阅读笔记 First Order Motion Model for Image Animation
文章解决的是图片动画的问题。假设有源图片和驱动视频,并且其中的物体是同一类的,文章的方法让源图片中的物体按照驱动视频中物体的动作而动。
文章的方法只需要一个同类物体的视频集,不需要而外的标注。
方法
该方法基于self-supervised策略,主要方法是基于训练视频中的一帧图像和和学习到的动作表示,重建出训练视频。其中,动作表示由动作特定的关键点(motion-specific keypoint)和局部仿射变换(local affine transformations)组成。

框架图如上图所示,由两个部分组成,一个是运动估计模块,一个是图像生成模块。
运动估计模块的目的是估计从驱动视频的一帧 D ∈ R 3 × H × W \mathbf D \in \mathbb R^{3\times H \times W} D∈R3×H×W到源图片 S ∈ R 3 × H × W \mathbf S \in \mathbb R^{3\times H \times W} S∈R3×H×W的稠密运动场(dense motion field)。运动场 T S ← D : R 2 → R 2 \mathcal T_{\mathbf S \leftarrow \mathbf D}: \mathbb R^2 \rightarrow \mathbb R^2 TS←D:R2→R2将 D \mathbf D D中每个像素位置映射到对应的 S \mathbf S S。 T S ← D \mathcal T_{\mathbf S \leftarrow \mathbf D} TS←D也被称为反向光流(backward optical flow)。使用反向光流而不是正向光流,因为可以使用双线性采样以可微分的方式有效地实现后向扭曲。
仿射变换
在齐次坐标上,仿射变换可以用下面的式子表示:
[ y ⃗ 1 ] = [ B b ⃗ 0 , … , 0 1 ] [ x ⃗ 1 ] {\begin{bmatrix}{\vec{y}}\\1\end{bmatrix}}= {\begin{bmatrix}B&{\vec {b}}\ \\0,\ldots ,0&1\end{bmatrix}} {\begin{bmatrix}{\vec {x}}\\1\end{bmatrix}} [y1]=[B0,…,0b 1][x1]因为运算矩阵的最后一行是为了运算补齐的,所以在2维图像上仿射变换的参数由矩阵 A ∈ R 2 × 3 \mathbf A \in \mathbb R^{2 \times 3} A∈R2×3表示。
运动估计模块
粗运动估计
粗运动估计预测关键点处的运动模式。
动作估计模块估计反向光流 T S ← D \mathcal T_{\mathbf S \leftarrow \mathbf D} TS←D。 T S ← D \mathcal T_{\mathbf S \leftarrow \mathbf D} TS←D用在关键点附近的一阶泰勒展开表示。
假设存在一个抽象参考帧 R \mathbf R R。这样,我们需要估计两个变换:从 R \mathbf R R到 S \mathbf S S( T S ← R \mathcal T_{\mathbf S \leftarrow \mathbf R} TS←R)和从 R \mathbf R R到 D \mathbf D D( T D ← R \mathcal T_{\mathbf D \leftarrow \mathbf R} TD←R)。抽象参考帧的好处是可以让我们独立的处理 D \mathbf D D和 S \mathbf S S。
为了描述方便,用 X \mathbf X X表示 S \mathbf S S或者 D \mathbf D D,用 p 1 , ⋯ , p K p_1,\cdots,p_K p1,⋯,pK表示抽象参考帧 R \mathbf R R上的关键点的坐标,用 z z z表示在其他帧上的点的坐标。我们估计在关键点 p 1 , ⋯ , p K p_1,\cdots,p_K p1,⋯,pK周围的 T X ← R \mathcal T_{\mathbf X \leftarrow \mathbf R} TX←R。具体而言,我们考虑 T X ← R \mathcal T_{\mathbf X \leftarrow \mathbf R} TX←R在关键点 p 1 , ⋯ , p K p_1,\cdots,p_K p1,⋯,pK的一阶泰勒展开:
T X ← R ( p ) = T X ← R ( p k ) + ( d T X ← R ( p ) d p ∣ p = p k ) ( p − p k ) + o ( ∥ p − p k ∥ ) \mathcal T_{\mathbf X \leftarrow \mathbf R}(p)=\mathcal T_{\mathbf X \leftarrow \mathbf R}(p_k)+(\frac{d \mathcal T_{\mathbf X \leftarrow \mathbf R}(p)}{dp}|_{p=p_k})(p-p_k)+o(\|p-p_k\|) TX←R(p)=TX←R(pk)+(dpdTX←R(p)∣p=pk)(p−pk)+o(∥p−pk∥)这是可以看做一个仿射变换 A X ← R k ∈ R 2 × 3 \mathbf A^k_{\mathbf X \leftarrow \mathbf R} \in \mathbb R^{2 \times 3} AX←Rk∈R2×3, T X ← R ( p k ) \mathcal T_{\mathbf X \leftarrow \mathbf R}(p_k) TX←R(pk)是平移参数, d T X ← R ( p ) d p ∣ p = p k \frac{d \mathcal T_{\mathbf X \leftarrow \mathbf R}(p)}{dp}|_{p=p_k} dpdTX←R(p)∣p=pk是线性映射的参数。
T X ← R \mathcal T_{\mathbf X \leftarrow \mathbf R} TX←R用其在K个关键点处的值和Jacobian表示。
