基于Bert的知识库智能问答系统
项目完整地址:
可以先看一下Bert的介绍。
Bert简单介绍
一.系统流程介绍。
-
知识库是指存储大量有组织、有结构的知识和信息的仓库。这些知识和信息被存储为实体和实体关系的形式,通常用于支持智能问答系统。在一个知识库中,每个句子通常来说都具有三元组,例如“苏琳的性别是男”。在这个句子中,第一个实体是苏琳,第二个实体是男,实体关系(属性)就是性别。在这样的系统中,知识库起到了至关重要的作用。这些知识和信息被存储为实体和实体关系的形式,通常用于支持智能问答系统。在此基于知识库的智能问答系统中,对于一个问题,需要提取出来的有两部分内容,一是实体,二是实体关系。确定实体和实体关系之后,系统才能够通过知识库找到对应的答案。因此,在构建这样的系统时,首先需要搭建知识库数据库,将数据中的每一个知识点分别归纳出实体、实体关系和答案。一个知识点对应一行数据,接着将这些数据存储进mysql数据库中,如图:

-
接下来是训练模型,一共需要训练两个,一个是Bert-Crf模型,用于识别问题中的第一个实体。。在问答系统中,识别问题中的实体是非常关键的一步,因为它是回答问题所必须的基本信息。举例来说,对于“苏琳的性别是男”这个问题,Bert-Crf模型可以识别出“苏琳”这个实体。
-
一般来说,回答一个问题需要三个要素:实体、实体关系和答案。但为了更快速地找到答案,在这里可以直接使用实体进行数据库查询。如果数据库中有关于这个实体的信息,就可以判断数据库中对应的属性是否存在于问题中。如果存在,就可以直接返回数据库中的答案,以此来简化整个问题回答的过程。
