数据的分组聚合
1:分组 t.groupby
#coding:utf-8
import pandas as pd
import numpy as np
file_path='./starbucks_store_worldwide.csv'
df=pd.read_csv(file_path)
#print(df.head(1))
#print(df.info())
grouped=df.groupby(by='Country')
print(grouped)
#DataFrameGroupBy
#可以遍历,也可以使用聚合方法2:DataFrameGroupBy可以进行遍历
grouped=df.groupby(by='Country')
print(grouped)
#DataFrameGroupBy
#可以遍历for i, j in grouped:print(i)print('_'*100)print(j,type(j))print('*'*100)3:DateFrameGroupBy可以聚合
print(grouped.count()),可以对grouped进行统计操作
country_count=grouped['Brand'].count()
print(country_count['CN'])
print(country_count['US'])4:统计中国每个省份店铺的数量
#coding:utf-8
import pandas as pd
import numpy as np
file_path='./starbucks_store_worldwide.csv'
df=pd.read_csv(file_path)
china_date=df[df['Country']=='CN']
#print(china_date)
grouped=china_date.groupby(by='City').count()['Brand']
print(grouped)5:按照多条件进行分组
#coding:utf-8
import pandas as pd
import numpy as np
file_path='./starbucks_store_worldwide.csv'
df=pd.read_csv(file_path)
china_date=df[df['Country']=='CN']
#print(china_date)
#grouped=china_date.groupby(by='City').count()['Brand']
grouped=df['Brand'].groupby(by=[df['Country'],df['State/Province']]).count()
print(grouped)
print(type(grouped))6:df['Brand']和df[['Brand']]一个代表Series格式,一个代表DateFrame格式
#coding:utf-8
import pandas as pd
import numpy as np
file_path='./starbucks_store_worldwide.csv'
df=pd.read_csv(file_path)
china_date=df[df['Country']=='CN']
#print(china_date)
#grouped=china_date.groupby(by='City').count()['Brand']
grouped=df['Brand'].groupby(by=[df['Country'],df['State/Province']]).count()
print(grouped)
print(type(grouped))7:索引和复合索引
#把某一列作为索引df.set_index
#重置索引 df.index=['x','y']
df1=pd.DataFrame(np.ones(8).reshape(2,4))
df1.index=['a','b']
# df1.reindex['a','f']
# print(df1)
df1.columns=['c','d','e','f']
#print(df1)
df2=df1.set_index('c')
print(df2)df2=df1.set_index('c',drop=False)
#c不止是索引,仍然是列
print(df2)#index.unique
df2=df1.set_index('c',drop=False).index.unique()print(df2)#index是可迭代的对象,可以len( ),也可以list()
df2=len(df1.set_index('c',drop=False))
#c不止是索引,仍然是列
print(df2)
df2=list(df1.set_index('c',drop=False))
print(df2)
#设置2个列作为索引
#设置两个列作为索引
df3=df1.set_index(['c','d'],drop='false')
print(df3)#简单的索引操作

