一种新的流:为 Java 加入生成器(Generator)特性
作者:文镭(依来)
前言
这篇文章不是工具推荐,也不是应用案例分享。其主题思想,是介绍一种全新的设计模式。它既拥有抽象的数学美感,仅仅从一个简单接口出发,就能推演出庞大的特性集合,引出许多全新概念。同时也有扎实的工程实用价值,由其实现的工具,性能均可显著超过同类的头部开源产品。
这一设计模式并非因Java而生,而是诞生于一个十分简陋的脚本语言。它对语言特性的要求非常之低,因而其价值对众多现代编程语言都是普适的。
关于Stream
首先大概回顾下Java里传统的流式API。自Java8引入lambda表达式和Stream以来,Java的开发便捷性有了质的飞跃,Stream在复杂业务逻辑的处理上让人效率倍增,是每一位Java开发者都应该掌握的基础技能。但排除掉parallelStream也即并发流之外,它其实并不是一个好的设计。
第一、封装过重,实现过于复杂,源码极其难读。我能理解这或许是为了兼容并发流所做的妥协,但毕竟耦合太深,显得艰深晦涩。每一位初学者被源码吓到之后,想必都会产生流是一种十分高级且实现复杂的特性的印象。实际上并不是这样,流其实可以用非常简单的方式构建。
第二、API过于冗长。冗长体现在stream.collect这一部分。作为对比,Kotlin提供的toList/toSet/associate(toMap)等等丰富操作是可以直接作用在流上的。Java直到16才抠抠索索加进来一个Stream可以直接调用的toList,他们甚至不肯把toSet/toMap一起加上。
第三、API功能简陋。对于链式操作,在最初的Java8里只有map/filter/skip/limit/peek/distinct/sorted这七个,Java9又加上了takeWhile/dropWhile。然而在Kotlin中,除了这几个之外人还有许多额外的实用功能。
例如:
mapIndexed,mapNotNull,filterIndexed,filterNotNull,onEachIndexed,distinctBy, sortedBy,sortedWith,zip,zipWithNext等等,翻倍了不止。这些东西实现起来并不复杂,就是个顺手的事,但对于用户而言有和没有的体验差异可谓巨大。
在这篇文章里,我将提出一种全新的机制用于构建流。这个机制极其简单,任何能看懂lambda表达式(闭包)的同学都能亲手实现,任何支持闭包的编程语言都能利用该机制实现自己的流。也正是由于这个机制足够简单,所以开发者可以以相当低的成本撸出大量的实用API,使用体验甩开Stream两条街,不是问题。
关于生成器
生成器(Generator)[1]是许多现代编程语言里一个广受好评的重要特性,在Python/Kotlin/C#/Javascript等等语言中均有直接支持。它的核心API就是一个yield关键字(或者方法)。
有了生成器之后,无论是iterable/iterator,还是一段乱七八糟的闭包,都可以直接映射为一个流。举个例子,假设你想实现一个下划线字符串转驼峰的方法,在Python里你可以利用生成器这么玩
def underscore_to_camelcase(s):def camelcase():yield str.lowerwhile True:yield str.capitalizereturn ''.join(f(sub) for sub, f in zip(s.split('_'), camelcase()))
这短短几行代码可以说处处体现出了Python生成器的巧妙。首先,camelcase方法里出现了yield关键字,解释器就会将其看作是一个生成器,这个生成器会首先提供一个lower函数,然后提供无数的capitalize函数。由于生成器的执行始终是lazy的,所以用while true的方式生成无限流是十分常见的手段,不会有性能或者内存上的浪费。其次,Python里的流是可以和list一起进行zip的,有限的list和无限的流zip到一起,list结束了流自然也会结束。
这段代码中,末尾那行join()括号里的东西,Python称之为生成器推导(Generator Comprehension)[2],其本质上依然是一个流,一个zip流被map之后的string流,最终通过join方法聚合为一个string。
以上代码里的操作, 在任何支持生成器的语言里都可以轻易完成,但是在Java里你恐怕连想都不敢想。Java有史以来,无论是历久弥新的Java8,还是最新的引入了Project Loom[3]的OpenJDK19,连协程都有了,依然没有直接支持生成器。
本质上,生成器的实现要依赖于continuation[4]的挂起和恢复,所谓continuation可以直观理解为程序执行到指定位置后的断点,协程就是指在这个函数的断点挂起后跳到另一个函数的某个断点继续执行,而不会阻塞线程,生成器亦如是。
Python通过栈帧的保存与恢复实现函数重入以及生成器[5],Kotlin在编译阶段利用CPS(Continuation Passing Style)[6]技术对字节码进行了变换,从而在JVM上模拟了协程[7]。其他的语言要么大体如此,要么有更直接的支持。
那么,有没有一种办法,可以在没有协程的Java里,实现或者至少模拟出一个yield关键字,从而动态且高性能地创建流呢。答案是,有。
正文
Java里的流叫Stream,Kotlin里的流叫Sequence。我实在想不出更好的名字了,想叫Flow又被用了,简单起见姑且叫Seq。
概念定义
首先给出Seq的接口定义
public interface Seq<T> {void consume(Consumer<T> consumer);
}
它本质上就是一个consumer of consumer,其真实含义我后边会讲。这个接口看似抽象,实则非常常见,java.lang.Iterable天然自带了这个接口,那就是大家耳熟能详的forEach。利用方法推导,我们可以写出第一个Seq的实例
List<Integer> list = Arrays.asList(1, 2, 3);
Seq<Integer> seq = list::forEach;
可以看到,在这个例子里consume和forEach是完全等价的,事实上这个接口我最早就是用forEach命名的,几轮迭代之后才改成含义更准确的consume。
利用单方法接口在Java里会自动识别为FunctionalInteraface这一伟大特性,我们也可以用一个简单的lambda表达式来构造流,比如只有一个元素的流。
static <T> Seq<T> unit(T t) {return c -> c.accept(t);
}
这个方法在数学上很重要(实操上其实用的不多),它定义了Seq这个泛型类型的单位元操作,即T -> Seq的映射。
map与flatMap
map
从forEach的直观角度出发,我们很容易写出map[8],将类型为T的流,转换为类型为E的流,也即根据函数T -> E得到Seq -> Seq的映射。
default <E> Seq<E> map(Function<T, E> function) {return c -> consume(t -> c.accept(function.apply(t)));
}
flatMap
同理,可以继续写出flatMap,即将每个元素展开为一个流之后再合并。
default <E> Seq<E> flatMap(Function<T, Seq<E>> function) {return c -> consume(t -> function.apply(t).consume(c));
}
大家可以自己在IDEA里写写这两个方法,结合智能提示,写起来其实非常方便。如果你觉得理解起来不太直观,就把Seq看作是List,把consume看作是forEach就好。
filter与take/drop
map与flatMap提供了流的映射与组合能力,流还有几个核心能力:元素过滤与中断控制。
filter
过滤元素,实现起来也很简单
default Seq<T> filter(Predicate<T> predicate) {return c -> consume(t -> {if (predicate.test(t)) {c.accept(t);}});
}
take
流的中断控制有很多场景,take是最常见的场景之一,即获取前n个元素,后面的不要——等价于Stream.limit。
由于Seq并不依赖iterator,所以必须通过异常实现中断。为此需要构建一个全局单例的专用异常,同时取消这个异常对调用栈的捕获,以减少性能开销(由于是全局单例,不取消也没关系)
public final class StopException extends RuntimeException {public static final StopException INSTANCE = new StopException();@Overridepublic synchronized Throwable fillInStackTrace() {return this;}
}
以及相应的方法
static <T> T stop() {throw StopException.INSTANCE;
}default void consumeTillStop(C consumer) {try {consume(consumer);} catch (StopException ignore) {}
}
然后就可以实现take了:
default Seq<T> take(int n) {return c -> {int[] i = {n};consumeTillStop(t -> {if (i[0]-- > 0) {c.accept(t);} else {stop();}});};
}
drop
drop是与take对应的概念,丢弃前n个元素——等价于Stream.skip。它并不涉及流的中断控制,反而更像是filter的变种,一种带有状态的filter。观察它和上面take的实现细节,内部随着流的迭代,存在一个计数器在不断刷新状态,但这个计数器并不能为外界感知。这里其实已经能体现出流的干净特性,它哪怕携带了状态,也丝毫不会外露。
default Seq<T> drop(int n) {return c -> {int[] a = {n - 1};consume(t -> {if (a[0] < 0) {c.accept(t);} else {a[0]--;}});};
}
其他API
onEach
对流的某个元素添加一个操作consumer,但是不执行流——对应Stream.peek。
default Seq<T> onEach(Consumer<T> consumer) {return c -> consume(consumer.andThen(c));
}
zip
流与一个iterable元素两两聚合,然后转换为一个新的流——在Stream里没有对应,但在Python里有同名实现。
default <E, R> Seq<R> zip(Iterable<E> iterable, BiFunction<T, E, R> function) {return c -> {Iterator<E> iterator = iterable.iterator();consumeTillStop(t -> {if (iterator.hasNext()) {c.accept(function.apply(t, iterator.next()));} else {stop();}});};
}
终端操作
上面实现的几个方法都是流的链式API,它们将一个流映射为另一个流,但流本身依然是lazy或者说尚未真正执行的。真正执行这个流需要使用所谓终端操作,对流进行消费或者聚合。在Stream里,消费就是forEach,聚合就是Collector。对于Collector,其实也可以有更好的设计,这里就不展开了。不过为了示例,可以先简单快速实现一个join。
default String join(String sep) {StringJoiner joiner = new StringJoiner(sep);consume(t -> joiner.add(t.toString()));return joiner.toString();
}
以及toList。
default List<T> toList() {List<T> list = new ArrayList<>();consume(list::add);return list;
}
至此为止,我们仅仅只用几十行代码,就实现出了一个五脏俱全的流式API。在大部分情况下,这些API已经能覆盖百分之八九十的使用场景。你完全可以依样画葫芦,在其他编程语言里照着玩一玩,比如Go(笑)。
生成器的推导
