【李老师云计算】HBase+Zookeeper部署及Maven访问(HBase集群实验)
索引
- 前言
- 1. Zookeeper
- 1.1 主机下载Zookeeper安装包
- 1.2 主机解压Zookeeper
- 1.3 ★解决解压后文件缺失
- 1.4 主机配置Zookeeper文件
- 1.4.1 配置zoo_sample.cfg文件
- 1.4.2 配置/data/myid文件
- 1.5 主机传输Zookeeper文件到从机
- 1.6 从机修改Zookeeper文件
- 1.6.1 修改zoo.cfg文件
- 1.6.2 修改myid文件
- 1.7 设置环境变量
- 1.8 启动Zookeeper
- 1.9 ★解决无法启动Zookeeper
- 1.10 验证Zookeeper安装成功
- 1.11 ★解决找不到JAVA_HOME
- 2. HBase
- 2.1 主机下载HBase
- 2.2 主机解压HBase
- 2.3 主机配置HBase文件
- 2.3.1 hbase-env.sh文件
- 2.3.2 hbase-site.xml文件
- 2.3.3 regionservers文件
- 2.4 主机配置环境变量
- 2.5 主机最后的调整
- 2.5.1 ★解决错误:找不到或无法加载主类 org.apache.hadoop.hbase.util.GetJavaProperty
- 2.5.2 ★解决SLF4J:...
- 2.6 主机传输HBase文件到从机
- 2.7 主机启动HBase
- 2.8 Hbase Shell
- 2.9 终极HBase测试
- 2.10 ★遇到解决不了的问题
- 3.Maven访问HBase
- 3.1 主机下载Maven
- 3.2 主机解压Maven
- 3.3 配置环境变量
- 3.4 设置阿里云镜像
- 3.5 Maven项目
- 3.5.1 创建项目
- 3.5.2 如何编译项目
- 3.5.3 如何测试项目
- 3.5.4 如何打包项目
- 3.5.5 如何安装项目
- 3.6 Eclipse打开Maven项目
- 3.7 Maven访问HBase
- 3.8 ★解决代码爆红
- 3.9 ★虚拟机重启后需要进行的操作
- 4. HBase集群实验
- 4.1 实验代码
- 4.2 二班的修改
- 4.3 解释HBase的逻辑结构和物理结构
- 4.4 分析HBase的插入和MySQL的插入有何不同10分
前言
本篇博客内容大部分参考了涛哥的博客,在此基础上进行了整合、补充以及融合了我自己的操作,向学长表示敬意!
本次操作,为什么说是操作不是实验呢,因为这个不算课内的作业,而是必须要完成的额外任务,是在完成了【李老师云计算】实验一:Hadoop伪分布式集群部署与Eclipse访问Hadoop进行单词计数统计的前提下进行的。
后来又布置了一个新的实验也添加上了。
共分成四大部分,第一部分是Zookeeper的搭建,第二部分是HBase的搭建,第三部分是Maven访问,以及第四部分HBase集群实验。
带★的是可能遇到的问题可以看一下,以防后续操作出问题。
内容可能来自博主自己手搓、吸取同学的经验、网络上内容的整合等等,仅供参考,更多内容可以查看大三下速通指南专栏。
1. Zookeeper
ZooKeeper是一个分布式应用程序协调服务,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
1.1 主机下载Zookeeper安装包
Apache官方下载地址
我下载的版本是apache-zookeeper-3.7.1-bin.tar
1.2 主机解压Zookeeper
将下载好的文件放到Master节点下的/usr/local/目录下
在该目录下右键打开终端(确保路径是local)使用以下指令:
tar -zxvf apache-zookeeper-3.7.1-bin.tar.gz(根据自己下载的版本修改)

之后再继续使用以下指令:
mv apache-zookeeper-3.7.1-bin zookeeper来把目录的版本号去掉(方便之后的操作)
当然上面的操作也可以直接右键文件夹重命名为zookeeper。总之就是最终把解压出来的文件重命名为zookeeper即可。
1.3 ★解决解压后文件缺失
如果从桌面向虚拟机拖文件,可能压缩包没有完全的导入。
如果出现了下面的错误反而不会导入失败,只需要点击重试就可以了。
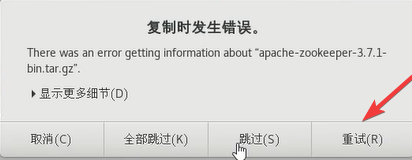
如果说压缩包的大小不一样就说明导入时出现错误了,可以尝试多导入几次或者用其他方法通过虚拟机获取。

1.4 主机配置Zookeeper文件
1.4.1 配置zoo_sample.cfg文件
进入到/usr/local/zookeeper/conf目录下。
首先把zoo_sample.cfg重命名为zoo.cfg,同样两种方法,使用下面的指令(确保此时终端位置是conf):
cp zoo_sample.cfg zoo.cfg
或者直接右键重命名都可以。
编辑zoo.cfg文件,将第12行的dataDir=/tmp/zookeeper并修改为dataDir=/usr/local/zookeeper/data/。
然后在文件末尾添加以下内容(注意把slave改成自己的slave主机名):
server.1=0.0.0.0:2881:3881
server.2=slave1-60:2881:3881
server.3=slave2-60:2881:3881
上面本机是0.0.0.0:2881:3881,另外两台机器都是主机名:2881:3881。
1.4.2 配置/data/myid文件
创建并配置/data/myid文件,执行以下指令即可:
mkdir -p /usr/local/zookeeper/data
cd /usr/local/zookeeper/data
touch myid
vi myid
打开myid文件后写入数字1
注意保证myid文件中只有数字1没有多余的内容(包括空格、换行、注释等),如果之后出现错误,请查看此文件。
1.5 主机传输Zookeeper文件到从机
因为配置Hadoop时已经关闭了防火墙,这里默认已经关闭了。
上面把master配置完了,我们可以直接把所有的文件都传输给从机,包括Zookeeper及其配置文件等。
把下面slave1-xx以及slave2-xx修改为自己的即可。
scp -r /usr/local/zookeeper slave1-60:/usr/local
scp -r /usr/local/zookeeper slave2-60:/usr/local
1.6 从机修改Zookeeper文件
虽然传过来了配置文件,但是还是要进行修改!
1.6.1 修改zoo.cfg文件
文件的路径是/usr/local/zookeeper/conf/zoo.cfg
打开以后dataDir我们已经在主机修改过了就不需要修改了。
把刚才在文件末尾添加的三行修改为以下内容(根据自己的slave主机名修改)
slave1:
server.1=master60:2881:3881
server.2=0.0.0.0:2881:3881
server.3=slave2-60:2881:3881
slave2:
server.1=master60:2881:3881
server.2=slave1-60:2881:3881
server.3=0.0.0.0:2881:3881
1.6.2 修改myid文件
文件的路径是/usr/local/zookeeper/data/myid
在slave1中内容修改为数字2,在slave2中内容修改为数字3。
注意保证myid文件中只有数字2或3没有多余的内容(包括空格、换行、注释等),如果之后出现错误,请查看此文件。
1.7 设置环境变量
在三台虚拟机上都进行以下的操作:vi ~/.bashrc进入.bashrc文件。
在文件末尾添加以下内容并wq保存退出:
export PATH=$PATH:/usr/local/zookeeper/bin
最后使用source ~/.bashrc来刷新环境变量。
在三台虚拟机都完成了以上操作之后进行下一步。
1.8 启动Zookeeper
Zookeeper的命令如下:
启动命令 zkServer.sh start
重启命令 zkServer.sh restart
关闭命令 zkServer.sh stop
状态命令 zkServer.sh status
在三台虚拟机上都使用指令打开Zookeeper:
zkServer.sh start
如果每个节点都显示以下提示说明到这里为止没什么问题。

使用zkServer.sh status查看状态可以发现其中一个是Mode:leader另外两个是Mode:follower,谁是leader无所谓不必在意。
1.9 ★解决无法启动Zookeeper
Zookeeper运行产生的data数据都在刚才创建的/usr/local/zookeeper/data/目录中,如果没有使用zkServer.sh stop关闭Zookeeper而关闭虚拟机可能会产生问题,此时删除该目录下除myid以外的所有文件即可。
1.10 验证Zookeeper安装成功
在master使用以下指令(修改为自己的master主机名):
zkCli.sh -server master60:2181
之后会出现以下的命令框:
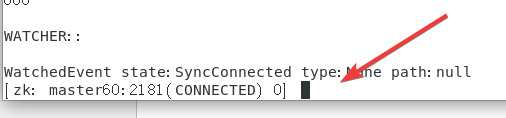
依次使用下面指令对照下图即可:
create /nihao nihao!get /nihaoquit

