python 之数据类型(四)
1、字符串(String)
使用双引号或者单引号中的数据,就是字符串
注:python中使用三引号时允许一个字符串跨多行,字符串中可以包含换行符、制表符以及其它特殊符号
a='''
a
c
g'''
print(a)运行结果:
a
c
g
1、下标
所谓‘下标’,就是编号,就好比超市中存储柜的编号,通过这个编号就能找到相应的存储空间
列表与元祖支持下标索引,字符串实际上就是字符的数组,所以也支持下标索引
python中下标从0开始,如果想取出部分字符,可以通过下表的方法,如:
name = 'abcdef '
print(name[0])
print(name[1])运行结果:
a
b
2、切片
切片是指对操作的对象截取其中一部分的操作。字符串、列表、元祖都支持切片操作
切片的语法:[起始:结束:步长]
注意:选取的区间属于左闭右开型,即从‘起始’位开始,到‘结束’位的前一位结束(不包含结束位本身)。如:
name = 'abcdef'
print('字符串name: ' + name)
print('name[0:3]的结果为: ' + name[0:3]) # 取下标 0~2 的字符
print('name[0:5]的结果为: ' + name[0:5]) # 取下标 0~4 的字符
print('name[3:5]的结果为: ' + name[3:5]) # 取下标 3、4 的字符
print('name[2:]的结果为: ' + name[2:]) # 取下标 2 开始到最后的字符
print('name[1:-1]的结果为: ' + name[1:-1]) # 取下标从 2 开始到倒数第2个字符之间的字符
print('name[:3]的结果为: ' + name[:3]) # 取下标 0~2 的字符
print('name[::2]的结果为: ' + name[::2]) # 取下标从 0 开始,步长为 2 的字符
print('name[::-2]的结果为: ' + name[::-2]) # 取下标从最后一个字符开始,步长为 -2(倒着取)的字符
print('name[5:1:2]的结果为: ' + name[5:1:2]) # 正向取 下标为 5~2 步长为 2 的字符
print('name[5:1:-2]的结果为: ' + name[5:1:-2]) # 倒着取下标为 5~2 且步长为 2 的字符
print('name[1:5:2]的结果为: ' + name[1:5:2]) # 取下标为 1~4 步长为 2 的字符运行结果:
字符串name: abcdef
name[0:3]的结果为: abc
name[0:5]的结果为: abcde
name[3:5]的结果为: de
name[2:]的结果为: cdef
name[1:-1]的结果为: bcde
name[:3]的结果为: abc
name[::2]的结果为: ace
name[::-2]的结果为: fdb
name[5:1:2]的结果为:
name[5:1:-2]的结果为: fd
name[1:5:2]的结果为: bd
2、列表(List)
nameList = ['xiaoWang', 'xiaoZhang', 'xiaoHua']
print(nameList[0])
print(nameList[1])
print(nameList[2])运行结果:
xiaoWang
xiaoZhang
xiaoHua
1、列表的循环遍历
1、使用 for 循环
nameList = ['xiaoWang', 'xiaoZhang', 'xiaoHua']
for name in nameList:print(name)
运行结果:
xiaoWang
xiaoZhang
xiaoHua
2、使用 while 循环
nameList=['xiaoWang','xiaoZhang','xiaoHua']
length=len(nameList)
i=0
while i<length:print(nameList[i])i+=1运行结果:
xiaoWang
xiaoZhang
xiaoHua
2、列表的相关操作
1、添加元素(‘增’ append,extend,insert)
1、通过 append 可以向列表添加元素
# 定义变量 A
A = ['xiaoWang','xiaoZhang','xiaoHua']
print('---添加之前列表 A 的数据---')
for a in A:print(a)
# 提示并添加元素
name = input('请输入要添加的学生姓名: ')
A.append(name)
print('---添加之后列表 A 的数据---')
for a in A:print(a)运行结果:
---添加之前列表 A 的数据---
xiaoWang
xiaoZhang
xiaoHua
请输入要添加的学生姓名: 张三
---添加之后列表 A 的数据---
xiaoWang
xiaoZhang
xiaoHua
张三
2、通过 extend 可以将另一个集合的元素逐一添加到列表中
a=[1,2]
b=[3,4]
a.append(b)
print(a)
a.extend(b)
print(a)运行结果:
[1, 2, [3, 4]]
[1, 2, [3, 4], 3, 4]
3、insert(index,object) 在指定位置 index 前插入元素 object
a = [0, 1, 2]
a.insert(1, 3)
print(a)运行结果:
[0, 3, 1, 2]
2、修改元素(‘改’)
修改元素的时候,要通过下标来确定修改的是那个元素,然后才能进行修改
# 定义变量 A
A = ['xiaoWang', 'xiaoZhang', 'xiaoHua']
print('---修改之前列表 A 的数据---')
for a in A:print(a)
# 修改元素
A[1] = 'xiaoLu'
print('---修改之后列表 A 的数据---')
for a in A:print(a)运行结果:
---修改之前列表 A 的数据---
xiaoWang
xiaoZhang
xiaoHua
---修改之后列表 A 的数据---
xiaoWang
xiaoLu
xiaoHua
3、查找元素(‘查’ in,not in,index,count)
所谓的查找,就是看看指定的元素是否存在
python中查找的常用方法为:
in(存在):如果存在结果为 True,否则结果为 False
