深度学习_Learning Rate Scheduling
我们在训练模型时学习率的设置非常重要。
- 学习率的大小很重要。如果它太大,优化就会发散,如果它太小,训练时间太长,否则我们最终会得到次优的结果。
- 其次,衰变率同样重要。如果学习率仍然很大,我们可能会简单地在最小值附近反弹,从而无法达到最优
我们可以通过学习率时间表(Learning Rate Scheduling)有效地管理准确性
一、基于FashionMNIST任务的学习率时间表实践准备
构建简单网络
def net_fn():model = nn.Sequential(nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2),nn.Conv2d(6, 16, kernel_size=5), nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2),nn.Flatten(),nn.Linear(16 * 5 * 5, 120), nn.ReLU(),nn.Linear(120, 84), nn.ReLU(),nn.Linear(84, 10))return model
模型结构如下(左-netron)
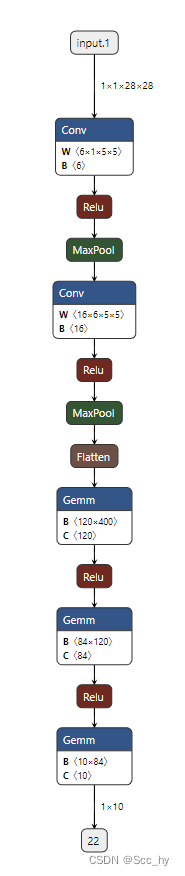
简单的训练框架
全部脚本可以查看笔者的github: LearningRateScheduling.ipynb
def train(model, train_iter, test_iter, config, scheduler=None):device = config.deviceloss = config.lossopt = config.optnum_epochs = config.num_epochsmodel.to(device)animator = Animator(xlabel='epoch', xlim=[0, num_epochs],legend=['train loss', 'train acc', 'test acc'])ep_total_steps = len(train_iter)for ep in range(num_epochs):tq_bar = tqdm(enumerate(train_iter))tq_bar.set_description(f'[ Epoch {ep+1}/{num_epochs} ]')# train_loss, train_acc, num_examplesmetric = Accumulator(3)for idx, (X, y) in tq_bar:final_flag = (ep_total_steps == idx + 1) & (num_epochs == ep + 1)model.train()opt.zero_grad()X, y = X.to(device), y.to(device)y_hat = model(X)l = loss(y_hat, y)l.backward()opt.step()with torch.no_grad():metric.add(l * X.shape[0], accuracy(y_hat, y), X.shape[0])train_loss = metric[0] / metric[2]train_acc = metric[1] / metric[2]tq_bar.set_postfix({"loss" : f"{train_loss:.3f}","acc" : f"{train_acc:.3f}",})if (idx + 1) % 50 == 0:animator.add(ep + idx / len(train_iter), (train_loss, train_acc, None), clear_flag=not final_flag)test_acc = evaluate_accuracy_gpu(model, test_iter)animator.add(ep+1, (None, None, test_acc), clear_flag=not final_flag)if scheduler:if scheduler.__module__ == lr_scheduler.__name__:# 使用 PyTorch In-Built schedulerscheduler.step()else:# 使用自定义 schedulerfor param_group in opt.param_groups:param_group['lr'] = scheduler(ep) print(f'train loss {train_loss:.3f}, train acc {train_acc:.3f}, 'f'test acc {test_acc:.3f}')plt.show()