T X ← R ( p ) ≈ { { T X ← R ( p 1 ) , d T X ← R ( p ) d p ∣ p = p 1 } , ⋯ , { T X ← R ( p K ) , d T X ← R ( p ) d p ∣ p = p K } } \mathcal T_{\mathbf X \leftarrow \mathbf R}(p) \approx \{\{ \mathcal T_{\mathbf X \leftarrow \mathbf R}(p_1),\frac{d \mathcal T_{\mathbf X \leftarrow \mathbf R}(p)}{dp}|_{p=p_1}\}, \cdots,\{ \mathcal T_{\mathbf X \leftarrow \mathbf R}(p_K),\frac{d \mathcal T_{\mathbf X \leftarrow \mathbf R}(p)}{dp}|_{p=p_K}\}\} TX←R(p)≈{{TX←R(p1),dpdTX←R(p)∣p=p1},⋯,{TX←R(pK),dpdTX←R(p)∣p=pK}}
我们假设 T X ← R \mathcal T_{\mathbf X \leftarrow \mathbf R} TX←R在每个关键点的局部是双射。则对于 T S ← D \mathcal T_{\mathbf S \leftarrow \mathbf D} TS←D,我们有
T S ← D = T S ← R ∘ T D ← R − 1 \mathcal T_{\mathbf S \leftarrow \mathbf D}=\mathcal T_{\mathbf S \leftarrow \mathbf R} \circ \mathcal T^{-1}_{\mathbf D \leftarrow \mathbf R} TS←D=TS←R∘TD←R−1用一阶泰勒展开近似有
T S ← D ( z ) ≈ T S ← R ( p k ) + J k ( z − T D ← R ( p k ) ) J k = ( d T S ← R ( p ) d p ∣ p = p k ) ( d T D ← R ( p ) d p ∣ p = p k ) − 1 \mathcal T_{\mathbf S \leftarrow \mathbf D}(z) \approx \mathcal T_{\mathbf S \leftarrow \mathbf R}(p_k) + J_k(z-\mathcal T_{\mathbf D \leftarrow \mathbf R}(p_k))\\ J_k=(\frac{d \mathcal T_{\mathbf S \leftarrow \mathbf R}(p)}{dp}|_{p=p_k})(\frac{d \mathcal T_{\mathbf D \leftarrow \mathbf R}(p)}{dp}|_{p=p_k})^{-1} TS←D(z)≈TS←R(pk)+Jk(z−TD←R(pk))Jk=(dpdTS←R(p)∣p=pk)(dpdTD←R(p)∣p=pk)−1
T S ← R ( p k ) \mathcal T_{\mathbf S \leftarrow \mathbf R}(p_k) TS←R(pk)和 T D ← R ( p k ) \mathcal T_{\mathbf D \leftarrow \mathbf R}(p_k) TD←R(pk)用基于U-Net的关键点预测网络(keypoint predictor network)预测。对每个关键点预测一个heatmap,总共预测K个heatmap。U-Net的decoder最后一层用softmax预测关键点置信图(keypoint confidence map),也就是关键点在每个像素位置的置信度,满足 ∑ z ∈ Z W k ( z ) = 1 \sum_{z \in \mathcal Z} \mathbf W^k(z)=1 ∑z∈ZWk(z)=1,其中 Z \mathcal Z Z表示所有的像素位置。
T S ← R ( p k ) \mathcal T_{\mathbf S \leftarrow \mathbf R}(p_k) TS←R(pk)和 T D ← R ( p k ) \mathcal T_{\mathbf D \leftarrow \mathbf R}(p_k) TD←R(pk)相当于仿射变换中的平移参数,注意这里是两维的(z包含x和y)。平移参数用关键点置信图加权计算:
b k = ∑ z ∈ Z W k ( z ) z b^k = \sum_{z \in \mathcal Z} \mathbf W^k(z)z bk=z∈Z∑Wk(z)z
d T S ← R ( p ) d p ∣ p = p k \frac{d \mathcal T_{\mathbf S \leftarrow \mathbf R}(p)}{dp}|_{p=p_k} dpdTS←R(p)∣p=pk和 d T D ← R ( p ) d p ∣ p = p k \frac{d \mathcal T_{\mathbf D \leftarrow \mathbf R}(p)}{dp}|_{p=p_k} dpdTD←R(p)∣p=pk相当于仿射变换中的线性变换部分,他们作为仿射变换中剩下的4个参数用keypoint predictor network的额外的4个通道估计,每个关键点4个额外的通道。用 P i j k ∈ R H × W P^k_{ij} \in \mathbb R^{H \times W} Pijk∈RH×W表示其中一个通道的估计值,其中 i , j i,j i,j是仿射变换的坐标。线性变换的参数用关键点置信图加权融合:
B k [ i , j ] = ∑ z ∈ Z W k ( z ) P i j k ( z ) \mathbf B^k[i,j] = \sum_{z \in \mathcal Z} \mathbf W^k(z)P^k_{ij}(z) Bk[i,j]=z∈Z∑Wk(z)Pijk(z)
密集运动估计
密集运动估计预测整个图像每个像素点的运动模式 T ^ S ← D \hat{\mathcal T}_{\mathbf S \leftarrow \mathbf D} T^S←D。
我们使用卷积网络从 K K K个关键点处的泰勒展开 T S ← D ( z ) \mathcal T_{\mathbf S \leftarrow \mathbf D}(z) TS←D(z)和源图像帧 S \mathbf S S中估计 T ^ S ← D \hat{\mathcal T}_{\mathbf S \leftarrow \mathbf D} T^S←D。
用关键点处的变换扭曲源图像帧 S \mathbf S S,可以得到 K K K个变换后的图像 S 1 , ⋯ , S K \mathbf S^1, \cdots, \mathbf S^K S1,⋯,SK。另外,考虑额外的图像 S 0 = S \mathbf S^0 = \mathbf S S0=S作为背景。