至此,Zookeeper成功安装。
1.11 ★解决找不到JAVA_HOME
如果没有遇到这个问题就别改
找到一个JDK路径添加进去vi /etc/profile(不要直接复制粘贴下面的)
注意区别JDK和JRE,JDK的目录里有bin文件也有JRE文件,然后JRE里还有一个bin文件。
我这里用的应该是当时用yum指令生成的另一个JDK。在里面添加:
JAVA_HOME=java-1.8.0-openjdk-1.8.0.362.b08-1.el7_9.x86_64
JRE_HOME=java-1.8.0-openjdk-1.8.0.362.b08-1.el7_9.x86_64/jre
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
地址一定是JDK而不是JRE。JDK文件里有一个bin并且有一个jre并且jre里也有一个bin,具体什么是JDK什么是JRE请参考菜鸟教程。
source /etc/profile刷新。
2. HBase
2.1 主机下载HBase
Apache官方下载地址
我下载的版本是hbase-2.2.2-bin.tar.gz
2.2 主机解压HBase
将下载好的文件放到Master节点下的/usr/local/目录下.
在该目录下右键打开终端(确保路径是local)使用以下指令:
tar -zxvf hbase-2.2.2-bin.tar.gz(根据自己下载的版本修改)
之后再继续使用以下指令:
mv /usr/local/hbase-2.2.2 /usr/local/hbase来把目录的版本号去掉(方便之后的操作)
当然上面的操作也可以直接右键文件夹重命名为hbase。总之就是最终把解压出来的文件重命名为hbase即可。
2.3 主机配置HBase文件
目录的路径是/usr/local/hbase/conf,直接通过GUI进行操作即可。
2.3.1 hbase-env.sh文件
文件末尾添加以下内容,根据自己的情况修改。
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.242.b08-1.el7.x86_64
export HBASE_CLASSPATH=/user/hadoop/hadoop-3.3.1/etc/hadoop
export HBASE_MANAGES_ZK=false
JAVA_HOME之前配置过,如Hadoop的/etc/hadoop中hadoop-env.sh中有出现过。·
HBASE_CLASSPATH后面是Hadoop/etc/hadoop请根据自己Hadoop的路径修改。
2.3.2 hbase-site.xml文件
文件末尾添加以下内容,根据自己的情况修改。注意!configuration标签在文件中已经给出,请覆盖掉,否则会出现错误。
主要是把value标签内的东西给修改成自己的!!
<configuration><property><name>hbase.cluster.distributed</name> <value>true</value> </property><property><name>hbase.rootdir</name><value>hdfs://Master60:9000/hbase</value> </property><property><name>hbase.zookeeper.quorum</name><value>Master60,Slave1-60,Slave2-60</value><description>The directory shared by RegionServers. </description></property><property><name>hbase.unsafe.stream.capability.enforce</name><value>false</value></property><property><name>hbase.zookeeper.property.dataDir</name><value>/usr/local/zookeeper</value></property>
</configuration>
hdfs://Master60:9000/hbase的端口一般就是9000,如果在Hadoop中修改过,请查看Hadoop/etc/hadoopcore-site.xml文件。
2.3.3 regionservers文件
删掉原有的localhost,添加两台从机的主机名
slave1-60
slave2-60
2.4 主机配置环境变量
使用指令vi ~/.bashrc
添加下面的内容:
export HBASE_HOME=/usr/local/hbase
export PATH=$HBASE_HOME/bin:$PATH
export PATH=$HBASE_HOME/lib:$PATH
并source ~/.bashrc刷新。
2.5 主机最后的调整
使用hbase version指令,可能出现的错误有以下两种:
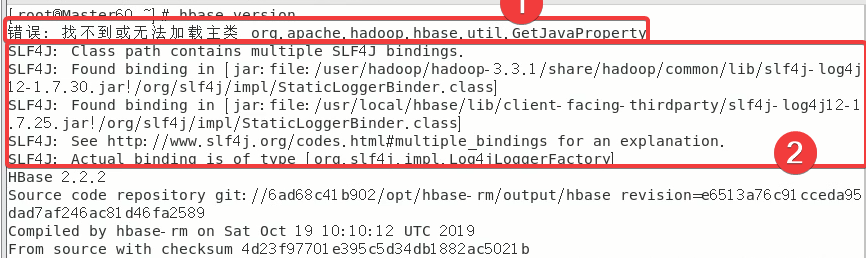
下面依次讲解如何解决以上错误
2.5.1 ★解决错误:找不到或无法加载主类 org.apache.hadoop.hbase.util.GetJavaProperty
进入到usr/local/hbase/bin目录下,我们来修改hbase文件。
共修改四处。
首先在大概327行附近修改两处
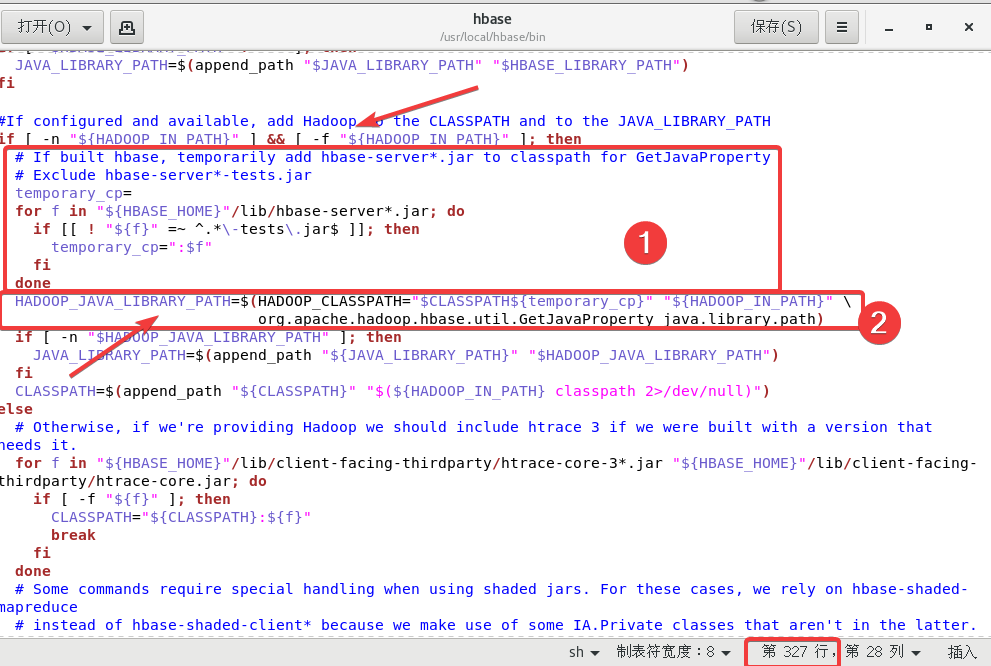
第一处在if [ -n "${HADOOP_IN_PATH}" ] && [ -f "${HADOOP_IN_PATH}" ]; then下面添加的代码如下:
# If built hbase, temporarily add hbase-server*.jar to classpath for GetJavaProperty# Exclude hbase-server*-tests.jartemporary_cp=for f in "${HBASE_HOME}"/lib/hbase-server*.jar; doif [[ ! "${f}" =~ ^.*\-tests\.jar$ ]]; thentemporary_cp=":$f"fidone
第二处将HADOOP_JAVA_LIBRARY_PATH=$(HADOOP_CLASSPATH="$CLASSPATH" "${HADOOP_IN_PATH}" \修改为HADOOP_JAVA_LIBRARY_PATH=$(HADOOP_CLASSPATH="$CLASSPATH${temporary_cp}" "${HADOOP_IN_PATH}" \
最后第三处、第四处在大概187行附近
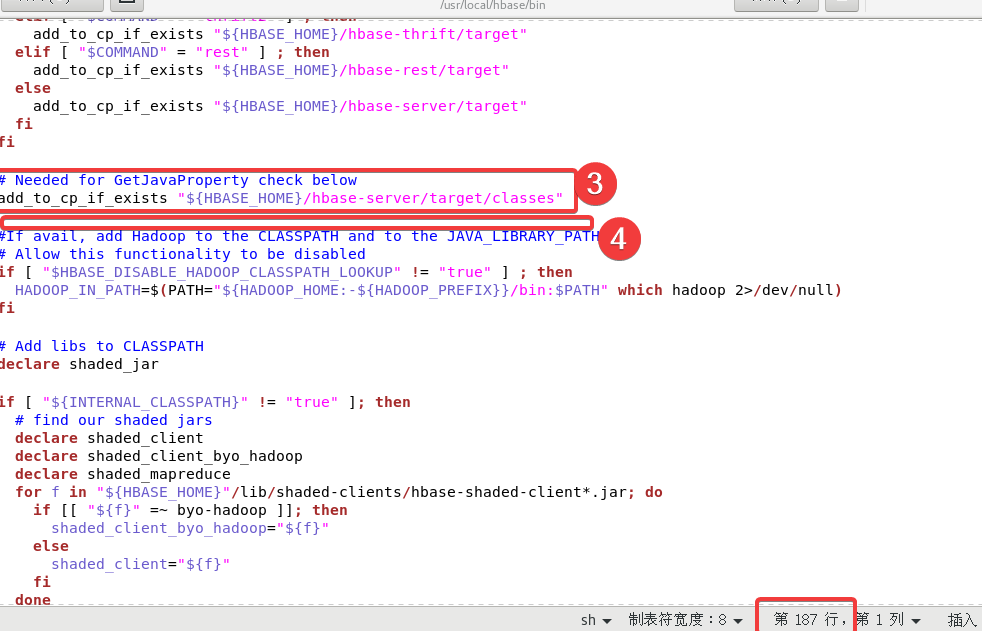
第三处在下面代码的下面
add_to_cp_if_exists "${HBASE_HOME}/hbase-server/target"fi
fi
添加以下内容:
# Needed for GetJavaProperty check below
add_to_cp_if_exists "${HBASE_HOME}/hbase-server/target/classes"
第四处把一段代码删除,要删除的代码如下:
#add the hbase jars for each modulefor f in $HBASE_HOME/hbase-jars/hbase*.jar; doif [[ $f = *sources.jar ]]then: # Skip sources.jarelif [ -f $f ]thenCLASSPATH=${CLASSPATH}:$f;fidone
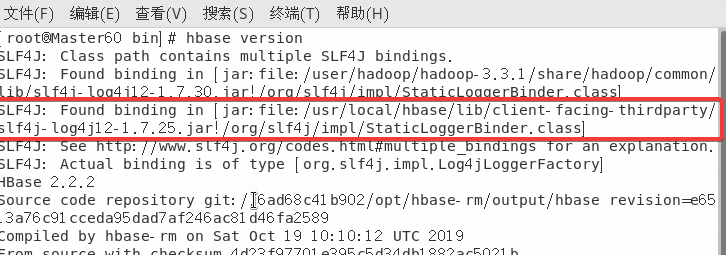
2.5.2 ★解决SLF4J:…
具体原因就是hadoop和hbase都有同一个jar包所以产生了冲突,因此只需要删除其中一个就可以了,这里删除hbase的文件。
因为rm -rf指令删除无法恢复请确保路径正确!如果错误删除只能重新解压HBase开始做。
后面的路径最好是直接复制报错中出现的
rm -rf /usr/local/hbase/lib/client-facing-thirdparty/slf4j-log4j12-1.7.25.jar
2.6 主机传输HBase文件到从机
先把HBase传给从机(改为自己的主机名):
scp -r /usr/local/hbase slave1-60:/usr/local/
scp -r /usr/local/hbase slave2-60:/usr/local/
把配置文件也传给从机:
scp -r ~/.bashrc slave1-60:~
scp -r ~/.bashrc slave2-60:~
记得给从机刷新一下配置文件:source ~/.bashrc。
2.7 主机启动HBase
一定要记住这条常用的命令:
-
启动HBase集群:
start-hbase.sh -
关闭HBase集群:
stop-hbase.sh
在主机启动HBase。
jps看一下主机有没有HMaster以及QuorumPeerMain。
从机有没有QuorumPeerMain以及HRegionServer
2.8 Hbase Shell
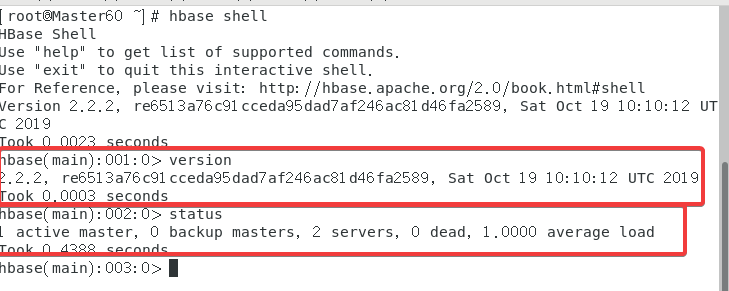
使用指令hbase shell
在内置命令行输入version以及status来测试。
2.9 终极HBase测试
打开浏览器,输入网址192.168.64.60:16010(主机名或IP:16010),能打开这个并且看到两台机器就没啥问题了。

