前端如何处理后端一次性传来的10w条数据?
写在前面
如果你在面试中被问到这个问题,你可以用下面的内容回答这个问题,如果你在工作中遇到这个问题,你应该先揍那个写 API 的人。
创建服务器
为了方便后续测试,我们可以使用node创建一个简单的服务器。
const http = require('http')
const port = 8000;let list = []
let num = 0// create 100,000 records
for (let i = 0; i < 100_000; i++) {num++list.push({src: 'https://miro.medium.com/fit/c/64/64/1*XYGoKrb1w5zdWZLOIEevZg.png',text: `hello world ${num}`,tid: num})
}http.createServer(function (req, res) {// for Cross-Origin Resource Sharing (CORS)res.writeHead(200, {'Access-Control-Allow-Origin': '*',"Access-Control-Allow-Methods": "DELETE,PUT,POST,GET,OPTIONS",'Access-Control-Allow-Headers': 'Content-Type'})res.end(JSON.stringify(list));
}).listen(port, function () {console.log('server is listening on port ' + port);
})node server.js//把服务器运行起来创建前端模板页面
然后我们的前端由一个 HTML 文件和一个 JS 文件组成。
Index.html:
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><meta http-equiv="X-UA-Compatible" content="IE=edge"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>Document</title><style>* {padding: 0;margin: 0;}#container {height: 100vh;overflow: auto;}.sunshine {display: flex;padding: 10px;}img {width: 150px;height: 150px;}
</style>
</head>
<body><div id="container"></div><script src="./index.js"></script>
</body>
</html>Index.js:
// fetch data from the server
const getList = () => {return new Promise((resolve, reject) => {var ajax = new XMLHttpRequest();ajax.open('get', 'http://127.0.0.1:8000');ajax.send();ajax.onreadystatechange = function () {if (ajax.readyState == 4 && ajax.status == 200) {resolve(JSON.parse(ajax.responseText))}}})
}// get `container` element
const container = document.getElementById('container')// The rendering logic should be written here.好的,这就是我们的前端页面模板代码,我们开始渲染数据。
直接渲染
最直接的方法是一次将所有数据渲染到页面。代码如下:
const renderList = async () => {const list = await getList()list.forEach(item => {const div = document.createElement('div')div.className = 'sunshine'div.innerHTML = `<img src="${item.src}" /><span>${item.text}</span>`container.appendChild(div)})
}
renderList()一次渲染 100,000 条记录大约需要 12 秒,这显然是不可取的。
通过 setTimeout 进行分页渲染
一个简单的优化方法是对数据进行分页。假设每个页面都有limit记录,那么数据可以分为Math.ceil(total/limit)个页面。之后,我们可以使用 setTimeout 顺序渲染页面,一次只渲染一个页面。
const renderList = async () => {const list = await getList()const total = list.lengthconst page = 0const limit = 200const totalPage = Math.ceil(total / limit)const render = (page) => {if (page >= totalPage) returnsetTimeout(() => {for (let i = page * limit; i < page * limit + limit; i++) {const item = list[i]const div = document.createElement('div')div.className = 'sunshine'div.innerHTML = `<img src="${item.src}" /><span>${item.text}</span>`container.appendChild(div)}render(page + 1)}, 0)}console.time("time");render(page)console.timeEnd("time");
//time: 0.27392578125 ms
}分页后,数据可以快速渲染到屏幕上,减少页面的空白时间。
requestAnimationFrame
在渲染页面的时候,我们可以使用requestAnimationFrame来代替setTimeout,这样可以减少reflow次数,提高性能。
