Quartz框架详解分析
文章目录
- 1 Quartz框架
- 1.1 入门demo
- 1.2 Job 讲解
- 1.2.1 Job简介
- 1.2.2 Job 并发
- 1.2.3 Job 异常
- 1.2.4 Job 中断
- 1.3 Trigger 触发器
- 1.3.1 SimpleTrigger
- 1.3.2 CornTrigger
- 1.4 Listener监听器
- 1.5 Jdbc store
- 1.5.1 简介
- 1.5.2 添加pom依赖
- 1.5.3 建表SQL
- 1.5.4 配置文件quartz.properties
- 1.5.5 Demo实践
- 1.6 quartz集群
- 1.6.1 简介
- 1.6.2 配置文件quartz.properties
1 Quartz框架
本例quartz使用版本为
<dependency><groupId>org.quartz-scheduler</groupId><artifactId>quartz</artifactId><version>2.3.2</version>
</dependency>
点击了解Quartz框架基本知识
1.1 入门demo
几个概念搞清楚先:
触发器 Trigger: 什么时候工作
任务 Job: 做什么工作
调度器 Scheduler: 搭配 Trigger和Job
Job类
import org.quartz.Job;
import org.quartz.JobDetail;
import org.quartz.JobExecutionContext;
import org.quartz.JobExecutionException;import java.text.SimpleDateFormat;
import java.util.Date;
public class MyJob implements Job {@Overridepublic void execute(JobExecutionContext context) throws JobExecutionException {JobDetail jobDetail = context.getJobDetail();String email = jobDetail.getJobDataMap().getString("email");SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS");String now = sdf.format(new Date());System.out.printf("向邮件 %s,发送了一封定时邮件,时间: %s %n",email,now);}
}
调用
import org.quartz.*;
import org.quartz.impl.StdSchedulerFactory;import java.text.SimpleDateFormat;
import java.util.Date;
public class TestQuartz {public static void main(String[] args) throws Exception {//创建调度器Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler();//创建触发器Trigger trigger = TriggerBuilder.newTrigger().withIdentity("tri_001","tri_group_001")//定义名称和所属的组// 根据为触发器配置的时间表,将触发器启动的时间设置为当前时刻(触发器此时可能会触发,也可能不会触发).startAt().withSchedule(SimpleScheduleBuilder.simpleSchedule().withIntervalInSeconds(2) //每隔两秒.withRepeatCount(2) //总共执行3次(第一次执行不基数)).build();//定义一个jobJobDetail job = JobBuilder.newJob(MyJob.class) //指定干活的类MailJob.withIdentity("job_001","job_group_001")//定义任务名称和分组.usingJobData("email","test@test.com")//定义属性.build();//使用jobDateMapjob.getJobDataMap().put("email","admin@test.com");//调度假如这个jobDate date = scheduler.scheduleJob(job, trigger);SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS");System.out.printf("定时器开始时间:%s %n",sdf.format(date));//启动scheduler.start();Thread.sleep(20000);scheduler.shutdown(true);}
}
1.2 Job 讲解
1.2.1 Job简介
job一般需要实现org.quartz.Job的接口,Job 其实是由 3 个部分组成:
JobDetail:用于描述这个Job是做什么的- 实现Job的类:具体干活的
JobDataMap:给 Job 提供参数用的
这是除了usingJobData方式之外,还可以是其他方式,像这样
job.getJobDataMap().put("email", "test@test.com");
1.2.2 Job 并发
默认的情况下,无论上一次任务是否结束或者完成,只要规定的时间到了,那么下一次就开始。
有时候会做长时间的任务,比如数据库备份,这个时候就希望上一次备份成功结束之后,才开始下一次备份,即便是规定时间到了,也不能开始,因为这样很有可能造成数据库被锁死 (几个线程同时备份数据库,引发无法预计的混乱)。
那么在这种情况下,给数据库备份任务增加一个注解就好了:@DisallowConcurrentExecution
job类
import cn.hutool.core.date.DateUtil;
import lombok.SneakyThrows;
import org.quartz.*;@DisallowConcurrentExecution
public class DatabaseBackupJob implements Job {@SneakyThrows@Overridepublic void execute(JobExecutionContext context) throws JobExecutionException {JobDetail detail = context.getJobDetail();String database = detail.getJobDataMap().getString("database");System.out.printf("给数据库 %s 备份,耗时10s,当前时间 %s %n",database, DateUtil.now());Thread.sleep(3000);}
}
调用类
import org.quartz.*;
import org.quartz.impl.StdSchedulerFactory;import java.text.SimpleDateFormat;
import java.util.Date;public class TestQuartz {public static void main(String[] args) throws Exception{Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler();//创建触发器Trigger trigger = TriggerBuilder.newTrigger().withIdentity("tri_001","tri_group_001")// 根据为触发器配置的时间表,将触发器启动的时间设置为当前时刻(触发器此时可能会触发,也可能不会触发).startNow().withSchedule(SimpleScheduleBuilder.simpleSchedule().withIntervalInSeconds(2) //每隔两秒.withRepeatCount(3) //重复).build();//定义一个jobJobDetail job = JobBuilder.newJob(DatabaseBackupJob.class).withIdentity("job_002","job_group_002").usingJobData("database","mysql").build();//调度假如这个jobDate date = scheduler.scheduleJob(job, trigger);SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS");System.out.printf("数据库定时器开始时间:%s %n",sdf.format(date));//启动scheduler.start();Thread.sleep(20000);scheduler.shutdown(true);}
}
1.2.3 Job 异常
任务里发生异常是很常见的。 异常处理办法通常是两种:
- 当异常发生,那么就通知所有管理这个
Job的调度,停止运行它 - 当异常发生,修改一下参数,马上重新运行
异常一:
import org.quartz.Job;
import org.quartz.JobExecutionContext;
import org.quartz.JobExecutionException;public class ExceptionJob1 implements Job {@Overridepublic void execute(JobExecutionContext context) throws JobExecutionException {int i=0;try{System.out.println(1/i);}catch (Exception e){System.out.println("发生了异常,取消了这个job对应的所有的调度");JobExecutionException je = new JobExecutionException(e);je.setUnscheduleAllTriggers(true);throw je;}}
}
异常二:
import org.quartz.Job;
import org.quartz.JobExecutionContext;
import org.quartz.JobExecutionException;public class ExceptionJob2 implements Job {static int i=0;@Overridepublic void execute(JobExecutionContext jobExecutionContext) throws JobExecutionException {try{System.out.println("运算结果:"+1/i);}catch (Exception e){System.out.println("发生了异常,修改下参数,立即重新执行");i=1;JobExecutionException je = new JobExecutionException(e);je.setRefireImmediately(true);throw je;}}
}
调度类,只是改下job中的异常类一或者二即可
import org.quartz.*;
import org.quartz.impl.StdSchedulerFactory;import java.text.SimpleDateFormat;
import java.util.Date;public class TestQuartz {public static void main(String[] args) throws Exception{exceptionJob1();}private static void exceptionJob1() throws Exception{Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler();//创建触发器Trigger trigger = TriggerBuilder.newTrigger().withIdentity("tri_001","tri_group_001").startNow().withSchedule(SimpleScheduleBuilder.simpleSchedule().withIntervalInSeconds(2) //每隔两秒.withRepeatCount(3) //重复).build();//定义一个jobJobDetail job = JobBuilder.newJob(ExceptionJob1.class).withIdentity("exceptionJob1","exception_group").build();//调度假如这个jobDate date = scheduler.scheduleJob(job, trigger);SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS");System.out.printf("数据库定时器开始时间:%s %n",sdf.format(date));//启动scheduler.start();Thread.sleep(20000);scheduler.shutdown(true);}