-
以“苏琳”这个实体为例,如果在数据库中有对应的属性“性别”,并且问题中也提到了“性别”一词,那么就可以直接返回数据库中“性别”对应的答案“男”。这样,通过Bert-Crf模型和数据库的配合使用,可以快速准确地回答问题,提高问答系统的效率和精度。
-
然而,实际上问题的复杂性可能不止于此。如果问题中涉及到多个实体,或者实体之间存在复杂的关系,这种简单的查询方法就不能满足需求了。此时,需要更加复杂的问答系统来处理这些问题。例如数据库中关于实体的数据的实体关系并不存在于问题中,这时候我们就需要利用第二个模型,即BertForSequenceClassification模型。
-
利用预训练的 BERT模型来实现自然语言理解和问答,同时将知识库和问答系统进行整合,从而能够对用户提出的问题进行准确、高效的回答。该系统通过将问题和知识库中的实体和关系进行匹配,从而找到最佳答案。具体来说,本系统先将三个属性:实体(问题),实体关系(实体属性),实体(答案)存储进 mysql 数据库。当提出问题时,用 BertCrf模型来识别出问题中所包含的实体,识别出实体之后就可以进行数据库的查询;识别出实体后就需要进行实体与属性的连接,利用BertForSequenceClassification模型进行连接,连接完成后查询数据库得到答案并将结果返回。
流程图如下:
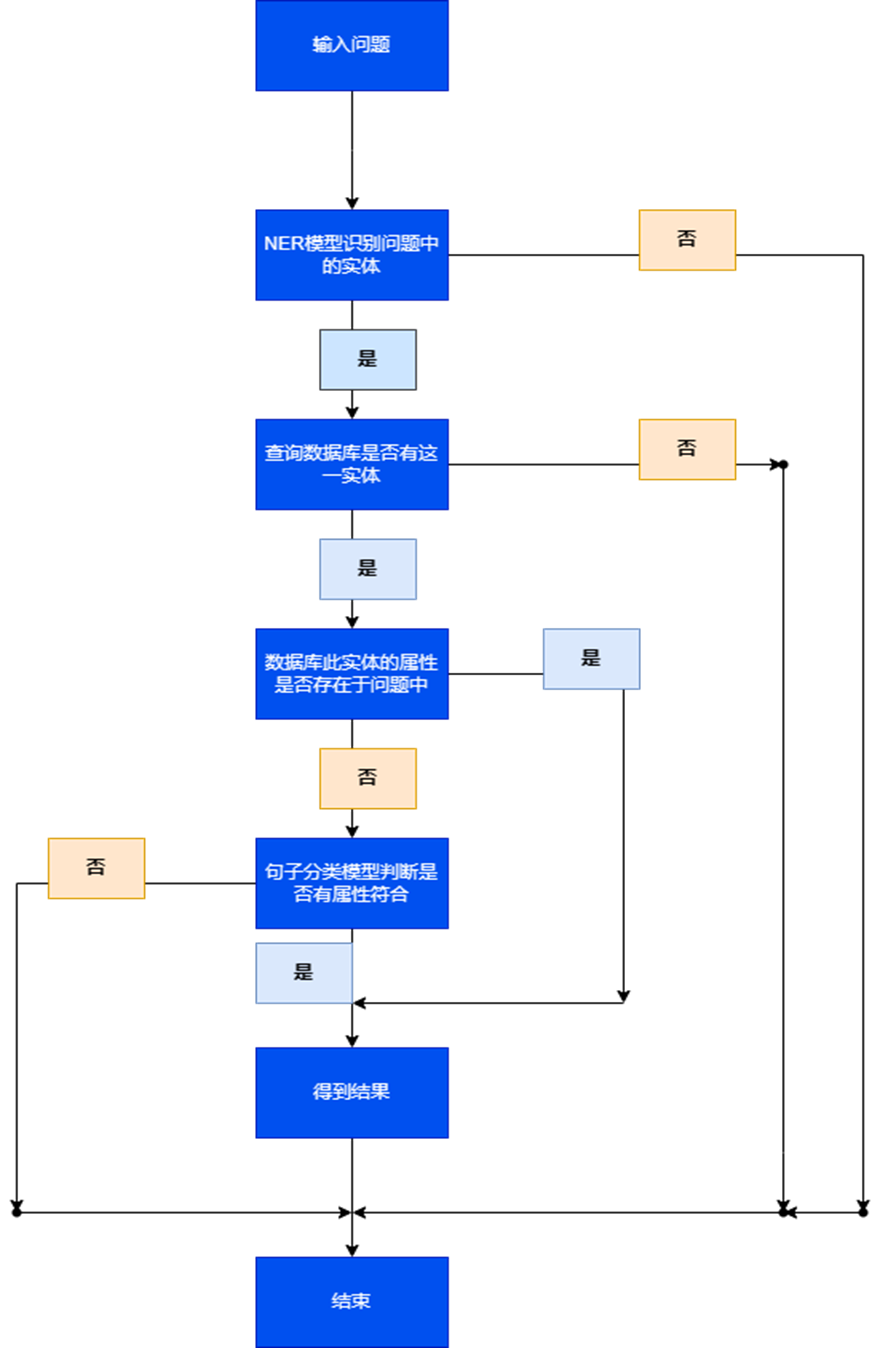
结果展示如下:

二.处理数据。
1.数据集介绍。
NLPCC(Natural Language Processing and Chinese Computing)是中国计算机学会主办的一个自然语言处理和中文计算会议,旨在促进中文自然语言处理领域的交流和发展。该会议自2002年开始举办,每年一届,通常在中国境内的某个城市举行。NLPCC已成为中国自然语言处理领域的重要学术盛会之一,吸引了众多国内外专家学者参与。该会议每年还会颁发最佳论文奖、最佳学生论文奖等奖项,以鼓励和表彰优秀的研究成果和研究人员。源数据集所在网址如下 :
源数据集
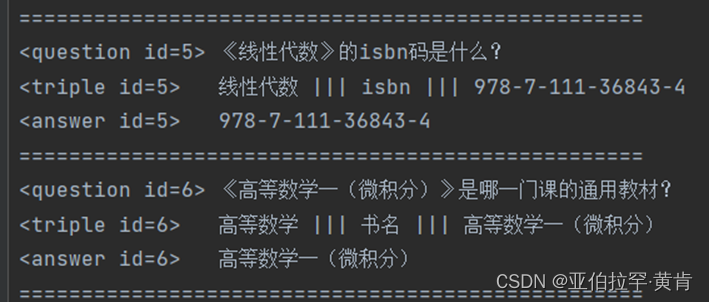
在本项目中,所使用的数据集是经过预处理的三元组数据。这些三元组数据包含了实体之间的关系和属性信息:
预处理过的数据集
其中包含了两个文件:一个是nlpcc-iccpol-2016.kbqa.training-data,另一个是nlpcc-iccpol-2016.kbqa.testing-data。分别是训练数据和测试数据。
内容如下:
2.切分数据。
- training-data样本数量为14609,testing-data样本数量为9870 。将文件重新切分一下,划分为train.txt,test.txt,dev.txt三个文件。划分如下:(运行 1_split_data.py )
- 将nlpcc-iccpol-2016.kbqa.testing-data 中的对半分,一半变成验证集(dev.text),一半变成测试集(test.txt)。
- nlpcc-iccpol-2016.kbqa.training-data 保持不变,直接复制成为训练集 train.txt。
3.构造命名实体识别(NER)数据集 (运行2-ner-data.py)
- 常见的命名实体识别的数据集实体类型包括国籍(CONT)、教育背景(EDU)、地名(LOC)、人名(NAME)、组织名(ORG)、专业(PRO)、民族(RACE)、职称(TITLE)。因为本系统只针对nlpcc的数据集做智能问答系统,故只定义一种数据类型LOC,并且以nlqcc的数据集作为训练数据。所以需要对nlqcc的数据做进一步处理。
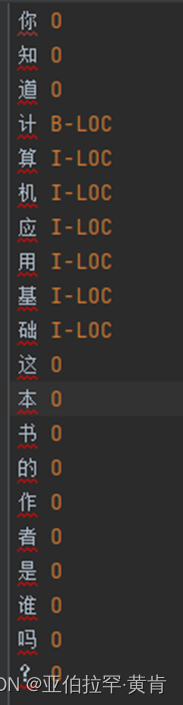
处理流程如下:首先,先检查每一行中是否包含 question 和 triple 两个字符串。虽然此系统只需要nlqcc数据集中的问题,但也需要得到问题中的实体作为标注的依据。如果发现包含这两个字符串中的一个,就将该行去除开头和结尾的空格并存储在 q_str 或 t_str 变量中。 - 当遇到 ==== 这个分隔符时,说明已经是新的一个样本了。就可以将 q_str 和 t_str 进一步处理,提取出t_str 中的所有实体,将它们存储在 entities 变量中。
- 接下来,代码将检查 entities 是否在 q_str 中出现,并将 q_str 拆分成一个字符列表 q_list,将其用空格分隔开并附加到 ner_list 后面,最后在 ner_tag_list 中附加相应的标记序列。
具体地说,代码会将实体标记为 “B-LOC”(实体的开始)和 “I-LOC”(实体的中间或结尾),并将相应的标记附加到 ner_tag_list 中。完成后,代码会将 ner_list 和 ner_tag_list 中的所有标记和字符以及空格都合并成一个字符串列表。
结果如下:
4.制作知识库。
先需要将数据的问题,实体关系,答案制作成一个csv(运行3-q-t-a-data.py)。结果如下:

接着运行4-load_dbdata.py,将数据更新到数据库上面。
5.构建属性相似度的数据
- 前文提到,如果我们输入的问题是“苏琳是男的吗?”,识别出“苏琳”这一实体后,当在数据库中查询到关于“苏琳”的数据后,因为数据库中关于“苏琳”这一数据的实体关系(属性)并不存在于问题当中,所以无法给出准确的答案,这个时候就需要利用到我们训练的第二个模型,BertForSequenceClassification模型。BertForSequenceClassification模型的作用简而言之就是判断我们提问的问题和知识库中存在的实体关系(属性)之间的关联,以此来找到准确的答案。所以数据集应该包含问题,属性,标签。
结果如下:

三.训练模型。
1. BertCrf模型(运行NER_main.py)
BertCrf模型是一个结合了BertForTokenClassification和条件随机场(CRF)的模型,用于从问题中识别实体。
调用transformers下的BertForTokenClassification来创建MLM模型,然后在模型后面再接一个crf模型。
模型训练时的数据(模仿谷歌官网Bert模型对数据的处理方式处理):
可以这么理解:
Input_ids:将输入到的词映射到模型当中的字典ID。
Attention_mask:要拿来mask的位置。在此处可以认为是判断是否有训练意义的标志。
Token_type_ids:在此处可以认为是segment_ids,因为是一个句子一个句子训练,所以都是第一个句子,都为0。
Labels_ids:文字对应的标签索引。(CRF_LABELS = [“O”, “B-LOC”, “I-LOC”])
评估结果如下:

2.BertForSequenceClassification模型(运行SIM_main.py)

模型训练时的数据(模仿谷歌官网Bert模型对数据的处理方式处理):

Input_ids:将输入到的词映射到模型当中的字典ID。
Attention_mask:要拿来mask的位置。在此处可以认为是判断是否有训练意义的标志。
Token_type_ids:在此处可以认为是属性词所在的位置,即segment_ids。
Labels:属性是否对应问题的标签。
评估结果如下:

四.搭建系统。(运行test_pro.py)
- 现在我们已经有了训练好的BertCrf模型和BertForSequenceClassification模型,分别保存为best_ner.bin和best_sim.bin,一个用于识别出问题中的实体,一个用于问题和属性相关性的判断。

参考文章:
Bert谷歌地址:https://github.com/google-research/bert
基于BERT模型的知识库问答(KBQA)系统
Pytorch: 命名实体识别: BertForTokenClassification/pytorch-crf
TensorFlow:NLP自然语言处理,通用框架BERT项目实战,唐博士带你快速入门!
相关文章:
基于Bert的知识库智能问答系统
项目完整地址: 可以先看一下Bert的介绍。 Bert简单介绍 一.系统流程介绍。 知识库是指存储大量有组织、有结构的知识和信息的仓库。这些知识和信息被存储为实体和实体关系的形式,通常用于支持智能问答系统。在一个知识库中,每个句子通常来说…...

