Golang每日一练(leetDay0047)

目录
138. 复制带随机指针的链表 Copy List with Random-pointer 🌟🌟
139. 单词拆分 Word Break 🌟🌟
140. 单词拆分 II Word Break II 🌟🌟🌟
🌟 每日一练刷题专栏 🌟
Golang每日一练 专栏
Python每日一练 专栏
C/C++每日一练 专栏
Java每日一练 专栏
138. 复制带随机指针的链表 Copy List with Random-pointer
给你一个长度为 n 的链表,每个节点包含一个额外增加的随机指针 random ,该指针可以指向链表中的任何节点或空节点。
构造这个链表的 深拷贝。 深拷贝应该正好由 n 个 全新 节点组成,其中每个新节点的值都设为其对应的原节点的值。新节点的 next 指针和 random 指针也都应指向复制链表中的新节点,并使原链表和复制链表中的这些指针能够表示相同的链表状态。复制链表中的指针都不应指向原链表中的节点 。
例如,如果原链表中有 X 和 Y 两个节点,其中 X.random --> Y 。那么在复制链表中对应的两个节点 x 和 y ,同样有 x.random --> y 。
返回复制链表的头节点。
用一个由 n 个节点组成的链表来表示输入/输出中的链表。每个节点用一个 [val,random_index] 表示:
val:一个表示Node.val的整数。random_index:随机指针指向的节点索引(范围从0到n-1);如果不指向任何节点,则为null。
你的代码 只 接受原链表的头节点 head 作为传入参数。
示例 1:
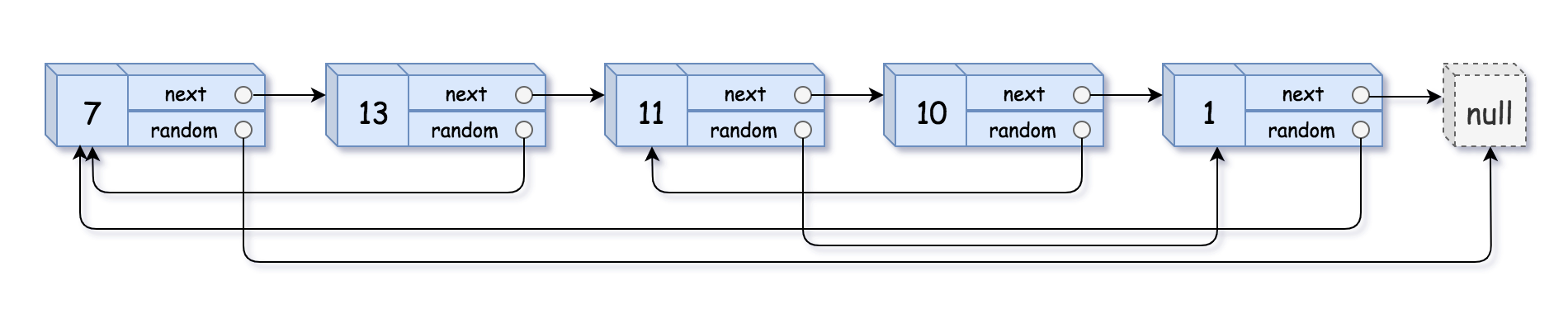
输入:head = [[7,null],[13,0],[11,4],[10,2],[1,0]] 输出:[[7,null],[13,0],[11,4],[10,2],[1,0]]
示例 2:

输入:head = [[1,1],[2,1]] 输出:[[1,1],[2,1]]
示例 3:

输入:head = [[3,null],[3,0],[3,null]] 输出:[[3,null],[3,0],[3,null]]
提示:
0 <= n <= 1000-10^4 <= Node.val <= 10^4Node.random为null或指向链表中的节点。
代码1: 直接在节点结构里增加Index属性
package mainimport "fmt"const null = -1 << 31type Node struct {Val intNext *NodeRandom *NodeIndex int
}func createNode(val int) *Node {return &Node{Val: val,Next: nil,Random: nil,}
}func buildRandomList(nums [][]int) *Node {if len(nums) == 0 {return nil}nodes := make([]*Node, len(nums))for i := 0; i < len(nums); i++ {nodes[i] = &Node{Val: nums[i][0], Index: i}}for i := 0; i < len(nums); i++ {if nums[i][1] != null {nodes[i].Random = nodes[nums[i][1]]}if i < len(nums)-1 {nodes[i].Next = nodes[i+1]}}return nodes[0]
}func traverseList(head *Node) {if head == nil {return}visited := make(map[*Node]bool)cur := headfmt.Print("[")for cur != nil {fmt.Print("[")fmt.Printf("%d,", cur.Val)if cur.Random != nil {fmt.Printf("%d", cur.Random.Index)} else {fmt.Print("null")}fmt.Print("]")visited[cur] = trueif cur.Next != nil && !visited[cur.Next] {fmt.Print(",")cur = cur.Next} else {break}}fmt.Println("]")
}func copyRandomList(head *Node) *Node {if head == nil {return nil}cur := headfor cur != nil {copy := &Node{cur.Val, cur.Next, nil, cur.Index}cur.Next = copycur = copy.Next}cur = headfor cur != nil {if cur.Random != nil {cur.Next.Random = cur.Random.Next}cur = cur.Next.Next}newHead := head.Nextcur = headfor cur != nil {copy := cur.Nextcur.Next = copy.Nextif copy.Next != nil {copy.Next = copy.Next.Next}cur = cur.Next}return newHead
}func copyRandomList2(head *Node) *Node {if head == nil {return nil}m := make(map[*Node]*Node)cur := headfor cur != nil {m[cur] = &Node{cur.Val, nil, nil, cur.Index}cur = cur.Next}cur = headfor cur != nil {m[cur].Next = m[cur.Next]m[cur].Random = m[cur.Random]cur = cur.Next}return m[head]
}func main() {nodes := [][]int{{7, null}, {13, 0}, {11, 4}, {10, 2}, {1, 0}}head := buildRandomList(nodes)traverseList(head)head = copyRandomList(head)traverseList(head)nodes = [][]int{{1, 1}, {2, 1}}head = buildRandomList(nodes)traverseList(head)head = copyRandomList(head)traverseList(head)nodes = [][]int{{3, null}, {3, 0}, {3, null}}head = buildRandomList(nodes)traverseList(head)head = copyRandomList(head)traverseList(head)
}
代码2: 增加getIndex()函数获取Index索引号
func getIndex(node *Node, head *Node) int
package mainimport ("fmt""strings"
)const null = -1 << 31type Node struct {Val intNext *NodeRandom *Node
}func createNode(val int) *Node {return &Node{Val: val,Next: nil,Random: nil,}
}func buildRandomList(nums [][]int) *Node {if len(nums) == 0 {return nil}nodes := make([]*Node, len(nums))for i := 0; i < len(nums); i++ {nodes[i] = &Node{Val: nums[i][0]}}for i := 0; i < len(nums); i++ {if nums[i][1] != null {nodes[i].Random = nodes[nums[i][1]]}if i < len(nums)-1 {nodes[i].Next = nodes[i+1]}}return nodes[0]
}func traverseList(head *Node) [][]int {if head == nil {return nil}visited := make(map[*Node]bool)cur := headres := make([][]int, 0)for cur != nil {visited[cur] = truerandomIndex := nullif cur.Random != nil {randomIndex = getIndex(cur.Random, head)}res = append(res, []int{cur.Val, randomIndex})if cur.Next != nil && !visited[cur.Next] {cur = cur.Next} else {break}}return res
}func getIndex(node *Node, head *Node) int {index := 0cur := headfor cur != node {index++cur = cur.Next}return index
}func copyRandomList(head *Node) *Node {if head == nil {return nil}cur := headfor cur != nil {copy := &Node{cur.Val, cur.Next, nil}cur.Next = copycur = copy.Next}cur = headfor cur != nil {if cur.Random != nil {cur.Next.Random = cur.Random.Next}cur = cur.Next.Next}newHead := head.Nextcur = headfor cur != nil {copy := cur.Nextcur.Next = copy.Nextif copy.Next != nil {copy.Next = copy.Next.Next}cur = cur.Next}return newHead
}func copyRandomList2(head *Node) *Node {if head == nil {return nil}m := make(map[*Node]*Node)cur := headfor cur != nil {m[cur] = &Node{cur.Val, nil, nil}cur = cur.Next}cur = headfor cur != nil {m[cur].Next = m[cur.Next]m[cur].Random = m[cur.Random]cur = cur.Next}return m[head]
}func Array2DToString(array [][]int) string {if len(array) == 0 {return "[]"}arr2str := func(arr []int) string {res := "["for i := 0; i < len(arr); i++ {if arr[i] == null {res += "null"} else {res += fmt.Sprint(arr[i])}if i != len(arr)-1 {res += ","}}return res + "]"}res := make([]string, len(array))for i, arr := range array {res[i] = arr2str(arr)}return strings.Join(strings.Fields(fmt.Sprint(res)), ",")
