有关实现深拷贝的四种方法
深拷贝与浅拷贝:
在开始之前我们需要先了解一下什么是浅拷贝和深拷贝,其实深拷贝和浅拷贝都是针对的引用类型,JS中的变量类型分为值类型(基本类型)和引用类型;对值类型进行复制操作会对值进行一份拷贝,而对引用类型赋值,则会进行地址的拷贝,最终两个变量指向同一份数据。
// 基本类型
var a = 1;
var b = a;
a = 2;
console.log(a, b); // 2, 1 ,a b指向不同的数据// 引用类型指向同一份数据
var a = {c: 1};
var b = a;
a.c = 2;
console.log(a.c, b.c); // 2, 2 全是2,a b指向同一份数据对于引用类型,会导致a b指向同一份数据,此时如果对其中一个进行修改,就会影响到另外一个,有时候这可能不是我们想要的结果,如果对这种现象不清楚的话,还可能造成不必要的bug.
那么如何切断a和b之间的关系呢,可以拷贝一份a的数据,根据拷贝的层级不同可以分为浅拷贝和深拷贝,浅拷贝就是只进行一层拷贝,深拷贝就是无限层级拷贝。
var a1 = {b: {c: {}}};var a2 = shallowClone(a1); // 浅拷贝a2.b.c === a1.b.c // true var a3 = clone(a1); // 深拷贝a3.b.c === a1.b.c // false这里认为shallowClone是指浅拷贝,clone是指深拷贝,a1对象是一个三层嵌套对象。浅拷贝只能拷贝第一层,b属性是一个对象,b里面存放的是这个对象的引用地址,因此a1.b.c===a2.b.c ; 深拷贝则是拷贝每一层,a1.b和a3.b的引用地址不同,完全独立,因此a3.b.c!=a1.b.c.
对于浅拷贝的实现来说非常简单,我们对要拷贝的对象或数组进行一次遍历,并赋值给创建的新对象或新数组,就可完成浅拷贝,这里不再多说。 下面我们将讨论深拷贝应该如何实现。这里介绍四种深拷贝方法。
1.递归法:
实现深拷贝最常用的方法便是递归法,原理就是通过递归的方式遍历要拷贝的对象或数组。首先对要拷贝的对象或数组进行类型判断,然后创建相应的一个空对象或空数组,然后和浅拷贝一样,通过循环遍历这个对象或数组,若发现某个属性是引用数据类型的话,就递归调用深拷贝函数,若该属性是基本数据类型,则直接进行赋值操作,直至遍历完所有子对象的所有属性。递归遍历本质上是深度优先遍历,在进行深拷贝时,若一个属性的值为对象,则优先对这个子对象进行拷贝,而不是拷贝与这个属性相邻的下一个属性。待这个属性所对应的子对象整体拷贝完毕后,才会拷贝下一个属性。下面放上递归法的代码:
//递归遍历每个属性进行深拷贝function clone(source) {let target = Array.isArray(source) ? [] : {};if(typeof(source)!="object") {target = source;return target;}if(source instanceof Array) {for(var i=0;i<source.length;i++) {if(typeof source[i] == "object") {target[i] = clone(source[i]);}else {target[i] = source[i];}}}else {for(let key in source) {if(source.hasOwnProperty(key)) {if(typeof source[key] == "object") {target[key] = clone(source[key]);}else {target[key] = source[key];}}}}return target;}在这里用一个包含多层的对象数组进行测试,并将深拷贝的属性进行修改,看看是否会影响到原始数据。
let e = [{a:'1',b:'2',c:'3'},{aa:'11',bb:'22',cc:'33'},{aaa:'111',bbb:'222',ccc:'333'}];let f = clone(e);f[2].ccc='444';console.log(e);console.log(f);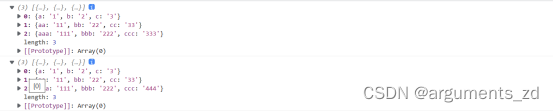
可以看到打印后的结果,修改拷贝数组第三个元素的ccc属性后,原数组并没有发生变化,说明深拷贝实现成功。
- JSON深拷贝法:
利用系统自带的JSON也可以实现深拷贝。
JSON.parse(JSON.stringify(a));实际上是将要拷贝的对象先转换为JSON字符串,再将字符串转换为对象。JSON对象与字符串转换的原理实际上也是做递归遍历,只不过需要做两次,因此在算法效率上递归法要比JSON转换高一倍。
但使用递归法和JSON进行深拷贝有一个弊端,就是在每次执行递归函数时,都会调用内存空间,所以当要拷贝的对象深度非常大时,使用递归函数会出现爆栈的问题。下面来模拟下这种情况。
//构造指定深度和广度的对象function createData(deep,num) {var data = {};var temp = data;for(var i=0;i<deep;i++) {temp.data = {};temp = temp.data;for(var j = 0;j<num;j++) {temp[j] = j;}}return data;}这个createData函数用来构造一个深度为deep,广度为num的对象。例如createData(3,3),创建出的对象为{data:{‘0’:0,’1’:1,’2’:2,data:{‘0’:0,’1’:1,’2’:2,data:{‘0’:0,’1’:1,’2’:2,}}}}。此时用createData创建一个深度为10000的对象,并用递归法clone()和JSON拷贝这个对象,会发现内存溢出报错。