还能看到Zookeeper的设置
2.10 ★遇到解决不了的问题
当你肯定自己的配置文件一点问题也没有,但是还是无法成功运行。
重启三台虚拟机然后再(3.9)
打开Hadoop 主机使用start-all.sh;
打开Zookeeper 三台虚拟机使用 zkServer.sh start;
打开HBase 主机使用 start-hbase.sh。
3.Maven访问HBase
3.1 主机下载Maven
Apache官方下载地址
我下载的版本是apache-maven-3.6.3-bin.tar.gz
3.2 主机解压Maven
将下载好的文件放到Master节点下的/usr/local/目录下.
在该目录下右键打开终端(确保路径是local)使用以下指令:
tar -zxvf apache-maven-3.6.3-bin.tar.gz(根据自己下载的版本修改)
之后再继续使用以下指令:
mv /usr/local/apache-maven-3.6.3 /usr/local/maven来把目录的版本号去掉(方便之后的操作)
当然上面的操作也可以直接右键文件夹重命名为maven。总之就是最终把解压出来的文件重命名为maven即可。
3.3 配置环境变量
使用指令vi /etc/profile
文件末尾添加:
MAVEN_HOME=/usr/local/maven
PATH=$PATH:$MAVEN_HOME/bin
export PATH MAVEN_HOME
刷新source /etc/profile
查看一下mvn -version
3.4 设置阿里云镜像
这个是为了加快依赖包的下载。
此时的文件路径是/usr/local/maven/conf/
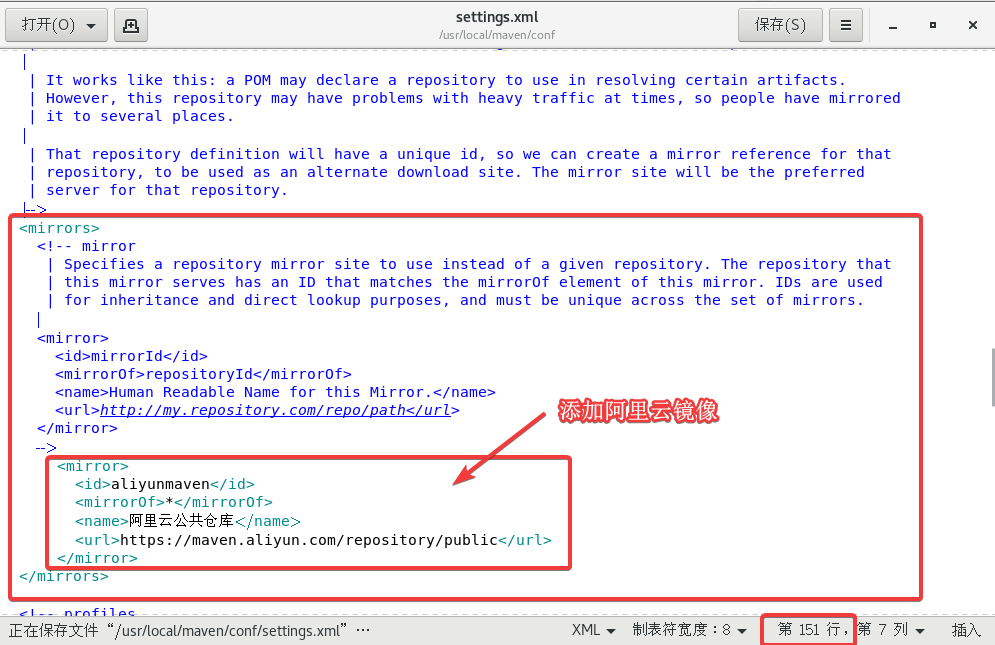
打开settings.xml,大概在151行附近的mirrors标签中添加以下内容:
<mirror><id>aliyunmaven</id><mirrorOf>*</mirrorOf><name>阿里云公共仓库</name><url>https://maven.aliyun.com/repository/public</url>
</mirror>
3.5 Maven项目
这一步可以只做3.5.1后面的想试一下也可以。3.6的开始会把3.5.1以外产生的文件全部清除。
3.5.1 创建项目
创建一个工作目录mkdir -p ~/workspace/source
进入workspace/source中右键终端。
使用指令mvn archetype:generate。
如果提示没有mvn,再用一遍source /etc/profile。
之后会让你手动输入几个参数:
如果想了解一下具体Maven模板是什么可以看菜鸟教程。
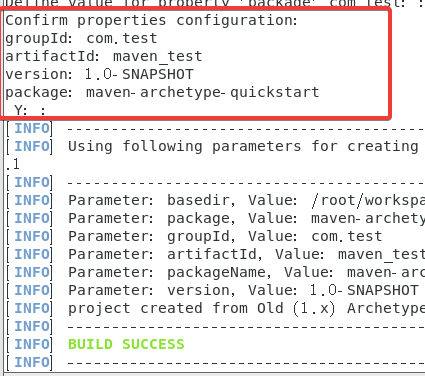
包括gtoupId、artifactId、version、package。
我分别用的com.test、maven_test、回车、main(用maven-archetype-quickstart没编译成功,因此后面改成了main)
最后会出现一个Y,直接回车就可以,最后看到BUILD SUCCESS。
最终成功之后我们可以看到source里出现了一个新的目录,目录名是刚才设置的artifactId参数。
3.5.2 如何编译项目
进入生成的目录,具体路径是/workspace/source/maven_test
右键打开终端,输入指令mvn compile,
我这边总是莫名奇妙用不了mvn然后刷新一次才可以用。
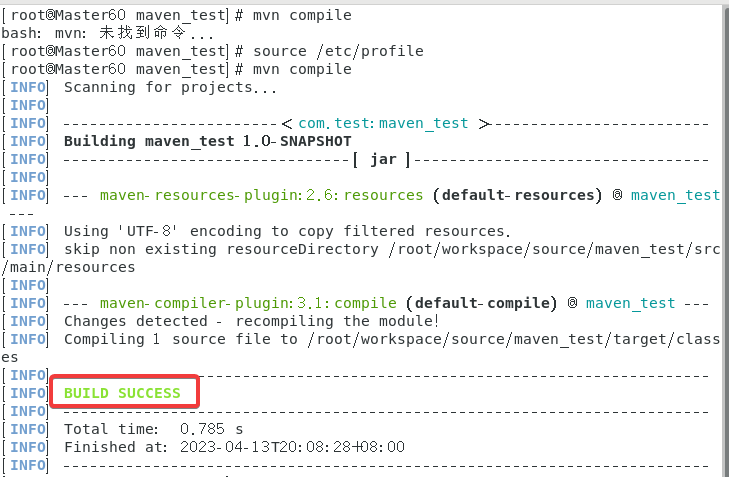
可以看到生成了一个target目录
3.5.3 如何测试项目
路径仍然是/workspace/source/maven_test
右键终端使用指令mvn test
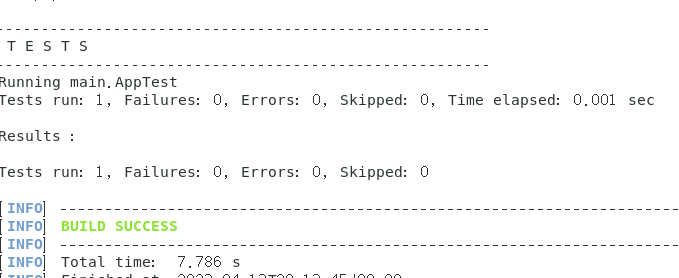
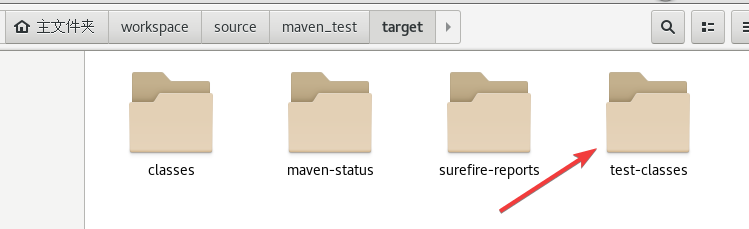
在target目录里又会生成test-classes目录。
3.5.4 如何打包项目
路径仍然是/workspace/source/maven_test
右键终端使用指令mvn package
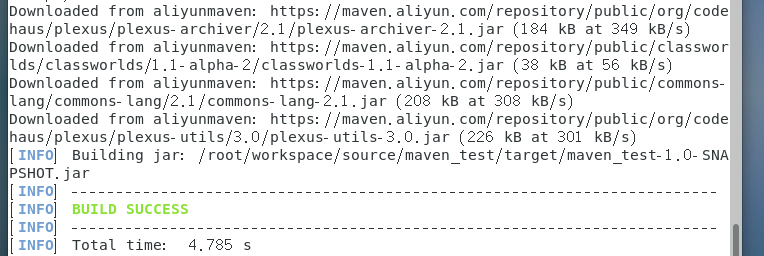
在target目录内生成了maven_test-1.0-SNAPSHOT.jar压缩包
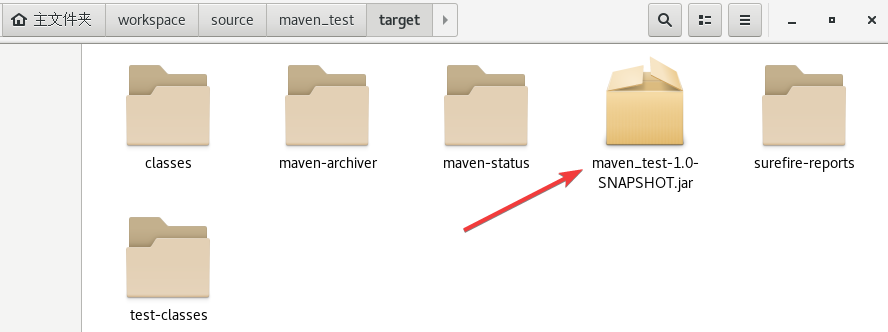
3.5.5 如何安装项目
路径仍然是/workspace/source/maven_test
右键终端使用指令mvn install