1.2.4 Job 中断
业务上,有时候需要中断任务,那么这个Job 需要实现 InterruptableJob 接口而不是 Job 接口,然后就方便中断了
import org.quartz.InterruptableJob;
import org.quartz.JobExecutionContext;
import org.quartz.JobExecutionException;
import org.quartz.UnableToInterruptJobException;public class StoppableJob implements InterruptableJob {private boolean stop = false;@Overridepublic void interrupt() throws UnableToInterruptJobException {System.out.println("被调度叫停");stop=true;}@Overridepublic synchronized void execute(JobExecutionContext jobExecutionContext) throws JobExecutionException {while (true){if(stop)break;try {System.out.println("每隔一秒,进行一次检测,看看是否停止");Thread.sleep(1000);}catch (InterruptedException e){e.printStackTrace();}System.out.println("持续工作中。。。。");}}
}
调度类
public class TestQuartz {public static void main(String[] args) throws Exception{stop();}private static void stop() throws Exception{Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler();//创建触发器Trigger trigger = TriggerBuilder.newTrigger().withIdentity("tri_001","tri_group_001")// 根据为触发器配置的时间表,将触发器启动的时间设置为当前时刻(触发器此时可能会触发,也可能不会触发).startNow().build();//定义一个jobJobDetail job = JobBuilder.newJob(StoppableJob.class).withIdentity("stop_job","stop_job_group").build();//调度假如这个jobDate date = scheduler.scheduleJob(job, trigger);SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS");System.out.printf("数据库定时器开始时间:%s %n",sdf.format(date));//启动scheduler.start();Thread.sleep(5000);System.out.println("过5秒,调度停止job");scheduler.interrupt(job.getKey());Thread.sleep(20000);scheduler.shutdown(true);}
}
1.3 Trigger 触发器
1.3.1 SimpleTrigger
Trigger 就是触发器的意思,用来指定什么时间开始触发,触发多少次,每隔多久触发一次,SimpleTrigger 可以方便的实现一系列的触发机制。
Job类都差不多,重点是调用类差别
import org.quartz.*;
import org.quartz.impl.StdSchedulerFactory;import java.text.SimpleDateFormat;
import java.util.Date;public class TestQuartz {public static void main(String[] args) throws Exception {SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS");Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler();System.out.println("当前时间是:"+sdf.format(new Date()));//下一个8秒的倍数Date startTime = DateBuilder.nextGivenSecondDate(null, 8);//10 秒后运行
// startTime = DateBuilder.futureDate(10, DateBuilder.IntervalUnit.SECOND);//累计n次,间隔n秒System.out.println("延迟后的时间:"+sdf.format(startTime));JobDetail job = JobBuilder.newJob(MailJob.class).withIdentity("mailJob", "mailGroup").build();SimpleTrigger trigger = (SimpleTrigger) TriggerBuilder.newTrigger().withIdentity("trigger_simple","trigger_simple_group")
// .startNow().startAt(startTime).withSchedule(SimpleScheduleBuilder.simpleSchedule().withRepeatCount(2)// .repeatForever() //永远运行下去.withIntervalInSeconds(1)).build();Date date = scheduler.scheduleJob(job, trigger);System.out.println("当前时间是:"+sdf.format(new Date()));System.out.printf("%s 这个任务会在 %s 准时开始运行,累计运行 %d 次,间隔时间是 %d 毫秒 %n",job.getKey(),sdf.format(date),trigger.getRepeatCount()+1,trigger.getRepeatInterval());scheduler.start();Thread.sleep(20000);scheduler.shutdown(true);}
}
1.3.2 CornTrigger
Cron 是 Linux下的一个定时器,功能很强大,但是表达式更为复杂
CronTrigger 就是用 Cron 表达式来安排触发时间和次数的。
点击了解Corn表达式
import cn.quartz.simple.MailJob;
import org.quartz.*;
import org.quartz.impl.StdSchedulerFactory;import java.util.Date;public class TestQuartz {public static void main(String[] args) throws Exception {Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler();Date startTime = DateBuilder.nextGivenSecondDate(null, 8);JobDetail job = JobBuilder.newJob(MailJob.class).withIdentity("mailJob", "mailGroup").build();CronTrigger trigger = TriggerBuilder.newTrigger().withIdentity("trigger1", "group1").withSchedule(CronScheduleBuilder.cronSchedule("0/2 * * * * ?")).build();// schedule it to run!scheduler.scheduleJob(job, trigger);System.out.println("使用的Cron表达式是:"+trigger.getCronExpression());
// System.out.printf("%s 这个任务会在 %s 准时开始运行,累计运行%d次,间隔时间是%d毫秒%n", job.getKey(), ft.toLocaleString(), trigger.getRepeatCount()+1, trigger.getRepeatInterval());scheduler.start();//等待20秒,让前面的任务都执行完了之后,再关闭调度器Thread.sleep(10000);scheduler.shutdown(true);}
}
1.4 Listener监听器
Quartz 的监听器有Job监听器,Trigger监听器, Scheduler监听器,对不同层面进行监控。 实际业务用的较多的是 Job监听器,用于监听器是否执行了,其他的用的相对较少,主要讲解Job的
MailJobListener 实现了 JobListener 接口,就必须实现如图所示的4个方法
| 方法 | 说明 |
|---|---|
| getName() | getName() 方法返回一个字符串用以说明JobListener的名称,对于注册为全局的监听器,getName()主要用于记录日志,对于由特定Job引用的JobListener,注册再JobDetail上的监听器名称必须匹配从监听器上 getName() 方法的返回值 |
| jobToBeExecuted() | Scheduler在JobDetail将要被执行时调用这个方法 |
| jobExecutionVetoed() | Scheduler在JobDetail即将被执行,但又被TriggerListener否决了时调用这个方法 |
| jobWasExecuted() | Scheduler在JobDetail 被执行之后调用这个方法 |
package cn.quartz.listen;import org.quartz.JobExecutionContext;
import org.quartz.JobExecutionException;
import org.quartz.JobListener;public class MailJobListener implements JobListener {@Overridepublic String getName() {return "listener of mail job";}@Overridepublic void jobToBeExecuted(JobExecutionContext jobExecutionContext) {System.out.println("准备执行: \t"+jobExecutionContext.getJobDetail().getKey());}@Overridepublic void jobExecutionVetoed(JobExecutionContext jobExecutionContext) {System.out.println("取消执行: \t"+jobExecutionContext.getJobDetail().getKey());}@Overridepublic void jobWasExecuted(JobExecutionContext jobExecutionContext, JobExecutionException e) {System.out.println("执行结束: \t"+jobExecutionContext.getJobDetail().getKey());}
}调度类
package cn.quartz.listen;import cn.hutool.json.JSONUtil;
import cn.quartz.simple.MailJob;
import org.quartz.*;
import org.quartz.impl.StdSchedulerFactory;
