【论文笔记】Attention和Visual Transformer
Attention和Visual Transformer
- Attention和Transformer
- 为什么需要Attention
- Attention机制
- Multi-head Attention
- Self Multi-head Attention,SMA
- Transformer
- Visual Transformer,ViT
Attention和Transformer
Attention机制在相当早的时间就已经被提出了,最先是在计算机视觉领域进行使用,但是始终没有火起来。Attention机制真正进入主流视野源自Google Mind在2014年的一篇论文"Recurrent models of visual attention"。在该文当中,首次在RNN上使用了Attention进行图像分类 。
然而,Attention真正得到广泛应用是在NLP领域,大量的方法在RNN/CNN模型上使用Attention机制进行各种任务。在2017年,Google的《Attention is all you need》中首次使用自注意力机制和多头注意力机制进行翻译任务,并提出了Transformer架构,取得了十分优异的性能,成为NLP领域的大爆点。
在2021年,Google Research发布了论文《AN IMAGE IS WORTH 16X16 WORDS:
TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE》,将在NLP领域取得巨大成功的Transformer引入计算机视觉领域,并提出了Visual Transformer架构,其性能接近或超过了此前传统的卷积网络。
为什么需要Attention
在Attention真正得到应用的时候(其实现在也是),神经网络的发展面临着两个问题:
- 计算能力的不足。随着模型的深度和宽度的不断增加,模型需要记住的“知识”越来越多。模型整体会变得愈发复杂,其训练和推理都会对计算能力提出很高的要求。
- 优化算法的限制。池化、BatchNorm和LayerNorm等操作可以让模型的优化变得相对简单容易,但对于高度复杂的模型,目前的优化算法或多或少存在难以优化的问题。比如,在RNN中存在的长程梯度消失问题。在进行机器翻译的时候,将长句子转换为长向量会使得模型变得很难优化,在训练过程中会出现信息损失的问题。
Attention解决以上两个问题的想法是,将模型当中的信息进行权重区分,对重要的部分进行重点关注,而忽略不是那么重要的部分。以一个翻译的例子来说,给出这样一句话
To be or not to be, that is the question.
在进行翻译的时候,对于that这个词的含义,我们显然回去更关注千年的To be or not to be,而不是is或者the。又或者,我们在看一幅图片的时候

