Fluid-数据编排能力原理解析
前言
本文对Fluid基础功能-数据编排能力进行原理解析。其中涉及到Fluid架构和k8s csi driver相关知识。建议先了解相关概念,
为了便于理解,本文使用JuiceFS作为后端runtime引擎。
原理概述
Fuild数据编排能力,主要是在云原生环境中,能让用户在使用远端存储时,只需简单声明几个对象,即可像使用本地存储一样简单。无需关心后端的繁琐配置,和数据存储、拉取过程。甚至无需关心后端的存储实现方式。
该能力主要利用dataSet和Runtime以及对应的controller组件实现。
dataset是用于告诉Fluid,在哪里能够找到所需要的数据,比如对于JuiceFS,指的是 JuiceFS 的子目录,是用户在 JuiceFS 文件系统中存储数据的目录。
runtime这里根据后端实际引擎不同,runtime的实现形式有多种,比如AlluxioRuntime、JuiceFSRuntime等,这些都是k8s的CRD。
以JuiceFSRuntime为例,它用于声明一个juiceFS的最小化集群,包括worker副本数量,worker的缓存形式(mem、ssd、hdd),worker的缓存大小等。runtime-controller根据该声明,部署相应的juiceFS组件。
用户使用时,只需要在pod中使用同名的pvc即可。
工作流程梳理
若字体看不清,可点击图片查看大图:
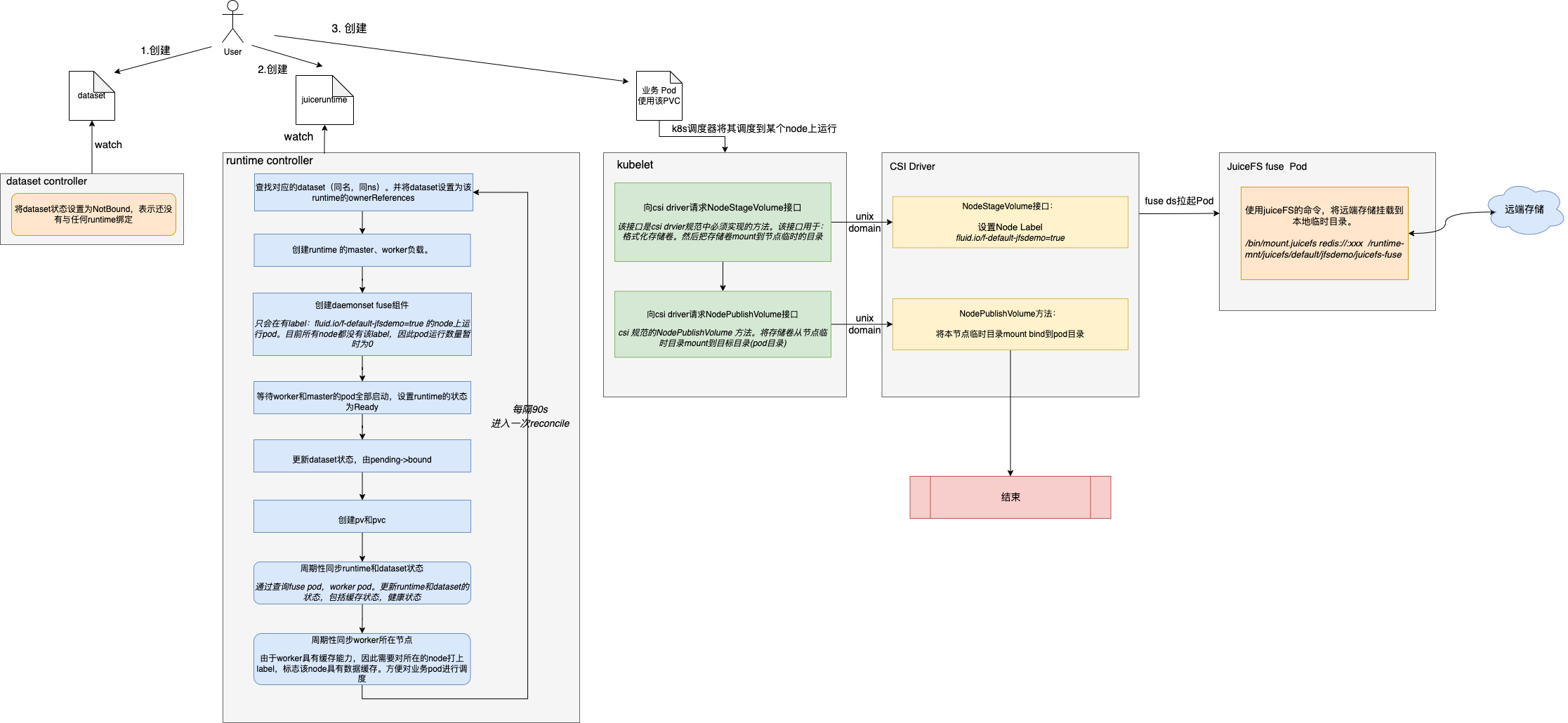
详细流程解析
一、用户创建Dataset
apiVersion: data.fluid.io/v1alpha1
kind: Dataset
metadata:name: jfsdemo
spec:mounts:- name: testmountPoint: "juicefs:///demo"options:bucket: "<bucket>"mounts字段:
name:juiceFS中创建的文件系统名称
mountPoint:指的是 JuiceFS 的子目录,是用户在 JuiceFS 文件系统中存储数据的目录,以 juicefs:// 开头;如 juicefs:///demo 为 JuiceFS 文件系统的 /demo 子目录。
options.bucket:Bucket URL。例如使用 S3 作为对象存储,bucket 为对象存储URL,如果使用其他,比如minio,mysql,也为对应URL。
二、Dataset Controller处理Dataset
controller监听到dataset被创建,将dataset状态设置为NotBound,表示还没有与任何runtime绑定。
三、用户创建JuiceFSRuntime
apiVersion: data.fluid.io/v1alpha1
kind: JuiceFSRuntime
metadata:name: jfsdemo
spec:replicas: 1tieredstore:levels:- mediumtype: MEMpath: /dev/shmquota: 40960mudiumtype:worker缓存形式,MEM,SSD,HDD
path:worker的缓存目录
quota:缓存大小,单位Mi
四、runtime controller处理JuiceFSRuntime
controller监听到JuiceFSRuntime被创建,开始一系列对于juiceFS 集群的创建操作。
1)查找对应的dataset(同名,同ns)。并将dataset设置为该runtime的ownerReferences。
...
if !utils.ContainsOwners(objectMeta.GetOwnerReferences(), dataset) {return r.AddOwnerAndRequeue(ctx, dataset)}
...2)创建runtime 的master负载。
根据runtime填入的参数,通过helm进行安装
valuefileName, err := j.generateJuicefsValueFile(runtime)
...found, err := helm.CheckRelease(j.name, j.namespace)
...return helm.InstallRelease(j.name, j.namespace, valuefileName, chartName)3)更新runtime的状态为NotReady
4)创建runtime的worker负载
根据runtime填入的参数,通过helm进行安装,同时设置pod 反亲和性,worker分散在不同节点
