Doris(7):数据导入(Load)之Routine Load
例行导入功能为用户提供了义中自动从指定数据源进行数据导入的功能
1 适用场景
当前仅支持kafka系统进行例行导入。
2 使用限制
- 支持无认证的 Kafka 访问,以及通过 SSL 方式认证的 Kafka 集群。
- 支持的消息格式为 csv 文本格式。每一个 message 为一行,且行尾不包含换行符。
- 仅支持 Kafka 0.10.0.0(含) 以上版本。
3 基本原理
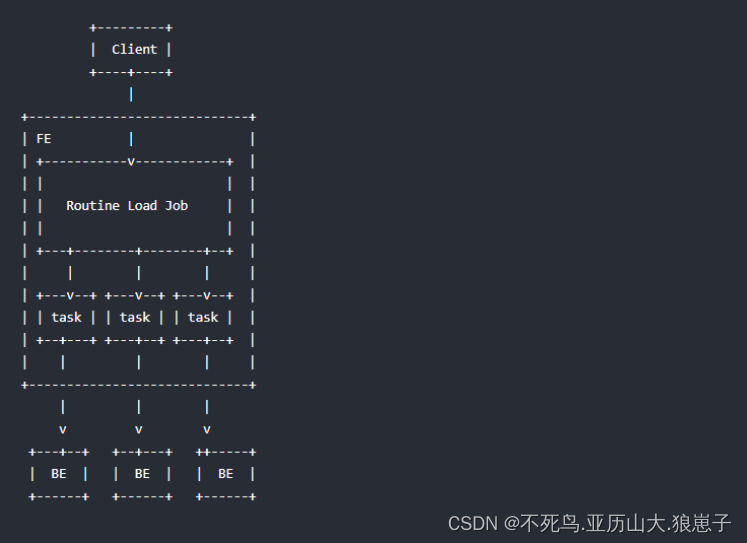
如上图,Client 向 FE 提交一个例行导入作业。
FE 通过 JobScheduler 将一个导入作业拆分成若干个 Task。每个 Task 负责导入指定的一部分数据。Task 被 TaskScheduler 分配到指定的 BE 上执行。
在 BE 上,一个 Task 被视为一个普通的导入任务,通过 Stream Load 的导入机制进行导入。导入完成后,向 FE 汇报。
FE 中的 JobScheduler 根据汇报结果,继续生成后续新的 Task,或者对失败的 Task 进行重试。整个例行导入作业通过不断的产生新的 Task,来完成数据不间断的导入。
4 前置操作
- 启动zookeeper集群(三台节点都启动):zkServer.sh start
- 启动kafka集群,创建topic,并向topic写入一批数据
5 创建例行导入任务
创建例行导入任务的的详细语法可以连接到 Doris 后,执行 HELP ROUTINE LOAD; 查看语法帮助。这里主要详细介绍,创建作业时的注意事项。
语法:
CREATE ROUTINE LOAD [db.]job_name ON tbl_name
[load_properties]
[job_properties]
FROM data_source
[data_source_properties]执行HELP ROUTINE LOAD; 查看语法帮助
Name: 'ROUTINE LOAD'
Description:例行导入(Routine Load)功能,支持用户提交一个常驻的导入任务,通过不断的从指定的数据源读取数据,将数据导入到 Doris 中。目前仅支持通过无认证或者 SSL 认证方式,从 Kakfa 导入文本格式(CSV)的数据。语法:CREATE ROUTINE LOAD [db.]job_name ON tbl_name[merge_type][load_properties][job_properties]FROM data_source[data_source_properties]1. [db.]job_name导入作业的名称,在同一个 database 内,相同名称只能有一个 job 在运行。2. tbl_name指定需要导入的表的名称。3. merge_type数据的合并类型,一共支持三种类型APPEND、DELETE、MERGE 其中,APPEND是默认值,表示这批数据全部需要追加到现有数据中,DELETE 表示删除与这批数据key相同的所有行,MERGE 语义 需要与delete on条件联合使用,表示满足delete 条件的数据按照DELETE 语义处理其余的按照APPEND 语义处理, 语法为[WITH MERGE|APPEND|DELETE]4. load_properties用于描述导入数据。语法:[column_separator],[columns_mapping],[where_predicates],[delete_on_predicates],[source_sequence],[partitions],[preceding_predicates]1. column_separator:指定列分隔符,如:COLUMNS TERMINATED BY ","默认为:\t2. columns_mapping:指定源数据中列的映射关系,以及定义衍生列的生成方式。1. 映射列:按顺序指定,源数据中各个列,对应目的表中的哪些列。对于希望跳过的列,可以指定一个不存在的列名。假设目的表有三列 k1, k2, v1。源数据有4列,其中第1、2、4列分别对应 k2, k1, v1。则书写如下:COLUMNS (k2, k1, xxx, v1)其中 xxx 为不存在的一列,用于跳过源数据中的第三列。2. 衍生列:以 col_name = expr 的形式表示的列,我们称为衍生列。即支持通过 expr 计算得出目的表中对应列的值。衍生列通常排列在映射列之后,虽然这不是强制的规定,但是 Doris 总是先解析映射列,再解析衍生列。接上一个示例,假设目的表还有第4列 v2,v2 由 k1 和 k2 的和产生。则可以书写如下:COLUMNS (k2, k1, xxx, v1, v2 = k1 + k2);3. where_predicates用于指定过滤条件,以过滤掉不需要的列。过滤列可以是映射列或衍生列。例如我们只希望导入 k1 大于 100 并且 k2 等于 1000 的列,则书写如下:WHERE k1 > 100 and k2 = 10004. partitions指定导入目的表的哪些 partition 中。如果不指定,则会自动导入到对应的 partition 中。示例:PARTITION(p1, p2, p3)5. delete_on_predicates表示删除条件,仅在 merge type 为MERGE 时有意义,语法与where 相同6. source_sequence:只适用于UNIQUE_KEYS,相同key列下,保证value列按照source_sequence列进行REPLACE, source_sequence可以是数据源中的列,也可以是表结构中的一列。7. preceding_predicatesPRECEDING FILTER predicate用于过滤原始数据。原始数据是未经列映射、转换的数据。用户可以在对转换前的数据前进行一次过滤,选取期望的数据,再进行转换。5. job_properties用于指定例行导入作业的通用参数。语法:PROPERTIES ("key1" = "val1","key2" = "val2")目前我们支持以下参数:1. desired_concurrent_number期望的并发度。一个例行导入作业会被分成多个子任务执行。这个参数指定一个作业最多有多少任务可以同时执行。必须大于0。默认为3。这个并发度并不是实际的并发度,实际的并发度,会通过集群的节点数、负载情况,以及数据源的情况综合考虑。例:"desired_concurrent_number" = "3"2. max_batch_interval/max_batch_rows/max_batch_size这三个参数分别表示:1)每个子任务最大执行时间,单位是秒。范围为 5 到 60。默认为10。2)每个子任务最多读取的行数。必须大于等于200000。默认是200000。3)每个子任务最多读取的字节数。单位是字节,范围是 100MB 到 1GB。默认是 100MB。这三个参数,用于控制一个子任务的执行时间和处理量。当任意一个达到阈值,则任务结束。例:"max_batch_interval" = "20","max_batch_rows" = "300000","max_batch_size" = "209715200"3. max_error_number采样窗口内,允许的最大错误行数。必须大于等于0。默认是 0,即不允许有错误行。采样窗口为 max_batch_rows * 10。即如果在采样窗口内,错误行数大于 max_error_number,则会导致例行作业被暂停,需要人工介入检查数据质量问题。被 where 条件过滤掉的行不算错误行。4. strict_mode是否开启严格模式,默认为关闭。如果开启后,非空原始数据的列类型变换如果结果为 NULL,则会被过滤。指定方式为 "strict_mode" = "true"5. timezone指定导入作业所使用的时区。默认为使用 Session 的 timezone 参数。该参数会影响所有导入涉及的和时区有关的函数结果。6. format指定导入数据格式,默认是csv,支持json格式。7. jsonpathsjsonpaths: 导入json方式分为:简单模式和匹配模式。如果设置了jsonpath则为匹配模式导入,否则为简单模式导入,具体可参考示例。8. strip_outer_array布尔类型,为true表示json数据以数组对象开始且将数组对象中进行展平,默认值是false。