let d = createData(10000,0);let e = clone(d);console.log(e);
let d = createData(10000,0);let e = JSON.parse(JSON.stringify(d));console.log(e); ![]()
可见碰到层级很多的对象时,这两种方法就不管用了,下面就来介绍第三种方法,循环递归深拷贝,这种方法可以很好的解决内存溢出的问题。
2.循环遍历法:
如果我们可以使用循环来遍历对象所有层级的属性,就可以省去递归调用函数时占用的内存空间,从而解决爆栈的问题。那么该如何运用循环的思想实现多层次遍历呢。下面来看一个数据结构
var a = {a1: {a11: 1,},a2: {b1: 1,b2: {c1: 1}}}a对象是一个嵌套对象,如果我们把它竖着来看,会发现它是一个树形的数据结构。
a/ \a1 a2 | / \ a11 b1 b2 | | | 1 1 c1|1 我们可以把对象中引用数据类型的属性看作是这颗树里面的子节点,基本数据类型的属性看作是叶子节点的父节点。会发现我们只需要遍历这颗树的每个节点,就可以实现深拷贝了。用循环遍历这棵树,我们需要借助一个栈,把子节点(除叶子节点和其父节点外)放入到这个栈中,表示这些节点需要拷贝,每次拷贝从栈中放出一个节点进行拷贝,当栈为空时,则表示这棵树已经遍历完并完成拷贝。循环遍历本质上就是对栈中的元素进行循环,栈空循环自然结束。下面来模拟一下利用栈循环遍历的这个过程。
在循环前我们先构造这个栈,栈是一个具有后进先出特点的数组,我们要将需要遍历的节点放入到栈中,在刚开始拷贝时,因为不知道要拷贝的对象里面的属性如何,所以先往栈里放入一个种子数据。栈中存放的元素需要有三个属性来描述节点信息,parent 表示当前所处的节点,也就是要做循环遍历的当前节点,key用来存放当前节点中属性名为key的子元素,表示需要拷贝的子对象,data表示要拷贝子对象的内容。
{parent: root,key: undefined,data: x,}拿要拷贝的a对象来举例,我们想把它拷贝到root中,先构造root空对象,然后将上面这个种子数据放入到栈中,遍历前我们处在root节点,所以parent为root,因为不知道拷贝的对象结构如何,所以key为undefined,data表示要拷贝的内容,也就是整个a对象。
第一轮循环开始,种子数据出栈,循环遍历当前parent节点下的节点,发现a1 a2都是引用数据类型,是要拷贝的节点,所以把他们对应的节点信息存入栈中,此时parent为root,key为a1和a2 data分别为 a1 对象和a2对象。因为a2在a1之后存入,则a2先出栈。
第二轮循环:循环遍历a2下的节点,b2为引用类型,b2对应节点信息存入到栈中,因为在a2下进行遍历,所以parent为a2。
第三轮循环:b2出栈,遍历b2下的节点,发现没有引用类型,直接拷贝。
第四轮循环:a1出栈,遍历a1下的节点,发现a11不是引用类型,直接拷贝。此时栈为空,并且没有需要入栈的引用类型,则表示已经遍历完毕,循环结束。
通过这个过程我们可以发现循环遍历的次数取决于要拷贝的数据中引用数据类型的个数,嵌套了多少个对象,就循环多少次。并且由于栈后进先出的特点,循环遍历同递归遍历一样也属于深度优先遍历。即先访问子元素,再访问兄弟元素。
下面贴出循环遍历深拷贝方法的代码
//循环遍历对象实现深拷贝function cloneLoop(x) {const root = {};// 栈 后进先出const loopList = [{parent: root,key: undefined,data: x,}];while(loopList.length) {// 深度优先const node = loopList.pop();const parent = node.parent;const key = node.key;const data = node.data;// 初始化赋值目标,key为undefined则拷贝到父元素,否则拷贝到子元素let res = parent;if (typeof key !== 'undefined') {res = parent[key] = {};}for(let k in data) {if (data.hasOwnProperty(k)) {if (typeof data[k] === 'object') {// 下一次循环loopList.push({parent: res,key: k,data: data[k],});} else {res[k] = data[k];}}}}return root;}这里为了方便,只考虑对象情况,若要考虑数组情况,则需要对拷贝类型进行判断,根据类型构造空对象或空数组。具体实现参考递归法。
通过循环遍历,我们可以破解递归爆栈,利用循环深拷贝法cloneLoop()对刚才的10000层对象进行拷贝,发现没有报栈溢出的错误,说明此方法有效。
let d = createData(10000,0);let e = cloneLoop(d);console.log(e);