func (e *Helper) SetupWorkers(runtime base.RuntimeInterface,currentStatus datav1alpha1.RuntimeStatus,workers *appsv1.StatefulSet) (err error) {desireReplicas := runtime.Replicas()if *workers.Spec.Replicas != desireReplicas {// workerToUpdate, err := e.buildWorkersAffinity(workers)workerToUpdate, err := e.BuildWorkersAffinity(workers)if err != nil {return err}workerToUpdate.Spec.Replicas = &desireReplicaserr = e.client.Update(context.TODO(), workerToUpdate)if err != nil {return err}
5)创建daemonset fuse组件
且只会在有label:fluid.io/f-default-jfsdemo=true 的node上运行pod。目前所有node都没有该label,因此fuse 的ds虽然部署成功,但是pod运行数量暂时为0。什么时候会给node打上该label呢,继续往后看。
6)等待worker和master的pod全部启动,设置runtime的状态为Ready
func (j *JuiceFSEngine) CheckAndUpdateRuntimeStatus() (ready bool, err error) {......runtimeToUpdate.Status.WorkerNumberReady = int32(workers.Status.ReadyReplicas)runtimeToUpdate.Status.WorkerNumberUnavailable = int32(*workers.Spec.Replicas - workers.Status.ReadyReplicas)runtimeToUpdate.Status.WorkerNumberAvailable = int32(workers.Status.CurrentReplicas)if workers.Status.ReadyReplicas > 0 {if runtime.Replicas() == workers.Status.ReadyReplicas {runtimeToUpdate.Status.WorkerPhase = data.RuntimePhaseReadyworkerReady = true} else if workers.Status.ReadyReplicas >= 1 {runtimeToUpdate.Status.WorkerPhase = data.RuntimePhasePartialReadyworkerReady = true}7)更新dataset状态,由pending->bound
func (j *JuiceFSEngine) BindToDataset() (err error) {return j.UpdateDatasetStatus(datav1alpha1.BoundDatasetPhase)
}8)创建pv和pvc
controller接下来创建pv和pvc
创建pv
PersistentVolumeSource: v1.PersistentVolumeSource{CSI: &v1.CSIPersistentVolumeSource{Driver: common.CSIDriver,VolumeHandle: pvName,VolumeAttributes: map[string]string{common.FluidPath: mountPath,common.MountType: mountType,其中pv的参数需要注意:
driver:所使用的csi driver的名称。这个值必须与 CSI 驱动程序在 GetPluginInfoResponse 中返回的值相对应;CSI 驱动程序也使用该值来辨识哪些 PV 对象属于该 CSI 驱动程序。这里common.CSIDriver就是:fuse.csi.fluid.io
VolumeHandle:唯一标识卷的字符串值。 该值必须与 CSI 驱动在 CreateVolumeResponse 的 volume_id 字段中返回的值相对应;在所有对 CSI 卷驱动程序的调用中,引用该 CSI 卷时都使用此值作为 volume_id 参数
spec:
......csi:driver: fuse.csi.fluid.io //csi drivervolumeAttributes:fluid_path: /runtime-mnt/juicefs/default/jfsdemo/juicefs-fusemount_type: JuiceFSvolumeHandle: default-jfsdemopersistentVolumeReclaimPolicy: RetainstorageClassName: fluidvolumeMode: Filesystem9)周期性同步runtime和dataset状态
通过查询fuse pod,worker pod。更新runtime和dataset的状态。包括
根据查询worker pod的metrics监控信息,查询缓存状态。并更新runtime和dataset的缓存数据状态,缓存进度。
根据worker pod数量是否正常,设置runtime和dataset的状态是否健康。
10)同步worker所在节点
由于worker具有缓存能力,因此需要对所在的node打上label,标志该node具有数据缓存。方便对业务pod进行调度。
查询所有worker所在节点,并与当前已经打上缓存label的节点进行对比,worker所在节点没有label的,需要加上。worker不在节点上有label的,需要删除。
五、创建业务pod,并使用该pvc
apiVersion: v1
kind: Pod
metadata:name: demo-app
spec:containers:- name: demoimage: nginxvolumeMounts:- mountPath: /dataname: demovolumes:- name: demopersistentVolumeClaim:claimName: jfsdemok8s调度器将其调度到某个node上运行。将pod信息与node绑定,接下来该节点上的kubelet接手pod,开始pod的真正创建流程。
六、kubelet向csi driver请求NodeStageVolume
kubelet发现pod有pvc的需求,kubelet的volumemanager组件会根据pvc声明所使用的csi driver名称:fuse.csi.fluid.io。查询当前集群中注册的csi driver,一旦发现匹配,就根据注册的信息,向csi driver发送请求,让csi driver开始进行数据卷挂载。
请求的接口是:NodeStageVolume。该接口也是csi drvier规范中必须实现的方法。该接口用于:如果存储卷没有格式化,首先要格式化。然后把存储卷mount到一个临时的目录(这个目录通常是节点上的一个全局目录)。
kubelet代码:
k8s.io/kubernetes/pkg/volume/csi/csi_attacher.go
func (c *csiAttacher) MountDevice(spec *volume.Spec, devicePath string, deviceMountPath string) error {.....fsType := csiSource.FSTypeerr = csi.NodeStageVolume(ctx,csiSource.VolumeHandle,publishContext,deviceMountPath,fsType,accessMode,nodeStageSecrets,csiSource.VolumeAttributes,mountOptions)....}七、csi driver 设置Node label
fluid的csi driver接收到kubelet发送的NodeStageVolume请求后,设置所在Node的label:fluid.io/f-default-jfsdemo=true
fluid/pkg/csi/plugins/nodeserver.go
// 2. Label nodefuseLabelKey := common.LabelAnnotationFusePrefix + namespace + "-" + namevar labelsToModify common.LabelsToModifylabelsToModify.Add(fuseLabelKey, "true")node, err := kubeclient.GetNode(ns.client, ns.nodeId)if err != nil {glog.Errorf("NodeStageVolume: can't get node %s: %v", ns.nodeId, err)return nil, errors.Wrapf(err, "NodeStageVolume: can't get node %s", ns.nodeId)}if _, ok := node.Labels[fuseLabelKey]; !ok {_, err = utils.ChangeNodeLabelWithPatchMode(ns.client, node, labelsToModify)if err != nil {glog.Errorf("NodeStageVolume: error when patching labels on node %s: %v", ns.nodeId, err)return nil, errors.Wrapf(err, "NodeStageVolume: error when patching labels on node %s", ns.nodeId)}设置该label后,之前部署的fuse daemonset会检测到该node存在符合条件label,就会在node上拉起fuse pod。
八、juice fuse pod进行本地目录挂载
fuse pod在节点上启动后,会使用juiceFS的命令,将远端存储挂载到本地临时目录。
fuse内部执行命令:
/usr/local/bin/juicefs format --storage=mysql --bucket=mysql2.redis.svc.linux.local:3306/test --access-key=${ACCESS_KEY} --secret-key=${SECRET_KEY} ${METAURL} mysql/bin/mount.juicefs redis://:123456@mymaster,redis-0.redis.redis.svc.linux.local,redis-1.redis.redis.svc.linux.local,redis-2.redis.redis.svc.linux.local:26379/3 /runtime-mnt/juicefs/default/jfsdemo/juicefs-fuse /runtime-mnt/juicefs/default/jfsdemo/juicefs-fuse 就是本节点的临时存储目录。
九、kubelet向csi driver请求NodePublishVolume
csi 规范的NodePublishVolume 方法。将存储卷从节点临时目录mount到目标目录(pod目录)。
k8s.io/kubernetes/pkg/volume/csi/csi_mounter.go
func (c *csiMountMgr) SetUpAt(dir string, mounterArgs volume.MounterArgs) error {err = csi.NodePublishVolume(ctx,volumeHandle,readOnly,deviceMountPath,dir,accessMode,publishContext,volAttribs,nodePublishSecrets,fsType,mountOptions,)
}十、csi driver 执行NodePublishVolume方法
fluid的csi driver接收到kubelet发送的NodePublishVolume请求后,将本节点临时目录mount bind到pod目录。
func (c *csiMountMgr) SetUpAt(dir string, mounterArgs volume.MounterArgs) error {err = csi.NodePublishVolume(ctx,volumeHandle,readOnly,deviceMountPath,dir,accessMode,publishContext,volAttribs,nodePublishSecrets,fsType,mountOptions,)
}比如pod目录:/var/lib/kubelet/pods/15b00274-11f2-4dde-9fdf-e590a6284e20/volumes/kubernetes.io~csi/default-jfsdemo/mount
该目录也是在节点上,也通过docker -v的形式挂载到pod内部,因此该目录的改动也能够在pod内部感知到。
以上,就完成了将远端存储挂载到pod内部的操作。
相关文章:
Fluid-数据编排能力原理解析
前言本文对Fluid基础功能-数据编排能力进行原理解析。其中涉及到Fluid架构和k8s csi driver相关知识。建议先了解相关概念,为了便于理解,本文使用JuiceFS作为后端runtime引擎。原理概述Fuild数据编排能力,主要是在云原生环境中,能…...
并发线程、锁、ThreadLocal
并发编程并发编程Java内存模型(JMM)并发编程核心问题—可见性、原子性、有序性volatile关键字原子性原子类CAS(Compare-And-Swap 比较并交换)ABA问题Java中的锁乐观锁和悲观锁可重入锁读写锁分段锁自旋锁共享锁/独占锁公平锁/非公平锁偏向锁/轻量级锁/重…...