安装到的路径如上红框所示。
3.6 Eclipse打开Maven项目
路径仍然是/workspace/source/maven_test
右键终端使用指令mvn clean
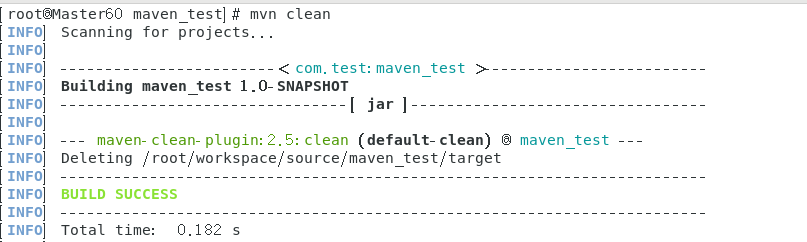
此时targer目录被清除。
执行下面两条指令:
cd ~/.m2
chmod 777 repository
之后我们打开eclipse,进入以后
之后
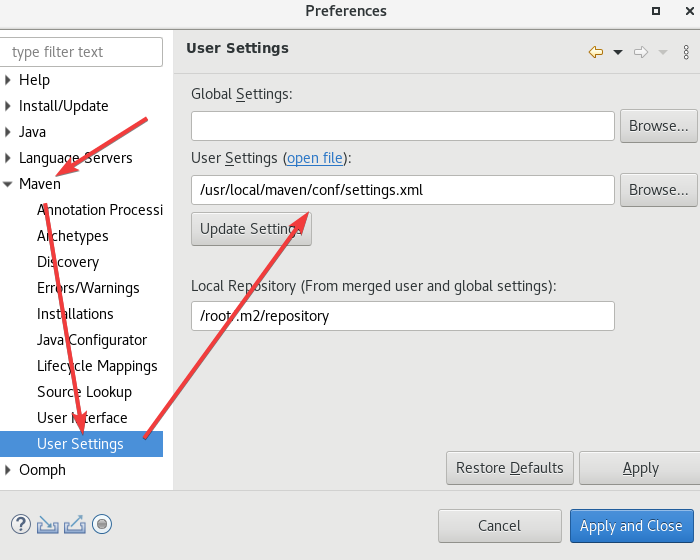
这里的User Settings打开的是maven的conf/settings.xml,如果按照上面来,位置应该是/usr/local/maven/conf/settings.xml。
点击Apply继续下一个设置。
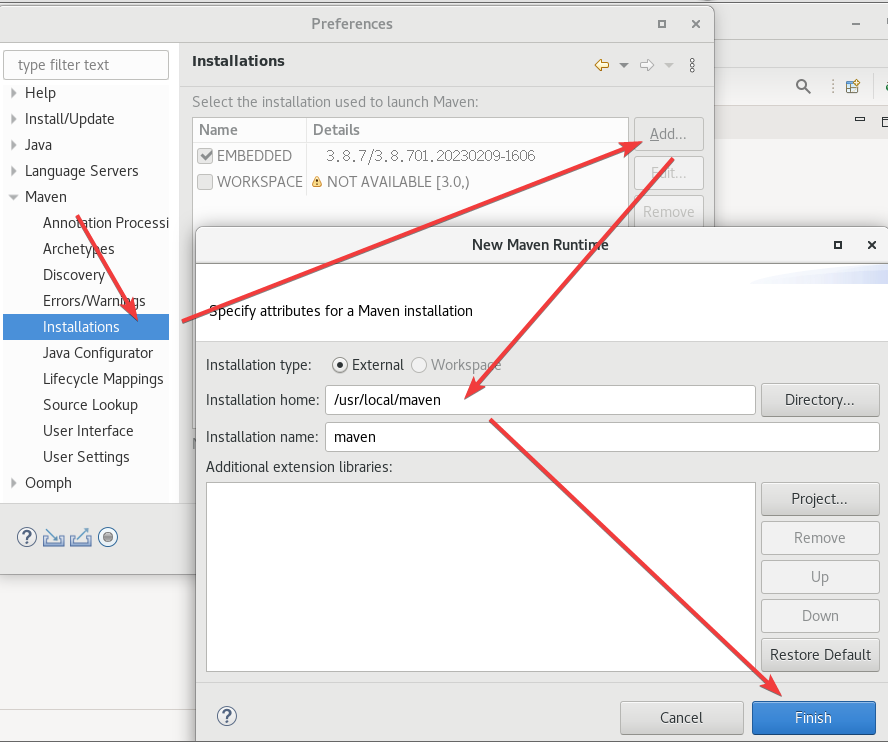
这里的路径是maven所在的位置。
然后选择刚创建的这个
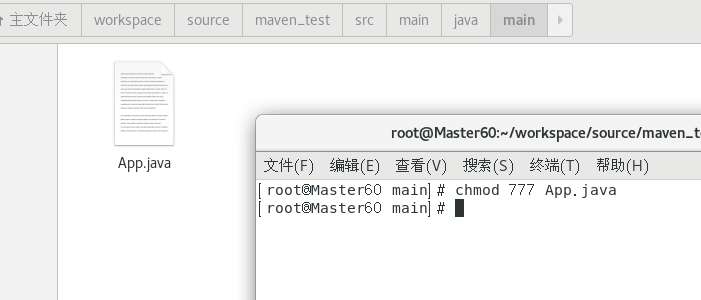
最后我们去给当时创建Maven项目时自动产生的App.java修改权限。chmod 777 App.java
3.7 Maven访问HBase
先把hbase拷贝一份给maven的工作目录
cp -a /usr/local/hbase ~/workspace/source/maven_test/HBase/
然后再Eclipse中打开项目。
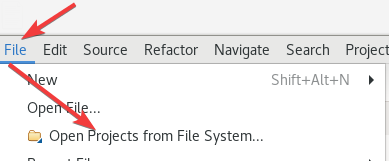
之后打开这个maven_test项目
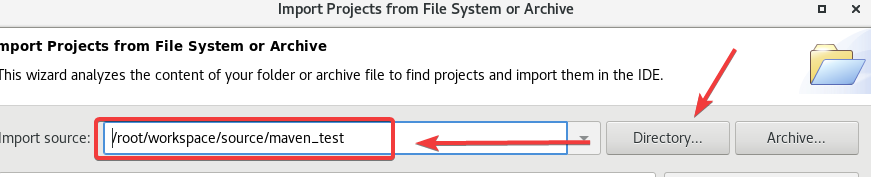
再继续配置
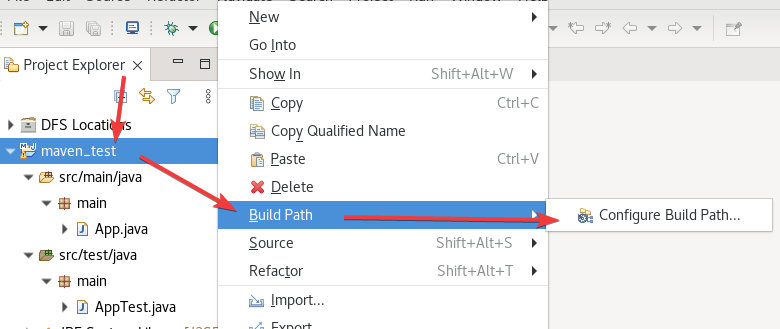
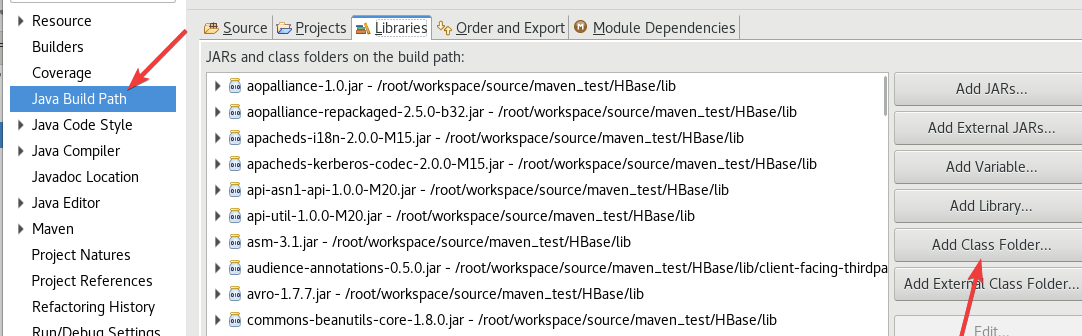
把所有jar包给加载了,如果你有class xx和model xx,导入到class里,我这里是没有这两个文件夹的。
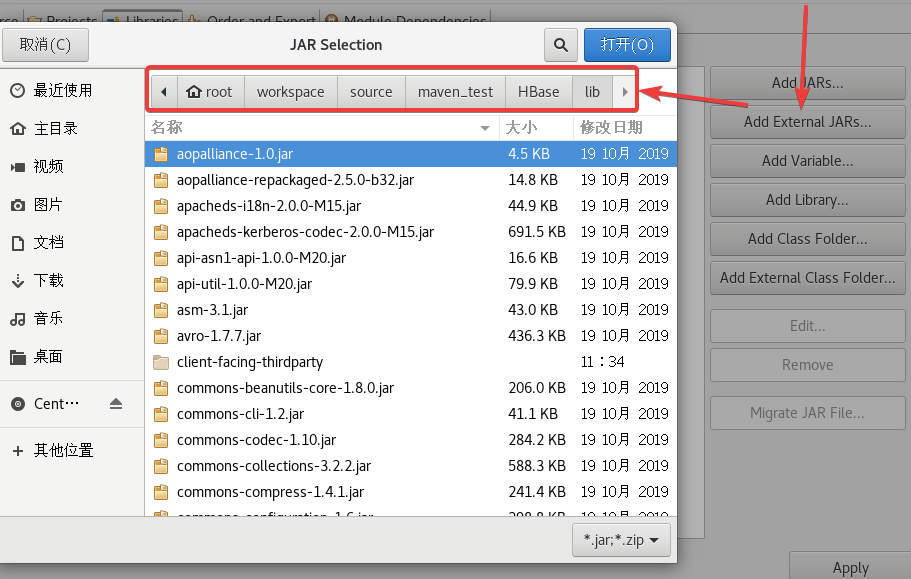
可以先ctrl+A全选ctrl+鼠标左键把目录(没有文件大小的)给取消了,然后就可以导入了。
然后再打开目录把目录里的jar包也给导入了。
在maven_test建一个conf目录复制一份文件(直接复制也行)
cp -a ~/workspace/source/maven_test/HBase/conf/hbase-site.xml ~/workspace/source/maven_test/conf/
给pom.xml开个权限
chmod 777 ~/workspace/source/maven_test/pom.xml
按照下图再添加一下