not in(不存在):如果不存在结果为 True,否则结果为 False
# 待查找的列表
nameList = ['xiaoWang', 'xiaoZhang', 'xiaoHua']
# 获取用户要查找的名字
name = input('请输入要查找的姓名: ')
# 查找是否存在
if name in nameList:print('找到了相同的名字')
else:print('没有找到相同的名字')运行结果:
请输入要查找的姓名: xiaoWang
找到了相同的名字
index 和 count 与字符串中的用法相同
a = ['a', 'b', 'c', 'a', 'b']
print(a.index('a', 1, 4)) # 注意是左闭右开区间
print(account('b'))运行结果:
3
2
4、删除元素(‘删’ del,pop,remove)
1、del:根据下标进行删除
movieName=['加勒比海盗','骇客帝国','第一滴血','指怀王','霍比特人']
print('---删除之前---')
for name in movieName:print(name)
del movieName[2]
print('---删除之后---')
for name in movieName:print(name)
2、pop:删除最后一个元素
movieName=['加勒比海盗','骇客帝国','第一滴血','指怀王','霍比特人']
print('---删除之前---')
for name in movieName:print(name)
movieName.pop()
print('---删除之后---')
for name in movieName:print(name)
3、remove:根据元素的值进行删除
movieName=['加勒比海盗','骇客帝国','第一滴血','指怀王','霍比特人']
print('---删除之前---')
for name in movieName:print(name)
movieName.remove('指怀王')
print('---删除之后---')
for name in movieName:print(name)
5、排序(sort、reverse)
sort 方法是将 list 按特定顺序重新排列,默认为由小到大,参数 reserve =True 可以将排序改为倒序
reverse 方法是将 list 逆置
a = [1, 4, 2, 3]
print(a)
a.reverse()
print(a)
a.sort()
print(a)
a.sort(reverse=True)
print(a)运行结果:
[1, 4, 2, 3]
[3, 2, 4, 1]
[1, 2, 3, 4]
[4, 3, 2, 1]
3、列表的嵌套
类似 while 循环的嵌套,列表也是支持嵌套的
一个列表中的元素又是一个列表,那么这就是列表的嵌套
schoolName = [['北京大学', '清华大学'],['南京大学', '天津大学', '天津师范大学'],['山东大学', '中国海洋大学']
]
print(schoolName)运行结果:
[['北京大学', '清华大学'], ['南京大学', '天津大学', '天津师范大学'], ['山东大学', '中国海洋大学']]
3、集合(Set)
集合是一个无序不重复元素的序列,基本功能是进行成员关系测试和删除重复元素,可以使用大括号 {} 或者 set() 函数创建集合(注意:创建一个空集合必须用set() 而不是 {} ,因为 {} 是用来创建一个空字典
student = {'Tom', 'Jim', 'Mary', 'Tom', 'Jack', 'Rose'}
print(student) # 输出集合,重复的元素被自动去掉运行结果:
{'Jack', 'Tom', 'Jim', 'Rose', 'Mary'}
1、成员测试
student = {'Tom', 'Jim', 'Mary', 'Tom', 'Jack', 'Rose'}
if 'Rose' in student:print('Rose 在集合中')
else:print('Rose 不在集合中')运行结果:
Rose 在集合中
2、set 可以进行集合运算
a = set('abracadabra')
b = set('alacazam')
print(a)
print(b)
print(a - b) # a 和 b 的差集
print(a | b) # a 和 b 的并集
print(a & b) # a 和 b 的交集
print(a ^ b) # a 和 b 中不同时存在的元素运行结果:
{'a', 'c', 'b', 'd', 'r'}
{'a', 'm', 'l', 'c', 'z'}
{'b', 'd', 'r'}
{'a', 'm', 'l', 'c', 'z', 'b', 'd', 'r'}
{'a', 'c'}
{'m', 'b', 'l', 'z', 'r', 'd'}
4、元祖(Tuple)
python 的元祖与列表类似,不同之处在于元祖的元素不能修改。元祖使用小括号,列表使用中括号。
1、访问元祖
aTuple = ('at', 77, 99.9)
print(aTuple)
print(aTuple[0])
print(aTuple[1])
print(aTuple[2])运行结果:
('at', 77, 99.9)
at
77
99.9
2、修改元祖
元组中的元素值是不允许修改的,但我们可以对元祖进行连接组合
tup1 = (12, 34.56)
tup2 = ('abc', 'xyz')
tup1[0] = 100
tup3 = tup1 + tup2
print(tup3)运行结果:
TypeError: 'tuple' object does not support item assignment
(12, 34.56, 'abc', 'xyz')
3、删除元祖
元组中的元素值是不允许删除的,但我们可以使用 del 语句来删除整个元祖
tup = ('a','b',1,2)
del tup
print('删除后的元祖tup:')
print(tup)运行结果:
删除后的元祖tup:
NameError: name 'tup' is not defined
5、字典(Dictionary)
字典和列表一样,也能存储多个数据。
列表中找某个元素时,是根据下标进行的
