Flink之TaskManager内存解析
一、CK失败
Flink任务的checkpoint操作失败大致分为两种情况,ck decline和ck expire:
(1)ck decline
发生ck decline情况时,我们可以通过查看JobManager.log或TaskManager.log查明具体原因。其中有一种特殊情况为ck cancel,当前 Flink 中如果较小的ck还没有对齐的情况下,收到了更大的ck,则会把较小的ck给取消掉。
(2)ck expire
如果ck做的非常慢,超过了timeout还没有完成,则整个ck也会失败。这种情况也可以通过查看JobManager.log或TaskManager.log查明具体原因。
由查看JobManager和TaskManager(下文简称TM)当时的日志可知,是因为TM重启,导致做ck超时,发生了ck Expire。
而TM重启的原因,主要有两个原因,一个可能是网络传输波动,另一个是TM资源不足,通过进一步排查,本次TM重启的原因是当时处理数据量增加,导致TM资源不足,发生了TM重启,进而导致了那次ck失败。
二、TaskManager内存分析
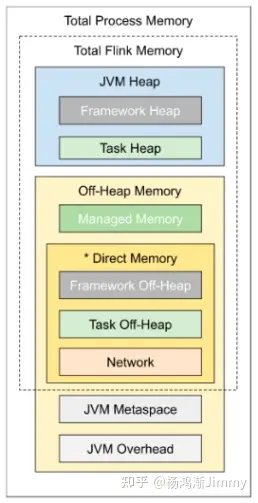
TaskManager内存示意图
| 组成部分 | 配置参数 | 描述 |
|---|---|---|
| 框架堆内存(Framework Heap Memory) | taskmanager.memory.framework.heap.size | 用于 Flink 框架的 JVM 堆内存 |
| 任务堆内存(Task Heap Memory) | taskmanager.memory.task.heap.size | 用于 Flink 应用的算子及用户代码的 JVM 堆内存 |
| 托管内存(Managed memory) | taskmanager.memory.managed.size | 由 Flink 管理的用于排序、哈希表、缓存中间结果及 RocksDB State Backend 的本地内存 |
| 框架堆外内存(Framework Off-heap Memory) | taskmanager.memory.framework.off-heap.size | 用于 Flink 框架的堆外内存(直接内存或本地内存) |
| 任务堆外内存(Task Off-heap Memory) | taskmanager.memory.task.off-heap.size | 用于 Flink 应用的算子及用户代码的堆外内存(直接内存或本地内存) |
| 网络内存(Network Memory) | taskmanager.memory.network.min | 用于任务之间数据传输的直接内存(例如网络传输缓冲)。该内存部分为基于 Flink 总内存的受限的等比内存部分 |
| JVM Metaspace | taskmanager.memory.jvm-metaspace.size | Flink JVM 进程的 Metaspace |
| JVM 开销 | taskmanager.memory.jvm-overhead.min | 用于其他 JVM 开销的本地内存,例如栈空间、垃圾回收空间等。该内存部分为基于进程总内存的受限的等比内存部分 |
Flink并不是将大量对象存在堆上,而是将对象都序列化到一个预分配的内存块上,这个内存块叫做MemorySegment,它代表了一段固定长度的内存(默认大小为32KB),也是Flink中最小的内存分配单元,并且提供了非常高效的读写方法。如果因为内存空间不足,无法申请到更多的内存区域来存储对象时,Flink会将MemorySegment中的数据溢写到本地文件系统(SSD/HDD)中。当再次需要操作数据时,会直接从磁盘中读取数据。
三、调整说明及建议
从以上内容的分析和介绍,在某些情况下,我们可以调整或优化TM的内存,来规避TM重启的问题,最终尽可能避免ck失败的情况。
对于没有硬性资源限制的环境,我们可以使用taskmanager.memory.flink.size参数来配置 Flink总内存的大小,然后Flink自己也会自动根据参数,计算得到各个子区域的配额。如果作业运行正常,则无需单独调整。
如果要更精细化的调整,可以调大JVM Heap中的Task Heap,Task Heap Memory是专门用于执行Flink任务的堆内存空间,是用户代码,自定义数据结构真正占用的内存,通过参数taskmanager.memory.task.heap.size指定。