const renderList = async () => {const list = await getList()const total = list.lengthconst page = 0const limit = 200const totalPage = Math.ceil(total / limit)const render = (page) => {if (page >= totalPage) returnrequestAnimationFrame(() => {for (let i = page * limit; i < page * limit + limit; i++) {const item = list[i]const div = document.createElement('div')div.className = 'sunshine'div.innerHTML = `<img src="${item.src}" /><span>${item.text}</span>`container.appendChild(div)}render(page + 1)})}console.time("time");render(page)console.timeEnd("time");
//time: 0.27685546875 ms 这里改善不明显
}window.requestAnimationFrame () 方法告诉浏览器您希望执行动画,并请求浏览器调用指定函数在下一次重绘之前更新动画。该方法将回调作为要在重绘之前调用的参数。
文档片段
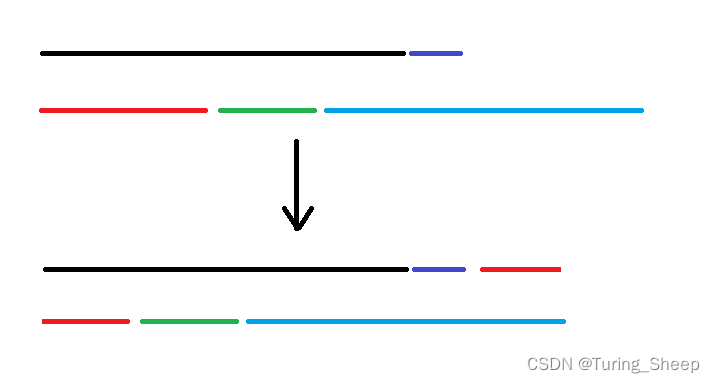
以前,每次创建 div 元素时,都会通过 appendChild 将元素直接插入到页面中。但是 appendChild 是一项昂贵的操作。
实际上,我们可以先创建一个文档片段,在创建了 div 元素之后,再将元素插入到文档片段中。创建完所有 div 元素后,将片段插入页面。这样做还可以提高页面性能。
const renderList = async () => {console.time('time')const list = await getList()console.log(list)console.timeEnd('time')console.time('time2')const total = list.lengthconst page = 0const limit = 200const totalPage = Math.ceil(total / limit)const render = (page) => {if (page >= totalPage) returnrequestAnimationFrame(() => {const fragment = document.createDocumentFragment()for (let i = page * limit; i < page * limit + limit; i++) {const item = list[i]const div = document.createElement('div')div.className = 'sunshine'div.innerHTML = `<img src="${item.src}" /><span>${item.text}</span>`fragment.appendChild(div)}container.appendChild(fragment)render(page + 1)})}render(page)console.timeEnd('time2')
//time2: 0.195068359375 ms 有改善
}延迟加载
虽然后端一次返回这么多数据,但用户的屏幕只能同时显示有限的数据。所以我们可以采用延迟加载的策略,根据用户的滚动位置动态渲染数据。
要获取用户的滚动位置,我们可以在列表末尾添加一个空节点空白。每当视口出现空白时,就意味着用户已经滚动到网页底部,这意味着我们需要继续渲染数据。
同时,我们可以使用getBoundingClientRect来判断空白是否在页面底部。
使用 Vue 的示例代码:
<script setup lang="ts">
import { onMounted, ref, computed } from 'vue'
const getList = () => {// code as before
}
const container = ref<HTMLElement>() // container element
const blank = ref<HTMLElement>() // blank element
const list = ref<any>([])
const page = ref(1)
const limit = 200
const maxPage = computed(() => Math.ceil(list.value.length / limit))
// List of real presentations
const showList = computed(() => list.value.slice(0, page.value * limit))
const handleScroll = () => {if (page.value > maxPage.value) returnconst clientHeight = container.value?.clientHeightconst blankTop = blank.value?.getBoundingClientRect().topif (clientHeight === blankTop) {// When the blank node appears in the viewport, the current page number is incremented by 1page.value++}
}
onMounted(async () => {const res = await getList()list.value = res
})
</script><template><div id="container" @scroll="handleScroll" ref="container"><div class="sunshine" v-for="(item) in showList" :key="item.tid"><img :src="item.src" /><span>{{ item.text }}</span></div><div ref="blank"></div></div>
</template>最后
我们从一个面试问题开始,讨论了几种不同的性能优化技术。
作者:前端学习站
链接:https://www.zhihu.com/question/525562842/answer/2536419265
来源:知乎
相关文章:

前端如何处理后端一次性传来的10w条数据?
写在前面 如果你在面试中被问到这个问题,你可以用下面的内容回答这个问题,如果你在工作中遇到这个问题,你应该先揍那个写 API 的人。 创建服务器 为了方便后续测试,我们可以使用node创建一个简单的服务器。 const http requir…...
Codeforces Round 867 (Div. 3)(A-G2)
文章目录 A. TubeTube Feed1、题目2、分析3、代码, B. Karina and Array1、题目2、分析3、代码 C. Bun Lover1、问题2、分析(1)观察样例法(2)正解推导 3、代码 D. Super-Permutation1、问题2、分析(1&#…...

蓝奥声核心技术分享——一种无线低功耗配置技术
1.技术背景 无线低功耗配置技术指基于对目标场景状态变化的协同感知而获得触发响应并进行智能决策,属于蓝奥声核心技术--边缘协同感知(EICS)技术的关键支撑性技术之一。该项技术涉及物联网边缘域的无线通信技术领域,具体主要涉及网络服务节点…...

kafka集群模拟单节点故障
这里通过kafka manage来展示节点宕机效果 现在三台主机节点均正常 topic正常识别到三个broker leader也均匀分配到了三个broker上 现在把节点id为0的主机模拟宕机 可以通过以上两张图片看到每个topic现在只识别到了两个broker节点,broker id为0的节点已经被剔除掉了 isr列…...

笔记:vue-cli-service
vue-cli-service serve 这个是什么意思? vue-cli-service serve 是一个 Vue.js CLI 命令,用于在本地开发环境下运行一个开发服务器,以便你可以在浏览器中查看和测试你的 Vue.js 应用程序。它在开发期间提供了自动重载、热模块替换和其它实用…...
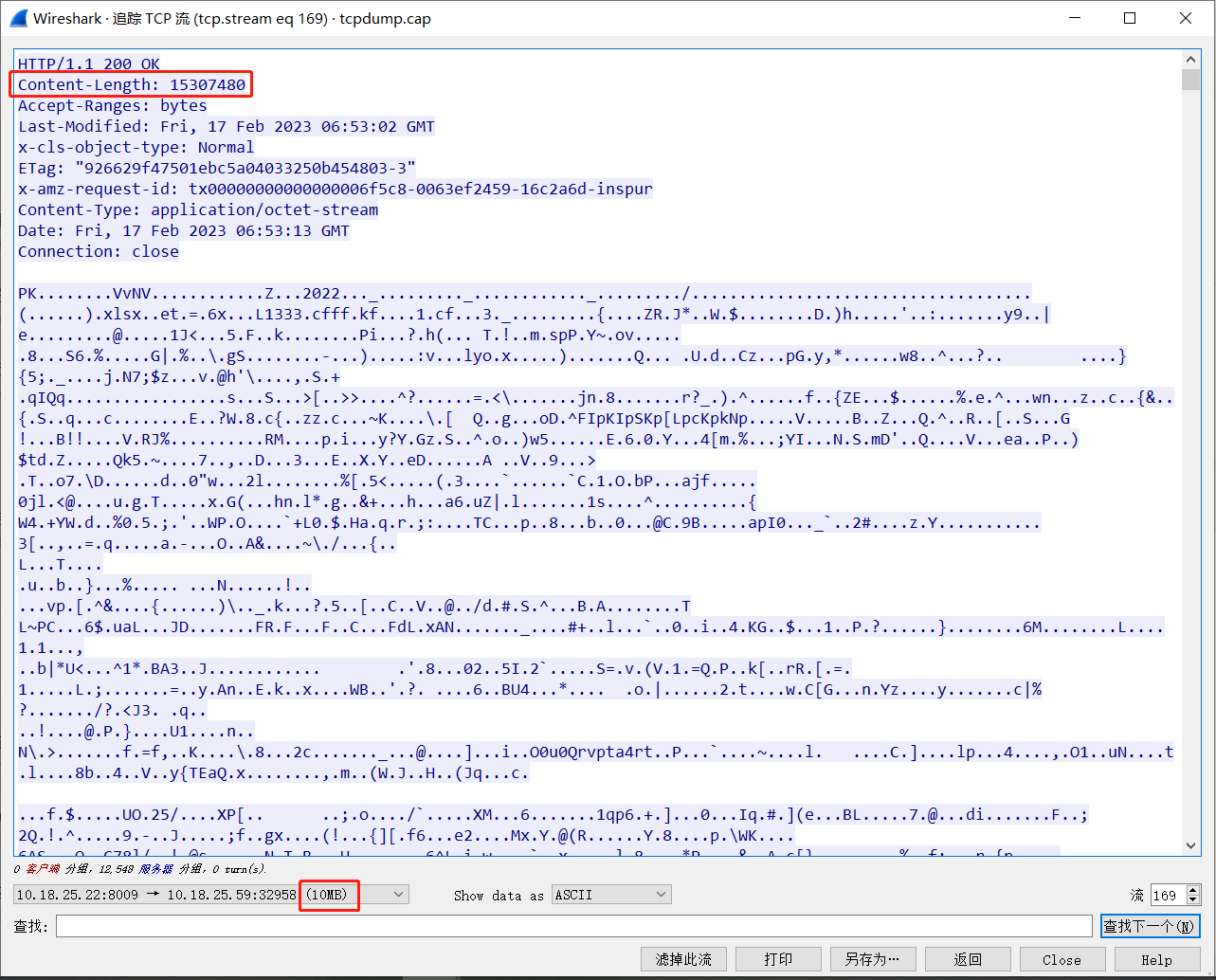
Amazon S3 对象存储Java API操作记录(Minio与S3 SDK两种实现)
缘起 今年(2023年) 2月的时候做了个适配Amazon S3对象存储接口的需求,由于4月份自学考试临近,一直在备考就拖着没总结记录下,开发联调过程中也出现过一些奇葩的问题,最近人刚从考试缓过来顺手记录一下。 S3对象存储的基本概念 …...