我们显然会首先关注照片中的香蕉,进而认为这是一幅香蕉的照片。而非重点关注香蕉下面的桌子,或者后面的背景。
Attention机制的核心思想就是这样。
Attention机制
Attention的实现基于Key-Value的模型。模型的输入作为Query,与Key、Value进行计算后得到一个Attention的结果。比较抽象的图如下面所示
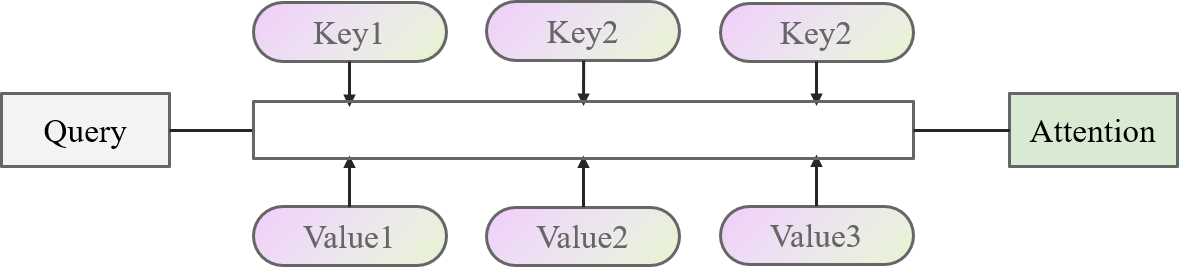
举个简单的例子来说,现在要去图书馆学习深度学习相关的知识,深度学习作为(Query)。在图书馆中,有很多类别(Key)的图书(Value),包括PyTorch与Python、数理统计、微积分、计算机组成原理、数据库等等。这些类别的图书与学习的目标有些很符合(数理统计、PyTorch),有些相关性很小(数据库、计算机组成原理)。那么,一种高效的学习方法就是重点去学习相关性很大的书籍,便可以计算深度学习(Query)和类别(Key)之间的相关性,让后根据相关性的大小学习这些书(Value),最后加起来得到学习到的知识(Attention)。
Attention的核心思想,用“加权求和”四个字就可以概括。大道至简,大爱无疆,大音希声,大象无形。加的权就是Query和Key的相关度(或者交相似性),求得和就是各个Value之间的求和。
基于此,我们再去理解一下上面的图,将上面的图展开一点。
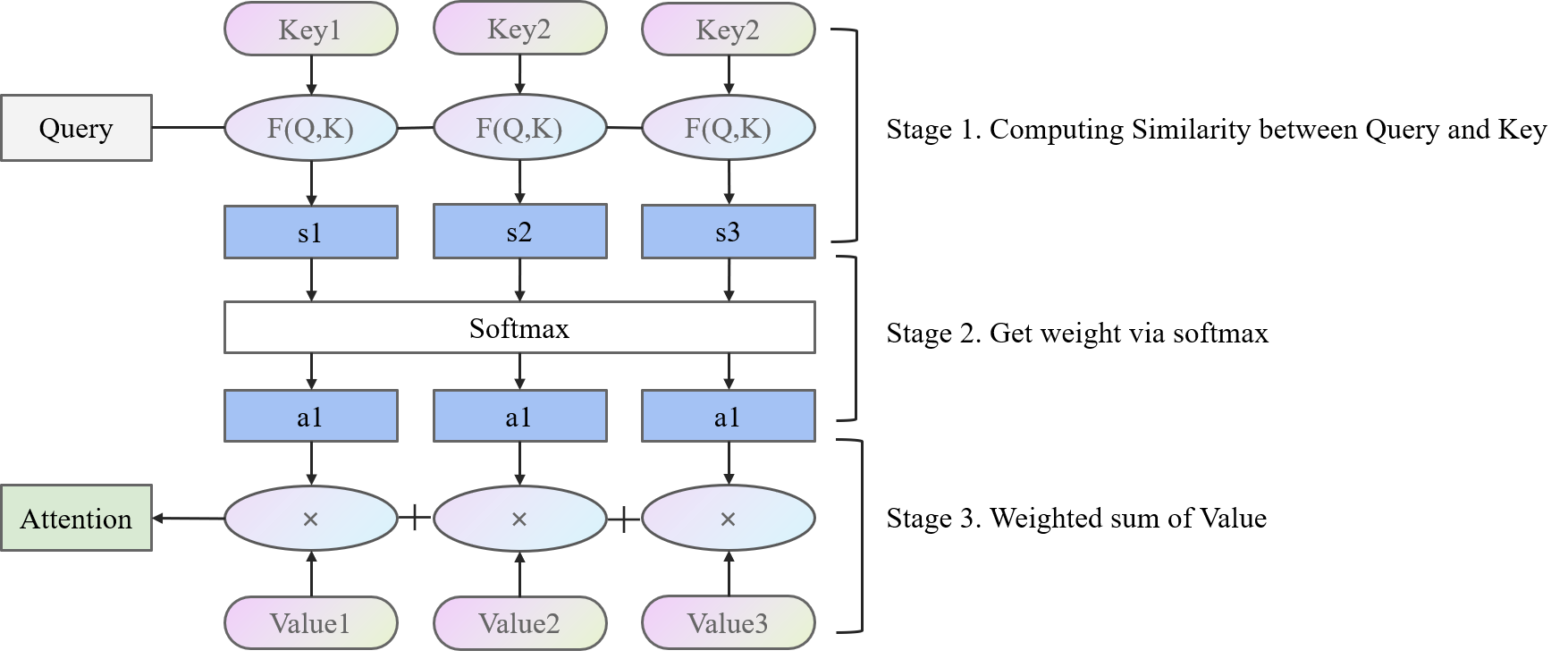
在计算Attention的时候
- 第一阶段用F(Q,K)计算Query和各个Key的相似度
- 第二阶段用softmax操作将相似度变成可以使用的权重
- 第三阶段用对应的权重乘以对应的Value,加起来得到Attention结果。
在《Attention is all you need》这篇文章中,作者给出了一种 Scaled Dot-Product Attention的计算方式。
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K ⊤ d k ) V {\rm Attention}(Q,K,V)=softmax\left( \frac{QK^{\top}}{\sqrt{d_{k}}} \right)V Attention(Q,K,V)=softmax(dkQK⊤)V