import org.quartz.impl.matchers.KeyMatcher;import java.util.Date;public class TestQuartz {public static void main(String[] args) throws Exception {Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler();Date startTime = DateBuilder.nextGivenSecondDate(null, 8);JobDetail job = JobBuilder.newJob(MailJob.class).withIdentity("mailJob", "mailGroup").build();Trigger trigger = TriggerBuilder.newTrigger().withIdentity("trigger1", "group1").startNow().withSchedule(SimpleScheduleBuilder.simpleSchedule().withRepeatCount(2).withIntervalInSeconds(1)).build();//增加监听器MailJobListener listener = new MailJobListener();KeyMatcher<JobKey> keyMatcher = KeyMatcher.keyEquals(job.getKey());System.out.println("获取到的 keymatcher :" + JSONUtil.toJsonStr(keyMatcher));scheduler.getListenerManager().addJobListener(listener,keyMatcher);// schedule it to run!scheduler.scheduleJob(job, trigger);scheduler.start();//等待20秒,让前面的任务都执行完了之后,再关闭调度器Thread.sleep(10000);scheduler.shutdown(true);}
}1.5 Jdbc store
1.5.1 简介
默认情况,Quartz 的触发器,调度,任务等信息都是放在内存中的,叫做 RAMJobStore。 好处是快速,坏处是一旦系统重启,那么信息就丢失了,就得全部从头来过。
所以Quartz还提供了另一个方式,可以把这些信息存放在数据库做,叫做 JobStoreTX。 好处是就算系统重启了,目前运行到第几次了这些信息都是存放在数据库中的,那么就可以继续原来的步伐把计划任务无缝地继续做下去。 坏处就是性能上比内存慢一些,毕竟数据库读取总是要慢一些的
1.5.2 添加pom依赖
用的是mysql和C3P0连接池,就需要添加这两个的依赖
<dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.27</version></dependency><dependency><groupId>com.mchange</groupId><artifactId>c3p0</artifactId><version>0.9.5.2</version></dependency>
1.5.3 建表SQL
| 表名 | 描述 |
|---|---|
| QRTZ_CALENDARS | 存储Quartz的日历信息 |
| QRTZ_CRON_TRIGGERS | 存储cron类型的Trigger 包括cron表达式和时区信息 |
| QRTZ_FIRED_TRIGGERS | 存储与已触发的Trigger相关的状态信息以及相关联的Job的执行信息 |
| QRTZ_PAUSED_TRIGGER_GRPS | 存储已暂停的Trigger组的信息 |
| QRTZ_SCHEDULER_STATE | 存储Scheduler相关的状态信息 |
| QRTZ_LOCKS | 如果程序使用了悲观锁,则存储程序的悲观锁信息 |
| QRTZ_JOB_DETAILS | 存储每一个已经配置的JobDetail信息 |
| QRTZ_SIMPLE_TRIGGERS | 存储Simple类型的Trigger,包括重复次数,间隔以及已经触发的次数 |
| QRTZ_BLOG_TRIGGERS | 存储Blog类型的Trigger |
| QRTZ_TRIGGERS | 存储已经配置的Trigger的基本信息 |
| QRTZ_TRIGGER_LISTENERS | 存储Trigger监听器的信息 |
| QRTZ_JOB_LISTENERS | 存储Job监听器信息 |
其文件在quartz-scheduler下的org/quartz/impl/jdbcjobstore/tables_mysql_innodb.sql
DROP TABLE IF EXISTS QRTZ_FIRED_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_PAUSED_TRIGGER_GRPS;
DROP TABLE IF EXISTS QRTZ_SCHEDULER_STATE;
DROP TABLE IF EXISTS QRTZ_LOCKS;
DROP TABLE IF EXISTS QRTZ_SIMPLE_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_SIMPROP_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_CRON_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_BLOB_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_JOB_DETAILS;
DROP TABLE IF EXISTS QRTZ_CALENDARS;CREATE TABLE QRTZ_JOB_DETAILS(
SCHED_NAME VARCHAR(120) NOT NULL,
JOB_NAME VARCHAR(190) NOT NULL,
JOB_GROUP VARCHAR(190) NOT NULL,
DESCRIPTION VARCHAR(250) NULL,
JOB_CLASS_NAME VARCHAR(250) NOT NULL,
IS_DURABLE VARCHAR(1) NOT NULL,
IS_NONCONCURRENT VARCHAR(1) NOT NULL,
IS_UPDATE_DATA VARCHAR(1) NOT NULL,
REQUESTS_RECOVERY VARCHAR(1) NOT NULL,
JOB_DATA BLOB NULL,
PRIMARY KEY (SCHED_NAME,JOB_NAME,JOB_GROUP))
ENGINE=InnoDB;CREATE TABLE QRTZ_TRIGGERS (
SCHED_NAME VARCHAR(120) NOT NULL,
TRIGGER_NAME VARCHAR(190) NOT NULL,
TRIGGER_GROUP VARCHAR(190) NOT NULL,
JOB_NAME VARCHAR(190) NOT NULL,
JOB_GROUP VARCHAR(190) NOT NULL,
DESCRIPTION VARCHAR(250) NULL,
NEXT_FIRE_TIME BIGINT(13) NULL,
PREV_FIRE_TIME BIGINT(13) NULL,
PRIORITY INTEGER NULL,
TRIGGER_STATE VARCHAR(16) NOT NULL,
TRIGGER_TYPE VARCHAR(8) NOT NULL,
START_TIME BIGINT(13) NOT NULL,
END_TIME BIGINT(13) NULL,
CALENDAR_NAME VARCHAR(190) NULL,
MISFIRE_INSTR SMALLINT(2) NULL,
JOB_DATA BLOB NULL,
PRIMARY KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP),
FOREIGN KEY (SCHED_NAME,JOB_NAME,JOB_GROUP)
REFERENCES QRTZ_JOB_DETAILS(SCHED_NAME,JOB_NAME,JOB_GROUP))
ENGINE=InnoDB;CREATE TABLE QRTZ_SIMPLE_TRIGGERS (
SCHED_NAME VARCHAR(120) NOT NULL,
TRIGGER_NAME VARCHAR(190) NOT NULL,
TRIGGER_GROUP VARCHAR(190) NOT NULL,
REPEAT_COUNT BIGINT(7) NOT NULL,
REPEAT_INTERVAL BIGINT(12) NOT NULL,
TIMES_TRIGGERED BIGINT(10) NOT NULL,
PRIMARY KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP),
FOREIGN KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)
REFERENCES QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP))
ENGINE=InnoDB;CREATE TABLE QRTZ_CRON_TRIGGERS (
SCHED_NAME VARCHAR(120) NOT NULL,
TRIGGER_NAME VARCHAR(190) NOT NULL,
TRIGGER_GROUP VARCHAR(190) NOT NULL,
CRON_EXPRESSION VARCHAR(120) NOT NULL,
TIME_ZONE_ID VARCHAR(80),
PRIMARY KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP),
FOREIGN KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)
REFERENCES QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP))
ENGINE=InnoDB;CREATE TABLE QRTZ_SIMPROP_TRIGGERS(SCHED_NAME VARCHAR(120) NOT NULL,TRIGGER_NAME VARCHAR(190) NOT NULL,TRIGGER_GROUP VARCHAR(190) NOT NULL,STR_PROP_1 VARCHAR(512) NULL,STR_PROP_2 VARCHAR(512) NULL,STR_PROP_3 VARCHAR(512) NULL,INT_PROP_1 INT NULL,INT_PROP_2 INT NULL,LONG_PROP_1 BIGINT NULL,LONG_PROP_2 BIGINT NULL,DEC_PROP_1 NUMERIC(13,4) NULL,DEC_PROP_2 NUMERIC(13,4) NULL,BOOL_PROP_1 VARCHAR(1) NULL,BOOL_PROP_2 VARCHAR(1) NULL,PRIMARY KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP),FOREIGN KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)REFERENCES QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP))
ENGINE=InnoDB;CREATE TABLE QRTZ_BLOB_TRIGGERS (
SCHED_NAME VARCHAR(120) NOT NULL,
TRIGGER_NAME VARCHAR(190) NOT NULL,
TRIGGER_GROUP VARCHAR(190) NOT NULL,
BLOB_DATA BLOB NULL,
PRIMARY KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP),
INDEX (SCHED_NAME,TRIGGER_NAME, TRIGGER_GROUP),
FOREIGN KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)
REFERENCES QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP))
ENGINE=InnoDB;CREATE TABLE QRTZ_CALENDARS (
SCHED_NAME VARCHAR(120) NOT NULL,
CALENDAR_NAME VARCHAR(190) NOT NULL,
CALENDAR BLOB NOT NULL,
PRIMARY KEY (SCHED_NAME,CALENDAR_NAME))
ENGINE=InnoDB;CREATE TABLE QRTZ_PAUSED_TRIGGER_GRPS (
SCHED_NAME VARCHAR(120) NOT NULL,
TRIGGER_GROUP VARCHAR(190) NOT NULL,
PRIMARY KEY (SCHED_NAME,TRIGGER_GROUP))
ENGINE=InnoDB;CREATE TABLE QRTZ_FIRED_TRIGGERS (