本文虽然从标题开始就在讲生成器,甚至毫不夸张的说生成器才是最核心的特性,但等到把几个核心的流式API写完了,依然没有解释生成器到底是咋回事——其实倒也不是我在卖关子,你只要仔细观察一下,生成器早在最开始讲到Iterable天生就是Seq的时候,就已经出现了。
List<Integer> list = Arrays.asList(1, 2, 3);
Seq<Integer> seq = list::forEach;
没看出来?那把这个方法推导改写为普通lambda函数,有
Seq<Integer> seq = c -> list.forEach(c);
再进一步,把这个forEach替换为更传统的for循环,有
Seq<Integer> seq = c -> {for (Integer i : list) {c.accept(i);}
};
由于已知这个list就是[1, 2, 3],所以以上代码可以进一步等价写为
Seq<Integer> seq = c -> {c.accept(1);c.accept(2);c.accept(3);
};
是不是有点眼熟?不妨看看Python里类似的东西长啥样:
def seq():yield 1yield 2yield 3
二者相对比,形式几乎可以说一模一样——这其实就已经是生成器了,这段代码里的accept就扮演了yield的角色,consume这个接口之所以取这个名字,含义就是指它是一个消费操作,所有的终端操作都是基于这个消费操作实现的。功能上看,它完全等价于Iterable的forEach,之所以又不直接叫forEach,是因为它的元素并不是本身自带的,而是通过闭包内的代码块临时生成的。
这种生成器,并非传统意义上利用continuation挂起的生成器,而是利用闭包来捕获代码块里临时生成的元素,哪怕没有挂起,也能高度模拟传统生成器的用法和特性。其实上文所有链式API的实现,本质上也都是生成器,只不过生成的元素来自于原始的流罢了。
有了生成器,我们就可以把前文提到的下划线转驼峰的操作用Java也依样画葫芦写出来了。
static String underscoreToCamel(String str) {// Java没有首字母大写方法,随便现写一个UnaryOperator<String> capitalize = s -> s.substring(0, 1).toUpperCase() + s.substring(1).toLowerCase();// 利用生成器构造一个方法的流Seq<UnaryOperator<String>> seq = c -> {// yield第一个小写函数c.accept(String::toLowerCase);// 这里IDEA会告警,提示死循环风险,无视即可while (true) {// 按需yield首字母大写函数c.accept(capitalize);}};List<String> split = Arrays.asList(str.split("_"));// 这里的zip和join都在上文给出了实现return seq.zip(split, (f, sub) -> f.apply(sub)).join("");
}
大家可以把这几段代码拷下来跑一跑,看它是不是真的实现了其目标功能。
生成器的本质
虽然已经推导出了生成器,但似乎还是有点摸不着头脑,这中间到底发生了什么,死循环是咋跳出的,怎么就能生成元素了。为了进一步解释,这里再举一个大家熟悉的例子。
生产者-消费者模式
生产者与消费者的关系不止出现在多线程或者协程语境下,在单线程里也有一些经典场景。比如A和B两名同学合作一个项目,分别开发两个模块:A负责产出数据,B负责使用数据。A不关心B怎么处理数据,可能要先过滤一些,进行聚合后再做计算,也可能是写到某个本地或者远程的存储;B自然也不关心A的数据是怎么来的。这里边唯一的问题在于,数据条数实在是太多了,内存一次性放不下。在这种情况下,传统的做法是让A提供一个带回调函数consumer的接口,B在调用A的时候传入一个具体的consumer。
public void produce(Consumer<String> callback) {// do something that produce strings// then use the callback consumer to eat them
}
这种基于回调函数的交互方式实在是过于经典了,原本没啥可多说的。但是在已经有了生成器之后,我们不妨胆子放大一点稍微做一下改造:仔细观察上面这个produce接口,它输入一个consumer,返回void——咦,所以它其实也是一个Seq嘛!
Seq<String> producer = this::produce;
接下来,我们只需要稍微调整下代码,就能对这个原本基于回调函数的接口进行一次升级,将它变成一个生成器。
public Seq<String> produce() {return c -> {// still do something that produce strings// then use the callback consumer to eat them};
}
基于这一层抽象,作为生产者的A和作为消费者的B就真正做到完全的、彻底的解耦了。A只需要把数据生产过程放到生成器的闭包里,期间涉及到的所有副作用,例如IO操作等,都被这个闭包完全隔离了。B则直接拿到一个干干净净的流,他不需要关心流的内部细节,当然想关心也关心不了,他只用专注于自己想做的事情即可。
更重要的是,A和B虽然在操作逻辑上完全解耦,互相不可见,但在CPU调度时间上它们却是彼此交错的,B甚至还能直接阻塞、中断A的生产流程——可以说没有协程,胜似协程。
至此,我们终于成功发现了Seq作为生成器的真正本质 :consumer of callback。明明是一个回调函数的消费者,摇身一变就成了生产者,实在是有点奇妙。不过仔细一想倒也合理:能够满足消费者需求(callback)的家伙,不管这需求有多么奇怪,可不就是生产者么。
容易发现,基于callback机制的生成器,其调用开销完全就只有生成器闭包内部那堆代码块的执行开销,加上一点点微不足道的闭包创建开销。在诸多涉及到流式计算与控制的业务场景里,这将带来极为显著的内存与性能优势。后面我会给出展现其性能优势的具体场景实例。
另外,观察这段改造代码,会发现produce输出的东西,根本就还是个函数,没有任何数据被真正执行和产出。这就是生成器作为一个匿名接口的天生优势:惰性计算——消费者看似得到了整个流,实际那只是一张爱的号码牌,可以涂写,可以废弃,但只有在拿着货真价实的callback去兑换的那一刻,才会真正的执行流。
生成器的本质,正是人类本质的反面:鸽子克星——没有任何人可以鸽它
IO隔离与流输出
Haskell发明了所谓IO Monad[9]来将IO操作与纯函数的世界隔离。Java利用Stream,勉强做到了类似的封装效果。以java.io.BufferedReader为例,将本地文件读取为一个Stream,可以这么写:
Stream<String> lines = new BufferedReader(new InputStreamReader(new FileInputStream("file"))).lines();
如果你仔细查看一下这个lines方法的实现,会发现它使用了大段代码去创建了一个iterator,而后才将其转变为stream。暂且不提它的实现有多么繁琐,这里首先应该注意的是BufferedReader是一个Closeable,安全的做法是在使用完毕后close,或者利用try-with-resources语法包一层,实现自动close。但是BufferedReader.lines并没有去关闭这个源,它是一个不那么安全的接口——或者说,它的隔离是不完整的。Java对此也打了个补丁,使用java.nio.file.Files.lines,它会添加加一个onClose的回调handler,确保stream耗尽后执行关闭操作。
那么有没有更普适做法呢,毕竟不是所有人都清楚BufferedReader.lines和Files.lines会有这种安全性上的区别,也不是所有的Closeable都能提供类似的安全关闭的流式接口,甚至大概率压根就没有流式接口。
好在现在我们有了Seq,它的闭包特性自带隔离副作用的先天优势。恰巧在涉及大量数据IO的场景里,利用callback交互又是极为经典的设计方式——这里简直就是它大展拳脚的最佳舞台。
用生成器实现IO的隔离非常简单,只需要整个包住try-with-resources代码即可,它同时就包住了IO的整个生命周期。
Seq<String> seq = c -> {try (BufferedReader reader = Files.newBufferedReader(Paths.get("file"))) {String s;while ((s = reader.readLine()) != null) {c.accept(s);}} catch (Exception e) {throw new RuntimeException(e);}
};
核心代码其实就3行,构建数据源,挨个读数据,然后yield(即accept)。后续对流的任何操作看似发生在创建流之后,实际执行起来都被包进了这个IO生命周期的内部,读一个消费一个,彼此交替,随用随走。
换句话讲,生成器的callback机制,保证了哪怕Seq可以作为变量四处传递,但涉及到的任何副作用操作,都是包在同一个代码块里惰性执行的。它不需要像Monad那样,还得定义诸如IOMonad,StateMonad等等花样众多的Monad。
与之类似,这里不妨再举个阿里中间件的例子,利用Tunnel将大家熟悉的ODPS表数据下载为一个流:
public static Seq<Record> downloadRecords(TableTunnel.DownloadSession session) {return c -> {long count = session.getRecordCount();try (TunnelRecordReader reader = session.openRecordReader(0, count)) {for (long i = 0; i < count; i++) {c.accept(reader.read());}} catch (Exception e) {throw new RuntimeException(e);}};
}
有了Record流之后,如果再能实现出一个map函数,就可以非常方便的将Record流map为带业务语义的DTO流——这其实就等价于一个ODPS Reader。
异步流
基于callback机制的生成器,除了可以在IO领域大展拳脚,它天然也是亲和异步操作的。毕竟一听到回调函数这个词,很多人就能条件反射式的想到异步,想到Future。一个callback函数,它的命运就决定了它是不会在乎自己被放到哪里、被怎么使用的。比方说,丢给某个暴力的异步逻辑:
public static Seq<Integer> asyncSeq() {return c -> {CompletableFuture.runAsync(() -> c.accept(1));CompletableFuture.runAsync(() -> c.accept(2));};
}
这就是一个简单而粗暴的异步流生成器。对于外部使用者来说,异步流除了不能保证元素顺序,它和同步流没有任何区别,本质上都是一段可运行的代码,边运行边产生数据。 一个callback函数,谁给用不是用呢。
并发流
既然给谁用不是用,那么给ForkJoinPool用如何?——Java大名鼎鼎的parallelStream就是基于ForkJoinPool实现的。我们也可以拿来搞一个自己的并发流。具体做法很简单,把上面异步流示例里的CompletableFuture.runAsync换成ForkJoinPool.submit即可,只是要额外注意一件事:parallelStream最终执行后是要阻塞的(比如最常用的forEach),它并非单纯将任务提交给ForkJoinPool,而是在那之后还要做一遍join。
对此我们不妨采用最为暴力而简单的思路,构造一个ForkJoinTask的list,依次将元素提交forkJoinPool后,产生一个task并添加进这个list,等所有元素全部提交完毕后,再对这个list里的所有task统一join。
default Seq<T> parallel() {ForkJoinPool pool = ForkJoinPool.commonPool();return c -> map(t -> pool.submit(() -> c.accept(t))).cache().consume(ForkJoinTask::join);
}
这就是基于生成器的并发流,它的实现仅仅只需要两行代码——正如本文开篇所说,流可以用非常简单的方式构建。哪怕是Stream费了老大劲的并发流,换一种方式,实现起来可以简单到令人发指。