如果找不到,右键项目文件(maven_test)然后刷新(Refresh)。
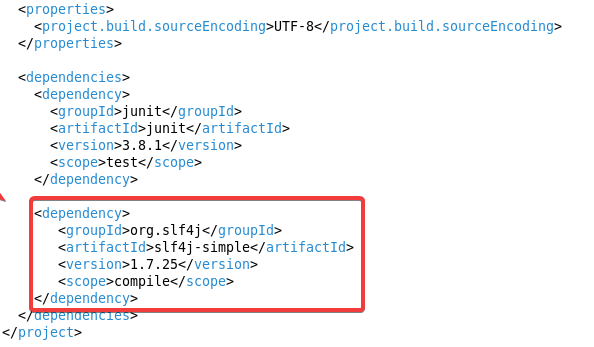
重新回到Eclipse,在pom.xml中新加一个dependency标签
<dependency><groupId>org.slf4j</groupId><artifactId>slf4j-simple</artifactId><version>1.7.25</version><scope>compile</scope>
</dependency>
打开App.java键入以下代码:
里面有一个主机名,修改成自己的。
package main;import java.io.IOException;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Admin;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.regionserver.BloomType;
import org.apache.hadoop.hbase.util.Bytes;public class App
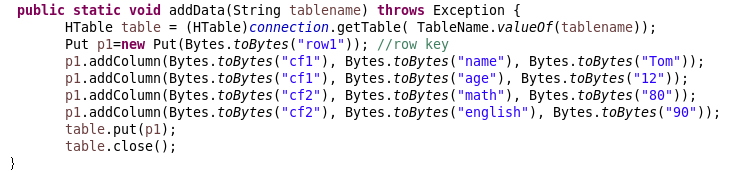
{static Configuration conf=HBaseConfiguration.create(); static Connection connection;public static void main( String[] args ){ String tablename="hbase_tb"; try { App.getConnect(); App.createTable(tablename); App.addData(tablename);}catch (Exception e) { e.printStackTrace(); } }public static void getConnect() throws IOException{conf.set("hbase.zookeeper.quorum", "master60");conf.set("hbase.zookeeper.property.clientPort", "2181");//conf.set("zookeeper.znode.parent", "/hbase");try{ connection=ConnectionFactory.createConnection(conf); }catch(IOException e){ } }//创建一张表,通过HBaseAdmin HTableDescriptor来创建 public static void createTable(String tablename) throws Exception { TableName tableName= TableName.valueOf(tablename);Admin admin = connection.getAdmin(); if (admin.tableExists(tableName)) {admin.disableTable(tableName);admin.deleteTable(tableName);System.out.println(tablename + " table Exists, delete ......"); } @SuppressWarnings("deprecation")HTableDescriptor desc = new HTableDescriptor(tableName); @SuppressWarnings("deprecation")HColumnDescriptor colDesc = new HColumnDescriptor("cf1");colDesc.setBloomFilterType(BloomType.ROWCOL);desc.addFamily(colDesc); desc.addFamily(new HColumnDescriptor("cf2")); admin.createTable(desc); admin.close();System.out.println("create table success!"); } public static void addData(String tablename) throws Exception { HTable table = (HTable)connection.getTable( TableName.valueOf(tablename));Put p1=new Put(Bytes.toBytes("row1")); //row key p1.addColumn(Bytes.toBytes("cf1"), Bytes.toBytes("name"), Bytes.toBytes("Tom")); p1.addColumn(Bytes.toBytes("cf1"), Bytes.toBytes("age"), Bytes.toBytes("12")); p1.addColumn(Bytes.toBytes("cf2"), Bytes.toBytes("math"), Bytes.toBytes("80")); p1.addColumn(Bytes.toBytes("cf2"), Bytes.toBytes("english"), Bytes.toBytes("90")); table.put(p1);table.close();}
}
其中向这个分布式数据库中添加的数据是:
最终呈现的结果是:
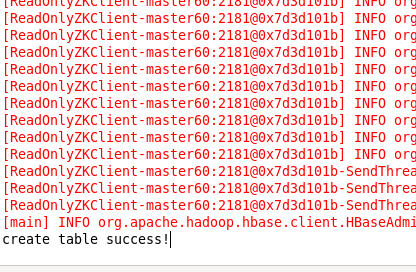
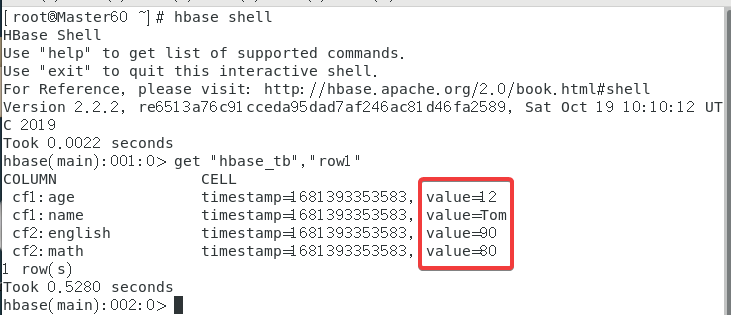
最后检查一下,终端输入hbase shell,之后使用get "hbase_tb","row1"来获取数据库内容。
3.8 ★解决代码爆红
比较玄学,我也没搞明白,我再pom.xml里添加了两个依赖,不爆红了但是不能运行,然后我又删了,也不爆红也能运行了……
<dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-server</artifactId><version>1.3.1</version>
</dependency>
<dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-client</artifactId><version>1.3.1</version>
</dependency>
3.9 ★虚拟机重启后需要进行的操作
打开Hadoop 主机使用start-all.sh;
打开Zookeeper 三台虚拟机使用 zkServer.sh start;
打开HBase 主机使用 start-hbase.sh。
4. HBase集群实验
下面是实验的描述,分的小标题混乱、不知所云,也不知从哪里冒出一个学生信息(下面代码里没写);表内容写的也抽象,后来才明白,是一班的同学写教师表,二班的同学写辅导员表,下面给出的是教师表,用辅导员表的同学只需要改一下参数就好了没有很大的难度。
1. 搭建HBase集群,一主两从,给出网页的截屏15分。
2. Eclispe/Idea Maven项目访问HBase
2.1 表内容
1班:教师,基本信息:年龄、性别、职称、职务,科研信息:发表文章数、横向项目数、纵向项目数。注意职务和科研信息中的所有属性根据实际确定。
2班:辅导员,基本信息:年龄、性别、职称、职务,业绩信息:红旗班次数、考研率超额次数、就业率超额次数。注意业绩信息根据实际填写。
2. 源程序评分
2.0 导入包和程序结构10分
2.1 创建表源程序和运行结果的截屏10分
2.2 添加三个典型行记录的源程序和运行结果后在HBase shell中看到的结果截屏20分
2.3 浏览所有记录的源程序和运行结果后HBase看到的结果截屏10分
3. 在HBase Shell浏览所有的学生信息10分
4. 根据浏览到的信息解释HBase的逻辑结构和物理结构15分
5. 分析HBase的插入和MySQL的插入有何不同10分。
4.1 实验代码
实际上就是上面代码的一个改进版,然后又多加了一个Teacher类(二班同学应该是Counselor类)。先给出一个项目栏的截图:

新建一个Teacher Class,这里直接用的public String是为了减少麻烦。
package main;public class Teacher {public String name;public String age;public String gender;public String title;public String position;public String articleCount;public String horizontalProjectCount;public String verticalProjectCount;// 构造函数public Teacher(String name, String age, String gender, String title, String position,String articleCount, String horizontalProjectCount, String verticalProjectCount) {this.name = name;this.age = age;this.gender = gender;this.title = title;this.position = position;this.articleCount = articleCount;this.horizontalProjectCount = horizontalProjectCount;this.verticalProjectCount = verticalProjectCount;}// getter 和 setter 方法// ...
}以及App.java的内容
package main;import java.io.IOException;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Admin;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.regionserver.BloomType;
import org.apache.hadoop.hbase.util.Bytes;public class App
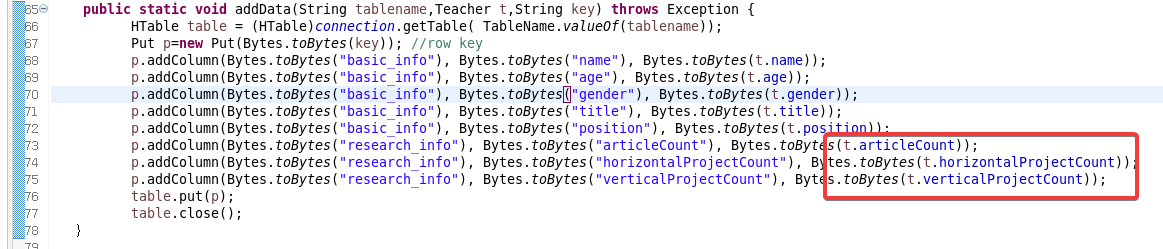
{static Configuration conf=HBaseConfiguration.create(); static Connection connection;public static void main( String[] args ){ String tablename="Teacher"; try { App.getConnect(); App.createTable(tablename); Teacher t1 = new Teacher("Jack","54","m","AssociateProfessor","Teacher","2","2","2");Teacher t2 = new Teacher("Amy","45","m","AssociateProfessor","Teacher","4","4","4");Teacher t3 = new Teacher("Mike","40","m","Professor","Teacher","6","6","6");App.addData(tablename,t1,"row1");App.addData(tablename,t2,"row2");App.addData(tablename,t3,"row3");}catch (Exception e) { e.printStackTrace(); } }public static void getConnect() throws IOException{conf.set("hbase.zookeeper.quorum", "master60");conf.set("hbase.zookeeper.property.clientPort", "2181");//conf.set("zookeeper.znode.parent", "/hbase");try{ connection=ConnectionFactory.createConnection(conf); }catch(IOException e){ } }//创建一张表,通过HBaseAdmin HTableDescriptor来创建 public static void createTable(String tablename) throws Exception { TableName tableName= TableName.valueOf(tablename);Admin admin = connection.getAdmin(); if (admin.tableExists(tableName)) {admin.disableTable(tableName);admin.deleteTable(tableName);System.out.println(tablename + " table Exists, delete ......"); } @SuppressWarnings("deprecation")HTableDescriptor desc = new HTableDescriptor(tableName); @SuppressWarnings("deprecation")HColumnDescriptor colDesc = new HColumnDescriptor("basic_info");colDesc.setBloomFilterType(BloomType.ROWCOL);desc.addFamily(colDesc); desc.addFamily(new HColumnDescriptor("research_info")); admin.createTable(desc); admin.close();System.out.println("create table success!");} public static void addData(String tablename,Teacher t,String key) throws Exception { HTable table = (HTable)connection.getTable( TableName.valueOf(tablename));Put p=new Put(Bytes.toBytes(key)); //row key