二、基于FashionMNIST任务的学习率时间表实践
2.1 无learning rate Scheduler 训练
def test(train_iter, test_iter, scheduler=None):net = net_fn()cfg = Namespace(device=try_gpu(),loss=nn.CrossEntropyLoss(),lr=0.3, num_epochs=10,opt=torch.optim.SGD(net.parameters(), lr=0.3))train(net, train_iter, test_iter, cfg, scheduler)batch_size = 256
train_iter, test_iter = load_data_fashion_mnist(batch_size=batch_size)
test(train_iter, test_iter)
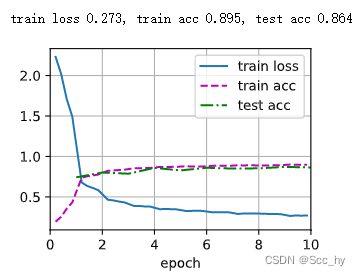
2.2 Square Root Scheduler训练
更新方式为
η = η ∗ n u m _ u p d a t e + 1 \eta =\eta *\sqrt{num\_update + 1} η=η∗num_update+1
本次试验是每一个epoch更新一次
def get_lr(scheduler):lr = scheduler.get_last_lr()[0]scheduler.optimizer.step()scheduler.step()return lrdef plot_scheduler(scheduler, num_epochs=10):s = scheduler.__class__.__name__if scheduler.__module__ == lr_scheduler.__name__:print('pytorch build lr_scheduler')plot_y = [get_lr(scheduler) for _ in range(num_epochs)]else:plot_y = [scheduler(t) for t in range(num_epochs)]plt.title(f'train with learning rate scheduler: {s}')plt.plot(torch.arange(num_epochs), plot_y)plt.xlabel('num_epochs')plt.ylabel('learning_rate')plt.show()class SquareRootScheduler:"""使用均方根scheduler每一个epoch更新一次"""def __init__(self, lr=0.1):self.lr = lrdef __call__(self, num_update):return self.lr * pow(num_update + 1.0, -0.5)scheduler = SquareRootScheduler(lr=0.1)
plot_scheduler(scheduler)
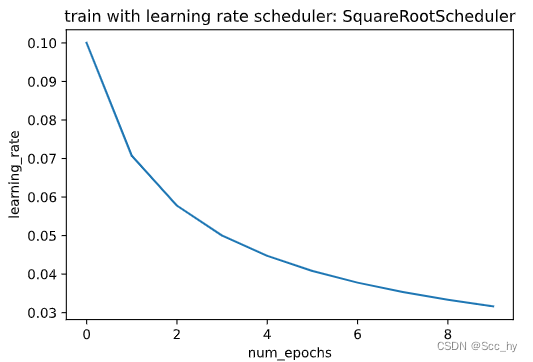
训练
test(train_iter, test_iter, scheduler)
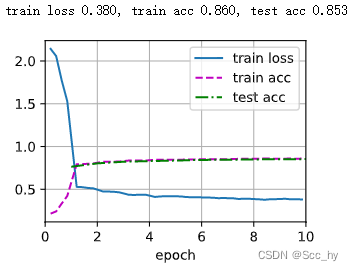
从下图中可以看出:曲线比以前更平滑了。其次,过度拟合较少。
2.3 FactorScheduler训练