字典的每个元素由2部分组成:键和值,字典中找某个元素时,是根据键
1、根据键访问值
info = {'name': '张三', 'id': 100, 'sex': '男', 'address': '北京'}
print(info['name'])
print(info['address'])运行结果:
张三
北京
若访问不存在的值,则会报错
info = {'name': '张三', 'id': 100, 'sex': '男', 'address': '北京'}
info['age']运行结果:
KeyError: 'age'
若我们不确定字典中是否存在某个键而又想获取其值时,可以使用 get方法,还可以设置默认值
info = {'name': '张三', 'id': 100, 'sex': '男', 'address': '北京'}
age = info.get('age')
print(type(age))
age = info.get('age', 18) # 若 info 中不存在 age 这个键,则返回默认值 18
print(age)运行结果:
<class 'NoneType'>
18
2、修改元素
字典的每个元素中的数据是可以修改的,只要通过 key 找到,即可修改
info = {'name': '张三', 'id': 100, 'sex': '男', 'address': '北京'}
newId = input('请输入新的学号:')
info['id'] = int(newId)
print('修改之后的 id 为 %d' % info['id'])运行结果:
请输入新的学号:001
修改之后的 id 为 1
3、添加元素
如果在使用 变量名[‘键’]=数据 时,这个键在字典中不存在,那么就会新增这个元素
info = {'name': '张三', 'sex': '男', 'address': '北京'}
print('id 为 %d' % info['id']) # 程序会终止运行,因为访问了不存在的减
newId = input('请输入新的学号:')
info['id'] = int(newId)
print('添加之后的 id 为 %d' % info['id'])运行结果:
KeyError: 'id'
请输入新的学号:001
添加之后的 id 为 1
4、删除元素
对字典进行删除操作有以下几种:del、clear()
1、del:删除指定的元素
info = {'name': '张三', 'sex': '男', 'address': '北京'}
print('删除前 %s' % info['name'])
del info['name']
print('删除后 %s' % info['name'])运行结果:
删除前 张三
KeyError: 'name'
2、del: 删除整个字典
info = {'name': '张三', 'sex': '男', 'address': '北京'}
print('删除前 %s' % info)
del info
print('删除后 %s' % info)运行结果:
删除前 {'name': '张三', 'sex': '男', 'address': '北京'}
NameError: name 'info' is not defined
3、clear :清空整个列表
info = {'name': '张三', 'sex': '男', 'address': '北京'}
print('清空前 %s' % info)
info.clear()
print('清空后 %s' % info)运行结果:
清空前 {'name': '张三', 'sex': '男', 'address': '北京'}
清空后 {}
5、len:返回字典中键值对的个数
info = {'name': '张三', 'sex': '男', 'address': '北京'}
print('info 中键值对的个数为:'+str(len(info)))运行结果:
info 中键值对的个数为:3
6、keys:返回一个包含字典所有 key 的可迭代对象
info = {'name': '张三', 'sex': '男', 'address': '北京'}
print(info.keys())运行结果:
dict_keys(['name', 'sex', 'address'])
7、values:返回一个包含字典所有 value 的可迭代对象
info = {'name': '张三', 'sex': '男', 'address': '北京'}
print(info.values())运行结果:
dict_values(['张三', '男', '北京'])
8、items:返回一个包含所有(键,值)元祖的可迭代对象
info = {'name': '张三', 'sex': '男', 'address': '北京'}
print(info.items())运行结果:
dict_items([('name', '张三'), ('sex', '男'), ('address', '北京')])
6、遍历
通过 for…in… 的语法结构,我们可以遍历字符串、列表、元祖、字典等数据结构
1、字符串遍历
s = 'hello world'
for c in s:print(c, end=' ')运行结果:
h e l l o w o r l d
2、列表遍历
list = [1, 2, 3, 4, 5]
for l in list:print(l, end=' ')运行结果:
1 2 3 4 5
3、元组遍历
tp = (1, 2, 3, 4, 5)
for t in tp:print(t, end=' ')运行结果:
1 2 3 4 5
4、字典遍历
1、遍历字典的 key(键)
dt = {'name': '张三', 'sex': '男', 'address': '北京'}
for key in dt.keys():print(key)运行结果:
name
sex
address
2、遍历字典的 value(值)
dt = {'name': '张三', 'sex': '男', 'address': '北京'}
for value in dt.values():print(value)运行结果:
张三
男
北京
3、遍历字典的项(元素)
dt = {'name': '张三', 'sex': '男', 'address': '北京'}
for item in dt.items():print(item)运行结果:
('name', '张三')
('sex', '男')
('address', '北京')
4、遍历字典的 key-value(键值对)
dt = {'name': '张三', 'sex': '男', 'address': '北京'}
for key, value in dt.items():print(key, value)运行结果:
name 张三
sex 男
address 北京
5、带下标索引的遍历
chars = ['a', 'b', 'c', 'd']
i = 0
for c in chars:print('%d: %s' % (i, c))i += 1运行结果:
0: a
1: b
2: c
3: d
6、enumerate()函数
用于将一个可遍历的数据对象(如列表、元祖、字符串)组合为一个索引序列,同时列出数组和数据下标,一般用在 for 循环当中
chars = ['a', 'b', 'c', 'd']
for i, c in enumerate(chars):print(i, c)运行结果:
0 a
1 b
2 c
3 d
7、公共方法
1、运算符
| 运算法 | 描述 | 支持的数据类型 |
|---|---|---|
| + | 合并 | 字符串、列表、元组 |
| * | 复制 | 字符串、列表、元组 |
| in | 元素是否存在 | 字符串、列表、元组、字典 |
| not in | 元素是否不存在 | 字符串、列表、元组、字典 |
1、+
print('hello' + 'world')
print([1, 2] + [3, 4])
print(('a', 'b') + ('c', 'd'))运行结果:
helloworld
[1, 2, 3, 4]
('a', 'b', 'c', 'd')
2、*
print('ab' * 4)
print([1, 2] * 4)
print(('a', 'b') * 4)运行结果:
abababab
[1, 2, 1, 2, 1, 2, 1, 2]
('a', 'b', 'a', 'b', 'a', 'b', 'a', 'b')
3、in
print('he' in 'hello world')
print(3 in [1, 2])
print(4 in (1, 2, 3, 4))
print('name' in {'name': '张三', 'age': 24})运行结果:
True
False
True
True
4、not in
print('he' not in 'hello world')
print(3 not in [1, 2])
print(4 not in (1, 2, 3, 4))
print('name' not in {'name': '张三', 'age': 24})运行结果:
False
True
False
False
注意:in,not in 在对字典操作时,判断的是字典的键
2、python 内置函数
| 方法 | 描述 |
|---|---|
| len(item) | 计算容器中元素个数 |
| max(item) | 返回容器中元素最大值 |
| min(item) | 返回容器中元素最小值 |
| del(item) | 删除变量 |
range()函数返回的是一个可迭代的对象
range(stop)
range(start,stop[,step])
for i in range(5):print(i, end=' ')
print()
for i in range(1, 5, 1):print(i, end=' ')
print()
for i in range(1, 5, 2):print(i, end=' ')运行结果:
0 1 2 3 4
1 2 3 4
1 3
列表推导式
所谓的列表推导式,就是指的轻量级循环创建列表
a = [x for x in range(4)]
print(a)
b = [x for x in range(1, 4)]
print(b)
c = [x for x in range(1, 10) if x % 2 == 0]
print(c)
d = [(x, y) for x in range(1, 3) for y in range(3)]
print(d)运行结果:
[0, 1, 2, 3]
[1, 2, 3]
[2, 4, 6, 8]
[(1, 0), (1, 1), (1, 2), (2, 0), (2, 1), (2, 2)]
8、引用
在 python 中,值是靠索引来传递的
我们可以用 id() 来判断两个变量是否为同一个值的引用,我们可以将 id 值理解为那块内存的地址标示
可变类型和不可变类型
可变类型:值可以改变
List(列表)、Dictionary(字典)、Set(集合)
以列表为例,如下:
a = ['a', 'b', 'c']
b = a
print(a)
print(b)
print(id(a))
print(id(b))
a.append('d')
print(a)
print(b)
print(id(a))
print(id(b))运行结果:
['a', 'b', 'c']
['a', 'b', 'c']
1307459048192
1307459048192
['a', 'b', 'c', 'd']
['a', 'b', 'c', 'd']
1307459048192
1307459048192
不可变类型:值不可以改变
Number(数字)、String(字符串)、Tuple(元祖)
以字符串为例,如下:
a='helloworld'
b=a
print('a = '+a)
print('b = '+b)
print(id(a))
print(id(b))
a='你好'
print('a = '+a)
print('b = '+b)
print(id(a))
print(id(b))运行结果:
a = helloworld
b = helloworld
1894198703984
1894198703984
a = 你好
b = helloworld
1894198795824
1894198703984
相关文章:
)
python 之数据类型(四)
1、字符串(String) 使用双引号或者单引号中的数据,就是字符串 注:python中使用三引号时允许一个字符串跨多行,字符串中可以包含换行符、制表符以及其它特殊符号 a a c g print(a)运行结果: a c g1、下标 …...