p.addColumn(Bytes.toBytes("basic_info"), Bytes.toBytes("name"), Bytes.toBytes(t.name)); p.addColumn(Bytes.toBytes("basic_info"), Bytes.toBytes("age"), Bytes.toBytes(t.age)); p.addColumn(Bytes.toBytes("basic_info"), Bytes.toBytes("gender"), Bytes.toBytes(t.gender)); p.addColumn(Bytes.toBytes("basic_info"), Bytes.toBytes("title"), Bytes.toBytes(t.title)); p.addColumn(Bytes.toBytes("basic_info"), Bytes.toBytes("position"), Bytes.toBytes(t.position)); p.addColumn(Bytes.toBytes("research_info"), Bytes.toBytes("articleCount"), Bytes.toBytes(t.articleCount)); p.addColumn(Bytes.toBytes("research_info"), Bytes.toBytes("horizontalProjectCount"), Bytes.toBytes(t.horizontalProjectCount)); p.addColumn(Bytes.toBytes("research_info"), Bytes.toBytes("verticalProjectCount"), Bytes.toBytes(t.verticalProjectCount)); table.put(p);table.close();} }其中:
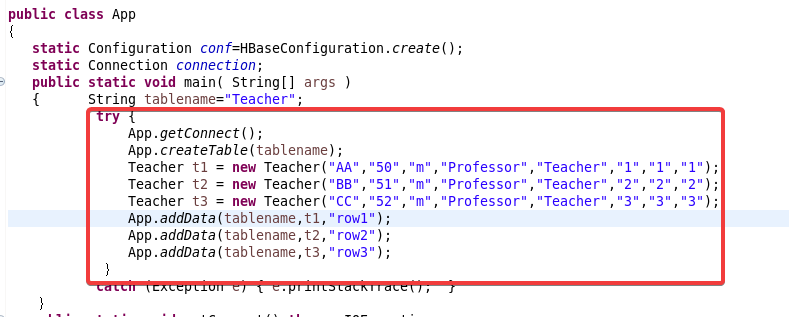
信息是通过构造函数直接搞得,在这里修改成自己的内容!还有表名也在这里修改↑
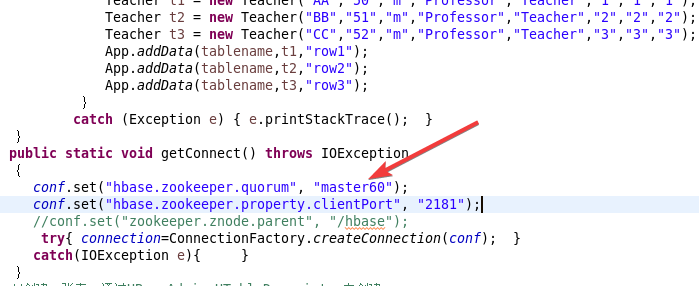
这里也改成自己的!
最后打开进入hbase shell使用指令scan 'Teacher'来查看
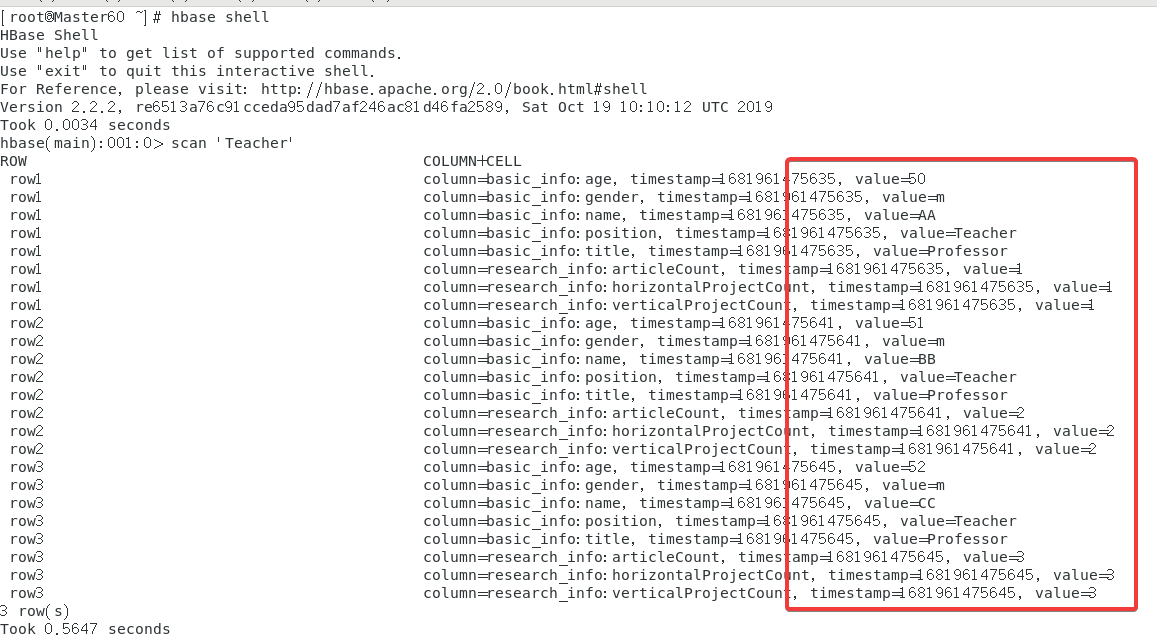
4.2 二班的修改
首先把教师类改成辅导员类,大概把下面三个参数的名改了,不改的话就和上面差不多做。
如果把参数的名改了,记得修改下面的部分。
4.3 解释HBase的逻辑结构和物理结构
1. 逻辑结构:- 表(Table):HBase 数据库中的基本单元,由多行和多列族组成,每行有唯一的行键(Row Key),每个列族包含多个列(Column)。
- 行(Row):HBase 表中的数据按行存储,每行都有唯一的行键,行键按照字典序排序,可以通过行键查找数据。
- 列族(Column Family):HBase 表中的数据按列族组织,每个列族包含多个列,每个列都有一个唯一的列名(Column Name),列名和列值一起构成了列。
- 列(Column):HBase 表中的数据由多个列组成,每个列由列名、时间戳和列值组成,列名和列值都是字节数组,时间戳是 long 类型的整数。2. 物理结构:- Region Server:HBase 的数据存储和查询都是通过 Region Server 来完成的,Region Server 是 HBase 集群中的一个节点,每个 Region Server 管理多个 Region。
- Region:HBase 表的数据被分为多个 Region 存储,每个 Region 是一段连续的行,每个 Region 包含一个主列族和多个次列族,Region 的大小由 HBase 的配置参数决定,通常在几百 MB 到几 GB 之间。
- HFile:HBase 数据在磁盘上是按 HFile 的格式存储的,HFile 是 HBase 中的一个重要的数据结构,它是一个稠密的、可变长的文件格式,用于存储一段连续的行。
- WAL:HBase 中的写操作会先写入 Write Ahead Log(WAL),WAL 是一种顺序写入的、不可修改的日志,用于保证数据写入的可靠性和一致性。
4.4 分析HBase的插入和MySQL的插入有何不同10分
1. 数据模型:- MySQL 是关系型数据库,其数据存储在表格中,每个表格由一组列和行组成,每行代表一个记录,每列代表一个属性。
- HBase 是基于列族的 NoSQL 数据库,其数据存储在表格中,每个表格由多个列族和行组成,每行代表一个记录,每个列族下包含多个列,每个列可以包含多个版本。2. 插入方式:- MySQL 的插入操作是通过 SQL 语句实现的,使用 INSERT INTO 语句将数据插入到指定的表格中。
- HBase 的插入操作是通过 Java API 或 HBase shell 命令实现的,使用 Put 操作将数据插入到指定的表格中。3. 数据存储:- MySQL 的数据是存储在硬盘中的,每次插入数据时,MySQL 会将数据写入磁盘。
- HBase 的数据是存储在内存中和硬盘中的,每次插入数据时,HBase 会将数据先写入内存中的 MemStore,当 MemStore 中的数据达到一定大小时,会将数据写入硬盘中的 HFile 中。4. 性能:- MySQL 的插入操作通常比 HBase 的插入操作更快,因为 MySQL 的数据存储方式更简单,且 MySQL 的数据通常是存储在本地磁盘上的,而 HBase 的数据存储在内存中和硬盘中,写入操作需要更多的计算资源和磁盘 I/O。
- HBase 的查询操作通常比 MySQL 的查询操作更快,因为 HBase 的数据存储方式更适合于大规模数据的存储和查询,且 HBase 支持快速的随机读取和扫描操作。
相关文章:
【李老师云计算】HBase+Zookeeper部署及Maven访问(HBase集群实验)
索引 前言1. Zookeeper1.1 主机下载Zookeeper安装包1.2 主机解压Zookeeper1.3 ★解决解压后文件缺失1.4 主机配置Zookeeper文件1.4.1 配置zoo_sample.cfg文件1.4.2 配置/data/myid文件 1.5 主机传输Zookeeper文件到从机1.6 从机修改Zookeeper文件1.6.1 修改zoo.cfg文件1.6.2 修…...
第11章_常用类和基础API
第11章_常用类和基础API 讲师:尚硅谷-宋红康(江湖人称:康师傅) 官网:http://www.atguigu.com 本章专题与脉络 1. 字符串相关类之不可变字符序列:String 1.1 String的特性 java.lang.String 类代表字符串…...
Java语言数据类型与c语言数据类型的不同
目录 一、c语言数据类型 1.基本类型: 2.枚举类型: 3.空类型: 4.派生类型: 二、C语言编程需要注意的64位和32机器的区别 三、 不同之处 一、c语言数据类型 首先,先来整体介绍一下C语言的数据类型分类。 1.基…...
、Trim()、Split()、Substring()、IndexOf() 、 LastIndexOf()函数)
C# Replace()、Trim()、Split()、Substring()、IndexOf() 、 LastIndexOf()函数
目录 一、Replace() 二、Trim() 三、Split() 四、Substring() 五、IndexOf() 六、LastIndexOf() 一、Replace() 在C#中,Replace()是一个字符串方法,用于将指定的字符或子字符串替换为另一个字符或字符串。下面是一些Replace()方法的常见用法和示例…...