ChatGPT技术原理 第六章:对话生成技术
目录 6.1 任务定义 6.2 基于检索的方法 6.3 基于生成的方法 6.4 评价指标 6.1 任务定义 对话生成技术是指使用自然语言处理技术生成与人类语言相似的对话。在对话生成任务中,模型需要理解输入的语境、用户的意图和上下文信息,然后生成能够回答用户问题…...

【C++ 八】写文件、读文件
写文件、读文件 文章目录 写文件、读文件前言1 文本文件1.1 写文件1.2 读文件 2 二进制文件2.1 写文件2.2 读文件 前言 本文包含文本文件写文件、文本文件读文件、二进制写文件、二进制读文件。 程序运行时产生的数据都属于临时数据,程序一旦运行结束都会被释放 通…...

【学习笔记】CF613E Puzzle Lover
这题本质上还是数据结构。 首先看到这个 2 n 2\times n 2n的网格图就很容易想到分治。我们还是考虑把要统计的东西变得可视化,一条路径要么穿过中线一次,那么我们可以将两边的串拼起来得到答案;要么穿过中线两次,考虑其中一边的…...

软考报名资格审核要多久?证明材料要哪些?
软考报名资格审核要多久? 一般来说,软考资格审核时间不超过1个工作日。当然,每个地区的具体情况都不一样。有些地区估计需要1-3个工作日。总之,为了顺利成功报名,大家应尽快报名,不要拖到最后一天。 软考…...

2023-04-27 polardbx-LSM-tree的Parallel Recovery性能优化
背景 数据库的Crash Recovery时长关系到数据库的可用性SLA、故障止损时间、升级效率等多个方面。本文描述了针对X-Engine数据库存储引擎的一种Crash Recovery优化手段,在典型场景下可以显著缩短数据库实例的故障恢复时间,提升用户使用感受。 当前面临的问题 X-Engine是阿里…...

创作纪念日让 AI 与我共同记录下今天 — 【第五周年、1460天】
今天正是五一,收到一条消息? 五一还要我加班 😏? 喔,原来是 CSDN 给我发的消息呀!我在 CSDN 不知不觉已经开启第五周年啦! 目录 1.机缘2.收获3.日常4.我与 AI 的“合作”part Ipart II Super al…...

枚举法计算24点游戏
# 请在此处编写代码 # 24点游戏 import itertools# 计算24点游戏代码 def twentyfour(cards):"""(1)itertools.permutations(可迭代对象):通俗地讲,就是返回可迭代对象的所有数学全排列方式。itertools.permutations("1118") -…...

@Cacheable注解
Cacheable注解是Spring框架中提供的一种缓存技术, 用于标记一个方法的返回值可以被缓存起来,当再次调用该方法时,如果缓存中已经存在缓存的结果,则直接从缓存中获取结果而不是再次执行该方法,从而提高系统的性能和响应…...

CentOS分区挂载 fdisk、parted方式解析
1 介绍 在linux中,通常会将持久化数据保存到硬盘当中,但是硬盘一把会比较大,因此我们为了方便管理,会将一个硬盘分成多个逻辑硬盘,称之为分区。 为了能够让分区中的文件使得能让操作系统处理,则需要对分区…...

BuildKit
介绍 BuildKit是一个现代化的构建系统,主要用于构建和打包容器镜像。它是Docker官方的构建引擎,支持构建多阶段构建、缓存管理、并行化构建、多平台构建等功能。BuildKit还支持多种构建语法和格式,包括Dockerfile、BuildKit Build Specifica…...
c++ 11标准模板(STL) std::vector (二)
定义于头文件 <vector> template< class T, class Allocator std::allocator<T> > class vector;(1)namespace pmr { template <class T> using vector std::vector<T, std::pmr::polymorphic_allocator<T>>; }(2)(C17…...

Python 循环技巧
目录 在字典中循环时,用 items() 方法可同时取出键和对应的值: 在序列中循环时,用 enumerate() 函数可以同时取出位置索引和对应的值: 同时循环两个或多个序列时,用 zip() 函数可以将其内的元素一一匹配:…...

