Flink主要有两种基础类型的状态:operator state。
Flink主要有两种基础类型的状态:keyed state 和operator state。
Operator State
对于Operator State(或者non-keyed state),每个operator state绑定到一个并行operator实例上。在Flink中,Kafka Connector是一个使用Operator State的很好的例子。每个并行Kafka消费者实例维护一个主题分区和偏移的map作为它的Operator State。
当并行度被修改时,Operator State接口支持在并行operator实例上重新分配状态。进行这种重新分配可以有不同的方案。
Raw and Managed State
Keyed State 和 Operator State 有两种形式: managed和raw。
Managed State表示数据结构由Flink runtime控制,例如内部哈希表或者RocksDB。例如,“ValueState”,“ListState”等等。Flink的runtime层会编码State并将其写入checkpoint中。
Raw State是操作算子保存在它的数据结构中的state。当进行checkpoint时,它只写入字节序列到checkpoint中。Flink并不知道状态的数据结构,并且只能看到raw字节。
所有的数据流函数都可以使用managed state,但是raw state接口只可以在操作算子的实现类中使用。推荐使用managed state(而不是raw state),因为使用managed state,当并行度变化时,Flink可以自动的重新分布状态,也可以做更好的内存管理。
注意 如果你的managed state需要自定义序列化逻辑,请参见managed state的自定义序列化以确保未来的兼容性。Flink默认的序列化不需要特殊处理。
managed non-keyed state
可以通过实现CheckpointedFunction或者ListCheckpointed接口,来使用managed non-keyed状态。
1.CheckpointedFunction
CheckpointedFunction接口通过不同的重新分配方案提供对non-keyed状态的访问。它需要实现两种方法:
void snapshotState(FunctionSnapshotContext context) throws Exception;
void initializeState(FunctionInitializationContext context) throws Exception;
每当必须执行checkpoint时,都会调用snapshotState()。对应的initializeState()在每次初始化用户定义的函数时调用,可以是在函数第一次初始化时调用,也可以是在函数实际从较早的checkpoint恢复时调用。因此,initializeState()不仅是初始化不同类型状态的地方,也是状态恢复逻辑实现地方。
目前,支持List样式的管理操作状态。状态是一个可序列化对象的列表,彼此独立,因此在重新扫描时能够进行重新分区。换句话说,这些对象是可以重新分区no-keyed状态的最佳粒度。根据状态访问方法的不同,定义了以下重分区方案:
Even-split redistribution:每个操作算子返回一个状态元素列表。逻辑上串联起所有的列表就是状态元素完整列表。在恢复/重新分区时,该列表会均分成算子实例个数个子列表。每个操作算子实例获取一个子列表,该子列表可以是空的,也可以包含一个或多个元素。例如,如果并行度为1,则操作算子的检查点状态包含元素element1和element2。当并行度增加到2时,element1可能会出现在算子实例0中,而element2会出现在算子实例1中。
Union redistribution: 每个操作算子返回一个状态元素列表。整个状态在逻辑上是串联起所有列表。在恢复/重新分发时,每个操作算子都获得状态元素的完整列表。
下面是一个有状态的SinkFunction,在讲数据元素写入外部存储之前使用CheckpointedFunction来缓存元素。主要是用来验证event-split充分布list状态。
下面的例子是一个有状态的SinkFunction,该sink会在数据发送到外部存储之前缓存数据元素。该例子是机遇均分重分布来实现的:
public class BufferingSink
implements SinkFunction<Tuple2<String, Integer>>,
CheckpointedFunction {
private final int threshold;private transient ListState<Tuple2<String, Integer>> checkpointedState;private List<Tuple2<String, Integer>> bufferedElements;public BufferingSink(int threshold) {this.threshold = threshold;this.bufferedElements = new ArrayList<>();
}@Override
public void invoke(Tuple2<String, Integer> value) throws Exception {bufferedElements.add(value);if (bufferedElements.size() == threshold) {for (Tuple2<String, Integer> element: bufferedElements) {// send it to the sink}bufferedElements.clear();}
}@Override
public void snapshotState(FunctionSnapshotContext context) throws Exception {checkpointedState.clear();for (Tuple2<String, Integer> element : bufferedElements) {checkpointedState.add(element);}