9. json_rootjson_root为合法的jsonpath字符串,用于指定json document的根节点,默认值为""。10. send_batch_parallelism整型,用于设置发送批处理数据的并行度,如果并行度的值超过 BE 配置中的 `max_send_batch_parallelism_per_job`,那么作为协调点的 BE 将使用 `max_send_batch_parallelism_per_job` 的值。 6. data_source数据源的类型。当前支持:KAFKA7. data_source_properties指定数据源相关的信息。语法:("key1" = "val1","key2" = "val2")1. KAFKA 数据源1. kafka_broker_listKafka 的 broker 连接信息。格式为 ip:host。多个broker之间以逗号分隔。示例:"kafka_broker_list" = "broker1:9092,broker2:9092"2. kafka_topic指定要订阅的 Kafka 的 topic。示例:"kafka_topic" = "my_topic"3. kafka_partitions/kafka_offsets指定需要订阅的 kafka partition,以及对应的每个 partition 的起始 offset。offset 可以指定从大于等于 0 的具体 offset,或者:1) OFFSET_BEGINNING: 从有数据的位置开始订阅。2) OFFSET_END: 从末尾开始订阅。3) 时间戳,格式必须如:"2021-05-11 10:00:00",系统会自动定位到大于等于该时间戳的第一个消息的offset。注意,时间戳格式的offset不能和数字类型混用,只能选其一。如果没有指定,则默认从 OFFSET_END 开始订阅 topic 下的所有 partition。示例:"kafka_partitions" = "0,1,2,3","kafka_offsets" = "101,0,OFFSET_BEGINNING,OFFSET_END""kafka_partitions" = "0,1","kafka_offsets" = "2021-05-11 10:00:00, 2021-05-11 11:00:00"4. property指定自定义kafka参数。功能等同于kafka shell中 "--property" 参数。当参数的 value 为一个文件时,需要在 value 前加上关键词:"FILE:"。关于如何创建文件,请参阅 "HELP CREATE FILE;"更多支持的自定义参数,请参阅 librdkafka 的官方 CONFIGURATION 文档中,client 端的配置项。示例:"property.client.id" = "12345","property.ssl.ca.location" = "FILE:ca.pem"1.使用 SSL 连接 Kafka 时,需要指定以下参数:"property.security.protocol" = "ssl","property.ssl.ca.location" = "FILE:ca.pem","property.ssl.certificate.location" = "FILE:client.pem","property.ssl.key.location" = "FILE:client.key","property.ssl.key.password" = "abcdefg"其中:"property.security.protocol" 和 "property.ssl.ca.location" 为必须,用于指明连接方式为 SSL,以及 CA 证书的位置。如果 Kafka server 端开启了 client 认证,则还需设置:"property.ssl.certificate.location""property.ssl.key.location""property.ssl.key.password"分别用于指定 client 的 public key,private key 以及 private key 的密码。2.指定kafka partition的默认起始offset如果没有指定kafka_partitions/kafka_offsets,默认消费所有分区,此时可以指定kafka_default_offsets指定起始 offset。默认为 OFFSET_END,即从末尾开始订阅。值为1) OFFSET_BEGINNING: 从有数据的位置开始订阅。2) OFFSET_END: 从末尾开始订阅。3) 时间戳,格式同 kafka_offsets示例:"property.kafka_default_offsets" = "OFFSET_BEGINNING""property.kafka_default_offsets" = "2021-05-11 10:00:00"8. 导入数据格式样例整型类(TINYINT/SMALLINT/INT/BIGINT/LARGEINT):1, 1000, 1234浮点类(FLOAT/DOUBLE/DECIMAL):1.1, 0.23, .356日期类(DATE/DATETIME):2017-10-03, 2017-06-13 12:34:03。字符串类(CHAR/VARCHAR)(无引号):I am a student, aNULL值:\N
Examples:1. 为 example_db 的 example_tbl 创建一个名为 test1 的 Kafka 例行导入任务。指定列分隔符和 group.id 和 client.id,并且自动默认消费所有分区,且从有数据的位置(OFFSET_BEGINNING)开始订阅CREATE ROUTINE LOAD example_db.test1 ON example_tblCOLUMNS TERMINATED BY ",",COLUMNS(k1, k2, k3, v1, v2, v3 = k1 * 100)PROPERTIES("desired_concurrent_number"="3","max_batch_interval" = "20","max_batch_rows" = "300000","max_batch_size" = "209715200","strict_mode" = "false")FROM KAFKA("kafka_broker_list" = "broker1:9092,broker2:9092,broker3:9092","kafka_topic" = "my_topic","property.group.id" = "xxx","property.client.id" = "xxx","property.kafka_default_offsets" = "OFFSET_BEGINNING");2. 为 example_db 的 example_tbl 创建一个名为 test1 的 Kafka 例行导入任务。导入任务为严格模式。CREATE ROUTINE LOAD example_db.test1 ON example_tblCOLUMNS(k1, k2, k3, v1, v2, v3 = k1 * 100),WHERE k1 > 100 and k2 like "%doris%"PROPERTIES("desired_concurrent_number"="3","max_batch_interval" = "20","max_batch_rows" = "300000","max_batch_size" = "209715200","strict_mode" = "false")FROM KAFKA("kafka_broker_list" = "broker1:9092,broker2:9092,broker3:9092","kafka_topic" = "my_topic","kafka_partitions" = "0,1,2,3","kafka_offsets" = "101,0,0,200");3. 通过 SSL 认证方式,从 Kafka 集群导入数据。同时设置 client.id 参数。