尽管循环遍历法可以解决拷贝层级很多对象时内存溢出的问题,但对于某些特殊情况依然无法应对。如循环引用对象或是属性间存在引用关系的对象。例如 :
a={};
a.a=a;
var obj = {};
var obj1 = {a1: obj, a2: obj};
a是循环引用对象,obj1是属性间存在引用关系的对象。像这样的对象上述三种方法都无法实现深拷贝后仍然保持引用关系,也无法破解循环引用。我们拿obj1来用这三种方法进行拷贝测试,结果如图:
var obj = {};var obj1 = {a1: obj, a2: obj};console.log(obj1.a1 === obj1.a2) // truevar obj3 = cloneLoop(obj1);console.log(obj3.a1 === obj3.a2) //falsevar obj4 = JSON.parse(JSON.stringify(obj1));console.log(obj4.a1 ===obj4.a2) //falsevar obj5 = clone(obj1);console.log(obj5.a1 === obj5.a2) //false 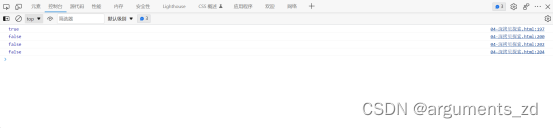
这里就要介绍第四种方法,它可以解决循环引用和属性间存在引用关系的问题。
3.破解循环引用法:
第四种方法其实是在循环遍历法的基础上进行改进。在每轮循环开始前如果我们发现个新对象就把这个对象和他的拷贝存下来,每次拷贝对象前,都先看一下这个对象是不是已经拷贝过了,如果拷贝过了,就不需要拷贝了,直接用原来的,这样我们就能够保留引用关系了。
引入一个数组uniqueList用来存储已经拷贝过的对象,每次循环遍历时,先判断本次要拷贝的对象是否在uniqueList中了,如果在的话就不执行拷贝逻辑了,直接将上次拷贝的对象的引用直接赋值给该要拷贝的属性。如果不在则表示要拷贝对象第一次出现,将这个对象和拷贝后的对象的引用存入uniqueList中。 代码如下:
/ 保持引用关系function cloneForce(x) {// =============const uniqueList = []; // 用来去重// =============let root = {};// 循环数组const loopList = [{parent: root,key: undefined,data: x,}];while(loopList.length) {// 深度优先const node = loopList.pop();const parent = node.parent;const key = node.key;const data = node.data;// 初始化赋值目标,key为undefined则拷贝到父元素,否则拷贝到子元素let res = parent;if (typeof key !== 'undefined') {res = parent[key] = {};}// =============// 数据已经存在let uniqueData = uniqueList.find((item) => item.source === data);if (uniqueData) {parent[key] = uniqueData.target;continue; // 中断本次循环}// 数据不存在// 保存源数据,再拷贝数据中对应的引用uniqueList.push({source: data,target: res,});// =============for(let k in data) {if (data.hasOwnProperty(k)) {if (typeof data[k] === 'object') {// 下一次循环loopList.push({parent: res,key: k,data: data[k],});} else {res[k] = data[k];}}}}return root;}运用改进后的循环遍历法cloneForce()对obj1进行测试,发现深拷贝后的对象里仍然保留了属性间的引用关系,说明该方法对于破解循环引用有效。
var obj = {};var obj1 = {a1: obj, a2: obj};console.log(obj1.a1 === obj1.a2) // truevar obj2 = cloneForce(obj1);console.log(obj2.a1 === obj2.a2) // true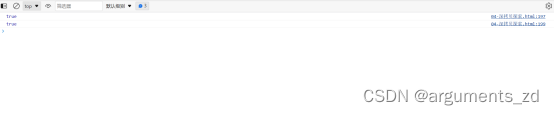
由于没拷贝过的新对象都要进入uniqueList数组,在每次拷贝前都要遍历uniqueList数组检查要拷贝的对象是否出现,当要拷贝的子对象过多并且只有较少量的属性间存在引用关系时,每次遍历uniqueList数组都会做无意义的判断从而导致算法效率降低。因此该方法只适用于数据量不大并且需要保持属性间的引用关系且符合这种关系的属性数量多。对于数据量较大的对象拷贝在不要求保持引用关系的情况下还是用第三种方法更好。
以上就是关于实现深拷贝的四种方法。
相关文章:
有关实现深拷贝的四种方法
深拷贝与浅拷贝: 在开始之前我们需要先了解一下什么是浅拷贝和深拷贝,其实深拷贝和浅拷贝都是针对的引用类型,JS中的变量类型分为值类型(基本类型)和引用类型;对值类型进行复制操作会对值进行一份拷贝,而对…...