C++类的理解与类型名,类的成员,两种定义方式,类的访问限定符,成员访问,作用域与实例化对象
面向过程和面向对象初步认识 C语言是面向过程的,关注的是过程,分析出求解问题的步骤,通过函数调用逐步解决问题 C是基于面向对象的,关注的是对象,将一件事情拆分成不同的对象,靠对象之间的交互完成 面向…...

【华为OD机试真题 C++】1051 - 处理器问题 | 机试题+算法思路+考点+代码解析
文章目录 一、题目🔸题目描述🔸输入输出🔸样例1🔸样例2 二、题目解析三、代码参考 作者:KJ.JK 🌈 🌈 🌈 🌈 🌈 🌈 🌈 🌈 &…...

Linux 常用操作命令大全
一、基础知识 1.1 Linux系统的文件结构 /bin 二进制文件,系统常规命令 /boot 系统启动分区,系统启动时读取的文件 /dev 设备文件 /etc 大多数配置文件 /home 普通用户的家目录 /lib 32位函数库 /lib64 64位库 /media 手动临时挂载点 /mnt 手动临时挂载点…...
Git使用教程
Git 目标 Git简介【了解】 使用Git管理文件版本【重点】 远程仓库使用【掌握】 分支管理【重点】 远程仓库【掌握】 一、Git简介 1、版本控制系统简介 1.1、版本控制前生今世 版本控制系统Version Control Systems,简称 VCS是将『什么时候、谁、对什么文件…...

substrate中打印调试信息的多种方式详解
目录 1. 获取substrate-node-template代码2. 添加一个用于测试的pallet至依赖到pallets目录3. log方式来输出信息3.1 将log依赖添到cargo.toml文件3.2 log-test/src/lib.rs修改call方法 3.3 polkadot.js.调用测试函数do_something_log_test4. printable trait方式来输出信息4.1…...
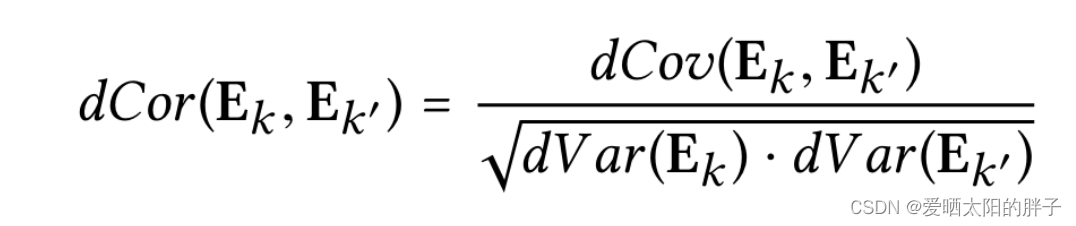
Disentangled Graph Collaborative Filtering
代码地址:https://github.com/ xiangwang1223/disentangled_graph_collaborative_filtering Background: 现有模型在很大程度上以统一的方式对用户-物品关系进行建模(将模型看做黑盒,历史交互作为输入,Embedding作为输出。)&…...

Nginx快速上手
Nginx快速上手 OVERVIEW Nginx快速上手一、基本概念1.Nginx初步认识2.正向/反向代理(1)正向代理(2)反向代理 二、Nginx 安装和配置1.安装2.Nginx指令3.Nginx配置 三、Nginx的使用1.Web服务器(1)静态网页存储…...

【设计模式】实际场景解释策略模式与工厂模式的应用
文章目录 前言策略模式概念场景示例 工厂模式概念场景示例 策略模式与工厂模式的比较相同点不同点 总结 前言 策略模式和工厂模式是常见的设计模式,它们可以帮助我们更好地组织和管理代码,提高代码的可维护性和可扩展性。 在本篇博客中,我将…...

外包干了三年,算是废了...
先说一下自己的情况。大专生,19年通过校招进入湖南某软件公司,干了接近3年的测试,今年年上旬,感觉自己不能够在这样下去了,长时间呆在一个舒适的环境会让一个人堕落!而我已经在一个企业干了三年,…...

九龙证券|光模块概念股封单资金超3亿元,传媒板块涨停潮来袭
今天A股三大股指低开低走。沪深两市收盘共37股涨停。剔除4只ST股,合计33股涨停。另外,10股封板未遂,整体封板率为78.72%。 涨停战场: 华工科技封单资金超3亿元 从收盘涨停板封单量来看,同方股份封单量最高࿰…...

[ES6] 数组
[ES6] 数组 数组的创建类数组对象可迭代对象的转换 扩展方法findfindIndexfillcopyWithinentrieskeysvaluesincludesflatflatMap 扩展运算符复制数组合并数组 数组缓冲区创建数组缓冲区视图创建 定型数组创建通过数组缓冲区生成通过构造函数 定型数组特性 拷贝浅拷贝深拷贝 数组…...

【问题描述】编写一个程序计算出球、圆柱和圆锥的表面积和体积。
【问题描述】 编写一个程序计算出球、圆柱和圆锥的表面积和体积。 要求: (1)定义一个基类,至少含有一个数据成员半径,并设为保护成员; (2)定义基类的派生类球、圆柱、圆锥&#…...

Python 人工智能:16~20
原文:Artificial Intelligence with Python 协议:CC BY-NC-SA 4.0 译者:飞龙 本文来自【ApacheCN 深度学习 译文集】,采用译后编辑(MTPE)流程来尽可能提升效率。 不要担心自己的形象,只关心如何…...
)
【华为OD机试真题】最优资源分配(javapython)
最优资源分配 知识点数组贪心Q时间限制:1s空间限制:32MB限定语言:不限 题目描述: 某块业务芯片最小容量单位为1.25G,总容量为M1.25G,对该芯片资源编号为1,2,…,M。该芯片支持3种不同的配置,分别为A、B、C。 配置A:占用容量为1.251=1.25G 配置B:占用容量为1.252=2…...

git的使用——操作流程
一、什么是git git是一个开源的分布式版本控制软件,能够有效并高效的处理很小到非常大的项目。 二、添加SSH公钥 安装下载后,会发现鼠标右击,会出现 Git Bash Here 这个选项,如图所示,点击进入 1.打开git窗口后&…...

Ae:自动定向
Ae 菜单:图层/变换/自动定向 Auto-Orient 快捷键:Ctrl Alt O 自动定向 Auto-Orient是 Ae 图层中的一个附加的、隐藏实现(不会在时间轴面板上更改属性的值)的功能,它可以使得图层自动旋转或改变方向以朝向指定的运动路…...

第07章 FastMCP 把检索封装成 Agent 工具
第07章 FastMCP 把检索封装成 Agent 工具 工单知识库已经能在 Python 进程内被普通函数调用,但要让外部 Agent、Web 后端或其他语言的客户端使用这份能力,函数级别的接口不够:缺少协议、缺少描述、缺少跨进程通讯。MCP(Model Cont…...

【人生底稿 28】新疆出差终章:几番波折终汇报,尽兴踏归津门路
三日游玩尽数落幕,忙碌工作正式回归。轻松的闲暇时光悄然收尾,紧绷的工作状态再次上线。整趟新疆之行,在起伏辗转中迎来最终收尾。一、深夜复盘材料,彻夜待汇报游玩结束回到酒店,我没有松懈休息,静下心重新…...

期权交易基础框架:模块化设计与Python实现指南
1. 项目概述:一个为期权交易者打造的“乐高积木”底座如果你在量化交易或者期权策略开发领域摸爬滚打过一段时间,大概率会遇到一个共同的痛点:策略想法很多,但把它们变成可回测、可实盘、可管理的代码,却要耗费大量的“…...

量子控制中的动态校正门与SCQC几何方法
1. 量子控制中的噪声挑战与动态校正门在超导量子处理器上实现高保真度的量子门操作,最大的障碍来自环境噪声。这些噪声主要分为两类:失谐噪声(δz)和幅度噪声(ϵ)。失谐噪声源于量子比特频率的漂移…...

Linux压缩归档与备份文件管理
Linux压缩归档与备份文件管理在 Linux 运维工作中,压缩与归档几乎无处不在。日志备份、数据迁移、配置留档、故障现场保存,都会涉及文件打包和压缩。如果缺乏规范,备份文件很容易散落各处、命名混乱、占用失控,最终从保障手段变成…...

DIY LED眼妆:从电路原理到穿戴制作的完整指南
1. 项目概述:打造你的专属发光眼妆想为下一次Cosplay活动或万圣节派对增添一抹赛博朋克般的未来感吗?厌倦了千篇一律的商店货,渴望一件真正独一无二、能让你在人群中脱颖而出的发光装饰?这个DIY LED眼妆项目,正是为你准…...

树莓派GPIO扩展实战:基于MCP23017芯片与Adafruit Bonnet
1. 项目概述:为什么你的树莓派需要GPIO扩展?玩树莓派的朋友,尤其是那些热衷于物联网、智能家居或者自动化项目的,肯定都经历过一个共同的烦恼:GPIO引脚不够用。树莓派引以为傲的40针GPIO排针,在连接了几个传…...

STM32嵌入式开发入门:从硬件配置到项目实战的完整学习路径
1. 项目概述:从零到一,如何构建你的STM32知识体系很多刚接触嵌入式开发的朋友,拿到一块STM32开发板,看着满屏的英文手册和复杂的库函数,第一反应往往是“从哪开始?”。这感觉就像面对一座零件齐全但没图纸的…...

英雄联盟智能助手Seraphine:免费开源的战绩查询与BP辅助神器
英雄联盟智能助手Seraphine:免费开源的战绩查询与BP辅助神器 【免费下载链接】Seraphine 英雄联盟战绩查询工具 项目地址: https://gitcode.com/gh_mirrors/se/Seraphine 还在为错过对局接受而懊恼吗?还在BP阶段犹豫不决错失最佳英雄选择吗&#…...

深入解析瑞芯微RK3399/RK3288平台ISP驱动:从V4L2框架到Camera Sensor联动
1. 项目概述 在嵌入式Linux开发,特别是涉及多媒体处理的项目中,图像信号处理器(ISP)驱动的理解往往是打通摄像头应用链路的关键一环,也是很多开发者感觉“黑盒”最多的地方。最近在调试基于瑞芯微RK3399和RK3288平台的…...