libapparmor非默认目录构建和安装
在AppArmor零知识学习五、源码构建(2)中,详细介绍了libapparmor的构建步骤,但那完全使用的是官网给出的默认参数。如果需要将目标文件生成到指定目录而非默认的/usr,则需要进行一些修改,本文就来详述如何进…...
2023-04-14 算法面试中常见的查找表问题
2023-04-14 算法面试中常见的查找表问题 1 Set的使用 LeetCode349号问题:两个数组的交集 给定两个数组,编写一个函数来计算它们的交集。示例 1:输入: nums1 [1,2,2,1], nums2 [2,2] 输出: [2] 示例 2:输入: nums1 [4,9,5], nums2 [9,4,9,8,4] 输出:…...
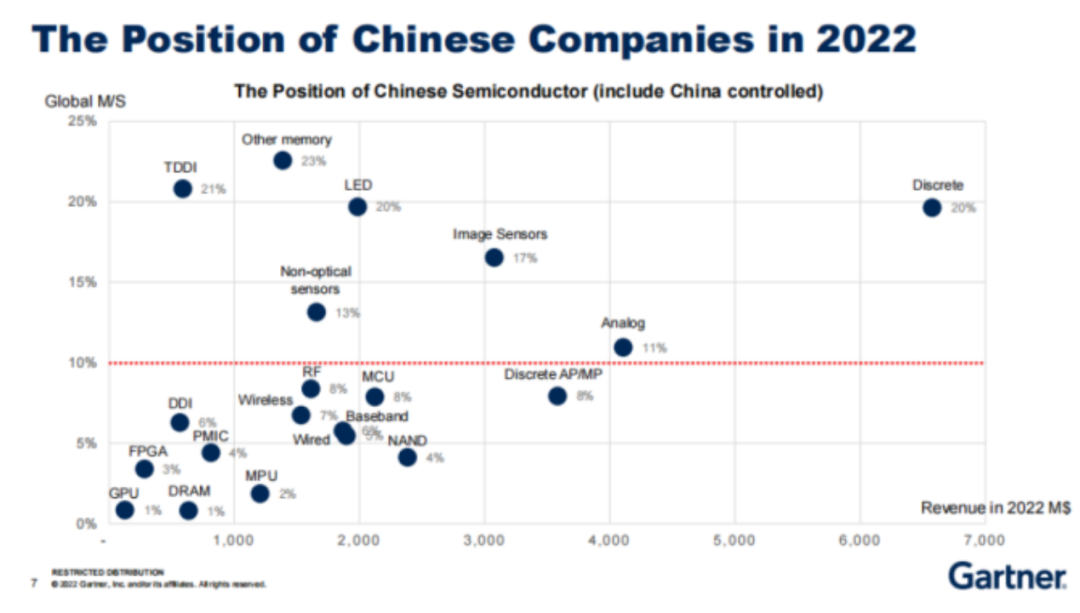
从TOP25榜单,看半导体之变
据SIA报告显示,2022年全球半导体销售额创历史新高达到5740亿美元。尽管2022年下半年,半导体市场出现了周期性的低迷,但其全年的销售额相较2021年增长了3.3%。 近日,市调机构Gartner发布了全球以及中国大陆TOP25名半导体厂商的排名…...