对每一个关键点计算heatmap H k ( z ) \mathbf H_k(z) Hk(z)表示每个变换在哪发生。
H k ( z ) = e x p ( ( T D ← R ( p k ) − z ) 2 σ ) − e x p ( ( T S ← R ( p k ) − z ) 2 σ ) \mathbf H_k(z) = exp(\frac{(\mathcal T_{\mathbf D \leftarrow \mathbf R}(p_k)-z)^2}{\sigma}) - exp(\frac{(\mathcal T_{\mathbf S \leftarrow \mathbf R}(p_k)-z)^2}{\sigma}) Hk(z)=exp(σ(TD←R(pk)−z)2)−exp(σ(TS←R(pk)−z)2)
将 H k \mathbf H_k Hk和 S 0 , ⋯ , S K \mathbf S^0, \cdots, \mathbf S^K S0,⋯,SK拼接输入基于U-Net的稠密运动网络(dense motion network)。dense motion network估计 K + 1 K+1 K+1个掩码 M k , k = 0 , ⋯ , K \mathbf M_k, k = 0, \cdots, K Mk,k=0,⋯,K 表示每个位置用哪个局部变换,满足 ∑ k = 0 K M k ( z ) = 1 \sum_{k=0}^K \mathbf M^k(z)=1 ∑k=0KMk(z)=1。最后的密集运动场表示为:
T ^ S ← D ( z ) = M 0 z + ∑ k = 1 K M k ( T S ← R ( p k ) + J k ( z − T D ← R ( p k ) ) ) \hat{\mathcal T}_{\mathbf S \leftarrow \mathbf D}(z) = \mathbf M_0z + \sum_{k=1}^K \mathbf M_k(\mathcal T_{\mathbf S \leftarrow \mathbf R}(p_k) + J_k(z-\mathcal T_{\mathbf D \leftarrow \mathbf R}(p_k))) T^S←D(z)=M0z+k=1∑KMk(TS←R(pk)+Jk(z−TD←R(pk)))
表示为矩阵坐标变换有:
O ( z ) = M 0 ( z ) z + ∑ k = 1 K M k ( z ) A S ← D k [ z 1 ] \mathbf O(z) = \mathbf M^0(z)z + \sum_{k=1}^K \mathbf M^k(z) \mathbf A^k_{\mathbf S \leftarrow \mathbf D} {\begin{bmatrix}{z}\\1\end{bmatrix}} O(z)=M0(z)z+k=1∑KMk(z)AS←Dk[z1]
图像生成模块
1.根据上面预测的 T ^ S ← D \hat{\mathcal T}_{\mathbf S \leftarrow \mathbf D} T^S←D对 S S S经过两个下采样卷积的特征图(feature map ) ξ ∈ R H ′ × W ′ \xi \in \mathbb R^{H'\times W'} ξ∈RH′×W′使用warp操作。
2.在 S S S中存在遮挡的时候, D ′ D' D′并不能完全通过warp源图像获得,而是需要inpaint。所以,预测一个遮挡图(occlusion map) O ^ S ← D ∈ [ 0 , 1 ] H ′ × W ′ \hat{\mathcal O}_{\mathbf S \leftarrow \mathbf D} \in [0,1]^{H'\times W'} O^S←D∈[0,1]H′×W′,表示源图像需要被inpaint的区域。occlusion map通过在dense motion network后添加一层来预测。
经过转换的feature map可以表示为:
ξ ′ = O ^ S ← D ⊙ f w ( ξ , T ^ S ← D ) \xi' = \hat{\mathcal O}_{\mathbf S \leftarrow \mathbf D} \odot f_w(\xi, \hat{\mathcal T}_{\mathbf S \leftarrow \mathbf D}) ξ′=O^S←D⊙fw(ξ,T^S←D) f w f_w fw表示反向变形(back-warping)操作。经过转换的feature map输入到图像生成模块的后面层处理,最后生成图像。
训练
训练的损失由多项组成。首先是基于perceptual loss的reconstruction loss。该loss用预训练的VGG-19网络作为特征提取器,对比重建帧和驱动视频的真实帧的特征差异。
另外考虑到关键点的学习是无标签的,这会导致不稳定的表现,引入Equivariance constraint用在无监督关键点的学习中。假设图片 X X X经过过一个已知的变换 T X ← Y \mathcal T_{\mathbf X \leftarrow \mathbf Y} TX←Y,得到 Y Y Y。Equivariance constraint要求:
T X ← R ≡ T X ← Y ∘ T Y ← R \mathcal T_{\mathbf X \leftarrow \mathbf R} \equiv \mathcal T_{\mathbf X \leftarrow \mathbf Y} \circ \mathcal T_{\mathbf Y \leftarrow \mathbf R} TX←R≡TX←Y∘TY←R通过对两边进行一阶泰勒展开有,并使用L1 loss分别约束关键点处的值和Jacobian。
参考资料
《First Order Motion Model for Image Animation》
《Motion Representations for Articulated Animation》
相关文章:
阅读笔记 First Order Motion Model for Image Animation
文章解决的是图片动画的问题。假设有源图片和驱动视频,并且其中的物体是同一类的,文章的方法让源图片中的物体按照驱动视频中物体的动作而动。 文章的方法只需要一个同类物体的视频集,不需要而外的标注。 方法 该方法基于self-supervised策…...
【计算机图形学】课堂习题汇总
在直线的光栅化算法中,如果不考虑最大位移方向则可能得到怎样的直线? A:斜率为1的线 B:总是垂直的 C:离散的点,无法构成直线 D:总是水平的 在直线的改进的Bresenham算法中,每当误…...