}@Override
public void initializeState(FunctionInitializationContext context) throws Exception {ListStateDescriptor<Tuple2<String, Integer>> descriptor =new ListStateDescriptor<>("buffered-elements",TypeInformation.of(new TypeHint<Tuple2<String, Integer>>() {}));checkpointedState = context.getOperatorStateStore().getListState(descriptor);if (context.isRestored()) {for (Tuple2<String, Integer> element : checkpointedState.get()) {bufferedElements.add(element);}}
}
}
initializeState方法以FunctionInitializationContext作为参数。用于初始化non-keyed状态“containers”。这是ListState类型的容器,其中non-keyed状态对象将在checkpoint上存储。
留意状态是如何初始化的,类似于keyed状态,使用一个StateDescriptor,其中包含状态名和关于状态持有的值的类型的信息:
ListStateDescriptor<Tuple2<String, Integer>> descriptor =
new ListStateDescriptor<>(
“buffered-elements”,
TypeInformation.of(new TypeHint<Tuple2<Long, Long>>() {}));
checkpointedState = context.getOperatorStateStore().getListState(descriptor);
状态访问方法的命名约定包含其重分区模式及其状态结构。例如,要在还原时使用具有union重分区方案的list state,使用getUnionListState(descriptor)访问状态。如果方法名不包含重分区模式,例如getListState(descriptor),它仅仅意味着将使用均分重分区模式(Even-split redistribution)。
在初始化container之后,我们使用上下文的isrestore()方法检查失败后是否正在恢复。如果是true,即正在恢复,则执行恢复逻辑。
如修改后的BufferingSink代码所示,状态初始化期间恢复的数据保存在一个ListState变量中,以备将来在snapshotState()中使用。在那里,ListState将清除前一个检查点包含的所有对象,然后被我们想要检查的新选项填满。
另外,keyed状态也可以在initializeState()方法中初始化。可以使用FunctionInitializationContext来完成。
2.ListCheckpointed
ListCheckpointed接口是CheckpointedFunction的一个有限制的变体,它只支持列表样式的状态,在恢复时使用均分重分区方案。它还需要实现两种方法:
List snapshotState(long checkpointId, long timestamp) throws Exception;
void restoreState(List state) throws Exception;
在snapshotState()上,操作应该向检查点返回一个对象列表,而restoreState()必须在恢复时处理这个列表。如果状态不可重分区,则始终可以在snapshotState()中返回Collections.singletonList(MY_STATE)。
有状态的源函数(Stateful Source Functions)
与其他操作符相比,有状态源需要更多的关注。为了更新状态和输出集合的原子性(用于故障/恢复上的精确一次语义),用户需要从源上下文获取一个锁。
public static class CounterSource
extends RichParallelSourceFunction
implements ListCheckpointed {
/** current offset for exactly once semantics */
private Long offset;/** flag for job cancellation */
private volatile boolean isRunning = true;@Override
public void run(SourceContext<Long> ctx) {final Object lock = ctx.getCheckpointLock();while (isRunning) {// output and state update are atomicsynchronized (lock) {ctx.collect(offset);offset += 1;}}
}@Override
public void cancel() {isRunning = false;
}@Override
public List<Long> snapshotState(long checkpointId, long checkpointTimestamp) {return Collections.singletonList(offset);
}@Override
public void restoreState(List<Long> state) {for (Long s : state)offset = s;
}
}
当Flink完全确认检查点时,一些操作可能需要这些信息来与外部世界进行通信。在本例中,请参见org.apache.flink.runtime.state.CheckpointListener接口。
相关文章:

Flink主要有两种基础类型的状态:operator state。
Flink主要有两种基础类型的状态:keyed state 和operator state。 Operator State 对于Operator State(或者non-keyed state),每个operator state绑定到一个并行operator实例上。在Flink中,Kafka Connector是一个使用Operator State的很好的例…...

【vue2】使用vue-admin-template动态添加路由的思路/addRoutes的使用
😉博主:初映CY的前说(前端领域) ,📒本文核心:用原生js实现省市区联动 【前言】在通用的后台管理项目的开发中,不仅仅是会涉及到对表单数据等的增删改查操作还会涉及到一些关于权限管理的问题。我们将基于一个RBAC的思维…...
Python语言中的注释方法应用
Python语言中的注释方法 在Python编程中,与其他编程语言一样,有良好的注释部分,会让你的程序在后续的改进或优化中,变得便利。同时,给自己培养了良好的编程习惯。 在Python语言中,有两种注释方法。 1.单行…...

Google浏览器翻译无法正常使用解决
1.查找可用服务器地址 按WinR键打开运行→输入cmd回车,打开命令提示符→输入ping google.cn 回车。记录一下下图红框里的ip地址,一会要用到 最近自己ping出来的ip可能不能用了,可以尝试用下面的ip 142.251.163.90 142.250.113.90 142.251.…...
ETCD(三)操作指令
1. put put #将给定的key写入到存储 --ignore-lease[false] #使用当前租约更新key --ignore-value[false] #使用当前值更新key --lease"0" # 要附加到key的租约ID(十六进制) --prev-kv[false] # 返回修改前的上一个键值对2. get get #获取给…...

小白学Pytorch系列--Torch.optim API Base class(1)
小白学Pytorch系列–Torch.optim API Base class(1) torch.optim是一个实现各种优化算法的包。大多数常用的方法都已得到支持,而且接口足够通用,因此将来还可以轻松集成更复杂的方法。 如何使用优化器 使用手torch.optim您必须构造一个优化器对象&…...

