如何通过筛选高质量爬虫IP提升爬虫效率?
前言
对于做数据抓取的技术员来说,如何稳定高效的爬取数据ip库池起到决定性作用,对于爬虫ip池的维护,可以从以下几个方面入手:
目录
- 一、验证爬虫ip的可用性
- 二、更新爬虫ip池
- 三、维护爬虫ip的质量
- 四、监控爬虫ip的使用情况
一、验证爬虫ip的可用性
可以通过requests库向目标网站发送请求,判断爬虫ip是否能够成功返回响应。如果返回成功,则说明爬虫ip可用,否则说明爬虫ip已失效。可以在代码中设置超时时间,避免长时间等待无响应的爬虫ip。
import requests
def check_proxy(proxy):try:response = requests.get(url, proxies=proxy, timeout=3)if response.status_code == 200:return Trueexcept:passreturn False
二、更新爬虫ip池
可以通过定期爬取爬虫ip网站或者购买付费爬虫ip服务来获取新的爬虫ip。可以使用requests库向爬虫ip网站发送请求,获取HTML页面,并使用BeautifulSoup库解析HTML页面,从而获取爬虫ip信息。通过一定的筛选规则,可以将新获取的爬虫ip加入到自有库池中。
import requests
from bs4 import BeautifulSoup
def get_proxies():url = 'http://jshk.com.cn/'headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}response = requests.get(url, headers=headers)soup = BeautifulSoup(response.text, 'html.parser')table = soup.find('table', {'id': 'ip_list'})tr_list = table.find_all('tr')proxies = []for tr in tr_list[1:]:td_list = tr.find_all('td')ip = td_list[1].textport = td_list[2].textprotocol = td_list[5].text.lower()proxy = '{}://{}:{}'.format(protocol, ip, port)proxies.append(proxy)return proxies
三、维护爬虫ip的质量
可以通过一些指标来衡量爬虫ip的质量,比如连接速度、响应时间、访问成功率等。可以定时对爬虫ip进行评估,筛选出质量较好的IP,并从爬虫ip池中删除质量较差的IP。
import requests
from multiprocessing import Pool
from functools import partial
def check_proxy_quality(proxy):try:response = requests.get(url, proxies=proxy, timeout=3)if response.status_code == 200:return True, response.elapsed.total_seconds()except:passreturn False, Nonedef evaluate_proxies(proxies):pool = Pool(processes=8)results = pool.map(partial(check_proxy_quality), proxies)pool.close()pool.join()quality_proxies = []for proxy, result in zip(proxies, results):is_valid, response_time = resultif is_valid:quality_proxies.append((proxy, response_time))return quality_proxies
四、监控爬虫ip的使用情况
对于监控爬虫ip的使用情况,一种比较简单的方法是记录每个爬虫ip的使用次数和成功率,以便及时发现哪些爬虫ip不再可用或者质量较差。
可以使用Python内置的shelve模块,将爬虫ip的使用情况保存在一个本地文件中。shelve模块可以提供类似字典的数据存储方式,方便快捷地读取和写入数据。
import shelve
class ProxyManager:def __init__(self, filename='proxies.db'):self.filename = filenameself.proxies = shelve.open(filename, writeback=True)if not self.proxies.get('used_proxies'):self.proxies['used_proxies'] = {}def mark_as_used(self, proxy):if proxy in self.proxies:self.proxies[proxy]['used_times'] += 1self.proxies[proxy]['success_rate'] = self.proxies[proxy]['success_times'] / self.proxies[proxy]['used_times']else:self.proxies[proxy] = {'used_times': 1, 'success_times': 0, 'success_rate': 0}self.proxies['used_proxies'][proxy] = Truedef mark_as_success(self, proxy):if proxy in self.proxies:self.proxies[proxy]['success_times'] += 1self.proxies[proxy]['success_rate'] = self.proxies[proxy]['success_times'] / self.proxies[proxy]['used_times']else:self.proxies[proxy] = {'used_times': 1, 'success_times': 1, 'success_rate': 1}self.proxies['used_proxies'][proxy] = Truedef is_used(self, proxy):return self.proxies['used_proxies'].get(proxy)def close(self):self.proxies.close()
在使用爬虫ip进行网络请求时,可以先检查该爬虫ip是否已被使用过。如果该爬虫ip已被使用过,则不再使用该爬虫ip。如果该爬虫ip未被使用过,则使用该爬虫ip进行网络请求,并在请求成功或失败后,更新该爬虫ip的使用情况。
def get_page(url, proxy_manager):for i in range(3):proxy = get_proxy(proxy_manager)if proxy:try:response = requests.get(url, proxies={'http': proxy, 'https': proxy}, timeout=3)if response.status_code == 200:proxy_manager.mark_as_success(proxy)return response.textexcept:passproxy_manager.mark_as_used(proxy)return None
def get_proxy(proxy_manager):proxies = list(proxy_manager.proxies.keys())for proxy in proxies:if not proxy_manager.is_used(proxy):return proxyreturn None
需要注意的是,shelve模块的写入操作可能比较耗时,如果爬虫ip池较大,可以考虑每隔一段时间将爬虫ip使用情况保存在本地文件中,以提高性能。同时,如果爬虫ip池中存在较多已失效的爬虫ip,证明这个池子的IP可用率已经极低了,还是会更建议大家伙使用优质厂商提供的爬虫ip。
正常情况下,很多人会说随着经济下行,能有使用的就已经不错了,还谈什么自行车,且不谈免费的爬虫ip的连通性,实际上只要选对爬虫ip,采购的成本也会在我们的承受范围内的。
相关文章:

如何通过筛选高质量爬虫IP提升爬虫效率?
前言 对于做数据抓取的技术员来说,如何稳定高效的爬取数据ip库池起到决定性作用,对于爬虫ip池的维护,可以从以下几个方面入手: 目录 一、验证爬虫ip的可用性二、更新爬虫ip池三、维护爬虫ip的质量四、监控爬虫ip的使用情况 一、验…...

C#中定义数组--字符串及数组操作
C#中定义数组–字符串及数组操作 以前用VB的时候经常使用数组,不过C#用习惯后数组基本上用的不多了。 像用List<>,ArrayList,Dirctionary<,>都比较好用。 一、一维: int[] numbers new int[]{1,2,3,4,5,6}; //不…...
嵌入式就业怎么样?
嵌入式就业怎么样? 现在的IT行业,嵌入式是大热门,下面也要来给大家介绍下学习嵌入式之后的发展以及就业怎么样。 首先是好找工作。嵌入式人才目前是处于供不应求的状态中,据权威统计机构统计在所有软件开发类人才的需求中,对嵌入式工程师的…...
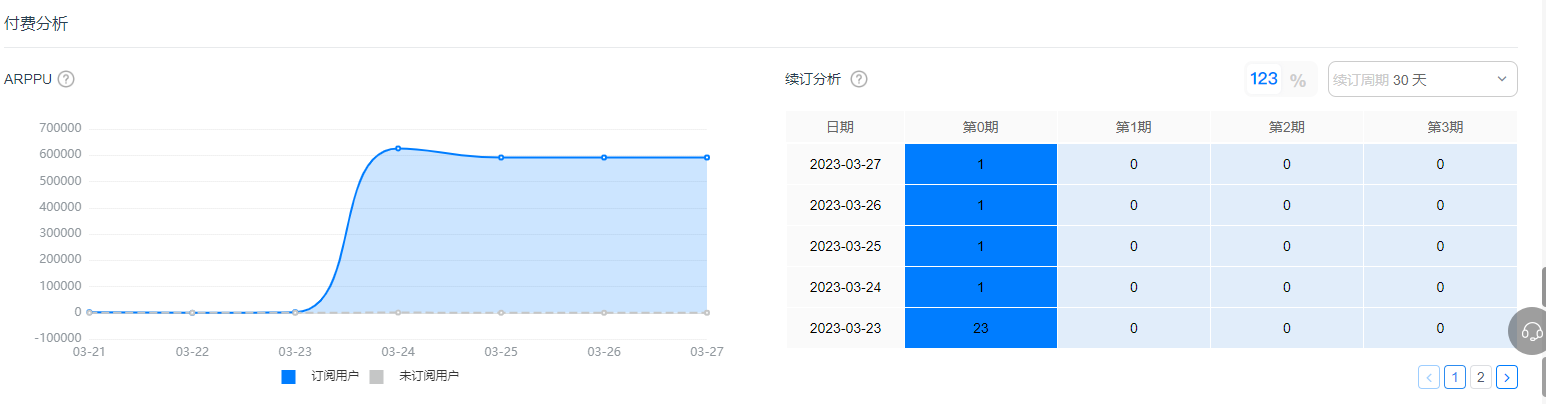
用户订阅付费如何拆解分析?看这篇就够了
会员制的订阅付费在影音娱乐行业中已相当普及,近几年,不少游戏厂商也开始尝试订阅收费模式。在分析具体的用户订阅偏好以及订阅付费模式带来的增长效果时,我们常常会有这些疑问: 如何从用户的整体付费行为中具体拆解订阅付费事件…...