国外导师对博士后申请简历的几点建议
正所谓“工欲善其事,必先利其器”,想要申请国外的博士后职位,就要准备好相应的申请文书材料。如果说Cover Letter是职位的窍门砖,那么申请者的简历就是争取职位的决定性筹码。 相信大家已经看过许多简历的模版了,但是…...

【五一创作】Scratch资料袋
Scratch软件是免费的、免费的、免费的。任何需要花钱才能下载Scratch软件的全是骗子。 1、什么是Scratch Scratch是麻省理工学院的“终身幼儿园团队”开发的一种图形化编程工具。是面向青少年的一款模块化,积木化、可视化的编程语言。 什么是模块化、积木化&…...
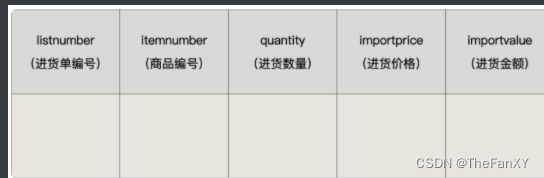
数据库基础篇 《17.触发器》
数据库基础篇 《17.触发器》 在实际开发中,我们经常会遇到这样的情况:有 2 个或者多个相互关联的表,如商品信息和库存信息分别存放在 2 个不同的数据表中,我们在添加一条新商品记录的时候,为了保证数据的完整性&#…...

03 - 大学生如何使用GPT
大学生如何使用GPT提高学习效率 一、引言 在当今的高速发展的信息时代,大学生面临着越来越多的学习挑战。作为一种先进的人工智能技术,GPT为大学生提供了一种强大的学习工具。本文将介绍大学生在不同场景中如何使用GPT来提高学习效率,并给出…...