相关文章:
数据的分组聚合
1:分组 t.groupby #coding:utf-8 import pandas as pd import numpy as np file_path./starbucks_store_worldwide.csv dfpd.read_csv(file_path) #print(df.head(1)) #print(df.info()) groupeddf.groupby(byCountry) print(grouped) #DataFrameGroupBy #可以遍历…...
【Airplay_BCT】Bonjour conformance tests苹果IOT
从Airplay开始,接触到BCT,这是什么?被迫从安卓变成ios用户和开发。。。开始我的学习之旅,记录成长过程,不定时更新 Bonjour 下面是苹果官网关于bonjour的解释 Bonjour, also known as zero-configuration networking, …...
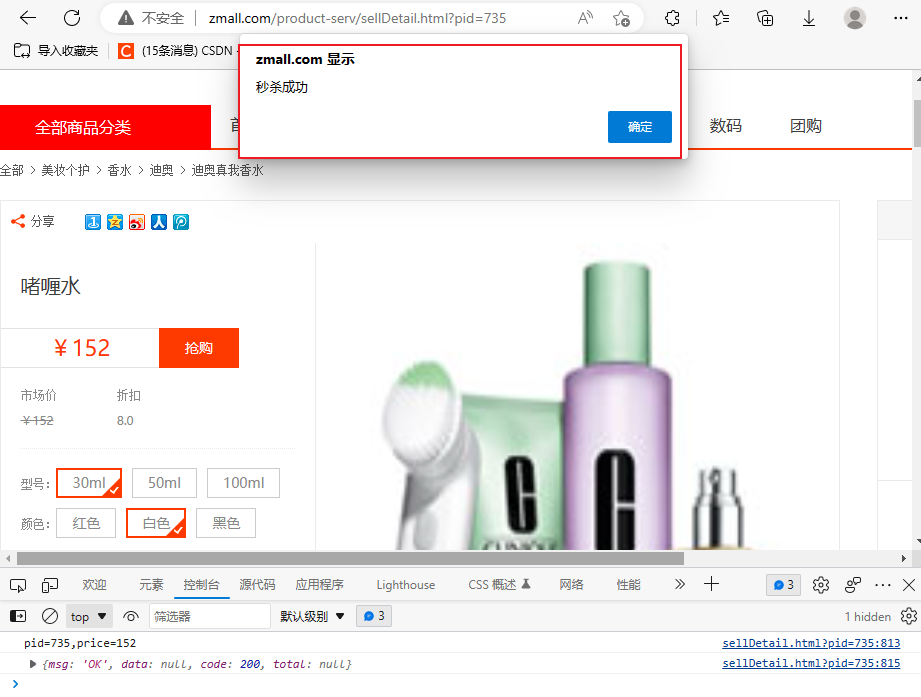
开发微服务电商项目演示(五)
登录方式调整第1步:从zmall-common的pom.xml中移除spring-session-data-redis依赖注意:本章节中不采用spring-session方式,改用redis直接存储用户登录信息,主要是为了方便之后的jmeter压测;2)这里只注释调用…...

Git删除大文件历史记录
Git删除大文件历史记录 git clone 仓库地址 查看大文件并排序 git rev-list --objects --all |grep $(git verify-pack -v .git/objects/pack/pack-*.idx | sort -k 3 -g | tail -1|awk {print $1})删除大文件 git filter-branch --force --index-filter git rm --cached --ig…...
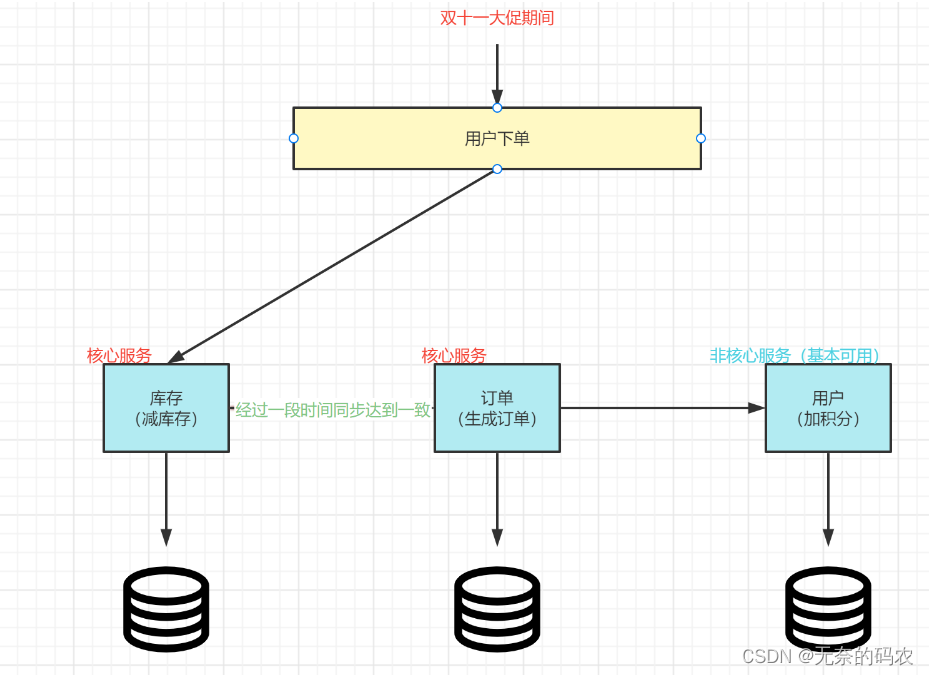
Seata-Server分布式事务原理加源码(一) - 微服务之分布式事务原理
概念 基础概念:事务ACID • A(Atomic):原子性,构成事务的所有操作,要么都执行完成,要么全部不执行,不可能出现部分成功部分失 败的情况。 • C(Consistency)…...