其中, Q Q Q和 K K K都具有 d k d_{k} dk的维度, N N N是样本数量。 V V V具有 d v d_{v} dv的维度。 Q K ⊤ QK^{\top} QK⊤使用点积计算两个向量的相似度,同时除以 d k \sqrt{d_{k}} dk保证数值的稳定性。这是因为,在维度过高的时候,向量内积的数值差距会变的很大,如果直接进行softmax,会使得分布趋近1和0,当对softmax求导的时候,导数会接近0,在优化过程中很难优化。
Multi-head Attention
在SDP中,计算Attention时没有什么可以计算的参数,可以先把原本的向量,通过线性层隐射到多个低维的空间,然后再并行地进行SDP Attention操作,在concat起来,可以取得更好的效果。这类似于CNN中的多通道机制。一个向量先隐射成多个更低维的向量,相当于分成了多个视角,然后每个视角都去进行Attention,这样模型的学习能力和潜力就会大大提升,另外由于这里的降维都是参数化的,所以让模型可以根据数据来学习最有用的视角。
在Attention文章中,作者提出了一种多头注意力机制Multi-head Attention,MA。其计算如下:
M u i l t H e a d ( Q , K , V ) = C o n c a t ( h e a d i , … , h e a d h ) W O h e a d i = A t t e n t i o n ( Q W i Q , K W i K , V W i V ) {\rm MuiltHead}(Q,K,V)={\rm Concat(head_{i},\dots,head_{h})}W^{O} \\ {\rm head_{i}=Attention}(QW_{i}^{Q},KW_{i}^{K},VW_{i}^{V}) MuiltHead(Q,K,V)=Concat(headi,…,headh)WOheadi=Attention(QWiQ,KWiK,VWiV)
这里,使用一个线性变换操作Q,K,V矩阵,同时在最后进行一次线性变换,得到Attention结果。整个结构如下图。