【P1】Jmeter 准备工作
文章目录 一、Jmeter 介绍1.1、Jmeter 有什么样功能1.2、Jmeter 与 LoadRunner 比较1.3、常用性能测试工具1.4、性能测试工具如何选型1.5、学习 Jmeter 对 Java 编程的要求 二、Jmeter 软件安装2.1、官网介绍2.2、JDK 安装及环境配置2.3、Jmeter 三种模式2.4、主要配置介绍2.4.…...
字节的面试,你能扛住几道?
C , Python 哪一个更快? 读者答:这个我不知道从哪方面说,就是 C 的话,它其实能够提供开发者非常多的权限,就是说它能涉及到一些操作系统级别的一些操作,速度应该挺快。然后 Python 实现功能还…...
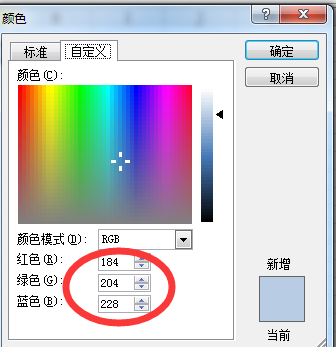
NOPI用法之自定义单元格背景色(3)
NPOI针对office2003使用HSSFWorkbook,对于offce2007及以上使用XSSFWorkbook;今天我以HSSFWorkbook自定义颜色为例说明,Office2007的未研究呢 在NPOI中默认的颜色类是HSSFColor,它内置的颜色有几十种供我们选择,如果不…...
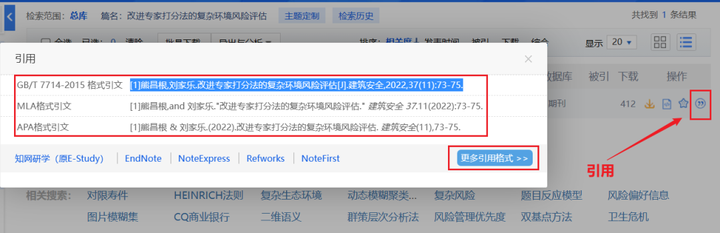
数据分析中常见标准的参考文献
做数据分析过程中,有些分析法方法的标准随便一搜就能找到,不管是口口相传还是默认,大家都按那样的标准做了。日常分析不细究出处还可以,但是正式的学术论文你需要为你写下的每一句话负责,每一个判断标准都应该有参考文…...
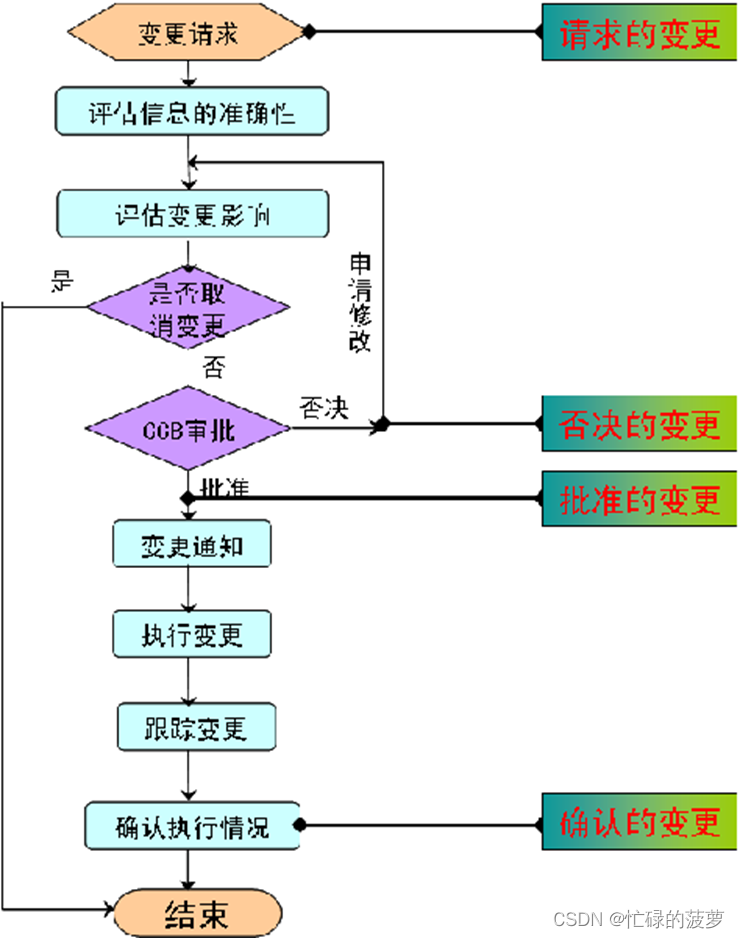
辨析 变更请求、批准的变更请求、实施批准的变更请求
变更请求、批准的变更请求、实施批准的变更请求辨析 辨析各种变更请求,不服来辨。 变更请求 定义:对正规受控的文件或计划(范围、进度、成本、政策、过程、计划或程序)等的变更,以反映修改或增加的意见或内容 根据变更请求的工作内容可将变…...

leetcode 561. 数组拆分
题目描述解题思路执行结果 leetcode 561. 数组拆分 题目描述 数组拆分 给定长度为 2n 的整数数组 nums ,你的任务是将这些数分成 n 对, 例如 (a1, b1), (a2, b2), ..., (an, bn) ,使得从 1 到 n 的 min(ai, bi) 总和最大。 返回该 最大总和 。 示例 1&am…...