flac格式如何转mp3,3招帮你搞定
flac格式如何转mp3,3招帮你搞定的方法来啦。当你的音频是flac格式是不是很头疼,又不知道怎么转mp3 。然后网上搜索出很多方法又不知道从哪个下手,是不是很疑惑?那今天就来看看小编推荐的方法吧,一定让你眼前一亮&#…...
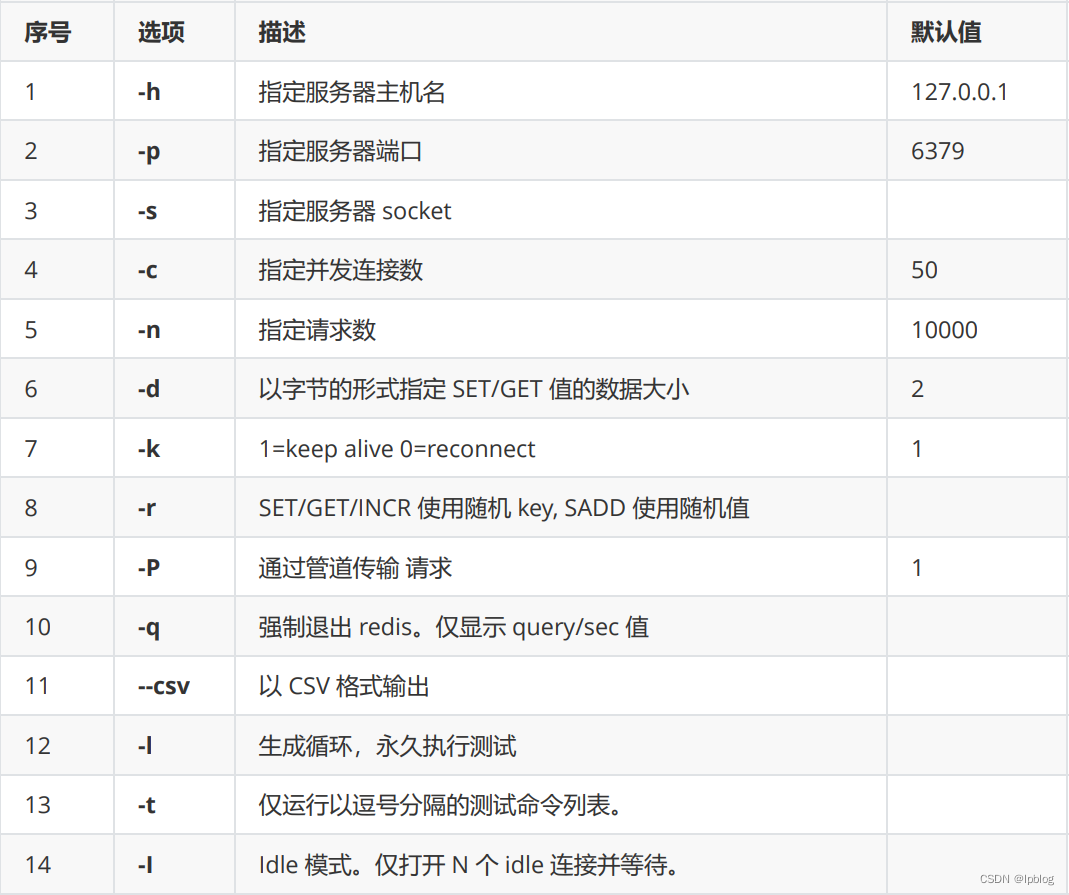
Redis入门到入土(day01)
NoSQL概述 为什么用NoSQL 1、单机MySQL的美好年代 在90年代,一个网站的访问量一般不大,用单个数据库完全可以轻松应付! 在那个时候,更多的都是静态网页,动态交互类型的网站不多。 上述架构下,我们来看看…...
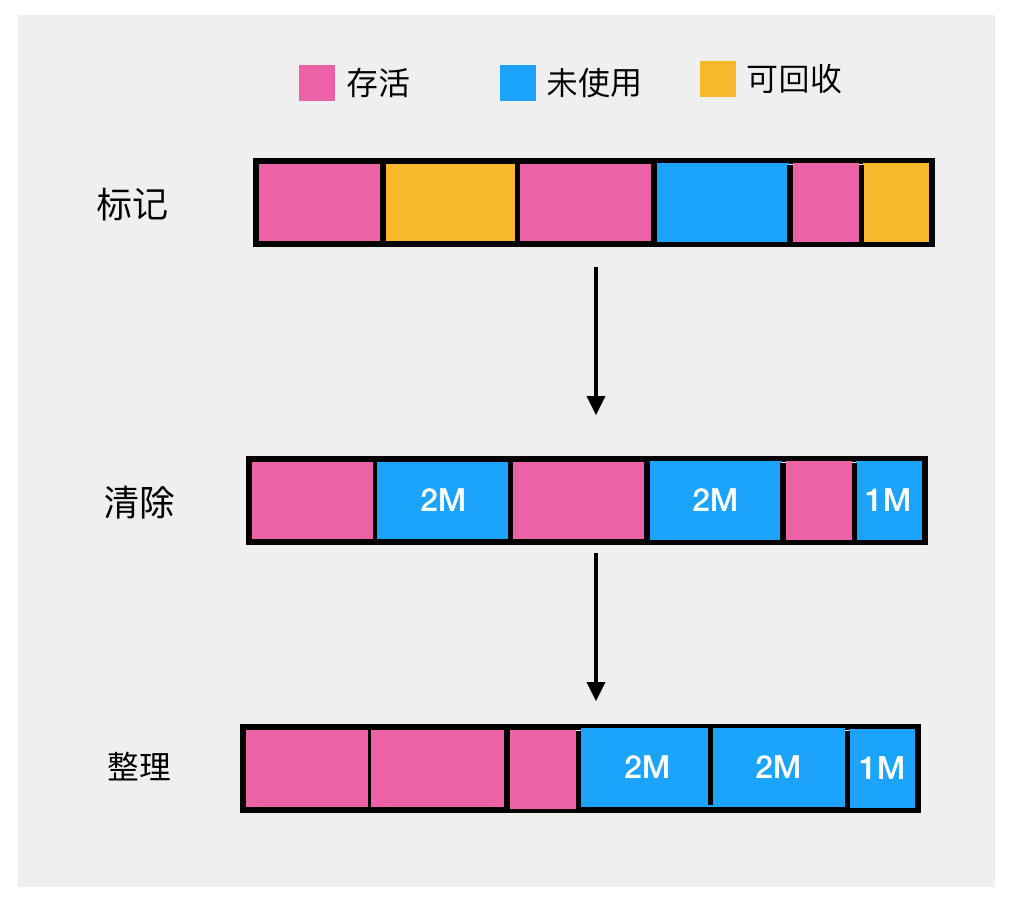
JVM垃圾回收GC 详解(java1.8)
目录 垃圾判断算法(你是不是垃圾?) 引用计数法 可达性算法 对象的引用 强引用 软引用 弱引用 虚引用 对象的自我救赎 垃圾回收算法--分代 标记清除算法 复制算法 标记整理法 垃圾处理器 垃圾判断算法(你是不是垃圾&…...