Self Multi-head Attention,SMA
自注意力机制Self Attention,将Q、K、V矩阵都变成相同的,即都是输入本身。自注意力机制实际上是想让机器注意到整个输入中不同部分之间的相关性,从自注意力机制出发,衍生出了SMA。具体流程如下所示。
首先,从Input X计算得到Q,K,V

然后进行注意力机制计算,这里以一个Head为例

Transformer
在了解了Attention相关的机理之后,就可以研究一下火到爆的变形金刚(不是)Transformer了。
我们从NLP领域的Transformer开始说起。在进行NLP任务时,Transformer使用了非常流行的编码器-解码器结构。Transformer的核心架构就是上面说的SMA。
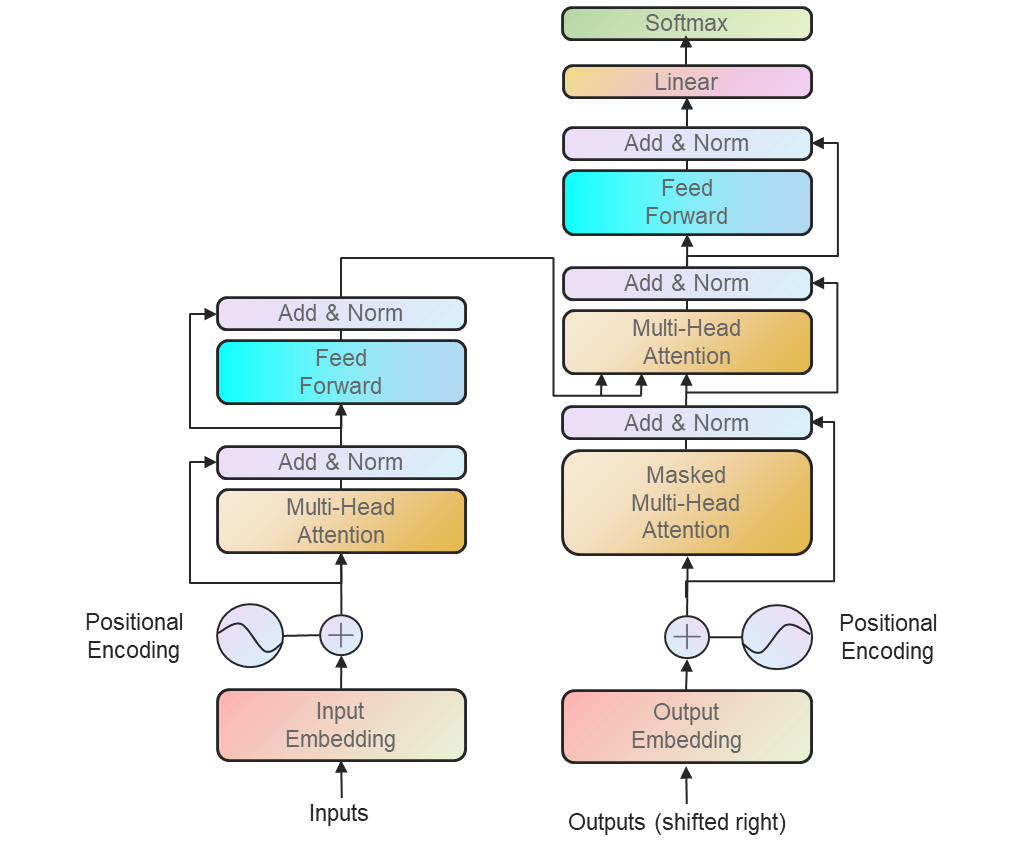
接下来我们对着这张图一步步描述Transformer的架构,这里主要描述一下编码器结构,解码器跟编码器差不多。
- Input Embedding,这部分没什么特别可说的,就是将输入变成嵌入向量。
- Positional Embedding。由于Transformer的结构完全基于Attention机制,所以对比传统RNN和CNN,模型没有办法利用输入序列的位置信息。所以,作者在这里用了一个Embedding来为模型的注入位置信息(相对或者绝对位置)。在原文中,作者给了两种进行Positional Embedding的方法,其中一种是直接对位置进行编码