AviatorScript
AviatorScript 是一门高性能、轻量级寄宿于 JVM (包括 Android 平台)之上的脚本语言 特性介绍 支持数字、字符串、正则表达式、布尔值、正则表达式等基本类型,完整支持所有 Java 运算符及优先级等。函数是一等公民,支持闭包和函…...
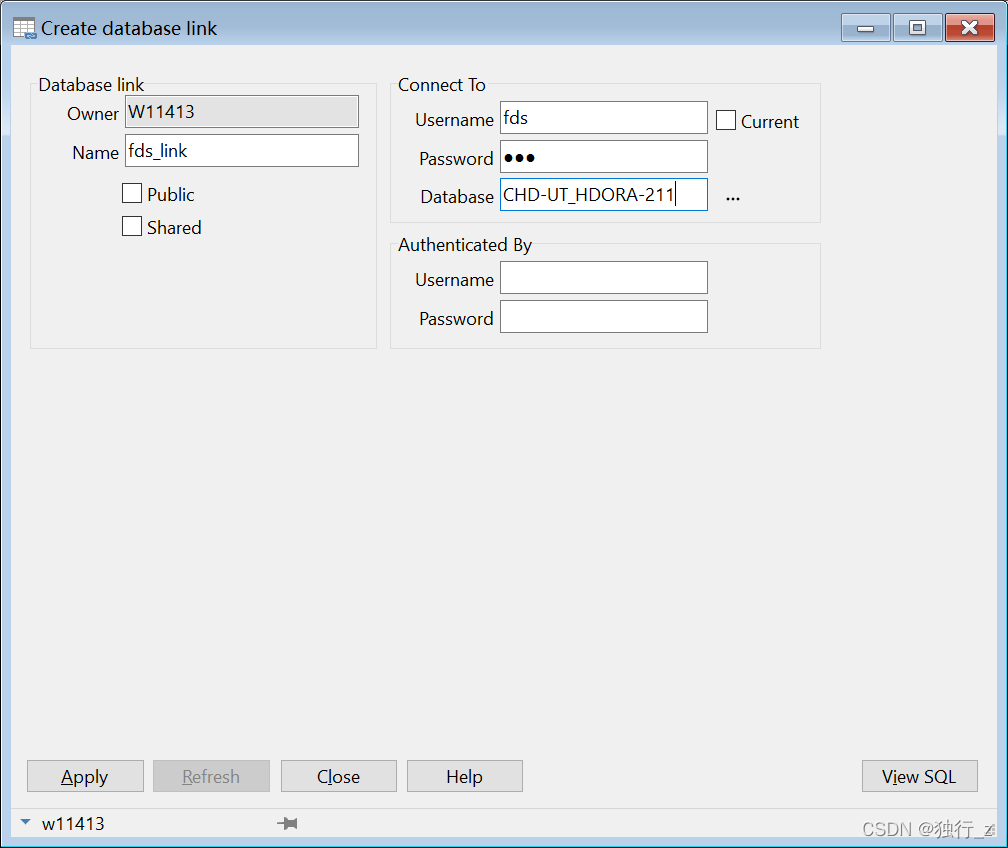
Oracle跨服务器取数——DBlink 初级使用
前言 一句话解释DBlink是干啥用的 实现跨库访问的可能性. 通过DBlink我们可以在A数据库访问到B数据库中的所有信息,例如我们在加工FDS层表时需要访问ODS层的表,这是就需要跨库访问 一、DBlink的分类 private:用户级别,只有创建该dblink的用户才可以使…...
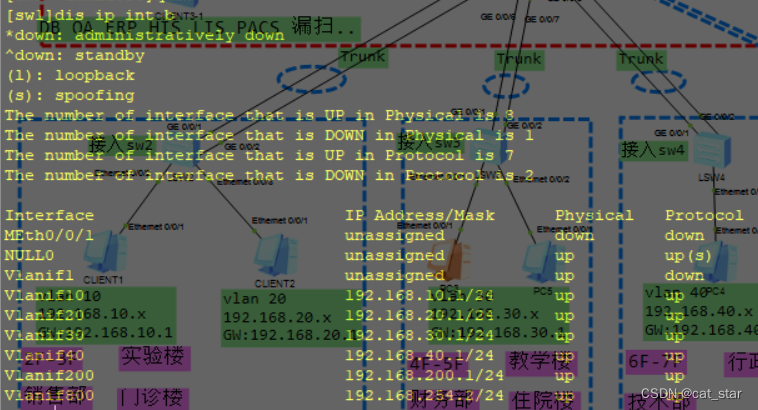
200人 500人 园区网设计
实验要求: ① 设置合理的STP优先级、边缘端口、Eth-trunk ② 企业内网划分多个vlan ,减少广播域大小,提高网络稳定性 ③ 所有设备,在任何位置都可以telnet远程管理 ④ 出口配置NAT ⑤ 所有用户均为自动获取ip地址 ⑥ 在企业…...
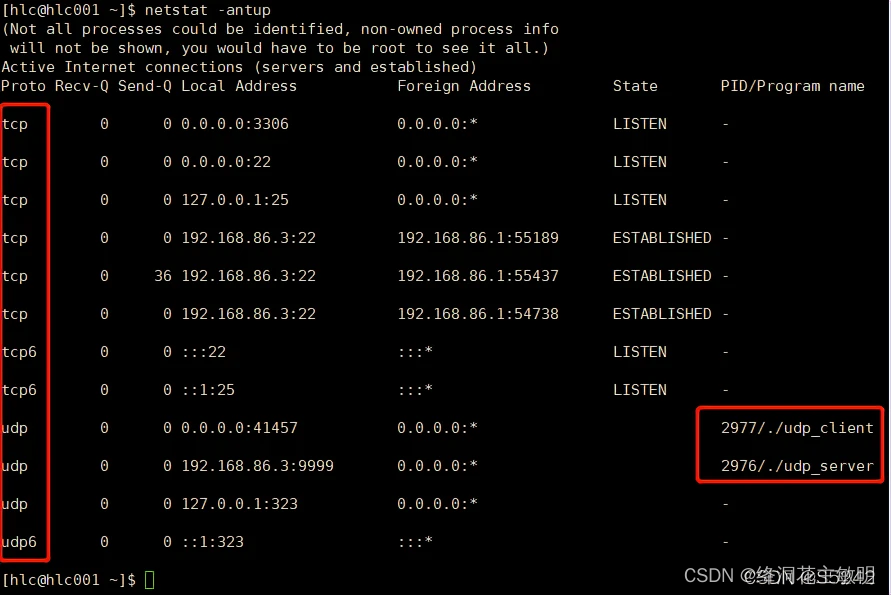
netstat命令解析
一、linux系统中netstat命令的帮助信息 └──╼ $netstat -h usage: netstat [-vWeenNcCF] [<Af>] -r netstat {-V|--version|-h|--help}netstat [-vWnNcaeol] [<Socket> ...]netstat { [-vWeenNac] -i | [-cnNe] -M | -s [-6tuw] }-r, --route …...