【ZooKeeper】zookeeper源码9-ZooKeeper读写流程源码分析
源码项目zookeeper-3.6.3:核心工作流程ZooKeeper选举和状态同步结束之后的服务启动ZooKeeper SessionTracker启动和工作机制ZooKeeper选举和状态同步结束之后的服务启动 在Leader的lead()方法的最后,即Leader完成了和集群过半Follower的同步之后&#x…...

Python实现批量导入xlsx数据1000条
遇到的问题:用户批量导入数据1000条,导入不成功的问题,提示查询不到商品资料。这个场景需要依靠批量的数据,每次测试的时候需要手动生成批量的数据,然后再导入操作,费时费劲。所以写了个脚本来实现。在前面…...
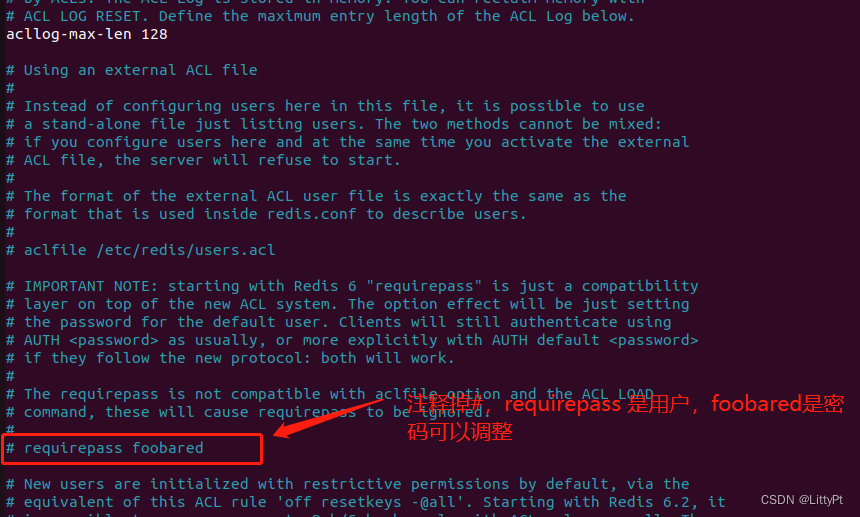
Ubuntu20.04安装redis与远程连接
一、安装Redis5.7 1、安装Redis apt-get install redis-server2、安装完成后,Redis服务器会自动启动。查看redis是否启动成功 service redis-server status #查看状态如下显示Active:active(running)状态:表示redis已在运行,启动成功。 …...

SAS应用入门学习笔记5
input 操作符: 代码说明: 1)1 表示第1列字符;7表示第7列字符; 2)col1 表示第一列数据;col2 表示第二列数据; 3)4.2 表示的是4个字符,2表示小数点后两位&a…...
PHP新特性集合
php8新特性命名参数function foo(string $a, string $b, ?string $c null, ?string $d null) { /* … */ }你可以通过下面的方式传入参数进行调用foo(b: value b, a: value a, d: value d, );联合类型php7class Number {/** var int|float */private $number;/*** param f…...
【开发环境配置】--Python3的安装
1-开发环境配置 工欲善其事,必先利其器! 编写和运行程序之前,我们必须先把开发环境配置好。只有配置好了环境并且有了更方便的开发工具,我们才能更加高效地用程序实现相应的功能。然而很多情况下,我们可能在最开始就…...