这里值得再次强调的是,这种机制并非Java限定,而是任何支持闭包的编程语言都能玩。事实上,这种流机制的最早验证和实现,就是我在AutoHotKey_v2[10]这个软件自带的简陋的脚本语言上完成的。
再谈生产者-消费者模式
前面为了解释生成器的callback本质,引入了单线程下的生产者-消费者模式。那在实现了异步流之后,事情就更有意思了。
回想一下,Seq作为一种中间数据结构,能够完全解耦生产者与消费者,一方只管生产数据交给它,另一方只管从它那里拿数据消费。这种构造有没有觉得有点眼熟?不错,正是Java开发者常见的阻塞队列,以及支持协程的语言里的通道(Channel) ,比如Go和Kotlin。
通道某种意义上也是一种阻塞队列,它和传统阻塞队列的主要区别,在于当通道里的数据超出限制或为空时,对应的生产者/消费者会挂起而不是阻塞,两种方式都会暂停生产/消费,只是协程挂起后能让出CPU,让它去别的协程里继续干活。
那Seq相比Channel有什么优势呢?优势可太多了:首先,生成器闭包里callback的代码块,严格确保了生产和消费必然交替执行,也即严格的先进先出、进了就出、不进不出,所以不需要单独开辟堆内存去维护一个队列,那没有队列自然也就没有锁,没有锁自然也就没有阻塞或挂起。其次,Seq本质上是消费监听生产,没有生产自然没有消费,如果生产过剩了——啊,生产永远不会过剩,因为Seq是惰性的,哪怕生产者在那儿while死循环无限生产,也不过是个司空见惯的无限流罢了。
这就是生成器的另一种理解方式,一个无队列、无锁、无阻塞的通道。Go语言channel常被诟病的死锁和内存泄露问题,在Seq身上压根就不存在;Kotlin搞出来的异步流Flow和同步流Sequence这两套大同小异的API,都能被Seq统一替换。
可以说,没有比Seq更安全的通道实现了,因为根本就没有安全问题。生产了没有消费?Seq本来就是惰性的,没有消费,那就啥也不会生产。消费完了没有关闭通道?Seq本来就不需要关闭——一个lambda而已有啥好关闭的。
为了更直观的理解,这里给一个简单的通道示例。先随便实现一个基于ForkJoinPool的异步消费接口,该接口允许用户自由选择消费完后是否join。
default void asyncConsume(Consumer<T> consumer) {ForkJoinPool pool = ForkJoinPool.commonPool();map(t -> pool.submit(() -> consumer.accept(t))).cache().consume(ForkJoinTask::join);
}
有了异步消费接口,立马就可以演示出Seq的通道功能。
@Test
public void testChan() {// 生产无限的自然数,放入通道seq,这里流本身就是通道,同步流还是异步流都无所谓Seq<Long> seq = c -> {long i = 0;while (true) {c.accept(i++);}};long start = System.currentTimeMillis();// 通道seq交给消费者,消费者表示只要偶数,只要5个seq.filter(i -> (i & 1) == 0).take(5).asyncConsume(i -> {try {Thread.sleep(1000);System.out.printf("produce %d and consume\n", i);} catch (InterruptedException e) {throw new RuntimeException(e);}});System.out.printf("elapsed time: %dms\n", System.currentTimeMillis() - start);
}
运行结果
produce 0 and consume
produce 8 and consume
produce 6 and consume
produce 4 and consume
produce 2 and consume
elapsed time: 1032ms
可以看到,由于消费是并发执行的,所以哪怕每个元素的消费都要花1秒钟,最终总体耗时也就比1秒多一点点。当然,这和传统的通道模式还是不太一样,比如实际工作线程就有很大区别。更全面的设计是在流的基础上加上无锁非阻塞队列实现正经Channel,可以附带解决Go通道的许多问题同时提升性能,后面我会另写文章专门讨论。
生成器的应用场景
上文介绍了生成器的本质特性,它是一个consumer of callback,它可以以闭包的形式完美封装IO操作,它可以无缝切换为异步流和并发流,并在异步交互中扮演一个无锁的通道角色。除去这些核心特性带来的优势外,它还有非常多有趣且有价值的应用场景。
树遍历
一个callback函数,它的命运就决定了它是不会在乎自己被放到哪里、被怎么使用的,比如说,放进递归里。而递归的一个典型场景就是树遍历。作为对比,不妨先看看在Python里怎么利用yield遍历一棵二叉树的:
def scan_tree(node):yield node.valueif node.left:yield from scan_tree(node.left)if node.right:yield from scan_tree(node.right)
对于Seq,由于Java不允许函数内部套函数,所以要稍微多写一点。核心原理其实很简单,把callback函数丢给递归函数,每次递归记得捎带上就行。
//static <T> Seq<T> of(T... ts) {
// return Arrays.asList(ts)::forEach;
//}// 递归函数
public static <N> void scanTree(Consumer<N> c, N node, Function<N, Seq<N>> sub) {c.accept(node);sub.apply(node).consume(n -> {if (n != null) {scanTree(c, n, sub);}});
}// 通用方法,可以遍历任何树
public static <N> Seq<N> ofTree(N node, Function<N, Seq<N>> sub) {return c -> scanTree(c, node, sub);
}// 遍历一个二叉树
public static Seq<Node> scanTree(Node node) {return ofTree(node, n -> Seq.of(n.left, n.right));
}
这里的ofTree就是一个非常强大的树遍历方法。遍历树本身并不是啥稀罕东西,但把遍历的过程输出为一个流,那想象空间就很大了。在编程语言的世界里树的构造可以说到处都是。比方说,我们可以十分简单的构造出一个遍历JSONObject的流。
static Seq<Object> ofJson(Object node) {return Seq.ofTree(node, n -> c -> {if (n instanceof Iterable) {((Iterable<?>)n).forEach(c);} else if (n instanceof Map) {((Map<?, ?>)n).values().forEach(c);}});
}
然后分析JSON就会变得十分方便,比如你想校验某个JSON是否存在Integer字段,不管这个字段在哪一层。使用流的any/anyMatch这样的方法,一行代码就能搞定:
boolean hasInteger = ofJson(node).any(t -> t instanceof Integer);
这个方法的厉害之处不仅在于它足够简单,更在于它是一个短路操作。用正常代码在一个深度优先的递归函数里执行短路,要不就抛出异常,要不就额外添加一个上下文参数参与递归(只有在返回根节点后才能停止),总之实现起来都挺麻烦。但是使用Seq,你只需要一个any/all/none。
再比如你想校验某个JSON字段里是否存在非法字符串“114514”,同样也是一行代码:
boolean isIllegal = ofJson(node).any(n -> (n instanceof String) && ((String)n).contains("114514"));
对了,JSON的前辈XML也是树的结构,结合众多成熟的XML的解析器,我们也可以实现出类似的流式扫描工具。比如说,更快的Excel解析器?
更好用的笛卡尔积
笛卡尔积对大部分开发而言可能用处不大,但它在函数式语言中是一种颇为重要的构造,在运筹学领域构建最优化模型时也极其常见。此前Java里若要利用Stream构建多重笛卡尔积,需要多层flatMap嵌套。
public static Stream<Integer> cartesian(List<Integer> list1, List<Integer> list2, List<Integer> list3) {return list1.stream().flatMap(i1 ->list2.stream().flatMap(i2 ->list3.stream().map(i3 -> i1 + i2 + i3)));
}
对于这样的场景,Scala提供了一种语法糖,允许用户以for循环+yield[11]的方式来组合笛卡尔积。不过Scala的yield就是个纯语法糖,与生成器并无直接关系,它会在编译阶段将代码翻译为上面flatMap的形式。这种糖形式上等价于Haskell里的do annotation[12]。
好在现在有了生成器,我们有了更好的选择,可以在不增加语法、不引入关键字、不麻烦编译器的前提下,直接写个嵌套for循环并输出为流。且形式更为自由——你可以在for循环的任意一层随意添加代码逻辑。
public static Seq<Integer> cartesian(List<Integer> list1, List<Integer> list2, List<Integer> list3) {return c -> {for (Integer i1 : list1) {for (Integer i2 : list2) {for (Integer i3 : list3) {c.accept(i1 + i2 + i3);}}}};
}
换言之,Java不需要这样的糖。Scala或许原本也可以不要。
可能是Java下最快的CSV/Excel解析器
我在前文多次强调生成器将带来显著的性能优势,这一观点除了有理论上的支撑,也有明确的工程实践数据,那就是我为CSV家族所开发的架构统一的解析器。所谓CSV家族除了CSV以外,还包括Excel与阿里云的ODPS,其实只要形式符合其统一范式,就都能进入这个家族。
但是对于CSV这一家子的处理其实一直是Java语言里的一个痛点。ODPS就不说了,好像压根就没有。CSV的库虽然很多,但好像都不是很让人满意,要么API繁琐,要么性能低下,没有一个的地位能与Python里的Pandas相提并论。其中相对知名一点的有OpenCSV[13],Jackson的jackson-dataformat-csv[14],以及号称最快的univocity-parsers[15]。
Excel则不一样,有集团开源软件EasyExcel[16]珠玉在前,我只能确保比它快,很难也不打算比它功能覆盖全。
对于其中的CsvReader实现,由于市面上类似产品实在太多,我也没精力挨个去比,我只能说反正它比公开号称最快的那个还要快不少——大概一年前我实现的CsvReader在我办公电脑上的速度最多只能达到univocity-parsers的80%~90%,不管怎么优化也死活拉不上去。直到后来我发现了生成器机制并对其重构之后,速度直接反超前者30%到50% ,成为我已知的类似开源产品里的最快实现。
对于Excel,在给定的数据集上,我实现的ExcelReader比EasyExcel快50%~55% ,跟POI就懒得比了。测试详情见以上链接。
注:最近和Fastjson作者高铁有很多交流,在暂未正式发布的Fastjson2的2.0.28-SNAPSHOT版本上,其CSV实现的性能在多个JDK版本上已经基本追平我的实现。出于严谨,我只能说我的实现在本文发布之前可能是已知最快的哈哈。
改造EasyExcel,让它可以直接输出流
上面提到的EasyExcel是阿里开源的知名产品,功能丰富,质量优秀,广受好评。恰好它本身又一个利用回调函数进行IO交互的经典案例,倒是也非常适合拿来作为例子讲讲。根据官网示例,我们可以构造一个最简单的基于回调函数的excel读取方法