}func main() {nodes := [][]int{{7, null}, {13, 0}, {11, 4}, {10, 2}, {1, 0}}head := buildRandomList(nodes)fmt.Println(Array2DToString(traverseList(head)))head = copyRandomList(head)fmt.Println(Array2DToString(traverseList(head)))nodes = [][]int{{1, 1}, {2, 1}}head = buildRandomList(nodes)fmt.Println(Array2DToString(traverseList(head)))head = copyRandomList(head)fmt.Println(Array2DToString(traverseList(head)))nodes = [][]int{{3, null}, {3, 0}, {3, null}}head = buildRandomList(nodes)fmt.Println(Array2DToString(traverseList(head)))head = copyRandomList(head)fmt.Println(Array2DToString(traverseList(head)))
}
输出:
[[7,null],[13,0],[11,4],[10,2],[1,0]]
[[7,null],[13,0],[11,4],[10,2],[1,0]]
[[1,1],[2,1]]
[[1,1],[2,1]]
[[3,null],[3,0],[3,null]]
[[3,null],[3,0],[3,null]]
139. 单词拆分 Word Break
给你一个字符串 s 和一个字符串列表 wordDict 作为字典。请你判断是否可以利用字典中出现的单词拼接出 s 。
注意:不要求字典中出现的单词全部都使用,并且字典中的单词可以重复使用。
示例 1:
输入: s = "leetcode", wordDict = ["leet", "code"] 输出: true 解释: 返回 true 因为 "leetcode" 可以由 "leet" 和 "code" 拼接成。
示例 2:
输入: s = "applepenapple", wordDict = ["apple", "pen"] 输出: true 解释: 返回 true 因为 "applepenapple" 可以由 "apple" "pen" "apple" 拼接成。注意,你可以重复使用字典中的单词。
示例 3:
输入: s = "catsandog", wordDict = ["cats", "dog", "sand", "and", "cat"] 输出: false
提示:
1 <= s.length <= 3001 <= wordDict.length <= 10001 <= wordDict[i].length <= 20s和wordDict[i]仅有小写英文字母组成wordDict中的所有字符串 互不相同
代码1: 暴力枚举
package mainimport ("fmt"
)func wordBreak(s string, wordDict []string) bool {return helper(s, wordDict)
}func helper(s string, wordDict []string) bool {if s == "" {return true}for i := 1; i <= len(s); i++ {if contains(wordDict, s[:i]) && helper(s[i:], wordDict) {return true}}return false
}func contains(wordDict []string, s string) bool {for _, word := range wordDict {if word == s {return true}}return false
}func main() {s := "leetcode"wordDict := []string{"leet", "code"}fmt.Println(wordBreak(s, wordDict))s = "applepenapple"wordDict = []string{"apple", "pen"}fmt.Println(wordBreak(s, wordDict))s = "catsandog"wordDict = []string{"cats", "dog", "sand", "and", "cat"}fmt.Println(wordBreak(s, wordDict))
}
代码2: 记忆化搜索
package mainimport ("fmt"
)func wordBreak(s string, wordDict []string) bool {memo := make([]int, len(s))for i := range memo {memo[i] = -1}return helper(s, wordDict, memo)
}func helper(s string, wordDict []string, memo []int) bool {if s == "" {return true}if memo[len(s)-1] != -1 {return memo[len(s)-1] == 1}for i := 1; i <= len(s); i++ {if contains(wordDict, s[:i]) && helper(s[i:], wordDict, memo) {memo[len(s)-1] = 1return true}}memo[len(s)-1] = 0return false
}func contains(wordDict []string, s string) bool {for _, word := range wordDict {if word == s {return true}}return false
}func main() {s := "leetcode"wordDict := []string{"leet", "code"}fmt.Println(wordBreak(s, wordDict))s = "applepenapple"wordDict = []string{"apple", "pen"}fmt.Println(wordBreak(s, wordDict))s = "catsandog"wordDict = []string{"cats", "dog", "sand", "and", "cat"}fmt.Println(wordBreak(s, wordDict))
}
代码3: 动态规划
package mainimport ("fmt"
)func wordBreak(s string, wordDict []string) bool {n := len(s)dp := make([]bool, n+1)dp[0] = truefor i := 1; i <= n; i++ {for j := 0; j < i; j++ {if dp[j] && contains(wordDict, s[j:i]) {dp[i] = truebreak}}}return dp[n]
}func contains(wordDict []string, s string) bool {for _, word := range wordDict {if word == s {return true}}return false
}func main() {s := "leetcode"wordDict := []string{"leet", "code"}fmt.Println(wordBreak(s, wordDict))s = "applepenapple"wordDict = []string{"apple", "pen"}fmt.Println(wordBreak(s, wordDict))s = "catsandog"wordDict = []string{"cats", "dog", "sand", "and", "cat"}fmt.Println(wordBreak(s, wordDict))
}
输出:
true
true
false
140. 单词拆分 II Word Break II
给定一个字符串 s 和一个字符串字典 wordDict ,在字符串 s 中增加空格来构建一个句子,使得句子中所有的单词都在词典中。以任意顺序 返回所有这些可能的句子。
注意:词典中的同一个单词可能在分段中被重复使用多次。
示例 1:
输入:s = "catsanddog", wordDict = ["cat","cats","and","sand","dog"] 输出:["cats and dog","cat sand dog"]
示例 2:
输入:s = "pineapplepenapple", wordDict = ["apple","pen","applepen","pine","pineapple"] 输出:["pine apple pen apple","pineapple pen apple","pine applepen apple"] 解释: 注意你可以重复使用字典中的单词。