postman实现接口测试详细教程
各位小伙伴大家好, 今天为大家带来postman实战接口测试详细教程 一、通过接口文档集合抓包分析接口 通过fiddler抓包获取到注册接口URL地址及相关参数数据,并通过接口文档分析接口参数内容及参数说明, 如有必要的依赖条件必须进行梳理, 如token等 Fiddler抓包注册接口请求与…...
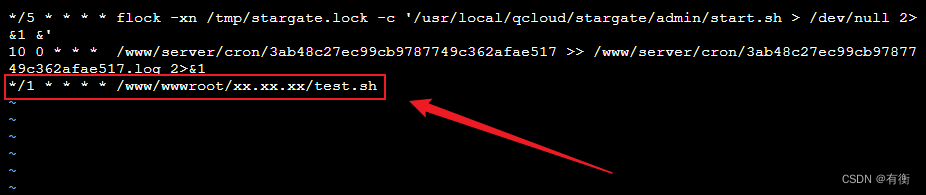
使用crontab执行定时任务
本来这个东西是挺简单的,是我脑子一直没转过来弯,我就想看看有多少人跟我一样😏 crontab语法自己去菜鸟教程看看就知道了,没什么难度 需求:每分钟定时执行一个PHP文件或者一个PHP命令 这是需要执行的文件࿰…...
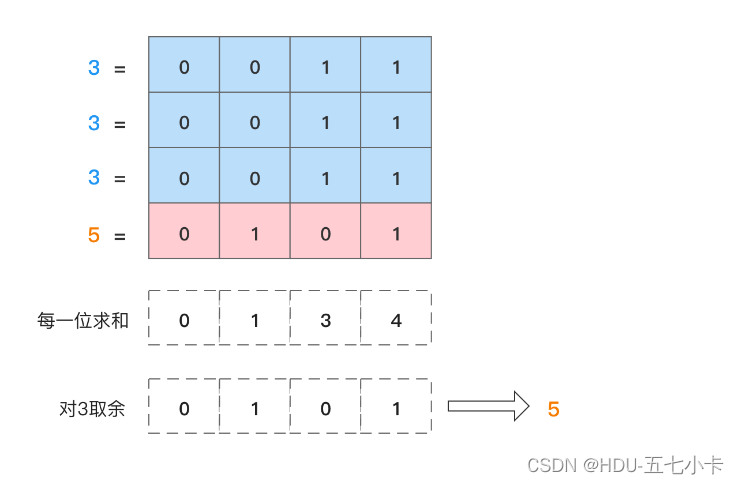
剑指 Offer 56 - II. 数组中数字出现的次数 II
题目 在一个数组 nums 中除一个数字只出现一次之外,其他数字都出现了三次。请找出那个只出现一次的数字。 思路 这题是剑指 Offer 56 - I. 数组中数字出现的次数的变体,本题只有一个数num出现一次,其余的均出现三次 三次的话使用异或消无法…...

C语言学习笔记(八): 自定义数据类型
结构体变量 什么是结构体 C语言允许用户自己建立由不同类型数据组成的组合型的数据结构,它称为结构体 结构体的成员可以是任何类型的变量,如整数,字符串,浮点数,其他结构体,指针等 struct Student //s…...

Video Speed Controller谷歌视频加速插件——16倍速
文章目录前言最简单的版本一、如果是简单的话 可以Microsoft Edge使用二、简单的版本 火狐的话使用Global Speed插件三、由于视频受限以上的方法行不通 还是谷歌好用前言 主要是网课刷的时候 太慢所以找到了刷视频的方法 由于前几个的权限受限制 所以还是选用了谷歌浏览器的 V…...

VSCode 的下载安装及基本使用
目录 一、VSCode 是什么? 二、VSCode 的下载和安装 2.1 - 下载 2.2 - 安装 2.3 - 安装汉化插件 三、MinGW-w64 的下载安装及配置 3.1 - 介绍 3.2 - 下载 3.3 - 解压安装 3.4 - 环境变量配置 3.5 - 验证配置是否成功 3.6 - 安装 C/C 插件 四、在 VSCode …...

【操作系统】磁盘IO常见性能指标和分析工具实战
1.磁盘读写常见的指标 (1)IOPS(Input/Output Operations per Second) 指每秒能处理的I/O个数,表示块存储处理读写(输出/输入)的能力,单位为次,有顺序IOPS和随机IOPS比如…...

SpringMVC基础
简介 Spring MVC 属于 SpringFrameWork 的后续产品,已经融合在 Spring Web Flow 里面;Spring 框架提供了构建 Web 应用程序的全功能 MVC 模块;使用 Spring 可插入的 MVC 架构,从而在使用Spring进行WEB开发时,可以选择…...