public static <T> void readEasyExcel(String file, Class<T> cls, Consumer<T> consumer) {EasyExcel.read(file, cls, new PageReadListener<T>(list -> {for (T person : list) {consumer.accept(person);}})).sheet().doRead();
}
EasyExcel的使用是通过回调监听器来捕获数据的。例如这里的PageReadListener,内部有一个list缓存。缓存满了,就喂给回调函数,然后继续刷缓存。这种基于回调函数的做法的确十分经典,但是难免有一些不方便的地方:
-
消费者需要关心生产者的内部缓存,比如这里的缓存就是一个list。
-
消费者如果想拿走全部数据,需要放一个list进去挨个add或者每次addAll。这个操作是非惰性的。
-
难以把读取过程转变为Stream,任何流式操作都必须要用list存完并转为流后,才能再做处理。灵活性很差。
-
消费者不方便干预数据生产过程,比如达到某种条件(例如个数)后直接中断,除非你在实现回调监听器时把这个逻辑override进去[17]。
利用生成器,我们可以将上面示例中读取excel的过程完全封闭起来,消费者不需要传入任何回调函数,也不需要关心任何内部细节——直接拿到一个流就好。改造起来也相当简单,主体逻辑原封不动,只需要把那个callback函数用一个consumer再包一层即可:
public static <T> Seq<T> readExcel(String pathName, Class<T> head) {return c -> {ReadListener<T> listener = new ReadListener<T>() {@Overridepublic void invoke(T data, AnalysisContext context) {c.accept(data);}@Overridepublic void doAfterAllAnalysed(AnalysisContext context) {}};EasyExcel.read(pathName, head, listener).sheet().doRead();};
}
这一改造我已经给EasyExcel官方提了PR[18],不过不是输出Seq,而是基于生成器原理构建的Stream,后文会有构建方式的具体介绍。
更进一步的,完全可以将对Excel的解析过程改造为生成器方式,利用一次性的callback调用避免内部大量状态的存储与修改,从而带来可观的性能提升。这一工作由于要依赖上文CsvReader的一系列API,所以暂时没法提交给EasyExcel。
用生成器构建Stream
生成器作为一种全新的设计模式,固然可以提供更为强大的流式API特性,但是毕竟不同于大家最为熟悉Stream,总会有个适应成本或者迁移成本。对于既有的已经成熟的库而言,使用Stream依然是对用户最为负责的选择。值得庆幸的是,哪怕机制完全不同,Stream和Seq仍是高度兼容的。
首先,显而易见,就如同Iterable那样,Stream天然就是一个Seq:
Stream<Integer> stream = Stream.of(1, 2, 3);
Seq<Integer> seq = stream::forEach;
那反过来Seq能否转化为Stream呢?在Java Stream提供的官方实现里,有一个StreamSupport.stream的构造工具,可以帮助用户将一个iterator转化为stream。针对这个入口,我们其实可以用生成器来构造一个非标准的iterator:不实现hastNext和next,而是单独重载forEachRemaining方法,从而hack进Stream的底层逻辑——在那迷宫一般的源码里,有一个非常隐秘的角落,一个叫AbstractPipeline.copyInto的方法,会在真正执行流的时候调用Spliterator的forEachRemaining方法来遍历元素——虽然这个方法原本是通过next和hasNext实现的,但当我们把它重载之后,就可以做到假狸猫换真太子。
public static <T> Stream<T> stream(Seq<T> seq) {Iterator<T> iterator = new Iterator<T>() {@Overridepublic boolean hasNext() {throw new NoSuchElementException();}@Overridepublic T next() {throw new NoSuchElementException();}@Overridepublic void forEachRemaining(Consumer<? super T> action) {seq.consume(action::accept);}};return StreamSupport.stream(Spliterators.spliteratorUnknownSize(iterator, Spliterator.ORDERED),false);
}
也就是说,咱现在甚至能用生成器来构造Stream了!比如:
public static void main(String[] args) {Stream<Integer> stream = stream(c -> {c.accept(0);for (int i = 1; i < 5; i++) {c.accept(i);}});System.out.println(stream.collect(Collectors.toList()));
}
图灵在上,感谢Stream的作者没有偷这个懒,没有用while hasNext来进行遍历,不然这操作咱还真玩不了。
当然由于这里的Iterator本质已经发生了改变,这种操作也会有一些限制,没法再使用parallel方法将其转为并发流,也不能用limit方法限制数量。不过除此以外,像map, filter, flatMap, forEach, collect等等方法,只要不涉及流的中断,都可以正常使用。
无限递推数列
实际应用场景不多。Stream的iterate方法可以支持单个种子递推的无限数列,但两个乃至多个种子的递推就无能为力了,比如最受程序员喜爱的炫技专用斐波那契数列:
public static Seq<Integer> fibonaaci() {return c -> {int i = 1, j = 2;c.accept(i);c.accept(j);while (true) {c.accept(j = i + (i = j));}};
}
另外还有一个比较有意思的应用,利用法里树的特性,进行丢番图逼近[22],简而言之,就是用有理数逼近实数。这是一个非常适合拿来做demo的且足够有趣的例子,限于篇幅原因我就不展开了,有机会另写文章讨论。
流的更多特性
流的聚合
如何设计流的聚合接口是一个很复杂的话题,若要认真讨论几乎又可以整出大几千字,限于篇幅这里简单提几句好了。在我看来,好的流式API应该要让流本身能直接调用聚合函数,而不是像Stream那样,先用Collectors构造一个Collector,再用stream去调用collect。可以对比下以下两种方式,孰优孰劣一目了然:
Set<Integer> set1 = stream.collect(Collectors.toSet());
String string1 = stream.map(Integer::toString).collect(Collectors.joinning(","));Set<Integer> set2 = seq.toSet();
String string2 = seq.join(",", Integer::toString);
这一点上,Kotlin做的比Java好太多。不过有利往往也有弊,从函数接口而非用户使用的角度来说,Collector的设计其实更为完备,它对于流和groupBy是同构的:所有能用collector对流直接做到的事情,groupBy之后用相同的collector也能做到,甚至groupBy本身也是一个collector。
所以更好的设计是既保留函数式的完备性与同构性,同时也提供由流直接调用的快捷方式。为了说明,这里举一个Java和Kotlin都没有实现但需求很普遍的例子,求加权平均:
public static void main(String[] args) {Seq<Integer> seq = Seq.of(1, 2, 3, 4, 5, 6, 7, 8, 9);double avg1 = seq.average(i -> i, i -> i); // = 6.3333double avg2 = seq.reduce(Reducer.average(i -> i, i -> i)); // = 6.3333Map<Integer, Double> avgMap = seq.groupBy(i -> i % 2, Reducer.average(i -> i, i -> i)); // = {0=6.0, 1=6.6}Map<Integer, Double> avgMap2 = seq.reduce(Reducer.groupBy(i -> i % 2, Reducer.average(i -> i, i -> i)));
}
上面代码里的average,Reducer.average,以及用在groupBy里的average都是完全同构的,换句话说,同一个Reducer,可以直接用在流上,也可以对流进行分组之后用在每一个子流上。这是一套类似Collector的API,既解决了Collector的一些问题,同时也能提供更丰富的特性。重点是,这玩意儿是开放的,且机制足够简单,谁都能写。
流的分段处理
分段处理其实是一直以来各种流式API的一个盲点,不论是map还是forEach,我们偶尔会希望前半截和后半截采取不同的处理逻辑,或者更直接一点的说希望第一个元素特殊处理。对此,我提供了三种API,元素替换replace,分段map,以及分段消费consume。
还是以前文提到的下划线转驼峰的场景作为一个典型例子:在将下划线字符串split之后,对第一个元素使用lowercase,对剩下的其他元素使用capitalize。使用分段的map函数,可以更快速的实现这一个功能。
static String underscoreToCamel(String str, UnaryOperator<String> capitalize) {// split=>分段map=>joinreturn Seq.of(str.split("_")).map(capitalize, 1, String::toLowerCase).join("");
}
再举个例子,当你解析一个CSV文件的时候,对于存在表头的情况,在解析时就要分别处理:利用表头信息对字段重排序,剩余的内容则按行转为DTO。使用适当的分段处理逻辑,这一看似麻烦的操作是可以在一个流里一次性完成的。
一次性流还是可重用流?
熟悉Stream的同学应该清楚,Stream是一种一次性的流,因为它的数据来源于一个iterator,二次调用一个已经用完的Stream会抛出异常。Kotlin的Sequence则采用了不同的设计理念,它的流来自于Iterable,大部分情况下是可重用的。但是Kotlin在读文件流的时候,采用的依然是和Stream同样的思路,将BufferedReader封装为一个Iterator,所以也是一次性的。
不同于以上二者,生成器的做法显然要更为灵活,流是否可重用,完全取决于被生成器包进去的数据源是否可重用。比如上面代码里不论是本地文件还是ODPS表,只要数据源的构建是在生成器里边完成的,那自然就是可重用的。你可以像使用一个普通List那样,多次使用同一个流。从这个角度上看,生成器本身就是一个Immutable,它的元素生产,直接来自于代码块,不依赖于运行环境,不依赖于内存状态数据。对于任何消费者而言,都可以期待同一个生成器给出始终一致的流。
生成器的本质和人类一样,都是复读机
当然,复读机复读也是要看成本的,对于像IO这种高开销的流需要重复使用的场景,反复去做同样的IO操作肯定不合理,我们不妨设计出一个cache方法用于流的缓存。
最常用的缓存方式,是将数据读进一个ArrayList。由于ArrayList本身并没有实现Seq的接口,所以不妨造一个ArraySeq,它既是ArrayList,又是Seq——正如我前面多次提到的,List天然就是Seq。
public class ArraySeq<T> extends ArrayList<T> implements Seq<T> {@Overridepublic void consume(Consumer<T> consumer) {forEach(consumer);}
}
有了ArraySeq之后,就可以立马实现流的缓存