示例 3:
输入:s = "catsandog", wordDict = ["cats","dog","sand","and","cat"] 输出:[]
提示:
1 <= s.length <= 201 <= wordDict.length <= 10001 <= wordDict[i].length <= 10s和wordDict[i]仅有小写英文字母组成wordDict中所有字符串都 不同
代码1: 回溯法
package mainimport ("fmt""strings"
)func wordBreak(s string, wordDict []string) []string {// 构建字典dict := make(map[string]bool)for _, word := range wordDict {dict[word] = true}// 回溯函数var res []stringvar backtrack func(start int, path []string)backtrack = func(start int, path []string) {if start == len(s) {res = append(res, strings.Join(path, " "))return}for i := start + 1; i <= len(s); i++ {if dict[s[start:i]] {path = append(path, s[start:i])backtrack(i, path)path = path[:len(path)-1]}}}backtrack(0, []string{})return res
}func ArrayToString(arr []string) string {res := "[\""for i := 0; i < len(arr); i++ {res += arr[i]if i != len(arr)-1 {res += "\",\""}}res += "\"]"if res == "[\"\"]" {res = "[]"}return res
}func main() {s := "catsanddog"wordDict := []string{"cat", "cats", "and", "sand", "dog"}fmt.Println(ArrayToString(wordBreak(s, wordDict)))s = "pineapplepenapple"wordDict = []string{"apple", "pen", "applepen", "pine", "pineapple"}fmt.Println(ArrayToString(wordBreak(s, wordDict)))s = "catsandog"wordDict = []string{"cats", "dog", "sand", "and", "cat"}fmt.Println(ArrayToString(wordBreak(s, wordDict)))
}
代码2: 动态规划 + 回溯法
package mainimport ("fmt""strings"
)func wordBreak(s string, wordDict []string) []string {// 构建字典dict := make(map[string]bool)for _, word := range wordDict {dict[word] = true}// 动态规划n := len(s)dp := make([]bool, n+1)dp[0] = truefor i := 1; i <= n; i++ {for j := 0; j < i; j++ {if dp[j] && dict[s[j:i]] {dp[i] = truebreak}}}if !dp[n] {return []string{}}// 回溯函数var res []stringvar backtrack func(start int, path []string)backtrack = func(start int, path []string) {if start == len(s) {res = append(res, strings.Join(path, " "))return}for i := start + 1; i <= len(s); i++ {if dict[s[start:i]] {path = append(path, s[start:i])backtrack(i, path)path = path[:len(path)-1]}}}backtrack(0, []string{})return res
}func ArrayToString(arr []string) string {res := "[\""for i := 0; i < len(arr); i++ {res += arr[i]if i != len(arr)-1 {res += "\",\""}}res += "\"]"if res == "[\"\"]" {res = "[]"}return res
}func main() {s := "catsanddog"wordDict := []string{"cat", "cats", "and", "sand", "dog"}fmt.Println(ArrayToString(wordBreak(s, wordDict)))s = "pineapplepenapple"wordDict = []string{"apple", "pen", "applepen", "pine", "pineapple"}fmt.Println(ArrayToString(wordBreak(s, wordDict)))s = "catsandog"wordDict = []string{"cats", "dog", "sand", "and", "cat"}fmt.Println(ArrayToString(wordBreak(s, wordDict)))
}
代码3: 动态规划 + 记忆化搜索
func wordBreak(s string, wordDict []string) []string {// 构建字典dict := make(map[string]bool)for _, word := range wordDict {dict[word] = true}// 动态规划n := len(s)dp := make([]bool, n+1)dp[0] = truefor i := 1; i <= n; i++ {for j := 0; j < i; j++ {if dp[j] && dict[s[j:i]] {dp[i] = truebreak}}}if !dp[n] {return []string{}}// 记忆化搜索memo := make(map[int][][]string)var dfs func(start int) [][]stringdfs = func(start int) [][]string {if _, ok := memo[start]; ok {return memo[start]}var res [][]stringif start == len(s) {res = append(res, []string{})return res}for i := start + 1; i <= len(s); i++ {if dict[s[start:i]] {subRes := dfs(i)for _, subPath := range subRes {newPath := append([]string{s[start:i]}, subPath...)res = append(res, newPath)}}}memo[start] = resreturn res}return format(dfs(0))
}
// 格式化结果集
func format(paths [][]string) []string {var res []stringfor _, path := range paths {res = append(res, strings.Join(path, " "))}return res
}输出:
["cat sand dog","cats and dog"]
["pine apple pen apple","pine applepen apple","pineapple pen apple"]
[]
🌟 每日一练刷题专栏 🌟
✨ 持续,努力奋斗做强刷题搬运工!
👍 点赞,你的认可是我坚持的动力!
🌟 收藏,你的青睐是我努力的方向!
✎ 评论,你的意见是我进步的财富!
☸ 主页:https://hannyang.blog.csdn.net/
 | Golang每日一练 专栏 |
 | Python每日一练 专栏 |
 | C/C++每日一练 专栏 |
 | Java每日一练 专栏 |
相关文章:
Golang每日一练(leetDay0047)
目录 138. 复制带随机指针的链表 Copy List with Random-pointer 🌟🌟 139. 单词拆分 Word Break 🌟🌟 140. 单词拆分 II Word Break II 🌟🌟🌟 🌟 每日一练刷题专栏 &…...
HCL Nomad Web 1.0.7发布和新功能验证
大家好,才是真的好。 要问在HCL Notes/Domino系列产品中,谁更新得最快,那么答案一定是HCL Nomad Web。 你看上图右边,从1.0.1更新到1.0.7,都没花多少时间。 从HCL Nomad Web 1.0.5版本开始,可以支持直接…...