其中 p o s pos pos是位置, i i i是维度。也就是说,位置编码的每个维度都对应于一个正弦曲线。选择这个函数是因为它允许模型容易地学习相对位置,因为对于任何固定偏移, P E p o s + PE_{pos+} PEpos+可以表示为 P E p o s PE_{pos} PEpos的线性函数。另一种embedding方法就简便的多,直接将embedding信息变为可学习的参数。 - 接下来的结构是两个残差的结构。在通过SMA之后进行进行残差操作,并进行一次LayerNorm,随后进入一个MLP进行相似的操作。这个模块在网络实现中是具有多个的,而非图中示意的一个。
- MLP。MLP模块中包含了两个线性层,以及一个GELU激活层。
Visual Transformer,ViT
这是一个小甜甜变牛夫人再变小甜甜的故事。最初在计算机视觉领域提出的Attention当年在视觉领域没有激起什么波澜,反而后来在NLP领域借助Transformer爆火,然后CV里面的人才想起来能不能把Transformer用到视觉领域呢?
于是乎谷歌继Attention文章之后,又提出了Visual Transformer,将Transformer的旗帜正式插到了CV领域。
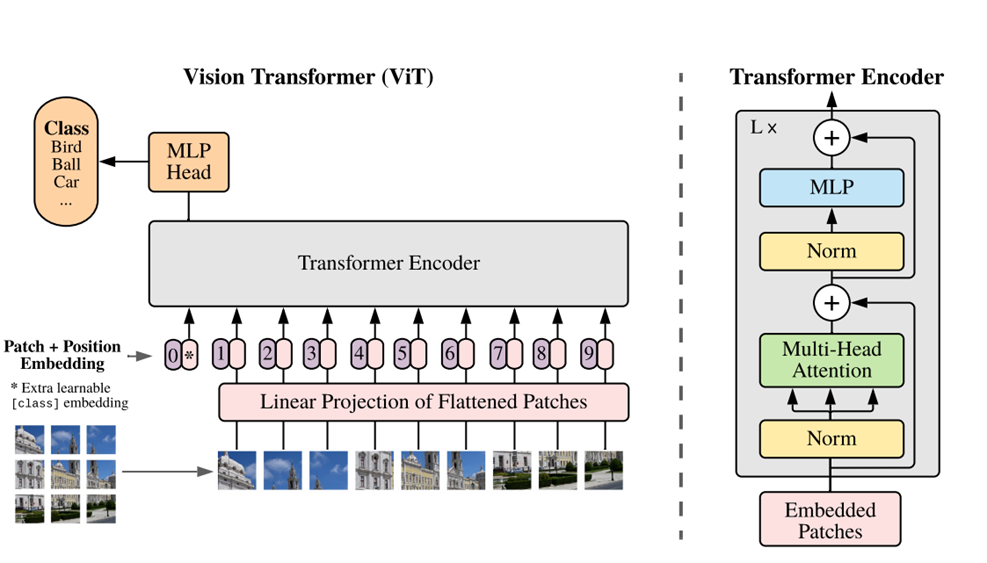
在ViT中,仅仅使用了Transformer中的编码器结构。然而,由于原始Transformer是为NLP任务设计的,是一个Sequence2Sequence的模型,这里必须将一幅图像变成Sequence的形式输入网络。接下来从头开始疏离一下ViT的结构。
- Patch。在ViT中,就如同文章标题An Image Is Worth 16X16 Words中说的一样,作者将一幅图像变成了一块一块的patch并Flatten,然后用一个线性映射做Embedding。
- Positional Embedding。和Attention文章不一样,在ViT中作者用了可学习的嵌入表示。
- Class token。作者说加入这个操作的想法来自BERT的token。简单来说,就是在Patch的序列中,加入一个学习的embedding参数,在最后用这个embedding代表整个序列进入MLP分类器作为分类。(另一种想法是序列中的所有patch就均值)
- Transformer Encoder。和Transformer基本相同,都适用MSA。
- MLP head。包含一个线性层,做分类器使用。
在看过Transformer的文章后,理解ViT其实没有难度。ViT在做实验的时候,使用在大规模数据集上的预训练模型做下游任务的fine-tuning,与先进的卷积方法达到了接近的性能。并且训练成本很低。
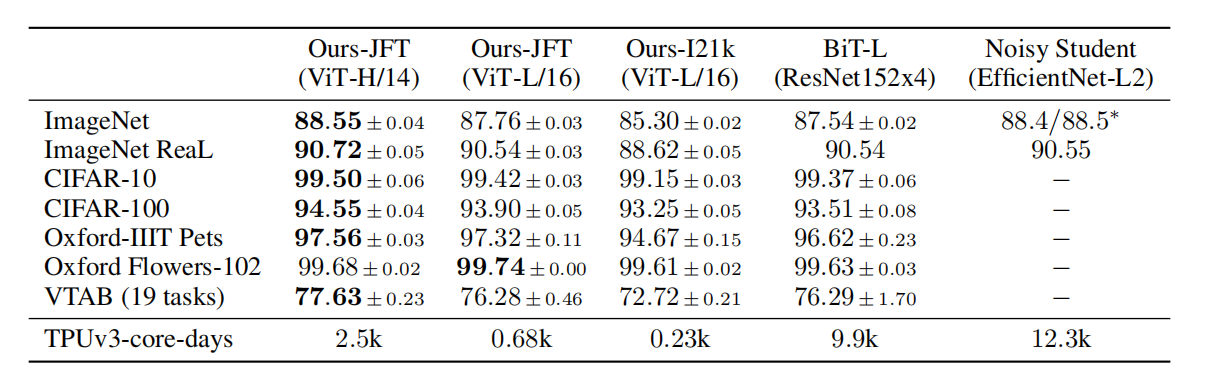
然而,在从头开始训练的时候,ViT的性能在中小规模的数据集上(ImageNet、ImageNet-21k)却不如卷积网络。如下图所示,只有在 大规模的数据集上(谷歌自家的JFT-300M),ViT的性能才表现的比卷积好。