SCHED_NAME VARCHAR(120) NOT NULL,
ENTRY_ID VARCHAR(95) NOT NULL,
TRIGGER_NAME VARCHAR(190) NOT NULL,
TRIGGER_GROUP VARCHAR(190) NOT NULL,
INSTANCE_NAME VARCHAR(190) NOT NULL,
FIRED_TIME BIGINT(13) NOT NULL,
SCHED_TIME BIGINT(13) NOT NULL,
PRIORITY INTEGER NOT NULL,
STATE VARCHAR(16) NOT NULL,
JOB_NAME VARCHAR(190) NULL,
JOB_GROUP VARCHAR(190) NULL,
IS_NONCONCURRENT VARCHAR(1) NULL,
REQUESTS_RECOVERY VARCHAR(1) NULL,
PRIMARY KEY (SCHED_NAME,ENTRY_ID))
ENGINE=InnoDB;CREATE TABLE QRTZ_SCHEDULER_STATE (
SCHED_NAME VARCHAR(120) NOT NULL,
INSTANCE_NAME VARCHAR(190) NOT NULL,
LAST_CHECKIN_TIME BIGINT(13) NOT NULL,
CHECKIN_INTERVAL BIGINT(13) NOT NULL,
PRIMARY KEY (SCHED_NAME,INSTANCE_NAME))
ENGINE=InnoDB;CREATE TABLE QRTZ_LOCKS (
SCHED_NAME VARCHAR(120) NOT NULL,
LOCK_NAME VARCHAR(40) NOT NULL,
PRIMARY KEY (SCHED_NAME,LOCK_NAME))
ENGINE=InnoDB;CREATE INDEX IDX_QRTZ_J_REQ_RECOVERY ON QRTZ_JOB_DETAILS(SCHED_NAME,REQUESTS_RECOVERY);
CREATE INDEX IDX_QRTZ_J_GRP ON QRTZ_JOB_DETAILS(SCHED_NAME,JOB_GROUP);CREATE INDEX IDX_QRTZ_T_J ON QRTZ_TRIGGERS(SCHED_NAME,JOB_NAME,JOB_GROUP);
CREATE INDEX IDX_QRTZ_T_JG ON QRTZ_TRIGGERS(SCHED_NAME,JOB_GROUP);
CREATE INDEX IDX_QRTZ_T_C ON QRTZ_TRIGGERS(SCHED_NAME,CALENDAR_NAME);
CREATE INDEX IDX_QRTZ_T_G ON QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_GROUP);
CREATE INDEX IDX_QRTZ_T_STATE ON QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_STATE);
CREATE INDEX IDX_QRTZ_T_N_STATE ON QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP,TRIGGER_STATE);
CREATE INDEX IDX_QRTZ_T_N_G_STATE ON QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_GROUP,TRIGGER_STATE);
CREATE INDEX IDX_QRTZ_T_NEXT_FIRE_TIME ON QRTZ_TRIGGERS(SCHED_NAME,NEXT_FIRE_TIME);
CREATE INDEX IDX_QRTZ_T_NFT_ST ON QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_STATE,NEXT_FIRE_TIME);
CREATE INDEX IDX_QRTZ_T_NFT_MISFIRE ON QRTZ_TRIGGERS(SCHED_NAME,MISFIRE_INSTR,NEXT_FIRE_TIME);
CREATE INDEX IDX_QRTZ_T_NFT_ST_MISFIRE ON QRTZ_TRIGGERS(SCHED_NAME,MISFIRE_INSTR,NEXT_FIRE_TIME,TRIGGER_STATE);
CREATE INDEX IDX_QRTZ_T_NFT_ST_MISFIRE_GRP ON QRTZ_TRIGGERS(SCHED_NAME,MISFIRE_INSTR,NEXT_FIRE_TIME,TRIGGER_GROUP,TRIGGER_STATE);CREATE INDEX IDX_QRTZ_FT_TRIG_INST_NAME ON QRTZ_FIRED_TRIGGERS(SCHED_NAME,INSTANCE_NAME);
CREATE INDEX IDX_QRTZ_FT_INST_JOB_REQ_RCVRY ON QRTZ_FIRED_TRIGGERS(SCHED_NAME,INSTANCE_NAME,REQUESTS_RECOVERY);
CREATE INDEX IDX_QRTZ_FT_J_G ON QRTZ_FIRED_TRIGGERS(SCHED_NAME,JOB_NAME,JOB_GROUP);
CREATE INDEX IDX_QRTZ_FT_JG ON QRTZ_FIRED_TRIGGERS(SCHED_NAME,JOB_GROUP);
CREATE INDEX IDX_QRTZ_FT_T_G ON QRTZ_FIRED_TRIGGERS(SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP);
CREATE INDEX IDX_QRTZ_FT_TG ON QRTZ_FIRED_TRIGGERS(SCHED_NAME,TRIGGER_GROUP);commit;1.5.4 配置文件quartz.properties
#调度标识名 集群中每一个实例都必须使用相同的名称 (区分特定的调度器实例)
org.quartz.scheduler.instanceName = MyScheduler
#ID设置为自动获取 每一个必须不同 (所有调度器实例中是唯一的)
org.quartz.scheduler.instanceId=AUTO#数据保存方式为持久化
org.quartz.jobStore.class = org.quartz.impl.jdbcjobstore.JobStoreTX
org.quartz.jobStore.driverDelegateClass = org.quartz.impl.jdbcjobstore.StdJDBCDelegate
#表的前缀
org.quartz.jobStore.tablePrefix = 12QRTZ_
#数据库别名
org.quartz.jobStore.dataSource = mysqlDatabase
#加入集群 true 为集群 false不是集群
org.quartz.jobStore.isClustered = falseorg.quartz.threadPool.threadCount = 3
org.quartz.threadPool.class = org.quartz.simpl.SimpleThreadPool#设置数据源
org.quartz.dataSource.mysqlDatabase.driver = com.mysql.jdbc.Driver
org.quartz.dataSource.mysqlDatabase.URL = jdbc:mysql://localhost:3306/quartz?characterEncoding=utf-8
org.quartz.dataSource.mysqlDatabase.user =root
org.quartz.dataSource.mysqlDatabase.password = root
org.quartz.dataSource.mysqlDatabase.maxConnections = 5
1.5.5 Demo实践
package cn.quartz.jdbc;import org.quartz.*;import java.text.SimpleDateFormat;
import java.util.Date;@DisallowConcurrentExecution
public class MailJob implements Job {@Overridepublic void execute(JobExecutionContext context) throws JobExecutionException {JobDetail detail = context.getJobDetail();String email = detail.getJobDataMap().getString("email");SimpleDateFormat sdf = new SimpleDateFormat("HH:mm:ss");String now = sdf.format(new Date());System.out.printf("给邮件地址 %s 发出了一封定时邮件, 当前时间是: %s (%s)%n" ,email, now,context.isRecovering());}
}
package cn.quartz.jdbc;import cn.hutool.json.JSONUtil;
import cn.quartz.listen.MailJobListener;import org.quartz.*;
import org.quartz.impl.StdSchedulerFactory;
import org.quartz.impl.matchers.KeyMatcher;import java.util.Date;public class TestQuartz {public static void main(String[] args) throws Exception{try {assginNewJob();} catch (ObjectAlreadyExistsException e) {System.err.println("任务已经存在");resumeJobFromDatabase();}}private static void resumeJobFromDatabase() throws Exception {Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler();scheduler.start();// 等待200秒,让前面的任务都执行完了之后,再关闭调度器Thread.sleep(20000);scheduler.shutdown(true);}private static void assginNewJob() throws SchedulerException, InterruptedException {// 创建调度器Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler();// 定义一个触发器Trigger trigger = TriggerBuilder.newTrigger().withIdentity("trigger1", "group1") // 定义名称和所属的租.startNow().withSchedule(SimpleScheduleBuilder.simpleSchedule().withIntervalInSeconds(1) // 每隔15秒执行一次.withRepeatCount(2)) // 总共执行11次(第一次执行不基数).build();// 定义一个JobDetailJobDetail job = JobBuilder.newJob(MailJob.class) // 指定干活的类MailJob.withIdentity("mailjob1", "mailgroup") // 定义任务名称和分组.usingJobData("email", "admin@10086.com") // 定义属性.build();// 调度加入这个jobscheduler.scheduleJob(job, trigger);// 启动scheduler.start();// 等待2秒,让前面的任务都执行完了之后,再关闭调度器Thread.sleep(20000);scheduler.shutdown(true);}
}
1.6 quartz集群
1.6.1 简介
Quartz集群,是指在 基于数据库存储 Quartz调度信息 的基础上, 有多个一模一样的 Quartz 应用在运行。
当某一个Quartz 应用重启或者发生问题的时候, 其他的 Quartz 应用会借助数据库这个桥梁探知到它不行了,从而接手把该进行的 Job 调度工作进行下去。
以这种方式保证任务调度的高可用性,即在发生异常重启等情况下,调度信息依然连贯性地进行下去,就好像 Quartz 应用从来没有中断过似的。