智能合约中如何调用其他智能合约
智能合约是区块链技术中的一项关键功能,它可以让开发者编写代码来自动执行一系列的操作,从而实现各种复杂的业务逻辑。在许多应用场景中,一个智能合约可能需要调用另一个智能合约来完成某些任务。本文将介绍智能合约如何调用其他智能合约&…...

python的多任务处理
在现代计算机系统中,多任务处理是一项重要的技术,可以大幅提高程序的运行效率。Python语言提供了多种多任务处理的方式,本文将介绍其中几种常见的方式,包括多进程、多线程和协程。 多进程 进程是计算机中运行程序的实例…...

Vue收集表单数据学习笔记
收集表单数据 v-model双向数据绑定,收集的是input框的value,单选按钮不存在value,就像代码中的男女选项,即使绑定性别v-model“sex”,控制台依然不能接收性别的值,因为没有value值,,…...
Linux搭建GitLab私有仓库,并内网穿透实现公网访问
文章目录 前言1. 下载Gitlab2. 安装Gitlab3. 启动Gitlab4. 安装cpolar5. 创建隧道配置访问地址6. 固定GitLab访问地址6.1 保留二级子域名6.2 配置二级子域名 7. 测试访问二级子域名 转载自远控源码文章:Linux搭建GitLab私有仓库,并内网穿透实现公网访问 …...

SpringBoot项目防重复提交注解开发
背景 在实际开发过程中,防重复提交的操作很常见。有细分配置针对某一些路径进行拦截,也有基于注解去实现的指定方法拦截的。 分析 实现原理 实现防重复提交,我们很容易想到就是用过滤器或者拦截器来实现。 使用拦截器就是继承HandlerInt…...

从软件哲学角度谈 Amazon SageMaker
如果你喜欢哲学并且你是一个 IT 从业者,那么你很可能对软件哲学感兴趣,你能发现存在于软件领域的哲学之美。本文我们就从软件哲学的角度来了解一下亚马逊云科技的拳头级产品 Amazon SageMaker,有两个出发点:一是 SageMaker 本身设…...
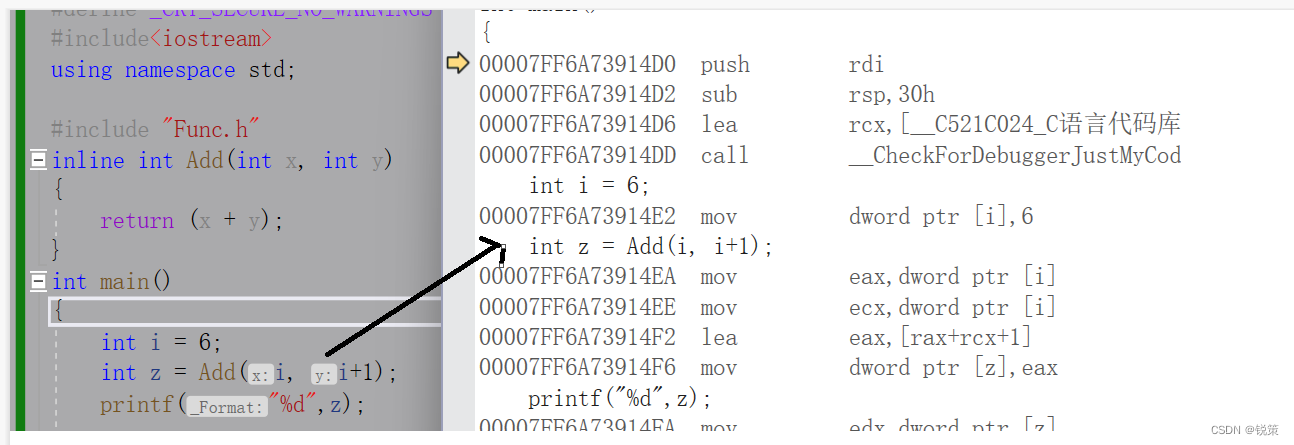
C++内联函数
目录 一、常规函数和内联函数的对比 二、如何使用 三、内联函数的特性 四、内联函数与宏 五、如何查看内联函数 六、【面试题】 前言-----内联函数是C中为程序运行速度所做的一项该进。常规函数和内联函数之间的主要区别不在于编写方式,而在于C编译器如何将他…...