default Seq<T> cache() {ArraySeq<T> arraySeq = new ArraySeq<>();consume(t -> arraySeq.add(t));return arraySeq;
}
细心的朋友可能会注意到,这个cache方法我在前面构造并发流的时候已经用到了。除此以外,借助ArraySeq,我们还能轻易的实现流的排序,感兴趣的朋友可以自行尝试。
二元流
既然可以用consumer of callback作为机制来构建流,那么有意思的问题来了,如果这个callback不是Consumer而是个BiConsumer呢?——答案就是,二元流!
public interface BiSeq<K, V> {void consume(BiConsumer<K, V> consumer);
}
二元流是一个全新概念,此前任何基于迭代器的流,比如Java Stream,Kotlin Sequence,还有Python的生成器,等等等等,都玩不了二元流。我倒也不是针对谁,毕竟在座诸位的next方法都必须吐出一个对象实例,意味着即便想构造同时有两个元素的流,也必须包进一个Pair之类的结构体里——故而其本质上依然是一个一元流。当流的元素数量很大时,它们的内存开销将十分显著。
哪怕是看起来最像二元流的Python的zip:
for i, j in zip([1, 2, 3], [4, 5, 6]):pass
这里的i和j,实际仍是对一个tuple进行解包之后的结果。
但是基于callback机制的二元流和它们完全不一样,它和一元流是同等轻量的!这就意味着节省内存同时还快。比如我在实现CsvReader时,重写了String.split方法使其输出为一个流,这个流与DTO字段zip为二元流,就能实现值与字段的一对一匹配。不需要借助下标,也不需要创建临时数组或list进行存储。每一个被分割出来的substring,在整个生命周期里都是一次性的,随用随丢。
这里额外值得一提的是,同Iterable类似,Java里的Map天生就是一个二元流。
Map<Integer, String> map = new HashMap<>();
BiSeq<Integer, String> biSeq = map::forEach;
有了基于BiConsumer的二元流,自然也可以有基于TriConsumer三元流,四元流,以及基于IntConsumer、DoubleConsumer等原生类型的流等等。这是一个真正的流的大家族,里边甚至还有很多不同于一元流的特殊操作,这里就不过多展开了,只提一个:
二元流和三元流乃至多元流,可以在Java里构造出货真价实的惰性元组tuple。当你的函数需要返回多个返回值的时候,除了手写一个Pair/Triple,你现在有了更好的选择,就是用生成器的方式直接返回一个BiSeq/TriSeq,这比直接的元组还额外增加了的惰性计算的优势,可以在真正需要使用的时候再用回调函数去消费。你甚至连空指针检查都省了。
结束语
首先感谢你能读到这里,我要讲的故事大体已经讲完了,虽然还有许多称得上有趣的细节没放出来讨论,但已经不影响这个故事的完整性了。我想要再次强调的是,上面这所有的内容,代码也好,特性也好,案例也罢,包括我所实现的CsvReader系列——全部都衍生自这一个简单接口,它是一切的源头,是梦开始的地方,完全值得我在文末再写一遍
public interface Seq<T> {void consume(Consumer<T> consumer);
}
对于这个神奇的接口,我愿称之为:
道生一——先有Seq定义
一生二——导出Seq一体两面的特性,既是流,又是生成器
二生三——由生成器实现出丰富的流式API,而后导出可安全隔离的IO流,最终导出异步流、并发流以及通道特性
至于三生万物的部分,还会有后续文章,期待能早日对外开源吧。
附录
附录的原本内容包含API文档,引用地址,以及性能benchmark。由于暂未开源,这里仅介绍下Monad相关。
Monad
Monad[24]是来自于范畴论里的一个概念,同时也是函数式编程语言代表者Haskell里极为重要的一种设计模式。但它无论是对流还是对生成器而言都不是必须的,所以放在附录讲。
我之所以要提Monad,是因为Seq在实现了unit, flatMap之后,自然也就成为了一种Monad。对于关注相关理论的同学来说,如果连提都不提,可能会有些难受。遗憾的是,虽然Seq在形式上是个Monad,但它们在理念上是存在一些冲突的。比方说在Monad里至关重要的flatMap,既是核心定义之一,还承担着组合与拆包两大重要功能。甚至连map对Monad来说都不是必须的,它完全可以由flatMap和unit推导出来(推导过程见下文),反之还不行。但是对于流式API而言,map才是真正最为关键和高频的操作,flatMap反而没那么重要,甚至压根都不太常用。
Monad这种设计模式之所以被推崇备至,是因为它有几个重要特性,惰性求值、链式调用以及副作用隔离——在纯函数的世界里,后者甚至称得上是性命攸关的大事。但是对包括Java在内的大部分正常语言来说,实现惰性求值更直接的方式是面向接口而不是面向对象(实例)编程,接口由于没有成员变量,天生就是惰性的。链式操作则是流的天生特性,无须赘述。至于副作用隔离,这同样不是Monad的专利。生成器用闭包+callback的方式也能做到,前文都有介绍。
推导map的实现
首先,map可以由unit与flatMap直接组合得到,这里不妨称之为map2:
default <E> Seq<E> map2(Function<T, E> function) {return flatMap(t -> unit(function.apply(t)));
}
即把类型为T的元素,转变为类型为E的Seq,再用flatMap合并。这个是最直观的,不需要流的先验概念,是Monad的固有属性。当然其在效率上肯定很差,我们可以对其化简。
已知unit与flatMap的实现
static <T> Seq<T> unit(T t) {return c -> c.accept(t);
}default <E> Seq<E> flatMap(Function<T, Seq<E>> function) {return c -> supply(t -> function.apply(t).supply(c));
}
先展开unit,代入上面map2的实现,有
default <E> Seq<E> map3(Function<T, E> function) {return flatMap(t -> c -> c.accept(function.apply(t)));
}
把这个flatMap里边的函数提出来变成flatFunction,再展开flatMap,有
default <E> Seq<E> map4(Function<T, E> function) {Function<T, Seq<E>> flatFunction = t -> c -> c.accept(function.apply(t));return consumer -> supply(t -> flatFunction.apply(t).supply(consumer));
}
容易注意到,这里的flatFunction连续有两个箭头,它其实就完全等价于一个双参数(t, c)函数的柯里化currying。我们对其做逆柯里化操作,反推出这个双参数函数:
Function<T, Seq<E>> flatFunction = t -> c -> c.accept(function.apply(t));
// 等价于
BiConsumer<T, Consumer<E>> biConsumer = (t, c) -> c.accept(function.apply(t));
可以看到,这个等价的双参数函数其实就是一个BiConsumer ,再将其代入map4,有
default <E> Seq<E> map5(Function<T, E> function) {BiConsumer<T, Consumer<E>> biConsumer = (t, c) -> c.accept(function.apply(t));return c -> supply(t -> biConsumer.accept(t, c));
}
注意到,这里biConsumer的实参和形参是完全一致的,所以可以将它的方法体代入下边直接替换,于是有
default <E> Seq<E> map6(Function<T, E> function) {return c -> supply(t -> c.accept(function.apply(t)));
}
到这一步,这个map6,就和前文从流式概念出发直接写出来的map完全一致了。证毕!
参考链接:
[1]https://en.wikipedia.org/wiki/Generator_(computer_programming)
[2]https://www.pythonlikeyoumeanit.com/Module2_EssentialsOfPython/Generators_and_Comprehensions.html
[3]https://openjdk.org/projects/loom/
[4]https://en.wikipedia.org/wiki/Continuation
[5]https://hackernoon.com/the-magic-behind-python-generator-functions-bc8eeea54220
[6]https://en.wikipedia.org/wiki/Continuation-passing_style
[7]https://kotlinlang.org/spec/asynchronous-programming-with-coroutines.html
[8]https://zh.wikipedia.org/wiki/Map_(%E9%AB%98%E9%98%B6%E5%87%BD%E6%95%B0)
[9]https://crypto.stanford.edu/~blynn/haskell/io.html
[10]https://www.autohotkey.com/docs/v2/
[11]https://stackoverflow.com/questions/1052476/what-is-scalas-yield
[12]https://stackoverflow.com/questions/10441559/scala-equivalent-of-haskells-do-notation-yet-again
[13]https://opencsv.sourceforge.net/
[14]https://github.com/FasterXML/jackson-dataformats-text/tree/master/csv
[15]https://github.com/uniVocity/univocity-parsers
[16]https://github.com/alibaba/easyexcel
[17]https://github.com/alibaba/easyexcel/issues/1566
[18]https://github.com/alibaba/easyexcel/pull/3052
[20]https://github.com/alibaba/easyexcel/pull/3052
[21]https://github.com/alibaba/fastjson2/blob/f30c9e995423603d5b80f3efeeea229b76dc3bb8/extension/src/main/java/com/alibaba/fastjson2/support/csv/CSVParser.java#L197
[22]https://www.bilibili.com/video/BV1ha41137oW/?is_story_h5=false&p=1&share_from=ugc&share_medium=android&share_plat=android&share_session_id=96a03926-820b-4c9f-a2fd-162944103bed&share_source=COPY&share_tag=s_i×tamp=1663058544&unique_k=p94n8tD
[24]https://en.wikipedia.org/wiki/Monad_(functional_programming)
更多内容,请点击此处进入云原生技术社区查看
相关文章:
特性)
一种新的流:为 Java 加入生成器(Generator)特性
作者:文镭(依来) 前言 这篇文章不是工具推荐,也不是应用案例分享。其主题思想,是介绍一种全新的设计模式。它既拥有抽象的数学美感,仅仅从一个简单接口出发,就能推演出庞大的特性集合,引出许多全新概念。…...