再其次可以调大Direct Memory中的Task Off-heap Memory,Task Off-heap Memory是Flink执行task所使用的堆外内存。如果在Flink应用的代码中调用了Native的方法,需要用到off-head内存,这些内存会分配到Off-heap堆外内存中,通过参数taskmanage.memory.task.off-heap.size 指定,默认为0。
再其次可以调大Direct Memory中的Network Memory,Flink的Task之间的shuffle,广播等操作以及与外部组件的数据传输需要用到Network Memory,该值通过3个参数确定:
--taskmanager.memory.network.min,Network Memory最小值
--taskmanager.memory.network.max,Network Memory最大值
--taskmanager.memory.network.fraction,Network Memory占Total Flink Memory的比例,默认0.1。如果通过该比例值计算出的结果超出前两个MIN-MAX参数的范围,则以MIN-MAX为准。如果MIN-MAX参数使用同样的值,则表示NetWork是固定的内存大小。
四、可参考的TaskManager内存计算公式
1、每个任务TaskManager分到的总共内存(tm_total_memory)=taskmanager.memory.flink.size - taskmanager.memory.jvm-metaspace.size(JVM元空间,JVM Metaspace)-JVM Overhead Memory (JVM 运行时开销)
其中JVM Overhead Memory用来存放线程栈、编译的代码缓存、JNI 调用的库所分配的内存等等。
--taskmanager.memory.jvm-overhead.fraction,默认 0.1
--taskmanager.memory.jvm-overhead.min,默认 192mb
--taskmanager.memory.jvm-overhead.max,默认 1gb
总进程内存*fraction,如果小于配置的 min(或大于配置的 max)大小,则使用 min/max大小。
2、每个任务TaskManager真正使用的堆内内存(tm_heap_memory)= tm_total_memory- taskmanager.memory.framework.heap.size(堆内框架内存,默认128M - taskmanager.memory.framework.off-heap.size(堆外框架内存,默认128M)- Network Memory(网络内存)- Managed memory(托管内存)
其中Managed Memory托管内存,是有Flink直接管理的堆外内存,用于排序,哈希表,中间结果缓存,以及RocksDB的状态后端。通过参数taskmanage.memory.managed.size指定,默认情况下不配置,通过参数taskmanager.memory.managed.fraction因子(默认0.4) * Total Flink Memory来指定大小。
最后具体情况需要根据业务的复杂度、数据量和集群情况合理分配slot ytm tjm p,其实并行度的设置可以根据算子里面的不同情况各自设置并行度,但是最大的并行度是由 [(slot * jobmanager的数据 ) * nodemanager数量 ]决定的,jobmanager的数量=(可申请的最大内存 - yjm ) / ytm 。其实有的时候slot越大并不会性能越高,集群的资源需要留一部分给hbase hive等数据仓库来做缓存使用,在代码层无法优化后,还是需要根据实际情况测试调整集群资源和运行资源。
相关文章:
Flink之TaskManager内存解析
一、CK失败 Flink任务的checkpoint操作失败大致分为两种情况,ck decline和ck expire: (1)ck decline 发生ck decline情况时,我们可以通过查看JobManager.log或TaskManager.log查明具体原因。其中有一种特殊情况为ck cancel&…...
为何越来越多人不喜欢“试用期六个月”的公司?网友:感觉不靠谱
众所周知,任何一份工作都有试用期,一般是三月左右。但如果你遇到试用期达到半年的公司,你会不会进入? 近日,就有人遇到了此类公司,并对是否要进入该公司犹豫不决。他在论坛上发帖求助:大家是怎…...