1.6.2 配置文件quartz.properties
#调度标识名 集群中每一个实例都必须使用相同的名称 (区分特定的调度器实例)
org.quartz.scheduler.instanceName = MyScheduler
#ID设置为自动获取 每一个必须不同 (所有调度器实例中是唯一的)
#要进行集群,多个应用调度id instanceId 必须不一样,这里使用AUTO,就会自动分配不同的ID。 目测是本机机器名称加上时间戳
org.quartz.scheduler.instanceId=AUTO#数据保存方式为持久化
org.quartz.jobStore.class = org.quartz.impl.jdbcjobstore.JobStoreTX
org.quartz.jobStore.driverDelegateClass = org.quartz.impl.jdbcjobstore.StdJDBCDelegate
#表的前缀
org.quartz.jobStore.tablePrefix = 12QRTZ_
#数据库别名
org.quartz.jobStore.dataSource = mysqlDatabase
#加入集群 true 为集群 false不是集群
org.quartz.jobStore.isClustered = true
#每个一秒钟去数据库检查一下,以在其他应用挂掉之后及时补上
org.quartz.jobStore.clusterCheckinInterval = 1000org.quartz.threadPool.threadCount = 3
org.quartz.threadPool.class = org.quartz.simpl.SimpleThreadPool#设置数据源
org.quartz.dataSource.mysqlDatabase.driver = com.mysql.jdbc.Driver
org.quartz.dataSource.mysqlDatabase.URL = jdbc:mysql://localhost:3306/quartz?characterEncoding=utf-8
org.quartz.dataSource.mysqlDatabase.user =root
org.quartz.dataSource.mysqlDatabase.password = root
org.quartz.dataSource.mysqlDatabase.maxConnections = 5
代码部分同jdbc store部分
相关文章:
Quartz框架详解分析
文章目录 1 Quartz框架1.1 入门demo1.2 Job 讲解1.2.1 Job简介1.2.2 Job 并发1.2.3 Job 异常1.2.4 Job 中断 1.3 Trigger 触发器1.3.1 SimpleTrigger1.3.2 CornTrigger 1.4 Listener监听器1.5 Jdbc store1.5.1 简介1.5.2 添加pom依赖1.5.3 建表SQL1.5.4 配置文件quartz.propert…...
Nginx专题-基于多网卡的主机配置
文章目录 Nginx 基于多网卡的主机实现一、虚拟机前置环境准备ifcfg-ens32配置文件的内容参考ifcfg-ens33配置文件的内容 二、案例演示修改nginx.conf配置文件解决中文乱码 Nginx 基于多网卡的主机实现 一、虚拟机前置环境准备 点击虚拟机右下角的 红色标框按钮,然后…...