春招网申简历填写三技巧
网申第一关很重要,不夸张的说网申决定了你的笔试机会,从如信银行考试中心了解到,银行网申筛选过程中,有机器筛选人工筛选两道程序,掌握填写技巧后对提升简历通过率有较大帮助,一定要把握住,关于…...
计算机网络基础知识总结
经过学习我们可以知道: 关于计算机网络: ip地址端口号协议协议分层TCP五层协议协议封装两台计算机之间的通信 目录 ip地址 端口号 协议 协议分层 五层协议体系结构 (1) 应用层 (2) 运输层 (3) 网络层 (4)数据链路层 (5)物理层 封装&分用 两台主机之间的通信 …...

(下)苹果有开源,但又怎样呢?
一开始,因为 MacOS X ,苹果与 FreeBSD 过往从密,不仅挖来 FreeBSD 创始人 Jordan Hubbard,更是在此基础上开源了 Darwin。但是,苹果并没有给予 Darwin 太多关注,作为苹果的首个开源项目,它算不上…...

row_number 和 cte 使用实例:考场监考安排
row_number 和 cte 使用实例:考场监考安排 考场监考安排使用 cte 模拟两个表的原始数据使用 master..spt_values 进行数据填充优先安排时长较长的考试使用 cte 安排第一个需要安排的科目统计老师已有的监考时长尝试使用 cte 递归,进行下一场考试安排&…...