CMMI-结项管理
结项管理(ProjectClosing Management, PCM)是指在项目开发工作结束后,对项目的有形资产和无形资产进行清算;对项目进行综合评估;总结经验教训等。结项管理过程域是SPP模型的重要组成部分。本规范阐述了结项管理的规程&…...
网络通信协议是什么?
网络通信基本模式 常见的通信模式有如下2种形式:Client-Server(CS) 、 Browser/Server(BS) 实现网络编程关键的三要素 IP地址:设备在网络中的地址,是唯一的标识。 端口:应用程序在设备中唯一的标识。 协议: 数据在网络中传输的…...

阶段5:Java分布式与微服务实战
目录 第33-34周 Spring Cloud电商实战 一、Eureka-server模块开发 1、引入依赖 2、配置文件 3、启动注解 一、Eureka-server模块开发 第33-34周 Spring Cloud电商实战 一、Eureka-server模块开发 1、引入依赖 父项目依赖:cloud-mall-practice springboot的…...

我的创作纪念日
目录 机缘 收获 日常 憧憬 机缘 其实本来从大一上学期后半段(2017)就开始谢谢零星的博客,只不过当时是自己用hexo搭建了一个小网站,还整了个域名:jiayoudangdang.top,虽然这个早就过期; 后来发现了CSDNÿ…...
Qml学习——动态加载控件
最近在学习Qml,但对Qml的各种用法都不太熟悉,总是会搞忘,所以写几篇文章对学习过程中的遇到的东西做一个记录。 学习参考视频:https://www.bilibili.com/video/BV1Ay4y1W7xd?p1&vd_source0b527ff208c63f0b1150450fd7023fd8 目…...