导入任务为非严格模式,时区为 Africa/AbidjanCREATE ROUTINE LOAD example_db.test1 ON example_tblCOLUMNS(k1, k2, k3, v1, v2, v3 = k1 * 100),WHERE k1 > 100 and k2 like "%doris%"PROPERTIES("desired_concurrent_number"="3","max_batch_interval" = "20","max_batch_rows" = "300000","max_batch_size" = "209715200","strict_mode" = "false","timezone" = "Africa/Abidjan")FROM KAFKA("kafka_broker_list" = "broker1:9092,broker2:9092,broker3:9092","kafka_topic" = "my_topic","property.security.protocol" = "ssl","property.ssl.ca.location" = "FILE:ca.pem","property.ssl.certificate.location" = "FILE:client.pem","property.ssl.key.location" = "FILE:client.key","property.ssl.key.password" = "abcdefg","property.client.id" = "my_client_id");4. 简单模式导入jsonCREATE ROUTINE LOAD example_db.test_json_label_1 ON table1COLUMNS(category,price,author)PROPERTIES("desired_concurrent_number"="3","max_batch_interval" = "20","max_batch_rows" = "300000","max_batch_size" = "209715200","strict_mode" = "false","format" = "json")FROM KAFKA("kafka_broker_list" = "broker1:9092,broker2:9092,broker3:9092","kafka_topic" = "my_topic","kafka_partitions" = "0,1,2","kafka_offsets" = "0,0,0");支持两种json数据格式:1){"category":"a9jadhx","author":"test","price":895}2)[{"category":"a9jadhx","author":"test","price":895},{"category":"axdfa1","author":"EvelynWaugh","price":1299}]5. 精准导入json数据格式CREATE TABLE `example_tbl` (`category` varchar(24) NULL COMMENT "",`author` varchar(24) NULL COMMENT "",`timestamp` bigint(20) NULL COMMENT "",`dt` int(11) NULL COMMENT "",`price` double REPLACE) ENGINE=OLAPAGGREGATE KEY(`category`,`author`,`timestamp`,`dt`)COMMENT "OLAP"PARTITION BY RANGE(`dt`)(PARTITION p0 VALUES [("-2147483648"), ("20200509")),PARTITION p20200509 VALUES [("20200509"), ("20200510")),PARTITION p20200510 VALUES [("20200510"), ("20200511")),PARTITION p20200511 VALUES [("20200511"), ("20200512")))DISTRIBUTED BY HASH(`category`,`author`,`timestamp`) BUCKETS 4PROPERTIES ("replication_num" = "1");CREATE ROUTINE LOAD example_db.test1 ON example_tblCOLUMNS(category, author, price, timestamp, dt=from_unixtime(timestamp, '%Y%m%d'))PROPERTIES("desired_concurrent_number"="3","max_batch_interval" = "20","max_batch_rows" = "300000","max_batch_size" = "209715200","strict_mode" = "false","format" = "json","jsonpaths" = "[\"$.category\",\"$.author\",\"$.price\",\"$.timestamp\"]","strip_outer_array" = "true")FROM KAFKA("kafka_broker_list" = "broker1:9092,broker2:9092,broker3:9092","kafka_topic" = "my_topic","kafka_partitions" = "0,1,2","kafka_offsets" = "0,0,0");json数据格式:[{"category":"11","title":"SayingsoftheCentury","price":895,"timestamp":1589191587},{"category":"22","author":"2avc","price":895,"timestamp":1589191487},{"category":"33","author":"3avc","title":"SayingsoftheCentury","timestamp":1589191387}]说明:1)如果json数据是以数组开始,并且数组中每个对象是一条记录,则需要将strip_outer_array设置成true,表示展平数组。2)如果json数据是以数组开始,并且数组中每个对象是一条记录,在设置jsonpath时,我们的ROOT节点实际上是数组中对象。6. 用户指定根节点json_rootCREATE ROUTINE LOAD example_db.test1 ON example_tblCOLUMNS(category, author, price, timestamp, dt=from_unixtime(timestamp, '%Y%m%d'))PROPERTIES("desired_concurrent_number"="3","max_batch_interval" = "20","max_batch_rows" = "300000","max_batch_size" = "209715200","strict_mode" = "false","format" = "json","jsonpaths" = "[\"$.category\",\"$.author\",\"$.price\",\"$.timestamp\"]","strip_outer_array" = "true","json_root" = "$.RECORDS")FROM KAFKA("kafka_broker_list" = "broker1:9092,broker2:9092,broker3:9092","kafka_topic" = "my_topic","kafka_partitions" = "0,1,2","kafka_offsets" = "0,0,0");json数据格式:{"RECORDS":[{"category":"11","title":"SayingsoftheCentury","price":895,"timestamp":1589191587},{"category":"22","author":"2avc","price":895,"timestamp":1589191487},{"category":"33","author":"3avc","title":"SayingsoftheCentury","timestamp":1589191387}]}7. 