洛谷P1345 无向图最小割点数
题意: 给出一副有 n n n个点, m m m条边的无向图,求出这副图的最小割点数 题意: 首先对于有向图,求他的最小割边,只需要令每条边的容量为 1 1 1,求出起点到终点的最大流就是最小割边数了。 容…...

适合程序员阅读的有用书籍:
几本适合程序员阅读的有用书籍: 1.《计算机程序设计艺术》(The Art of Computer Programming)是由Donald E. Knuth撰写的一系列著作,是计算机科学领域的经典之作。该系列著作共分为三卷,分别介绍了算法和计算机程序设计的基础知识和技巧。 …...
MySQL: 自动添加约束、更改(删除)表名和字段、删除表
目录 自动添加表的属性: 向表内插入数据: 查看表中的数据: 查看表结构: 查看表的详细结构: 更改表名和字段: 更改表名: 更改字段数据类型: 修改字段名: 添加字段…...

基于微博评论的细粒度的虚假信息识别软件
任务 目标:能检测单模态的虚假信息就可以,是个软件就可以 参考文章:基于多模态深度融合的虚假信息检测 Multi-modal deep fusion for false information detection 思路 多模态指的是多种不同类型的数据,比如图像、文本、音频等。虚假信息识别软件可以从这些不同类型的数据…...