学习率更新方式: η t + 1 ← m a x ( η m i n , η t ⋅ α ) \eta_{t+1} \leftarrow \mathop{\mathrm{max}}(\eta_{\mathrm{min}}, \eta_t \cdot \alpha) ηt+1←max(ηmin,ηt⋅α)
class FactorScheduler:def __init__(self, factor=1, stop_factor_lr=1e-7, base_lr=0.1):self.factor = factorself.stop_factor_lr = stop_factor_lrself.base_lr = base_lrdef __call__(self, num_update):self.base_lr = max(self.stop_factor_lr, self.base_lr * self.factor)return self.base_lrscheduler = FactorScheduler(factor=0.8, stop_factor_lr=1e-2, base_lr=0.6)
plot_scheduler(scheduler)
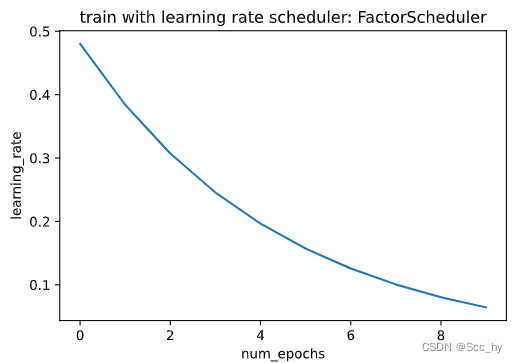
训练
test(train_iter, test_iter, scheduler)
2.4 Multi Factor Scheduler训练
保持学习率分段恒定,并每隔一段时间将其降低一个给定的量。也就是说,给定一组何时降低速率的时间比如$ (s = {3, 8} )$
d e c r e a s e ( η t + 1 ← η t ⋅ α ) t ∈ s decrease (\eta_{t+1} \leftarrow \eta_t \cdot \alpha) \ \ t \in s decrease(ηt+1←ηt⋅α) t∈s
net = net_fn()
trainer = torch.optim.SGD(net.parameters(), lr=0.5)
scheduler = lr_scheduler.MultiStepLR(trainer, milestones=[3, 8], gamma=0.5)plot_scheduler(scheduler)
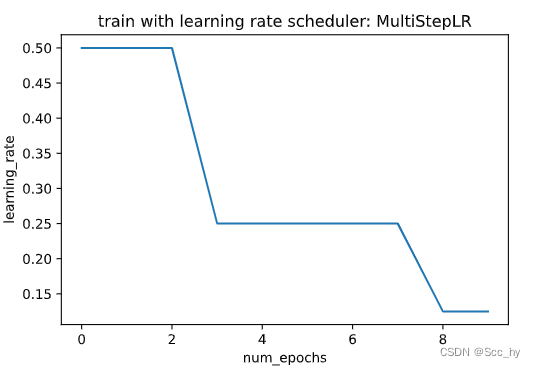
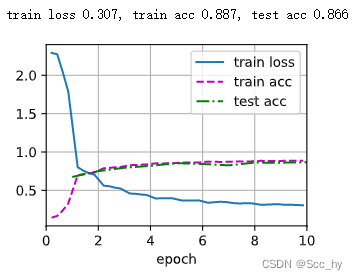
训练
test(train_iter, test_iter, scheduler)
2.5 Cosine Scheduler训练
Loshchilov和Hutter提出了一个相当令人困惑的启发式方法。它依赖于这样一种观察,即我们可能不想在一开始就大幅降低学习率,此外,我们可能希望在最后使用非常小的学习率来“完善”解决方案。这导致了一个类似余弦的时间表,具有以下函数形式,用于范围内的学习率 t ∈ [ 0 , T ] t \in [0, T] t∈[0,T]
η t = η T + η 0 − η T 2 ( 1 + cos ( π t T ) ) \eta_t = \eta_T + \frac{\eta_0 - \eta_T}{2} \left(1 + \cos(\frac{\pi t}{T})\right) ηt=ηT+2η0−ηT(1+cos(Tπt))
注:
- η T \eta_T ηT: 为最终的学习率
- η 0 \eta_0 η0: 为最开始的学习率
class CosineScheduler:def __init__(self, max_update, base_lr=0.01, final_lr=0,warmup_steps=0, warmup_begin_lr=0):self.base_lr_orig = base_lrself.max_update = max_updateself.final_lr = final_lrself.warmup_steps = warmup_stepsself.warmup_begin_lr = warmup_begin_lrself.max_steps = self.max_update - self.warmup_stepsdef