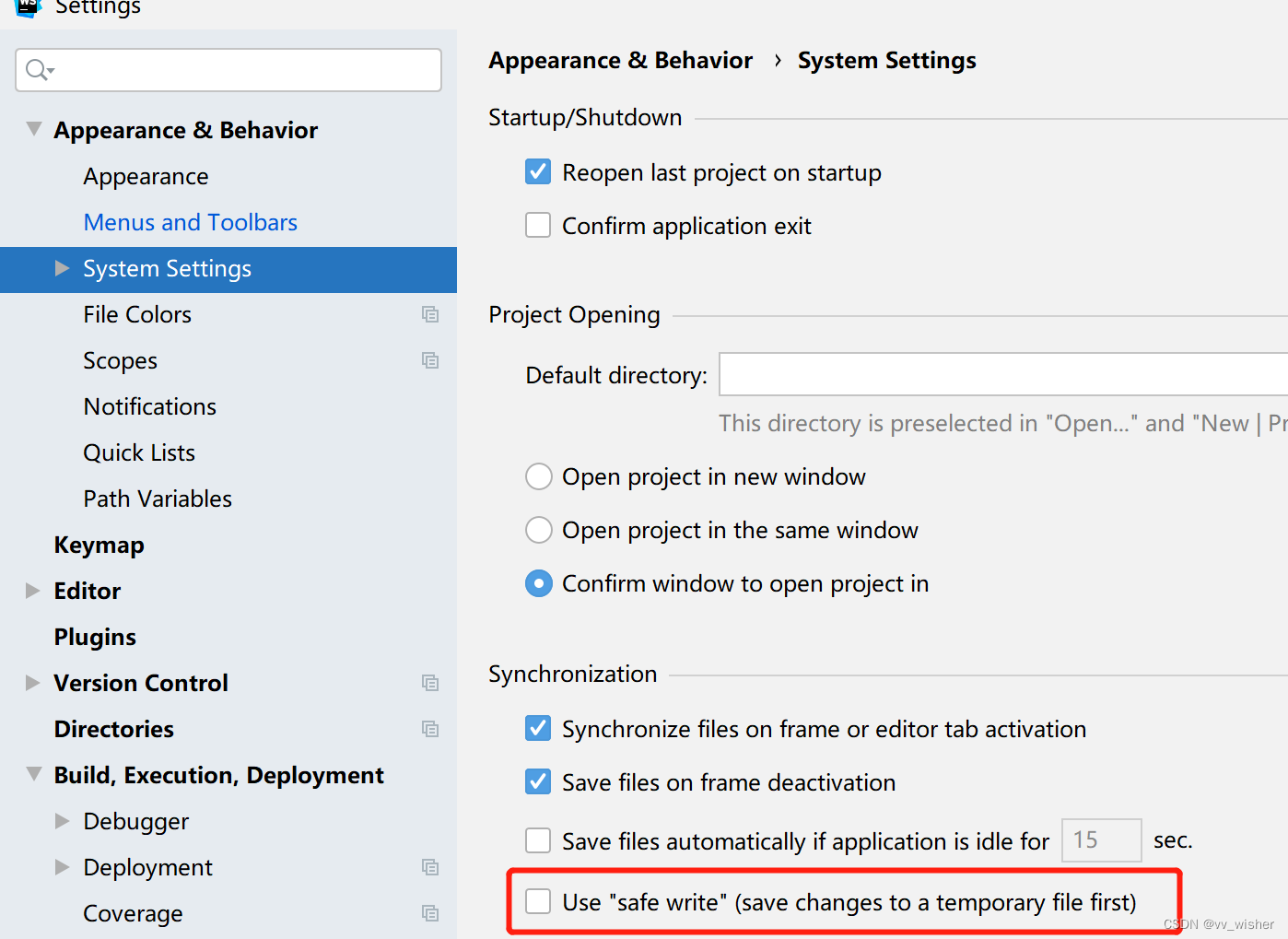
websorm启动vue项目修改内容后自动运行内存溢出
手动启动vue项目正常运行,修改部分内容保存后会自动重新run一下, 这个时候就报错内存溢出,然后很悲伤的需要再手动重启一下。 (在网上查了好多方法就不单独加链接了) 前3个方法都试过对于我的项目无效,第4…...
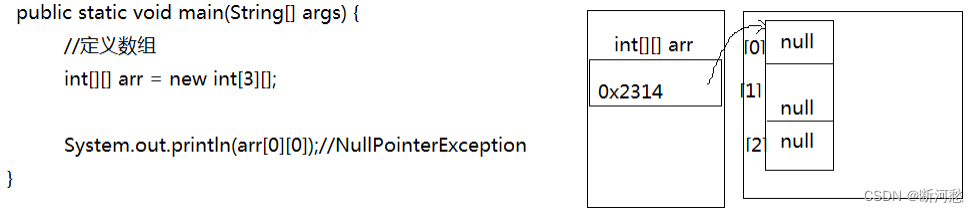
第05章_数组
第05章_数组 讲师:尚硅谷-宋红康(江湖人称:康师傅) 官网:http://www.atguigu.com 本章专题与脉络 1. 数组的概述 1.1 为什么需要数组 需求分析1: 需要统计某公司50个员工的工资情况,例如计…...