Android 11.0 系统systemui状态栏下拉左滑显示通知栏右滑显示控制中心模块的流程分析
1.前言 在android11.0的系统rom定制化开发中,在系统原生systemui进行自定义下拉状态栏布局的定制的时候,需要在systemui下拉状态栏下滑的时候,根据下滑坐标来 判断当前是滑出通知栏还是滑出控制中心模块,所以就需要根据屏幕宽度,来区分x坐标值为多少是左滑出通知栏或者右…...
ROS学习第三十二节——xacro构建激光雷达小车
https://download.csdn.net/download/qq_45685327/87718396 在前面小车底盘基础之上,添加摄像头和雷达传感器。 0.底盘实现 deamo02_base.xacro <!--使用 xacro 优化 URDF 版的小车底盘实现:实现思路:1.将一些常量、变量封装为 xacro:property比如…...

中厂,面试就问了4道题,凉了!
你好,我是田哥 所谓的金三银四,已变成铜三铁四了。很多人基本上莫有面试机会,更可惜的是机会有了,却没有把握住。 加入我知识星球:免费做简历优化、简历包装、模拟面试... 今天早上,一个朋友和我说面试中被…...

22.轮播模块
学习要点: 1.轮播模块 本节课我们来开始了解 Layui 的内置模块:轮播模块。 一.轮播模块 1. 轮播模块,即跑马灯等轮播交互场景,先来看下基本设置; <div id"test" class"layui-carousel&qu…...

MYSQL命令小总结
一、创建查看 1.输入cmd,打开控制器,输入如下,打开MYSQL C:\Users\ASUS> mysql -u root -p 2.查看已有数据库 mysql> show databases; 3.建立数据库 4.使用数据库 use englishword;5.建立表单 CREATE TABLE user ( id INT primar…...

Java常见开发工具和Object类
Java是一种面向对象的编程语言,被广泛应用于各种应用程序和软件开发中。在Java开发过程中,使用一个好的开发工具可以大大提高开发效率和代码质量。Eclipse是一个功能强大、灵活易用的Java集成开发环境(IDE),被广泛使用…...
Linux 配置YUM源(FTP方式获取软件源、使用阿里云yum源、同时使用本地源与在线源)YUM获取安装包并生成YUM软件仓库
YUM介绍 YUM(yellow dog updater modified) 基于RPM包构建的软件更新机制 自动解决依赖关系 yum软件仓库集中管理软件包 RPM软件包的来源 centos发布的RPM包集合第三方组织发布的RPM包集合用户自定义的RPM包集合 软件仓库的提供方式 FTP服务:…...

Java版工程行业管理系统源码-专业的工程管理软件-提供一站式服务
Java版工程项目管理系统 Spring CloudSpring BootMybatisVueElementUI前后端分离 功能清单如下: 首页 工作台:待办工作、消息通知、预警信息,点击可进入相应的列表 项目进度图表:选择(总体或单个)项目显示…...
养老保障金查询系统【GUI/Swing+MySQL】(Java课设)
系统类型 Swing窗口类型Mysql数据库存储数据 使用范围 适合作为Java课设!!! 部署环境 jdk1.8Mysql8.0Idea或eclipsejdbc 运行效果 本系统源码地址:https://download.csdn.net/download/qq_50954361/87700421 更多系统资源库…...

国考省考行测:词句理解,词的对象指代,就近原则,主语一致法,语意语境分析上下文找出指代含义
国考省考行测:词句理解,词的对象指代,就近原则,主语一致法,语意语境分析上下文找出指代含义 2022找工作是学历、能力和运气的超强结合体! 公务员特招重点就是专业技能,附带行测和申论,而常规国…...