get_warmup_lr(self, step):increase = (self.base_lr_orig - self.warmup_begin_lr) \* float(step) / float(self.warmup_steps)return self.warmup_begin_lr + increasedef __call__(self, step):if step < self.warmup_steps:return self.get_warmup_lr(step)if step <= self.max_update:self.base_lr = self.final_lr + (self.base_lr_orig - self.final_lr) * (1 + math.cos(math.pi * (step - self.warmup_steps) / self.max_steps)) / 2return self.base_lrscheduler = CosineScheduler(max_update=10, base_lr=0.2, final_lr=0.02)
plot_scheduler(scheduler)
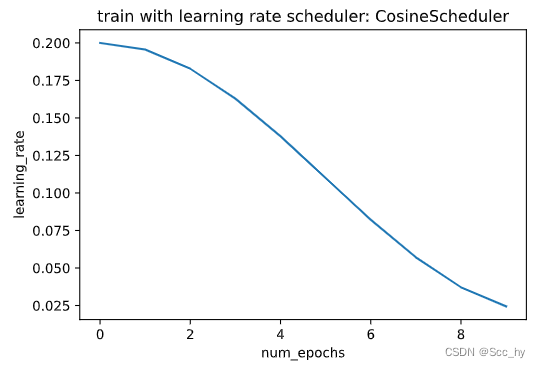
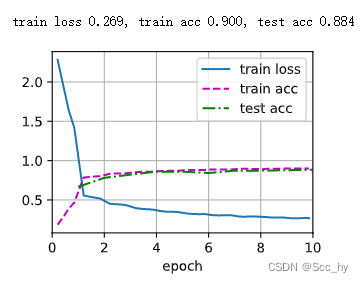
训练
test(train_iter, test_iter, scheduler)
2.6 Warmup
在某些情况下,初始化参数不足以保证良好的解决方案。对于一些先进的网络设计来说,这尤其是一个问题(Transformer的训练常用该方法),可能会导致不稳定的优化问题。
我们可以通过选择一个足够小的学习率来解决这个问题,以防止一开始就出现分歧。不幸的是,这意味着进展缓慢。相反,学习率高最初会导致差异。
对于这种困境,一个相当简单的解决方案是使用一个预热期,在此期间学习速率增加到其初始最大值,并冷却速率直到优化过程结束。为了简单起见,通常使用线性增加来实现这一目的。
scheduler = CosineScheduler(max_update=10, warmup_steps=3, base_lr=0.2, final_lr=0.02)
plot_scheduler(scheduler, 15)
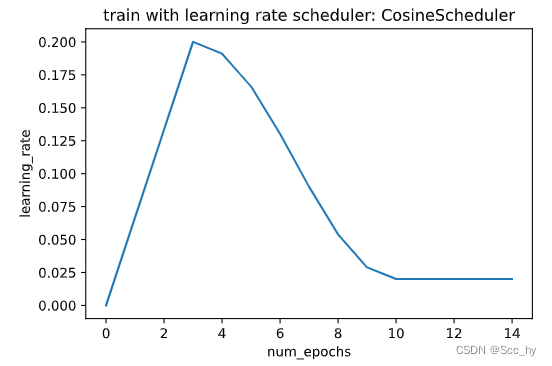
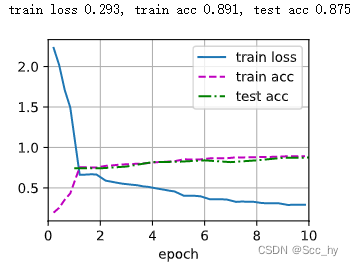
训练
test(train_iter, test_iter, scheduler)
小结
从上述的5个策略上来看,一般情况我们用 Cosine Scheduler 或者线性衰减就能得到较好的结果。不过对于较大的模型,需要用warmup 并且需要特意去设计,比如NoamOpt等。
相关文章:
深度学习_Learning Rate Scheduling
我们在训练模型时学习率的设置非常重要。 学习率的大小很重要。如果它太大,优化就会发散,如果它太小,训练时间太长,否则我们最终会得到次优的结果。其次,衰变率同样重要。如果学习率仍然很大,我们可能会简…...
)
snmp服务利用(端口:161、199、391、705、1993)
服务介绍 简单网络管理协议 是一种广泛应用于TCP/IP网络的网络管理标准协议(应用层协议),它提供了一种通过运行网络管理软件的中心计算机(即网络管理工作站)来监控和管理计算机网络的标准化管理框架(方法)。目前已颁布了SNMPv1、SNMPv2c和SNMPv3三个版本,广泛应用于网…...
MyBatis(二)—— 进阶
一、详解配置文件 1.1 核心配置文件 官方建议命名为mybatis-config.xml,核心配置文件里可以进行如下的配置: <environments> 和 <environment> mybatis可以配置多套环境(开发一套、测试一套、、、), 在…...
婚恋交友app开发中需要注意的安全问题
前言 随着移动设备的普及,婚恋交友app已经成为了人们生活中重要的一部分。但是,这些应用的开发者需要确保应用的安全性,以保护用户的隐私和数据免受攻击。本文将介绍在婚恋交友app开发中需要注意的安全问题。 在当今数字化时代,…...