为 example_db 的 example_tbl 创建一个名为 test1 的 Kafka 例行导入任务。并且删除与v3 >100 行相匹配的key列的行CREATE ROUTINE LOAD example_db.test1 ON example_tblWITH MERGECOLUMNS(k1, k2, k3, v1, v2, v3),WHERE k1 > 100 and k2 like "%doris%",DELETE ON v3 >100PROPERTIES("desired_concurrent_number"="3","max_batch_interval" = "20","max_batch_rows" = "300000","max_batch_size" = "209715200","strict_mode" = "false")FROM KAFKA8. 导入数据到含有sequence列的UNIQUE_KEYS表中CREATE ROUTINE LOAD example_db.test_job ON example_tblCOLUMNS TERMINATED BY ",",COLUMNS(k1,k2,source_sequence,v1,v2),ORDER BY source_sequencePROPERTIES("desired_concurrent_number"="3","max_batch_interval" = "30","max_batch_rows" = "300000","max_batch_size" = "209715200") FROM KAFKA("kafka_broker_list" = "broker1:9092,broker2:9092,broker3:9092","kafka_topic" = "my_topic","kafka_partitions" = "0,1,2,3","kafka_offsets" = "101,0,0,200");8. 过滤原始数据CREATE ROUTINE LOAD example_db.test_job ON example_tblCOLUMNS TERMINATED BY ",",COLUMNS(k1,k2,source_sequence,v1,v2),PRECEDING FILTER k1 > 2PROPERTIES("desired_concurrent_number"="3","max_batch_interval" = "30","max_batch_rows" = "300000","max_batch_size" = "209715200") FROM KAFKA("kafka_broker_list" = "broker1:9092,broker2:9092,broker3:9092","kafka_topic" = "my_topic","kafka_partitions" = "0,1,2,3","kafka_offsets" = "101,0,0,200");9. 从指定的时间点开始消费CREATE ROUTINE LOAD example_db.test_job ON example_tblPROPERTIES("desired_concurrent_number"="3","max_batch_interval" = "30","max_batch_rows" = "300000","max_batch_size" = "209715200") FROM KAFKA("kafka_broker_list" = "broker1:9092,broker2:9092,broker3:9092","kafka_topic" = "my_topic","property.kafka_default_offsets" = "2021-10-10 11:00:00");
6 数据导入演示
6.1 启动kafka集群(三台节点都启动)
自行启动安装好的kafka环境,这里不做详细讲解
6.2 创建topic
bin/kafka-topics.sh --create --zookeeper 192.168.222.130:2181,192.168.222.131:2181,192.168.222.133:2181 --replication-factor 3 --partitions 3 --topic test6.3 在doris中创建对应表
create table student_kafka
(
id int,
name varchar(50),
age int
)
DUPLICATE KEY(id)
DISTRIBUTED BY HASH(id) BUCKETS 10;
6.4 创建导入作业,desired_concurrent_number指定并行度
CREATE ROUTINE LOAD test_db.kafka_job1 on student_kafka
PROPERTIES
("desired_concurrent_number"="1","strict_mode"="false","format" = "json"
)
FROM KAFKA
("kafka_broker_list"= "192.168.222.130:9092,192.168.222.131:9092,192.168.222.132:9092","kafka_topic" = "test","property.group.id" = "test_group_1","property.kafka_default_offsets" = "OFFSET_BEGINNING","property.enable.auto.commit" = "false"
);
6.5 在kafka生产者命令行输入json字符串
{"id":1,"name":"zhangsan","age":20}
{"id":2,"name":"lisi","age":30}
6.6 查询表的数据(有一定延迟时间)
select * from student_kafka;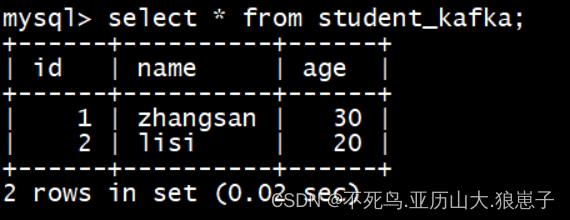
6.7 查看导入作业状态
- 查看作业状态的具体命令和示例可以通过 HELP SHOW ROUTINE LOAD; 命令查看。
- 只能查看当前正在运行中的任务,已结束和未开始的任务无法查看。
HELP SHOW ROUTINE LOAD;
SHOW ALL ROUTINE LOAD;显示 test_db 下,所有的例行导入作业(包括已停止或取消的作业)。结果为一行或多行。
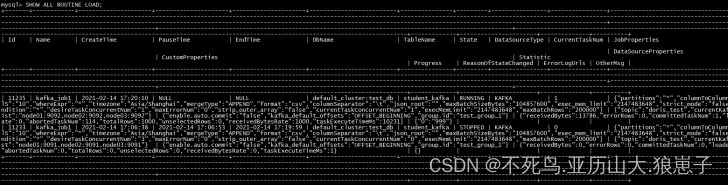
6.8 修改作业属性
用户可以修改已经创建的作业。具体说明可以通过 HELP ALTER ROUTINE LOAD; 命令查看。
6.9 作业控制
用户可以通过一下三个命令来控制作业:
- STOP:停止
- PAUSE:暂停
- RESUME:重启
可以通过以下三个命令查看帮助和示例。
HELP STOP ROUTINE LOAD;
HELP PAUSE ROUTINE LOAD; 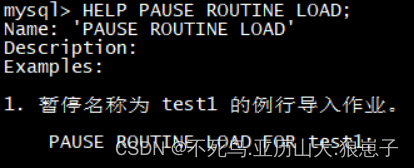
HELP RESUME ROUTINE LOAD; 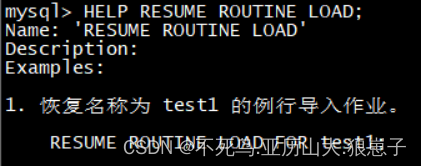
相关文章:
Doris(7):数据导入(Load)之Routine Load
例行导入功能为用户提供了义中自动从指定数据源进行数据导入的功能 1 适用场景 当前仅支持kafka系统进行例行导入。 2 使用限制 支持无认证的 Kafka 访问,以及通过 SSL 方式认证的 Kafka 集群。支持的消息格式为 csv 文本格式。每一个 message 为一行,…...
linux 安装php8.1 ZipArchive和libzip最新版扩展安装
1、概述 安装前咱们先看下我本地环境 [rootelk php8]# cat /etc/redhat-release Red Hat Enterprise Linux Server release 7.9 (Maipo) [rootelk php8]# [rootelk php8]# ./bin/php -v PHP 8.1.18 (cli) (built: Apr 17 2023 13:15:17) (NTS) Copyright (c) The PHP Group Z…...