作者在在文章中也说了,ViT缺乏一些CNN的归纳偏置(先验知识)。例如
- 局部性Locality。CNN以滑动窗口的形式工作,这假设相邻的位置特征往往相同,例如一个桌子的左边和右边的特征差不多。
- 平移不变性。translation equivariance。图像不论是先做卷积还是先平移,因为只要相同的部分遇到同一个卷积核,输出是一样的。在图像上就表现为桌子在图像上部还是下部是一样的。
ViT没有卷积操作,就缺乏了这两个先验知识。唯一的先验来自于position embedding,这其实也是逐渐学习到的。
作者还给了一些可视化的操作,例如,
给patch做embedding的结果

position embedding的可视化,可以看到虽然用的是1d的embedding,但是ViT学习到了很好的2d位置信息,比如4行4列的patch,他的poison embedding和自己的最相近,同时越和他靠近的相似性越高。而且表现出了一些行列的信息在里面。

每个注意力头的平均注意距离。平均注意距离就是两个像素点间的实际距离乘上二者之间的注意力权重。虽然在刚开始的时候有些注意力头的平均注意距离比较小(类似于卷积只利用局部信息),但到后期的注意力头已经可以注意到全局的范围上的信息了。

相关文章:
【论文笔记】Attention和Visual Transformer
Attention和Visual Transformer Attention和Transformer为什么需要AttentionAttention机制Multi-head AttentionSelf Multi-head Attention,SMA TransformerVisual Transformer,ViT Attention和Transformer Attention机制在相当早的时间就已经被提出了&…...

独立IP服务器和共享IP服务器有什么区别
在选择一个合适的服务器时,最常见的选择是共享IP服务器和独立IP服务器。尽管两者看起来很相似,但它们有着很大的不同。本文将详细介绍共享IP服务器和独立IP服务器的不同之处,以及如何选择适合您需求的服务器。 一、什么是共享IP服务器? 共享…...

Java8
Java8 (一)、双列集合(二)、Map集合常用api(三)、Map集合的遍历方式(四)、HashMap(五)、LinkedHashMap(六)、TreeMap(七&a…...

nn.conv1d的输入问题
Conv1d(in_channels, out_channels, kernel_size, stride1, padding0, dilation1, groups1, biasTrue) in_channels(int) – 输入信号的通道。在文本分类中,即为词向量的维度out_channels(int) – 卷积产生的通道。有多少个out_channels,就需要多少个1维…...
js判断是否为null,undefined,NaN,空串或者空对象
js判断是否为null,undefined,NaN,空串或者空对象 这里写目录标题 js判断是否为null,undefined,NaN,空串或者空对象特殊值nullundefinedNaN空字符串("")空对象(…...

Java每日一练(20230501)
目录 1. 路径交叉 🌟🌟 2. 环形链表 🌟🌟 3. 被围绕的区域 🌟🌟 🌟 每日一练刷题专栏 🌟 Golang每日一练 专栏 Python每日一练 专栏 C/C每日一练 专栏 Java每日一练 专栏…...

从零开始学习Web自动化测试:如何使用Selenium和Python提高效率?
B站首推!2023最详细自动化测试合集,小白皆可掌握,让测试变得简单、快捷、可靠https://www.bilibili.com/video/BV1ua4y1V7Db 目录 引言: 一、了解Web自动化测试的基本概念 二、选择Web自动化测试工具 三、学习Web自动化测试的…...

fastdfs环境搭建
安装包下载路径 libfastcommon下载地址:https://github.com/happyfish100/libfastcommon/releasesFastDFS下载地址:https://github.com/happyfish100/fastdfs/releasesfastdfs-nginx-module下载地址:https://github.com/happyfish100/fastdf…...