低代码开发平台|制造管理-质检管理搭建指南
1、简介1.1、案例简介本文将介绍,如何搭建制造管理-质检管理。1.2、应用场景质检分别包括来料质检、过程质检、成品质检,来料质检在采购物料入库后会自动发起来料质检的流程,质检合格才可提交结束流程;过程检是在生产过程中的质检…...
和滚动统计为预测模型打好基础)
你的时间序列真的平稳吗?手把手教你用ADF检验(Dickey-Fuller)和滚动统计为预测模型打好基础
时间序列平稳性诊断实战:从理论到Python实现 时间序列分析中,平稳性检验是建模前的关键步骤。许多经典预测模型(如ARIMA)都建立在数据平稳的假设之上。但现实中的时间序列往往带有趋势或季节性,直接建模会导致预测失效…...

基于Vagrant的Claude本地部署:自动化AI开发环境搭建指南
1. 项目概述:一个让Claude在本地“安家”的Vagrant包装器 如果你和我一样,是个喜欢在本地环境折腾各种AI工具的开发人员,那你肯定对Claude这个强大的语言模型不陌生。但官方提供的使用方式往往受限于网络环境、API调用成本或者隐私顾虑&…...

AI时代下,泳装行业的内容竞争正在被重新定义
北京先智先行科技有限公司持续推进人工智能产业应用,构建了“先知大模型”“先行 AI 商学院”“先知 AIGC 超级工场”三大核心产品体系,并围绕先知大模型私有化部署、先知 AIGC 超级工场、AI 训练师、先知人力资源服务、先知产业联盟等核心业务方向&…...

ADAS环视系统与视频解码器关键技术解析
1. ADAS环视系统技术解析1.1 汽车安全技术演进路径从ABS防抱死系统到安全气囊,再到如今的ADAS(高级驾驶辅助系统),汽车安全技术在过去二十年经历了三次重大迭代。德国车企在这个领域始终保持着技术领先,最早实现了车道…...

CANN/ops-nn: 原位加法RMS归一化算子
InplaceAddRmsNorm 【免费下载链接】ops-nn 本项目是CANN提供的神经网络类计算算子库,实现网络在NPU上加速计算。 项目地址: https://gitcode.com/cann/ops-nn 产品支持情况 产品是否支持Ascend 950PR/Ascend 950DT√Atlas A3 训练系列产品/Atlas A3 推理系…...

动态紧凑模型在电子热设计中的高效应用
1. 动态紧凑模型在电子热设计中的核心价值在电子设备日益小型化、高功率化的今天,热管理已成为决定产品可靠性的关键因素。传统热仿真方法面临两大痛点:一是计算资源消耗大,特别是处理复杂封装结构时;二是难以准确预测半导体器件的…...
04)
【审计专栏-监督监管领域】【信息科学与工程学】【社会科学】第十篇 社会底层核心规则(核心权力、核心利益、核心资源绑定、私下运作、关键价值交换、上下博弈)04
模型046:企业复杂利益链与多方利益博弈模型 1. 模型概述 项目 内容 模型名称 企业复杂利益链与多方利益博弈模型 核心场景 一家大型建筑企业“宏建集团”中标某市的地铁延长线建设项目。项目涉及总包方(宏建)、多个分包商(土建、机电、装修等)、材料供应商、监理…...

GEE筛选行政区的两种野路子:手绘个圈圈或者随便点个点,就能搞定研究区边界
GEE自定义研究区边界:交互式绘图与动态筛选实战指南 当研究区域无法用标准行政区划描述时,传统GIS工作流程往往陷入数据准备的泥潭。本文介绍两种Google Earth Engine(GEE)中高效定义不规则边界的创新方法,特别适合生态…...

智能体工程:从氛围编程到结构化AI辅助开发方法论
1. 项目概述:从“氛围编程”到“智能体工程”如果你和我一样,在过去一年里深度使用过 Claude Code、Cursor 或者 GitHub Copilot 来写代码,大概率经历过两种极端状态:一种是“哇,这 AI 太神了,我动动嘴皮子…...

JetBrains IDE重置插件:终极免费解决方案告别30天试用期限制
JetBrains IDE重置插件:终极免费解决方案告别30天试用期限制 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter 你是否曾经在项目开发的关键时刻,突然被JetBrains IDE弹出的"试用期已到期…...