[异常]java常见异常
Java.io.NullPointerException null 空的,不存在的NullPointer 空指针 空指针异常,该异常出现在我们操作某个对象的属性或方法时,如果该对象是null时引发。 String str null; str.length();//空指针异常 上述代码中引用类型变量str的值为…...
gpt4all保姆级使用教程! 不用联网! 本地就能跑的GPT
原文:gpt4all保姆级使用教程! 不用联网! 本地就能跑的GPT 什么是gpt4all gpt4all是在大量干净数据上训练的一个开源聊天机器人的生态系统。它不用科学上网!甚至可以不联网!本地就能用,像这样↓: 如何使用ÿ…...
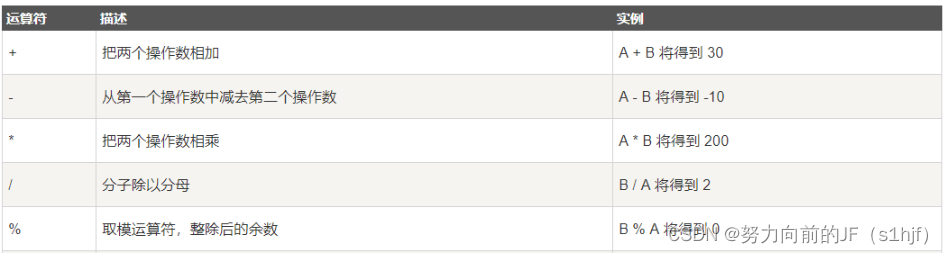
AcWing语法基础班 1.1 变量、输入输出、表达式和顺序语句
预备知识 首先先来了解一下最简单的C代码。 本文的所有代码操作均在AcWing的AC Editor中 #include <iostream>using namespace std;int main(){cout << "Hello World" << endl;return 0; }然后使用编译(点击调试,再点击运…...
DC:5靶机通关详解
信息收集 漏洞发现 扫个目录 发现存在footer.php 查看,发现好像没什么用 参考他人wp得知thankyou.php会包含footer.php 可以通过传参来包含别的文件 但是我们不知道参数,这里用fuzz来跑参数 这里用wfuzz的时候报错了 解决方法如下 卸载 sudo apt --purge remove python3-pycu…...
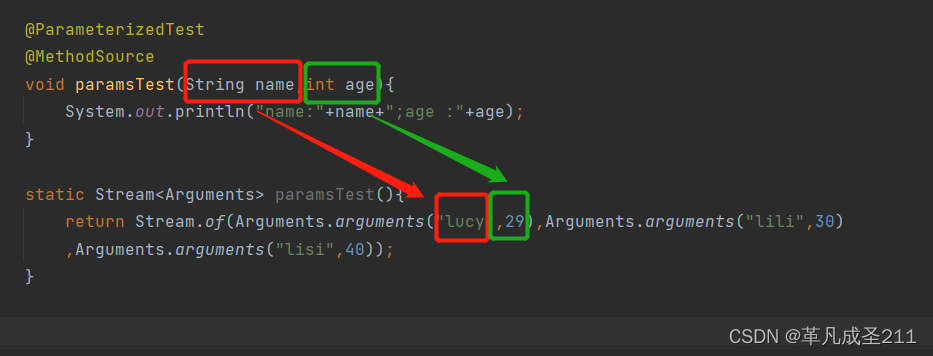
【测试开发篇9】Junit框架
目录 一、认识Junit框架 Junit和Selenium的关系是什么 导入Junit框架common-io包 二、Junit框架的使用 2.1Junit有哪些常用注解 2.1.1Test注解 2.1.2BeforeEach 2.1.3BeforeAll 2.1.4AfterAll 2.1.5AfterEach 2.2Junit的断言 Assertions.assertEquals(期待值&#…...

《Spring MVC》 第五章 实现RESTful
前言 教授大家如何实现RESTful 1、什么是RESTful resource Representational State Transfer 的缩写,就是“表现层资源表述状态转移” 1.1、Resource(资源) web应用的文件,uri定位 1.2、Representation(资源的描…...

Last Week in Milvus
What’s New Core Updates #23353 在 2.3 版本中, milvus 和 knowhere 引擎会移除了 Annoy 索引。Annoy 索引在性能和召回率方面均不如 IVF、HNSW 等索引,维护成本比较高所以经过讨论决定在 2.3 中移出 Annoy 索引的支持,有使用的用户要注意…...
Cursor IDE一个GPT4人工智能自动程序编辑器
让我们来了解一下Cursor IDE是什么。Cursor IDE是一个新型的编程工具,可以通过它生成、编辑以及与人工智能进行交互分析代码。官方网站上的三个单词“Build Software. Fast.”(快速构建软件)以及“Write, edit, and chat about your code wit…...

PPO算法-理论篇
1. Policy Gradient 【李宏毅深度强化学习笔记】1、策略梯度方法(Policy Gradient) 李宏毅深度强化学习-B站 2. PPO PPO 算法 PPO算法更新过程如下: 初始化policy参数 θ 0 \theta^0 θ0在每一步迭代中: 使用 θ k \theta^k …...

【现货】AP6317 同步3A锂电充电芯片 带短温度保护
AP6317是一款面向5V交流适配器的3A锂 离子电池充电器。它是采用800KHz固定频率的同 步降压型转换器,因此具有高达92%以上的充电效 率,自身发热量极小。 包括完整的充电终止电路、自动再充 电和一个精确度达1%的4.2V预设充电电压,内 部集成了防…...

MyBatis详解(2)
8、自定义映射resultMap 8.1、resultMap处理字段和属性的映射关系 若字段名和实体类中的属性名不一致,则可以通过resultMap设置自定义映射 <!--resultMap:设置自定义映射属性:id:表示自定义映射的唯一标识type:查询…...