Mysql 高可用部署实践
mysql主从是如何备份的? 在MySQL主从复制架构下,备份通常需要在主库和从库上分别进行。 主库备份: 在主库上进行备份时,可以使用mysqldump等命令生成SQL文件,并将其保存到本地或者远程服务器上。备份过程中需要注意以下几点&a…...

IEEE-TMI:张孝勇团队开发小鼠精细脑结构自动分割的深度学习算法
近日,复旦大学类脑智能科学与技术研究院青年研究员张孝勇课题组联合德国亥姆霍兹慕尼黑研究中心,在医学图像处理领域顶尖期刊《IEEE医学影像汇刊》(IEEE Transactions on Medical Imaging,TMI) 发表了题为《MouseGAN:用于小鼠大脑…...

八股文之面向对象和面向过程的区别
面向对象(Object-Oriented)和面向过程(Procedural)是两种不同的编程思想。 面向过程是以任务为中心,将程序分解成一系列步骤,在每个步骤中定义一个函数来完成特定的任务。它主要关注程序执行的过程和如何组…...

SpringBoot使用Redis实现分布式缓存
✅作者简介:2022年博客新星 第八。热爱国学的Java后端开发者,修心和技术同步精进。 🍎个人主页:Java Fans的博客 🍊个人信条:不迁怒,不贰过。小知识,大智慧。 💞当前专栏…...
Three——二、加强对三维空间的认识
Three——二、加强对三维空间的认识 接上个例子我们接着往下看 辅助观察坐标系 THREE.AxesHelper()的参数表示坐标系坐标轴线段尺寸大小,你可以根据需要改变尺寸。 使用方法: // AxesHelper:辅助观察的坐标系 const axesHelper new THRE…...

【Java】Java8接口中方法区别和使用
Java接口说明 jdk1.8之前接口只能是抽象方法。实现接口必须重写所有方法,比较麻烦。在java8中,支持default和static方法,这样,实现接口时,可以选择是否对default修饰的方法重写。 抽象方法 接口当中的抽象方法&#x…...

WPF 控件库Live Charts 折线图多折线比较问题处理
使用Live Charts功能对比多条折线时当Label不是一一对应时会发现折线无法对比如 Labels List<double> list2 new List<double>(); list2.Add(2.1); //x为0.5时 list2.Add(2.2); //x为0.6时 …...
接口优化方案
前言 最近随着国产化热潮,公司的用于营业的电脑全部从windows更换成了某国产化电脑,换成国产化之后,我们系统的前台web界面也由之前的jsp页面重构成vue.所以之前的一体式架构也变成了前后端分离的架构。但是在更换过程后,发现一些…...

《商用密码应用与安全性评估》第二章政策法规2.1网络空间安全形式与商业密码工作
一、国际国内网络空间安全形势 网络空间已成为与陆地、海洋、天空、太空同等重要的人类第五空间。 1.国际形势 网络空间安全纳入国家战略 网络攻击在国家对抗中深度应用 网络空间已逐步深入网络底层固件 2.国内形势 核心技术仍受制于人 信息产品存在巨大安全隐患 关…...

C#实现将文件、文件夹压缩为压缩包
C#实现将文件、文件夹压缩为压缩包 一、C#实现将文件、文件夹压缩为压缩包核心 1、介绍 Title:“基础工具” 项目(压缩包帮助类) Description步骤描述: 1、创建 zip 存档,该文档包含指定目录的文件和子目录…...