大数据 | 实验一:大数据系统基本实验 | 熟悉常用的HBase操作
文章目录 📚HBase安装🐇安装HBase🐇伪分布式模式配置🐇测试运行HBase🐇HBase java API编程环境配置 📚实验目的📚实验平台📚实验内容🐇HBase Shell 编程命令实现以下指定…...
)
Linux command(split)
原理 在split.c中,首先处理传递给split命令的参数,包括需要拆分的文件、拆分大小/行数等选项。然后,通过调用open()函数打开需要拆分的文件,并获取文件信息。接着根据选项计算每个拆分文件的大小/行数,并根据需要创建输…...

开放式耳机好用吗,盘点几款口碑不错的开放式耳机
开放式耳机作为一种全新的耳机形态,已经成为了当前市场上非常火爆的一款产品。由于无需入耳佩戴,可以很好的避免了耳膜受到损伤,而且也能够让我们在佩戴眼镜时也能够正常使用。加上开放式耳机的音质和舒适度都要优于其他类型的耳机…...
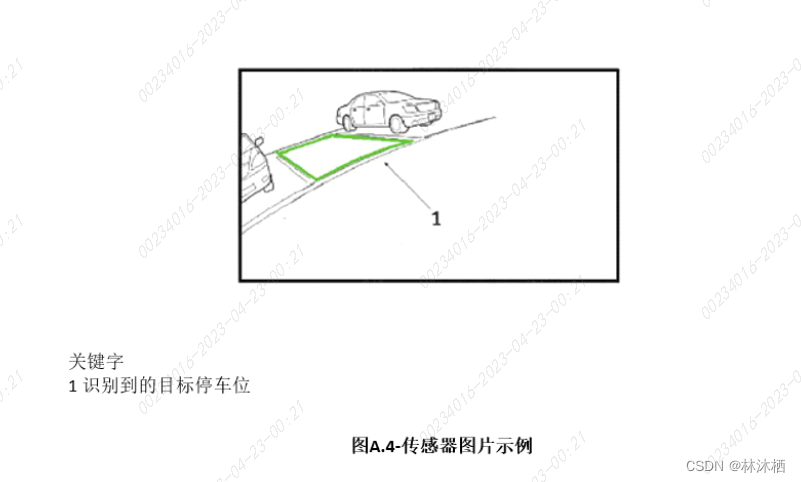
法规标准-ISO 16787标准解读
ISO 16787是做什么的? ISO 16787全称为智能运输系统-辅助泊车系统(APS)-性能要求和测试程序,其中主要描述了对APS系统的功能要求及测试规范 APS类型 根据目标停车位类型将APS系统分为两类: 1)APS类型I&a…...