设计模式之职责链模式
什么是职责链模式 职责链模式是避免请求发送者与接受者耦合在一起,让多个对象都可以接受到请求,从而将这些对象连接成一条链,并且沿着这条链传递请求,直到有对象处理为止。 职责链模式包含以下几个角色: …...

MySQL入门篇-MySQL 8.0 延迟复制
备注:测试数据库版本为MySQL 8.0 这个blog我们来聊聊MySQL 延迟复制 概述 MySQL的复制一般都很快,虽然有时候因为 网络原因、大事务等原因造成延迟,但是这个无法人为控制。 生产中可能会存在主库误操作,导致数据被删除了,Oracl…...
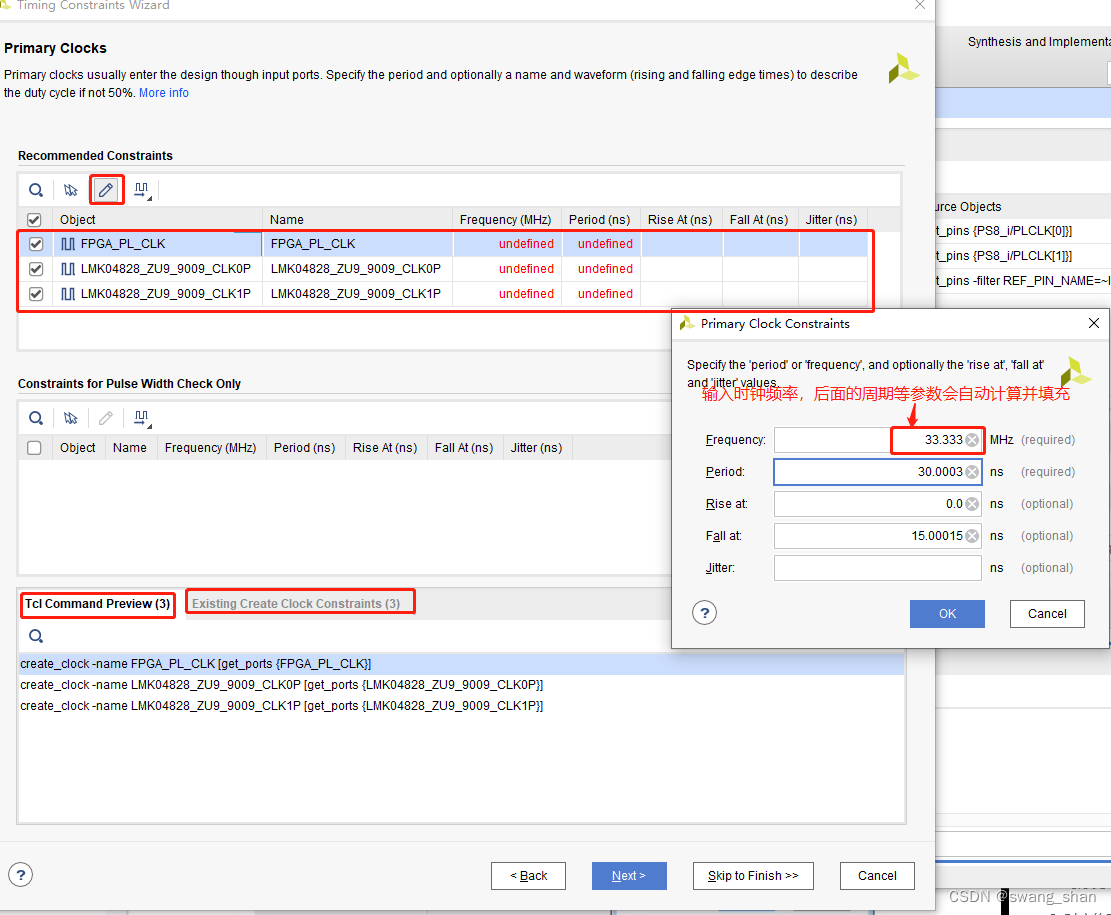
FPGA时序约束与分析 --- 实例教程(1)
注意: 时序约束辅助工具或者相关的TCL命令,都必须在 open synthesis design / open implemention design 后才能有效运行。 1、时序约束辅助工具 2、查看相关时序信息 3、一般的时序约束顺序 1、 时序约束辅助工具(1)时序约束编辑…...

go深拷贝和浅拷贝
1、深拷贝(Deep Copy)拷贝的是数据本身,创造一个样的新对象,新创建的对象与原对象不共享内存,新创建的对象在内存中开辟一个新的内存地址,新对象值修改时不会影响原对象值。既然内存地址不同,释…...

linux网络系统层面的配置、管理及操作命令汇总
前几篇文章一一介绍了LINUX进程管理控制命令,关于linux系统中的软件包管理内容等,作为一名运维工程师,前两天刚处理了一起linux网络层面的情况,那么今天这篇文章就以linux网络层面为主题吧。当说到linux网络系统层面,e…...

R数据分析:孟德尔随机化中介的原理和实操
中介本身就是回归,基本上我看到的很多的调查性研究中在中介分析的方法部分都不会去提混杂,都是默认一个三角形画好,中介关系就算过去了,这里面默认的逻辑就是前两步回归中的混杂是一样的,计算中介效应的时候就自动消掉…...