部署YUM仓库
部署YUM仓库 YUM概述软件仓库的提供方式RPM软件包的来源FTP源的配置方法本地源配置方法在线源配置方法本地源和在线源一起使用的方法数据包缓存方法 自己配置本地yum源时需要使用createrepo来生成依赖关系库 YUM概述 YUM(Yellow dog Updater Modified) 基于RPM包构建的软件更…...

SpringBoot框架(邮件发送Mail|持久层框架JPA|Extra前后端分离跨域处理|接口管理Swagger)这一篇就够了(超详细)
🙈作者简介:练习时长两年半的Java up主 🙉个人主页:老茶icon 🙊 ps:点赞👍是免费的,却可以让写博客的作者开兴好久好久😎 📚系列专栏:Java全栈,计…...

chatGPT对话R语言
文章目录 R语言介绍R语言基本语法R语言常用函数有哪些R语言数据结构向量矩阵数组和列表数组列表 数据框因子 R如何导入数据如何在R语言中导出数据?R语言图形绘制描述性统计描述统计也可以这样来计算 统计推断配对设计t检验样本均数和总体均数t检验两(独立…...

代码随想录--字符串--替换空格题型
①这道题可以直接申请一个临时数组,然后遍历字符串,是空格则加入20%,最后再把临时数组转化为字符串。 怎么把一个数组转化为字符串? 如数组arry[], string newstr new string(arry,0,arry.size()-1); return newstr; 而且临时数…...
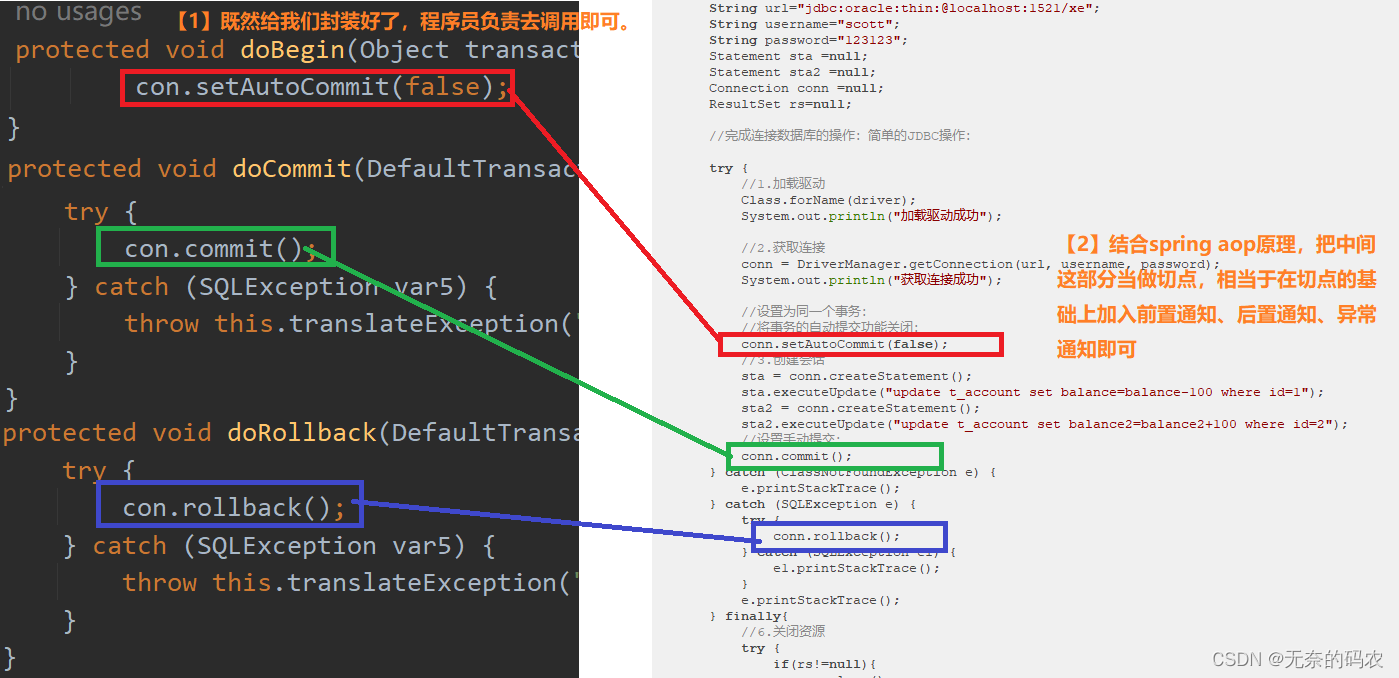
Spring JDBC和事务控制
目录 Spring JDBC 和 事务控制主要内容Spring 整合 JDBC 环境构建项目添加依赖坐标添加 jdbc 配置文件编写 spring 配置文件配置数据源C3P0 数据源配置DBCP 数据源配置 模板类配置Spring JDBC 测试 (入门)创建指定数据库创建数据表使用 JUnit 测试JUnit …...