2023天梯赛记录
文章目录 L2-001 紧急救援L2-002 链表去重L2-004 这是二叉搜索树吗?L2-005 集合相似度L2-006 树的遍历L2-007 家庭房产L2-010 排座位L2-011 玩转二叉树L2-012 关于堆的判断L2-013 红色警报L2-014 列车调度L2-016 愿天下有情人都是失散多年的兄妹L2-019 悄悄关注L2-0…...
被吐槽 GitHub仓 库太大,直接 600M 瘦身到 6M,这下舒服了
大家好,我是小富~ 前言 忙里偷闲学习了点技术写了点demo代码,打算提交到我那 2000Star 的Github仓库上,居然发现有5个Issues,最近的一条日期已经是2022/8/1了,以前我还真没留意过这些,我这人懒…...
OpenGL(三)——着色器
目录 一、前言 二、Shader 2 Shader 2.1 顶点着色器 2.2 片段着色器 三、APP 2 Shader 四、顶点颜色属性 五、着色器类C 一、前言 着色器Shader是运行在GPU上的小程序,为图形渲染管线的某个特定部分而运行。各阶段着色器之间无法通信,只有输入和输…...

【MySQL】单表查询
一、表的准备 查询操作的SQL演示将基于下面这四张表进行,我们先创建好这四张数据表,并为其添加数据。 1、第一张表为部门表,名称为包含三个字段:部门编号(deptno),部门名称(dname&…...

第一章 安装Unity
使用Unity开发游戏的话,首先要安装Unity Hub和Unity Editor两个软件。大家可以去官方地址下载:https://unity.cn/releases/full/2020 (这里我们选择的是2020版本) Unity Hub 是安装 Unity Editor、创建项目、管理帐户和许可证的主…...