2023-04-14 使用纯JS实现一个2048小游戏
文章目录 一.实现思路1.2048的逻辑2.移动操作的过程中会有三种情况 二.代码部分:分为初始化部分和移动部分1.初始化部分1.1.生成第一个方块:1.2.生成第二个方块: 2.移动过程部分: 三.实现代码1.HTML部分2.CSS部分3.JS部分3.1.game对象的属性3.2.game对象的start方法3.3.game对象…...

C++入门(3)
C入门 1.auto关键字(C11)1.1. 类型别名的思考1.2. auto简介1.3. auto使用情景1.4. auto的使用细则1.5. auto不能推导的场景 1.auto关键字(C11) 1.1. 类型别名的思考 随着程序越来越复杂,程序中用到的类型也越来越复杂…...
【亲测有效】更新了WIN11之后 右键无 新建WORD,PPT,EXCEL 选项 问题 解决方案
原本正常的正版系统,在昨天4月自动更新安装之后,发现右键找 不到新建文档了,word,ppt,excel都不见了。 看了网上大神的方法 Win11安装了Office右键没有新建Excel选项怎么办? - 知乎 可以解决一部分 官方解决方案,亲…...

2023年4月北京/西安/郑州/深圳CDGA/CDGP数据治理认证考试报名
DAMA认证为数据管理专业人士提供职业目标晋升规划,彰显了职业发展里程碑及发展阶梯定义,帮助数据管理从业人士获得企业数字化转型战略下的必备职业能力,促进开展工作实践应用及实际问题解决,形成企业所需的新数字经济下的核心职业…...
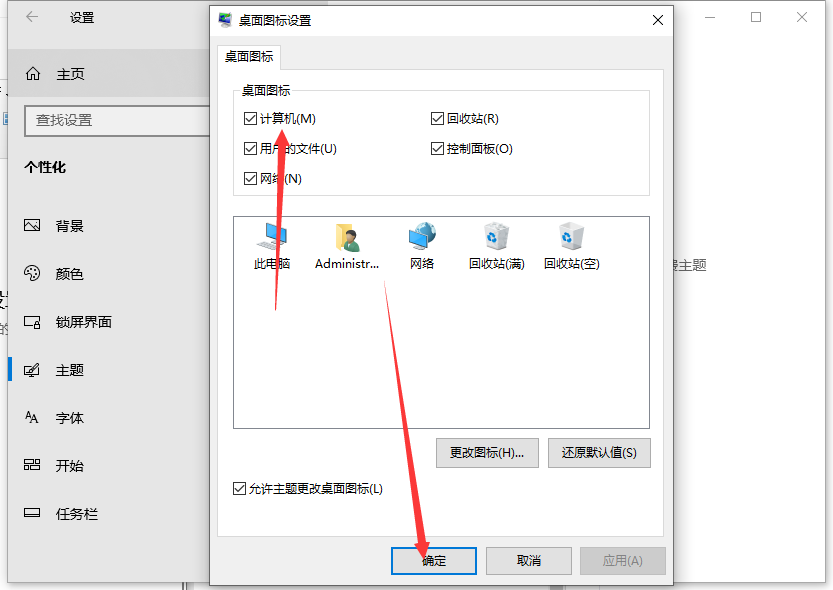
Win10桌面我的电脑怎么调出来?最简单方法教学
Win10桌面我的电脑怎么调出来?有用户发现自己的电脑桌面没有我的电脑这个程序图标,每次要访问磁盘的时候,开启都非常的麻烦。那么怎么将这个图标设置到桌面显示呢?接下来我们一起来看看以下的解决方法吧。 方法一: 在开…...