有什么牌子台灯性价比高?性价比最高的护眼台灯
由心感叹现在的孩子真不容易,学习压力比我们小时候大太多,特别是数学,不再是简单的计算,而更多的是培养学生其他思维方式,有时候我都觉得一年级数学题是不是超纲了。我女儿现在基本上都是晚上9点30左右上床睡觉&#x…...

信息系统项目管理师 第9章 项目范围管理
1.管理基础 1.产品范围和项目范围 产品范围:某项产品、服务或成果所具有的特征和功能。根据产品需求来衡量。 项目范围:包括产品范围,是为交付具有规定特性与功能的产品、服务或成果而必须完成的工作。项目管理计划来衡量 2.管理新实践 更加注重与商业分析师一起…...

【Android入门到项目实战-- 8.2】—— 使用HTTP协议访问网络
目录 一、使用HttpURLConnection 1、使用Android的HttpURLConnection步骤 1)获取HttpURLConnection实例 2)设置HTTP请求使用的方法 3)定制HTTP请求,如连接超时、读取超时的毫秒数 4)调用getInputStream()方法获取返回的输入流 5)关闭HTTP连接 2、…...
Go官方指南(五)并发
Go 程 Go 程(goroutine)是由 Go 运行时管理的轻量级线程。 go f(x, y, z) 会启动一个新的 Go 程并执行 f(x, y, z) f, x, y 和 z 的求值发生在当前的 Go 程中,而 f 的执行发生在新的 Go 程中。 Go 程在相同的地址空间中运行,…...

VS快捷键大全 | 掌握这些快捷键,助你调试快人一步
欢迎关注博主 Mindtechnist 或加入【Linux C/C/Python社区】一起学习和分享Linux、C、C、Python、Matlab,机器人运动控制、多机器人协作,智能优化算法,滤波估计、多传感器信息融合,机器学习,人工智能等相关领域的知识和…...

【刷题】203. 移除链表元素
203. 移除链表元素 一、题目描述二、示例三、实现方法1-找到前一个节点修改next指向方法2-不是val的尾插重构 总结 203. 移除链表元素 一、题目描述 给你一个链表的头节点 head 和一个整数 val ,请你删除链表中所有满足 Node.val val 的节点,并返回 新…...

C++11学习- CPU多核与多线程、并行与并发
随着计算机编程频繁使用,关于CPU的处理性能的讨论从未停止过,由于我最近在学习多线程相关的知识,那么就来理一理CPU的核心问题。 一、线程与进程 业解释 线程是CPU调度和分配的基本单位,可以理解为CPU只看得到线程; …...

docker登录harbor、K8s拉取镜像报http: server gave HTTP response to HTTPS client
docker登录harbor、K8s拉取镜像报http: server gave HTTP response to HTTPS client 当搭建完docker私有仓库后,准备docker login http://ip:端口 登录时会包如下错误 当我们使用docker私有仓库中的镜像在K8s集群中部署应用时会包如下错误 以上错误根据报错信息可…...

Redis在linux下安装
1.下载安装包 redis官网: Download | Redis 2.解压 2.1在目录下解压压缩包 tar -zxvf redis-7.0.11.tar.gz 2.2将redis移至另一目录下并改名为redis mv redis-7.0.11 /usr/local/redis 3.编译 进入到redis目录下,make命令编译 [rootVM-24-15-centos local]# cd…...

这里有你想知道的那些卖家友好型跨境电商平台!
目前市面上的跨境电商平台千千万,想要找到那个最合适的平台其实不容易,而且合适这个定义也有很多不同标准。龙哥今天打算从其中一个标准展开,那就是对卖家的友好程度。我们要做的话可以优先选择一些对卖家友好的平台,无论是方便我…...

架构中如何建设共识
在互联网时代,我们面临着三个与沟通交流相关的重要挑战: 分布式研发:日常工作中相对隔离的微服务研发模式;沟通障碍:分散在全球或全国多地的研发团队,以及由此带来的语言、文化和沟通障碍;认知…...