20230425----重返学习-vue项目-vue自定义指令-vue-cli的配置
day-057-fifty-seven-20230425-vue项目-vue自定义指令-vue-cli的配置 vue项目 vuex版 普通版纯axios:切换页面,就会重新发送一次ajax请求普通版升级:vuex版vuex的常用功能 vuex 数据通信vuex 缓存数据 前进后退,切换页面&#…...
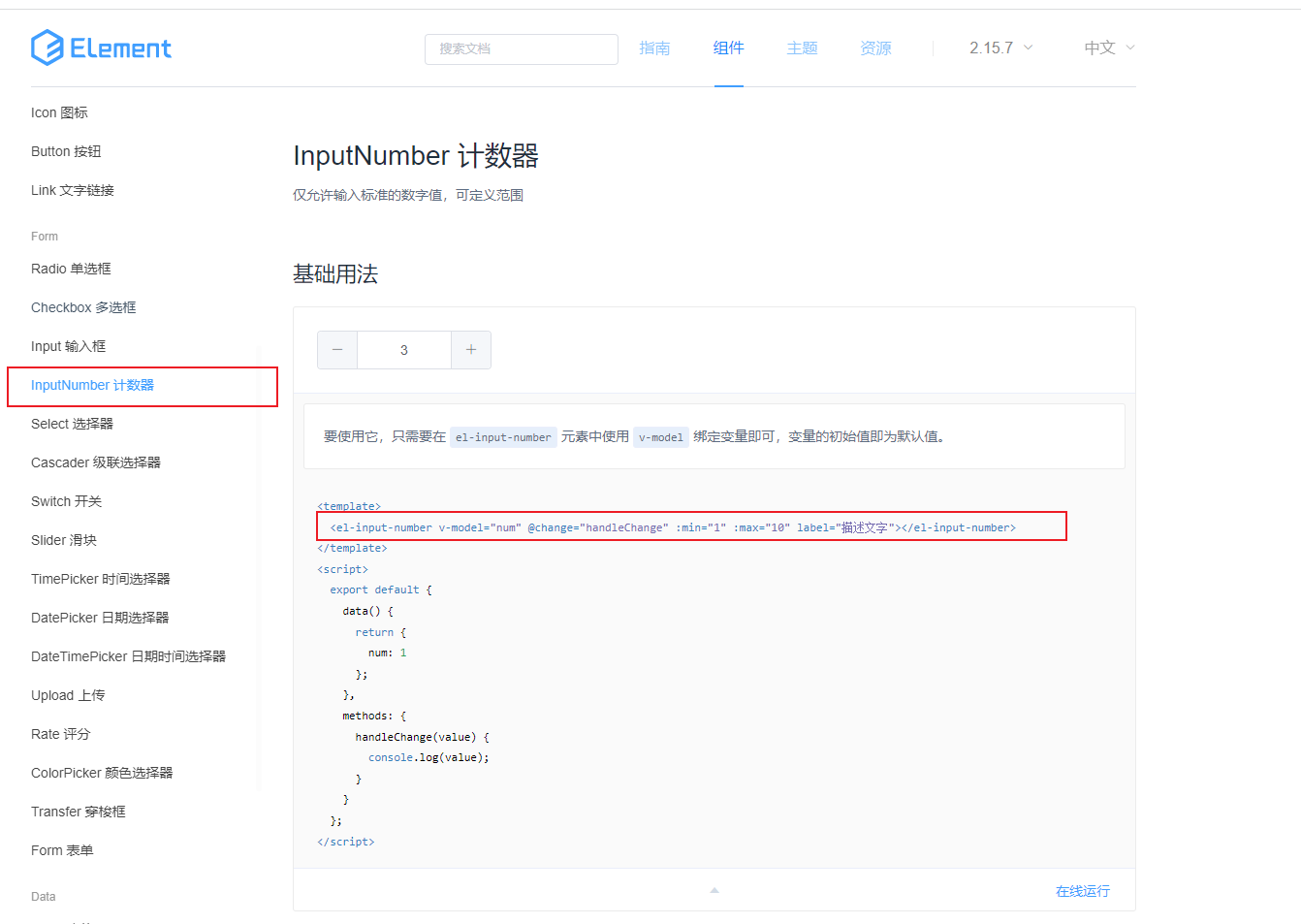
el-input 只能输入整数(包括正数、负数、0)或者只能输入整数(包括正数、负数、0)和小数
使用el-input-number标签 也可以使用typenumbe和v-model.number属性,两者结合使用,能满足大多数需求,如果还不满足,可以再结合正则表达式过滤 <el-input v-model.number"value" type"number" /> el-i…...
Docker Compose的常用命令与docker-compose.yml脚本属性配置
Docker Compose的常用命令与配置 常见命令ps:列出所有运行容器logs:查看服务日志输出port:打印绑定的公共端口build:构建或者重新构建服务start:启动指定服务已存在的容器stop:停止已运行的服务的容器&…...
)
with语句和上下文管理器(py编程)
1. with语句的使用 基础班向文件中写入数据的示例代码: # 1、以写的方式打开文件f open("1.txt", "w")# 2、写入文件内容f.write("hello world")# 3、关闭文件f.close()代码说明: 文件使用完后必须关闭,因为文件对象会占用操作系统…...

《JavaEE初阶》HTTP协议和HTTPS
《JavaEE初阶》HTTP协议和HTTPS 文章目录 《JavaEE初阶》HTTP协议和HTTPSHTTP协议是应用层协议:使用Fiddler抓取HTTP请求和响应:Fiddler的下载和基本使用:Fiddler的中间代理人身份:其他抓包工具: 先简单认识HTTP请求与HTTP响应:HTTP请求:HTTP响应: HTTP请求详解:首行࿱…...

微信小程序 | 基于高德地图+ChatGPT实现旅游规划小程序
🎈🎈效果预览🎈🎈 ❤ 路劲规划 ❤ 功能总览 ❤ ChatGPT交互 一、需求背景 五一假期即即将到来,在大家都阳过之后,截止到目前这应该是最安全的一个假期。所以出去旅游想必是大多数人的选择。 然后&#x…...

Excel技能之实用技巧,高手私藏
今天来讲一下Excel技巧,工作常用,高手私藏。能帮到你是我最大的荣幸。 与其加班熬夜赶进度,不如下班学习提效率。能力有成长,效率提上去,自然不用加班。 消化吸收,工作中立马使用,感觉真不错。…...