Mybatis-Plus -03 Mybatis-Plus实现CRUD
Mybatis-Plus实现CRUD 1 Insert增加2 ID生成策略3 Delete删除4 逻辑删除5 Update修改6 Select查询 Mybatis-Plus实现CRUD 通用 CRUD 封装**BaseMapper (opens new window)**接口,为 Mybatis-Plus 启动时自动解析实体表关系映射转换为 Mybatis 内部对象注入容器参数 …...

综合能源系统中基于电转气和碳捕集系统的热电联产建模与优化研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
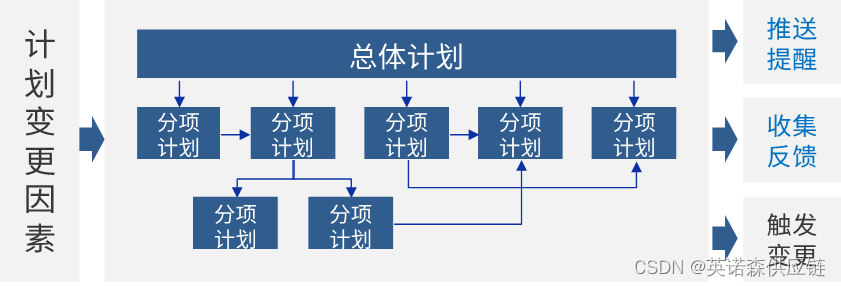
“智慧赋能 强链塑链”|工程物资供应链管理中的数字化应用
工程项目中的供应链管理至关重要 工程建设行业是国民经济的重要支柱之一,虽然在总产值上持续保持增长态势,但近年来行业的利润总额增速已连续多年呈现下降趋势。究其原因,可以大体从两个方面来看:一是行业盈利能力出现下降&#x…...