脑力劳动-英文单词
标题 前言必学场景词汇及用法会议简报电话出差市场调研广告与媒介电脑情境常用单词会议简报电话市场调研广告与媒介电脑前言 加油 必学场景词汇及用法 会议 1meeting [ˈmitɪŋ] n.会议hold / have / call off a meeting举办/取消会议be in a meeting在开会The meeting w…...
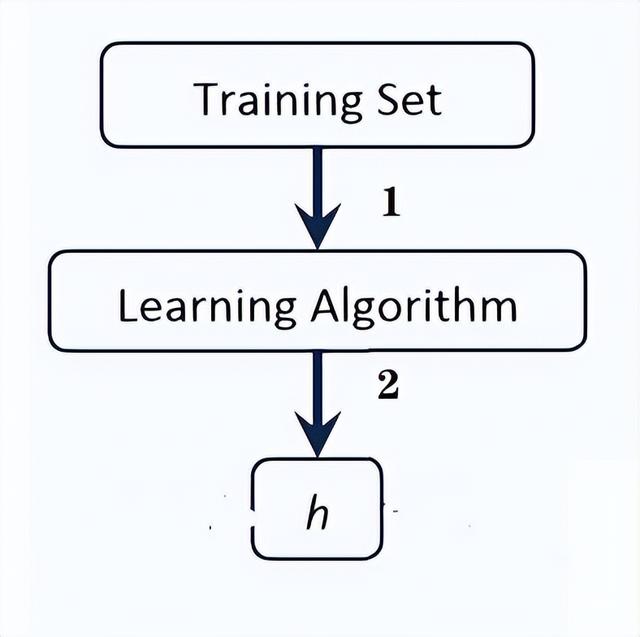
机器学习中的三个重要环节:训练、验证、测试
本文重点 模型训练、验证和测试是机器学习中的三个重要环节。这三个环节之间存在着紧密的关系,它们相互作用,共同构建出一个完整的机器学习模型。在本文中,我们将详细介绍模型训练、验证和测试之间的关系。 模型训练、验证和测试之间的关系 模型训练是机器学习中最基本的…...
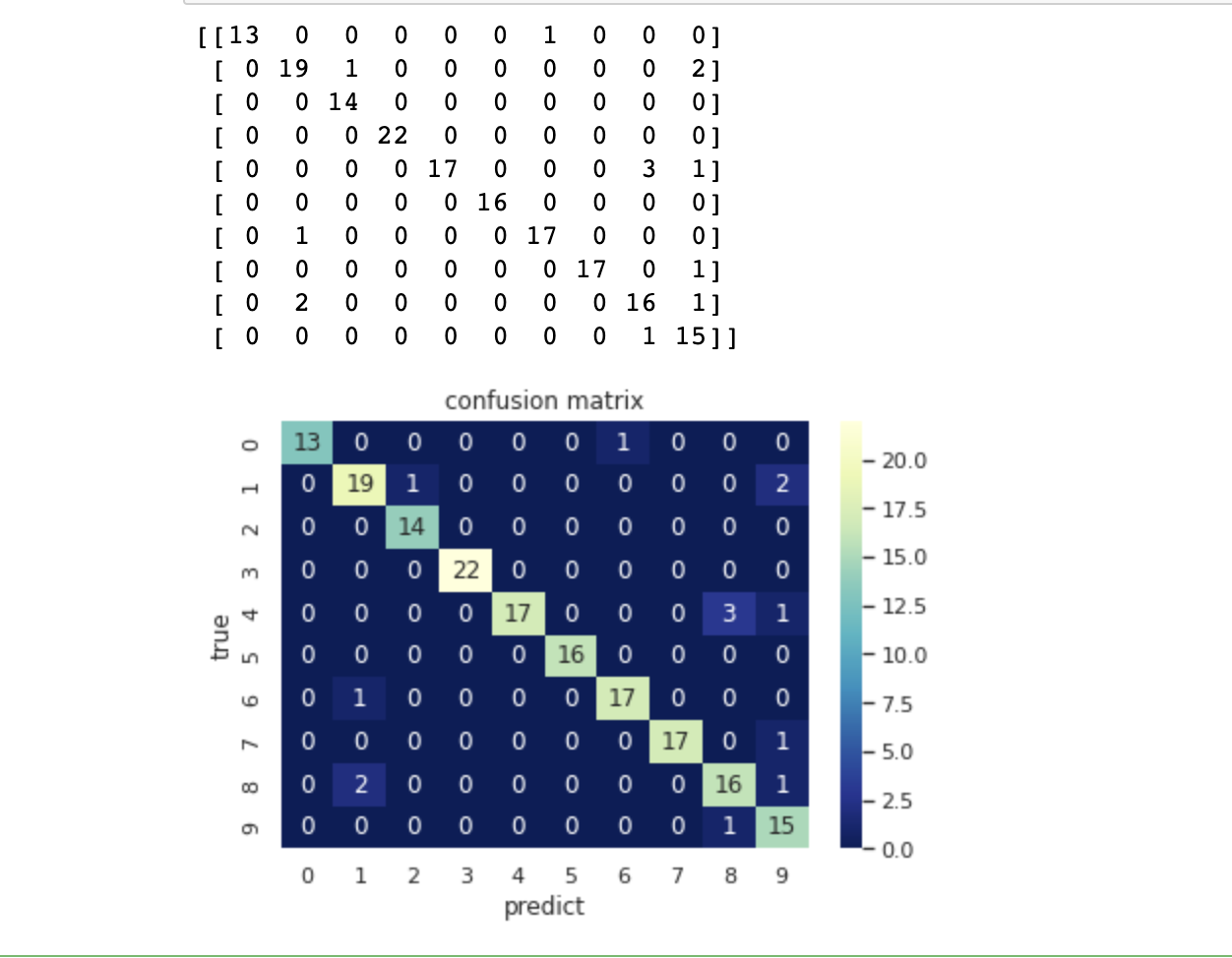
机器学习实战:Python基于LDA线性判别模型进行分类预测(五)
文章目录 1 前言1.1 线性判别模型的介绍1.2 线性判别模型的应用 2 demo数据演示2.1 导入函数2.2 训练模型2.3 预测模型 3 LDA手写数字数据演示3.1 导入函数3.2 导入数据3.3 输出图像3.4 建立模型3.5 预测模型 4 讨论 1 前言 1.1 线性判别模型的介绍 线性判别模型(…...
)
Java枚举(Enum)
枚举(enum) enum全称enumeration,JDK 1.5中引入的新特性。在Java中,被enum关键字修饰的类型就是枚举类型 可以将枚举看成一个类,它继承于java.lang.enum类,当定义一个枚举类型时,每一个枚举类型…...