如何快速掌握小程序UI组件库:Vant Weapp的5大优势与完整指南
如何快速掌握小程序UI组件库:Vant Weapp的5大优势与完整指南 【免费下载链接】vant-weapp 轻量、可靠的小程序 UI 组件库 项目地址: https://gitcode.com/gh_mirrors/va/vant-weapp Vant Weapp是一款轻量、可靠的小程序UI组件库,专为微信小程序开…...

多模态模型中图像生成器使用的扩散模型的组件
多模态模型中图像生成器使用的扩散模型组件 多模态模型中的图像生成器,通常不是一个单独网络,而是一套 条件扩散生成系统。典型输入是文本、图像、mask、bbox、姿态、深度图、边缘图、语义图、视频帧或多模态 embedding,输出是目标图像。 最常…...

为什么说Ohook重新定义了Office激活的技术边界?
为什么说Ohook重新定义了Office激活的技术边界? 【免费下载链接】ohook An universal Office "activation" hook with main focus of enabling full functionality of subscription editions 项目地址: https://gitcode.com/gh_mirrors/oh/ohook 当…...

承压含水层中变流量抽水试验井流动力学模型与参数反演方法【附算法】
✨ 长期致力于变流量、抽水试验、参数反演、井损、粒子群优化算法研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)线性衰减变流量抽水试验理论模型与半…...

mpv.net 高效配置实战:从媒体播放到专业调优的进阶指南
mpv.net 高效配置实战:从媒体播放到专业调优的进阶指南 【免费下载链接】mpv.net 🎞 mpv.net is a media player for Windows with a modern GUI. 项目地址: https://gitcode.com/gh_mirrors/mp/mpv.net 作为一款基于mpv核心的现代化Windows媒体播…...

3步搞定专业级流程图:dagre-d3终极可视化指南
3步搞定专业级流程图:dagre-d3终极可视化指南 【免费下载链接】dagre-d3 A D3-based renderer for Dagre 项目地址: https://gitcode.com/gh_mirrors/da/dagre-d3 还在为创建复杂的流程图而头疼吗?🤔 今天我要向大家介绍一个神奇的工具…...

数据血缘是什么?一数据血缘、数据质量和数据地图的区别是什么?
数据血缘、数据质量、数据地图,这三个概念经常被混为一谈,尤其是刚入行的新人,觉得不就是管数据的吗,非要分那么清楚?就连一些工作了三五年的工程师,在面试时也常常搞混,比如把血缘当成地图&…...

Agent相关面试
Agent高频面试题1. 一分钟讲清楚 Agent 的定义Agent 是以大模型为推理大脑,具备感知、思考、规划、工具调用、记忆、执行迭代能力的智能体。不再是简单问答,而是能自主拆解复杂任务、自主选择工具、自主多轮推理、记忆上下文、闭环完成目标,可…...

模型替换易,工作流锁定难!AI 锁定效应转移,企业决策何去何从?
模型替换易,工作流锁定难模型替换正变得越来越容易,但围绕模型的操作、集成和治理机制却难以更换。近日,普华永道(PwC)宣布为 3 万名员工提供有关 Anthropic 公司 Claude 模型的培训和认证,并围绕该模型为银…...

Cat-Catch浏览器资源嗅探扩展深度解析:高性能流媒体捕获架构揭秘
Cat-Catch浏览器资源嗅探扩展深度解析:高性能流媒体捕获架构揭秘 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch Cat-Catch作为一款专业…...