【C++】 类和对象 (下)
文章目录📕再谈构造函数1. 构造函数体赋值2. 初始化列表3. explicit 关键字📕static 成员1. 概念2. static 成员变量3. static 成员函数📕 友元1. 友元函数2. 友元类📕内部类📕编译器优化📕再谈构造函数 1…...

asp获取毫秒时间戳的方法 asp获取13位时间戳的方案
一、背景。时间戳就是计算当前与"1970-01-01 08:00:00"的时间差,在asp中通常是使用Datediff函数来计算两个日期差,代码:timestamp Datediff("s", "1970-01-01 08:00:00",now)返回结果:1675951060可…...
-- Python程序接入MySQL数据库)
Python基础篇(十五)-- Python程序接入MySQL数据库
程序运行时,数据都在内存中,程序终止时,需要将数据保存到磁盘上。为了便于程序保存和读取,并能直接通过条件快速查询到指定数据,数据库(Database)应运而生,本篇主要学习使用Python操作数据库,在…...
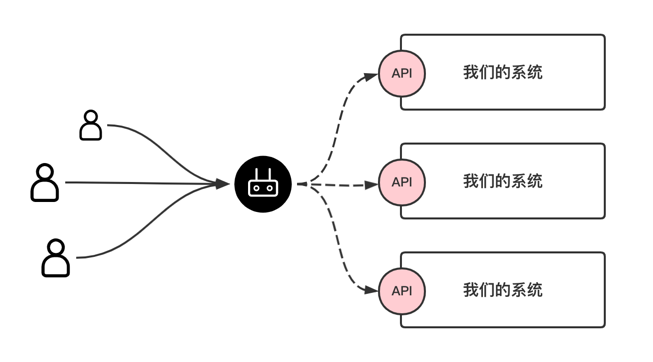
程序员不得不知道的 API 接口常识
说实话,我非常希望自己能早点看到本篇文章,大学那个时候懵懵懂懂,跟着网上的免费教程做了一个购物商城就屁颠屁颠往简历上写。 至今我仍清晰地记得,那个电商教程是怎么定义接口的: 管它是增加、修改、删除、带参查询…...
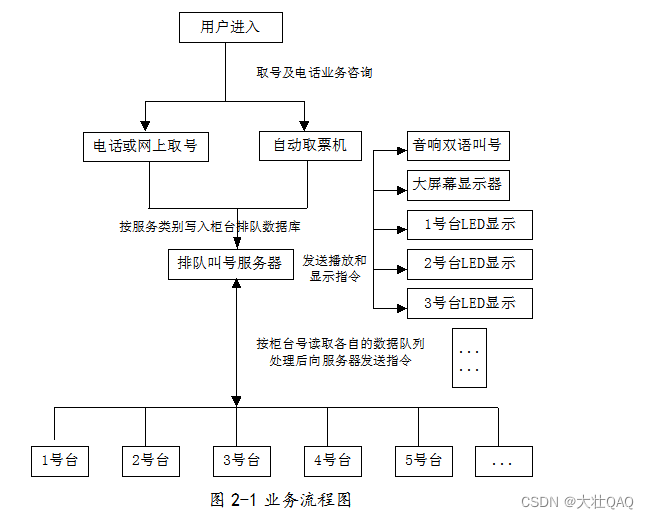
【项目精选】基于Java的银行排号系统的设计与实现
银行排号系统是为解决一些服务业营业大厅排队问题而设计的,它能够有效地提高工作人员的工作效率,也能够使顾客合理的安排等待时间,让顾客感到服务的公平公正。论文首先讨论了排号系统的背景、意义、应用现状以及研究与开发现状。本文在对C/S架…...
前端 基于 vue-simple-uploader 实现大文件断点续传和分片上传
文章目录一、前言二、后端部分新建Maven 项目后端pom.xml配置文件 application.ymlHttpStatus.javaAjaxResult.javaCommonConstant.javaWebConfig.javaCheckChunkVO.javaBackChunk.javaBackFileList.javaBackChunkMapper.javaBackFileListMapper.javaBackFileListMapper.xmlBac…...
解决报错: ERR! code 128npm ERR! An unknown git error occurred
在github下载的项目运行时,进行npm install安装依赖时,出现如下错误:npm ERR! code 128npm ERR! An unknown git error occurrednpm ERR! command git --no-replace-objects ls-remote ssh://gitgithub.com/nhn/raphael.gitnpm ERR! gitgithu…...