单例模式的四种创建方式
前言 单例模式是日常开发中最常见的一种设计模式,常用来做为池对象,或者计数器之类的需要保证全局唯一的场景。 单例模式的目的是保证在整个程序中只存在一个对象实例,使用单例一个前提条件就是构造器私有化,不允许通过new 对象…...

Nginx+Keepalived 中的脑裂现象
如何解决和预防 NginxKeepalived 中会出现的脑裂现象? Nginx是一种高性能的Web服务器和反向代理服务器,可以处理大量并发请求。Keepalived是一种开源软件,用于实现IP负载均衡和故障转移。在Nginx和Keepalived结合使用时,可以通过将多个Ngin…...

04 KVM虚拟化网络概述
文章目录 04 KVM虚拟化网络概述4.1 Linux Bridge4.2 Open vSwitch 04 KVM虚拟化网络概述 为了使虚拟机可以与外部进行网络通信,需要为虚拟机配置网络环境。KVM虚拟化支持Linux Bridge、Open vSwitch网桥等多种类型的网桥。如图1所示,数据传输路径为“虚…...
110页智慧农业解决方案(农业信息化解决方案)(ppt可编辑)
本资料来源公开网络,仅供个人学习,请勿商用,如有侵权请联系删除。 第一部分 智慧农业概述 智慧农业以农业资源为基础、市场为导向、效益为中心、产业化为抓手,面向农业管理部门、农技推广部门、农业企业、农业园区和基地、农业专…...

Java知识体系及聊天室程序
Java知识体系结构梳理如下: 基础语法:Java的基本语法,包括数据类型、运算符、控制语句、数组等。 面向对象编程:Java是一种面向对象的编程语言,需要掌握类、对象、继承、多态等概念。 异常处理:Java提供了…...

java的详细发展历程
Java是一种跨平台、面向对象的编程语言,具有简单性、可移植性、安全性等特点。Java的历史可以追溯到上世纪90年代初期,以下是Java的详细发展历程: 1991年,Sun Microsystems公司的James Gosling和他的团队开始开发一种名为Oak的编程…...

丢石子
I 一堆石子有n个,两人轮流取.先取者第1次可以取任意多个,但不能全部取完.以后每次取的石子数不能超过上次取子数的2倍。取完者胜.先取者负输出"Second win".先取者胜输出"First win". 思路: 任何正整数都可以表示为不连续斐波那契…...