API接口的自我阐述
API(Application Programming Interface),翻译为应用程序接口,是一套定义程序之间如何通讯的接口。API可以实现软件的可重用性、可维护性和互操作性,同时也可以提升软件的性能和安全性。API接口是一个软件系统中的重要…...

Day32内部类
内部类 内部类就是在一个类中定义一个类,(在A类中定义一个B类,B类就被称为内部类) 格式:public class 类名{ 修饰符 class 类名{} } 如:public class Outer{ public class Inner {} } //内部类可以访问外部…...
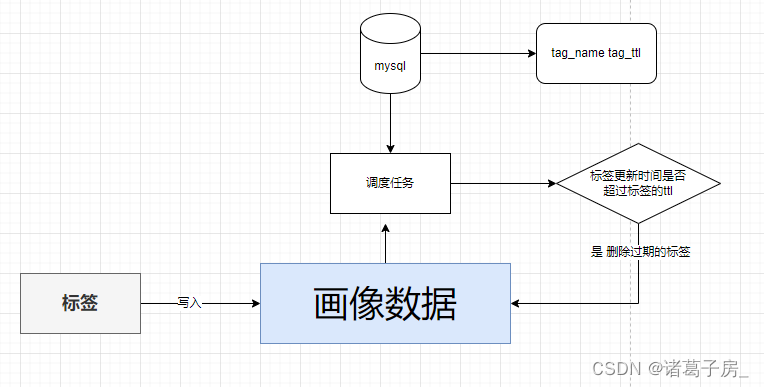
用户画像系列——HBase 在画像标签过期策略中的应用
一、背景 前面系列文章介绍了用户画像的概念、用户画像的标签加工、用户画像的应用。本篇文章主要介绍一些画像的技术细节,让大家更加详细的了解画像数据存储和处理的逻辑 举个现实中的例子: 例子1:因为疫情原因,上线一个平台(…...
时下热门话题:ChatGPT能否取代人类?
时下热门话题:ChatGPT能否取代人类? 2022年11月底,人工智能对话聊天机器人ChatGPT推出,迅速在社交媒体上走红,短短5天,注册用户数就超过100万。2023年1月末,ChatGPT的月活用户已突破1亿&#x…...