JAVA大师的秘籍:轻松掌握高质量代码之道
如果你想写出高质量的代码,那掌握编写技巧可是必不可少哦!这不仅能让你的代码变得更加易读易维护,还可以让你的应用程序性能更强、稳定性更高!所以,别怕麻烦,多花些时间和心思在代码上,相信你一定能成为优秀的JAVA开发者! 要想让代码易读易维护、性能稳定,得拿出耐心和…...

OpenGL入门教程之 变换
引言 这是一个闪耀的时刻,因为我们即将能生产出令人惊叹的3D效果! 变换 向量和矩阵变换包括太多内容,但由于学过线性代数和GAMES101,因此不在此做过多阐述。仅阐述包括代码的GLM内容。 GLM的使用 (1)GLM…...

ASPICE详细介绍-4.车载项目为什么要符合ASPICE标准?
目录 车载项目为什么要符合ASPICE标准?ASPICE与功能安全的关系、区别?各大车厂对软件体系的要求 车载项目为什么要符合ASPICE标准? ASPICE(Automotive Software Process Improvement and Capability Determination)最…...
一文彻底理解Java 17中的新特性密封类
密封类的作用 在面向对象语言中,我们可以通过继承(extend)来实现类的能力复用、扩展与增强。但有的时候,有些能力我们不希望被继承了去做一些不可预知的扩展。所以,我们需要对继承关系有一些限制的控制手段。而密封类…...
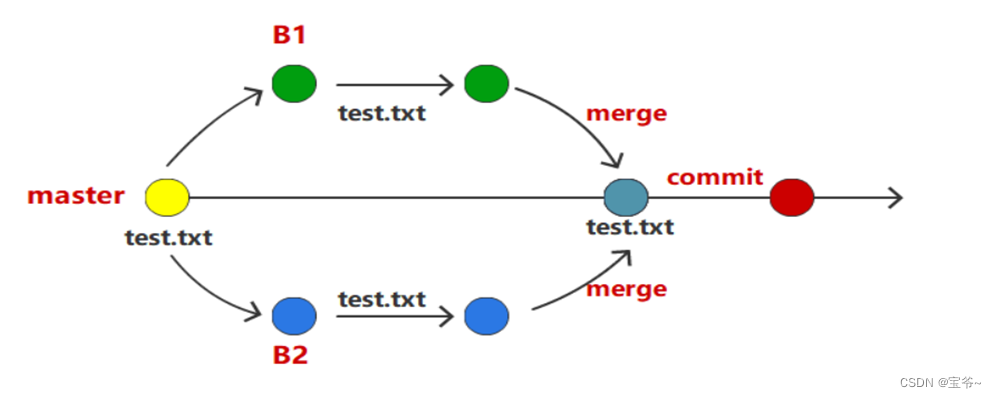
【Git 入门教程】第四节、Git冲突:如何解决版本控制的矛盾
Git是目前最流行的版本控制系统之一,它为团队协作开发提供了方便和高效的方式。然而,在多人同时修改同一个文件时,可能会出现代码冲突(conflict),导致代码无法正确合并。那么,如何解决Git冲突呢…...

c++验证用户输入合法性的示例代码
c验证用户输入合法性的示例代码 本文介绍c验证用户输入合法性,用于检测限定用户输入值。包括:1、限定用户输入为整数(正负整数);2、限定用户输入为正整数;3、限定用户输入为正数(可以含有小数&…...

ctfshow web入门phpcve web311-315
1.web311 通过抓包发现php版本时为PHP/7.1.33dev 漏洞cve2019-11043 远程代码执行漏洞 利用条件: nginx配置了fastcgi_split_path_info 受影响系统: PHP 5.6-7.x,Nginx>0.7.31 下载工具进行利用 需要安装go环境 yum install golang -y …...

gpt.4.0-gpt 国内版
gpt 使用 GPT(Generative Pre-trained Transformer)是一种预训练的语言模型,可用于多种自然语言处理任务,如情感分析、文本分类、文本生成等。下面是使用GPT的一些步骤和建议: 确定任务和数据集:首先&…...
放弃手动测试,快来了解JMeter压测神器的安装和使用吧~~
目录:导读 引言 jmeter的安装 JMeter是干什么的 JMeter都可以做那些测试 JMeter的使用和组件介绍 下面我们进行XML格式的实战练习 jmeter与postman的区别 JSON的插件 另附视频教程资源 引言 你是否曾经为手动测试而苦恼?是不是觉得手动测试太费…...