相机的内参和外参介绍
注:以下相机内参与外参介绍除来自网络整理外全部来自于《视觉SLAM十四讲从理论到实践 第2版》中的第5讲:相机与图像,为了方便查看,我将每节合并到了一幅图像中 相机与摄像机区别:相机着重于拍摄静态图像&#x…...

Node【包】
文章目录 🌟前言🌟Nodejs包🌟什么是包?🌟自定义包🌟包配置文件🌟示例🌟Package.json 属性说明🌟语义化版本号🌟package.json示例 🌟符合CommonJS规…...

CHAPTER 2: 《BACK-OF-THE-ENVELOPE ESTIMATION》 第2章 《初略的估计》
CHAPTER 2: BACK-OF-THE-ENVELOPE ESTIMATION 在系统设计面试中,有时您会被要求估计系统容量或使用粗略估计的性能需求。根据杰夫迪恩的说法,谷歌高级研究员,“粗略的计算是你使用结合思想实验和常见的性能数字,以获得良好的感觉…...

RocketMQ高级概念
一 RocketMQ核心概念 1.消息模型(Message Model) RocketMQ主要由 Producer、Broker、Consumer 三部分组成,其中Producer 负责⽣产消息,Consumer 负责消费消息,Broker 负责存储消息。Broker 在实际部署过程中对应⼀台…...