基于VitePress构建开源AI智能体框架深度中文文档站实战指南
1. 项目概述:一个为AI智能体框架量身打造的中文文档站如果你正在寻找一个能帮你把Claude、GPT这些大模型快速接入到微信、Telegram、飞书等聊天软件的开源框架,那你大概率会接触到OpenClaw(原名ClawdBot)。但当你兴冲冲地打开官方…...

芯片设计中的责任边界:从工程师素养到系统性流程构建
1. 从桥梁垮塌到芯片失效:工程师的责任边界在哪里?每次看到新闻里报道桥梁垮塌、大楼倾斜或者某个关键设备在运行中突然失效,我心里总会咯噔一下。作为一个在电子设计自动化(EDA)和半导体行业摸爬滚打了十几年的工程师…...

QProcess::FailedToStart “No program defined“。qtcreator用的好好的,然后就不能调试了
点击 项目-》运行-》执行档根本原因:执行档:路径为空 解决办法:添加这样执行档 就有路径了。就可以用了...

PiliPlus:如何用第三方B站客户端解锁终极观影体验?
PiliPlus:如何用第三方B站客户端解锁终极观影体验? 【免费下载链接】PiliPlus PiliPlus 项目地址: https://gitcode.com/gh_mirrors/pi/PiliPlus 你是否厌倦了官方B站客户端的广告轰炸?是否想要更纯净、更流畅的观影体验?P…...

告别模拟器!3种方法在Windows上直接安装Android应用
告别模拟器!3种方法在Windows上直接安装Android应用 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 想在Windows电脑上流畅运行Android应用,却厌…...

如何用开源工具Lano Visualizer让桌面音乐体验“看得见“?[特殊字符]
如何用开源工具Lano Visualizer让桌面音乐体验"看得见"?🎵 【免费下载链接】Lano-Visualizer A simple but highly configurable visualizer with rounded bars. 项目地址: https://gitcode.com/gh_mirrors/la/Lano-Visualizer 在数字时…...

MTKClient实用指南:三步解锁联发科设备的终极解决方案
MTKClient实用指南:三步解锁联发科设备的终极解决方案 【免费下载链接】mtkclient MTK reverse engineering and flash tool 项目地址: https://gitcode.com/gh_mirrors/mt/mtkclient MTKClient是一款专为联发科芯片设备设计的开源逆向工程与刷机工具&#x…...

虞城装修公司选哪家专业?业主正确对比装修公司的方法,看完不踩坑
在虞城准备装修的业主,大多都会纠结一个问题:虞城装修公司这么多,到底哪家更专业? 很多人都是第一次装修,不懂行、不会分辨,只会看价格、看广告,很容易被低价套路、中途增项、工艺偷工减料坑到崩…...

Perplexity ScienceDirect搜索响应延迟超8秒?3种底层协议优化策略+2个隐藏headers参数,实验室实测提速5.8倍
更多请点击: https://intelliparadigm.com 第一章:Perplexity ScienceDirect搜索响应延迟超8秒?3种底层协议优化策略2个隐藏headers参数,实验室实测提速5.8倍 ScienceDirect API 在与 Perplexity 的实时检索链路中常因 TLS 握手冗…...

HUM4D数据集:无标记人体动作捕捉的挑战与评估
1. HUM4D数据集概述HUM4D是一个专门针对无标记人体动作捕捉技术评估的基准数据集,由计算机视觉研究团队开发。这个数据集的核心价值在于填补了现有动作捕捉基准在复杂场景下的空白——那些包含快速运动、严重遮挡、深度突变和身份混淆的真实挑战。在动作捕捉领域&am…...