Seraphine:如何通过智能战绩查询和BP辅助提升英雄联盟竞技体验
Seraphine:如何通过智能战绩查询和BP辅助提升英雄联盟竞技体验 【免费下载链接】Seraphine 英雄联盟战绩查询工具 项目地址: https://gitcode.com/gh_mirrors/se/Seraphine 想象一下这样的场景:你刚刚进入英雄联盟的排位赛BP阶段,屏幕…...

公域卖课佣金高、粉丝留不住?这套私域打法,完课率提升了3倍
公域卖课的两大痛点痛点一:佣金太高,利润被吃掉一大块。相信在公域卖过课的朋友都有体会。平台抽成、分销佣金、投流成本……七七八八算下来,到手的钱可能连一半都不到。你辛辛苦苦打磨的课程,大头却被别人拿走了。这感觉…...

[260520] x-cmd v0.9.5:x install 支持 skill 安装,新增 git ci 命令让 AI 帮你写 commit
[260520] x-cmd v0.9.5:x install 支持 skill 安装,新增 git ci 命令让 AI 帮你写 commit x install 全面升级:支持 skill 安装、前缀语法、三种自动化模式、AI Agent 友好选项x git ci/commit 支持 AI 自动生成 Conventional Commits 提交信…...
)
阿里云ECS新手避坑指南:搞定校园网、安全组和SSH端口映射(附XShell连接测试)
阿里云ECS新手全流程配置手册:从安全组到SSH连接的深度实践 第一次接触云服务器时,那种既兴奋又忐忑的心情我至今记忆犹新。看着控制台里各种陌生的术语和选项,明明按照教程一步步操作却总是卡在连接阶段,这种经历想必不少技术爱好…...
)
免费额度哪家强?ESP32玩家实测八大国产大模型API(含通义千问、Kimi、DeepSeek)
ESP32开发者指南:八大国产大模型API横向评测与实战选型 当ESP32遇上大语言模型,会擦出怎样的火花?在物联网设备上直接运行AI交互功能,已经成为越来越多开发者的新选择。但面对众多国产大模型API,如何选择最适合ESP32项…...

CANN/asc-devkit SIMT数学函数erfinvf
erfinvf 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode.com/ca…...

UE5运行时动态调整游戏视口:解决UI遮挡导致物体位置偏移的实战方案
UE5运行时动态调整游戏视口:解决UI遮挡导致物体位置偏移的实战方案 当你在UE5项目中设计了一个精美的HUD界面,却发现那些半透明的UI元素正在悄悄改变游戏世界的坐标规则——原本应该出现在屏幕中心的角色突然偏离了位置。这不是视觉错觉,而是…...

【从零学Vibe Coding】前言:为什么要写这份教程
前言:为什么要写这份教程 一切从一个画面开始 2025 年,你大概率刷到过这样的画面: 有人对着 AI 说一句"帮我做个记账 App"十几分钟后,页面已经能点、能跳、能保存数据评论区一半人在惊呼"程序员要失业了"另…...

类型转换:隐式、显式与类型提升
在Java开发中,数据类型转换是最基础也最容易被忽略的核心操作——从简单的变量赋值、数字运算,到复杂的方法传参、泛型适配、多态转型、序列化,几乎每一行代码都隐含着类型转换的逻辑。很多同学只停留在“会用”的层面:知道int转l…...

BGA底部填充胶:嵌入式主控板可靠性设计与工艺全解析
1. 项目概述:为什么BGA底部填充胶是嵌入式主控板的“定海神针”?在嵌入式计算机主控板的设计与生产领域,尤其是那些采用高密度、细间距BGA(球栅阵列)封装芯片的板卡上,有一个工艺环节常常被新手工程师忽略&…...