力扣(LeetCode)1172. 餐盘栈(C++)
优先队列 解题思路:根据题意模拟。用数组存储无限数量的栈。重在实现 p u s h push push 和 p o p pop pop 操作。 对于 p u s h push push 操作,需要知道当前从左往右第一个空栈的下标。分两类讨论: ①所有栈都是满的,那么我…...

从零构建知识图谱:基于NLP的实体关系抽取与Neo4j存储实践
1. 项目概述:从文本到知识的桥梁最近几年,知识图谱这个概念在自然语言处理(NLP)和人工智能领域火得不行。简单来说,它就是把散落在海量文本里的“知识点”——比如实体(人物、地点、概念)和它们…...

命令行集成AI代码审查:基于Gemini的Git工作流自动化实践
1. 项目概述:当命令行遇上代码审查在开发者的日常工作中,代码审查是保证代码质量、促进知识共享的关键环节。然而,传统的代码审查流程往往伴随着频繁的上下文切换:你需要离开终端,打开浏览器,登录代码托管平…...

nardeas/ssh-agent:增强版SSH代理工具的设计、部署与实战应用
1. 项目概述:一个被低估的SSH代理工具如果你和我一样,日常需要在多台服务器、开发机、跳板机之间穿梭,手里捏着十几把甚至几十把SSH密钥,那你一定对ssh-agent这个工具又爱又恨。爱的是,它确实能让你免去一遍遍输入密钥…...
RWKV:融合RNN与Transformer优势的高效语言模型架构解析与实践
1. 项目概述:一个“非Transformer”的现代语言模型 如果你最近在关注大语言模型(LLM)的开源生态,除了那些基于Transformer架构的“巨无霸”,可能还听说过一个名字有点特别的项目: RWKV 。这个由开发者Bli…...

终极免费解决方案:番茄小说下载器的完整使用指南
终极免费解决方案:番茄小说下载器的完整使用指南 【免费下载链接】Tomato-Novel-Downloader 番茄小说下载器不精简版 项目地址: https://gitcode.com/gh_mirrors/to/Tomato-Novel-Downloader 在数字阅读时代,你是否经常遇到网络小说格式不兼容、内…...

NotebookLM文献管理到底靠不靠谱?——基于372篇实证论文的引用准确率压力测试报告
更多请点击: https://intelliparadigm.com 第一章:NotebookLM文献管理到底靠不靠谱?——基于372篇实证论文的引用准确率压力测试报告 为验证Google NotebookLM在学术场景下的引用可靠性,我们对372篇跨学科实证论文(含…...

深度解析AzurLaneAutoScript:碧蓝航线自动化脚本的技术架构与应用实践
深度解析AzurLaneAutoScript:碧蓝航线自动化脚本的技术架构与应用实践 【免费下载链接】AzurLaneAutoScript Azur Lane bot (CN/EN/JP/TW) 碧蓝航线脚本 | 无缝委托科研,全自动大世界 项目地址: https://gitcode.com/gh_mirrors/az/AzurLaneAutoScript…...

LabVIEW通过OPC DA连接任意PLC:架构、配置与实战指南
1. 项目概述:为什么是LabVIEWOPC? 如果你在工业自动化、测试测量或者数据采集领域摸爬滚打过一阵子,大概率听过LabVIEW的大名,也可能被各种PLC(可编程逻辑控制器)五花八门的通讯协议搞得头疼。把LabVIEW和任…...

基于改进型PCNN的不规则图像自适应分割算法研究
基于改进型PCNN的不规则图像自适应分割算法研究根据论文中的相关内容,以下是使用不同方法解决图像分割问题并进行改进的研究:冯登超等人提出了基于改进型脉冲耦合神经网络(PCNN)的自适应分割算法。他们在原有PCNN模型的基础上对神…...

RakkasJS深度解析:基于Bun的全栈React框架性能与迁移实践
1. 项目概述:下一代全栈React框架的探索如果你和我一样,在过去几年里深度使用过Next.js、Remix或者SvelteKit这类全栈框架,那你肯定对它们带来的开发体验又爱又恨。爱的是它们统一了前后端,让全栈开发变得前所未有的顺畅ÿ…...