【Python】【进阶篇】二十一、Python爬虫的多线程爬虫
目录 二十一、Python爬虫的多线程爬虫21.1 多线程使用流程21.2 Queue队列模型21.3 多线程爬虫案例1) 案例分析2) 完整程序 二十一、Python爬虫的多线程爬虫 网络爬虫程序是一种 IO 密集型程序,程序中涉及了很多网络 和 本地磁盘的 IO 操作,这会消耗大…...
)
Python从入门到精通14天(eval、literal_eval、exec函数的使用)
eval、literal_eval、exec函数的使用 eval函数literal_eval函数exec函数三者的区别 eval函数 eval()是Python中的内置函数,它可以将一个字符串作为参数,并将该字符串作为Python代码执行。它的语法格式为:eval(expression,globalsNone,locals…...
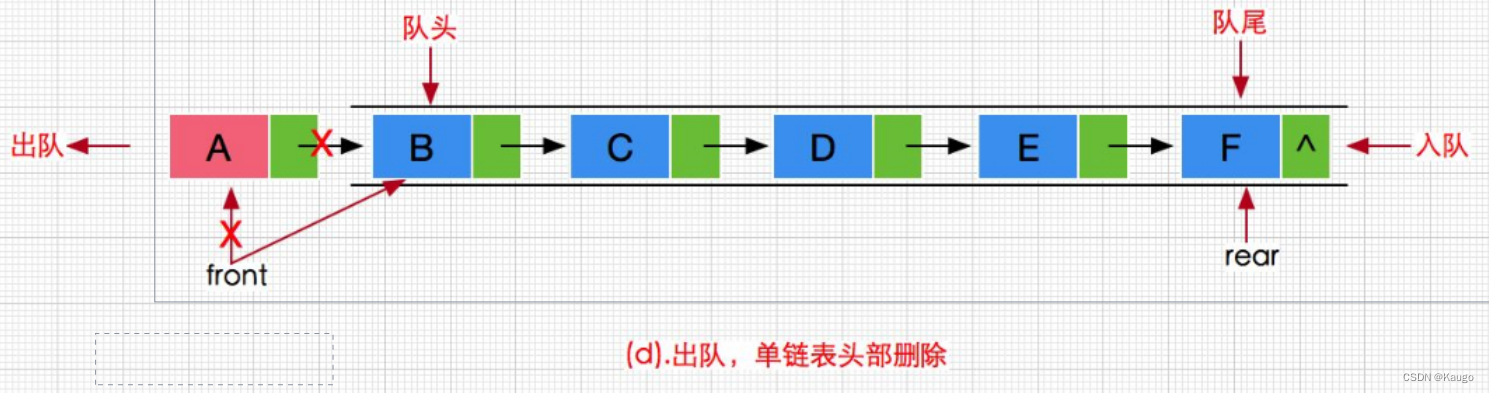
队列的基本操作(C语言链表实现)初始化,入队,出队,销毁,读取数据
文章目录 前言一、队列基本变量的了解二、队列的基本操作2.1队列的初始化(QueueInit)2.2入队(QueuePush)2.3判断是否为空队(QueueEmpty)2.4出队(QueuePop)2.5队列的队头数据…...
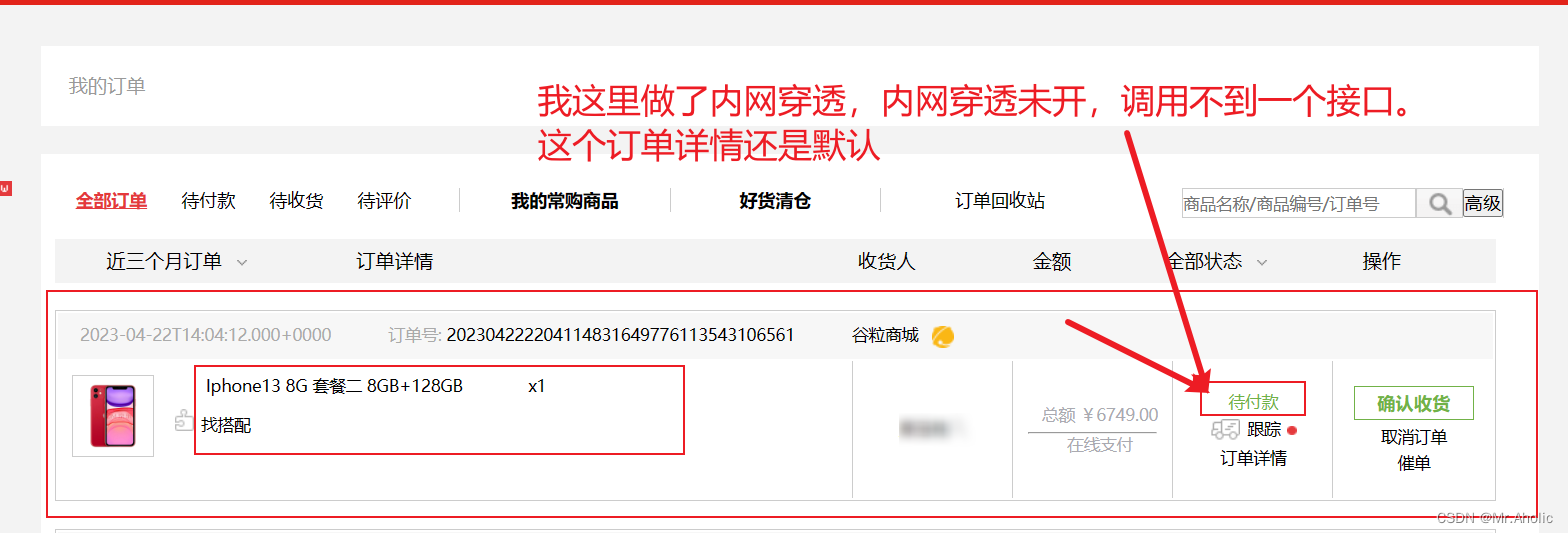
项目支付接入支付宝【沙箱环境】
前言 订单支付接入支付宝,使用支付宝提供的沙箱机制模拟为订单付款。我这里主要记录一下沙箱环境如何接入到系统中,具体细节的实现。按照官方文档来就可以了。 1、使用步骤 这里有几个重要数据要拿到,一个是支付宝的公钥和私钥,…...