4.2和4.3、MAC地址、IP地址、端口
计算机网络等相关知识可以去小林coding进行巩固(点击前往) 4.2和4.3、MAC地址、IP地址、端口 1.MAC地址的简介2.IP地址①IP地址简介②IP地址编址方式③A类IP地址④B类IP地址⑤C类IP地址⑥D类IP地址⑧子网掩码 3.端口①简介②端口类型 1.MAC地址的简介 …...

放弃 console.log 吧!用 Debugger 你能读懂各种源码
很多同学不知道为什么要用 debugger 来调试,console.log 不行么? 还有,会用 debugger 了,还是有很多代码看不懂,如何调试复杂源码呢? 这篇文章就来讲一下为什么要用这些调试工具: console.lo…...

epoll机制解析
一、epoll实现原理 1、实现原理 epoll通过3个方法来实现对句柄的监控操作,要深刻理解epoll,首先得了解epoll的三大关键要素:mmap、红黑树、链表。下面是epoll的框架图,如下: mmap epoll是通过内核与用户空间mmap同一块…...
基于 SpringBoot + Vue 实现的可视化拖拽编辑的大屏项目
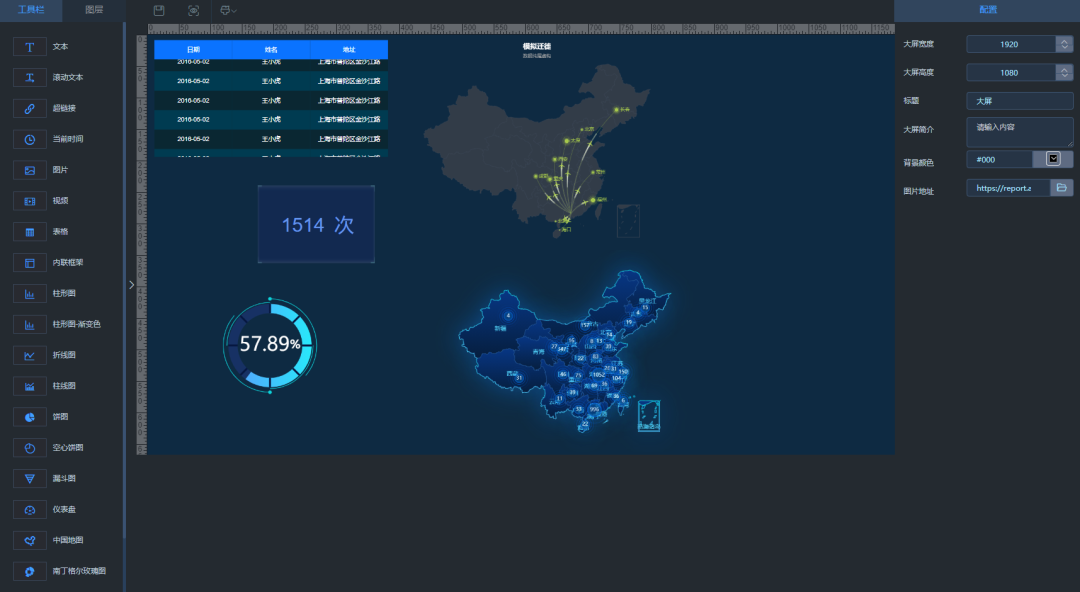
今天给小伙伴们分享一个基于 SpringBoot Vue 实现的可视化拖拽编辑的大屏项目; 一、简介 这个是一个开源的一个BI平台,酷炫大屏展示,能随时随地掌控业务动态,让每个决策都有数据支撑。 多数据源支持,内置mysql、el…...