eureka注册中心和RestTemplate
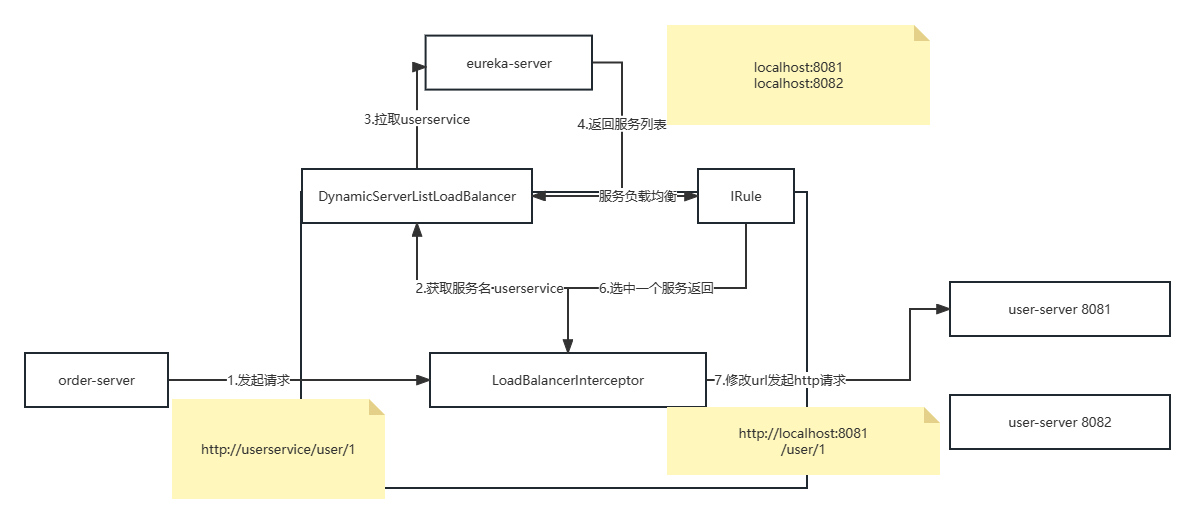
eureka注册中心和restTemplate的使用说明 eureka的作用 消费者该如何获取服务提供者的具体信息 1.服务者启动时向eureka注册自己的信息 2.eureka保存这些信息 3.消费者根据服务名称向eureka拉去提供者的信息 如果有多个服务提供者,消费者该如何选择? 服…...
redis复制的设计与实现
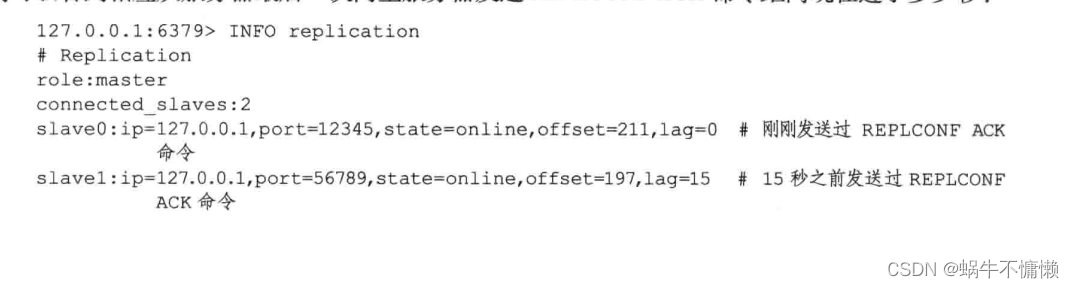
一、复制 1.1旧版功能的实现 旧版Redis的复制功能分为 同步(sync)和 命令传播。 同步用于将从服务器更新至主服务器的当前状态。命令传播用于 主服务器状态变化时,让主从服务器状态回归一致。 1.1.1同步 当客户端向服务端发送slaveof命令…...
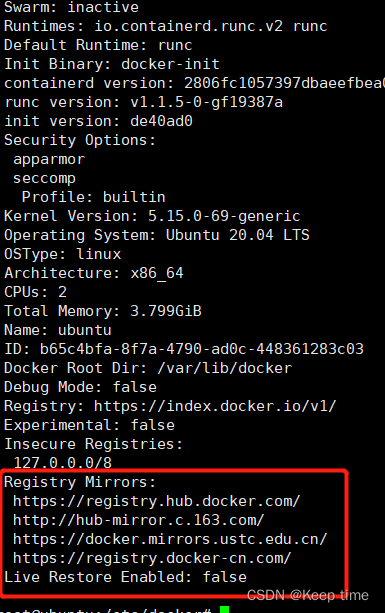
Docker更换国内镜像源
什么是Docker Docker 是一个开源的应用容器引擎,基于 Go 语言 并遵从 Apache2.0 协议开源。 Docker 可以让开发者打包他们的应用以及依赖包到一个轻量级、可移植的容器中,然后发布到任何流行的 Linux 机器上,也可以实现虚拟化。 容器是完全…...