skywalking手动上报一些指标信息
skywalking的相关概念我就不介绍了,有兴趣可以参看官网文档 以下提供以下简单示例手工上报一些对问题排查比较有用的一些信息。当然这些内容你也可以写成探针插件的形式,怎么开发探针插件也自行参考官方文档。此处仅在项目框架层面提供一些简单的示例&am…...
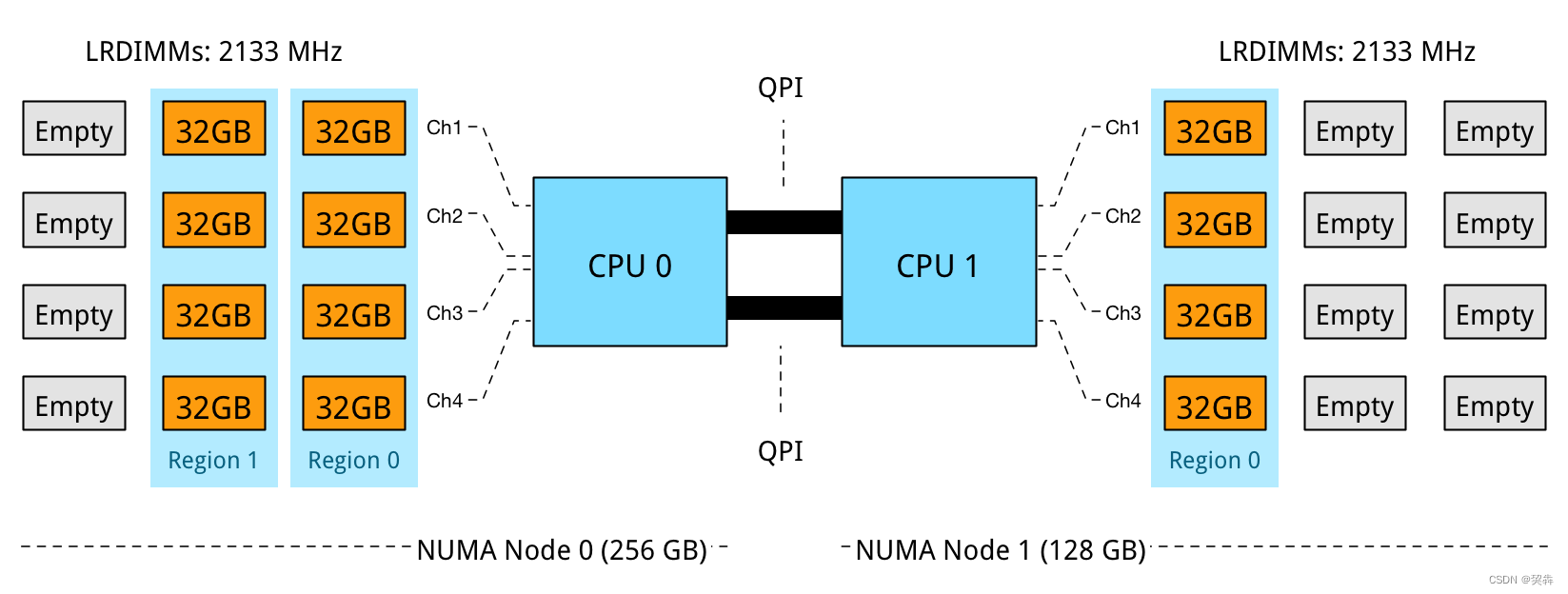
NUMA详解
目录 NUMA简介 NUMA开启与关闭 查看系统是否支持 关闭方法 numactl --hardware介绍 没有安装numactl工具下查看NUMA架构节点数: 查看每个NUMA节点的CPU使用情况: 看每个NUMA节点的内存使用情况: 查看NUMA下指定进程的运行情况 创建…...