❌别再硬拆QA了!谷歌SEO最大的坑你还在踩
2026年5月7日,谷歌在官方开发者文档悄然更新了一则重磅公告:FAQ 富摘要(FAQ Rich Results)正式全面下线,即日起不再搜索结果中展示。这不是临时调整,而是持续三年收紧后的终极收尾 —— 从 2023 年仅对政府、医疗站开放,到 2026 年 3 月大幅缩减展示量,再到如今彻底关闭…...

Inkscape实战:用蒙版给你的Logo或文字快速添加酷炫的渐变效果
Inkscape蒙版进阶:打造专业级渐变Logo的5种创意技法 在矢量设计领域,一个普通的Logo与令人眼前一亮的作品之间,往往只差一层巧妙的渐变蒙版。作为开源矢量图形编辑器的标杆,Inkscape的蒙版功能远不止于基础遮罩——当它与渐变工具…...
TranslucentTB完全指南:轻松实现Windows任务栏透明化的终极方案
TranslucentTB完全指南:轻松实现Windows任务栏透明化的终极方案 【免费下载链接】TranslucentTB A lightweight utility that makes the Windows taskbar translucent/transparent. 项目地址: https://gitcode.com/gh_mirrors/tr/TranslucentTB 想要让Window…...
)
别再到处搜了!高德、百度、ArcGIS地图瓦片URL,我帮你整理好了(附Leaflet加载代码)
地图瓦片集成实战:从URL解析到Leaflet高效加载 1. 地图瓦片服务的选择与评估 在WebGIS开发中,选择合适的瓦片地图服务是项目成功的第一步。主流服务商提供的地图瓦片各有特点,开发者需要根据项目需求进行综合评估。 高德地图瓦片以其丰富的图…...
)
从‘黑盒子’到清晰电路:用替代定理‘破译’未知网络N的VCR(图解+方程双解法)
从‘黑盒子’到清晰电路:用替代定理‘破译’未知网络N的VCR(图解方程双解法) 在电子工程实践中,工程师们常常会遇到一种令人头疼的"黑盒子"——那些内部结构不明、数据手册不全的电路模块。面对这样的未知网络ÿ…...

OPPO新时代板凳精神:解码长期主义研发体系与前沿技术人才战略
1. 从“板凳精神”到“微笑前行”:OPPO的研发哲学与人才战略最近,OPPO在五四青年节发布的那支名为《板凳》的品牌片,以及随之公布的超过2000人的技术研发招聘计划,在科技圈里引发了不小的讨论。很多人乍一看,觉得这又是…...
)
别再只用Leaflet了!Mapbox GL JS加载本地MVT矢量瓦片保姆级教程(附避坑点)
从Leaflet到Mapbox GL JS:解锁MVT矢量瓦片的进阶玩法 当传统WebGIS开发者第一次看到Mapbox GL JS渲染的矢量瓦片地图时,那种震撼感不亚于从黑白电视切换到4K HDR。Leaflet就像一把可靠的瑞士军刀,而Mapbox GL JS则像一套专业厨房设备——当你…...

双核Delfino架构解析:如何解决复杂实时控制系统的性能瓶颈
1. 项目概述:从“双核”到“创新架构”的深度解构最近在和一些做工业控制、新能源以及高端医疗器械的朋友交流时,发现一个词被反复提及,那就是“双核Delfino”。乍一听,这像是一个具体的芯片型号,但深入聊下去…...

5分钟搭建拼多多数据采集系统:零基础也能掌握的电商数据分析利器
5分钟搭建拼多多数据采集系统:零基础也能掌握的电商数据分析利器 【免费下载链接】scrapy-pinduoduo 拼多多爬虫,抓取拼多多热销商品信息和评论 项目地址: https://gitcode.com/gh_mirrors/sc/scrapy-pinduoduo 想要了解拼多多平台的热销商品趋势…...

【亲测免费】 GeoMatch_src:基于边缘的模板匹配技术
GeoMatch_src:基于边缘的模板匹配技术 【下载地址】GeoMatch_srcVS2015OpenCV3.3版说明文档 本仓库提供了**GeoMatch_src**项目的更新版本,专为使用Visual Studio 2015和OpenCV 3.3环境的开发者设计。GeoMatch_src是一个基于边缘的模板匹配技术实现&…...