【网络编程】网络套接字,UDP,TCP套接字编程
前言 小亭子正在努力的学习编程,接下来将开启javaEE的学习~~ 分享的文章都是学习的笔记和感悟,如有不妥之处希望大佬们批评指正~~ 同时如果本文对你有帮助的话,烦请点赞关注支持一波, 感激不尽~~ 特别说明:本文分享的代码运行结果…...
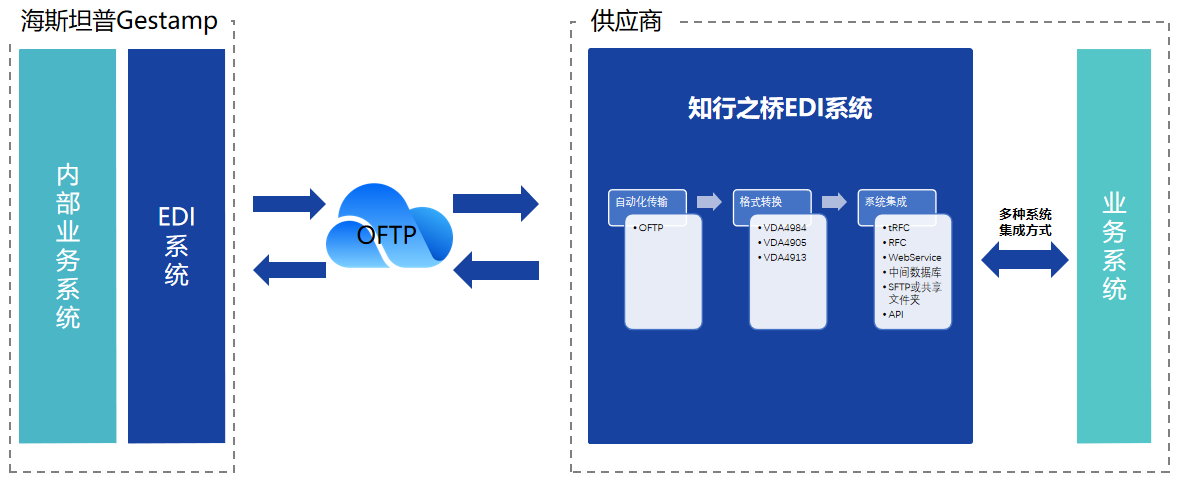
海斯坦普Gestamp EDI 需求分析
海斯坦普Gestamp(以下简称:Gestamp)是一家总部位于西班牙的全球性汽车零部件制造商,目前在全球23个国家拥有超过100家工厂。Gestamp的业务涵盖了车身、底盘和机电系统等多个领域,其产品范围包括钣金、车身结构件、车轮…...
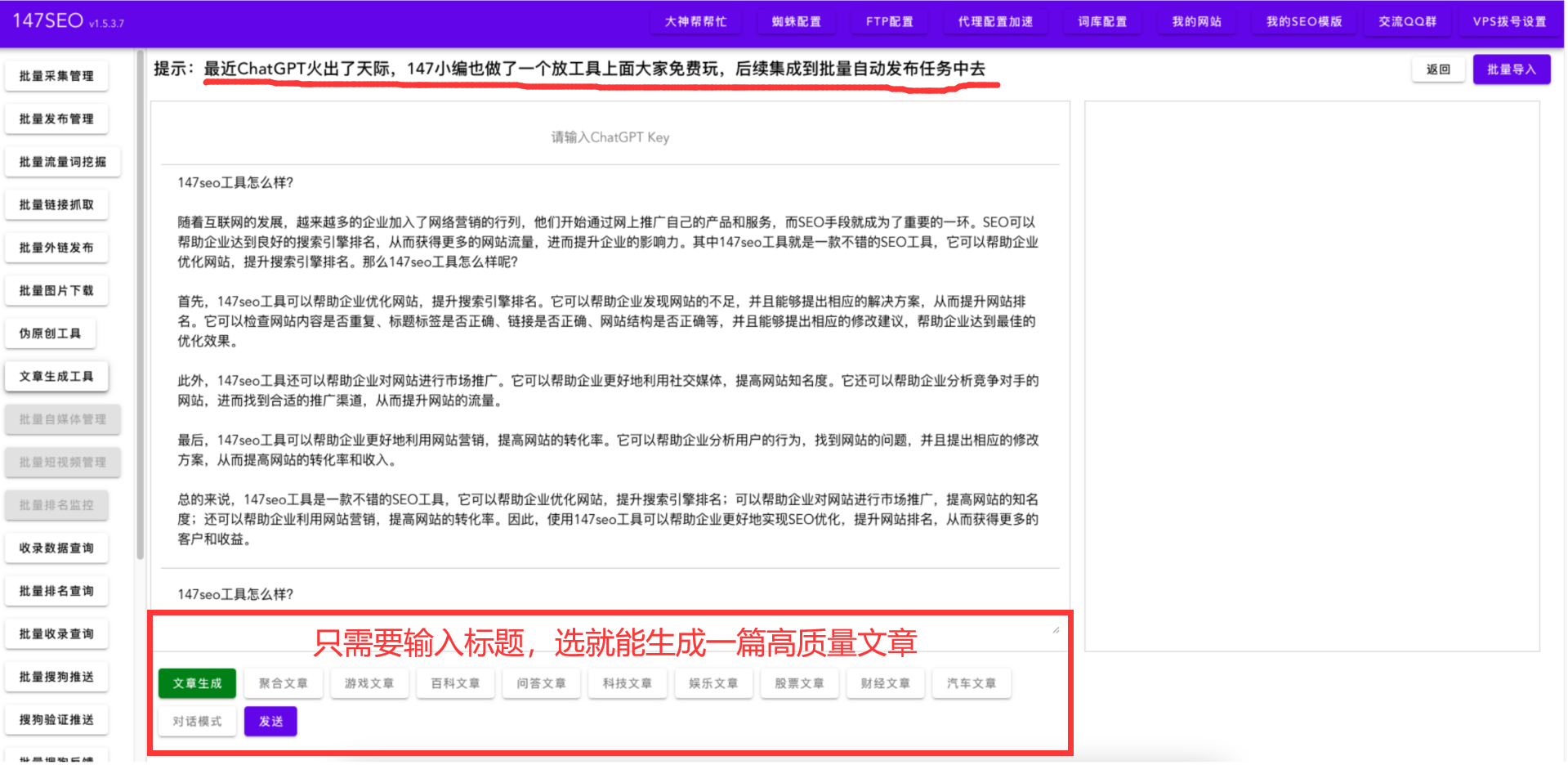
gpt写文章批量写文章-gpt3中文生成教程
怎么用gpt写文章批量写文章 批量写作文章是很多网站、营销人员、编辑等需要的重要任务,GPT可以帮助您快速生成大量自然、通顺的文章。下面是一个简单的步骤介绍,告诉您如何使用GPT批量写作文章。 步骤1:选择好训练模型 首先,选…...