程序员跳槽,要求涨薪50%过分吗?
如果问在TI行业涨工资最快的方式是什么? 回答最多的一定是:跳槽! 前段时间,知乎上这样一条帖子引发了不少IT圈子的朋友的讨论 ,有网友提问 “程序员跳槽要求涨薪50%过分吗?” 截图来源于知乎,…...
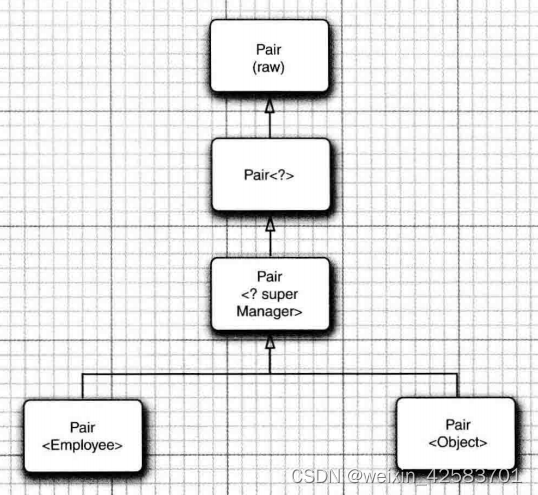
Java核心技术 卷1-总结-10
Java核心技术 卷1-总结-10 通配符类型通配符概念通配符的超类型限定无限定通配符通配符捕获 通配符类型 通配符概念 通配符类型中,允许类型参数变化。 例如,通配符类型Pair<? extends Employee>表示任何泛型Pair类型,它的类型参数是…...

React Props
state 和 props 主要的区别在于 props 是不可变的,而 state 可以根据与用户交互来改变。 所以,有些容器组件需要定义 state 来更新和修改数据。 而子组件只能通过 props 来传递数据。 props 使用 Demo.js : import React from reactfunct…...
【Hello Network】协议
作者:小萌新 专栏:网络 作者简介:大二学生 希望能和大家一起进步 本篇博客简介:简单介绍下协议并且设计一个简单的网络服务器 协议 协议的概念结构化数据传输序列化和反序列化网络版计算机服务端代码协议定制客户端代码服务线程执…...

零项目零科研,本科排名倒数,一战上岸上海交大电子与通信工程
笔者来自通信考研小马哥23上交819全程班学员 本科就读于哈工大(威海),本科成绩很差,专业排名62/99,没有科研,没有实验室,没有项目,连最基本大家都会参加的科技立项我四年也没有参与…...

NOIP模拟赛 T3区间
题目大意 有 n n n个数字,第 i i i个数字为 a i a_i ai。有 m m m次询问,每次给出 k i k_i ki个区间,每个区间表示第 l i , j l_{i,j} li,j到第 r i , j r_{i,j} ri,j个数字,求这些区间中一共出现了多少种不同的数字。部…...
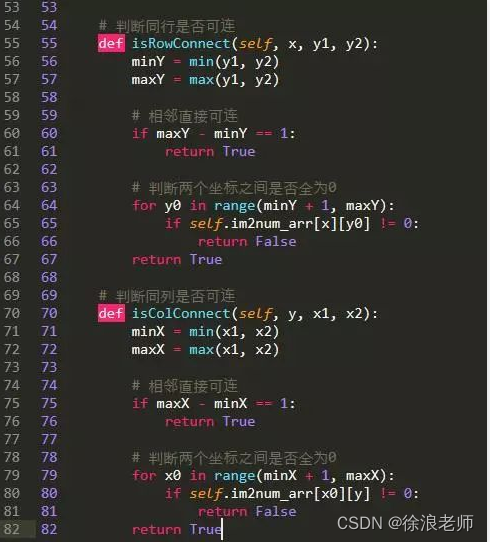
【Python】如何用pyth做游戏脚本(太简单了吧)
文章目录 前言一、开发前景二、开发流程3.1、获取窗口句柄,把窗口置顶3. 2、截取游戏界面,分割图标,图片比较 二、程序核心-图标连接算法(路径寻找)四、开发总结五、源码总结 前言 简述:本文将以4399小游戏…...
【Linux】磁盘与文件系统
目录 一、磁盘的物理结构 二、磁盘逻辑抽象 三、文件系统 1、Super Block 2、Group Descriptor Table 3、inode Table 4、Data Blocks 5、inode Bitmap 6、Block Bitmap 四、Linux下文件系统 1、inode与文件名 2、文件的增删查改 2.1、查看文件内容 2.2、删除文件…...
Transformer中的注意力机制及代码
文章目录 1、简介2、原理2.1 什么是注意力机制2.2 注意力机制在NLP中解决了什么问题2.3 注意力机制公式解读2.4 注意力机制计算过程 3、单头注意力机制与多头注意力机制4、代码4.1 代码14.2 代码2 1、简介 最近在学习transformer,首先学习了多头注意力机制…...