《数据结构C++版》实验一:线性表的顺序存储结构
实验目的 1、实现线性表的顺序存储结构 2、熟悉C++程序的基本结构,掌握程序中的头文件、实现文件和主文件之间的相互关系及各自的作用 3、熟悉顺序表的基本操作方式,掌握顺序表相关操作的具体实现 实验内容 对顺序存储的线性表进行一些基本操作。主要包括: (1)插入:操作…...
ChatGPT的开源平替,终于来了!
最近这段时间,一个号称全球最大ChatGPT开源平替项目Open Assistant引起了大家的注意。 这不最近还登上了GitHub的Trending热榜。 https://github.com/LAION-AI/Open-Assistant 根据官方的介绍,Open Assistant也是一个对话式的大型语言模型项目ÿ…...

Redis基础
Redis6 1. NoSQL数据库简介 1.1 技术发展 技术的分类 1、解决功能性的问题:Java、Jsp、RDBMS、Tomcat、HTML、Linux、JDBC、SVN。 2、解决扩展性的问题:Struts、Spring、SpringMVC、Hibernate、Mybatis。 3、解决性能的问题:NoSQL、Jav…...

为什么重视安全的公司都在用SSL安全证书?
我们今天来讲一讲为什么重视安全的公司都在用SSL证书 SSL证书是什么? SSL安全证书是由权威认证机构颁发的,是CA机构将公钥和相关信息写入一个文件,CA机构用他们的私钥对我们的公钥和相关信息进行签名后,将签名信息也写入这个文件…...
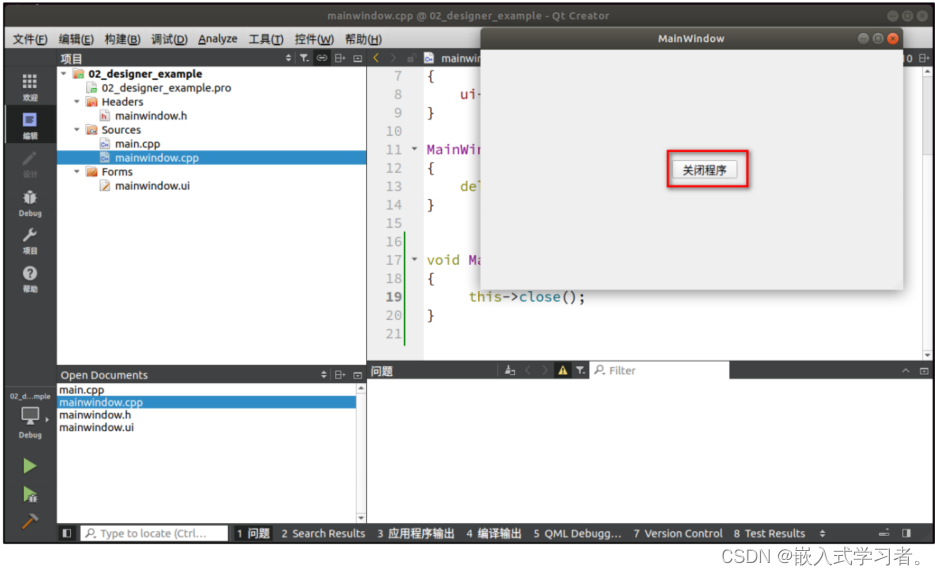
嵌入式QT (使用 Qt Designer 开发)
一、使用 UI 设计器开发程序 1.1、 在 UI 文件添加一个按钮 1.2、在 UI 文件里连接信号与槽 所谓信号即是一个对象发出的信号,槽即是当这个对象发出这个信号时,对应连接的槽就发被执行或者触发。 UI 设计器里信号与槽的连接方法一: 在主窗…...