程序员应该如何提升自己
作为一名程序员,以下是您可以考虑的一些方法来提高自己的技能和知识: 深入学习编程语言和相关工具:了解您使用的编程语言和相关工具的基本原理和高级特性,以便更好地理解其工作方式并更有效地使用它们。 刻意练习:刻意…...

全球上线!ABB中国涡轮增压器分拆 – 数据清理阶段完成
ABB是数字行业的技术前沿者,拥有四项主营业务:电气化,工业自动化,运动控制以及机器人和离散自动化。ABB总部位于瑞士苏黎世,业务遍及100多个国家,拥有约105,000名员工。2021年,该公司…...
)
手写简易 Spring(三)
文章目录 三. 手写简易 Spring(三)1. Bean 对象初始化和销毁方法1. XML 添加 init-method 与实现 InitializingBean 接口注册初始化2. XML 添加 destroy-method 与实现 DisposableBean 接口注册销毁3. DefaultSingletonBeanRegistry 优秀的解耦方法 2. 定…...

设计模式-看懂UML类图和时序图
这里不会将UML的各种元素都提到,只讲类图中各个类之间的关系; 能看懂类图中各个类之间的线条、箭头代表什么意思后,也就足够应对 日常的工作和交流; 同时,应该能将类图所表达的含义和最终的代码对应起来; 1…...

2023年全国最新安全员精选真题及答案57
百分百题库提供安全员考试试题、建筑安全员考试预测题、建筑安全员ABC考试真题、安全员证考试题库等,提供在线做题刷题,在线模拟考试,助你考试轻松过关。 101.(单选题)遇有()及以上强风、浓雾等…...

数字图像处理基础
图像增强:不论方法,只要能够得到较好的图像即可 图像复原:找到图像退化的原因,把噪声过滤得到较好的图像 RGB——HSI(色调 饱和度 亮度)彩色图像处理需要用到灰度图像处理 直方图均衡,灰度概率密度函数接近均匀分布&a…...

基于Trinket M0与伺服电机的宠物激光护目镜DIY全攻略
1. 项目概述与核心思路给自家毛孩子做个赛博朋克风的万圣节装备,这个想法在我脑子里盘桓很久了。市面上那些宠物装饰要么千篇一律,要么就是简单的布料缝制,总感觉少了点“硬核”的趣味。直到我看到伺服电机和激光二极管这两个小玩意儿&#x…...

湿版摄影风格失效的5个致命误区,第4个连Midjourney官方文档都未披露——基于217组AB测试的权威归因报告
更多请点击: https://intelliparadigm.com 第一章:湿版摄影风格失效的5个致命误区,第4个连Midjourney官方文档都未披露——基于217组AB测试的权威归因报告 为何“wet plate collodion”提示词突然失灵? 在 Midjourney v6.1 及 N…...

Hermes Agent 工具如何配置接入 Taotoken 提供的模型服务
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Hermes Agent 工具如何配置接入 Taotoken 提供的模型服务 Hermes Agent 是一个流行的开源智能体框架,它允许开发者通过…...

5大核心模块彻底解决Windows更新故障:Reset-Windows-Update-Tool专业修复指南
5大核心模块彻底解决Windows更新故障:Reset-Windows-Update-Tool专业修复指南 【免费下载链接】Reset-Windows-Update-Tool Troubleshooting Tool with Windows Updates (Developed in Dev-C). 项目地址: https://gitcode.com/gh_mirrors/re/Reset-Windows-Update…...

如何快速掌握NCBI基因组批量下载:面向生物信息学新手的完整实战指南
如何快速掌握NCBI基因组批量下载:面向生物信息学新手的完整实战指南 【免费下载链接】ncbi-genome-download Scripts to download genomes from the NCBI FTP servers 项目地址: https://gitcode.com/gh_mirrors/nc/ncbi-genome-download NCBI基因组数据批量…...
)
仅0.3%用户掌握的胶片叙事技巧:用Midjourney实现“过期胶卷”时间衰减效果(含Exif元数据欺骗指令集)
更多请点击: https://intelliparadigm.com 第一章:胶片叙事与数字时代的时间诗学 胶片影像的物理性——帧率、显影时长、机械快门延时——曾将时间锚定为可触摸的物质存在;而数字媒介则以纳秒级采样、无损复制与非线性剪辑,将时间…...
Point Transformer V3 牙齿语义分割测试结果为0问题:完整调试与修复方案
Point Transformer V3 牙齿语义分割测试结果为0问题:完整调试与修复方案 摘要 Point Transformer V3(PTv3)是CVPR 2024发布的高效点云处理模型,在语义分割任务中表现出色。然而,在16类牙齿语义分割任务的测试阶段,模型输出全部为0的问题却常常困扰开发者。本文将从数据…...

在Windows电脑上玩转酷安社区:这款免费UWP客户端让你告别手机小屏幕
在Windows电脑上玩转酷安社区:这款免费UWP客户端让你告别手机小屏幕 【免费下载链接】Coolapk-UWP 一个基于 UWP 平台的第三方酷安客户端 项目地址: https://gitcode.com/gh_mirrors/co/Coolapk-UWP 还在用手机刷酷安社区吗?是时候体验大屏幕带来…...

画图工具2.0
在上篇文章中,我们已经对简易画图工具有了一个初步了解,下面我们要对一些具体细节进行完善并加上一些新的功能,我们直接来看升级点:1.界面类加上颜色按钮Color[] colors {Color.BLACK, Color.RED, Color.GREEN, Color.BLUE, Colo…...

深入解析vsync:基于版本化状态流的高并发同步原语
1. 项目概述:一个被低估的同步利器如果你在开发中经常需要处理跨进程、跨线程的数据同步,或者为状态管理中的竞态条件头疼,那么nicepkg/vsync这个项目很可能就是你一直在寻找的“瑞士军刀”。乍一看这个标题,它像是一个普通的版本…...