实测测评|零注册AI PDF翻译工具:保留排版\+OCR无损翻译,替代DeepL/谷歌翻译
在日常开发、学术科研、外文文献研读场景中,PDF翻译一直是高频刚需痛点。市面上主流的翻译工具普遍存在排版错乱、OCR收费、文件大小受限、强制登录注册等问题,尤其是学术论文、带表格/公式的技术手册、扫描版外文资料,翻译后的可用性极差。 …...

EPM900编程器HEX文件烧录指南与技巧
1. EPM900编程器与HEX文件烧录概述 EPM900是Keil公司推出的一款LPC系列微控制器仿真编程器,主要用于NXP LPC系列ARM芯片的调试与程序烧录。在实际工程开发中,我们经常需要将编译生成的HEX文件直接烧录到目标芯片中,而EPM900恰好支持这一功能。…...

Claude Code + OpenCode + OpenSpec 规范驱动开发实战:AI 驱动智能客服管理系统开发
当 AI 编程从“凭感觉聊天”升级为“按规范执行的流水线” 一、引言:AI 编程的“效率悖论” 2024 年 Google DORA 报告揭示了一个令人困惑的数据:AI 编码助手采用率每提升 25%,软件交付稳定性反而下降 7.2%。主观上开发者觉得用 AI 写代码速…...

从理论到实践:用Magma解锁代数计算新维度
1. 为什么你需要Magma这个代数计算神器 第一次接触Magma是在研究生时期,当时我需要计算一个椭圆曲线上的有理点。用Matlab折腾了整整一周毫无进展,导师随手扔给我一个Magma代码示例,三行命令就解决了问题。那一刻我才明白,专业的事…...
方案:四横五纵框架 、元模型+视图 、业务、应用、数据、技术四大架构)
企业信息化架构(业务架构、应用架构、数据架构、技术架构)方案:四横五纵框架 、元模型+视图 、业务、应用、数据、技术四大架构
该方案提出了企业信息化架构的“四横五纵”框架,涵盖业务、应用、数据、技术四大架构及架构管控,通过元模型定义元素关系,以多层级视图实现从战略到实施的可视化与落地,支撑企业架构全生命周期管理。 四横五纵框架清晰划分了企业架…...

城市生活垃圾焚烧过程参数的智能自主设定方法【附程序】
✨ 长期致力于城市生活垃圾、焚烧过程、智能自主、参数设定、设定方法软件研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)基于学习型伪度量方法的焚烧…...

如何用Univer在3小时内构建企业级电子表格应用?5个实战技巧分享
如何用Univer在3小时内构建企业级电子表格应用?5个实战技巧分享 【免费下载链接】univer Build AI-native spreadsheets. Univer is a full-stack framework for creating and editing spreadsheets on both web and server. With Univer Platform, Univer Spreadsh…...
)
告别PCL!用Qt+QGLWidget手把手教你打造自己的3D点云查看器(附完整源码)
轻量级3D点云可视化:基于Qt与OpenGL的高效实现方案 在工业测量、自动驾驶和三维重建等领域,点云数据的可视化一直是开发者面临的挑战。传统方案如PCL虽然功能强大,但其庞大的体积和复杂的依赖链往往让项目变得臃肿。本文将展示如何利用Qt的QG…...

枚举进阶:从常量集合到业务逻辑承载者的实战扩展技巧
1. 项目概述:从“能用”到“好用”的枚举进阶之路在软件开发中,枚举(Enum)是我们再熟悉不过的基础工具了。它把一组有限的、具名的常量组织在一起,让代码意图更清晰,避免“魔法数字”满天飞。但不知道你有没…...

红外图像/红外遥感图像/可见光红外图像对 近红外和可见光成对图像 生成对抗网络的风格迁移,或者图像融合/图像生成/图像转换 可见光遥感生成红外遥感图像,37500对图像数据
红外图像/红外遥感图像/可见光红外图像对 近红外和可见光成对图像 生成对抗网络的风格迁移,或者图像融合/图像生成/图像转换 可见光遥感生成红外遥感图像,37500对图像数据 文章目录**数据集描述:**🧾 项目背景🧰 一、环…...