黑马程序员Java零基础视频教程笔记-运算符
文章目录 一、算数运算符详解和综合练习二、隐式转换和强制转换三、字符串和字符的加操作四、自增自减运算符五、赋值运算符和关系运算符六、四种逻辑运算符七、短路逻辑运算符八、三元运算符 一、算数运算符详解和综合练习 1. 运算符和表达式 ① 运算符:对字面量…...
部署方案)
Microsoft Data Loss Prevention(DLP)部署方案
目录 一、前言 二、部署流程 步骤一:确定数据需求 步骤二:规划信息保护策略...
)
别再乱用Pre Launch Init了!Actor Framework嵌套操作者启动的正确姿势(附LabVIEW 2023示例)
Actor Framework嵌套操作者启动陷阱与实战解决方案 在LabVIEW的Actor Framework(AF)开发中,嵌套操作者的启动顺序是一个看似简单却暗藏玄机的技术细节。许多中级开发者在项目实践中都曾遇到过这样的场景:明明按照常规思路在Pre La…...

别再死记硬背了!用一张图+三个故事彻底搞懂PCIe TLP帧结构
用快递、交通与银行故事轻松掌握PCIe TLP帧结构 每次打开PCIe协议文档,看到那些密密麻麻的字段定义,是不是感觉头大如斗?Fmt、Type、TC、Attr...这些抽象术语就像一堵高墙,把许多工程师挡在了深入理解PCIe的大门之外。但今天&…...

QQ音乐API逆向工程与数据解析技术架构深度解析
QQ音乐API逆向工程与数据解析技术架构深度解析 【免费下载链接】MCQTSS_QQMusic QQ音乐解析 项目地址: https://gitcode.com/gh_mirrors/mc/MCQTSS_QQMusic QQ音乐作为中国领先的数字音乐平台,其API接口设计与数据加密机制一直是技术社区关注的热点。本项目通…...
)
Langchain的学习(一)
目录 一,实操 编码 Runnable Runnable 是什么 核心方法(所有 Runnable 都有) 最关键能力:用 | 组合(LCEL) 常用内置 Runnable 总结 二,聊天模型-核心能力 定义模型 init_chat_model 本地部署 调用工具 定义工具-Tool version1 schema: version2(基于…...

离谱!上海交大一学生私吞 5000 奖金,还用豆包 P 假收据骗队友。网友:学历虽高但人品太低
①5 月 18 日,上海交大一则学生违纪通报冲上热搜,实锤了前几天网上曝光的一名学生侵占团队竞赛奖金、造假欺骗队友的恶劣行为。②在 2025 下半年,樊同学(上交大智慧能源学院女生)与 K 同学(电院男生&#x…...

NoSleep:彻底告别电脑自动休眠的终极解决方案
NoSleep:彻底告别电脑自动休眠的终极解决方案 【免费下载链接】NoSleep Lightweight Windows utility to prevent screen locking 项目地址: https://gitcode.com/gh_mirrors/nos/NoSleep 你是否经历过这些令人沮丧的时刻?在线会议进行到关键演示…...

我的第一个CANOpen主站:手把手教你用CanFestival-3源码配置心跳、SYNC和PDO映射
我的第一个CANOpen主站:手把手教你用CanFestival-3源码配置心跳、SYNC和PDO映射 当你第一次面对工业现场总线协议时,那种既兴奋又忐忑的心情我至今记忆犹新。CANOpen作为工业自动化领域的"普通话",其主站开发往往是工程师进阶路上的…...

3分钟快速找回:手机号查QQ号Python工具完整指南
3分钟快速找回:手机号查QQ号Python工具完整指南 【免费下载链接】phone2qq 项目地址: https://gitcode.com/gh_mirrors/ph/phone2qq 你是否曾因为忘记QQ号而无法登录?或者换了新手机后,只记得手机号却找不到对应的QQ账号?…...

如何用Winhance一键优化Windows系统?完整免费指南
如何用Winhance一键优化Windows系统?完整免费指南 【免费下载链接】Winhance-zh_CN A Chinese version of Winhance. C# application designed to optimize and customize your Windows experience. 项目地址: https://gitcode.com/gh_mirrors/wi/Winhance-zh_CN …...

顶伯在线语音工具背后的技术力量:AI语音合成与深度学习解析
顶伯在线语音工具背后的技术力量在人工智能浪潮中,语音交互正成为人机沟通的核心方式。顶伯作为行业领先的在线语音工具,凭借自主研发的深度学习架构,将文字转化为高度自然的语音,广泛应用于有声阅读、智能客服、教育辅助等领域。…...