完整实战指南:使用N_m3u8DL-RE高效解决流媒体下载难题
完整实战指南:使用N_m3u8DL-RE高效解决流媒体下载难题 【免费下载链接】N_m3u8DL-RE Cross-Platform, modern and powerful stream downloader for MPD/M3U8/ISM. English/简体中文/繁體中文. 项目地址: https://gitcode.com/GitHub_Trending/nm3/N_m3u8DL-RE …...

Windows Defender终极移除指南:高效卸载13项核心服务完整教程
Windows Defender终极移除指南:高效卸载13项核心服务完整教程 【免费下载链接】windows-defender-remover A tool which is uses to remove Windows Defender in Windows 8.x, Windows 10 (every version) and Windows 11. 项目地址: https://gitcode.com/gh_mirr…...
技术解析与应用前景)
量子私有信息检索(QPIR)技术解析与应用前景
1. 量子私有信息检索技术概述量子私有信息检索(Quantum Private Information Retrieval, QPIR)是密码学领域的一项突破性技术,它允许用户从数据库中检索特定条目而不泄露被查询的是哪个条目。这项技术的核心价值在于解决了隐私保护与数据获取…...

避坑指南:在Unity 2022 LTS中配置XCharts插件时遇到的3个常见问题及解决方法
Unity 2022 LTS中XCharts插件实战避坑手册 当数据可视化成为现代应用的核心需求时,Unity开发者常会选择XCharts这类开源图表插件来快速实现专业级图表展示。但在实际项目落地过程中,版本兼容性、环境配置和平台适配等问题往往会让开发进程意外卡壳。本文…...
:多智能体沙箱与工具配置)
OpenClaw从入门到应用——工具(Tools):多智能体沙箱与工具配置
通过OpenClaw实现副业收入:《OpenClaw赚钱实录:从“养龙虾“到可持续变现的实践指南》 概述 在多智能体设置中,每个智能体现在可以拥有自己的: 沙箱配置(agents.list[].sandbox 会覆盖 agents.defaults.sandbox&…...

AI Agent架构深度解析:从核心原理到工程实践
1. 项目概述:一次关于AI Agent的深度技术探险最近在GitHub上看到一个名为“tvytlx/ai-agent-deep-dive”的项目,光看标题就让人眼前一亮。这显然不是一个简单的“Hello World”式教程,而是一次对AI Agent(智能体)技术的…...

CI/CD安全最佳实践:保护软件交付流程
CI/CD安全最佳实践:保护软件交付流程 一、CI/CD安全最佳实践概述 1.1 CI/CD安全最佳实践的定义 CI/CD安全最佳实践是指在持续集成和持续部署流程中实施的安全策略和措施。它涵盖代码提交、构建、测试、部署等各个阶段的安全防护。 1.2 CI/CD安全最佳实践的价值 安全…...

Arm Cortex-A35 Cycle Model技术解析与SoC集成实战
1. Arm Cortex-A35 Cycle Model技术解析在SoC设计领域,虚拟平台验证已成为不可或缺的关键环节。作为Armv8-A架构中的能效比优化核心,Cortex-A35处理器通过Cycle Model提供了RTL级精度的硬件行为模拟能力。我在多个车载SoC项目中验证发现,其Cy…...

MedAgentBench:大模型临床决策能力评估基准详解与应用
1. 项目概述:当大模型成为医疗决策的“实习生” 最近在医疗AI的圈子里,一个名为“MedAgentBench”的开源项目引起了不小的讨论。这个由斯坦福机器学习组(Stanford ML Group)发布的项目,其核心目标非常明确:…...
)
告别闪烁屏!瑞芯微RK3399开发板Debian系统烧写保姆级教程(含DriverAssistant v5.1.1 + AndroidTool v2.69)
RK3399开发板Debian系统烧写实战:从屏幕闪烁到完美显示的终极解决方案 当你在RK3399开发板上成功烧写Debian系统后,最期待的莫过于看到系统稳定运行的画面。然而,不少开发者却遭遇了屏幕闪烁的困扰——这个问题看似简单,背后却隐藏…...