通过docker发布项目
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言例如:docker项目的发布方式 [docker发布的参考链接](https://www.cnblogs.com/emperorking/articles/11244253.html) 一、docker是什么?…...
为什么Spring和IDEA不推荐使用@Autowired注解?
在Spring开发中,Autowired注解是一个常用的依赖注入方式。但是,你可能会惊奇地发现,Spring和IDEA都不推荐使用Autowired注解。关于这个问题,其实答案相对统一,实际上用大白话说起来也容易理解。 官方答案 首先&#…...
windows下运行dpdk下的helloworld
打开“本地安全策略”管理单元,在搜索框输入secpol。 打开本地策略->用户权限分配->锁定内存页->添加用户或组->高级->立即查找 输入电脑用户名,选择并添加。点击确定后,重启电脑。 安装内核驱动,下载地址https://download.csdn.net/download/qq_36314864…...
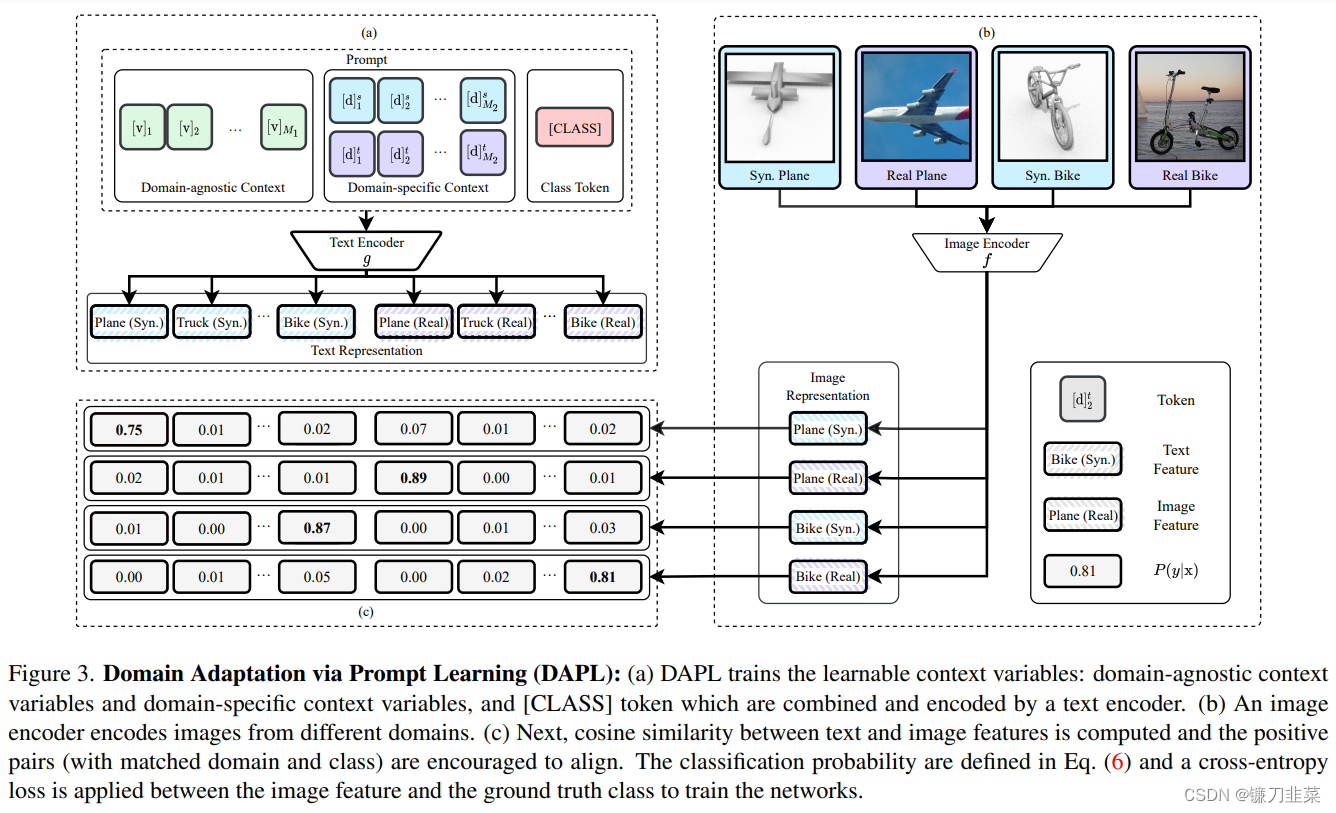
【AI理论学习】深入理解Prompt Learning和Prompt Tuning
深入理解Prompt Learning和Prompt Tuning 背景Prompt Learning简介1. Prompt是什么?2. 为什么要使用Prompt?3. Prompt Learning的形式(举例)4. 有哪些Pre-training language model?5. 常见的Prompt Learning的方法 Pro…...

从Authy中导出账户和secret
本文转载于我的博客从Authy中导出账户和secret 前言 因为最近买了CanoKey,所以多算试一下CanoKey的TOTP功能,但是之前一直用的Authy并且它默认不支持导出功能 在网上找了一些文档,终于在github上找到了一个有效且简单的方法 目前网上大部分…...

图像锐度评分算法,方差,点锐度法,差分法,梯度法
图像锐度评分算法,方差,点锐度法,差分法,梯度法 图像锐度评分是用来描述图像清晰度的一个指标。常见的图像锐度评分算法包括方差法、点锐度法、差分法和梯度法等。 方差法:该方法是通过计算图像像素值的方差来评估图像…...

查询练习:连接查询
准备用于测试连接查询的数据: CREATE DATABASE testJoin;CREATE TABLE person (id INT,name VARCHAR(20),cardId INT );CREATE TABLE card (id INT,name VARCHAR(20) );INSERT INTO card VALUES (1, 饭卡), (2, 建行卡), (3, 农行卡), (4, 工商卡), (5, 邮政卡); S…...