H68K在Armbina系统下开AP
背景需求替代路由器,网上找了一大堆都不行 最后成功开启了AP 参考了两篇文章, 一篇是如何创建热点, 一篇是如何开启5G 树莓派4B创建5Ghz WiFi热点 – 风声 https://www.hncldz.com/2020/02/01/%e6%a0%91%e8%8e%93%e6%b4%be4b%e5%88%9b%e5%bb%ba5ghz-wifi%e7%83%ad%e7%82%b…...
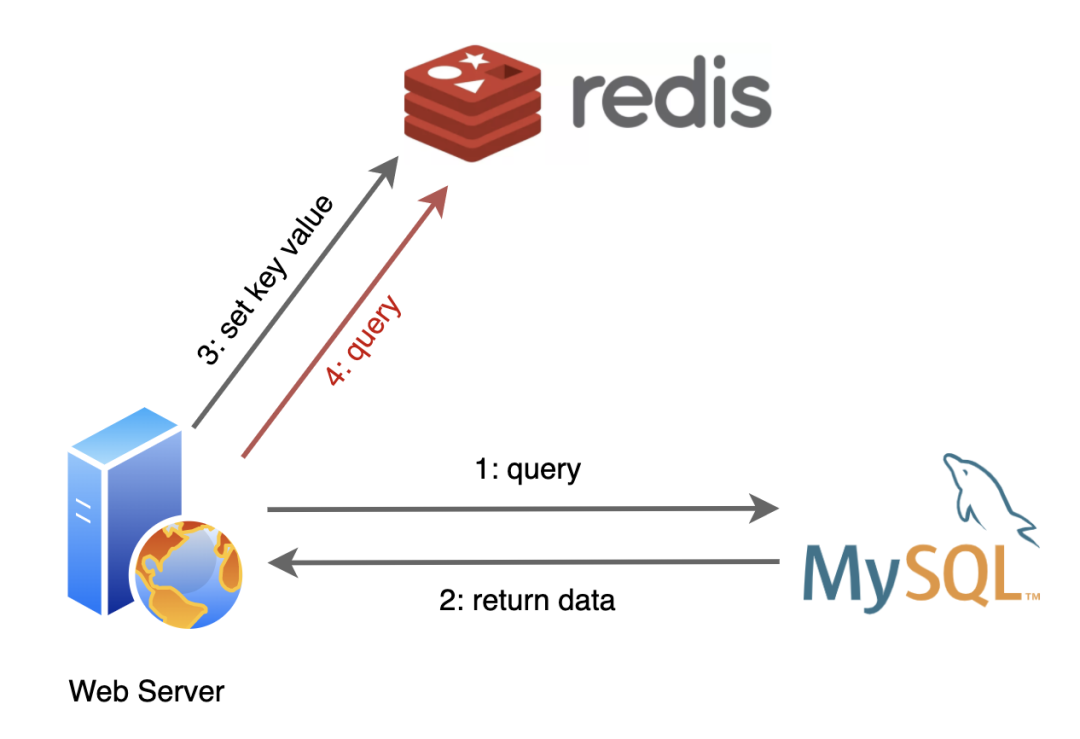
还不懂Redis?看完这个故事就明白了!
还不懂Redis?看完这个故事就明白了! 我是Redis 你好,我是Redis,一个叫Antirez的男人把我带到了这个世界上。 说起我的诞生,跟关系数据库MySQL还挺有渊源的。 在我还没来到这个世界上的时候,MySQL过的很辛苦,互联网发展的越来越快,它容纳的数据也越来越多,用户请求也…...
Haproxy负载均衡集群
1.Haproxy支持四层和七层 2.haproxy常用的调度算法? 3.LSV/NGINX/HAPROXT的区别? 4. 5.Haproy负载均衡部署 实验需求 利用Haproxy的运用配置出负载均衡调度器,以此来调用两台Nginx服务器进行工作 实验所需组件 Haproxy服务器:192…...

17.计及电转气协同的含碳捕集与垃圾焚烧虚拟电厂优化调度
说明书 MATLAB代码:计及电转气协同的含碳捕集与垃圾焚烧虚拟电厂优化调度 关键词:碳捕集 虚拟电厂 需求响应 优化调度 电转气协同调度 参考文档:《计及电转气协同的含碳捕集与垃圾焚烧虚拟电厂优化调度》完全复现 仿真平台:…...

企业数字化管理中,数据治理到底怎么“治”
随着信息化、数字化的理念、技术及其应用在社会的方方面面进行扩散,数据的规模和丰富程度已经达到了一个新的高度,所以当下如何更进一步利用好数据,充分发挥数据的价值,将其真正变为高质量的数据资产成为了企业要面对的重要问题&a…...

《HelloGitHub》第 85 期
兴趣是最好的老师,HelloGitHub 让你对编程感兴趣! 简介 HelloGitHub 分享 GitHub 上有趣、入门级的开源项目。 https://github.com/521xueweihan/HelloGitHub 这里有实战项目、入门教程、黑科技、开源书籍、大厂开源项目等,涵盖多种编程语言 …...

自动驾驶人机交互HMI产品技术方案
1. 概述 1.1 目的 本文档描述集卡自动驾驶系统中HMI产品的技术方案,设计人员遵循本方案进行设计,为项目开发实施提供技术方案保障。 1.2 范围 本文档适用于HMI产品项目。本文档用于指导HMI产品项目的UI、前端开发过程。 1.3 术语与缩写 术语/缩写 描述 HMI...

开发感悟20230426
一、element-ui样式设置 1. 可以直接在css中写个样式文件,把对应的类名改写样式,然后在main.js中引用,可以覆盖上面的,如果想给element-ui设置样式,不用设置deep了 2.可以直接修改引入的element-ui的样式,…...