我们为什么要写作?
为什么要写书是一个很难回答的问题,因为从不同的角度,会有不同的答案。 最近ChatGPT很火!诸事不决,先问问ChatGPT,看看它是怎么回答的。 ChatGPT给出的答案还是比较全,虽然没有“一本正经的胡说八道”&…...

设计模式:创建者模式 - 建造者模式
文章目录 1.概述2.结构3.实例4.优缺点5.使用场景6.模式扩展 1.概述 将一个复杂对象的构建与表示分离,使得同样的构建过程可以创建不同的表示。 分离了部件的构造(由Builder来负责)和装配(由Director负责)。 从而可以构造出复杂的对象。这个模式适用于:某…...
; 创建了几个对象?String a = “abc“; 呢?)
String a = new String(“abc“); 创建了几个对象?String a = “abc“; 呢?
String a new String(“abc”); 创建了几个对象?String a “abc”; 呢? 答案:String a new String(“abc”); 创建了1个或2个对象;String a “abc”; 创建了0个或1个都对象 String a new String(“abc”); 创建过程 首先在…...
keepalived+nginx安装
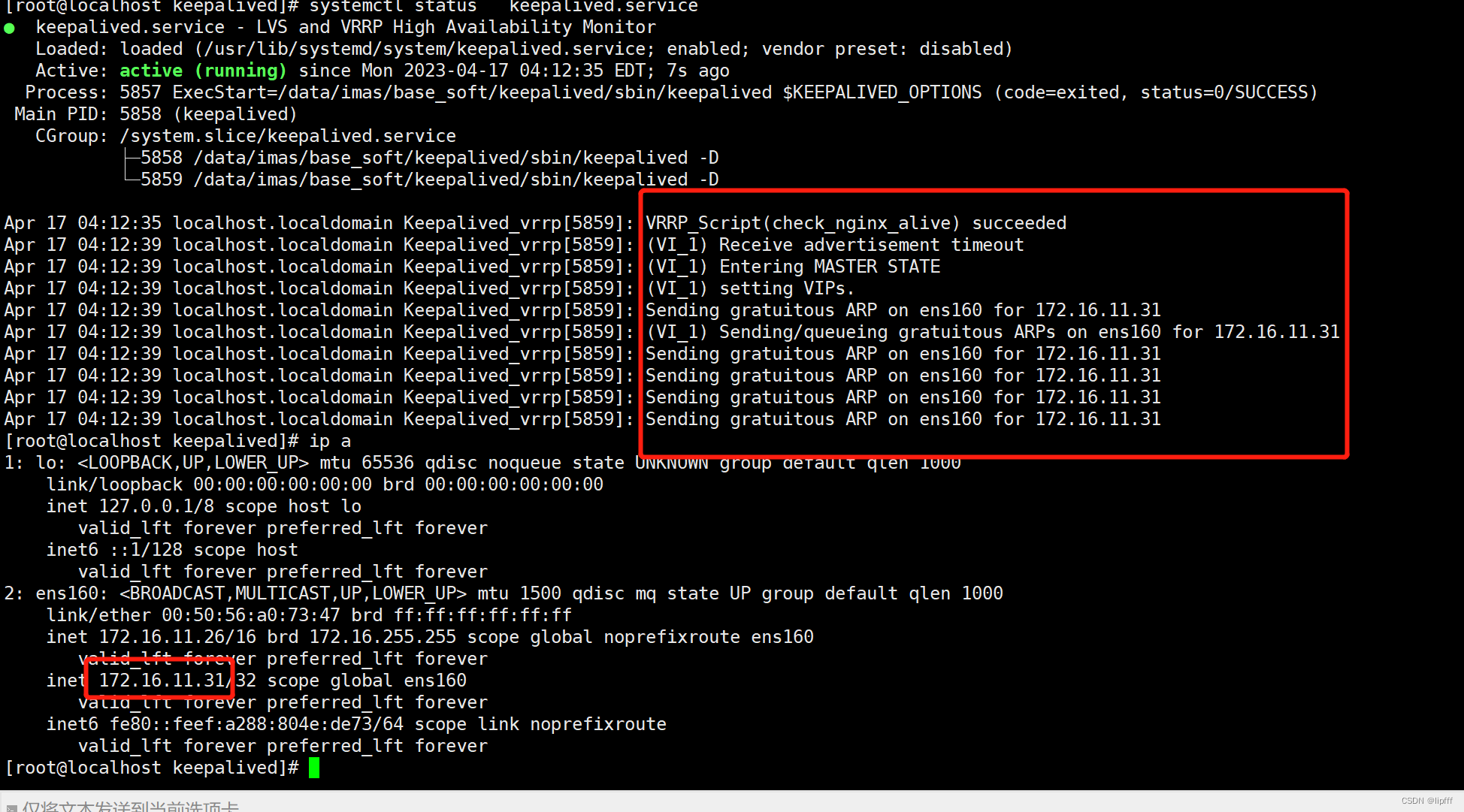
欢迎使用ShowDoc! 1、安装基础包: yum -y install libnl libnl-devel 2、上传包: tar -zxvf keepalived-2.0.20.tar.gz -C /data/imas/base_soft mkdir -p /data/imas/base_soft/keepalived cd /data/imas/base_soft/keepalived-2.0.20 .…...
硬盘格式化工具,强烈推荐这个!
案例:硬盘格式化工具推荐 【我的电脑已经用了好几年了,硬盘存储容量严重不够了,最近想把它格式化,但却不知道怎么操作,大家有什么比较好的硬盘格式化工具可以推荐吗?】 硬盘作为存储设备,我们…...

Python的异常捕获和处理
程序在运行过程当中,不可避免的会出现一些错误,比如:使用了没有赋值过的变量,使用了不存在的索引,一个数字除以0 …… 这些错误在程序中,我们称其为异常。 程序运行过程中,一旦出现异常将会导致…...
oracle学习之rownum和rowid
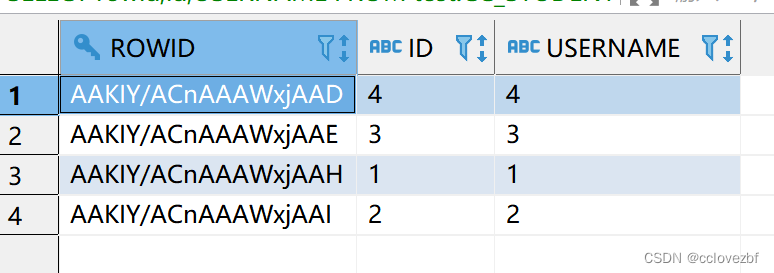
rownum先百度一波https://www.cnblogs.com/xfeiyun/p/16355165.html rownum是oracle特有的一个关键字。 对于基表,在insert记录时,oracle就按照insert的顺序,将rownum分配给每一行记录,因此在select一个基表的时候,r…...