【mmdeploy】【TODO】使用mmdeploy将mmdetection模型转tensorrt
mmdetection转换 文章目录 mmdetection转换mmdetection 自带转换ONNX——无法测试使用mmdeploy(0.6.0)使用mmdeploy转onnx使用mmdeploy直接转tensorRT调试记录 先上结论:作者最后是转tensorrt的小图才成功的,大图一直不行。文章仅作者自我记录使用&#…...

如何为SUSI ViberBot添加自定义功能:扩展按钮与交互体验的完整指南
如何为SUSI ViberBot添加自定义功能:扩展按钮与交互体验的完整指南 【免费下载链接】susi_viberbot Viberbot for SUSI AI http://susi.ai 项目地址: https://gitcode.com/gh_mirrors/su/susi_viberbot 想要为你的SUSI ViberBot添加个性化功能吗?…...

CaldroidListener使用教程:轻松实现Android日期点击事件处理
CaldroidListener使用教程:轻松实现Android日期点击事件处理 【免费下载链接】Caldroid A better calendar for Android 项目地址: https://gitcode.com/gh_mirrors/ca/Caldroid Caldroid是一款功能强大的Android日历组件,而CaldroidListener则是…...

测试工程师如何与开发人员高效沟通?这5个技巧让你不再背锅
在互联网软件研发流程中,测试工程师和开发工程师是天生的“搭档”也是最容易产生矛盾的组合:测试测出bug,开发说“这不是我的问题”“环境不对”“你操作错了”,最后问题定位下来测试背锅;测试提前同步风险,…...

到底什么是 AI 测试?AI 测试与传统测试的区别?
过去两年,AI已经从"加分项"变成了"必选项"。 不只是大厂,二线公司、甚至传统行业的测试团队都在要求:"能熟练使用AI工具提效"。 更关键的是,面试的玩法也变了。现在的技术面试早就跳出了 “考 AI 零…...

AI、机器学习、深度学习:工程师的三层实战分水岭
1. 这不是概念辨析课,而是一张能让你少走三年弯路的“技术地图”我带过三十多个从零起步转行做数据工作的学员,几乎每个人在入职前都反复问过同一个问题:“AI、机器学习、深度学习,到底谁是谁的爸爸?”——结果翻遍教程…...

GD32/STM32串口高效收数秘籍:巧用IDLE中断判断一帧数据收完
GD32/STM32串口高效收数实战:IDLE中断DMA的黄金组合 在嵌入式开发中,串口通信就像设备间的"普通话",但如何高效接收不定长数据帧却让不少工程师头疼。想象一下无人机飞控与地面站的通信场景:数据包可能短至几个字节的指…...

寄存器文件与SRAM:芯片设计中存储层次的核心差异与选型指南
1. 项目概述:从“存储”到“访问”的鸿沟在数字电路和处理器设计的核心地带,有两个名字经常被提及,却又常常让初学者甚至一些从业者感到混淆:Register File(寄存器文件)和SRAM(静态随机存取存储…...

量子计算在DNA序列相似性比较中的应用与优化
1. 量子计算与DNA序列相似性比较的背景DNA序列相似性比较是生物信息学和比较基因组学中的基础性任务。想象一下,你手上有两串由A、T、G、C四个字母组成的长字符串,如何判断它们的相似程度?这个问题看似简单,但在实际应用中却极具挑…...

量子PSO与机器学习在天线小型化设计中的应用
1. 量子PSO与机器学习在天线小型化设计中的革命性应用作为一名长期从事射频工程和天线设计的从业者,我见证了传统设计方法从纯手工计算到计算机辅助设计的演进。但直到接触量子粒子群优化(QDPSO)与机器学习的融合应用,才真正体会到智能化设计带来的效率飞…...

Prompt Engineering、Context Engineering 与 Harness Engineering 的异同点
在大型语言模型(LLM)应用开发中,随着模型能力的提升,单纯依靠“写提示词”已经无法满足复杂、稳定、可落地的生产需求。于是,Prompt Engineering(提示工程)、Context Engineering(上…...