HashMap实现原理
HashMap是基于散列表的Map接口的实现。插入和查询的性能消耗是固定的。可以通过构造器设置容量和负载因子,一调整容易得性能。 散列表:给定表M,存在函数f(key),对任意给定的关键字值key,代入函数后若能得到包含该关键字…...

【Java 数据结构】PriorityQueue(堆)的使用及源码分析
🎉🎉🎉点进来你就是我的人了 博主主页:🙈🙈🙈戳一戳,欢迎大佬指点!人生格言:当你的才华撑不起你的野心的时候,你就应该静下心来学习! 欢迎志同道合的朋友一起加油喔🦾&am…...

使用 Kubernetes 运行 non-root .NET 容器
翻译自 Richard Lander 的博客 Rootless 或 non-root Linux 容器一直是 .NET 容器团队最需要的功能。我们最近宣布了所有 .NET 8 容器镜像都可以通过一行代码配置为 non-root 用户。今天的文章将介绍如何使用 Kubernetes 处理 non-root 托管。 您可以尝试使用我们的 non-root…...

为什么大量失业集中爆发在2023年?被裁?别怕!失业是跨越职场瓶颈的关键一步!对于牛逼的人,这是白捡N+1!...
被裁究竟是因为自身能力不行,还是因为大环境不行? 一位网友说: 被裁后找不到工作,本质上还是因为原来的能力就配不上薪资。如果确实有技术在身,根本不怕被裁,相当于白送n1! 有人赞同楼主的观点&…...
Word控件Spire.Doc 【脚注】字体(3):将Doc转换为PDF时如何使用卸载的字体
Spire.Doc for .NET是一款专门对 Word 文档进行操作的 .NET 类库。在于帮助开发人员无需安装 Microsoft Word情况下,轻松快捷高效地创建、编辑、转换和打印 Microsoft Word 文档。拥有近10年专业开发经验Spire系列办公文档开发工具,专注于创建、编辑、转…...

keil5使用c++编写stm32控制程序
keil5使用c编写stm32控制程序 一、前言二、配置图解三、std::cout串口重定向四、串口中断服务函数五、结尾废话 一、前言 想着搞个新奇的玩意玩一玩来着,想用c编写代码来控制stm32,结果在keil5中,把踩给我踩闷了,这里简单记录一下…...

免费开源神器:SMUDebugTool让你轻松掌控AMD Ryzen处理器的秘密
免费开源神器:SMUDebugTool让你轻松掌控AMD Ryzen处理器的秘密 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: ht…...

解锁音乐边界:Windows平台下网易云音乐NCM文件格式转换解决方案
解锁音乐边界:Windows平台下网易云音乐NCM文件格式转换解决方案 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 在数字音乐消费日益普及的今天&…...

英特尔现代代码开发挑战:实战性能优化与工具链应用指南
1. 项目概述:一场面向开发者的实战演练最近深度参与并复盘了英特尔举办的“现代代码开发挑战”网络研讨会,感触颇深。这远不止是一场普通的技术分享会,而是一个精心设计的、让开发者亲手“触摸”现代硬件性能潜力的实战沙盒。如果你是一名C/C…...

RTX166任务调度:K_IVL与K_TMO事件机制详解
1. RTX166任务调度中的K_IVL与K_TMO事件机制解析在RTX166实时操作系统中,os_wait函数提供的K_IVL和K_TMO事件是任务调度的核心机制。这两个看似相似的延时控制参数,在实际应用中却有着截然不同的行为模式。作为深耕嵌入式领域十余年的开发者,…...
线上服务卡顿?从一次ES写入超时故障,复盘我是如何调整`refresh_interval`和`translog`参数的
线上服务卡顿?一次Elasticsearch写入超时故障的深度调优实战 凌晨三点,监控系统突然告警——核心服务的API响应时间突破5秒阈值。快速排查发现,所有慢请求都卡在了日志写入环节。作为运维负责人,我立即意识到这又是一次Elasticsea…...

Cortex-M7 WIC模块移除的影响与工程实践
1. Cortex-M7中移除WIC的影响解析在嵌入式系统设计中,Cortex-M7处理器的WIC(Wakeup Interrupt Controller)模块是一个值得深入探讨的组件。作为一位从事ARM架构开发多年的工程师,我经常遇到客户询问关于WIC配置的问题。这个看似简…...

okbiye 降重 | 降 AIGC 功能实测:双标检测时代,论文合规通关的新解法
okbiye-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPT降重复率 - Okbiye智能写作https://www.okbiye.com/reduceAIGC 引言:从 “单查重” 到 “双标审”,毕业论文合规压力的全面升级 当你熬夜写完一篇万字毕业论文,用查…...
)
2026年数据驱动经济与信息管理国际学术会议(DDEMI 2026)
2026年数据驱动经济与信息管理国际学术会议(DDEMI 2026)会议时间:2026年8月07日-09日会议地点:江苏-南京截稿日期:2026年7月31日录用结果:投稿后1周内收录检索:EI Compendex, Scopus【大会简介】…...

2026 年 5 月 AI 热点:大模型、硬件、人形机器人全面升级
一、大模型技术突破 | LLM Technology Breakthroughs 1.1 OpenAI GPT‑5.5 正式成为ChatGPT默认模型 | GPT‑5.5 Becomes ChatGPT Default Model 英文内容 | English On May 5, 2026, OpenAI officially rolled out GPT‑5.5 Instant as the new default model for ChatGPT, …...

航空航班延误预测:可解释性模型与四源融合实战
1. 项目概述:这不是一个“预测准不准”的问题,而是一个“预测有没有用”的问题我做航班延误预测项目,不是为了在Kaggle排行榜上刷个0.89的AUC就收工。真正让我在凌晨三点改完第17版特征工程脚本、盯着滚动的日志等模型收敛的,是去…...