为什么说过早优化是万恶之源?
Donald Knuth(高德纳)是一位计算机科学界的著名学者和计算机程序设计的先驱之一。他被誉为计算机科学的“圣经”《计算机程序设计艺术》的作者,提出了著名的“大O符号”来描述算法的时间复杂度和空间复杂度,开发了TeX系统用于排版…...

如何用 ModelScope 实现 “AI 换脸” 视频
前言 当下,视频内容火爆,带有争议性或反差大的换脸视频总能吸引人视线。虽然 AI 换脸在市面上已经流行了许久,相关制作工具或移动应用也是数不胜数。但是多数制作工具多数情况下不是会员就是收费,而且替换模板有限。以下在实战的角…...

怎么样成为一名Python工程师?到底要会哪些东西?你会了多少?
目录 重点:爬虫部分项目、源码展示python数据分析可视化大屏看板python爬虫爬取淘宝卤鸭货商品数据python游戏开发python自动化办公 重点: 1、做一名程序员,绝对要耐得住寂寞,并且要一直有点兴趣促进你学习。如果你完全没兴趣&am…...

项目前期1.0
今天是项目的第二天 昨天一顿迷茫,可恶 今天啥也不关先来点基本的构架 #include<queue>//队列 #define FALSE 0 #define TRUE 1 #define ERROR 0 #define OK 1 #define nocnect 999999//未链接的距离 #define maxplace 31//景区的观景点的最大个30数不要0下标的 #defi…...

MySQL语句执行耗时分析
MySQL语句执行耗时分析 MySQL Profile查看SQL执行各阶段耗时Performance Schema查看SQL执行各阶段耗时配置收集哪些用户的SQL执行信息开启SQL执行信息收集的相关特性执行目标SQL获取SQL执行的EVENT_ID获取SQL执行各阶段耗时 MySQL Profile查看SQL执行各阶段耗时 --开启SQL Pro…...

FVM链的Themis Pro(0x,f4) 5日IDO超百万美元,领Filecoin重回高点
交易一直是 DeFi 乃至web3领域最经久不衰的话题,也因此催生了众多优秀的去中心化协议,如 Uniswap 和 Curve。这些协议逐渐成为了整个系统的基石。 在永续合约方面,DYDX 的出现将 WEB2 时代的订单簿带回了web3。其链下交易的设计,仿…...

【PMP】优秀的项目经理如何做好范围管理?
范围管理是项目管理中的一个专用词汇,它的主要任务是界定项目包含且只包含所有需要完成的工作,并对项目其他管理工作起到指导作用,以保证顺利完成项目的所有过程。确定了项目范围,也就确定了项目的工作边界,明确了项目…...
RWKV:融合RNN与Transformer优势的高效语言模型架构解析与实践
1. 项目概述:一个“非Transformer”的现代语言模型 如果你最近在关注大语言模型(LLM)的开源生态,除了那些基于Transformer架构的“巨无霸”,可能还听说过一个名字有点特别的项目: RWKV 。这个由开发者Bli…...

GenAI云服务事故特征与高效缓解策略解析
1. GenAI云服务事故特征与挑战 在云服务运维领域,GenAI服务因其独特的架构特性呈现出明显区别于传统云服务的事故特征。根据微软云系统的大规模实证研究数据,GenAI事故的平均缓解时间(TTM)达到1.12个时间单位,比非GenA…...

为你的 AI Agent 项目选择并接入性价比更高的多模型服务
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为你的 AI Agent 项目选择并接入性价比更高的多模型服务 在构建 AI Agent 应用时,开发者常常面临一个两难选择…...

Context-Mode:基于React Context的模式化状态管理新范式
1. 项目概述:一个为现代前端开发量身定制的状态管理新范式 最近在重构一个中后台项目时,我又一次陷入了状态管理的泥潭。组件间层层传递的 props 像一团乱麻,全局 store 里塞满了各种不相关的数据,每次修改一个状态都得小心翼…...

基于ARM9核心板的工业双CAN网关开发实战:从硬件选型到软件架构
1. 项目概述与核心价值最近在做一个工业网关项目,客户要求设备必须支持双路CAN总线,用于同时连接现场的执行器和上位机监控系统。时间紧,任务重,自己从头设计硬件、画板、调试驱动,周期太长,风险也高。这时…...

Apex Legends压枪宏终极指南:轻松掌握自动武器检测与后坐力补偿技术
Apex Legends压枪宏终极指南:轻松掌握自动武器检测与后坐力补偿技术 【免费下载链接】Apex-NoRecoil-2021 Scripts to reduce recoil for Apex Legends. (auto weapon detection, support multiple resolutions) 项目地址: https://gitcode.com/gh_mirrors/ap/Ape…...

SoC芯片设计全流程解析:从架构定义到流片制造
1. 项目概述:从“黑盒子”到“城市蓝图”当我们谈论智能手机、智能手表、路由器乃至汽车里的智能座舱时,我们谈论的核心,往往是一个被称为“片上系统”或SoC的硅片。对于很多刚入行的朋友,甚至是一些有经验的软件工程师来说&#…...

自托管MCP服务器模板:快速构建AI智能体私有工具箱
1. 项目概述:一个为AI智能体赋能的“工具箱”模板最近在折腾AI智能体(Agent)开发的朋友,可能都听说过MCP(Model Context Protocol)这个概念。简单来说,MCP就像是为AI大模型准备的一套标准化的“…...
3分钟掌握Windows任务栏透明化:TranslucentTB完全手册
3分钟掌握Windows任务栏透明化:TranslucentTB完全手册 【免费下载链接】TranslucentTB A lightweight utility that makes the Windows taskbar translucent/transparent. 项目地址: https://gitcode.com/gh_mirrors/tr/TranslucentTB 你是否厌倦了Windows任…...

S32K324双核M7实战:如何利用192KB TCM提升关键代码性能
S32K324双核M7实战:如何利用192KB TCM提升关键代码性能 在嵌入式系统开发中,实时性往往是决定产品成败的关键因素。当您面对电机控制、信号处理等高实时性需求场景时,处理器与内存之间的数据通路可能成为性能瓶颈的隐形杀手。S32K324芯片内置…...