每日一个小技巧:今天告诉你拍照识别文字的软件有哪些
在现代社会里,手机已经成为了人们生活中必不可少的工具。它的功能众多,比如通讯、上网、拍照以及导航等,为我们的生活带来了许多便利。除此之外,手机还能帮助我们解决一些实际的问题,例如,当你需要识别图片…...

多版本VersionARXDBG
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、一级标题二级标题三级标题四级标题五级标题六级标题总结前言 提示:这里可以添加本文要记录的大概内容: VersionARXDBG,多版本,2023.4.22-4.23两天时间,分别研究了在多版本编译ARXDB…...

# 生成器
生成器 生成器是什么? 生成器(generator)是一种用来生成数据的对象。它们是普通函数的一种特殊形式,可以用来控制数据的生成过程。 生成器有什么优势? 使用生成器的优势在于它们可以在生成数据的同时控制数据的生成过程…...
Netty 源码解析(上)
序 Netty的影响力以及使用场景就不用多说了, 去年10月份后,就着手研究Netty源码,之前研究过Spring源码,MyBatis源码,java.util.concurrent源码,tomcat源码,发现一个特点,之前的源码都…...
Vue 消息订阅与发布
消息订阅与发布,也可以实现任意组件之间的通信。 订阅者:就相当于是我们,用于接收数据。 发布者:就相当于是媒体,用于传递数据。 安装消息订阅与发布插件: 在原生 JS 中 不太容易实现消息订阅与发布&…...

如何在你的云服务器/云主机上更新并使用最新版本的python(python3.11)
更新并使用最新版本的python3.11 第一步,登录云服务器,并更新系统包 打开您的终端(Terminal)或使用任意SSH客户端,输入如下命令来登录云主机: ssh 用户名IP地址 在输入密码后,您将成功登录到云…...
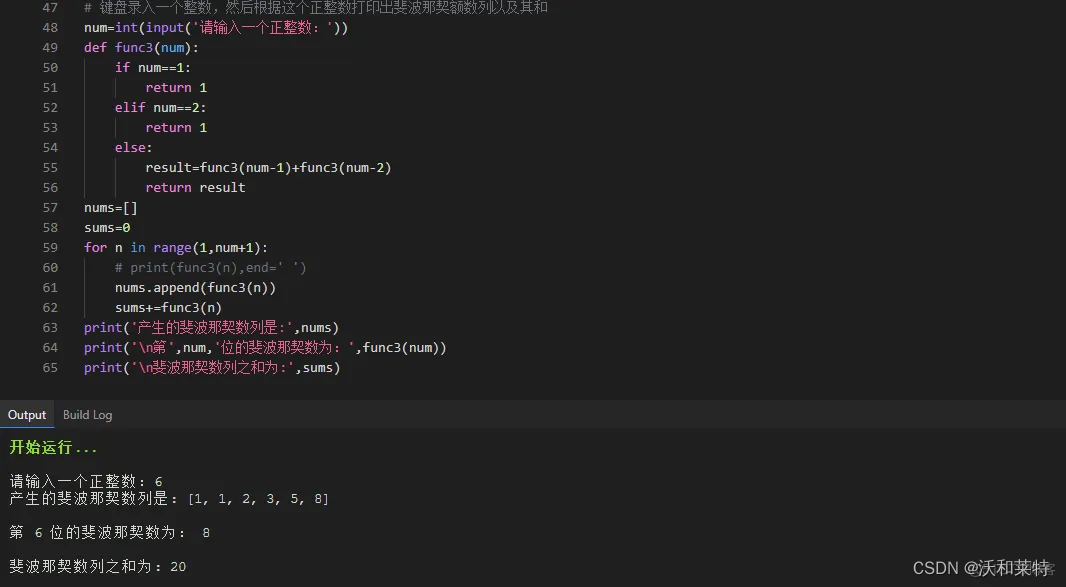
python学习——【第八弹】
前言 上篇文章 python学习——【第七弹】学习了python中的可变序列集合,自此python中的序列的学习就完成啦,这篇文章开始学习python中的函数。 函数 在学习其他编程语言的时候我们就了解过函数:函数就是执行特定任何以完成特定功能的一段代…...
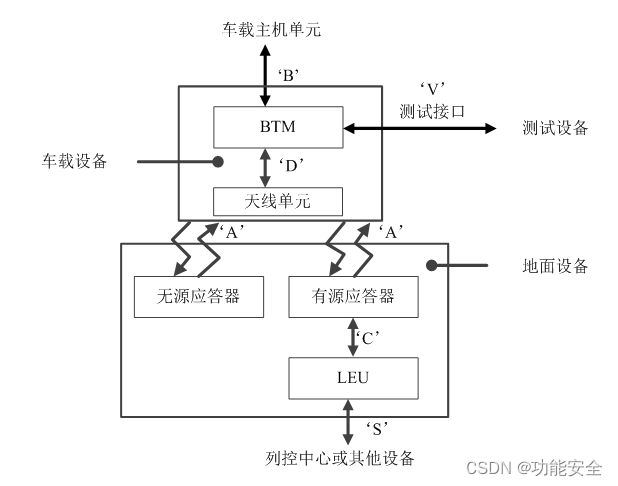
铁路应答器传输系统介绍
应答器传输系统 应答器传输系统是安全点式信息传输系统,通过应答器实现地面设备向车载设备传输信息。 应答器可根据应用需求向车载设备传输固定的(通过无源应答器)或可变的(通过有源应答器)上行链路数据。 当天线单…...
)
Baumer工业相机堡盟工业相机如何通过BGAPI SDK直接实现Mono16位深度的图像保存(C#)
Baumer工业相机堡盟工业相机如何通过BGAPI SDK直接实现Mono16位深度的图像保存(C#) Baumer工业相机Baumer工业相机保存位深度12/16位图像的技术背景代码案例分享1:引用合适的类文件2:通过BGAPI SDK直接保存Mono12/16图像3…...
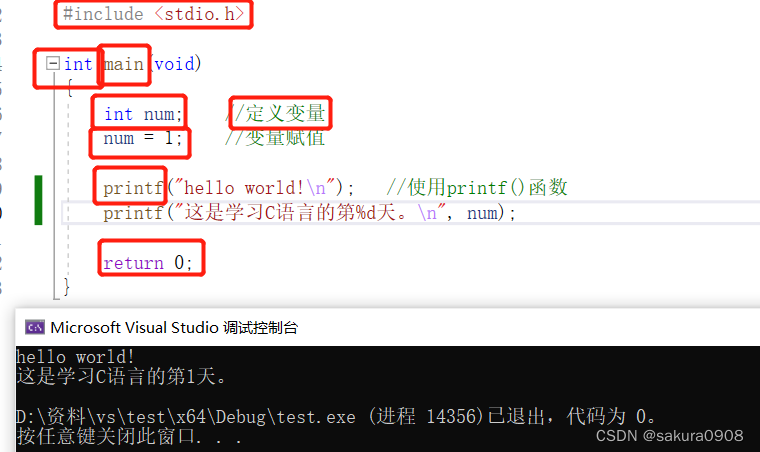
C语言入门篇——介绍篇
目录 1、什么是C语言 1、C语言的优点 3、语言标准 4、使用C语言的步骤 5、第一个C语言程序 6、关键字 1、什么是C语言 1972年,贝尔实验室的丹尼斯里奇和肯汤普逊在开发UNIX操作系统时设计了C语言,C语言是在B语言的基础上进行设计。C语言设计的初衷…...