【Java笔试强训 7】
🎉🎉🎉点进来你就是我的人了博主主页:🙈🙈🙈戳一戳,欢迎大佬指点! 欢迎志同道合的朋友一起加油喔🤺🤺🤺 目录 一、选择题 二、编程题 🔥Fibona…...
工作7年的程序员,明白了如何正确的“卷“
背景 近两年,出台和落地的反垄断法,明确指出要防止资本无序扩张。 这也就导致现在的各大互联网公司,不能再去染指其他已有的传统行业,只能专注自己目前存量的这些业务。或者通过技术创新,开辟出新的行业。 但创新这…...

BesTV_R3300-L S905L芯片刷机实战:从驱动识别到固件烧录的完整避坑指南
1. 认识你的BesTV_R3300-L盒子 我手头这台BesTV_R3300-L盒子已经吃灰大半年了,原厂系统用起来卡顿不说,还经常弹出各种广告。拆开外壳看到S905L芯片的那一刻,我就知道这玩意儿有救——毕竟这是刷机圈里的"老熟人"了。先给新手朋友科…...

LabVIEW 2021生成EXE后报表报错?手把手教你添加NIReport.llb和LVClass文件
LabVIEW报表生成避坑指南:从源码到EXE的完整解决方案 在LabVIEW开发过程中,报表生成功能是许多工程师不可或缺的工具。然而,当我们将精心编写的程序打包成可执行文件(EXE)时,常常会遇到一个令人头疼的问题&…...
)
【无人机三维路径规划】基于遗传算法GA实现复杂山地环境下无人机三维路径规划研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

深入解析PCI中断路由:从硬件引脚到操作系统中断处理的完整链路
1. 项目概述与核心问题在计算机硬件系统里,中断机制是设备与处理器高效通信的生命线。它允许设备在需要处理器服务时,主动“打断”处理器当前的工作流,而不是让处理器不断地去“询问”设备的状态。对于PCI(Peripheral Component I…...

3分钟搞定!Blender 3MF插件让你的3D打印工作流飞起来 [特殊字符]
3分钟搞定!Blender 3MF插件让你的3D打印工作流飞起来 🚀 【免费下载链接】Blender3mfFormat Blender add-on to import/export 3MF files 项目地址: https://gitcode.com/gh_mirrors/bl/Blender3mfFormat 还在为3D打印文件格式转换头疼吗…...

告别M3U8下载烦恼:N_m3u8DL-CLI-SimpleG让你的视频下载变得超简单!
告别M3U8下载烦恼:N_m3u8DL-CLI-SimpleG让你的视频下载变得超简单! 【免费下载链接】N_m3u8DL-CLI-SimpleG N_m3u8DL-CLIs simple GUI 项目地址: https://gitcode.com/gh_mirrors/nm3/N_m3u8DL-CLI-SimpleG 你是否曾经面对心爱的在线视频却束手无…...

langchain4j笔记-09
RAG 1. easy rag Test void test03() {// 1. 创建模型// 2. 加载文档List<Document> documents ClassPathDocumentLoader.loadDocuments("excel");//List<Document> documents FileSystemDocumentLoader.loadDocuments("/home/langchain4j/docum…...

LabVIEW编程整洁之道:提升代码可读性与可维护性的实战技巧
1. 项目概述:从“能用”到“好用”的进阶之路在LabVIEW这个图形化编程环境里摸爬滚打十几年,我见过太多工程师能把功能做出来,但做出来的程序却像一团乱麻——前面板控件堆叠、程序框图连线交错、结构嵌套深不见底。这样的程序,别…...

把 Key User 自定义字段纳入 abapGit 管理,让扩展交付真正可追踪
在 SAP S/4HANA Cloud 的扩展项目里,Key User Extensibility 很容易被误解成一种只属于业务顾问的配置能力。打开 Custom Fields 应用,创建字段,选择 business context,启用 UI、报表、API 或表单相关用途,发布字段,业务界面上就多了一个可用字段。这个体验很轻,几乎不像…...

2025年知识竞赛行业趋势报告:智能化、场景化与生态融合
📊 2025年知识竞赛行业趋势报告技术更智能 场景更融合 内容更鲜活 工具更普惠🚀 引言:变革中的竞赛生态知识竞赛,这一古老的知识检验与娱乐形式,在数字技术的持续赋能下,正经历着一场深刻的范式变革。从…...