C和C++的区别
C和C的区别 1、面向对象编程:C是面向对象的语言,而C语言则不支持面向对象编程。C提供了类、对象、封装、继承、多态等面向对象的特性,使得程序结构更加清晰、可读性更强。2、模板:C提供了模板的特性,使得程序员可以通…...

英雄联盟个性化工具终极指南:3分钟免费打造专属游戏身份
英雄联盟个性化工具终极指南:3分钟免费打造专属游戏身份 【免费下载链接】LeaguePrank 项目地址: https://gitcode.com/gh_mirrors/le/LeaguePrank 想要在英雄联盟中展示与众不同的个人资料吗?LeaguePrank是一款开源免费的英雄联盟个性化工具&am…...
)
从ARM Cortex-M到FPGA:手把手教你用AXI4-Lite搭建自定义外设(以Zynq-7000为例)
从ARM Cortex-M到FPGA:用AXI4-Lite实现自定义外设的工程实践 在嵌入式系统开发中,处理器与可编程逻辑的高效协同一直是提升性能的关键路径。当标准外设无法满足特定需求时,工程师往往需要在FPGA中设计定制硬件模块,并通过标准化总…...

3步解决B站缓存视频播放难题:m4s-converter使用指南
3步解决B站缓存视频播放难题:m4s-converter使用指南 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾为B站缓存视频无法在其他…...
)
别再傻傻等下载了!QMT历史数据获取的3个高效技巧(含xtquant代码示例)
QMT历史数据获取效率优化实战:3个让回测提速200%的高级技巧 每次打开QMT准备回测策略时,最让人抓狂的莫过于漫长的历史数据等待时间。作为一名量化研究员,我曾在数据准备环节浪费了无数个下午——直到发现这几个能彻底改变工作流的技巧。本文…...

MySQL 8.3远程连接踩坑记:Navicat提示caching_sha2_password错误的完整修复流程
MySQL 8.3远程连接认证插件问题深度解析与实战修复指南 1. 问题现象与背景分析 那天下午,当我正尝试用Navicat Premium 16连接新部署的MySQL 8.3数据库时,屏幕上突然弹出的红色错误框让我的咖啡杯悬在了半空: Authentication plugin caching_…...
可视化STM32引脚波形)
告别盲调!用Keil自带的逻辑分析仪(Debug Simulator)可视化STM32引脚波形
告别盲调!用Keil自带的逻辑分析仪(Debug Simulator)可视化STM32引脚波形 在嵌入式开发中,调试环节往往占据整个开发周期的40%以上时间。对于STM32开发者而言,传统的调试方式主要依赖LED闪烁观察或串口打印输出,这种方式不仅效率低…...

Multi-Agent产品创新:从单一场景到跨域协同的演进
Multi-Agent产品创新:从单一场景到跨域协同的演进 关键词:多智能体系统、产品创新、跨域协同、单一场景智能、Agent协作框架、LLM驱动Agent、分布式智能 摘要:大语言模型的爆发式发展,让智能Agent从实验室走向了大众消费级产品。本文从生活场景的真实痛点切入,逐层拆解Mul…...

Adams新手避坑指南:从几何点、Marker坐标系到立方体,这些基础元素你真的用对了吗?
Adams新手避坑指南:几何元素背后的工程逻辑与实战陷阱 刚接触Adams的工程师常会陷入一个误区——把软件操作手册当作圣经,却忽略了每个几何元素背后的物理意义和工程逻辑。这种"知其然不知其所以然"的学习方式,往往会导致仿真结果失…...

Visual C++运行库合集:解决Windows程序依赖的终极方案
Visual C运行库合集:解决Windows程序依赖的终极方案 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否遇到过这样的烦恼?刚下载了一个…...

创业团队如何利用taotoken管理多项目ai调用成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 创业团队如何利用Taotoken管理多项目AI调用成本 对于同时推进多个AI应用原型开发的创业团队而言,一个常见的挑战是如何…...