别再只查‘待办’了!Flowable任务查询的三种高级场景:拾取、归还与候选组权限控制详解
Flowable任务管理的三大高阶场景:从候选池到个人待办的完整控制策略 当我们在处理业务流程自动化时,任务管理往往是最容易被简化的环节。大多数开发者止步于基础的待办列表查询,却忽视了任务流转过程中的精细控制。本文将带您深入Flowable任务…...

Qwen3.5-9B-AWQ-4bit企业应用落地:电商商品图智能解析与文字提取实战
Qwen3.5-9B-AWQ-4bit企业应用落地:电商商品图智能解析与文字提取实战 1. 电商场景下的图片理解挑战 在电商运营中,每天需要处理海量商品图片。传统的人工审核和标注方式面临三大痛点: 效率瓶颈:人工处理一张商品图平均需要3-5分…...

实战构建企业技能评估系统:基于快马平台实现skill-vetter全流程解决方案
实战构建企业技能评估系统:基于快马平台实现skill-vetter全流程解决方案 最近在帮公司搭建内部技能认证系统时,发现传统线下考试方式存在效率低、数据难沉淀的问题。于是尝试用InsCode(快马)平台开发了一套skill-vetter系统,整个过程比想象中…...

落地生产级推理引擎!高性能GPU算子生成系统Kernel-Smith发布
在当今的大模型时代,高性能 GPU 算子(Kernel)是将硬件算力转化为实际吞吐量的核心引擎。无论是支撑 Megatron、vLLM、LMDeploy 等底层系统,还是驱动 AI for Science (AI4S) 的复杂科学计算,高效的算子实现都是释放硬件…...

攻克ComfyUI ControlNet Aux预处理难题:4个实用方案助你快速恢复功能
攻克ComfyUI ControlNet Aux预处理难题:4个实用方案助你快速恢复功能 【免费下载链接】comfyui_controlnet_aux ComfyUIs ControlNet Auxiliary Preprocessors 项目地址: https://gitcode.com/gh_mirrors/co/comfyui_controlnet_aux ComfyUI ControlNet Auxi…...

前端测试的学习阶段,由基础到进阶的过程认识.....
前言:突然想起刚入行的学习感悟,一个知识点不懂的背后,是整个知识体系的欠缺, 那会从后端转入前端(非科班)有时候一个报错不知道从何找起,一、单元测试 【已经案例和知识相结合,可看…...
Pixel Dream Workshop 快速上手:Python 零基础入门到生成第一幅AI画作
Pixel Dream Workshop 快速上手:Python 零基础入门到生成第一幅AI画作 1. 前言:为什么选择Pixel Dream Workshop 如果你对AI绘画感兴趣但苦于没有编程基础,这篇教程就是为你量身定制的。Pixel Dream Workshop是一个对新手极其友好的AI绘画工…...

ProfControl V8的介绍 组合成为模板
作者:刘凌波链接:环野电子, profcontrolhttp://oa.profcontrol.cn/teaching_V8-7926f783c6.html来源:ProfControl组合为模版1、按下SHIFT键,在地图区域空白处按下鼠标左键不松开,移动鼠标则进入框选模式,让…...
Pixel Epic实战案例:用AgentCPM-Report 3步生成逻辑严密深度研报
Pixel Epic实战案例:用AgentCPM-Report 3步生成逻辑严密深度研报 1. 引言:当研究报告遇上像素冒险 想象一下这样的场景:你需要完成一份关于新能源行业的深度研究报告,传统方式可能需要花费数周时间收集资料、分析数据、撰写内容…...

W25Q64 进阶应用:从电路设计到高效存储管理的实战解析
1. W25Q64硬件电路设计实战 第一次用W25Q64做项目时,我在电路设计上踩过不少坑。记得有个设备频繁出现数据丢失,最后发现是电源滤波没做好。这个8MB容量的SPI Flash芯片虽然引脚不多,但每个脚的设计细节都直接影响系统稳定性。 1.1 关键引脚…...