Latex数学公式排版
文章目录 Latex使用最佳方式:读官方文档Latex中的字符数学公式排版1.引入宏包:2.公式排版基础3.数学符号(1).希腊字母(2).指数,上下标,导数(3).分式和根式(4).关系符(5).算符(6).巨算符(7).箭头 Latex使用 最佳方式:读官方文档 The not so short intro…...

【Linux】-关于Linux的指令(上)
作者:小树苗渴望变成参天大树 作者宣言:认真写好每一篇博客 作者gitee:gitee 如 果 你 喜 欢 作 者 的 文 章 ,就 给 作 者 点 点 关 注 吧! TOC 前言 今天我们来讲关于Linux的基本指令,博主讲的指令会对应着Windows…...

【论文写作】引言写作的四个重要的语言点之时态!!!
在本篇文章当中,我们将着重介绍四个重要的写作语言要点之一的时态,其他语言点如下: 1. 时态 2. 标志性的衔接词 3. 主动、被动语态 4. 段落 1. 简单现在时和现在进行时 时态主要有现在时和现在进行时,看以下两个句子 I live in…...
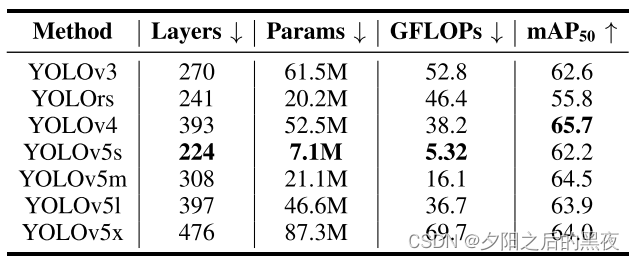
Super Yolo论文翻译
论文:SuperYOLO: Super Resolution Assisted Object Detection in Multimodal Remote Sensing Imagery【IEEE】 论文地址: IEEE Xplore Full-Text PDF:https://ieeexplore.ieee.org/stamp/stamp.jsp?tp&arnumber10075555项目地址:icey…...

硬件设计应用解析:钡特电源 VB10-48S05S 与金升阳 URB4805S-10WR3 属工业标准模块电源封装与性能
在工业电子系统设计中,工业 DC-DC 模块作为能源转换核心器件,其标准化程度、电气性能与长期可靠性直接决定整机稳定性。钡特电源 VB10-48S05S 与金升阳 URB4805S-10WR3 均为国产 10W 级隔离型直流电源模块,二者采用国际标准封装引脚ÿ…...

G-Helper:华硕笔记本性能控制的终极轻量级替代方案
G-Helper:华硕笔记本性能控制的终极轻量级替代方案 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenbook, Exper…...

用Excel手搓反向传播神经网络:零代码理解梯度下降
1. 项目概述:用Excel手搓一个能反向传播的神经网络,真不用写一行代码你有没有过这种感觉:想搞懂神经网络到底是怎么“学”会识别猫狗、预测房价的,可一翻开教材就是矩阵求导、链式法则、张量运算,还没开始就卡在了数学…...

技术人如何找到自己的“甜蜜点”?一个四象限模型帮你定位
在软件测试这条“越走越深”的路上,每个从业者早晚都会撞上一堵墙——技能焦虑。自动化框架层出不穷,性能工具日新月异,安全左移、精准测试、AI 辅助……每一样看起来都很重要,每一样又都学不完。于是有人拼命考证,有人…...

Rescuezilla:3步轻松搞定系统备份与恢复的瑞士军刀
Rescuezilla:3步轻松搞定系统备份与恢复的瑞士军刀 【免费下载链接】rescuezilla The Swiss Army Knife of System Recovery 项目地址: https://gitcode.com/gh_mirrors/re/rescuezilla 当你面对电脑系统崩溃、硬盘损坏或数据丢失的紧急情况时,是…...

OpenSSH CVE-2024-6387 漏洞原理与实战修复指南
1. 这不是普通补丁:CVE-2024-6387 是 OpenSSH 里埋了二十年的“定时炸弹”你有没有遇到过这种情况:凌晨三点,监控告警疯狂闪烁,SSH 登录失败率突然飙升到98%,但服务器负载、内存、磁盘一切正常;运维同事反复…...

技术选型指南:Pentaho Data Integration 11.x企业级数据集成架构深度解析
技术选型指南:Pentaho Data Integration 11.x企业级数据集成架构深度解析 【免费下载链接】pentaho-kettle Pentaho Data Integration ( ETL ) a.k.a Kettle 项目地址: https://gitcode.com/gh_mirrors/pe/pentaho-kettle Pentaho Data Integrationÿ…...

OpenMTP:macOS上最强大的免费Android文件传输终极解决方案
OpenMTP:macOS上最强大的免费Android文件传输终极解决方案 【免费下载链接】openmtp OpenMTP - Advanced Android File Transfer Application for macOS 项目地址: https://gitcode.com/gh_mirrors/op/openmtp 还在为macOS和Android设备之间的文件传输而烦恼…...

CTF流量分析实战:从协议层还原攻击链
1. 这不是“看图说话”,而是网络攻防现场的证据链重建CTF流量分析题,很多人第一反应是打开Wireshark点开pcap文件,扫一眼HTTP请求、找找base64字符串、翻翻DNS查询——然后卡在第3个包就停了。我带过三届校队,每年都有至少一半选手…...

2026大模型全栈学习路线:从零基础入门到实战就业
随着AI技术全面落地,大模型已从实验室技术转变为各行各业的刚需能力。2026年,AI Agent、多模态生成、轻量化模型部署、行业定制微调成为行业主流趋势,大模型相关岗位需求持续爆发,应用工程师、微调工程师、AI架构师等岗位薪资稳居…...